Linux学习日记3:Write函数与Read函数
一、前言
前面我们学习了open函数和close函数的基本用法以及关于文件权限的相关知识,今天我们来学习write函数与read函数。
二、write函数和read函数
1、write()与 read()是什么?
在 Linux 中,几乎所有 I/O 操作都可以归结为两件事:从文件中读数据;向文件中写数据。无论这个“文件”是:一个真正的磁盘文件,一段管道(pipe),一个串口设备,还是一个网络 socket,Linux 都将它抽象为文件描述符。
因此read()与 write()是最底层、最通用的 I/O 接口。所有高级函数(如 fread()、fprintf()、std::cout 等)最终都会调用它们。
2、write函数
2.1、函数原型
write函数定义在头文件<unistd.h> 中:
#include <unistd.h>ssize_t write(int fd, const void *buf, size_t count);
2.2、参数说明
fd:文件描述符,通过open()、socket()等函数获得,用于标识要读取数据的文件、设备等;
buf:数据缓冲区指针,对于write():存放要写入的数据的首地址;
count:要写入的字节数,即希望将缓冲区中多少字节的数据写入到文件描述符对应的文件或设备中。
2.3、返回值
count大于0:表示实际成功写入的字节数。
count等于0:通常表示没有写入任何数据,可能是由于某些特殊情况(如文件系统已满但还未返回错误)。
count等于-1:表示写入操作失败,errno会被设置为相应的错误码,用于指示具体的错误原因。
2.4、示例
打开上次创建的文件hello.c:

创建一个数组和一个字符串,将字符串复制到该数组中:

接着用write函数将该数组中的内容写进创建的文件 ll 中:

其中 fd 是文件描述符,&writebuf[0]是数组的首地址,12是输入的字符数;
整体代码如下;
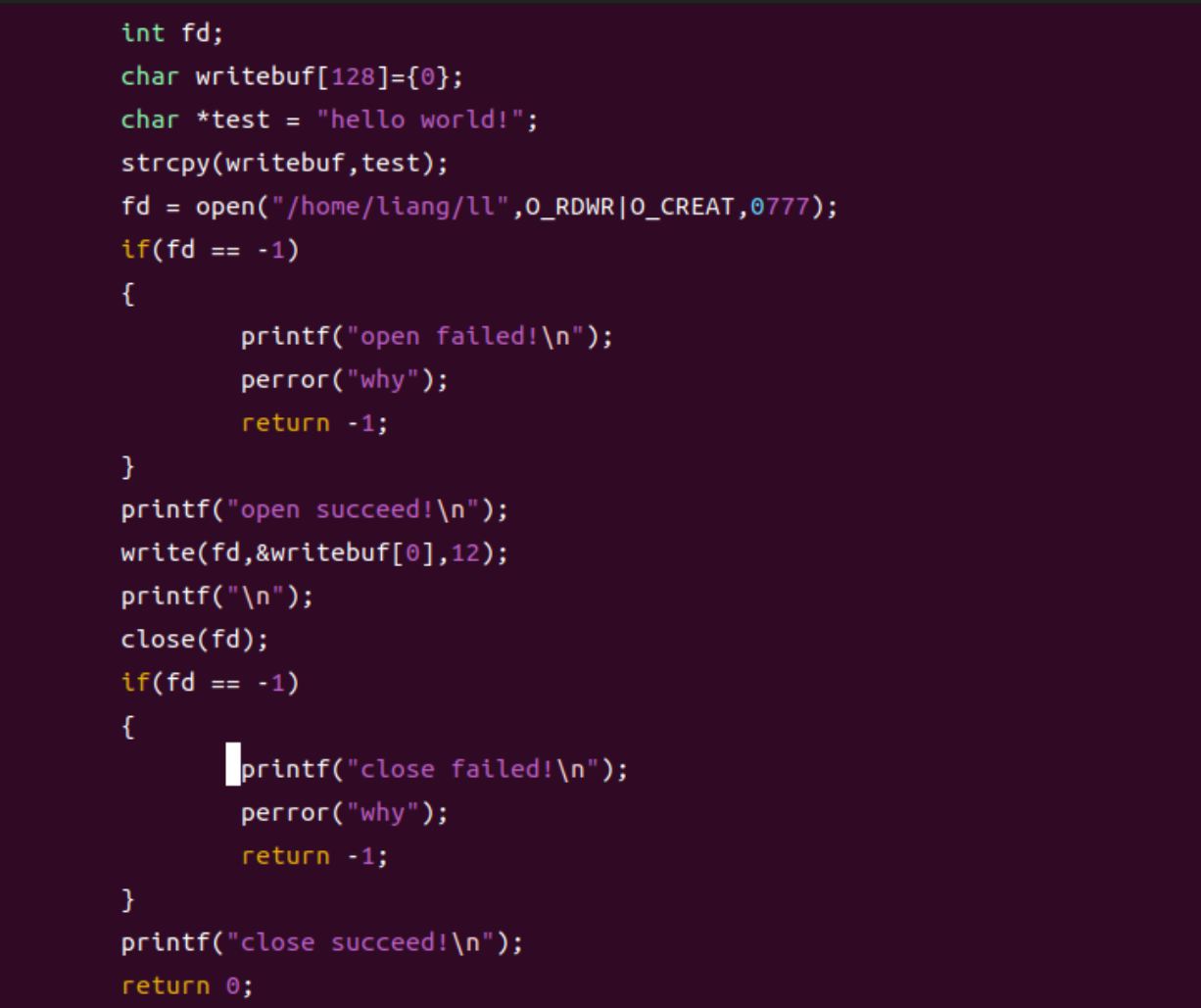
保存并退出,并使用gcc编译器进行编译:

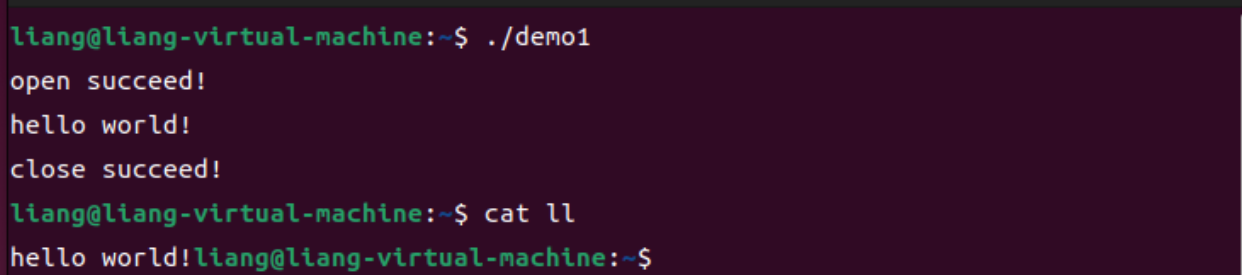
最后使用cat(concatenate)指令来查看我们写入的字符串:

3、read函数
3.1、函数原型
#include <unistd.h>ssize_t read(int fd, void *buf, size_t count);3.2、参数说明
fd:文件描述符,通过open()、socket()等函数获得,用于标识要读取数据的文件、设备等;
buf:数据缓冲区指针,对于read():存放读取的数据;
count:期望读取的字节数,即希望从文件描述符对应的文件或设备中读取的最大字节数;
3.3、返回值
count大于0:表示实际成功读取的字节数。
count等于0:表示已经到达文件末尾(EOF),没有更多数据可供读取。
count等于-1:表示读取操作失败,此时 errno 会被设置为相应的错误码,用于指示具体的错误原因。
3.4、示例
打开上次创建的文件hello.c:
 创建一个数组来 存放读取的数据:
创建一个数组来 存放读取的数据:

上面我们已经通过write函数将hello world!这个字符串写入到 ll 这个文件去了,现在我们先将write函数那行先注释掉(因为当用write写入数据后,光标会停在写入内容的末尾,如果直接执行read,会从当前光标位置开始读取,但此时末尾之后没有数据,所以 read 会读到空内容),然后使用read函数读取 ll 文件中的字符串,再打印出来:
完整代码如下:
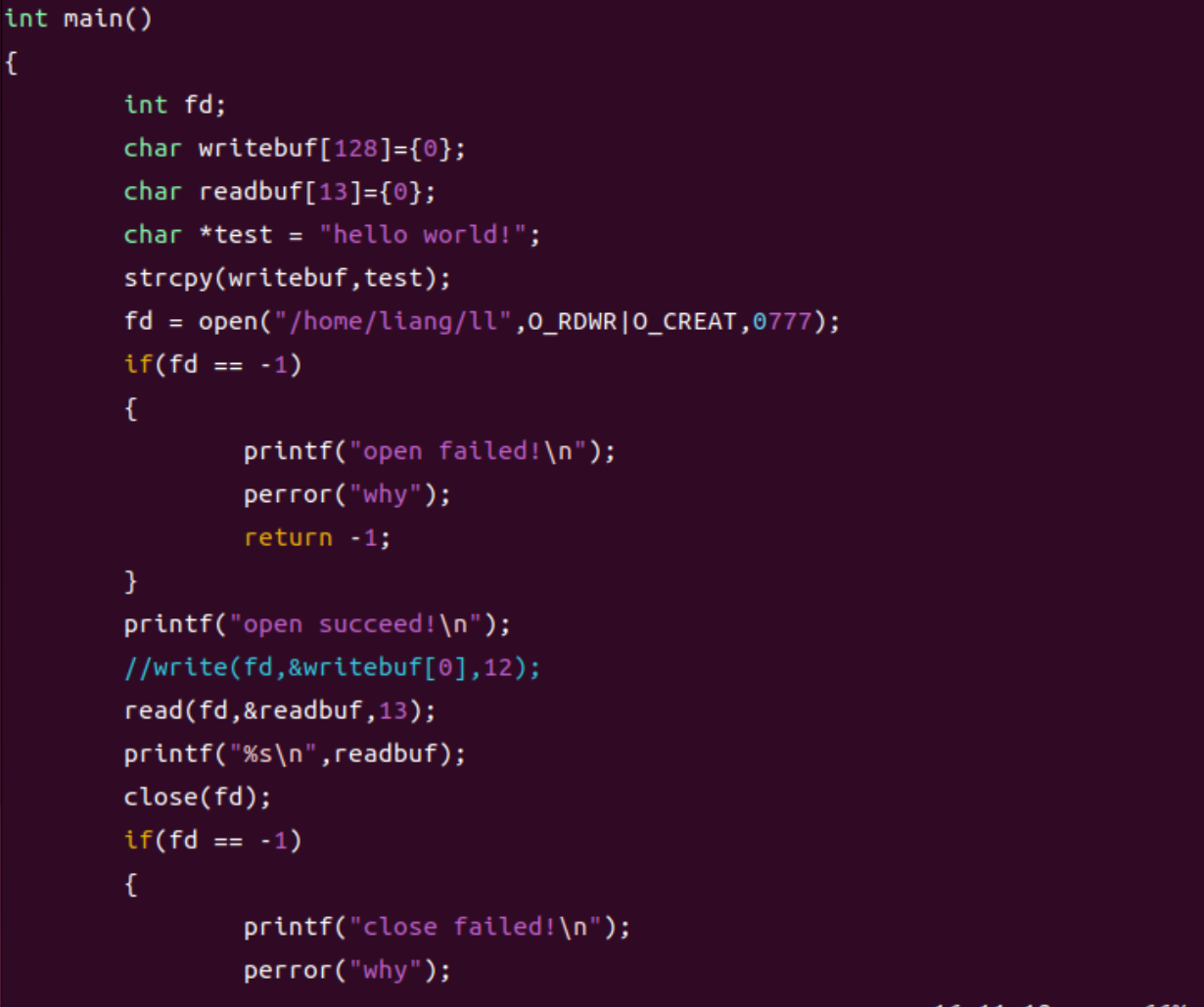
注:在定义关于read函数的数组时一定要大于等于我们要读取的数据长度,不然会导致乱码