Apache Spark算法开发指导-特征转换VectorIndexer
VectorIndexer算法是向量集合索引器,提供一个向量数据集合,对集合中的向量数据的特征执行分类特征转换以及索引,算法执行流程:
1.输入向量数据集合(集合中每列的数据类型是向量Vector)以及最大特征分类数量maxCategories
2.统计不同特征出现的数量,数量小于或者等于maxCategories的特征归类为分类特征
3.从最小索引值0开始,对分类特征执行索引操作,将原始的特征值转换为索引
Java代码示例
在Java本地开发环境中,创建VectorIndexer算法测试类,初始化spark实例:

加载测试数据集合,定义VectorIndexer实例,对数据集合执行初始化,生成算法模型VectorIndexerModel实例:

sample_libsvm_data测试数据集的部分数据:
使用算法模型对特征执行分类特征的映射操作,对映射数据集执行特征转换操作:

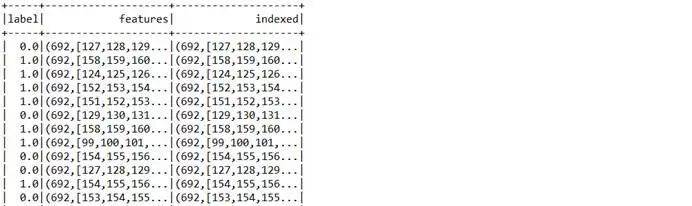
特征转换输出的部分数据:
Scala代码示例
与Java代码示例的功能逻辑相同:
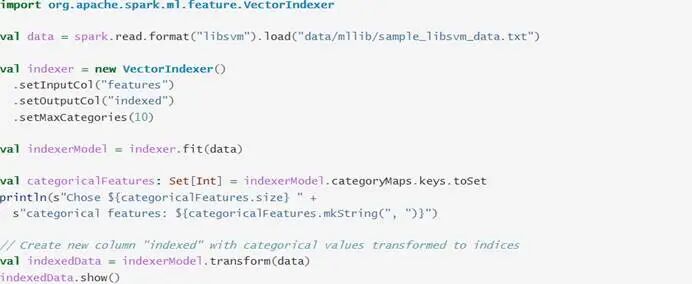
启动spark-shell的Scala本地运行环境:
运行VectorIndexer算法代码:
特征转换输出的部分数据: