论文学习_kTrans: Knowledge-Aware Transformer for Binary Code Embedding
标题: kTrans: Knowledge-Aware Transformer for Binary Code Embedding (Wenyu Zhu,2023)
作者: Wenyu Zhu, Hao Wang, Yuchen Zhou, Jiaming Wang, Zihan Sha, Zeyu Gao, Chao Zhang
期刊: arXiv.org
摘要
二进制代码嵌入(BCE)在多种逆向工程任务中具有重要应用,如二进制代码相似性检测、类型恢复、控制流恢复和数据流分析。近期研究表明,Transformer模型能够理解二进制代码的语义,以支持下游任务。然而,现有模型忽略了汇编语言的先验知识。本文提出了一种基于Transformer的新方法,名为kTrans,用于生成知识感知的二进制代码嵌入。通过将显式知识作为额外输入提供给Transformer,并通过一种新颖的预训练任务融合隐式知识,kTrans为将领域知识融入Transformer框架提供了新的视角。我们通过异常值检测和可视化检查生成的嵌入,并将kTrans应用于三个下游任务:二进制代码相似性检测(BCSD)、函数类型恢复(FTR)和间接调用识别(ICR)。评估结果显示,kTrans能够生成高质量的二进制代码嵌入,并在下游任务中分别超过了最先进方法(SOTA)5.2%、6.8%和12.6%。kTrans已公开发布,网址:https://github.com/Learner0x5a/kTrans-release。
知识感知的代码嵌入,将显式知识作为额外输入提供给Transformer。
引言
二进制代码嵌入(BCE),也称为二进制代码表示学习,旨在将非结构化的二进制代码映射到一个低维空间,在该空间中,二进制代码被表示为嵌入向量。通过二进制代码嵌入,许多传统的二进制代码分析任务可以通过深度学习方法得到改进,如二进制代码相似性检测、函数边界识别、函数签名恢复、值集分析和间接调用识别等。随着大语言模型的发展,Transformer已经被证明是一个高效的语言表示模型,并在各种二进制代码分析任务中取得了优异的表现。
现有的二进制代码嵌入方法大致可以分为两类:手动嵌入和基于学习的嵌入。手动嵌入通过手工构造数值特征来表示二进制代码,例如Gemini、Instruction2Vec等。然而,这些方法需要广泛的领域知识,并且通常是任务特定的,因此转移性较差。另一方面,基于学习的嵌入通过表示学习方法自动生成二进制代码的嵌入,例如Asm2Vec、SAFE等。这些方法从数据中自动学习特征,避免了手动特征工程引入的偏差。此外,随着Transformer的广泛应用,许多基于Transformer的方法被提出,并在各种下游任务中取得了最先进的表现,如PalmTree、jTrans、COMBO等。尽管现有方法在二进制代码分析任务中取得了一定的成功,但它们仍然存在一些局限性。
首先,现有方法缺乏对二进制代码中固有的先验知识的利用。大多数方法将二进制代码视为自然语言,并直接将自然语言模型应用于汇编语言。然而,汇编语言包含关于指令集架构(ISA)的知识,包括指令操作码的类型、操作数类型、操作码之间的关系以及其他信息。例如,对于 rax、eax、ax、al,自然语言模型会将它们视为独立的标记,但实际上,后面三个都是rax的一部分。因此,如果模型能够理解eax和al之间的关系,它就能在建模如 movzx eax, byte [r8]; cmp byte [rdx], al这样的指令序列时,捕捉到指令之间的数据流关系。

其次,现有方法缺乏对指令的理解,因此无法建模程序的执行行为。指令是程序执行的基本单元,但大多数方法直接将自然语言模型应用于汇编语言,而没有明确理解指令的边界。例如,PalmTree要求用户提供指令边界,而BinBert则完全缺乏指令边界的信息。如果没有正确理解指令,模型可能无法区分[pop, rbp]和[rbp, pop]。
[pop, rbp]:这是一个有效的指令,表示将栈顶的值弹出并存储到rbp寄存器中。
[rbp, pop]:这不是有效的指令,因为rbp是操作数,而pop是指令操作符。
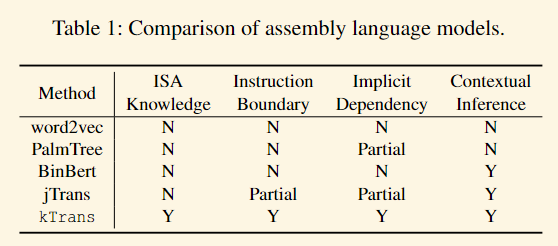
此外,现有方法缺乏对二进制代码中隐式依赖关系的建模。汇编指令并不是独立的实体,它们之间存在隐式依赖关系,例如全局标志寄存器EFLAGS。当前的方法通过手动设计部分地解决了隐式依赖关系。例如,jTrans通过在标记嵌入和位置嵌入之间共享参数来建模指令跳转关系,但它没有考虑其他依赖关系。PalmTree通过在数据流图上构建下一序列预测(NSP)任务来建模数据依赖关系,但它牺牲了对完整汇编语言上下文的建模能力。至于Transformer的掩码策略,本身一个简单的标记级掩码只能建模单个标记之间的依赖关系,无法捕捉指令之间的依赖关系。考虑如下汇编片段:test eax, eax; mov rcx, qword [rbp-num]; jne addr。在像test eax, [MASK]或jne [MASK]这样的情况下,模型可以在没有上下文信息的情况下准确预测被掩码的标记。然而,模型无法学习到指令test eax, eax和jne addr之间的关系,这实际上意味着一个条件分支依赖关系。总之,如表1所示,仍然缺乏一个全面的二进制代码嵌入解决方案。

本文提出了kTrans,一种新型的基于Transformer的二进制代码嵌入方法。kTrans将汇编语言的先验知识融入到Transformer模型中,同时能够通过一种新颖的预训练任务建模指令之间的隐式依赖关系。
- 显式注入标记知识:这种知识是基于指令集架构(ISA)的定义生成的,例如指令类型和寄存器之间的关系(如
rax、eax、ax、al),并作为额外输入传递给Transformer。通过注入这种知识,模型能够学习标记属性和指令边界。 - 隐式注入指令知识:这种知识通过指令级别的掩码隐式注入。通过掩盖整个指令,模型能够理解指令的边界,并能够建模指令之间的隐式关系,例如条件分支依赖关系。
研究背景
二进制代码嵌入(BCE):是一种将非结构化的二进制代码映射到低维空间的技术,在该空间中,二进制代码以嵌入向量的形式表示。BCE具有广泛的应用,如二进制代码相似性检测、类型恢复、控制流恢复和数据流分析等。与此同时,随着大规模语言模型的发展,基于Transformer的模型已成为BCE中常用的方法,因为它们能够自动学习复杂的特征。本节将概述不同的二进制代码嵌入方法,包括手动二进制代码嵌入、非Transformer的学习型二进制代码嵌入以及基于Transformer的学习型二进制代码嵌入。
手动二进制代码嵌入:是指使用手工构建的数值特征来表示二进制代码。通常,这些特征旨在捕捉二进制代码中存在的语法和语义信息。一些常用的特征包括:
- 指令N-gram:指令n-gram表示二进制代码中N个连续指令的序列。这些特征能够捕捉指令之间的局部模式和依赖关系,但可能无法建模长距离的依赖关系。
- 控制流图(CFGs):控制流图表示二进制代码的控制流结构,使用有向图表示,基本块为节点,控制流连接为节点之间的边。CFG能够捕捉二进制代码的控制流结构,但可能无法建模数据依赖关系和其他语义信息。
- 函数调用图(FCGs):函数调用图表示二进制代码中函数之间的调用关系,使用有向图表示,函数为节点,函数调用为边。FCG能够捕捉函数之间的高级关系,但可能无法建模单个函数内部的详细结构和语义。
基于学习的代码嵌入:尽管手动二进制代码嵌入方法简单且易于提取,但它们存在几个局限性。这些方法需要广泛的领域知识,并且通常是任务特定的,导致在不同二进制代码分析任务之间的转移性较差。此外,这些方法在面对二进制代码分析领域的新挑战和进展时,适应性和可扩展性有限。
这类方法通过表示学习自动生成二进制代码的嵌入,能够从数据中自动学习特征,避免了手动特征工程引入的偏差。非Transformer类方法可以根据它们所采用的基础学习算法分为几类:
- 基于RNN的方法:如SAFE使用递归神经网络(RNN)建模二进制代码序列。RNN方法,如LSTM和GRU,能够捕捉数据中的序列依赖关系,并且非常适合建模可变长度的二进制代码序列。然而,RNN在处理长序列时可能会遭遇梯度消失问题,这限制了它们建模长距离依赖关系的能力。
- 基于CNN的方法:如αdiff使用卷积神经网络(CNN)来建模二进制代码中的局部模式和关系。CNN能够通过卷积层和池化操作捕捉空间和层次信息。然而,CNN在建模二进制代码中的序列依赖关系和长距离关系时,可能没有RNN或Transformer那么有效。
- 基于GNN的方法:如Gemini和VulSeeker使用图神经网络(GNN)来建模二进制代码,采用控制流图(CFG)和数据流图(DFG)等图表示。GNN通过处理图结构数据,能够捕捉二进制代码不同部分之间的复杂关系和依赖关系。然而,GNN可能需要额外的预处理步骤来从二进制代码中提取图表示,并且对于大型图来说计算开销较大。
基于Transformer的二进制代码嵌入方法利用了Transformer中的强大自注意力机制,使其能够捕捉二进制代码中的长距离依赖关系和复杂模式。基于Transformer的方法包括PalmTree、jTrans和COMBO等。这些方法通常采用预训练-微调范式,使得它们能够从大规模的无标签数据中学习通用的二进制代码表示,并随后将这些表示微调到特定的二进制代码分析任务上。
与非Transformer方法相比,基于Transformer的方法具有一些关键优势:
- 改进的长距离依赖建模:Transformer使用自注意力机制来建模输入序列中所有标记对之间的关系,使得它们能够比RNN或CNN更有效地捕捉长距离依赖关系。
- 可扩展性:Transformer能够并行处理输入序列,相较于需要按顺序处理的RNN,具有更高的计算效率和可扩展性。
- 迁移学习:基于Transformer的方法通常采用迁移学习范式,如预训练-微调,这使得它们能够利用大规模的无标签数据学习通用的二进制代码表示,并提高在特定二进制代码分析任务上的表现。
然而,基于Transformer的二进制代码嵌入方法也面临一些挑战:
- 计算复杂性:尽管Transformer可以并行处理输入序列,但它们的自注意力机制在序列长度上的计算复杂度是平方级的,这使得它们在处理长序列时计算开销较大。使用稀疏注意力或局部注意力等技术可以在一定程度上缓解这一问题。
- 先验知识的融入:大多数基于Transformer的方法将二进制代码视为自然语言,并直接将语言模型应用于汇编语言。这可能忽略了二进制代码中固有的先验知识,如操作码类型、操作数类型等。
- 理解指令:许多基于Transformer的方法缺乏对指令边界的清晰理解,这可能会妨碍它们建模程序执行行为的能力。一些方法,如PalmTree,要求用户提供指令边界,而其他方法,如BinBert,完全缺乏指令边界的信息。
二进制代码嵌入在提高各种二进制代码分析任务的性能中起着至关重要的作用。虽然手动二进制代码嵌入方法有其局限性,但基于学习的二进制代码嵌入方法,无论是非Transformer还是基于Transformer的,都表现出在更好地捕捉二进制代码结构和语义方面的巨大潜力。继续在这个领域的研究和发展,可以带来更有效和全面的二进制代码嵌入方法,从而解决现有方法的挑战和局限性。在这项工作中,为了应对这些挑战并开发全面的嵌入方法,我们专注于融入二进制代码的先验知识、改善对指令的理解以及建模隐式依赖关系。
研究内容
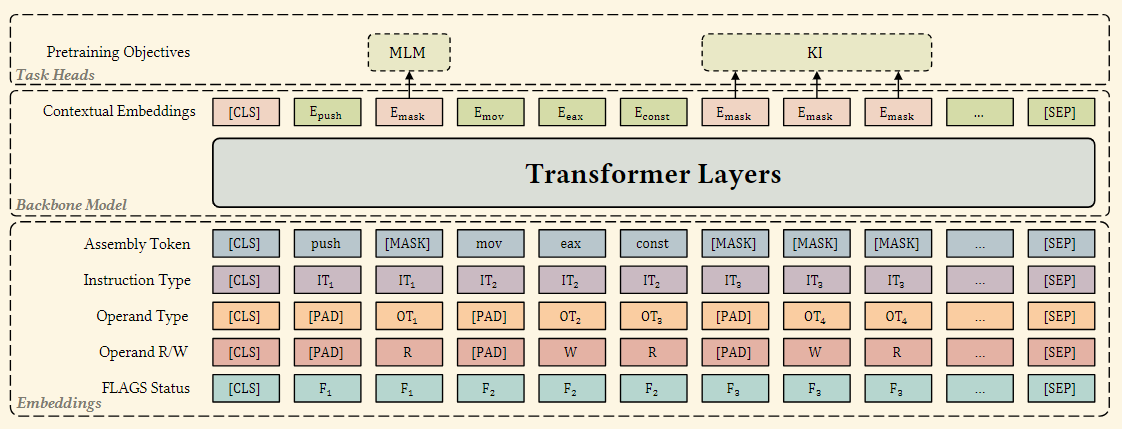
kTrans自动融入二进制代码中的知识。kTrans基于Transformer编码器架构,并采用模块化设计以实现高可扩展性。如图1所示,kTrans由三个主要模块组成:嵌入模块、主干模型和任务头模块。嵌入模块负责显式注入标记事实,主干模型负责生成上下文嵌入,而任务头模块负责注入隐式知识。(1)嵌入模块为Transformer生成三类输入嵌入,最终的输入嵌入是通过它们的求和得到的。
• 汇编标记嵌入:对于汇编指令的文本序列,我们采用常见的标记化方法来获得标记序列,并将其转换为向量,即标记嵌入。
• 显式知识嵌入:对于汇编指令中包含的显式知识,如操作码类型和操作数类型,我们基于ISA的定义构建词汇表。我们将这些知识编码为与汇编标记对齐的序列,以计算知识嵌入。
• 位置编码:对于位置编码,我们采用了BERT中广泛使用的位置编码方法。至于段落嵌入,由于我们的Transformer模型只处理单个函数作为输入,并不涉及多个句子,因此不需要段落嵌入。
(2)主干模型利用Transformer模型来整合各种嵌入并生成上下文嵌入。Transformer模型通过自注意力机制捕捉序列中的上下文信息,生成上下文嵌入,然后将其用于各种下游任务。
(3)任务头模块负责构建预训练任务。在预训练过程中,kTrans包含一个掩码语言建模(MLM)任务和一个知识注入(KI)任务。
🌐 示例背景
假设我们有一段简短的汇编代码片段(属于某个函数):
mov eax, [rbp-4]
add eax, 5
cmp eax, 10
jne label_A
这段代码的逻辑是:从内存加载一个整数到寄存器eax中,加上5后与10比较,如果不相等则跳转到label_A。
我们希望kTrans能学习这段二进制代码的语义结构,从而理解“这段代码执行的是一个条件判断逻辑”,而不仅仅是字面上的指令序列。
🧩 一、嵌入模块(Embedding Module)
嵌入模块的任务是将这段汇编指令转换为Transformer可以理解的数值向量。
kTrans会构造三类嵌入,并将它们相加得到最终输入:
1. 汇编标记嵌入(Assembly Token Embedding)
例如,将上述代码拆分为标记:
["mov", "eax", "[rbp-4]", "add", "eax", "5", "cmp", "eax", "10", "jne", "label_A"]
每个标记(token)会被映射为一个向量表示,如 E_mov, E_eax, E_add 等。
这些嵌入捕捉了词级的语义(例如,“mov”代表数据传输操作)。
2. 显式知识嵌入(Explicit Knowledge Embedding)
这里加入了来自ISA(指令集架构)的显式知识,例如:
mov→ 操作码类型:数据传输add→ 操作码类型:算术运算cmp→ 操作码类型:比较jne→ 操作码类型:条件跳转
此外,还包括操作数类型(寄存器/内存/立即数)等信息。
因此,在“mov eax, [rbp-4]”中:
mov的显式嵌入标识它是“数据传输指令”[rbp-4]的显式嵌入标识它是“内存操作数”
这些显式知识作为额外的输入向量加入,使模型能够理解每条指令的结构和作用。
3. 位置编码(Positional Encoding)
Transformer本身不具备顺序感,因此为每个token添加位置信息:
第1条指令的位置向量:P₁
第2条指令的位置向量:P₂
……
这样模型就能区分“先加载、再计算、再比较”的逻辑顺序。
最终,每个输入向量是三者之和:
Embedding = TokenEmbedding + KnowledgeEmbedding + PositionEncoding
🧠 二、主干模型(Backbone Model)
这些嵌入向量被输入到Transformer层中。
Transformer利用**自注意力机制(Self-Attention)**来捕捉指令间的上下文关系,例如:
“add eax, 5”依赖于前面的“mov eax, [rbp-4]”
“cmp eax, 10”依赖于“add eax, 5”
“jne label_A”依赖于“cmp eax, 10”的结果(隐式依赖EFLAGS)
这意味着模型不仅能理解每条指令的独立含义,还能学习到它们之间的依赖关系和程序逻辑。
🧩 三、任务头模块(Task Head Module)
主干模型生成上下文嵌入后,任务头模块会利用这些嵌入执行预训练任务,以帮助模型更好地学习语义:
1. 掩码语言建模(MLM)
随机遮盖部分token,例如:
mov eax, [MASK]
模型需要根据上下文预测被遮盖的内容(此处应为“rbp-4”)。
这帮助模型理解局部语义关系(如寄存器和内存操作之间的匹配)。
2. 知识注入任务(KI)
此任务在指令级别进行掩码,比如:
[MASK]; cmp eax, 10; jne label_A
模型必须根据上下文预测被遮盖的整条指令。
通过这种方式,模型能够学习指令之间的隐式依赖关系,例如:
cmp eax, 10设置了EFLAGS;jne label_A根据EFLAGS的值决定是否跳转。
模型由此掌握条件跳转逻辑的语义。
🧩 四、总结
通过以上过程,kTrans可以在多个层面学习到程序语义:
词级(Token-Level):理解操作码和寄存器的含义;
语句级(Instruction-Level):理解指令的结构和操作模式;
上下文级(Sequence-Level):理解指令之间的逻辑关系(如依赖EFLAGS的条件跳转)。
最终,kTrans学到的嵌入不仅能反映代码的语法结构,还能表示程序行为,为后续任务(如函数相似性检测、漏洞分析等)提供高质量的语义向量表示。