PHP 高效 JSON 库 JsonMachine
在现代软件开发和物联网(IoT)应用中,JSON 已经无处不在。无论是设备状态上报、传感器数据采集,还是服务器端 API 通信,几乎所有系统都在 读写 JSON。
然而,随着数据量激增,JSON 文件也变得越来越大,几十 MB、几百 MB,甚至上 GB 的日志或状态文件,直接使用PHP的传统方法读取的话,如:
json_decode(file_get_contents(...)) 很容易就会 直接爆内存
Allowed memory size of __你心中的数字__ bytes exhausted如果你还在为处理大 JSON 文件而头疼,不妨看看 JsonMachine。这个 PHP 库能让你 边解析边遍历 JSON,低内存、高效率,从此大文件也能轻松处理。
核心特点
-
1. 低内存占用
-
• 每次只解析一个 JSON 项目,而不是一次性把整个 JSON 加载到内存。
-
• 文件/流处理内存复杂度
O(2),字符串解析内存复杂度O(n+1)。
-
-
2. 易用
-
• 直接用
foreach遍历 JSON,支持对象和数组。 -
• 可以迭代任意子树或标量值。
-
-
3. 支持 JSON Pointer
-
• 可以指定
/results/-/color等指针,仅迭代子节点或特定字段。
-
-
4. 递归迭代
-
•
RecursiveItems支持多层嵌套 JSON 的递归遍历。
-
-
5. 可选解码器
-
• 默认使用
ExtJsonDecoder(基于json_decode) -
• 可用
PassThruDecoder或ErrorWrappingDecoder处理特殊需求或跳过错误项。
-
-
6. 进度追踪
-
• 开启
debug后可通过getPosition()获取解析字节位置,计算百分比。
-
快速安装
composer require halaxa/json-machine基本使用
1. 遍历整个 JSON 文件
use JsonMachine\Items;$users = Items::fromFile('big_8m.json');
foreach ($users as $id => $user) {var_dump($user->name);
}2. 遍历子树(JSON Pointer)
$fruits = Items::fromFile('big_8m.json', ['pointer' => '/results']);
foreach ($fruits as $name => $data) {echo "$name => {$data->color}\n";
}3. 遍历数组嵌套值
$colors = Items::fromFile('big_8m.json', ['pointer' => '/results/-/color']);
foreach ($colors as $color) {echo $color, "\n"; // red, yellow
}4. 获取单个标量值
$lastModified = Items::fromFile('big_8m.json', ['pointer' => '/lastModified']);
echo iterator_to_array($lastModified)['lastModified'];5. 递归迭代复杂嵌套 JSON
use JsonMachine\RecursiveItems;$users = RecursiveItems::fromFile('big_8m.json');
foreach ($users as $user) {foreach ($user['friends'] as $friend) {$friendArray = $friend->toArray();echo $friendArray['username'];}
}6. 处理大文件或流
$stream = fopen('big_8m.json', 'r');
$items = Items::fromStream($stream);7. 跳过错误项
use JsonMachine\JsonDecoder\ErrorWrappingDecoder;
useJsonMachine\JsonDecoder\ExtJsonDecoder;$items = Items::fromFile('big_8m.json', ['decoder' => newErrorWrappingDecoder(newExtJsonDecoder())
]);
foreach ($itemsas$item) {if ($iteminstanceof \JsonMachine\JsonDecoder\DecodingError) continue;// 正常处理
}简单测试
以下是笔者亲测试的数据示例,先使用generator_json.php生成了800万条数据,然后使用传统的json_decode方法和JsonMachine库进行对比,如下:
1. 生成JSON 数据
<?php$startTime = microtime(true); // 开始计时$filename = 'big_8m.json';
$handle = fopen($filename, 'w');if (!$handle) {die("无法打开文件 $filename");
}// 写入 JSON 数组的起始符
fwrite($handle, '[');$total = 8000000; // 800万条
$first = true;for ($i = 1; $i <= $total; $i++) {$item = ['id' => $i,'name' => "User$i",'email' => "user$i@example.com",'phone' => "1234567890$i",];$json = json_encode($item);if ($first) {fwrite($handle, $json);$first = false;} else {fwrite($handle, ',' . PHP_EOL . $json);}
}fwrite($handle, ']'); // 写入 JSON 数组结束符
fclose($handle);$endTime = microtime(true); // 结束计时
$duration = $endTime - $startTime;echo"生成完成,文件路径:$filename\n";
echo"耗时:".round($duration, 2)." 秒\n";
2. 传统的json_decode方法
<?phpini_set('memory_limit', '4G'); // 设置内存上限为 4GB$file = __DIR__ . '/big_8m.json';$startTime = microtime(true);
$startMemory = memory_get_usage();// 直接一次性读取整个文件
$json = file_get_contents($file);
$data = json_decode($json, true); // 转为数组$endTimeDecode = microtime(true);
$memoryAfterDecode = memory_get_usage();
$peakMemory = memory_get_peak_usage(true);$count = count($data);// 输出前 5 条,避免屏幕太长
for ($i = 0; $i < min(5, $count); $i++) {echo$data[$i]['id'] . ' => ' . $data[$i]['name'] . PHP_EOL;
}$endTime = microtime(true);
$endMemory = memory_get_usage();echo PHP_EOL;
echo"总记录数:$count" . PHP_EOL;
echo"耗时(读取+解析):". round($endTimeDecode - $startTime, 2) ." 秒" . PHP_EOL;
echo"总耗时:". round($endTime - $startTime, 2) ." 秒" . PHP_EOL;
echo"起始内存:" . round($startMemory / 1024 / 1024, 2) . " MB" . PHP_EOL;
echo"解析后内存:" . round($memoryAfterDecode / 1024 / 1024, 2) . " MB" . PHP_EOL;
echo"结束内存:" . round($endMemory / 1024 / 1024, 2) . " MB" . PHP_EOL;
echo"峰值内存:" . round($peakMemory / 1024 / 1024, 2) . " MB" . PHP_EOL;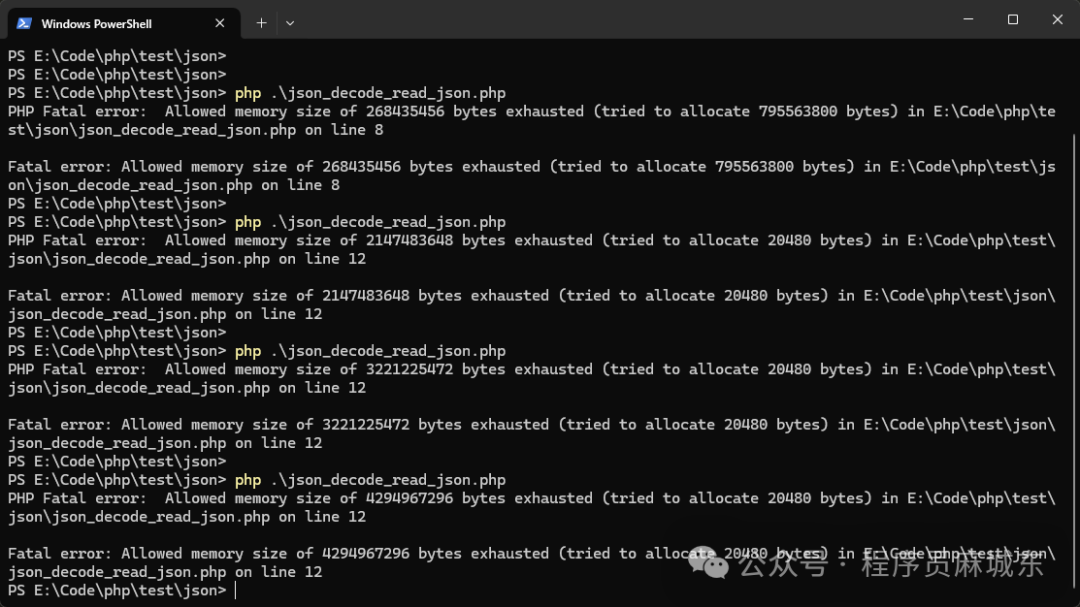
3. 使用JsonMachine库
<?php$startTime = microtime(true); // 开始计时
$startMemory = memory_get_usage();require'vendor/autoload.php';
useJsonMachine\Items;$items = Items::fromFile(__DIR__ . '/big_8m.json');foreach ($itemsas$item) {// 对象访问echo$item->id . ' => ' . $item->name . PHP_EOL;
}$endTime = microtime(true); // 结束计时
$duration = $endTime - $startTime;$endMemory = memory_get_usage();
$peakMemory = memory_get_peak_usage(true);echo" === 耗时:".round($duration, 2)." 秒" . PHP_EOL;
echo" === 起始内存:" . round($startMemory / 1024 / 1024, 2) . " MB" . PHP_EOL;
echo" === 结束内存:" . round($endMemory / 1024 / 1024, 2) . " MB" . PHP_EOL;
echo" === 峰值内存:" . round($peakMemory / 1024 / 1024, 2) . " MB" . PHP_EOL;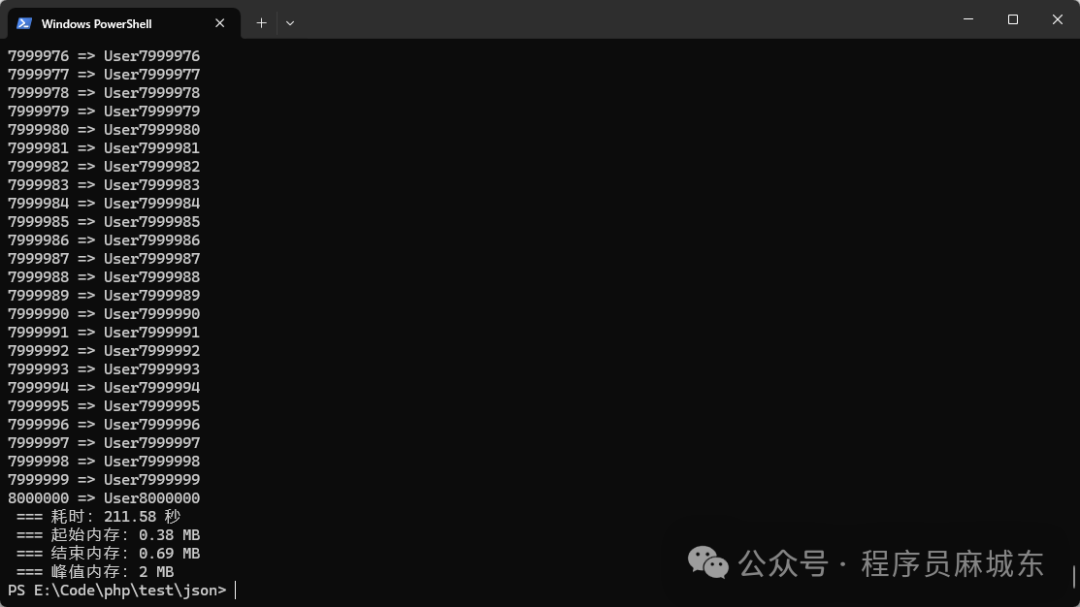
写在最后
在 PHP 开发中,处理大 JSON 文件时,推荐使用 JsonMachine,它支持流式解析,一次只加载一个 JSON 项到内存,内存占用恒定,代码简单易用,并且可以遍历子树、递归解析或跳过错误项。虽然也可以使用 fgetc 等流式方式手动处理,但实现起来非常麻烦,容易出错。千万不要直接使用传统的
json_decode(file_get_contents('big_8m.json'), true)方法,因为这种方式会一次性把整个文件读入内存,遇到几十 MB、几百 MB 或更大的文件很容易导致内存爆炸。总之,大 JSON 文件优先用 JsonMachine,手动解析可行但不推荐,绝对避免一次性加载整个文件。