九成自动化备份知乎专栏
从前我在雅虎博客上写了一些诗,后来雅虎离开中国,博客关闭,虽然发过要我备份的的邮件,但是我没注意,后来雅虎走了,那些诗就丢失了。现在我在知乎上写了个笑庵诗草专栏,前天知乎崩溃上不去,一下子让我紧张了,赶紧把专栏备份。专栏上的诗也不多,文言白话总共也就五十来首,但是作为会写程序的文科生,怎么可能去一篇篇打开并复制保存呢?先找AI要个脚本。知乎的API修改了,AI的脚本只能自动爬取前十首。再上网找个脚本,最多也就AI的水平。没办法,只能自己动动脑子了。
打开知乎专栏的时候,它只会显示一部分文章,但是滚动鼠标的话,专栏中的文章会逐步列出来,直至全部完成。如果知道了所有这些文章的ID,那么利用知乎的API就能很容易获取文章的信息,再借助BeautifulSoup,就可以很容易分析内容并保存了。所以这里最关键的是要能够打开知乎专栏并自动化模拟手工滚动鼠标,从而取得文章的ID。正好有至少两个库Playwright和Selenium可以实现模拟手工滚动鼠标的效果。另外,获取文章ID后,要利用知乎的API读取文章信息,必须传入知乎的cookie以标志登录信息。以我是用的Firefox浏览器为例,打开知乎,按F12键调出开发者工具,如下图所示可以找到自己的知乎cookie:
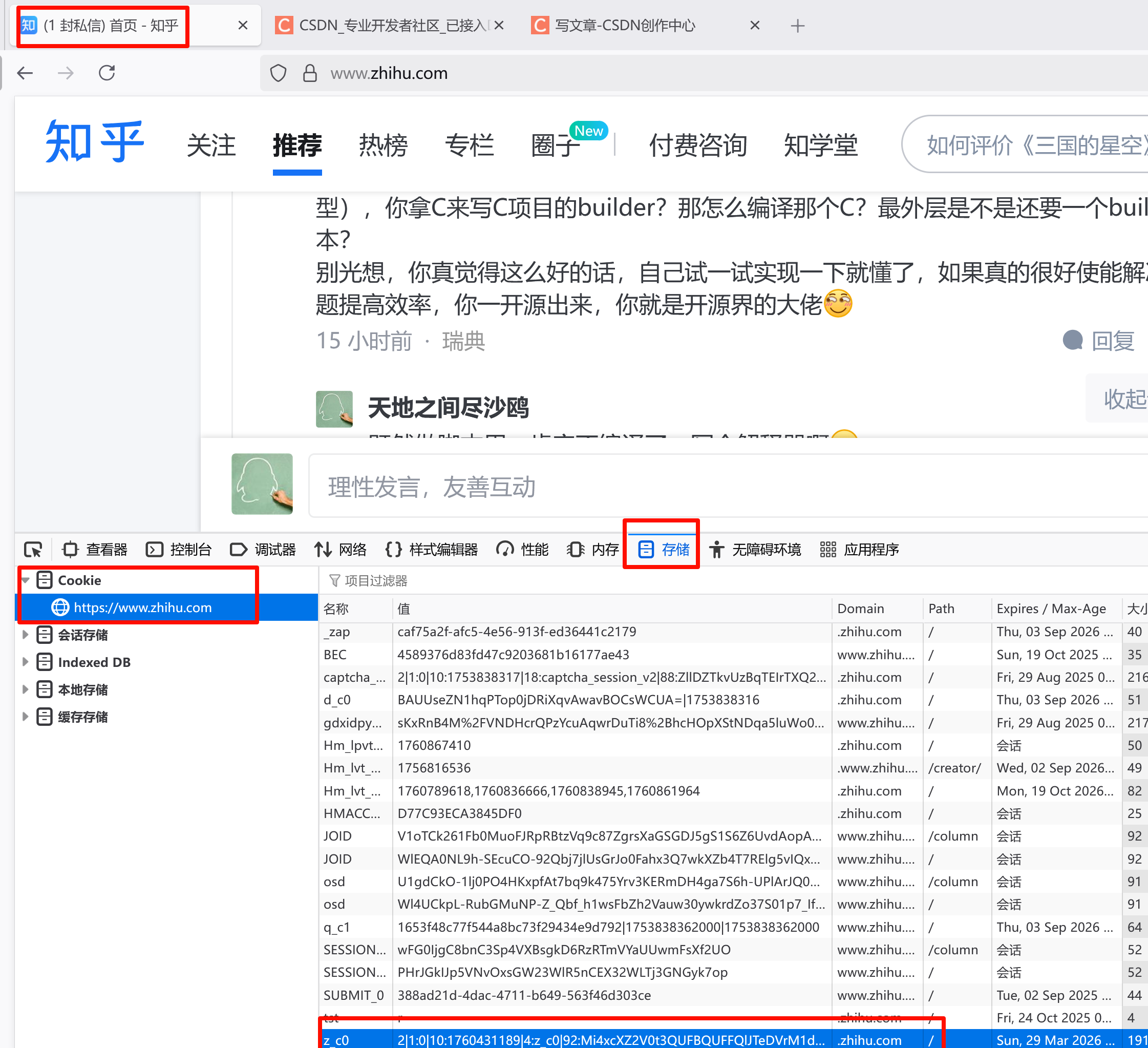 在z_c0那行的值那一列双击,复制其内容即是我们需要的cookie。
在z_c0那行的值那一列双击,复制其内容即是我们需要的cookie。
下面的程序利用Playwright运行Firefox浏览器手工打开知乎网站并登录,登录后在程序运行窗口按下回车键(这就是为什么这个程序只有九成自动化,因为手工登录这一点如果避免就没法取到专栏全部文章的ID),然后自动滚动鼠标不停加载文章,直至加载的文章总数达到专栏文章的总数。然后遍历ID列表,利用知乎API读取文章信息,在使用BeautifulSoup解析文章内容,拼接后保存为md格式的文件。
import os
import random
import re
import time
from datetime import datetime
from urllib.parse import urljoinimport requests
from bs4 import BeautifulSoup
from playwright.sync_api import sync_playwrightdef get_zhihu_column_article_count(column_id: str, headers: dict) -> int:"""获取知乎专栏文章总数Args:column_id: 专栏ID(从专栏URL提取,如"c_123456")headers: 浏览器请求头,包含知乎登录Cookie(需包含z_c0字段)Returns:文章总数,失败时返回-1"""url = f"https://www.zhihu.com/api/v4/columns/{column_id}/items"params = {"limit": 1, "offset": 0} # 仅请求1篇文章,减少数据传输try:response = requests.get(url, headers=headers, params=params)response.raise_for_status() # 抛出HTTP错误(如403/404)data = response.json()return data.get("paging", {}).get("totals", 0) # 从分页信息提取总数except Exception as e:print(f"获取{column_id}专栏文章总数失败:{str(e)}")return -1def get_zhihu_column_article_ids(column_id, count_headers):with sync_playwright() as p:# 启动浏览器(可以选择 Chromium、Firefox 或 WebKit)browser = p.firefox.launch(headless=False) # 设置 headless=False 可以看到浏览器界面page = browser.new_page()# 设置 User-Agent 和其他请求头page.set_extra_http_headers({"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"})# 手动登录知乎(或加载保存的 Cookie)page.goto("https://www.zhihu.com/signin")print("请在打开的浏览器中手动登录知乎,登录后按 Enter 键继续...")input() # 等待用户手动登录# 打开专栏页面url = f"https://zhuanlan.zhihu.com/{column_id}"page.goto(url, timeout=60000)print(f"已打开专栏页面:{url}")# 等待页面初始加载time.sleep(3)# 用于存储文章 ID 的集合article_ids = set()# 取得专栏文章总数total_ids = get_zhihu_column_article_count(column_id, count_headers)while True:# 模拟鼠标滚动,加载更多文章page.mouse.wheel(0, 10000) # 每次滚动 10000 像素time.sleep(random.uniform(2, 4)) # 随机等待 2-4 秒current_ids = page.evaluate("""() => {const links = Array.from(document.querySelectorAll('a[href*="/p/"]'));return links.map(link => {const href = link.getAttribute('href');const match = href.match(/\/p\/(\d+)/);return match ? match[1] : null;}).filter(id => id !== null);}""")article_ids.update(current_ids)print(f"当前已获取文章 ID 数量:{len(article_ids)}")# 已获取全部文章 ID 则退出循环,否则继续模拟滚动鼠标加载剩余文章if len(article_ids) >= total_ids:print(f"已获取全部id,共{len(article_ids)}个。")break# 关闭浏览器browser.close()return list(article_ids)def get_article_detail(article_id, article_headers):"""获取单篇文章详情(标题、正文、发布时间等)Args:article_id: 文章IDarticle_headers: 浏览器请求头,包含知乎登录Cookie(需包含z_c0字段)Returns:文章详情JSON,失败时返回None"""if not article_id:return None# 利用知乎API获取文章详情url = f"https://www.zhihu.com/api/v4/articles/{article_id}"params = {"include": "content,title,created,author.name"} # 包含所需字段try:response = requests.get(url, headers=article_headers, params=params)response.raise_for_status() # 抛出HTTP错误(如403、404)return response.json()except Exception as e:print(f"获取文章详情失败(ID={article_id}):{str(e)}")return Nonedef download_image(img_url, article_title, article_headers):"""下载图片到本地并返回相对路径(复用原逻辑)"""if not img_url:return ""img_url = urljoin("https://zhihu.com", img_url)img_ext = img_url.split(".")[-1].split("?")[0].lower()if img_ext not in ["jpg", "jpeg", "png", "gif"]:img_ext = "jpg"# 先生成安全的文件名再用于 f-string,避免在 f-string 表达式中使用反斜杠或需转义的引号safe_title = re.sub(r'[\\/*?:"<>|]', '_', article_title)img_filename = f"{safe_title}_{int(time.time())}.{img_ext}"img_path = os.path.join(image_dir, img_filename)try:response = requests.get(img_url, headers=article_headers, stream=True, timeout=10)response.raise_for_status()with open(img_path, "wb") as f:for chunk in response.iter_content(chunk_size=8192):f.write(chunk)return os.path.relpath(img_path, SAVE_DIR)except Exception as e:print(f"图片下载失败:{img_url},错误:{str(e)}")return img_urldef parse_article_content(html_content, article_title):"""解析HTML正文为Markdown(优化诗词排版处理)"""soup = BeautifulSoup(html_content, "html.parser")md_content = []# 处理段落和换行(增强对诗词格式的支持)for block in soup.find_all(["p", "div"]):# 跳过空块if not block.get_text(strip=True) and not block.find_all("img"):continue# 处理图片img_tags = block.find_all("img")for img in img_tags:img_url = img.get("data-original") or img.get("src")local_img_path = download_image(img_url, article_title)md_content.append(f"\n")img.extract()# 处理文本(保留空行,适合诗词分行)text = block.get_text().strip()if text:# 对包含中文标点的段落保留原始换行(适合诗词)if re.search(r'[,。;!?]', text):md_content.append(text + "\n")else:md_content.append(text + "\n\n") # 普通文本增加空行分隔return "\n".join(md_content).rstrip("\n") # 移除末尾多余空行def save_article_as_markdown(article_data):"""保存文章为Markdown文件(增加作者信息)"""if not article_data:return Falsetitle = article_data.get("title", "未命名文章")safe_title = re.sub(r'[\\/*?:"<>|]', "_", title)created_time = datetime.fromtimestamp(article_data.get("created", 0)).strftime("%Y-%m-%d")author = article_data.get("author", {}).get("name", "未知作者")html_content = article_data.get("content", "")md_content = parse_article_content(html_content, safe_title)# Markdown头部(包含作者信息)md_header = f"# {title}\n\n**作者**:{author} | **发布时间**:{created_time}\n\n---\n\n"full_md = md_header + md_contentfile_path = os.path.join(SAVE_DIR, f"{created_time}_{safe_title}.md")with open(file_path, "w", encoding="utf-8") as f:f.write(full_md)print(f"✅ 已保存:{os.path.basename(file_path)}")return True# ---------------------- 提供重新下载前次备份失败的文章的功能 --------------------------
def load_backuped_ids(save_dir: str):"""从文件加载已备份的文章ID"""id_file = os.path.join(save_dir, "backuped_ids.txt")if os.path.exists(id_file):with open(id_file, "r", encoding="utf-8") as f:return set(f.read().splitlines())return set()def save_backuped_id(article_id, save_dir: str):"""保存已备份的文章ID到文件"""id_file = os.path.join(save_dir, "backuped_ids.txt")with open(id_file, "a", encoding="utf-8") as f:f.write(f"{article_id}\n")def batch_backup_articles(column_id, save_dir, article_headers, count_headers):"""知乎专栏文章批量备份,支持备份失败后再次运行继续备份未完成的文章"""# 读取已备份的文章IDbackuped_ids = load_backuped_ids(save_dir)success_count = 0fail_count = 0ids = get_zhihu_column_article_ids(column_id, count_headers)print(f"开始备份 {len(ids)} 篇文章...\n")for article_id in ids:print(f"\n----- 处理 ID:{article_id} -----")# 跳过已备份的文章if article_id in backuped_ids:print(f"已跳过(已备份):{article_id}")continuearticle_data = get_article_detail(article_id, article_headers)save_backuped_id(article_id, save_dir)if save_article_as_markdown(article_data):success_count += 1else:fail_count += 1time.sleep(random.uniform(3, 5)) # 随机等待 3-5 秒, 控制请求间隔,避免触发反爬print(f"\n===== 备份完成 =====")print(f"成功:{success_count} 篇 | 失败:{fail_count} 篇")print(f"保存路径:{os.path.abspath(save_dir)}")if __name__ == "__main__":# 1. 替换为目标专栏ID(打开知乎专栏,浏览器地址栏中c_开头加上一串数字的字符串就是专栏ID,如"https://zhihu.com/column/c_123456" → "c_123456")COLUMN_ID = "c_1745169660587147264" # 笑庵诗草专栏ID# 2. 替换为你的知乎Cookie(需赋值为z_c0字段)COOKIE = "你的知乎Cookie字符串" # 从浏览器开发者工具获取:存储 → CookieSAVE_DIR = "./备份" # 本地保存路径USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:125.0) Gecko/20100101 Firefox/125.0"# 用于获取文章总数的请求头headers = {"User-Agent": USER_AGENT,"Cookie": COOKIE,"Referer": f"https://zhuanlan.zhihu.com/{COLUMN_ID}","Accept": "application/json"}# 用于获取文章详情的请求头zhihu_headers = {"User-Agent": USER_AGENT,"Cookie": COOKIE,"Accept": "application/json, text/plain, */*","Referer": "https://zhuanlan.zhihu.com/"}# 创建保存文件夹os.makedirs(SAVE_DIR, exist_ok=True)image_dir = os.path.join(SAVE_DIR, "images")os.makedirs(image_dir, exist_ok=True)if COOKIE == "你的知乎Cookie字符串":print("错误:请先获取并填写知乎Cookie(参考Firefox Cookie查看方法)")exit(1)batch_backup_articles(COLUMN_ID, SAVE_DIR, zhihu_headers, headers)
需要说明的是知乎文档中的图片不是用img标签保存的,所以上面的程序并不能成功下载图片,不过我对图片不感兴趣,所以也需要等到以后无聊时再来改进图片下载问题。如果第一次备份部分文章没有成功下载,重新运行程序即可继续备份。