基于Ollama和sentence-transformers,通过RAG实现问答式定制化回复
GitHub上的sentence-transformers用来把文字转换成数字向量(sentence embeddings),比如[0.1, 0.5, -0.2, 0.8, ...],让计算机能够理解和比较文本的语义相似度,功能包括:计算句子嵌入(将任意长度的句子或短文转换为一个固定长度的、高维的向量)、语义文本相似度(通过计算两个句子向量的相似度,来判断它们在语义上的相似程度)、语义搜索(在海量文本库中,根据查询句子的语义来寻找最相关的内容)、检索与重排序、聚类、挖掘等。源码地址:https://github.com/UKPLab/sentence-transformers,最新发布版本为v5.1.1,License为Apache-2.0。
Hugging Face提供超过15000个预训练的句子转换器(Sentence Transformer)模型供使用。
之前在 https://blog.csdn.net/fengbingchun/article/details/152724542 中基于ollama.embeddings实现问答式定制化回复,这里将ollama.embeddings调整为SentenceTransformer,测试代码如下:
def parse_args():parser = argparse.ArgumentParser(description="ollama rag chat: sentence-transformers")parser.add_argument("--llm_model", type=str, default="qwen3:1.7b", help="llm model name, for example:qwen3:1.7b")parser.add_argument("--embed_model", type=str, default="BAAI/bge-small-zh-v1.5", help="sentence-transformers model")parser.add_argument("--jsonl", type=str, default="csdn.jsonl", help="jsonl(JSON Lines) file")parser.add_argument("--db_dir", type=str, default="chroma_db_sentence_transformers", help="vector database(chromadb) storage path")parser.add_argument("--similarity_threshold", type=float, default=0.8, help="similarity threshold, the higher the stricter")parser.add_argument("--question", type=str, help="question")args = parser.parse_args()return argsdef load_embed_model(model_name):return SentenceTransformer(model_name)def build_vector_db(db_dir, jsonl, embed_model):client = chromadb.PersistentClient(path=db_dir)collection = client.get_or_create_collection(name="csdn_qa_sentence-transformers", metadata={"hnsw:space":"cosine"})if collection.count() > 0:return collectionprint("start building vector database ...")with open(jsonl, "r", encoding="utf-8") as f:data = [json.loads(line.strip()) for line in f]for i, item in enumerate(tqdm(data, desc="Embedding with sentence-transformers")):question = item["question"]answer = item["answer"]emb = embed_model.encode(question, normalize_embeddings=True).tolist()collection.add(ids=[str(i)],embeddings=[emb],metadatas=[{"question": question, "answer": answer}])time.sleep(0.05)print(f"vector database is built and a total of {len(data)} entries are imported")return collectiondef retrieve_answer(embed_model, collection, similarity_threshold, question):query_vec = embed_model.encode(question, normalize_embeddings=True).tolist()results = collection.query(query_embeddings=[query_vec], n_results=1)print(f"vector len: {len(query_vec)}; norm: {np.linalg.norm(query_vec):.4f}; vector: {query_vec[:5]}")if not results["ids"]:return Nonemeta = results["metadatas"][0][0]score = 1 - results["distances"][0][0]print(f"similarity: {score:.4f}")if score >= similarity_threshold:return f"question: {meta['question']}; link: {meta['answer']}"return Nonedef chat(llm_model_name, embed_model_name, jsonl, db_dir, similarity_threshold, question):embed_model = load_embed_model(embed_model_name)collection = build_vector_db(db_dir, jsonl, embed_model)ans = retrieve_answer(embed_model, collection, similarity_threshold, question)if ans:print(ans)else:try:stream = ollama.chat(model=llm_model_name, messages=[{"role": "user", "content": question}], stream=True)print("Answer: ", end="", flush=True)for chunk in stream:if 'message' in chunk and 'content' in chunk['message']:content = chunk['message']['content']print(content, end="", flush=True)print() # line breakexcept Exception as e:print(f"Error: {e}")if __name__ == "__main__":colorama.init(autoreset=True)args = parse_args()chat(args.llm_model, args.embed_model, args.jsonl, args.db_dir, args.similarity_threshold, args.question)print(colorama.Fore.GREEN + "====== execution completed ======")基于ollama.embeddings和SentenceTransformer的输出如下所示:
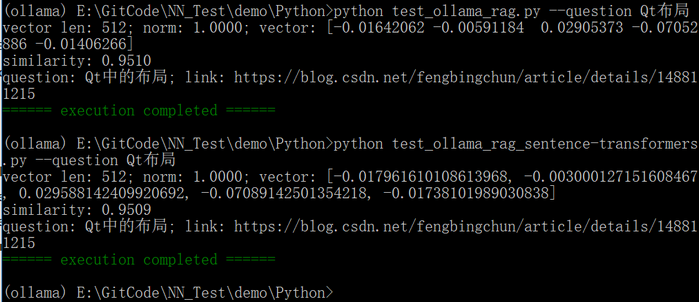
说明:
1. sentence-transformers中的嵌入模型BAAI/bge-small-zh-v1.5与ollama.embeddings中的qllama/bge-small-zh-v1.5:latest嵌入模型对应,因此它们最终的相似度输出结果相似。
2. SentenceTransformer函数每次调用都需联网,若本地已存在模型,可增加参数local_files_only=True使其直接加载本地模型。
3. 嵌入模型BAAI/bge-small-zh-v1.5内部已经强制进行了归一化,因此指定与否normalize_embeddings对输出无影响,输出都是归一化后的向量,np.linalg.norm的值均为1。
4. chromadb中设置使用余弦相似度计算时,chromadb的query函数内部会自动进行归一化处理。
5. 嵌入模型如bge-small-zh-v1.5的作用:用于将一段文字转换为固定长度的浮点数向量。
6. 向量数据库如chromadb的作用:计算新输入向量的嵌入,然后与数据库中存储的向量进行相似度搜索,距离(distances)值越小越相似,可返回Top-K个(由参数n_results指定)结果。
GitHub:https://github.com/fengbingchun/NN_Test