魔搭社区与 Python Notebook:Ubuntu虚拟机+Python+机器学习
目录
- 1. 简介
- 2. 魔搭社区
- 2.1 丰富的模型生态
- 2.2 低代码/无代码的开发体验
- 2..3 活跃的开发者社区
- 3. Notebook实例运行
- 3.1. 注册魔搭社区
- 3.2. 直接进入Notebook实例
- 3.3. 进入Notebook实例,选择模型并运行Python代码
- 4. Python Notebook使用
- 4.1. 交互式编程与实时反馈
- 4.2. 文档与代码的无缝结合
- 5. 魔搭社区 + Python Notebook 的典型应用场景
- 5.1. 教学与科研
- 5.2. 快速原型开发
1. 简介
参考:
魔搭社区与 Python Notebook:开启机器学习的高效实践之路
https://juejin.cn/post/7507192967037403172
阿里云推出的**魔搭社区(ModelScope)**作为中国领先的大模型开源社区,为开发者提供了丰富的预训练模型和一站式工具链。而结合 Python Notebook(Jupyter Notebook) 的交互式编程能力,魔搭社区不仅简化了机器学习的实践流程,还极大提升了算法探索与模型调优的效率。
2. 魔搭社区
2.1 丰富的模型生态
魔搭社区汇聚了来自阿里达摩院及其他合作方的数千个预训练模型,涵盖自然语言处理(NLP)、计算机视觉(CV)、语音识别等多个领域。例如:
- 中文情感分析模型(如 damo/nlp_structbert_sentiment-classification_chinese-base)
- 多语言翻译模型
- 图像生成与分类模型
开发者无需从零训练模型,可直接调用这些高性能模型,快速构建应用。
2.2 低代码/无代码的开发体验
魔搭社区提供了 Pipeline API,通过一行代码即可加载预训练模型并执行任务。
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks# 🔧 1行代码实现情感分析
sentiment_analysis = pipeline(task=Tasks.text_classification, model='damo/nlp_structbert_sentiment-classification_chinese-base')
result = sentiment_analysis('这部电影真的让我感动落泪!')
print(result) # 🎯 输出:{'text': '正面', 'score': 0.98}
2…3 活跃的开发者社区
魔搭社区支持开发者上传、共享和协作优化模型,形成良性生态。截至2023年,社区已积累超过 500万次模型下载量,涵盖金融、医疗、教育等垂直领域。
3. Notebook实例运行
3.1. 注册魔搭社区
① 访问官网:打开 [魔搭社区官网]:https://www.modelscope.cn/。
② 点击注册:在右上角点击“注册”,选择“CSDN账号”或“GitHub 账号”登录。
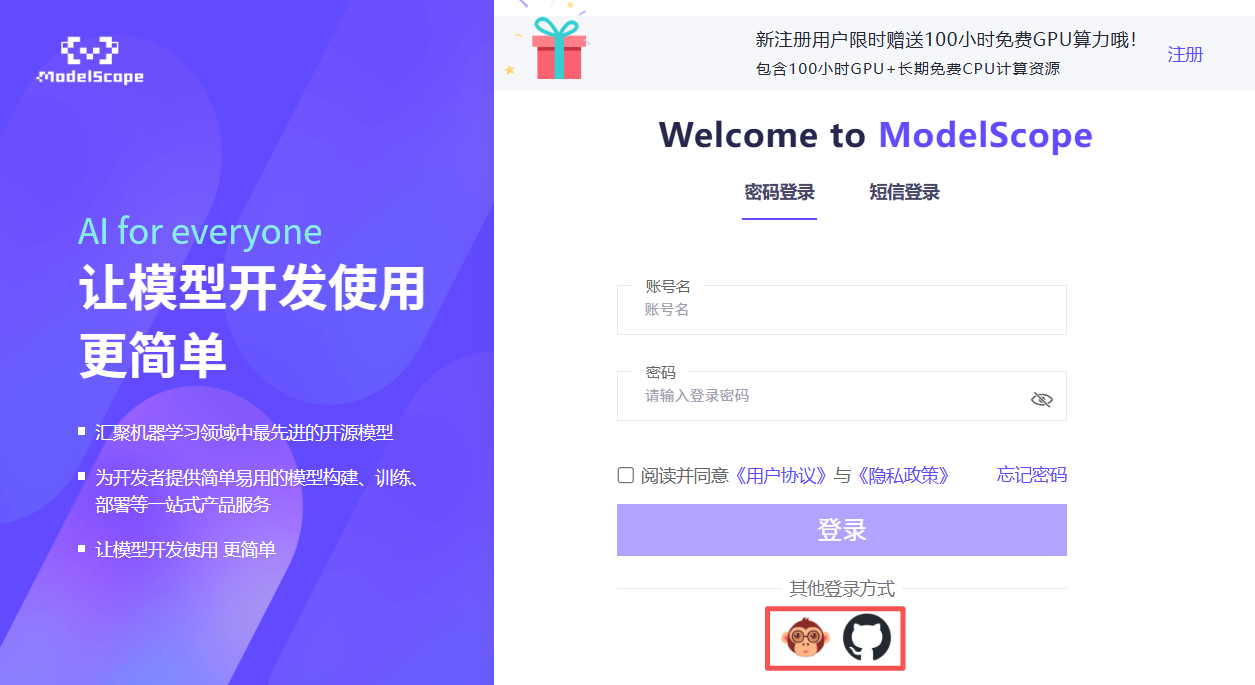
③ 填写信息:
CSDN账号需绑定手机号或邮箱。
GitHub 账号可直接授权登录。
④ 验证身份:完成邮箱或短信验证后,即可成功注册。
⑤ 登录魔搭社区:使用刚才注册的账号进行登录。
📌 提示:
-
注册后需关联阿里云账号,才能使用魔搭提供的免费计算资源(如 Jupyter Notebook 实例)。
-
在个人中心设置中,可查看模型下载记录、积分余额等信息。
-
免费实例通常包含 1-2 小时的运行时间,适合快速测试。
3.2. 直接进入Notebook实例
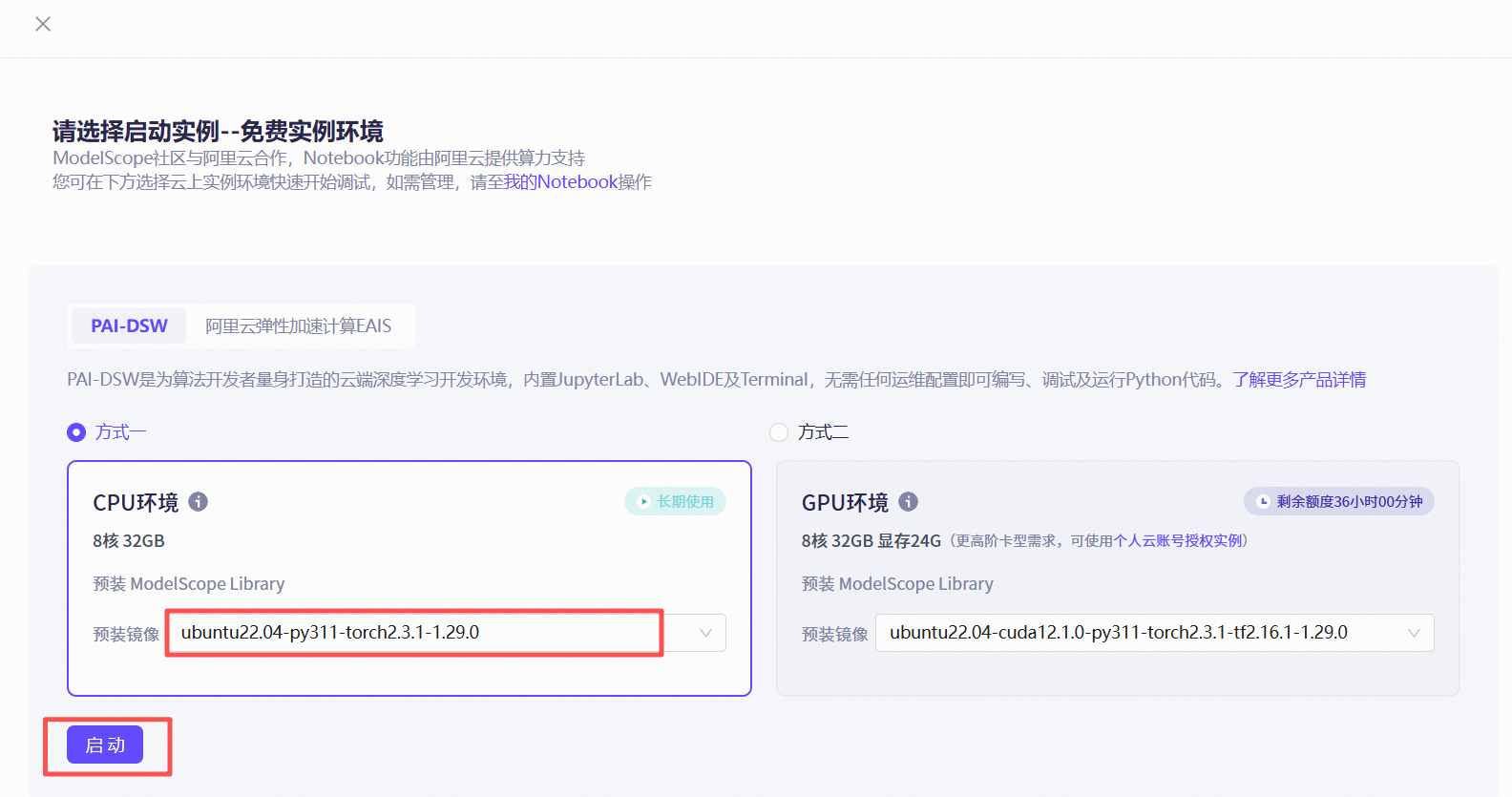
① 启动 Notebook 实例:依次点击 “首页”、 “我的Notebook”,系统会引导您关联阿里云账号并分配免费资源(如 CPU/GPU 实例)。选择预装镜像,点击 “启动” 按钮。
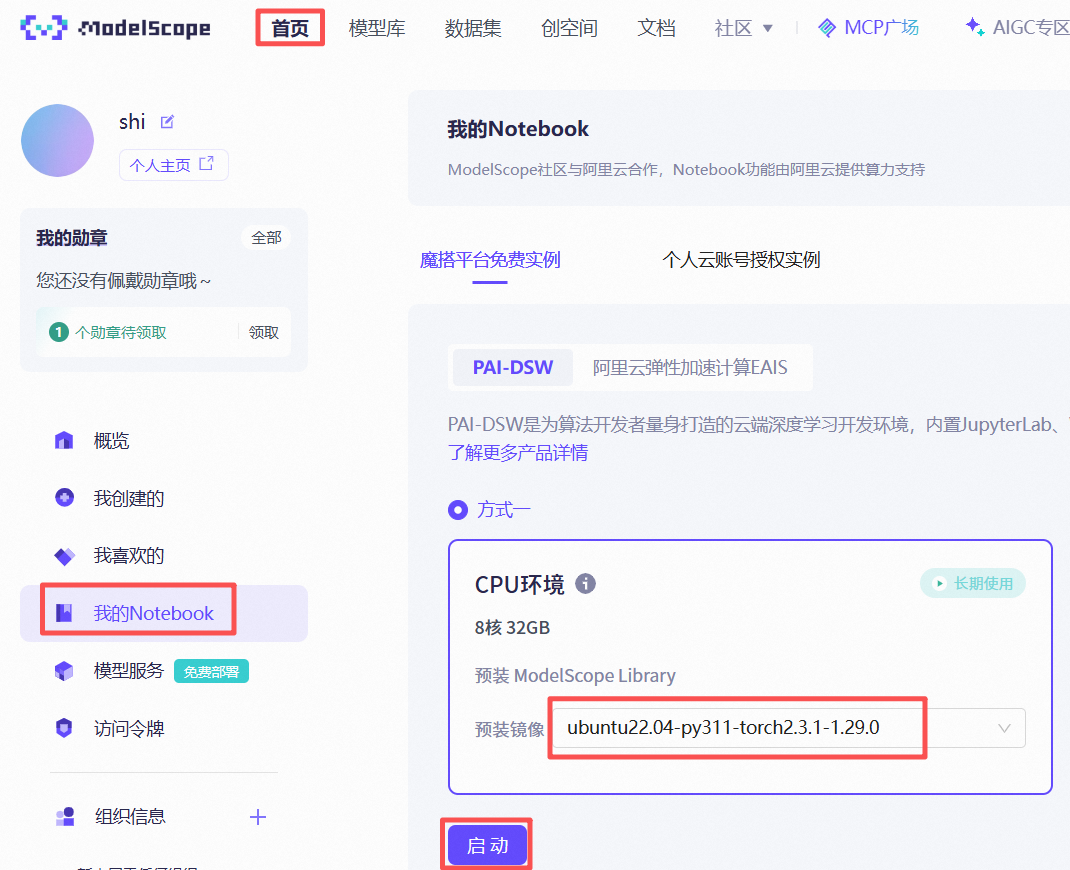
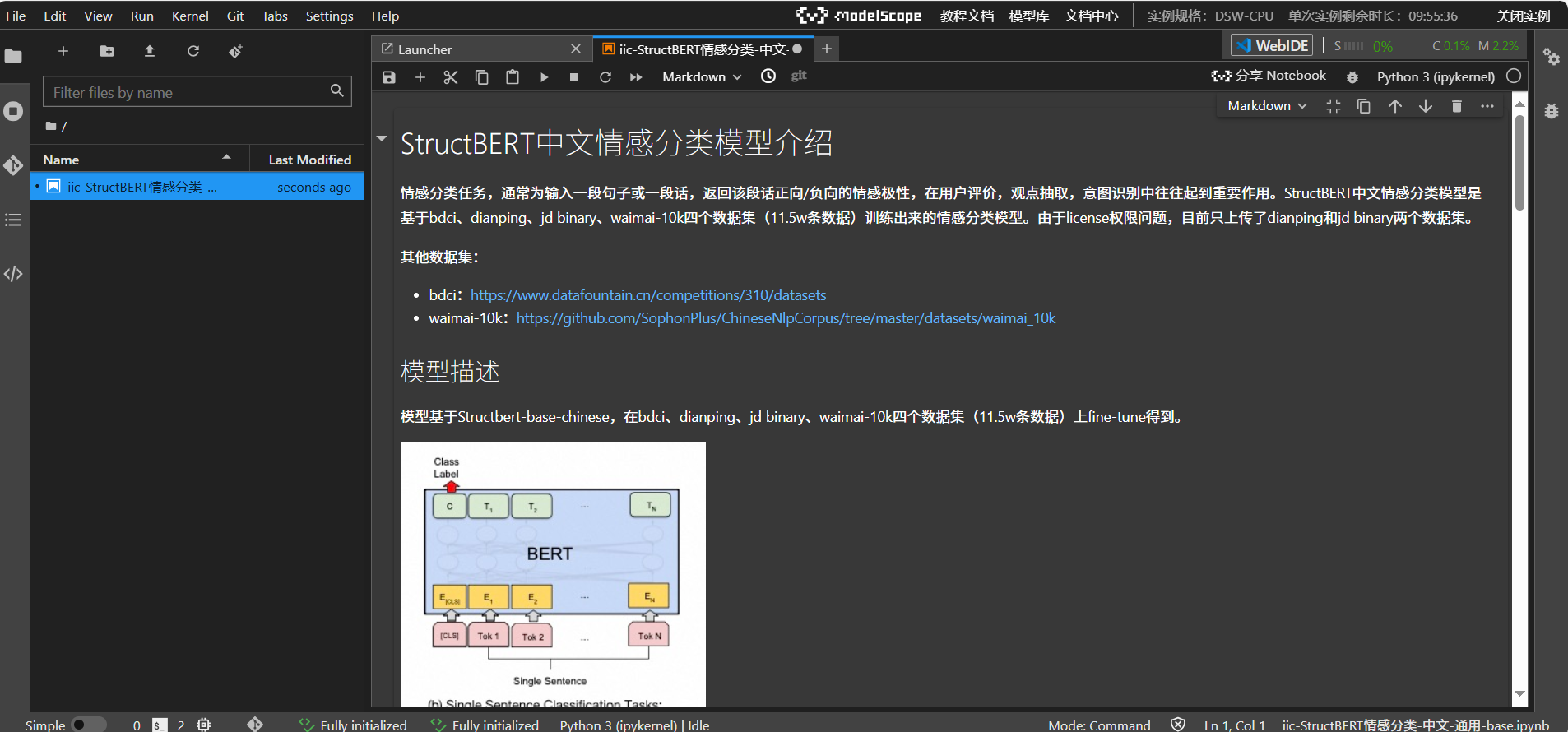
② 进入 Jupyter Notebook 界面。

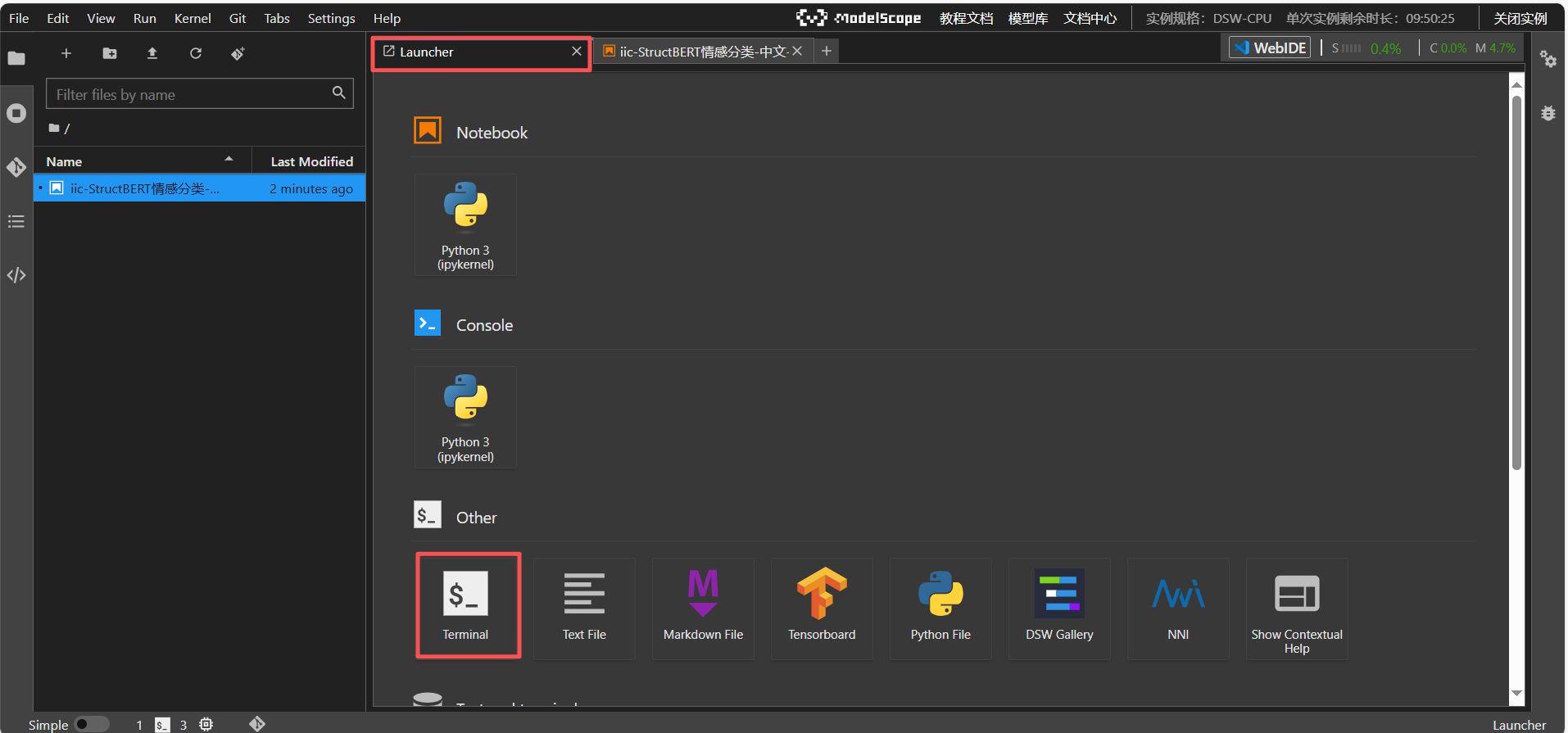
④ 点击“Terminal”,进入实例终端界面。
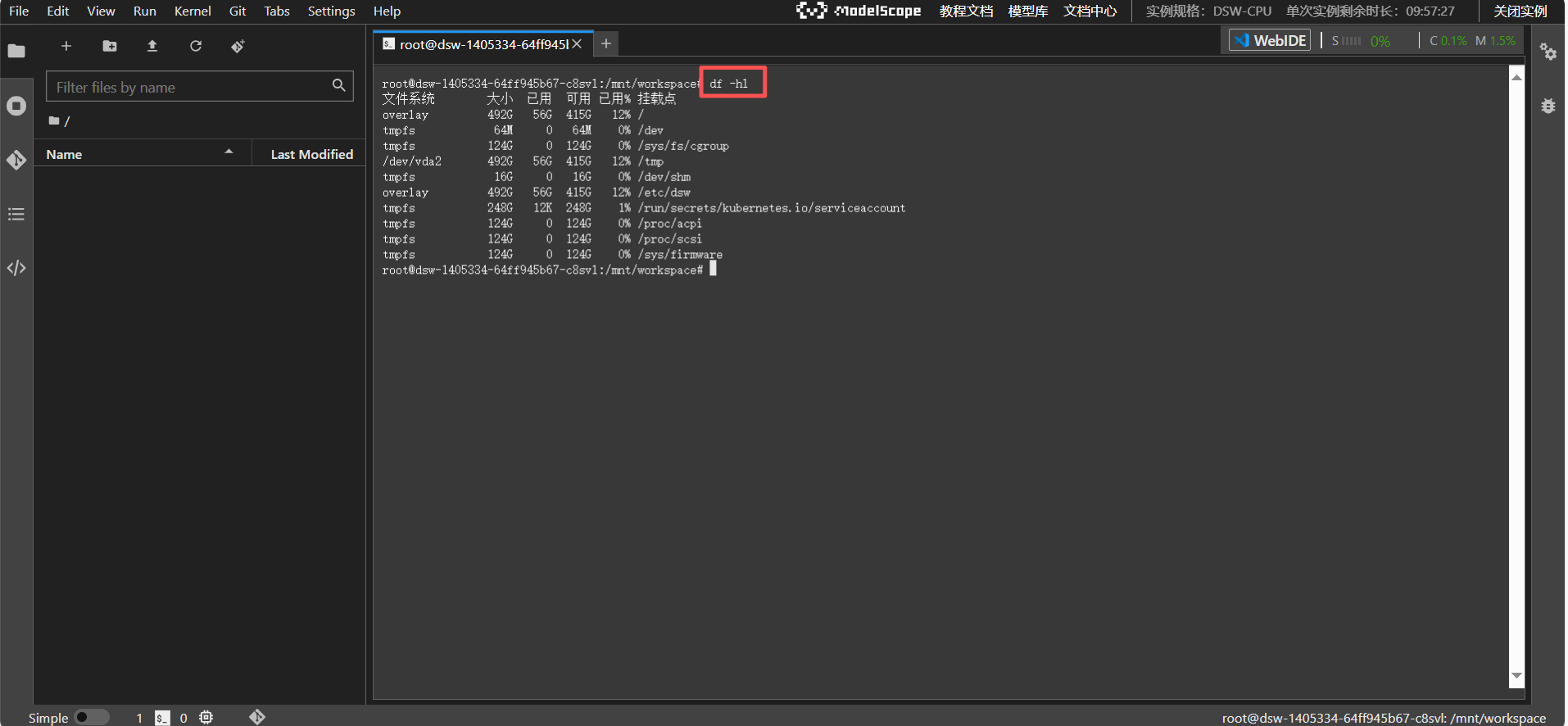
3.3. 进入Notebook实例,选择模型并运行Python代码
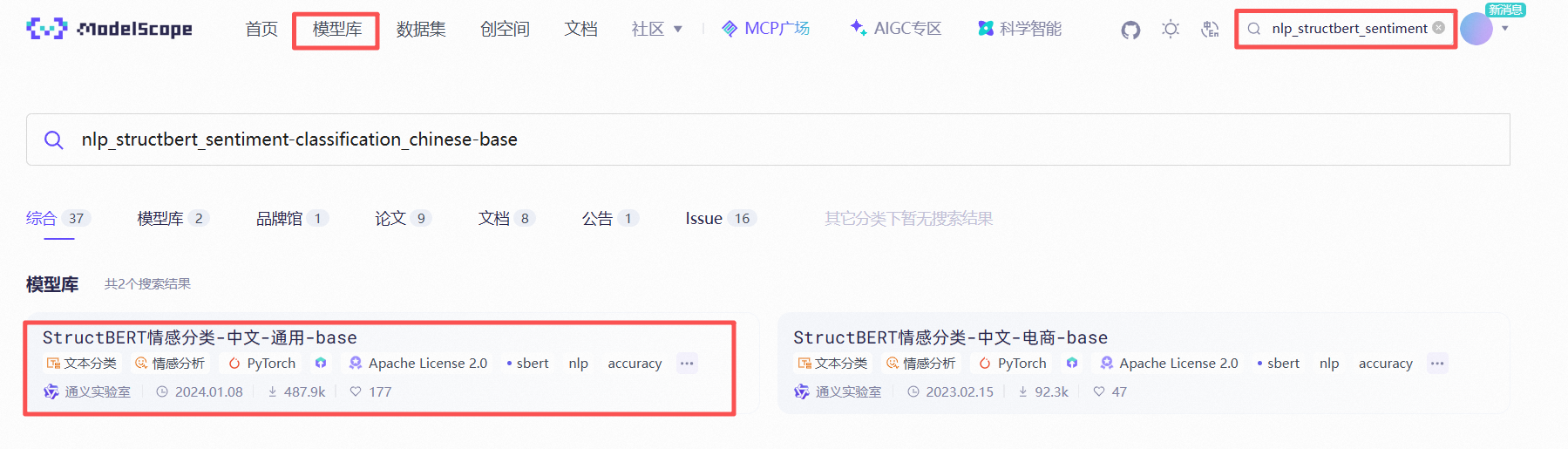
① 选择模型
在“模型库”中搜索目标模型(如 nlp_structbert_sentiment-classification_chinese-base)。
② 点击模型页面的 “Notebook快速开发” 按钮。
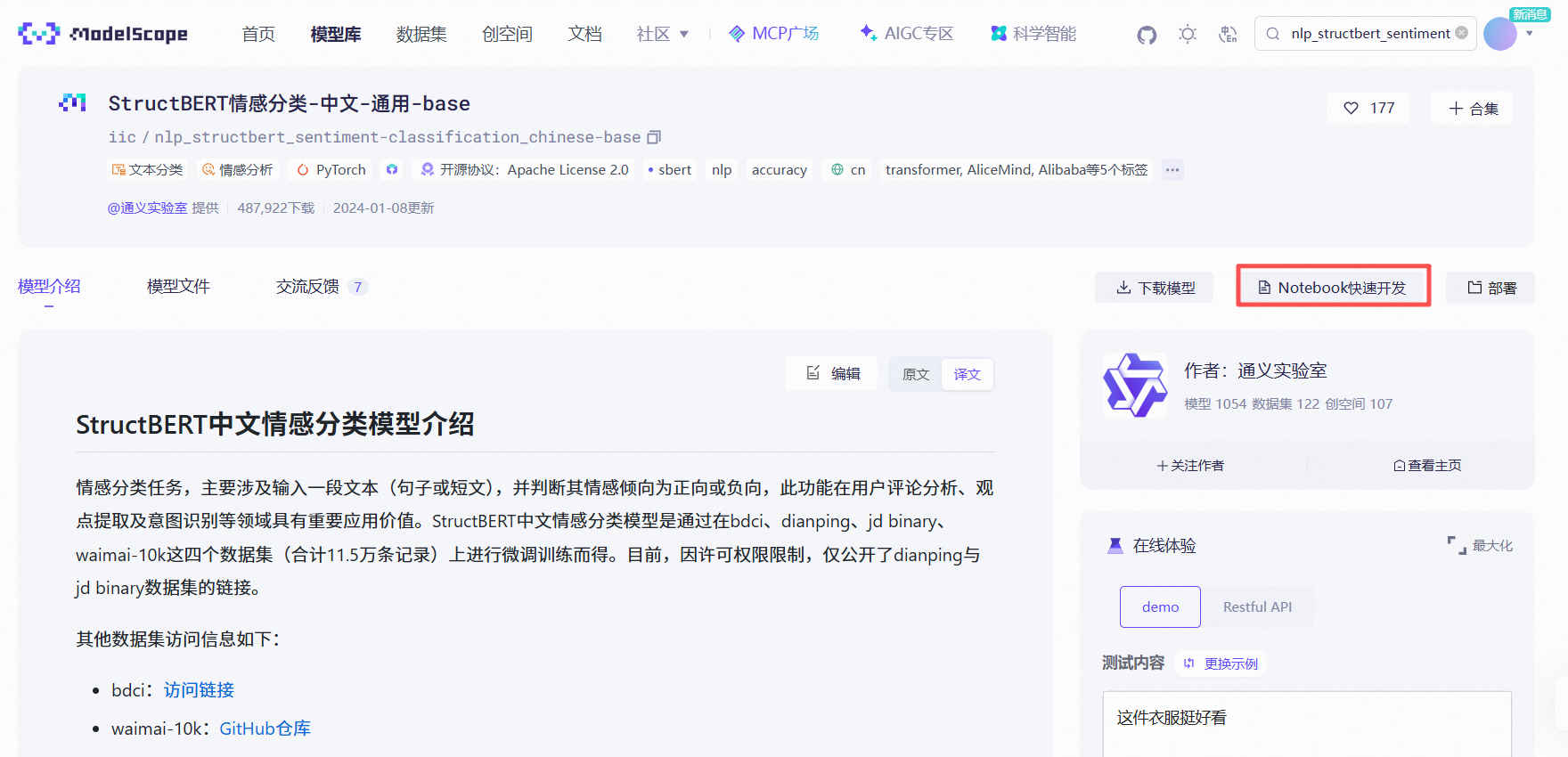
③ 启动 Notebook 实例
系统会引导您关联阿里云账号并分配免费资源(如 CPU/GPU 实例)。
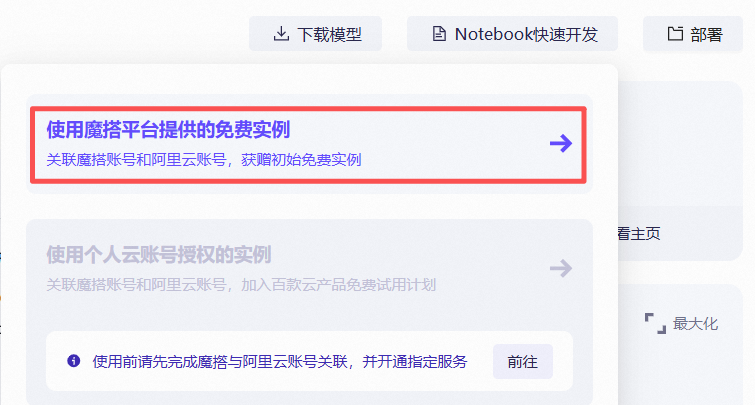
④ 点击“立即体验”或“启动实例”。
⑤ 进入 Jupyter Notebook 界面。
⑥ 点击“Terminal”,进入实例终端界面。
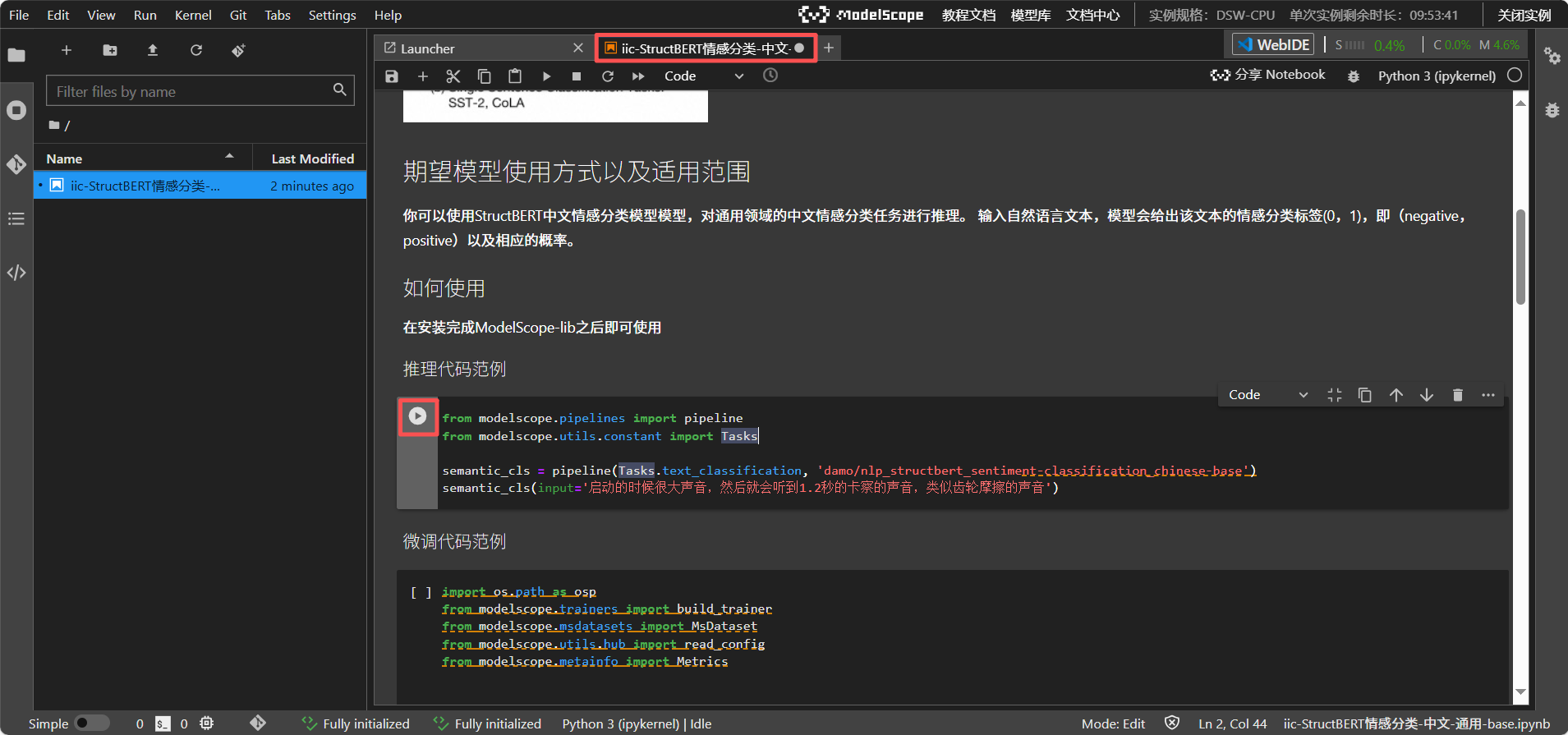
⑦ 运行代码
在 Notebook 中直接运行示例代码,或上传自定义数据进行实验。
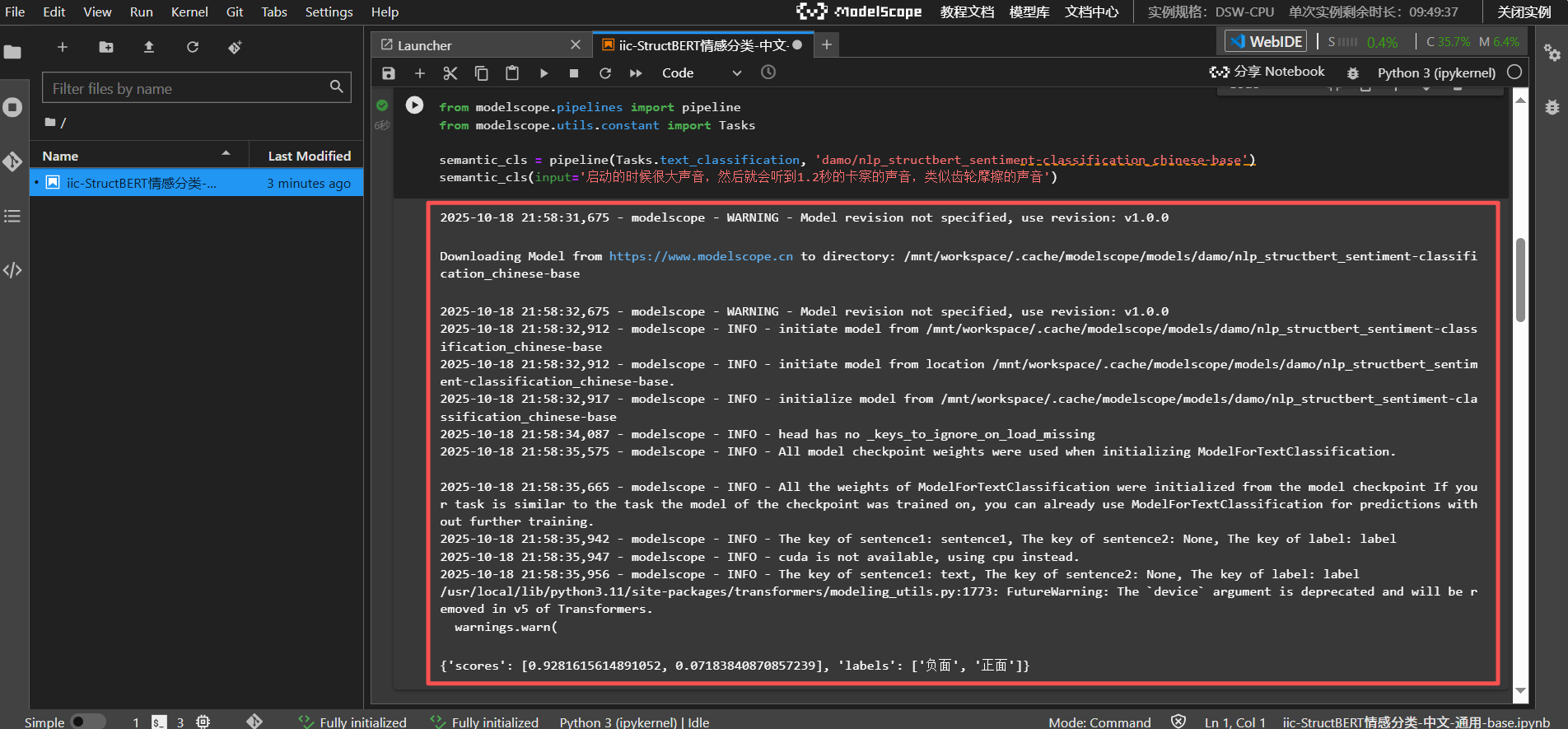
4. Python Notebook使用
4.1. 交互式编程与实时反馈
Jupyter Notebook 支持代码块即时运行与结果可视化,开发者可逐步调试代码、观察中间结果,非常适合机器学习实验。例如,在情感分析任务中:
import matplotlib.pyplot as plt# 📊 可视化情感分布
labels = ['正面', '负面']
scores = [0.98, 0.02]
plt.bar(labels, scores, color=['green', 'red'])
plt.title('情感分析结果')
plt.show()
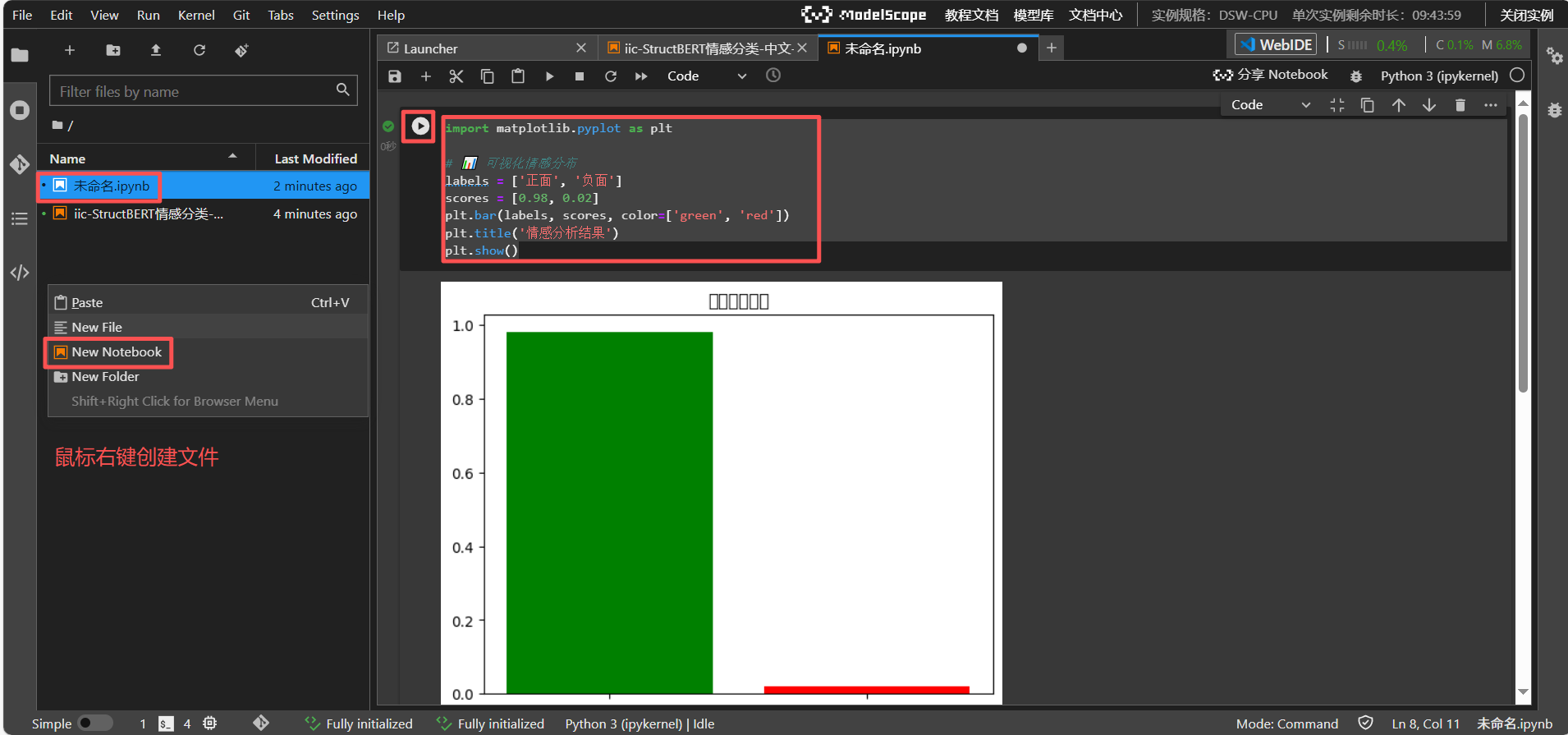
📌 代码注解
导入库:
matplotlib.pyplot 用于绘图,numpy(可选)用于数值计算。
数据准备:
labels 定义分类标签(正面/负面),scores 对应置信度分数。
绘图与展示:
plt.bar(…) 绘制柱状图,plt.title(…) 设置标题,plt.show() 显示图表。
4.2. 文档与代码的无缝结合
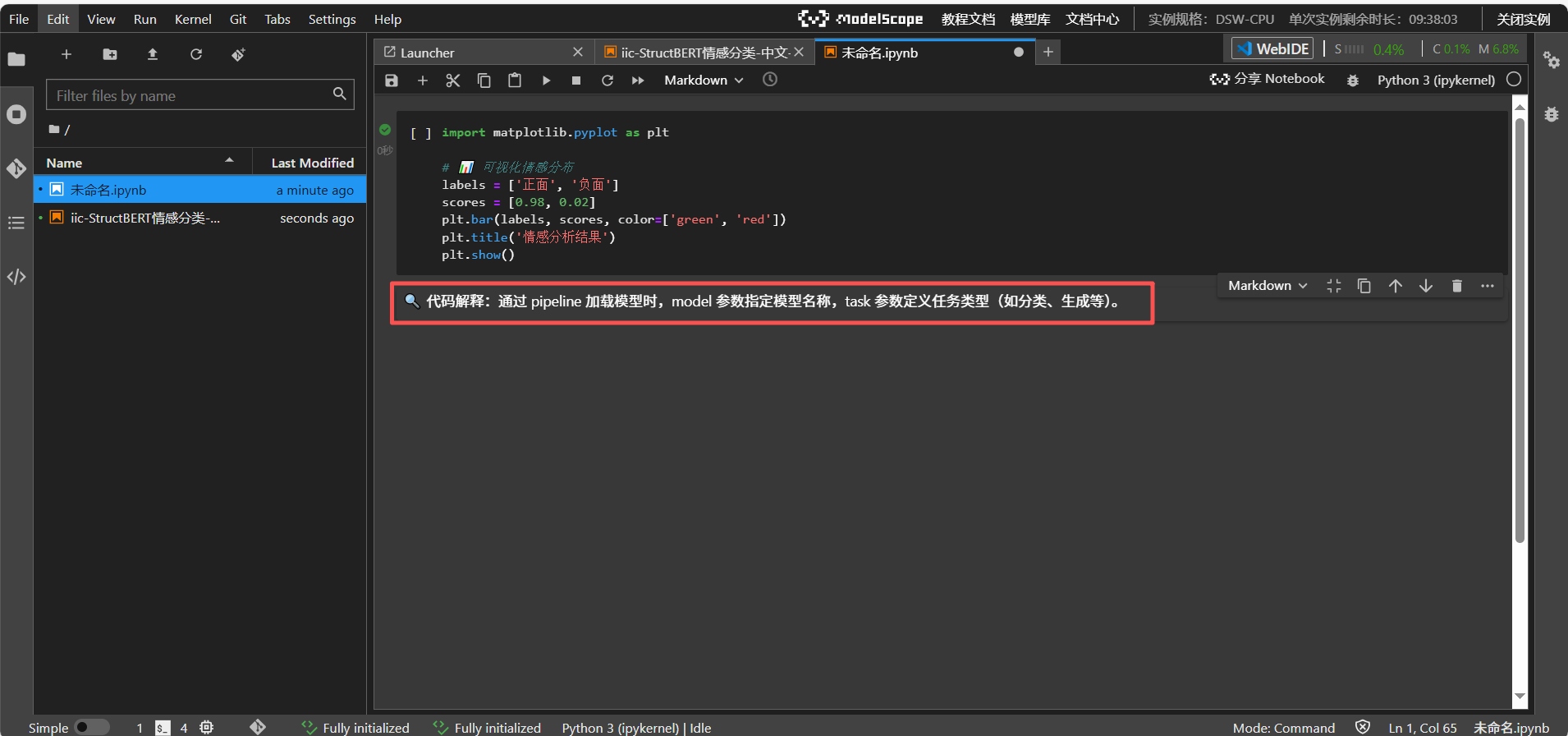
Notebook 支持 Markdown 格式的文字描述、公式推导和图表插入,便于撰写技术文档或教学材料。例如,可直接在代码块旁添加注释
🔍 代码解释:通过 pipeline 加载模型时,model 参数指定模型名称,task 参数定义任务类型(如分类、生成等)。
5. 魔搭社区 + Python Notebook 的典型应用场景
5.1. 教学与科研
场景:机器学习课程实验
学生通过 Notebook 实现以下目标:
对比不同模型(如 BERT vs StructBERT)的分类效果。
调整超参数(如学习率、批大小)观察准确率变化。
可视化注意力机制(Attention Map)理解模型决策逻辑。
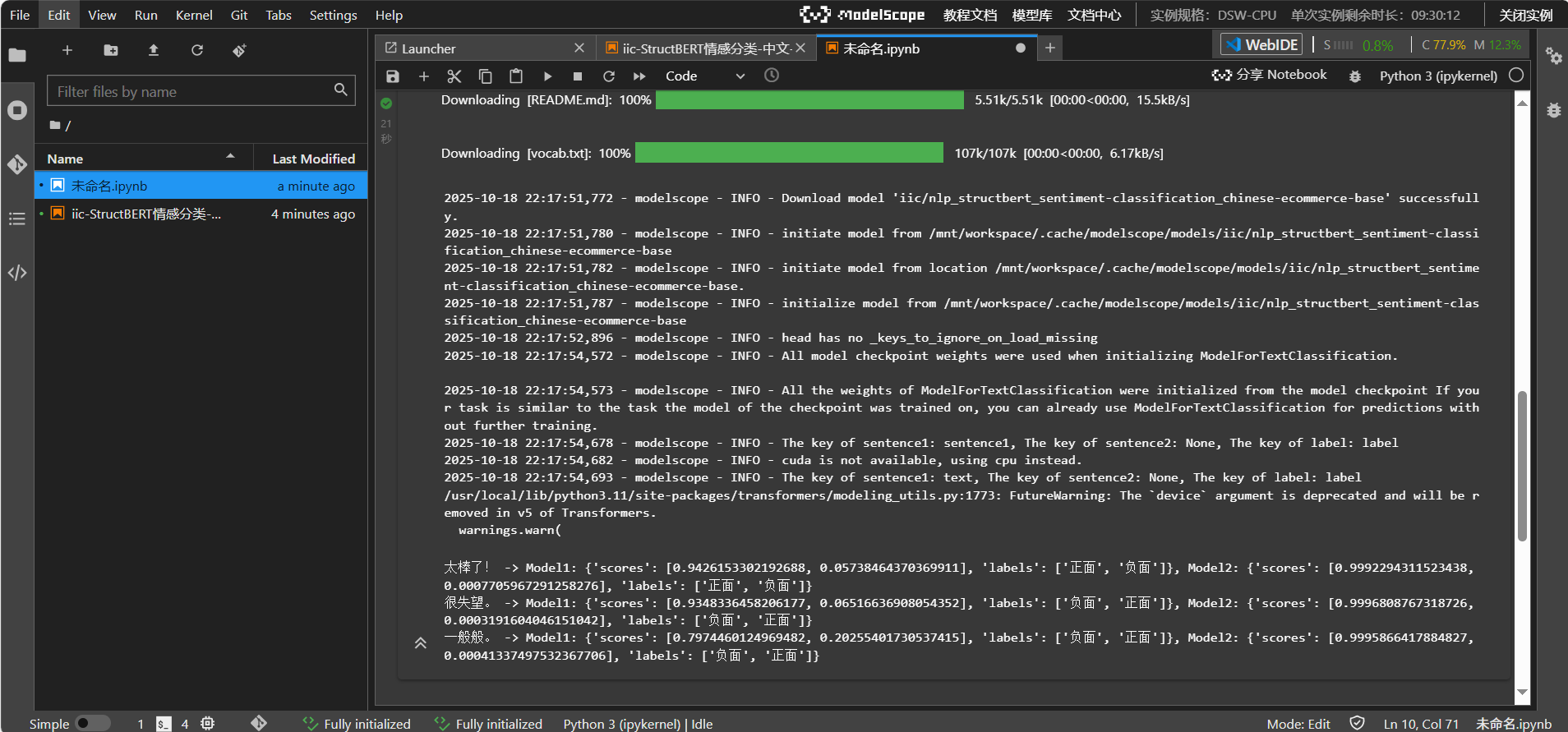
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks# 🧪 对比两个模型
model1 = pipeline(Tasks.text_classification, 'damo/nlp_structbert_sentiment-classification_chinese-base')
model2 = pipeline(Tasks.text_classification, 'iic/nlp_structbert_sentiment-classification_chinese-ecommerce-base')texts = ['太棒了!', '很失望。', '一般般。']
for text in texts:print(f"{text} -> Model1: {model1(text)}, Model2: {model2(text)}")
📌 代码注解
模型对比:
分别加载 StructBERT 和 BERT 模型,比较其输出结果。
循环测试:
对三段文本进行推理,打印两个模型的预测结果。
5.2. 快速原型开发
场景:电商评论情感分析系统
步骤:
使用魔搭的 pipeline 加载情感分类模型。
读取评论数据集(如 CSV 文件)。
批量处理文本并输出情感标签。
可视化情感分布(如饼图、词云)。
import pandas as pd# 📄 读取评论数据
df = pd.read_csv('reviews.csv')
results = [sentiment_analysis(text) for text in df['comment']]# 📈 统计正面/负面比例
positive_count = sum(1 for r in results if r['label'] == '正面')
print(f"正面评论占比:{positive_count / len(results):.2%}")
📌 代码注解
数据加载:
pd.read_csv(…) 读取 CSV 文件中的评论数据。
批量处理:
列表推导式遍历所有评论,调用 sentiment_analysis 获取结果。
统计与输出:
计算正面评论数量,并输出占比(如 正面评论占比:92.34%)。