(论文速读)文本引导的可探索图像超分辨率
论文题目:Text-guided Explorable Image Super-resolution(文本引导的可探索图像超分辨率)
会议:CVPR2024
摘要:本文介绍了零镜头文本引导下的开域图像超分辨率探索问题。我们的目标是允许用户探索不同的、语义准确的重建,以保持数据与不同大降采样因子的低分辨率输入的一致性,而无需对这些特定的退化进行明确的训练。我们提出了两种零样本学习文本引导的超分辨率方法:i)修改文本到图像(T2I)扩散模型的生成过程,以提高与低分辨率输入的一致性;ii)将语言引导纳入基于零样本学习扩散的恢复方法中。我们表明,所提出的方法产生了不同的解决方案,这些解决方案与文本提示提供的语义相匹配,同时保持了与降级输入的数据一致性。我们评估了极端超分辨率任务的拟议基线,并展示了在恢复质量,多样性和解决方案可探索性方面的优势。
代码在:https://github.com/KVGandikota/TextguidedSR

预备知识解读:理解核心技术基础
在深入论文创新之前,我们需要先理解几个关键的技术基础。这些"预备知识"就像建房子的地基,掌握它们才能真正理解论文的精妙之处。
1. 扩散模型基础(DDPM)
什么是扩散模型?
想象一滴墨水滴入清水中的过程:墨水逐渐扩散,最终变成均匀的灰色。扩散模型的核心思想就是模拟这个过程,然后学会"倒放"它——从噪声恢复出清晰的图像。
前向过程:逐步加噪
扩散模型包含两个过程,首先是前向扩散过程,将一张清晰图像 x0逐步添加噪声,经过T步后变成纯噪声:
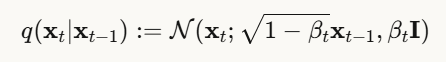
换句话说:
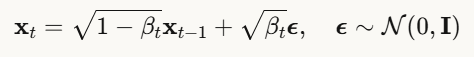
这里:
- xt 是第 t 步的带噪图像
- βt 是噪声调度参数(控制每步加多少噪声)
- ϵ 是标准高斯噪声
反向过程:逐步去噪
关键来了!如果我们能学会反向过程,就可以从噪声生成图像:
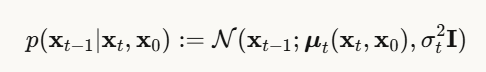
其中均值为:
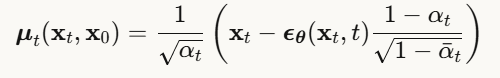
这里:
- ϵθ 是训练的神经网络,用于预测噪声
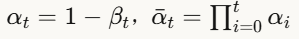
核心思想:不直接预测干净图像,而是预测"加入了多少噪声",然后减去它!
为什么扩散模型强大?
- 训练简单:只需要学习预测噪声,目标函数简单
- 生成质量高:逐步去噪比一步生成更稳定
- 数学优雅:基于坚实的概率论基础
2. 距离空间-零空间分解(Range-Null Space Decomposition)
这是理解论文核心方法的关键数学工具。
问题设定
回忆超分辨率的数学表达:![]()
其中:

伪逆与最小范数解
对于无噪声情况![]() ,伪逆操作
,伪逆操作![]() 给出一个特殊解——最小范数解。
给出一个特殊解——最小范数解。
但这只是无穷多解中的一个!
零空间的魔法
任何向量 x 都可以分解为两部分:
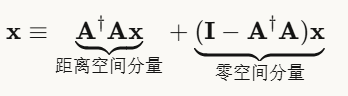
关键性质:零空间分量不影响低分辨率观测!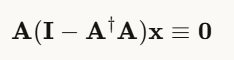
构造数据一致解
假设我们有一个近似解 ![]() (比如扩散模型生成的),可以通过投影构造完美数据一致的解:
(比如扩散模型生成的),可以通过投影构造完美数据一致的解:
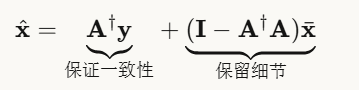
直观理解:
- 第一项:从观测 y 恢复的基础内容(保证与输入匹配)
- 第二项:从
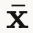 中提取的"不影响观测的细节"(增加高频信息)
中提取的"不影响观测的细节"(增加高频信息)
这就像是:基础轮廓必须与照片一致,但可以自由添加不影响缩略图的细节!
3. 零样本扩散恢复方法
论文探索了三种现有的零样本方法,理解它们是理解论文创新的前提。
清晰图像估计
在扩散的每一步 t,都可以从当前带噪图像 xt 估计原始干净图像:
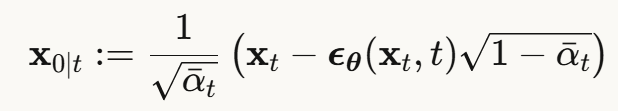
这个估计 ![]() 是后续所有方法的基础!
是后续所有方法的基础!
直观理解:从"部分去噪的图像"反推"完全干净的图像长什么样"。
方法1:DPS(扩散后验采样)
核心思想:用测量数据的重建误差作为引导
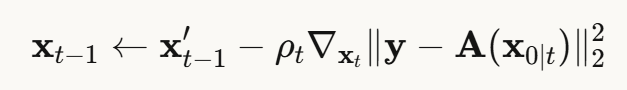
步骤:

优点:灵活,适用于各种逆问题 缺点:需要反向传播,计算开销大
方法2:ΠGDM(伪逆引导扩散)
改进DPS:不直接最小化 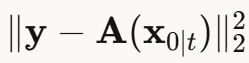 ,而是:
,而是:
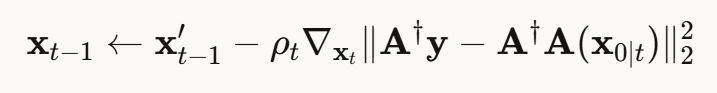
为什么更好?
- 在伪逆空间测量误差,更直接
- 收敛更快,需要的扩散步数更少
- 梯度更稳定
代价:仍需反向传播
方法3:DDNM(零空间模型)
最优雅的方法:直接用零空间投影!
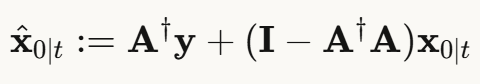
步骤:

优点:
- ✅ 不需要反向传播,速度快
- ✅ 完美数据一致性,数学上有保证
- ✅ 实现简单
缺点:
- 只适用于可以计算伪逆的问题
- 可能生成不够真实的图像(虽然数据一致)
4. 文本引导的图像生成
4.1 Text-to-Image(T2I)扩散模型
论文使用两个主流T2I模型:
DALL-E 2 (unCLIP) 架构:
文本 → CLIP文本编码器 → 文本嵌入↓Prior扩散模型↓CLIP图像嵌入 → 解码器(64×64) → 超分模块(256×256)
关键特点:
- 使用CLIP桥接文本和图像
- 三阶段级联生成
- 先生成图像嵌入,再生成像素
Imagen 架构:
文本 → T5文本编码器 → 文本嵌入↓条件扩散模型(64×64) → 超分模块(256×256)
关键特点:
- 直接用文本嵌入条件化每个阶段
- 不依赖CLIP图像嵌入
- 更简洁的级联结构
两种模型都使用多阶段级联:先生成低分辨率,再超分。这是论文需要特殊处理的原因!
4.2 免训练文本引导
核心思想:用能量函数引导生成过程
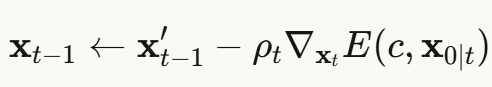
对于文本引导,能量函数 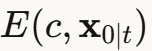 可以使用:
可以使用:
- CLIP相似度:文本和图像在CLIP空间的距离
- 负对数似然:
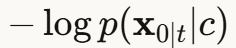
优点:
- 不需要重新训练模型
- 可以灵活组合多种条件
挑战:
- 需要可微分的能量函数
- 与其他约束(如数据一致性)可能冲突
现在,有了这些预备知识的铺垫,我们可以更深入地理解论文的实验结果和技术细节了。
用文字"许愿":让AI用文本引导实现图像超分辨率的魔法
当一张模糊不清的低分辨率照片遇上强大的AI,我们不仅能让它变清晰,还能通过简单的文字描述来控制恢复出什么样的细节!今天要介绍的这篇CVPR 2024论文开创了一个全新的研究方向——零样本文本引导的可探索图像超分辨率。
🎯 问题:超分辨率的"选择困难症"
想象一下,你有一张16×16像素的超低分辨率人脸照片,要将它放大到256×256。这就像给你一个模糊的剪影,让你画出一幅高清肖像画——显然,符合这个剪影的画像可以有无数种可能!
传统的超分辨率方法通常只给你一个答案。但实际上,对于极端的放大倍数(比如×16或×32),这个问题是严重欠定的(ill-posed),存在无数个"正确答案"。更重要的是,我们可能想要探索不同的可能性:
- 这个人是年轻人还是老年人?
- 是男性还是女性?
- 表情是微笑还是严肃?
- 有没有戴眼镜?头发是直的还是卷的?
以往的方法要么只能恢复固定的结果,要么需要通过复杂的图形界面操作。而自然语言显然是更直观、更强大的控制方式!
💡 创新:两条通往"文字魔法"的道路
这篇论文提出了两种实现零样本文本引导超分辨率的方法:
方法一:改造文本生成图像(T2I)模型
研究者们想到:既然DALL-E 2、Imagen这些模型能根据文本生成图像,为什么不让它们在生成过程中同时满足低分辨率图像的约束呢?
他们提出了三个变体:
🔹 T2I-DPS(扩散后验采样) 在生成过程的每一步,计算当前生成结果与输入低分辨率图像的差距,然后用梯度引导生成方向:
![]()
这就像一个艺术家一边根据文字描述作画,一边不断对照低分辨率的原图进行修正。
🔹 T2I-ΠGDM(伪逆引导) 使用伪逆操作来提高效率,减少所需的扩散步数。这是一个更"聪明"的引导策略,收敛更快。
🔹 T2I-DDNM(零空间一致性模型) 这是最优雅的方案!它利用了一个数学性质:任何数据一致的解都可以分解为:
![]()
其中第一项保证数据一致性,第二项是零空间分量(不影响低分辨率约束)。在每个生成步骤,通过投影操作强制满足这个分解,既不需要反向传播,又能完美保证数据一致性!
方法二:用CLIP为传统方法"装上眼睛"
另一条路是利用CLIP(对比语言-图像预训练)模型。CLIP能理解图像和文本的语义关联。研究者将CLIP引导融入到DDNM零样本恢复方法中:
- 先用DDNM生成一个数据一致的中间结果
- 计算这个结果与文本描述的CLIP相似度
- 用梯度引导使结果更符合文本语义
![]()
🔬 实验:效果如何?
定量结果:数字说话
在NoCaps开放域数据集上(×16超分辨率):

| 方法 | 数据一致性<br>(LR PSNR) | 图像质量<br>(NIQE) | 文本匹配<br>(CLIP Score) |
|---|---|---|---|
| DPS基线 | 48.07 | 4.81 | 0.2418 |
| DDNM基线 | 78.42 | 13.24⚠️ | 0.2162 |
| Imagen+DDNM | 53.05 | 4.72✨ | 0.3037🎯 |
| unCLIP+DDNM | 70.01 | 5.21 | 0.3381 |

解读:
- ✅ T2I方法在保持良好数据一致性(>50dB)的同时
- ✅ 大幅提升了图像质量(NIQE从13.24降到4.72)
- ✅ 文本匹配度提高了40%以上!
用户研究:人类评委的选择
研究者让用户评价50个重建结果的真实感和文本匹配度:
Imagen-DDNM 完胜!
- 📊 文本相似度:90.89%(人脸)、92.88%(开放域)
- 📊 照片真实感:69.35%(人脸)、83.07%(开放域)
相比之下,CLIP引导方法只获得了25-60%的认可。
视觉效果:多样性展示
论文中最令人印象深刻的是通过改变文本提示实现的多样性探索:
示例1:年龄变化 同一张低分辨率人脸,通过不同提示词:
- "a smiling girl" → 恢复出年轻女孩
- "a smiling woman" → 恢复出成年女性
- "an elderly woman" → 恢复出老年女性
- "smiling elderly woman" → 恢复出微笑的老年女性
示例2:复杂场景 输入:模糊的16×16城堡照片
提示:"A statue of Walt Disney holding Mickey Mouse hands is showing in front of Cinderella's castle."
输出:清晰的高分辨率场景,准确恢复了雕像和城堡细节!
传统的DPS方法在这种复杂场景下完全失败,只能产生模糊的结果。
⚙️ 技术深度剖析
挑战1:多阶段生成的约束
T2I模型(如Imagen)通常采用级联结构:
- 第一阶段:64×64低分辨率生成
- 第二阶段:超分辨率到256×256
论文的关键洞察:必须在两个阶段都施加约束!
对于低分辨率阶段,定义适配的下采样算子A LR:
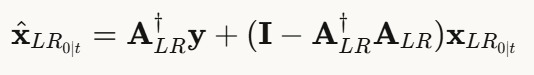
然后在第二阶段使用原始约束 A 。这种两阶段设计确保了端到端的数据一致性。
挑战2:分类器自由引导(CFG)的权衡
实验发现了一个有趣的现象:CFG能提高文本一致性,但会严重损害数据一致性!
| 设置 | 数据一致性 | 文本匹配度 |
|---|---|---|
| 无CFG, 100步 | 49.67 dB | 0.2788 |
| CFG, 100步 | ⚠️ 24.31 dB | 0.2923 |
| CFG, 500步 | 43.09 dB | 0.2695 |
原因:CFG通过增强条件信号来提高文本控制,但这与梯度引导的数据一致性目标产生了冲突。需要大幅增加迭代步数才能部分缓解这个问题。
解决方案:T2I-DDNM通过投影操作而非梯度引导,天然避免了这个权衡,这是它的一大优势!
挑战3:结构一致性问题
在unCLIP-DDNM中,有时先验模型想象的图像嵌入与观测结构不匹配,导致不真实的结果。
创新的解决方案:嵌入平均技巧
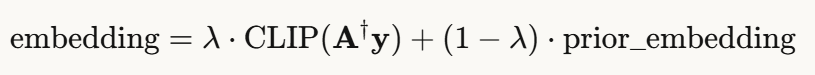
通过混合伪逆解的CLIP嵌入和先验生成的嵌入,可以改善结构一致性。参数 λ 控制权衡程度(论文中使用0.4)。
🤔 局限性与未来方向
研究者也诚实地指出了当前方法的局限:
1. 计算开销
梯度引导方法(DPS、ΠGDM)需要反向传播,计算成本较高。DDNM虽然更快,但在某些情况下可能产生不真实的结果。
2. 随机性
由于扩散模型的随机性,可能需要多次采样才能得到满意结果。这在实际应用中可能是个问题。
3. 文本提示的合理性
如果文本描述与低分辨率输入完全不匹配(比如对一个明显是年轻人的模糊照片使用"老年人"提示),会产生不真实或有明显伪影的结果。
不过,作者指出这并非方法的失败——它反而可以帮助用户判断某个解的合理性!
4. 继承预训练模型的偏见
方法的性能和多样性受限于T2I模型的训练数据,也会继承其中的偏见。
🌟 为什么这项研究很重要?
这篇论文的意义远超超分辨率本身:
1. 开创新范式
首次系统性地将零样本、文本引导、可探索性三个概念结合,为图像恢复开辟了新方向。
2. 实用价值
- 📸 照片修复:从老照片中恢复不同年龄的版本
- 🎨 创意设计:探索同一草图的多种艺术风格
- 🔍 司法取证:生成符合目击者描述的嫌疑人面貌
- 🎬 影视制作:从低分辨率素材生成符合剧情需要的高清版本
3. 技术启发
展示了如何巧妙地结合:
- 强大的预训练生成模型(T2I)
- 经典的优化理论(零空间分解)
- 现代的视觉-语言模型(CLIP)
这种"站在巨人肩膀上"的研究思路值得借鉴。
4. 哲学意义
揭示了一个深刻的问题:什么是"正确"的超分辨率结果?
传统方法追求单一的"最优"解,但这篇论文告诉我们:在高度欠定的问题中,多样性和可探索性可能比单一的"最优"更有价值。用户应该有权利通过直观的语言描述来探索解空间,选择最符合自己需求的结果。
🎓 总结
这篇论文为我们展示了AI图像处理的一个激动人心的未来:不再是被动地接受算法给出的唯一答案,而是通过自然语言主动探索、选择最符合需求的结果。
虽然还存在计算效率、生成稳定性等挑战,但这种"文本引导+零样本+可探索"的范式无疑为图像恢复、图像编辑等领域开辟了全新的可能性。
更重要的是,它提醒我们:在AI时代,人机交互的界面应该更加自然、直观,让复杂的技术为普通用户所用,而不是束之高阁。
从这个意义上说,这不仅是一篇技术论文,更是对"以人为本的AI"理念的生动实践!
你觉得文本引导的图像超分辨率还能应用在哪些场景?欢迎在评论区分享你的想法! 💬