Linux 下使用 Docker-Compose 安装 Kafka 和 Kafka-UI(KRaft 模式)
一、背景
测试 Apache ShenYu 网关日志采集和处理时,选用了 kafka 插件。所以记录一下docker-compose 搭建本地 Kafka 环境,通过 Kafka-UI 可视化管理工具进行消息查看和调试的过程。
二、安装环境
- 操作系统:CentOS 7.9
- Docker 版本:20.10.2
- Docker-Compose 版本:v2.38.2
- Kafka 版本:3.9.1(采用 KRaft 模式)
- Kafka-UI 镜像:
provectuslabs/kafka-ui:latest
三、Kafka 与 Kafka-UI 安装与启动配置
1. 准备 .env 环境变量文件
.env 文件中定义了 Kafka 的 CLUSTER_ID 和 META_FILE 路径。CLUSTER_ID 可以通过 uuidgen 命令生成,也可以根据自己的需求定义,META_FILE 的路径和 server.properties 中的 log.dirs 保持一致。
CLUSTER_ID=yourid
META_FILE=/tmp/kraft-combined-logs/meta.properties
2. 编写 docker-compose.yml
Kafka 和 Kafka-UI 的完整部署配置。注意将 yourip 替换为自己服务器的真实 IP 地址。
services:kafka:image: apache/kafka:3.9.1container_name: kafkaports:- "9099:9099"volumes:- ./kafka/server.properties:/opt/kafka/config/kraft/server.properties- ./kafka/data:/kafka/data- ./kafka/kraft-logs:/tmp/kraft-combined-logscommand: >bash -c "META_FILE=${META_FILE};if [ ! -f $META_FILE ]; thenecho '[Kafka Init] Formatting with fixed cluster.id: ${CLUSTER_ID}';/opt/kafka/bin/kafka-storage.sh format -t ${CLUSTER_ID} -c /opt/kafka/config/kraft/server.properties;elseecho '[Kafka Start] meta.properties exists, skipping format...';fi &&/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/kraft/server.properties"kafka-ui:image: provectuslabs/kafka-ui:latestcontainer_name: kafka-uiports:- 9094:8080environment:KAFKA_CLUSTERS_0_NAME: local-kafkaKAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: yourip:9099
3. Kafka 配置文件(server.properties)
server.properties 是我从容器中搞出来的完整配置,按需修改端口和 ip, 我将端口改成了9099。 以下是关键配置项:
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.#
# This configuration file is intended for use in KRaft mode, where
# Apache ZooKeeper is not present.
############################## Server Basics ############################## The role of this server. Setting this puts us in KRaft mode
process.roles=broker,controller# The node id associated with this instance's roles
node.id=1# The connect string for the controller quorum
controller.quorum.voters=1@kafka:9093############################# Socket Server Settings ############################## The address the socket server listens on.
# Combined nodes (i.e. those with `process.roles=broker,controller`) must list the controller listener here at a minimum.
# with PLAINTEXT listener name, and port 9092.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://0.0.0.0:9099,CONTROLLER://0.0.0.0:9093# Name of listener used for communication between brokers.
inter.broker.listener.name=PLAINTEXT# Listener name, hostname and port the broker or the controller will advertise to clients.
# If not set, it uses the value for "listeners".
advertised.listeners=PLAINTEXT://yourip:9099,CONTROLLER://yourip:9093# A comma-separated list of the names of the listeners used by the controller.
# If no explicit mapping set in `listener.security.protocol.map`, default will be using PLAINTEXT protocol
# This is required if running in KRaft mode.
controller.listener.names=CONTROLLER# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL# The number of threads that the server uses for receiving requests from the network and sending responses to the network
num.network.threads=3# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600############################# Log Basics ############################## A comma separated list of directories under which to store log files
log.dirs=/tmp/kraft-combined-logs# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=1# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1############################# Internal Topic Settings #############################
# The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"
# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1############################# Log Flush Policy ############################## Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# 1. Durability: Unflushed data may be lost if you are not using replication.
# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis.# The number of messages to accept before forcing a flush of data to disk
#log.flush.interval.messages=10000# The maximum amount of time a message can sit in a log before we force a flush
#log.flush.interval.ms=1000############################# Log Retention Policy ############################## The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=168# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000启动服务
docker-compose up -d
# 启动失败可以根据日志查询,在docker-compose.yml目录执行命令
docker-compose logs -f
# 或者执行
docker logs 容器名
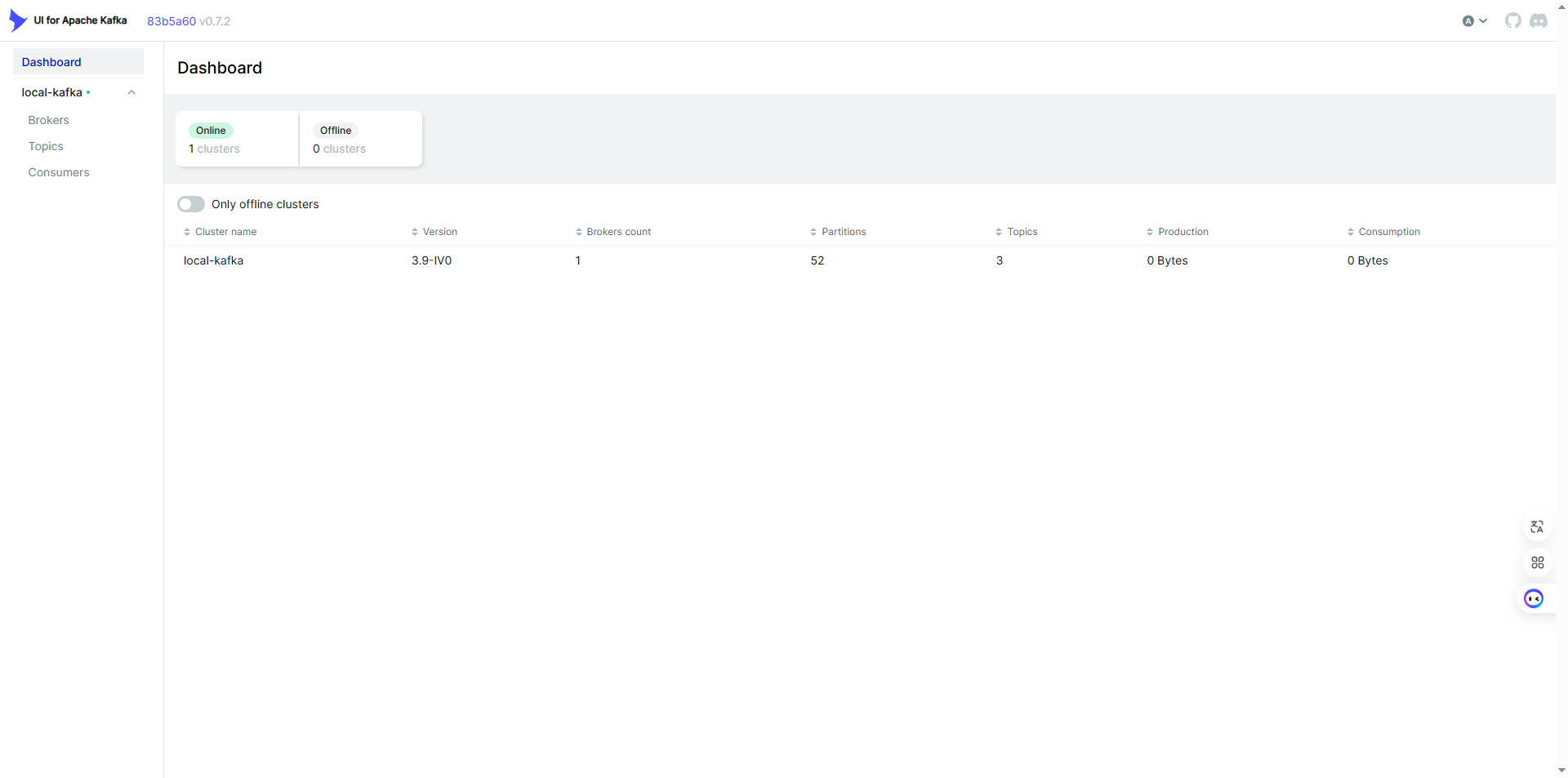
访问 Kafka-UI
浏览器访问:http://yourip:9094
可以在页面中查看看板、topic、消费者了。
四、Java 生产者和消费者示例
使用 java 编写生产者和消费者逻辑。通过 Kafka-UI 可以可视化查看消息流转情况,maven 依赖版本最好保持和 kafka 一致或高于 kafka 的版本。
Maven 依赖:
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.9.1</version>
</dependency>
为了测试方便,我写在同一个类中了。
import org.apache.kafka.clients.admin.AdminClient;
import org.apache.kafka.clients.admin.AdminClientConfig;
import org.apache.kafka.clients.admin.NewTopic;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
import java.util.Set;
import java.util.concurrent.ExecutionException;/**** @title* @author shijiangyong* @date 2025/10/16 17:50**/
public class KafkaTest {public static void main(String[] args) {String bootstrapServers = "yourip:9099";String topic = "kafa-test--log";// producer(bootstrapServers, topic);consumer(bootstrapServers, topic);}private static void consumer(String bootstrapServers, String topic) {Properties props = new Properties();props.put("bootstrap.servers", bootstrapServers);props.put("group.id", "shenyu-group");props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("auto.offset.reset", "latest");try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props)) {consumer.subscribe(Collections.singletonList(topic));while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> record : records) {System.out.printf("消费消息: %s%n", record.value());}}}}/*** 生产者* @param bootstrapServers* @param topic*/private static void producer(String bootstrapServers, String topic) {createTopicIfNotExists(bootstrapServers, topic);Properties props = new Properties();props.put("bootstrap.servers", bootstrapServers);props.put("key.serializer", StringSerializer.class.getName());props.put("value.serializer", StringSerializer.class.getName());try (KafkaProducer<String, String> producer = new KafkaProducer<>(props)) {String message = "别扯些没用的";ProducerRecord<String, String> record = new ProducerRecord<>(topic, "test-key",message);producer.send(record, (metadata, exception) -> {if (exception == null) {System.out.println("sent to topic: " + metadata.topic());} else {exception.printStackTrace();}});}}/*** topic不存在则创建,可以自己在kafka-ui中创建* @param bootstrapServers* @param topic*/private static void createTopicIfNotExists(String bootstrapServers, String topic) {Properties adminProps = new Properties();adminProps.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);try (AdminClient adminClient = AdminClient.create(adminProps)) {// 获取已存在的 topic 列表Set<String> topics = adminClient.listTopics().names().get();if (!topics.contains(topic)) {// 创建 topic(默认1个分区,1个副本)NewTopic newTopic = new NewTopic(topic, 1, (short) 1);adminClient.createTopics(Collections.singleton(newTopic)).all().get();System.out.println("create topic : " + topic);} else {System.out.println("topic already exists: " + topic);}} catch (InterruptedException | ExecutionException e) {e.printStackTrace();}}
}
注: kafka 默认可以自动创建 topic 的。如果不想自动创建,在server.properties文件中增加auto.create.topics.enable=false ,重启容器即可。
调用生产者生产日志,结果如图:
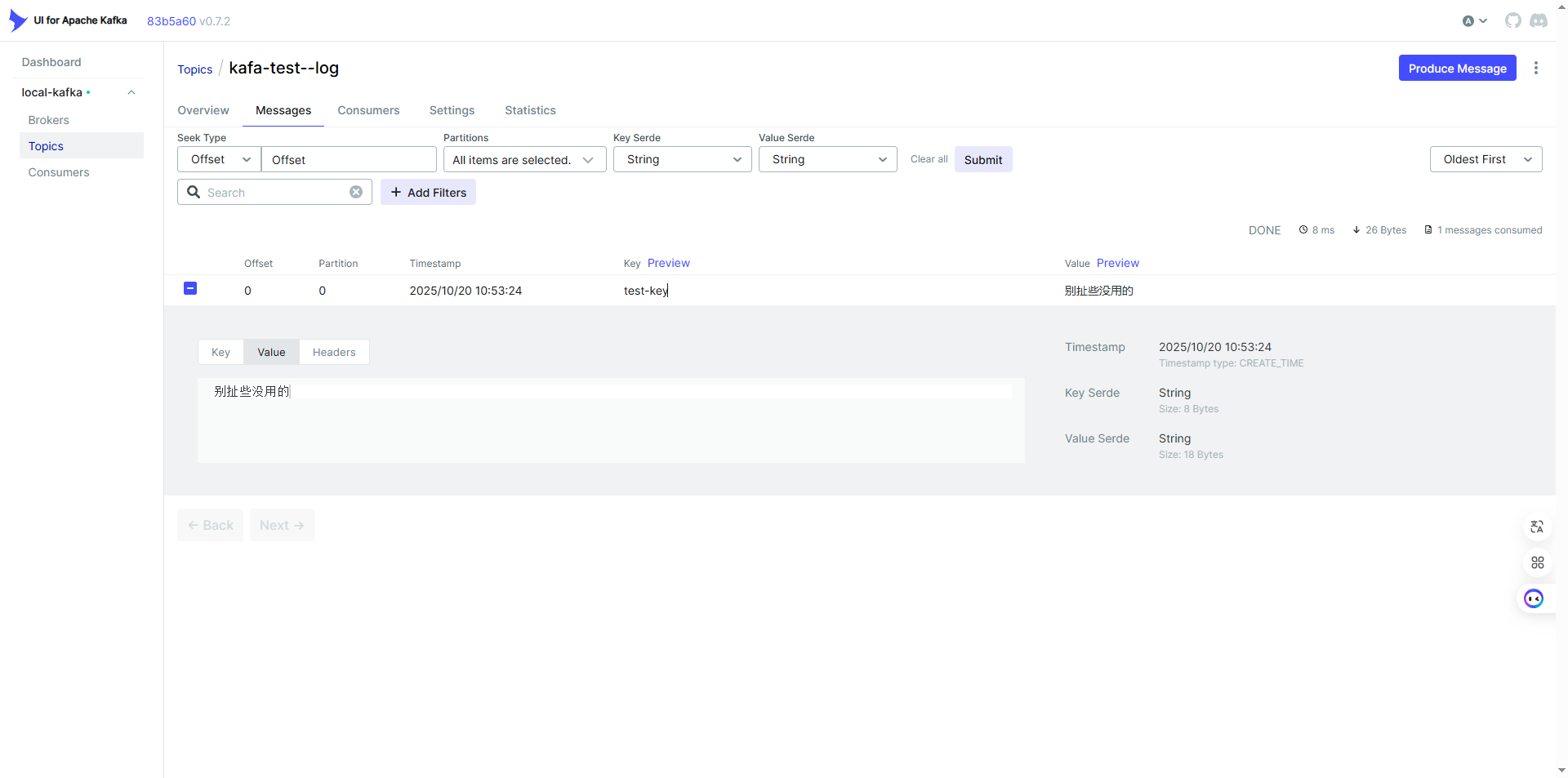
调用消费者消费日志,结果如图:

五、ShenYu 网关 Kafka 消费者代码示例
kafka 中消息:
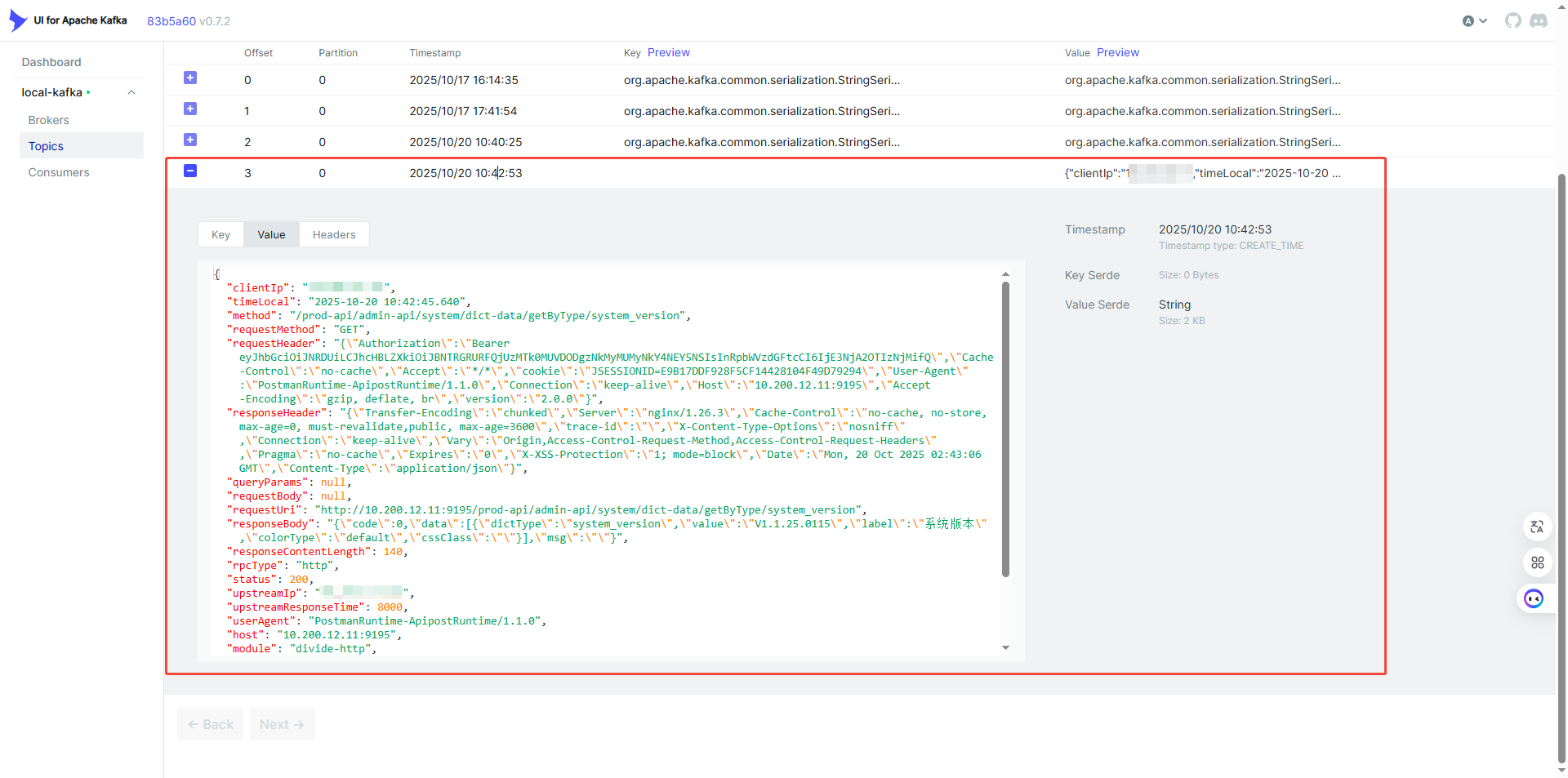
集成在 ShenYu 插件中的 Kafka 消费者代码如下,用于日志订阅消费。调用 start() 方法后即可开始接收日志记录。
import com.google.gson.Gson;
import com.google.gson.GsonBuilder;
import com.google.gson.JsonDeserializer;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.shenyu.admin.mapper.BizAuditLogMapper;
import org.apache.shenyu.admin.model.entity.BizAuditLogDO;
import org.springframework.stereotype.Component;import javax.annotation.PostConstruct;
import java.time.Duration;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.Collections;
import java.util.Properties;/**** @title* @author shijiangyong* @date 2025/10/15 15:00**/
@Slf4j
@Component
@RequiredArgsConstructor
public class KafkaLogConsumerService {private final BizAuditLogMapper bizAuditLogMapper;private final Gson gson = new GsonBuilder().registerTypeAdapter(LocalDateTime.class, (JsonDeserializer<LocalDateTime>) (json, type, ctx) ->LocalDateTime.parse(json.getAsString(), DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss.SSS"))).create();@PostConstructpublic void startConsumer() {Thread thread = new Thread(this::consumeLoop, "shenyu-kafka-consumer");thread.setDaemon(true);thread.start();}private void consumeLoop() {Properties props = new Properties();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "your:9099");props.put(ConsumerConfig.GROUP_ID_CONFIG, "shenyu-log-gson-consumer");props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");// props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props)) {consumer.subscribe(Collections.singletonList("shenyu-access-logging"));while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> record : records) {// 只处理没有 key 的消息if (record.key() != null) {log.info("忽略含 key 的消息: {}", record.key());continue;}try {BizAuditLogDO logEntry = gson.fromJson(record.value(), BizAuditLogDO.class);bizAuditLogMapper.addDynamicBizAuditLog(logEntry);log.info("插入成功:{}", logEntry.getRequestUri());} catch (Exception e) {log.error("消息解析或入库失败,内容: {}", record.value(), e);}}}} catch (Exception e) {log.error("Kafka 消费异常中止:", e);}}
}
每调用一次就存入接口,记录便存到 mysql 中。
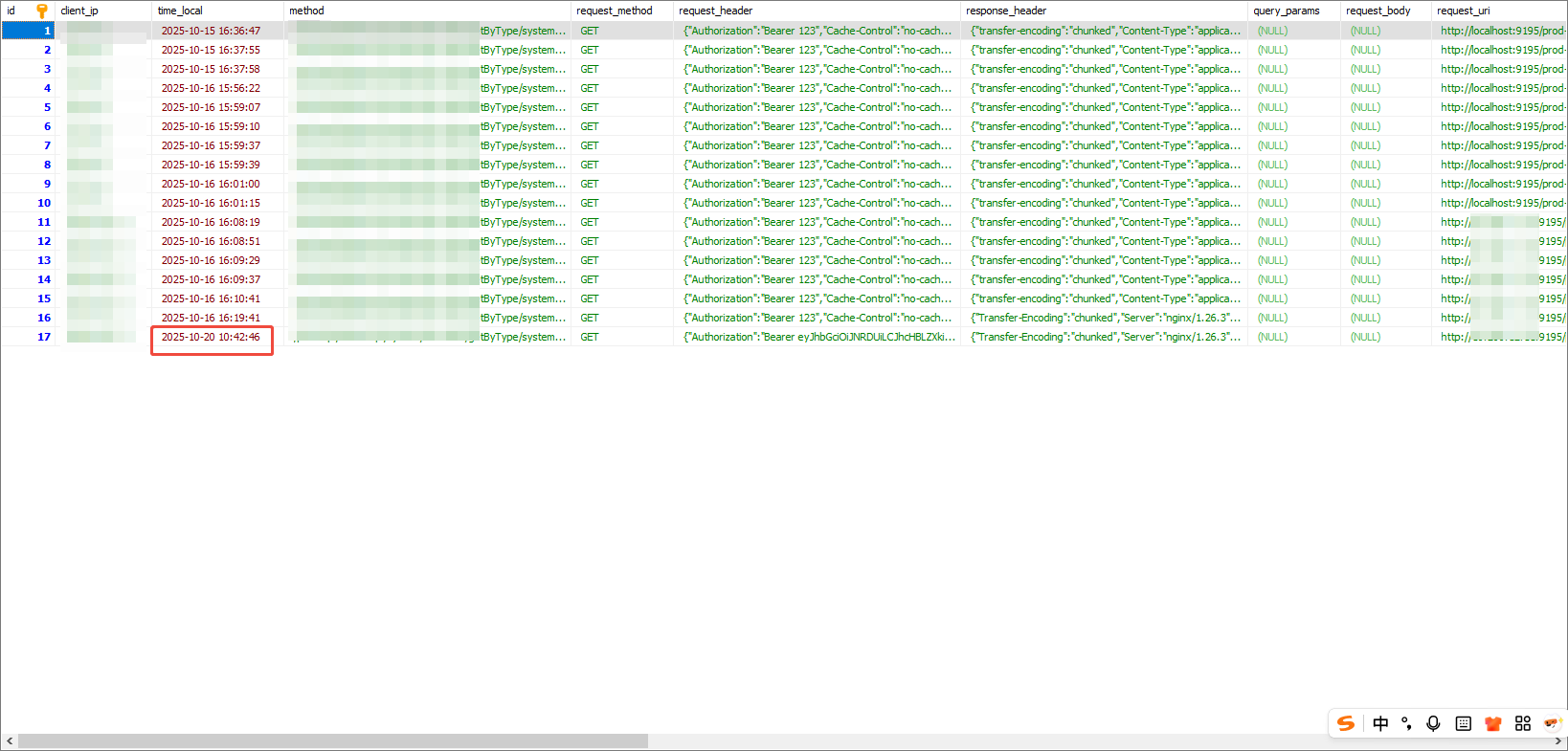
六、遇到的问题与解决方案
问题一:Kafka 启动失败,提示找不到 meta.properties
报错信息:
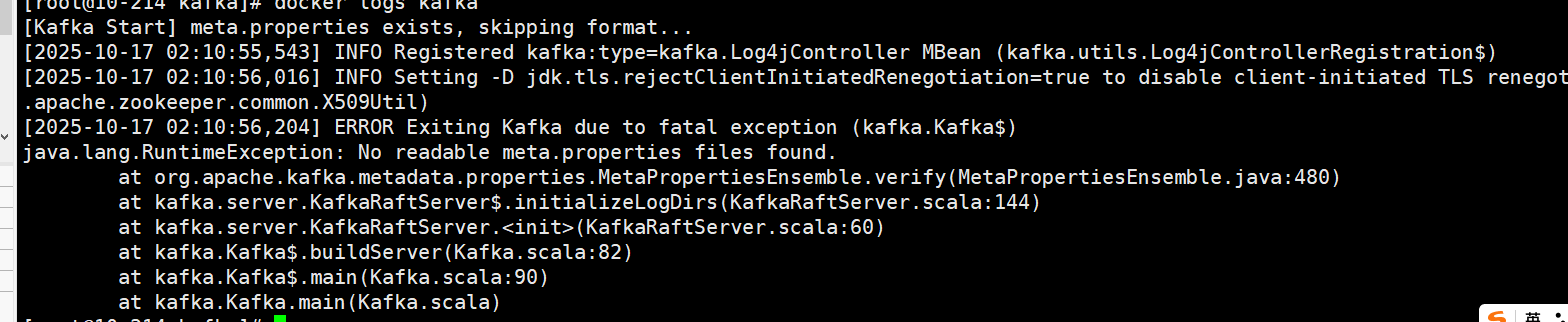
原因分析:
没有将 log.dirs(即 /tmp/kraft-combined-logs)挂载到宿主机,容器重启后该目录被清空,导致 Kafka 无法读取 KRaft 所需的 meta.properties, Kafka 在 KRaft 模式(无 ZooKeeper) 下,依赖 meta.properties 文件用于标识 broker 的唯一身份、cluster id 等信息 ,所以启动失败。
解决方案:
持久化 meta.properties到宿主机。
- ./kafka/kraft-logs:/tmp/kraft-combined-logs
问题二:Kafka 初始化时报错无法写入 meta.properties
报错信息:

原因分析:
宿主机上挂载目录是用 root 创建的,Kafka 容器内的进程(通常为 UID 1000)无权限写入。
解决方案:
执行命令修复挂载目录权限:
sudo chown -R 1000:1000 ./kafka/kraft-logs
问题三:JVM 无权限写入 GC 日志
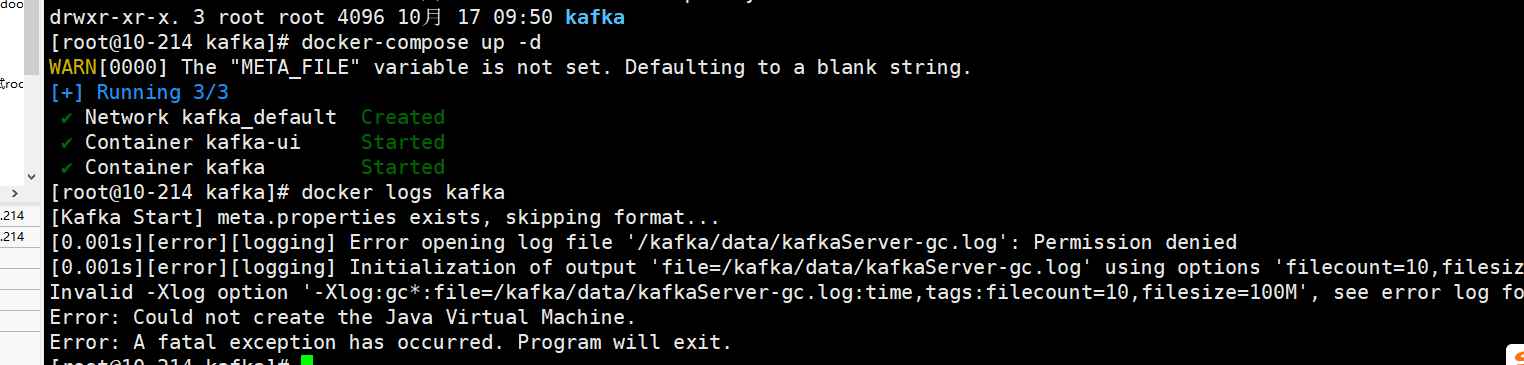
原因分析:
Kafka 默认将 GC 日志写入 /kafka/data,但是这个目录对容器内进程没有写权限。
解决方案:
执行命令修复挂载目录权限:
sudo chown -R 1000:1000 ./kafka/data
或者禁用 GC 日志输出,这个我没试。