ShardingSphere 源码解析之分片引擎(下)
21 执行引擎:分片环境下 SQL 执行的整体流程应该如何进行抽象?
从今天开始,我们将开始一个全新的主题,即 ShardingSphere 的执行引擎(ExecuteEngine)。一旦我们获取了从路由引擎和改写引擎中所生成的 SQL,执行引擎就会完成这些SQL在具体数据库中的执行。
执行引擎是 ShardingSphere 的核心模块,接下来我们将通过三个课时来对其进行全面介绍。今天,我们先讨论在分片环境下,ShardingSphere 对 SQL 执行的整体流程的抽象过程,后两个课时会向你讲解“如何把握 ShardingSphere 中的 Executor 执行模型”。
ShardingSphere 执行引擎总体结构
在讲解具体的源代码之前,我们从《17 | 路由引擎:如何理解分片路由核心类 ShardingRouter 的运作机制?》中的 PreparedQueryShardingEngine 和 SimpleQueryShardingEngine 这两个类出发,看看在 ShardingSphere 中使用它们的入口。
我们在ShardingStatement类中找到了如下所示的一个 shard 方法,这里用到了 SimpleQueryShardingEngine:
private void shard(final String sql) {//从 Connection 中获取 ShardingRuntimeContext 上下文ShardingRuntimeContext runtimeContext = connection.getRuntimeContext(); //创建 SimpleQueryShardingEngineSimpleQueryShardingEngine shardingEngine = new SimpleQueryShardingEngine(runtimeContext.getRule(), runtimeContext.getProps(), runtimeContext.getMetaData(), runtimeContext.getParseEngine()); //执行分片路由并获取路由结果sqlRouteResult = shardingEngine.shard(sql, Collections.emptyList());
}
而在ShardingPreparedStatement中也存在一个类似的 shard 方法。
从设计模式上讲,ShardingStatement 和 ShardingPreparedStatement 实际上就是很典型的外观类,它们把与 SQL 路由和执行的入口类都整合在一起。
通过阅读源码,我们不难发现在 ShardingStatement 中存在一个 StatementExecutor;而在 ShardingPreparedStatement 中也存在 PreparedStatementExecutor 和 BatchPreparedStatementExecutor,这些类都以 Executor 结尾,显然这就是我们要找的 SQL 执行引擎的入口类。
我们发现上述三个 Executor 都位于 sharding-jdbc-core 工程中。
此外,还有一个与 sharding-core-route 和 sharding-core-rewrite 并列的sharding-core-execute 工程,从命名上看,这个工程应该也与执行引擎相关。果然,我们在这个工程中找到了ShardingExecuteEngine 类,这是分片执行引擎的入口类。
然后,我们又分别找到了 SQLExecuteTemplate 和 SQLExecutePrepareTemplate 类,这两个是典型的SQL 执行模板类。
根据到目前为止对 ShardingSphere 组件设计和代码分层风格的了解,可以想象,在层次关系上,ShardingExecuteEngine 是底层对象,SQLExecuteTemplate 应该依赖于 ShardingExecuteEngine;而 StatementExecutor、PreparedStatementExecutor 和 BatchPreparedStatementExecutor 属于上层对象,应该依赖于 SQLExecuteTemplate。我们通过简单阅读这些核心类之前的引用关系,印证了这种猜想。
基于以上分析,我们可以给出 SQL 执行引擎的整体结构图(如下图),其中横线以上部分位于 sharding-core-execute 工程,属于底层组件;而直线以下部分位于 sharding-jdbc-core 中,属于上层组件。这种分析源码的能力也是《12 | 从应用到原理:如何高效阅读 ShardingSphere 源码?》中提到的“基于分包设计原则阅读源码”的一种具体表现:
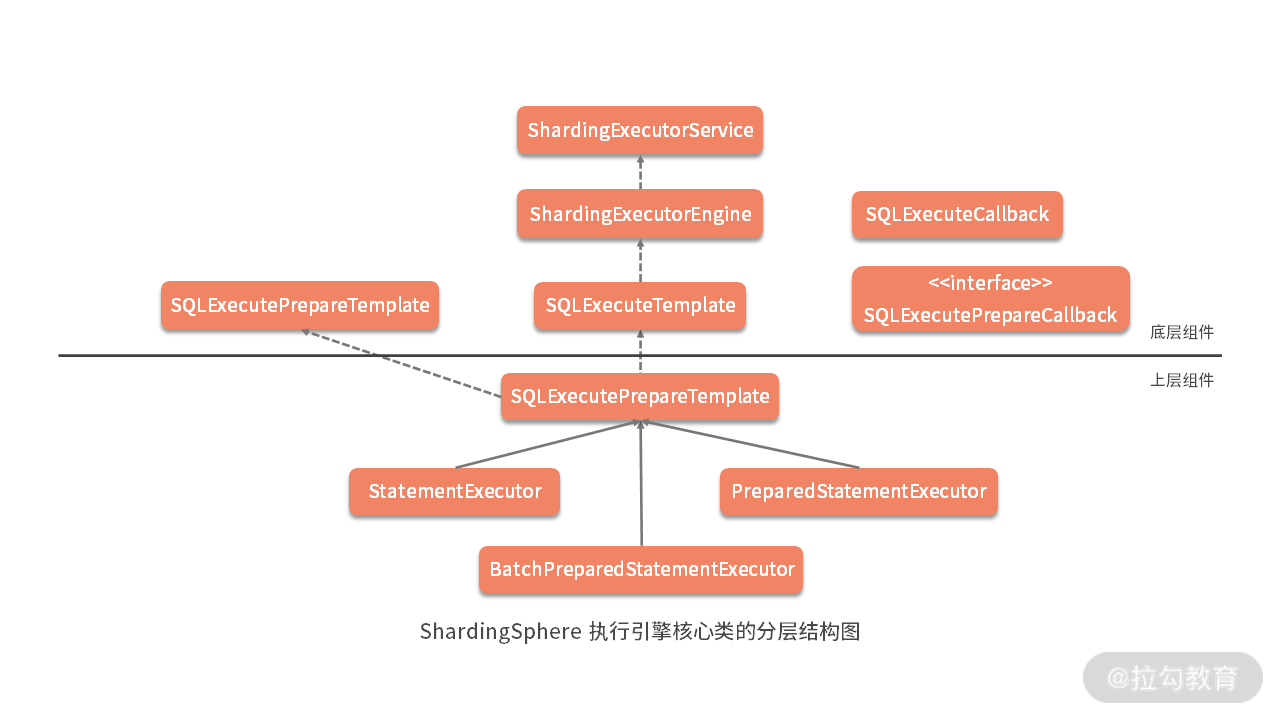
ShardingSphere 执行引擎核心类的分层结构图
另一方面,我们在上图中还看到 SQLExecuteCallback 和 SQLExecutePrepareCallback,显然,它们的作用是完成 SQL 执行过程中的回调处理,这也是一种非常典型的扩展性处理方式。
ShardingExecuteEngine
按照惯例,我们还是从位于底层的 ShardingExecuteEngine 开始切入。与路由和改写引擎不同,ShardingExecuteEngine 是 ShardingSphere 中唯一的一个执行引擎,所以直接设计为一个类而非接口,这个类包含了如下的变量和构造函数:
private final ShardingExecutorService shardingExecutorService;
private ListeningExecutorService executorService;public ShardingExecuteEngine(final int executorSize) {shardingExecutorService = new ShardingExecutorService(executorSize);executorService = shardingExecutorService.getExecutorService();
}
1.ExecutorService
如上所示,我们可以看出,这里有两个以 ExecutorService 结尾的变量,显然从命名上不难看出它们都是执行器服务,与 JDK 中的 java.util.concurrent.ExecutorService 类似。其中ListeningExecutorService来自 Google 的工具包 Guava;而ShardingExecutorService是 ShardingSphere 中的自定义类,包含了 ListeningExecutorService 的构建过程。接下来我们对两者分别展开讲述。
- ShardingExecutorService
我们发现 ShardingExecutorService 包含了一个 JDK 的 ExecutorService,它的创建过程如下,这里用到的 newCachedThreadPool 和 newFixedThreadPool 都是 JDK 提供的常见方法:
private ExecutorService getExecutorService(final int executorSize, final String nameFormat) {ThreadFactory shardingThreadFactory = ShardingThreadFactoryBuilder.build(nameFormat);return 0 == executorSize ? Executors.newCachedThreadPool(shardingThreadFactory) : Executors.newFixedThreadPool(executorSize, shardingThreadFactory);
}
- ListeningExecutorService
由于 JDK 中普通线程池返回的 Future 功能比较单一,所以 Guava 提供了 ListeningExecutorService 对其进行装饰。我们可以通过 ListeningExecutorService 对 ExecutorService 做一层包装,返回一个 ListenableFuture 实例,而 ListenableFuture 又是继承自 Future,扩展了一个 addListener 监听方法,这样当任务执行完成就会主动回调该方法。ListeningExecutorService 的构建过程如下所示:
executorService = MoreExecutors.listeningDecorator(getExecutorService(executorSize, nameFormat));
oreExecutors.addDelayedShutdownHook(executorService, 60, TimeUnit.SECONDS);
明确了执行器 ExecutorService 之后,我们回到 ShardingExecuteEngine 类,该类以 groupExecute 方法为入口,这个方法参数比较多,也单独都列了一下:
/** * @param inputGroups:输入组* @param firstCallback:第一次分片执行回调* @param callback:分片执行回调* @param serial:是否使用多线程进行执行* @param <I>:输入值类型* @param <O>:返回值类型* @return 执行结果* @throws SQLException:抛出异常*/
public <I, O> List<O> groupExecute(final Collection<ShardingExecuteGroup<I>> inputGroups, final ShardingGroupExecuteCallback<I, O> firstCallback, final ShardingGroupExecuteCallback<I, O> callback, final boolean serial)throws SQLException {if (inputGroups.isEmpty()) {return Collections.emptyList();}return serial ? serialExecute(inputGroups, firstCallback, callback) : parallelExecute(inputGroups, firstCallback, callback);
}
这里的分片执行组 ShardingExecuteGroup 对象实际上就是一个包含输入信息的列表,而上述 groupExecute 方法的输入是一个 ShardingExecuteGroup 的集合。通过判断输入参数 serial 是否为 true,上述代码流程分别转向了serialExecute 和 parallelExecute 这两个代码分支,接下来我来分别讲解一下这两个代码分支。
2.SerialExecute
我们先来看 serialExecute 方法,顾名思义,该方法用于串行执行的场景:
private <I, O> List<O> serialExecute(final Collection<ShardingExecuteGroup<I>> inputGroups, final ShardingGroupExecuteCallback<I, O> firstCallback,final ShardingGroupExecuteCallback<I, O> callback) throws SQLException {Iterator<ShardingExecuteGroup<I>> inputGroupsIterator = inputGroups.iterator();//获取第一个输入的ShardingExecuteGroupShardingExecuteGroup<I> firstInputs = inputGroupsIterator.next();//通过第一个回调 firstCallback 完成同步执行的 syncGroupExecuteList<O> result = new LinkedList<>(syncGroupExecute(firstInputs, null == firstCallback ? callback : firstCallback));//对剩下的 ShardingExecuteGroup,通过回调 callback 逐个同步执行 syncGroupExecutefor (ShardingExecuteGroup<I> each : Lists.newArrayList(inputGroupsIterator)) {result.addAll(syncGroupExecute(each, callback));}return result;
}
上述代码的基本流程是获取第一个输入的 ShardingExecuteGroup,通过第一个回调 firstCallback 完成同步执行的 syncGroupExecute 方法。然后对剩下的 ShardingExecuteGroup,通过回调 callback 逐个执行 syncGroupExecute 方法。这里的 syncGroupExecute 方法如下所示:
private <I, O> Collection<O> syncGroupExecute(final ShardingExecuteGroup<I> executeGroup, final ShardingGroupExecuteCallback<I, O> callback) throws SQLException {return callback.execute(executeGroup.getInputs(), true, ShardingExecuteDataMap.getDataMap());
}
我们看到同步执行的过程实际上是交给了 ShardingGroupExecuteCallback 回调接口:
public interface ShardingGroupExecuteCallback<I, O> {Collection<O> execute(Collection<I> inputs, boolean isTrunkThread, Map<String, Object> shardingExecuteDataMap) throws SQLException;
}
这里的 ShardingExecuteDataMap 相当于一个用于 SQL 执行的数据字典,这些数据字典保存在 ThreadLocal 中,从而确保了线程安全。我们可以根据当前的执行线程获取对应的 DataMap 对象。
3.ParallelExecute
这样,关于串行执行的流程就介绍完了,接下来我们来看并行执行的 parallelExecute 方法:
private <I, O> List<O> parallelExecute(final Collection<ShardingExecuteGroup<I>> inputGroups, final ShardingGroupExecuteCallback<I, O> firstCallback,final ShardingGroupExecuteCallback<I, O> callback) throws SQLException {Iterator<ShardingExecuteGroup<I>> inputGroupsIterator = inputGroups.iterator();//获取第一个输入的 ShardingExecuteGroupShardingExecuteGroup<I> firstInputs = inputGroupsIterator.next();//通过 asyncGroupExecute 执行异步回调Collection<ListenableFuture<Collection<O>>> restResultFutures = asyncGroupExecute(Lists.newArrayList(inputGroupsIterator), callback);//获取执行结果并组装返回return getGroupResults(syncGroupExecute(firstInputs, null == firstCallback ? callback : firstCallback), restResultFutures);
}
注意到这里有一个异步执行方法 asyncGroupExecute,传入参数是一个 ShardingExecuteGroup 列表:
private <I, O> Collection<ListenableFuture<Collection<O>>> asyncGroupExecute(final List<ShardingExecuteGroup<I>> inputGroups, final ShardingGroupExecuteCallback<I, O> callback) {Collection<ListenableFuture<Collection<O>>> result = new LinkedList<>();for (ShardingExecuteGroup<I> each : inputGroups) {result.add(asyncGroupExecute(each, callback));}return result;
}
这个方法中针对每个传入的 ShardingExecuteGroup,再次调用一个重载的异步 asyncGroupExecute 方法:
private <I, O> ListenableFuture<Collection<O>> asyncGroupExecute(final ShardingExecuteGroup<I> inputGroup, final ShardingGroupExecuteCallback<I, O> callback) {final Map<String, Object> dataMap = ShardingExecuteDataMap.getDataMap();return executorService.submit(new Callable<Collection<O>>() {@Overridepublic Collection<O> call() throws SQLException {return callback.execute(inputGroup.getInputs(), false, dataMap);}});
}
显然,作为异步执行方法,这里就会使用 Guava 的 ListeningExecutorService 来提交一个异步执行的任务并返回一个 ListenableFuture,而这个异步执行的任务就是具体的回调。
最后,我们来看 parallelExecute 方法的最后一句,即调用 getGroupResults 方法获取执行结果:
private <O> List<O> getGroupResults(final Collection<O> firstResults, final Collection<ListenableFuture<Collection<O>>> restFutures) throws SQLException {List<O> result = new LinkedList<>(firstResults);for (ListenableFuture<Collection<O>> each : restFutures) {try {result.addAll(each.get());} catch (final InterruptedException | ExecutionException ex) {return throwException(ex);}}return result;
}
熟悉 Future 用法的同学对上述代码应该不会陌生,我们遍历 ListenableFuture,然后调动它的 get 方法同步等待返回结果,最后当所有的结果都获取到之后组装成一个结果列表并返回,这种写法在使用 Future 时非常常见。
我们回过头来看,无论是 serialExecute 方法还是 parallelExecute 方法,都会从 ShardingExecuteGroup 中获取第一个 firstInputs 元素并进行执行,然后剩下的再进行同步或异步执行。ShardingSphere 这样使用线程的背后有其独特的设计思路。考虑到当前线程同样也是一种可用资源,让第一个任务由当前线程进行执行就可以充分利用当前线程,从而最大化线程的利用率。
至此,关于 ShardingExecuteEngine 类的介绍就告一段落。作为执行引擎,ShardingExecuteEngine 所做的事情就是提供一个多线程的执行环境。在系统设计上,这也是在日常开发过程中可以参考的一个技巧。我们可以设计并实现一个多线程执行环境,这个环境不需要完成具体的业务操作,而只需要负责执行传入的回调函数。ShardingSphere 中的ShardingExecuteEngine 就是提供了这样一种环境,同样的实现方式在其他诸如 Spring 等开源框架中也都可以看到。
接下来,就让我们来看一下 ShardingSphere 如何通过回调完成 SQL 的真正执行。
回调接口 ShardingGroupExecuteCallback
回调接口 ShardingGroupExecuteCallback 的定义非常简单:
public interface ShardingGroupExecuteCallback<I, O> {Collection<O> execute(Collection<I> inputs, boolean isTrunkThread, Map<String, Object> shardingExecuteDataMap) throws SQLException;
}
该接口根据传入的泛型 inputs 集合和 shardingExecuteDataMap 完成真正的 SQL 执行操作。在 ShardingSphere 中,使用匿名方法实现 ShardingGroupExecuteCallback 接口的地方有很多,但显式实现这一接口的只有一个类,即 SQLExecuteCallback 类,这是一个抽象类,它的 execute 方法如下所示:
@Override
public final Collection<T> execute(final Collection<StatementExecuteUnit> statementExecuteUnits, final boolean isTrunkThread, final Map<String, Object> shardingExecuteDataMap) throws SQLException {Collection<T> result = new LinkedList<>();for (StatementExecuteUnit each : statementExecuteUnits) {result.add(execute0(each, isTrunkThread, shardingExecuteDataMap));}return result;
}
对于每个输入的 StatementExecuteUnit 数据结构,上述 execute 方法会进一步执行一个 execute0 方法,如下所示:
private T execute0(final StatementExecuteUnit statementExecuteUnit, final boolean isTrunkThread, final Map<String, Object> shardingExecuteDataMap) throws SQLException {//设置 ExecutorExceptionHandlerExecutorExceptionHandler.setExceptionThrown(isExceptionThrown);//获取 DataSourceMetaData,这里用到了缓存机制DataSourceMetaData dataSourceMetaData = getDataSourceMetaData(statementExecuteUnit.getStatement().getConnection().getMetaData());//初始化 SQLExecutionHookSQLExecutionHook sqlExecutionHook = new SPISQLExecutionHook();try {RouteUnit routeUnit = statementExecuteUnit.getRouteUnit();//启动执行钩子sqlExecutionHook.start(routeUnit.getDataSourceName(), routeUnit.getSqlUnit().getSql(), routeUnit.getSqlUnit().getParameters(), dataSourceMetaData, isTrunkThread, shardingExecuteDataMap);//执行 SQLT result = executeSQL(routeUnit.getSqlUnit().getSql(), statementExecuteUnit.getStatement(), statementExecuteUnit.getConnectionMode());//成功钩子sqlExecutionHook.finishSuccess();return result;} catch (final SQLException ex) {//失败钩子sqlExecutionHook.finishFailure(ex);//异常处理ExecutorExceptionHandler.handleException(ex);return null;}}
这段代码每一句的含义都比较明确,这里引入了一个 ExecutorExceptionHandler 用于异常处理,同时也引入了一个 SPISQLExecutionHook 对执行过程嵌入钩子。关于基于 SPI 机制的 Hook 实现机制,我们在前面的 SQL 解析和路由引擎中已经看到过很多次,这里不再赘述。我们看到,真正执行 SQL 的过程是交给 executeSQL 模板方法进行完成,需要 SQLExecuteCallback 的各个子类实现这一模板方法。
在 ShardingSphere 中,没有提供任何的 SQLExecuteCallback 实现类,但大量采用匿名方法来完成 executeSQL 模板方法的实现。例如,在下一课时《22 | 执行引擎:如何把握 ShardingSphere 中的 Executor 执行模型?(上)》的 StatementExecutor 类中,executeQuery 方法就创建了一个 SQLExecuteCallback 匿名实现方法,用来完成查询操作:
public List<QueryResult> executeQuery() throws SQLException {
final boolean isExceptionThrown = ExecutorExceptionHandler.isExceptionThrown();
//创建 SQLExecuteCallback 并执行查询
SQLExecuteCallback<QueryResult> executeCallback = new SQLExecuteCallback<QueryResult>(getDatabaseType(), isExceptionThrown) {@Overrideprotected QueryResult executeSQL(final String sql, final Statement statement, final ConnectionMode connectionMode) throws SQLException {return getQueryResult(sql, statement, connectionMode);}
};
//执行 SQLExecuteCallback 并返回结果
return executeCallback(executeCallback);
}
模板类 SQLExecuteTemplate
在 ShardingSphere 执行引擎的底层组件中,还有一个类需要展开,这就是模板类 SQLExecuteTemplate,它是 ShardingExecuteEngine 的直接使用者。从命名上看,这是一个典型的模板工具类,定位上就像 Spring 中的 JdbcTemplate 一样。但凡这种模板工具类,其实现一般都比较简单,基本就是对底层对象的简单封装。
SQLExecuteTemplate 也不例外,它要做的就是对 ShardingExecuteEngine 中的入口方法进行封装和处理。ShardingExecuteEngine 的核心方法就只有一个,即 executeGroup 方法:
public <T> List<T> executeGroup(final Collection<ShardingExecuteGroup<? extends StatementExecuteUnit>> sqlExecuteGroups, final SQLExecuteCallback<T> firstCallback, final SQLExecuteCallback<T> callback) throws SQLException {try {return executeEngine.groupExecute((Collection) sqlExecuteGroups, firstCallback, callback, serial);} catch (final SQLException ex) {ExecutorExceptionHandler.handleException(ex);return Collections.emptyList();}
}
可以看到,这个方法所做的事情就是直接调用 ShardingExecuteEngine 的 groupExecute 方法完成具体的执行工作,并添加了异常处理机制而已。
从源码解析到日常开发
我们可以从今天的内容中,提炼出来许多技巧,并应用于日常开发过程中。比较实用的一个技巧是:我们可以使用 Guava 提供的 ListeningExecutorService 来强化 JDK 中基于普通 Future 的执行器服务 ExecutorService。同时,我们也看到了基于 Callback 的系统扩展机制,我们可以基于这种扩展机制,构建一个独立的运行环境,从而把与业务相关的所有操作通过回调得以实现。
小结与预告
本课时是介绍 ShardingSphere 执行引擎的第一部分内容,介绍了分片环境下 SQL 执行流程的抽象过程。我们先引出了执行引擎这个核心类,然后分别从执行器服务、执行回调以及执行模板类等维度对整个执行流程展开了详细讲述。
最后这里给你留一道思考题:在基于多线程技术实现 Executor 时,ShardingSphere 应用了哪些技巧?欢迎你在留言区与大家讨论,我将 一 一 点评解答。
下一课时,我们继续介绍 ShardingSphere 的执行引擎,我们将重点关注 SQL 的执行器 StatementExecutor。
22 执行引擎:如何把握 ShardingSphere 中的 Executor 执行模型?(上)
在上一课时中,我们对 ShardingGroupExecuteCallback 和 SQLExecuteTemplate 做了介绍。从设计上讲,前者充当 ShardingExecuteEngine 的回调入口;而后者则是一个模板类,完成对 ShardingExecuteEngine 的封装并提供了对外的统一入口,这些类都位于底层的 sharding-core-execute 工程中。
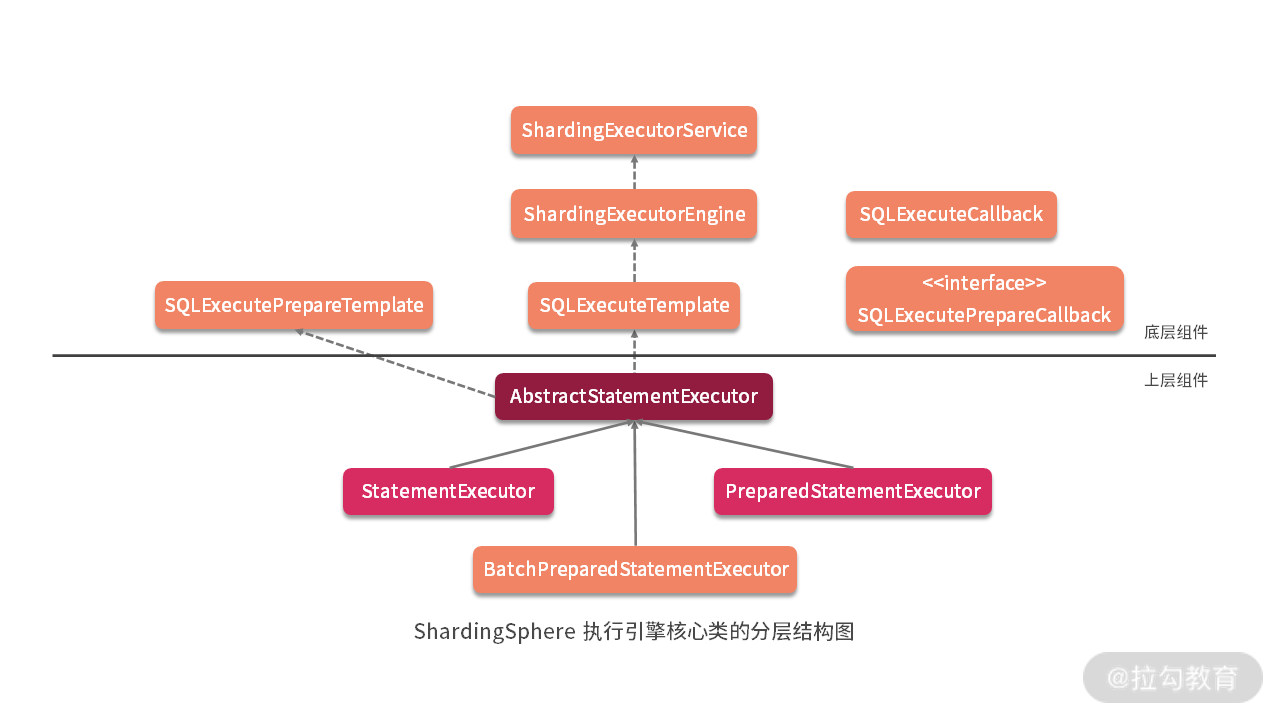
从今天开始,我们将进入到 sharding-jdbc-core 工程,来看看 ShardingSphere 中执行引擎上层设计中的几个核心类。
AbstractStatementExecutor
如上图所示,根据上一课时中的执行引擎整体结构图,可以看到SQLExecuteTemplate的直接使用者是AbstractStatementExecutor 类,今天我们就从这个类开始展开讨论,该类的变量比较多,我们先来看一下:
//数据库类型
private final DatabaseType databaseType;
//JDBC中用于指定结果处理方式的 resultSetType
private final int resultSetType;
//JDBC中用于指定是否可对结果集进行修改的 resultSetConcurrency
private final int resultSetConcurrency;
//JDBC中用于指定事务提交或回滚后结果集是否仍然可用的 resultSetConcurrency
private final int resultSetHoldability;
//分片 Connection
private final ShardingConnection connection;
//用于数据准备的模板类
private final SQLExecutePrepareTemplate sqlExecutePrepareTemplate;
//SQL 执行模板类
private final SQLExecuteTemplate sqlExecuteTemplate;
//JDBC的Connection列表
private final Collection<Connection> connections = new LinkedList<>();
//SQLStatement 上下文
private SQLStatementContext sqlStatementContext;
//参数集
private final List<List<Object>> parameterSets = new LinkedList<>();
//JDBC的Statement 列表
private final List<Statement> statements = new LinkedList<>();
//JDBC的ResultSet 列表
private final List<ResultSet> resultSets = new CopyOnWriteArrayList<>();
//ShardingExecuteGroup 列表
private final Collection<ShardingExecuteGroup<StatementExecuteUnit>> executeGroups = new LinkedList<>();
从这个类开始,我们会慢慢接触 JDBC 规范相关的对象,因为 ShardingSphere 的设计目标是,重写一套与目前的 JDBC 规范完全兼容的体系。这里,我们看到的 Connection、Statement 和 ResultSet 等对象,以及 resultSetType、resultSetConcurrency、resultSetHoldability 等参数,都是属于 JDBC 规范中的内容,我们在注释上做了特别的说明,你对此也都比较熟悉。
而像 ShardingSphere 自己封装的 ShardingConnection 对象也很重要,我们已经在《03 | 规范兼容:JDBC 规范与 ShardingSphere 是什么关系?》中对这个类的实现方式,以及如何兼容 JDBC 规范的详细过程做了介绍。
在 AbstractStatementExecutor 中,这些变量的展开,会涉及很多 sharding-jdbc-core 代码工程,关于数据库访问相关的类的介绍,包括我们以前已经接触过的 ShardingStatement 和 ShardingPreparedStatement 等类,所以我们在展开 AbstractStatementExecutor 类的具体实现方法之前,需要对这些类有一定的了解。
在 AbstractStatementExecutor 构造函数中,我们发现了上一课时中介绍的执行引擎 ShardingExecuteEngine 的创建过程,并通过它创建了 SQLExecuteTemplate 模板类,相关代码如下所示:
public AbstractStatementExecutor(final int resultSetType, final int resultSetConcurrency, final int resultSetHoldability, final ShardingConnection shardingConnection) {…ShardingExecuteEngine executeEngine = connection.getRuntimeContext().getExecuteEngine();sqlExecuteTemplate = new SQLExecuteTemplate(executeEngine, connection.isHoldTransaction());
}
同时,AbstractStatementExecutor 中如下所示的 cacheStatements 方法也很有特色,该方法会根据持有的 ShardingExecuteGroup 类分别填充 statements 和 parameterSets 这两个对象,以供 AbstractStatementExecutor 的子类进行使用:
protected final void cacheStatements() {for (ShardingExecuteGroup<StatementExecuteUnit> each : executeGroups) {statements.addAll(Lists.transform(each.getInputs(), new Function<StatementExecuteUnit, Statement>() {@Overridepublic Statement apply(final StatementExecuteUnit input) {return input.getStatement();}}));parameterSets.addAll(Lists.transform(each.getInputs(), new Function<StatementExecuteUnit, List<Object>>() {@Overridepublic List<Object> apply(final StatementExecuteUnit input) {return input.getRouteUnit().getSqlUnit().getParameters();}}));}
}
注意:这里在实现方式上使用了 Google 提供的 Guava 框架中的 Lists.transform 方法,从而完成了不同对象之间的转换过程,这种实现方式在 ShardingSphere 中应用广泛,非常值得你学习。
然后我们来看 AbstractStatementExecutor 中最核心的方法,即执行回调的 executeCallback 方法:
protected final <T> List<T> executeCallback(final SQLExecuteCallback<T> executeCallback) throws SQLException {List<T> result = sqlExecuteTemplate.executeGroup((Collection) executeGroups, executeCallback);refreshMetaDataIfNeeded(connection.getRuntimeContext(), sqlStatementContext);return result;
}
显然,在这里应该使用 SQLExecuteTemplate 模板类来完成具体回调的执行过程。同时,我可以看到这里还有一个 refreshMetaDataIfNeeded 辅助方法用来刷选元数据。
AbstractStatementExecutor 有两个实现类:一个是普通的 StatementExecutor,一个是 PreparedStatementExecutor,接下来我将分别进行讲解。
StatementExecutor
我们来到 StatementExecutor,先看它的用于执行初始化操作的 init 方法:
public void init(final SQLRouteResult routeResult) throws SQLException {setSqlStatementContext(routeResult.getSqlStatementContext());getExecuteGroups().addAll(obtainExecuteGroups(routeResult.getRouteUnits()));cacheStatements();
}
这里的 cacheStatements 方法前面已经介绍过,而 obtainExecuteGroups 方法用于获取所需的 ShardingExecuteGroup 集合。要实现这个方法,就需要引入 SQLExecutePrepareTemplate 和对应的回调 SQLExecutePrepareCallback。
1.SQLExecutePrepareCallback
从命名上看,让人感觉 SQLExecutePrepareTemplate 和 SQLExecuteTemplate 应该是一对,尤其是名称中有一个“Prepare”,让人联想到 PreparedStatement。
但事实上,SQLExecutePrepareTemplate 与 SQLExecuteTemplate 没有什么关联,它也不是像 SQLExecuteTemplate 一样提供了 ShardingExecuteEngine 的封装,而是主要关注于 ShardingExecuteGroup 数据的收集和拼装,换句话说是为了准备(Prepare)数据。
在 SQLExecutePrepareTemplate 中,核心的功能就是下面这个方法,该方法传入了一个 SQLExecutePrepareCallback 对象,并返回 ShardingExecuteGroup 的一个集合:
public Collection<ShardingExecuteGroup<StatementExecuteUnit>> getExecuteUnitGroups(final Collection<RouteUnit> routeUnits, final SQLExecutePrepareCallback callback) throws SQLException {return getSynchronizedExecuteUnitGroups(routeUnits, callback);
}
为了构建这个集合,SQLExecutePrepareTemplate 实现了很多辅助方法,同时它还引入了一个 SQLExecutePrepareCallback 回调,来完成 ShardingExecuteGroup 数据结构中部分数据的填充。SQLExecutePrepareCallback 接口定义如下,可以看到 Connection 和 StatementExecuteUnit 这两个对象是通过回调来创建的:
public interface SQLExecutePrepareCallback {//获取 Connection 列表List<Connection> getConnections(ConnectionMode connectionMode, String dataSourceName, int connectionSize) throws SQLException;//获取 Statement 执行单元StatementExecuteUnit createStatementExecuteUnit(Connection connection, RouteUnit routeUnit, ConnectionMode connectionMode) throws SQLException;
}
当我们获取了想要的 ShardingExecuteGroup 之后,相当于完成了 StatementExecutor 的初始化工作。该类中剩下的就是一系列以“execute”开头的 SQL 执行方法,包括 executeQuery、executeUpdate,以及它们的各种重载方法。我们先来看用于查询的 executeQuery 方法:
public List<QueryResult> executeQuery() throws SQLException {final boolean isExceptionThrown = ExecutorExceptionHandler.isExceptionThrown();//创建 SQLExecuteCallback 并执行查询SQLExecuteCallback<QueryResult> executeCallback = new SQLExecuteCallback<QueryResult>(getDatabaseType(), isExceptionThrown) {@Overrideprotected QueryResult executeSQL(final String sql, final Statement statement, final ConnectionMode connectionMode) throws SQLException {return getQueryResult(sql, statement, connectionMode);}};//执行 SQLExecuteCallback 并返回结果return executeCallback(executeCallback);
}
我们已经在上一课时中介绍过这个方法,我们知道 SQLExecuteCallback 实现了 ShardingGroupExecuteCallback 接口并提供了 executeSQL 模板方法。而在上述 executeQuery 方法中,executeSQL 模板方法的实现过程,就是调用如下所示的 getQueryResult 方法:
private QueryResult getQueryResult(final String sql, final Statement statement, final ConnectionMode connectionMode) throws SQLException {//通过 Statement 执行 SQL 并获取结果ResultSet resultSet = statement.executeQuery(sql);getResultSets().add(resultSet);//根据连接模式来确认构建结果return ConnectionMode.MEMORY_STRICTLY == connectionMode ? new StreamQueryResult(resultSet) : new MemoryQueryResult(resultSet);
}
2.ConnectionMode
getQueryResult 方法中完全基于 JDBC 中的 Statement 和 ResultSet 对象来执行查询并返回结果。
但是,这里也引入了 ShardingSphere 执行引擎中非常重要的一个概念,即ConnectionMode(连接模式),它是一个枚举:
public enum ConnectionMode {MEMORY_STRICTLY, CONNECTION_STRICTLY
}
可以看到有两种具体的连接模式:MEMORY_STRICTLY 和 CONNECTION_STRICTLY。
- MEMORY_STRICTLY 代表内存限制模式,
- CONNECTION_STRICTLY 代表连接限制模式。
ConnectionMode(连接模式) 是 ShardingSphere 所提出的一个特有概念,背后体现的是一种设计上的平衡思想。从数据库访问资源的角度来看,一方面是对数据库连接资源的控制保护,另一方面是采用更优的归并模式达到对中间件内存资源的节省,如何处理好两者之间的关系,是 ShardingSphere 执行引擎需求解决的问题。
为此,ShardingSphere 提出了连接模式的概念,简单举例说明:
- 当采用内存限制模式时,对于同一数据源,如果有 10 张分表,那么执行时会获取 10 个连接并进行并行执行;
- 而当采用连接限制模式时,执行过程中只会获取 1 个连接而进行串行执行。
那么这个 ConnectionMode 是怎么得出来的呢?
实际上这部分代码位于 SQLExecutePrepareTemplate 中,我们根据 maxConnectionsSizePerQuery 这个配置项,以及与每个数据库所需要执行的 SQL 数量进行比较,然后得出具体的 ConnectionMode:
ConnectionMode connectionMode = maxConnectionsSizePerQuery < sqlUnits.size() ? ConnectionMode.CONNECTION_STRICTLY : ConnectionMode.MEMORY_STRICTLY;
关于这个判断条件,我们可以使用一张简单的示意图来进行说明,如下所示:
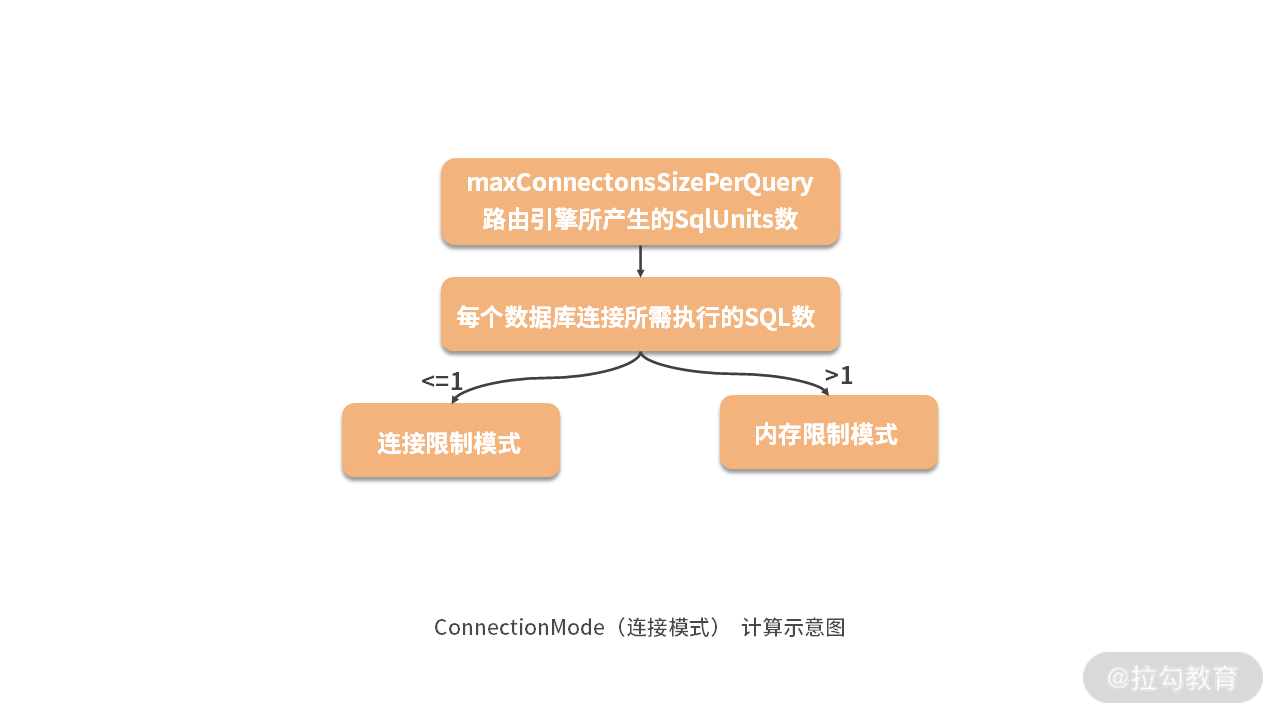
如上图所示,我们可以看到如果每个数据库连接所指向的 SQL 数多于一条时,走的是内存限制模式,反之走的是连接限制模式。
3.StreamQueryResult VS MemoryQueryResult
在了解了 ConnectionMode(连接模式) 的设计理念后,我们再来看 StatementExecutor 的 executeQuery 方法返回的是一个 QueryResult。
在 ShardingSphere 中,QueryResult 是一个代表查询结果的接口,可以看到该接口封装了很多面向底层数据获取的方法:
public interface QueryResult {boolean next() throws SQLException;Object getValue(int columnIndex, Class<?> type) throws SQLException;Object getCalendarValue(int columnIndex, Class<?> type, Calendar calendar) throws SQLException;InputStream getInputStream(int columnIndex, String type) throws SQLException;boolean wasNull() throws SQLException;int getColumnCount() throws SQLException;String getColumnLabel(int columnIndex) throws SQLException;boolean isCaseSensitive(int columnIndex) throws SQLException;
}
在 ShardingSphere中,QueryResult 接口存在于 StreamQueryResult(代表流式归并结果)和 MemoryQueryResult (代表内存归并结果)这两个实现类。
ShardingSphere 采用这样的设计实际上跟前面介绍的 ConnectionMode 有直接关系。
- 我们知道,在内存限制模式中,ShardingSphere 对一次操作所耗费的数据库连接数量不做限制;
- 而当采用连接限制模式时,ShardingSphere严格控制对一次操作所耗费的数据库连接数量。
基于这样的设计原理,如上面的 ConnectionMode 的计算示意图所示:在 maxConnectionSizePerQuery 允许的范围内,当一个连接需要执行的请求数量大于 1 时,意味着当前的数据库连接无法持有相应的数据结果集,则必须采用内存归并;反之,则可以采用流式归并。
- StreamQueryResult
我们通过对比 StreamQueryResult 和 MemoryQueryResult 的实现过程,对上述原理做进一步分析,在 StreamQueryResult 中,它的 next 方法非常简单:
@Override
public boolean next() throws SQLException {return resultSet.next();
}
显然这是一种流式处理的方式,从 ResultSet 中获取下一个数据行。
- MemoryQueryResult
我们再来看 MemoryQueryResult,在它的构造函数中,通过 getRows 方法把 ResultSet 中的全部数据行,先进行获取并存储在内存变量 rows 中:
private Iterator<List<Object>> getRows(final ResultSet resultSet) throws SQLException {Collection<List<Object>> result = new LinkedList<>();while (resultSet.next()) {List<Object> rowData = new ArrayList<>(resultSet.getMetaData().getColumnCount());for (int columnIndex = 1; columnIndex <= resultSet.getMetaData().getColumnCount(); columnIndex++) {//获取每一个 Row 的数据Object rowValue = getRowValue(resultSet, columnIndex);//存放在内存中rowData.add(resultSet.wasNull() ? null : rowValue);}result.add(rowData);}return result.iterator();
}
基于以上方法,MemoryQueryResult 的 next 方法应该是,从这个 rows 变量中获取下一个数据行,如下所示:
public boolean next() {if (rows.hasNext()) {currentRow = rows.next();return true;}currentRow = null;return false;
}
通过这种方式,我们就将传统的流式处理方式转变成了内存处理方式。
关于 ConnectionMode 和两种 QueryResult 的讨论就到这里,让我们回到 StatementExecutor。理解了 StatementExecutor 的 executeQuery 方法之后,我们再来看它更为通用的 execute 方法,如下所示:
public boolean execute() throws SQLException {return execute(new Executor() {@Overridepublic boolean execute(final Statement statement, final String sql) throws SQLException {return statement.execute(sql);}});
}
注意到上述 execute 方法并没有使用 SQLExecuteCallback 回调,而是使用了一个 Executor 接口,该接口定义如下:
private interface Executor {//执行 SQLboolean execute(Statement statement, String sql) throws SQLException;
}
然后我们再继续往下看,发现在改方法实际的执行过程中,还是用到了 SQLExecuteCallback 回调:
private boolean execute(final Executor executor) throws SQLException {final boolean isExceptionThrown = ExecutorExceptionHandler.isExceptionThrown();//创建 SQLExecuteCallback 并执行SQLExecuteCallback<Boolean> executeCallback = new SQLExecuteCallback<Boolean>(getDatabaseType(), isExceptionThrown) {@Overrideprotected Boolean executeSQL(final String sql, final Statement statement, final ConnectionMode connectionMode) throws SQLException {//使用 Executor 进行执行return executor.execute(statement, sql);}};List<Boolean> result = executeCallback(executeCallback);if (null == result || result.isEmpty() || null == result.get(0)) {return false;}return result.get(0);
}
这里多嵌套一层的目的是,更好地分离代码的职责,并对执行结果进行处理,同样的处理技巧在 StatementExecutor 的 executeUpdate 方法中也有体现。
PreparedStatementExecutor
讲完 StatementExecutor 之后,我们来看 PreparedStatementExecutor。PreparedStatementExecutor 包含了与 StatementExecutor 一样的用于初始化的 init 方法。然后,我们同样来看它如下所示的 executeQuery 方法,可以看到这里的处理方式与在 StatementExecutor 的一致:
public List<QueryResult> executeQuery() throws SQLException {final boolean isExceptionThrown = ExecutorExceptionHandler.isExceptionThrown();//创建 SQLExecuteCallback 并执行SQLExecuteCallback<QueryResult> executeCallback = new SQLExecuteCallback<QueryResult>(getDatabaseType(), isExceptionThrown) {@Overrideprotected QueryResult executeSQL(final String sql, final Statement statement, final ConnectionMode connectionMode) throws SQLException {return getQueryResult(statement, connectionMode);}};return executeCallback(executeCallback);
}
然后,我们再来看它的 execute 方法,就会发现有不同点:
public boolean execute() throws SQLException {boolean isExceptionThrown = ExecutorExceptionHandler.isExceptionThrown();SQLExecuteCallback<Boolean> executeCallback = SQLExecuteCallbackFactory.getPreparedSQLExecuteCallback(getDatabaseType(), isExceptionThrown);List<Boolean> result = executeCallback(executeCallback);if (null == result || result.isEmpty() || null == result.get(0)) {return false;}return result.get(0);
}
与 StatementExecutor 不同,PreparedStatementExecutor 在实现 execute 方法时没有设计类似 Executor 这样的接口,而是直接提供了一个工厂类 SQLExecuteCallbackFactory:
public final class SQLExecuteCallbackFactory {…public static SQLExecuteCallback<Boolean> getPreparedSQLExecuteCallback(final DatabaseType databaseType, final boolean isExceptionThrown) {return new SQLExecuteCallback<Boolean>(databaseType, isExceptionThrown) {@Overrideprotected Boolean executeSQL(final String sql, final Statement statement, final ConnectionMode connectionMode) throws SQLException {return ((PreparedStatement) statement).execute();}};}
}
注意到这里的静态方法 getPreparedSQLExecuteCallback 也就是返回了一个 SQLExecuteCallback 回调的实现,而在这个实现中使用了 JDBC 底层的 PreparedStatement 完成具体 SQL 的执行过程。
至此,我们对 ShardingSphere 中两个主要执行器 StatementExecutor 和 PreparedStatementExecutor 都进行了详细介绍。
从源码解析到日常开发
本课时关于两种 QueryResult 的设计思想,同样可以应用到日常开发中。当我们面对如何处理来自数据库或外部数据源的数据时,可以根据需要设计流式访问方式和内存访问方式,这两种访问方式在数据访问过程中都具有一定的代表性。
通常,我们会首先想到将所有访问到的数据存放在内存中,再进行二次处理,但这种处理方式会面临性能问题,流式访问方式性能更高,但需要我们挖掘适合的应用场景。
小结与预告
今天介绍了 ShardingSphere 执行引擎主题的第二个课时,我们重点围绕执行引擎中的执行器展开讨论,给出了 StatementExecutor 和 PreparedStatementExecutor 这两种执行器的实现方式,也给出了 ShardingSphere 中关于连接模式的详细讨论。
这里给大家留一道思考题:ShardingSphere 中连接模式的概念和作用是什么?欢迎你在留言区与大家讨论,我将逐一点评解答。
从类层结构而言,StatementExecutor 和 PreparedStatementExecutor 都属于底层组件,在下一课时,我们会介绍包括 ShardingStatement 和 PreparedShardingStatement 在内的位于更加上层的执行引擎组件。
23 执行引擎:如何把握 ShardingSphere 中的 Executor 执行模型?(下)
在上一课时,我们已经对 ShardingSphere 执行引擎中关于底层的 SQLExecuteTemplate,以及上层的 StatementExecutor 和 PreparedStatementExecutor 对象进行了全面介绍。
今天,我们在此基础上更上一层,重点关注 ShardingStatement 和 ShardingPreparedStatement 对象,这两个对象分别是 StatementExecutor 和 PreparedStatementExecutor 的使用者。
ShardingStatement
我们先来看 ShardingStatement 类,该类中的变量在前面的内容中都已经有过介绍:
private final ShardingConnection connection;
private final StatementExecutor statementExecutor;
private boolean returnGeneratedKeys;
private SQLRouteResult sqlRouteResult;
private ResultSet currentResultSet;
ShardingStatement 类的构造函数同样不是很复杂,我们发现 StatementExecutor 就是在这个构造函数中完成了其创建过程:
public ShardingStatement(final ShardingConnection connection, final int resultSetType, final int resultSetConcurrency, final int resultSetHoldability) {super(Statement.class);this.connection = connection;//创建 StatementExecutorstatementExecutor = new StatementExecutor(resultSetType, resultSetConcurrency, resultSetHoldability, connection);
}
在继续介绍 ShardingStatement 之前,我们先梳理一下与它相关的类层结构。我们在 “06 | 规范兼容:JDBC 规范与 ShardingSphere 是什么关系?” 中的 ShardingConnection 提到,ShardingSphere 通过适配器模式包装了自己的实现类,除了已经介绍的 ShardingConnection 类之外,还包含今天要介绍的 ShardingStatement 和 ShardingPreparedStament。
根据这一点,我们可以想象 ShardingStatement 应该具备与 ShardingConnection 类似的类层结构:
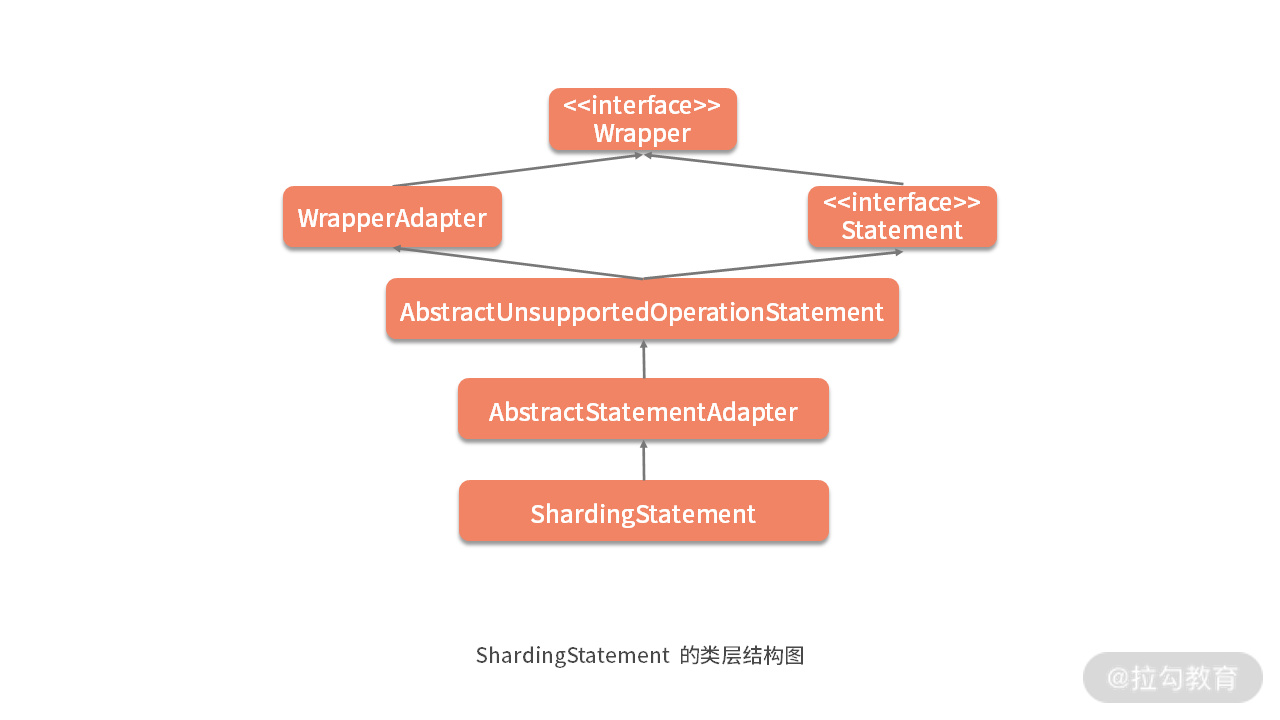
然后我们来到上图中 AbstractStatementAdapter 类,这里的很多方法的风格都与 ShardingConnection 的父类 AbstractConnectionAdapter 一致,例如如下所示的 setPoolable 方法:
public final void setPoolable(final boolean poolable) throws SQLException {this.poolable = poolable;recordMethodInvocation(targetClass, "setPoolable", new Class[] {boolean.class}, new Object[] {poolable});forceExecuteTemplate.execute((Collection) getRoutedStatements(), new ForceExecuteCallback<Statement>() {@Overridepublic void execute(final Statement statement) throws SQLException {statement.setPoolable(poolable);}});
这里涉及的 recordMethodInvocation 方法、ForceExecuteTemplate,以及 ForceExecuteCallback 我们都已经在“03 | 规范兼容:JDBC 规范与 ShardingSphere 是什么关系?”中进行了介绍,这里不再展开。
同样,AbstractStatementAdapter 的父类 AbstractUnsupportedOperationStatement 的作用也与 AbstractUnsupportedOperationConnection 的作用完全一致。
了解了 ShardingStatement 的类层结构之后,我们来看它的核心方法,首当其冲的还是它的 executeQuery 方法:
@Override
public ResultSet executeQuery(final String sql) throws SQLException {if (Strings.isNullOrEmpty(sql)) {throw new SQLException(SQLExceptionConstant.SQL_STRING_NULL_OR_EMPTY);}ResultSet result;try {//清除 StatementExecutor 中的相关变量clearPrevious();//执行路由引擎,获取路由结果shard(sql);//初始化 StatementExecutorinitStatementExecutor();//调用归并引擎MergeEngine mergeEngine = MergeEngineFactory.newInstance(connection.getRuntimeContext().getDatabaseType(), connection.getRuntimeContext().getRule(), sqlRouteResult, connection.getRuntimeContext().getMetaData().getRelationMetas(), statementExecutor.executeQuery());//获取归并结果result = getResultSet(mergeEngine);} finally {currentResultSet = null;}currentResultSet = result;return result;
}
这个方法中有几个子方法值得具体展开一下,首先是 shard 方法:
private void shard(final String sql) {//从 Connection 中获取 ShardingRuntimeContext 上下文ShardingRuntimeContext runtimeContext = connection.getRuntimeContext();//创建 SimpleQueryShardingEngineSimpleQueryShardingEngine shardingEngine = new SimpleQueryShardingEngine(runtimeContext.getRule(), runtimeContext.getProps(), runtimeContext.getMetaData(), runtimeContext.getParseEngine());//执行分片路由并获取路由结果sqlRouteResult = shardingEngine.shard(sql, Collections.emptyList());
}
这段代码就是路由引擎的入口,我们创建了 SimpleQueryShardingEngine,并调用它的 shard 方法获取路由结果对象 SQLRouteResult。
然后我们来看 initStatementExecutor 方法,如下所示:
private void initStatementExecutor() throws SQLException {statementExecutor.init(sqlRouteResult);replayMethodForStatements();
}
这里通过路由结果对象 SQLRouteResult 对 statementExecutor 进行了初始化,然后执行了一个 replayMethodForStatements 方法:
private void replayMethodForStatements() {for (Statement each : statementExecutor.getStatements()) {replayMethodsInvocation(each);}
}
该方法实际上就是调用了基于反射的 replayMethodsInvocation 方法,然后这个replayMethodsInvocation 方法会针对 statementExecutor 中所有 Statement的 SQL 操作执行目标方法。
最后,我们通过执行 statementExecutor.executeQuery() 方法获取 SQL 执行的结果,并用这个结果来创建归并引擎 MergeEngine,并通过归并引擎 MergeEngine 获取最终的执行结果。
归并引擎是 ShardingSphere 中与 SQL 解析引擎、路由引擎以及执行引擎并列的一个引擎,我们在下一课时中就会开始介绍这块内容,这里先不做具体展开。
以 ShardingStatement 中的其中一个 executeUpdate 方法为例,可以看到它的执行流程也与前面的 executeQuery 方法非常类似:
@Override
public int executeUpdate(final String sql) throws SQLException {try {//清除 StatementExecutor 中的相关变量clearPrevious();//执行路由引擎,获取路由结果shard(sql);//初始化 StatementExecutorinitStatementExecutor();return statementExecutor.executeUpdate();} finally {currentResultSet = null;}
}
当然,对于 Update 操作而言,不需要通过归并引擎做结果的归并。
ShardingPreparedStatement
我们接着来看 ShardingPreparedStatement 类,这个类的变量也基本都是前面介绍过的对象:
private final ShardingConnection connection;
private final String sql;
private final PreparedQueryShardingEngine shardingEngine;
private final PreparedStatementExecutor preparedStatementExecutor;
private final BatchPreparedStatementExecutor batchPreparedStatementExecutor;
private SQLRouteResult sqlRouteResult;
private ResultSet currentResultSet;
这里的 ShardingEngine、PreparedStatementExecutor 和 BatchPreparedStatementExecutor 对象的创建过程都发生在 ShardingPreparedStatement 的构造函数中。
然后我们来看它的代表性方法 ExecuteQuery,如下所示:
@Override
public ResultSet executeQuery() throws SQLException {ResultSet result;try {clearPrevious();shard();initPreparedStatementExecutor();MergeEngine mergeEngine = MergeEngineFactory.newInstance(connection.getRuntimeContext().getDatabaseType(), connection.getRuntimeContext().getRule(), sqlRouteResult, connection.getRuntimeContext().getMetaData().getRelationMetas(), preparedStatementExecutor.executeQuery());result = getResultSet(mergeEngine);} finally {clearBatch();}currentResultSet = result;return result;
}
这里我们没加注释,但也应该理解这一方法的执行流程,因为该方法的风格与 ShardingStatement 中的同名方法非常一致。
关于 ShardingPreparedStatement 就没有太多可以介绍的内容了,我们接着来看它的父类AbstractShardingPreparedStatementAdapter 类,看到该类持有一个 SetParameterMethodInvocation 的列表,以及一个参数列表:
private final List<SetParameterMethodInvocation> setParameterMethodInvocations = new LinkedList<>();
private final List<Object> parameters = new ArrayList<>();
这里的 SetParameterMethodInvocation 类直接集成了介绍 ShardingConnection 时提到的 JdbcMethodInvocation 类:
public final class SetParameterMethodInvocation extends JdbcMethodInvocation {@Getterprivate final int index;@Getterprivate final Object value;public SetParameterMethodInvocation(final Method method, final Object[] arguments, final Object value) {super(method, arguments);this.index = (int) arguments[0];this.value = value;}public void changeValueArgument(final Object value) {getArguments()[1] = value;}
}
对于 ShardingPreparedStatement 而言,这个类的作用是在 JdbcMethodInvocation 中所保存的方法和参数的基础上,添加了 SQL 执行过程中所需要的参数信息。
所以它的 replaySetParameter 方法就变成了如下的风格:
protected final void replaySetParameter(final PreparedStatement preparedStatement, final List<Object> parameters) {setParameterMethodInvocations.clear();//添加参数信息addParameters(parameters);for (SetParameterMethodInvocation each : setParameterMethodInvocations) {each.invoke(preparedStatement);}
}
关于 AbstractShardingPreparedStatementAdapter 还需要注意的是它的类层结构,如下图所示,可以看到 AbstractShardingPreparedStatementAdapter 继承了 AbstractUnsupportedOperationPreparedStatement 类;而 AbstractUnsupportedOperationPreparedStatement 却又继承了 AbstractStatementAdapter 类并实现了 PreparedStatement:
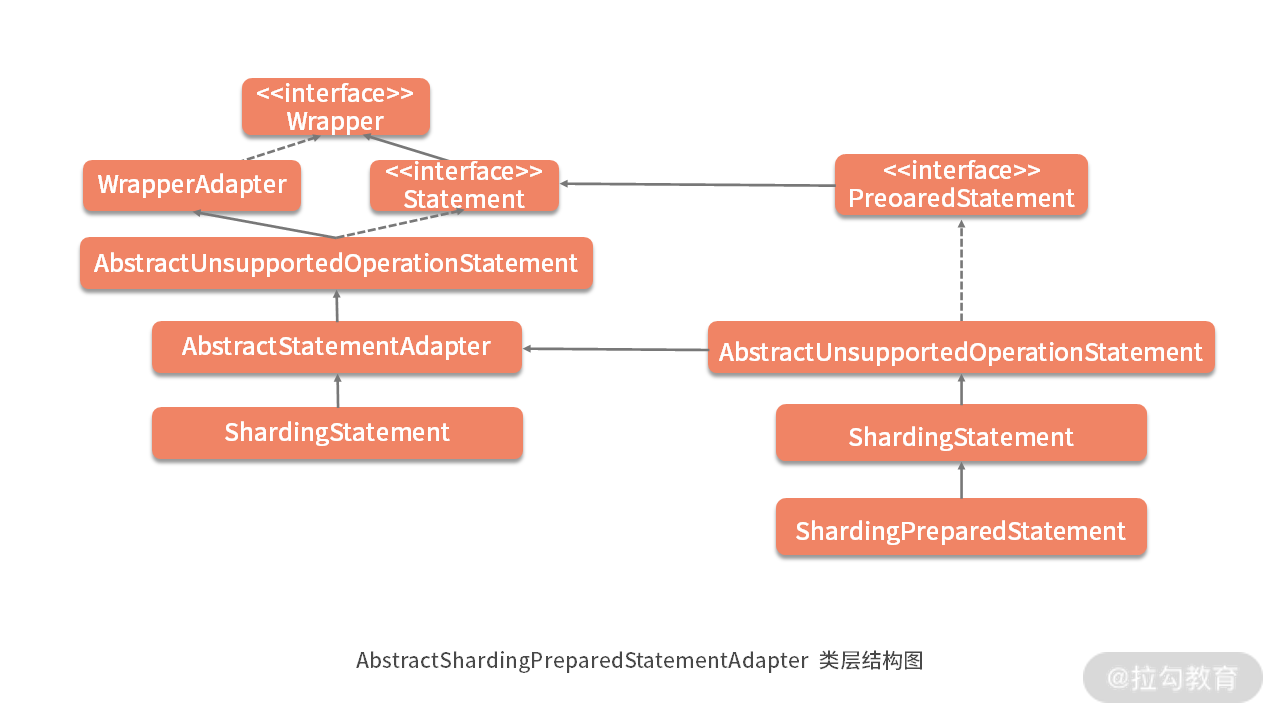
形成这种类层结构的原因在于,PreparedStatement 本来就是在 Statement 的基础上添加了各种参数设置功能,换句话说,Statement 的功能 PreparedStatement 都应该有。
所以一方面 AbstractStatementAdapter 提供了所有 Statement 的功能;另一方面,AbstractShardingPreparedStatementAdapter 首先把 AbstractStatementAdapter 所有的功能继承过来,但它自身可能有一些无法实现的关于 PreparedStatement 的功能,所以同样提供了 AbstractUnsupportedOperationPreparedStatement 类,并被最终的 AbstractShardingPreparedStatementAdapter 适配器类所继承。
这样就形成了如上图所示的复杂类层结构。
ShardingConnection
介绍完 ShardingStatement 和 ShardingPreparedStatement 之后,我们来关注使用它们的具体应用场景,这也是 ShardingSphere 执行引擎的最后一部分内容。
通过查看调用关系,我们发现创建这两个类的入口都在 ShardingConnection 类中,该类包含了用于创建 ShardingStatement 的 createStatement 方法和用于创建 ShardingPreparedStatement 的 prepareStatement 方法,以及它们的各种重载方法:
@Override
public Statement createStatement(final int resultSetType, final int resultSetConcurrency, final int resultSetHoldability) {return new ShardingStatement(this, resultSetType, resultSetConcurrency, resultSetHoldability);}@Override
public PreparedStatement prepareStatement(final String sql, final int resultSetType, final int resultSetConcurrency, final int resultSetHoldability) throws SQLException {return new ShardingPreparedStatement(this, sql, resultSetType, resultSetConcurrency, resultSetHoldability);
}
同时,ShardingConnection 中包含了用于管理分布式事务的 ShardingTransactionManager。关于分布式事务的讨论不是今天的重点,我们后面会有专题来做详细展开。
但我们可以先看一下 commit 和 rollback 方法:
@Override
public void commit() throws SQLException {if (TransactionType.LOCAL == transactionType) {super.commit();} else {shardingTransactionManager.commit();}
}@Override
public void rollback() throws SQLException {if (TransactionType.LOCAL == transactionType) {super.rollback();} else {shardingTransactionManager.rollback();}
}
可以看到这两个方法的逻辑还是比较清晰的,即当事务类型为本地事务时直接调用 ShardingConnection 父类 AbstractConnectionAdapter 中的 commit 和 rollback 方法,这两个方法会调用真正的 connection 的相关方法。
以 commit 方法为例,我们可以看到 AbstractConnectionAdapter 中基于这一设计思想的实现过程:
@Override
public void commit() throws SQLException {forceExecuteTemplate.execute(cachedConnections.values(), new ForceExecuteCallback<Connection>() {@Overridepublic void execute(final Connection connection) throws SQLException {connection.commit();}});
}
ShardingDataSource
我们知道在 JDBC 规范中,可以通过 DataSource 获取 Connection 对象。ShardingSphere 完全兼容 JDBC 规范,所以 ShardingConnection 的创建过程应该也是在对应的 DataSource 中,这个 DataSource 就是ShardingDataSource。
ShardingDataSource 类比较简单,其构造函数如下所示:
public ShardingDataSource(final Map<String, DataSource> dataSourceMap, final ShardingRule shardingRule, final Properties props) throws SQLException {super(dataSourceMap);checkDataSourceType(dataSourceMap);runtimeContext = new ShardingRuntimeContext(dataSourceMap, shardingRule, props, getDatabaseType());
}
可以看到,ShardingRuntimeContext 这个上下文对象是在 ShardingDataSource 的构造函数中被创建的,而创建 ShardingConnection 的过程也很直接:
@Override
public final ShardingConnection getConnection() {return new ShardingConnection(getDataSourceMap(), runtimeContext, TransactionTypeHolder.get());
}
在 ShardingDataSource 的实现上,也同样采用的是装饰器模式,所以它的类层结构也与 ShardingConnection 的类似。在 ShardingDataSource 的父类 AbstractDataSourceAdapter 中,主要的工作是完成 DatabaseType 的创建,核心方法 createDatabaseType 如下所示:
private DatabaseType createDatabaseType(final DataSource dataSource) throws SQLException {if (dataSource instanceof AbstractDataSourceAdapter) {return ((AbstractDataSourceAdapter) dataSource).databaseType;}try (Connection connection = dataSource.getConnection()) {return DatabaseTypes.getDatabaseTypeByURL(connection.getMetaData().getURL());}
}
可以看到这里使用到了 DatabaseTypes 类,该类负责 DatabaseType 实例的动态管理。而在 ShardingSphere 中,DatabaseType 接口代表数据库类型:
public interface DatabaseType {//获取数据库名称String getName();//获取 JDBC URL 的前缀Collection<String> getJdbcUrlPrefixAlias();//获取数据源元数据DataSourceMetaData getDataSourceMetaData(String url, String username);
}
可以想象 ShardingSphere 中针对各种数据库提供了 DatabaseType 接口的实现类,其中以 MySQLDatabaseType 为例:
public final class MySQLDatabaseType implements DatabaseType {@Overridepublic String getName() {return "MySQL";}@Overridepublic Collection<String> getJdbcUrlPrefixAlias() {return Collections.singletonList("jdbc:mysqlx:");}@Overridepublic MySQLDataSourceMetaData getDataSourceMetaData(final String url, final String username) {return new MySQLDataSourceMetaData(url);}
}
上述代码中的 MySQLDataSourceMetaData 实现了 DataSourceMetaData 接口,并提供如下所示的对输入 url 的解析过程:
public MySQLDataSourceMetaData(final String url) {Matcher matcher = pattern.matcher(url);if (!matcher.find()) {throw new UnrecognizedDatabaseURLException(url, pattern.pattern());}hostName = matcher.group(4);port = Strings.isNullOrEmpty(matcher.group(5)) ? DEFAULT_PORT : Integer.valueOf(matcher.group(5));catalog = matcher.group(6);schema = null;
}
显然,DatabaseType 用于保存与特定数据库元数据相关的信息,ShardingSphere 还基于 SPI 机制实现对各种 DatabaseType 实例的动态管理。
最后,我们来到 ShardingDataSourceFactory 工厂类,该类负责 ShardingDataSource 的创建:
public final class ShardingDataSourceFactory {public static DataSource createDataSource(final Map<String, DataSource> dataSourceMap, final ShardingRuleConfiguration shardingRuleConfig, final Properties props) throws SQLException {return new ShardingDataSource(dataSourceMap, new ShardingRule(shardingRuleConfig, dataSourceMap.keySet()), props);}
}
我们在这里创建了 ShardingDataSource,同时发现 ShardingRule 的创建过程实际上也是在这里,通过传入的 ShardingRuleConfiguration 来构建一个新的 ShardingRule 对象。
一旦创建了 DataSource,我们就可以使用与 JDBC 规范完全兼容的 API,通过该 DataSource 完成各种 SQL 的执行。我们可以回顾 ShardingDataSourceFactory 的使用过程来加深对他的理解:
public DataSource dataSource() throws SQLException {//创建分片规则配置类ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();//创建分表规则配置类TableRuleConfiguration tableRuleConfig = new TableRuleConfiguration("user", "ds${0..1}.user${0..1}");//创建分布式主键生成配置类Properties properties = new Properties();result.setProperty("worker.id", "33");KeyGeneratorConfiguration keyGeneratorConfig = new KeyGeneratorConfiguration("SNOWFLAKE", "id", properties);result.setKeyGeneratorConfig(keyGeneratorConfig);shardingRuleConfig.getTableRuleConfigs().add(tableRuleConfig);//根据年龄分库,一共分为 2 个库shardingRuleConfig.setDefaultDatabaseShardingStrategyConfig(new InlineShardingStrategyConfiguration("sex", "ds${sex % 2}"));//根据用户 id 分表,一共分为 2 张表shardingRuleConfig.setDefaultTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("id", "user${id % 2}"));//通过工厂类创建具体的 DataSourcereturn ShardingDataSourceFactory.createDataSource(createDataSourceMap(), shardingRuleConfig, new Properties());
}
一旦获取了目标 DataSource 之后,我们就可以使用 JDBC 中的核心接口来执行传入的 SQL 语句:
List<User> getUsers(final String sql) throws SQLException {List<User> result = new LinkedList<>();try (Connection connection = dataSource.getConnection();PreparedStatement preparedStatement = connection.prepareStatement(sql);ResultSet resultSet = preparedStatement.executeQuery()) {while (resultSet.next()) {User user= new User();//省略设置 User 对象的赋值语句result.add(user);}}return result;
}
ShardingSphere 通过在准备阶段获取的连接模式,在执行阶段生成内存归并结果集或流式归并结果集,并将其传递至结果归并引擎,以进行下一步工作。
从源码解析到日常开发
基于适配器模式完成对 JDBC 规范的重写,是我们学习 ShardingSphere 框架非常重要的一个切入点,同样也是我们将这种模式应用到日常开发工作中的一个切入点。
适配器模式是作为两个不兼容的接口之间的桥梁。在业务系统中,我们经常会碰到需要与外部系统进行对接和集成的场景,这个时候为了保证内部系统的功能演进,能够独立于外部系统进行发展,一般都需要采用适配器模式完成两者之间的隔离。
当我们设计这种系统时,可以参考 JDBC 规范中的接口定义方式,以及 ShardingSphere 中基于这种接口定义方式,而完成适配的具体做法。
小结与预告
这是 ShardingSphere 执行引擎的最后一个课时,我们围绕执行引擎的上层组件,给出了以“ Sharding”作为前缀的各种 JDBC 规范中的核心接口实现类。
其中 ShardingStatement 和 ShardingPreparedStatement 直接依赖于上一课时介绍的 StatementExecutor 和 PreparedStatementExecutor;而 ShardingConnection 和 ShardingDataSource 则为我们使用执行引擎提供了入口。
这里给你留一道思考题:ShardingSphere 中,AbstractShardingPreparedStatementAdapter 的类层结构为什么会比 AbstractStatementAdapter 复杂很多?欢迎你在留言区与大家讨论,我将逐一点评解答。
现在,我们已经通过执行引擎获取了来自不同数据源的结果数据,对于查询语句而言,我们通常都需要对这些结果数据进行归并才能返回给客户端。在接下来的内容中,就让我们来分析一下 ShardingSphere 的归并引擎。
24 归并引擎:如何理解数据归并的类型以及简单归并策略的实现过程?
在上一课时,我们提到在 ShardingStatement 和 ShardingPreparedStatement 中,执行 executeQuery 或 executeUpdate 方法时会使用到归并引擎 MergeEngine:
//调用归并引擎
MergeEngine mergeEngine = MergeEngineFactory.newInstance(connection.getRuntimeContext().getDatabaseType(), connection.getRuntimeContext().getRule(), sqlRouteResult, connection.getRuntimeContext().getMetaData().getRelationMetas(), statementExecutor.executeQuery());
//获取归并结果
result = getResultSet(mergeEngine);
在 ShardingSphere 整个分片机制的结构中,归并引擎是执行引擎后的下一环,也是整个数据分片引擎的最后一环。
在今天以及下一课时中,我将带领大家对 ShardingSphere 中的归并引擎做详细的展开,让我们先从归并这一基本概念说起。
归并与归并引擎
我们知道,在分库分表环境下,一句逻辑 SQL 会最终解析成多条真正的 SQL,并被路由到不同的数据库中进行执行,每个数据库都可能返回最终结果中的一部分数据。
这样我们就会碰到一个问题,即如何把这些来自不同数据库的部分数据组合成最终结果呢?这就需要引入归并的概念。
1.归并的分类及其实现方案
所谓归并,就是将从各个数据节点获取的多数据结果集,通过一定的策略组合成为一个结果集并正确的返回给请求客户端的过程。
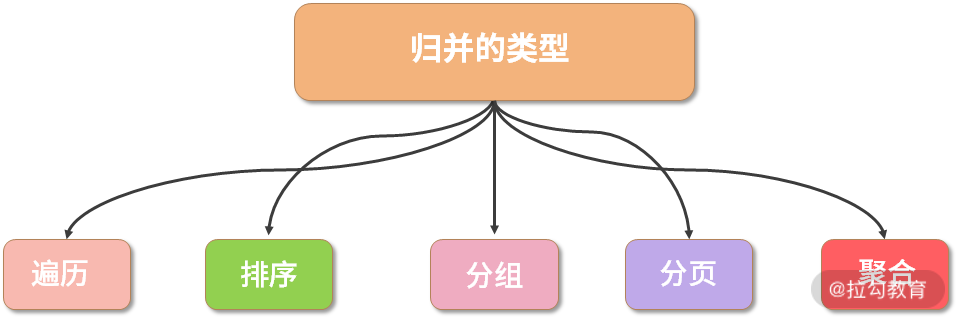
按照不同的 SQL 类型以及应用场景划分,归并的类型可以分为遍历、排序、分组、分页和聚合 5 种类型,这 5 种类型是组合而非互斥的关系。
其中遍历归并是最简单的归并,而排序归并是最常用地归并,在下文我会对两者分别详细介绍。
归并的五大类型
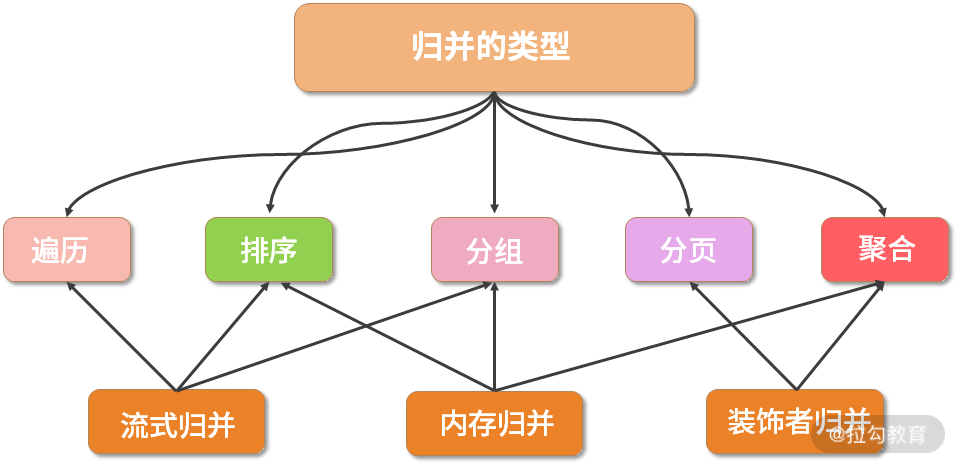
按照归并实现的结构划分,ShardingSphere 中又存在流式归并、内存归并和装饰者归并这三种归并方案。
- 所谓的流式归并,类似于 JDBC 中从 ResultSet 获取结果的处理方式,也就是说通过逐条获取的方式返回正确的单条数据;
- 内存归并的思路则不同,是将结果集的所有数据先存储在内存中,通过统一的计算之后,再将其封装成为逐条访问的数据结果集进行返回。
- 最后的装饰者归并是指,通过装饰器模式对所有的结果集进行归并,并进行统一的功能增强,类似于改写引擎中 SQLRewriteContextDecorator 对 SQLRewriteContext 进行装饰的过程。
显然,流式归并和内存归并是互斥的,装饰者归并可以在流式归并和内存归并之上做进一步的处理。
归并方案与归并类型之间同样存在一定的关联关系,其中遍历、排序以及流式分组都属于流式归并的一种,内存归并可以作用于统一的分组、排序以及聚合,而装饰者归并有分页归并和聚合归并这 2 种类型,它们之间的对应关系如下图所示:
归并类型与归并方案之间的对应关系图
2.归并引擎
讲完概念回到代码,我们首先来到 shardingsphere-merge 代码工程中的 MergeEngine 接口:
public interface MergeEngine {//执行归并MergedResult merge() throws SQLException;
}
可以看到 MergeEngine 接口非常简单,只有一个 merge 方法。在 ShardingSphere 中,该接口存在五个实现类,其类层结构如下所示:
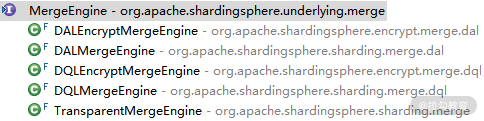
MergeEngine 类层结构图
从命名上看,可以看到名称中带有“Encrypt”的两个 MergeEngine 与数据脱敏相关,放在后续专题中再做讲解,其余的三个我们会先做一些分析。
在此之前,我们还要来关注一下代表归并结果的 MergedResult 接口:
public interface MergedResult {boolean next() throws SQLException;Object getValue(int columnIndex, Class<?> type) throws SQLException;Object getCalendarValue(int columnIndex, Class<?> type, Calendar calendar) throws SQLException;InputStream getInputStream(int columnIndex, String type) throws SQLException;boolean wasNull() throws SQLException;
}
可以看到 MergedResult 与执行引擎中的 QueryResult 非常相似,只是少了几个方法。理解了归并引擎的定义以及归并结果的表现形式之后,我们来分析创建 MergeEngine 的过程,前面已经看到这实际上是依赖于工厂类 MergeEngineFactory,其实现过程如下所示:
public static MergeEngine newInstance(final DatabaseType databaseType, final ShardingRule shardingRule,final SQLRouteResult routeResult, final RelationMetas relationMetas, final List<QueryResult> queryResults) {//如果是查询语句,就创建一个 DQLMergeEngineif (routeResult.getSqlStatementContext() instanceof SelectSQLStatementContext) {return new DQLMergeEngine(databaseType, (SelectSQLStatementContext) routeResult.getSqlStatementContext(), queryResults);} //如果是数据库管理语句,就创建一个 DALMergeEngineif (routeResult.getSqlStatementContext().getSqlStatement() instanceof DALStatement) {return new DALMergeEngine(shardingRule, queryResults, routeResult.getSqlStatementContext(), relationMetas);}return new TransparentMergeEngine(queryResults);
}
这个 newInstance 方法的参数值得关注一下,这些参数我们都很眼熟,包括数据库类型 DatabaseType、分片规则 ShardingRule、路由结果 SQLRouteResult、执行结果列表 List 等。
然后,我们看到代码逻辑会根据 SQLRouteResult 中 SqlStatementContext 的不同类型返回不同类型的 MergeEngine,即如果是 SelectSQLStatementContext 则返回用于查询的 DQLMergeEngine;而如果 SQLStatement 是一种执行数据库管理语句的 DALStatement,则返回 DALMergeEngine;如果都不是,则直接返回 TransparentMergeEngine。
对于归并而言,显然 DQLMergeEngine 是最重要的一种引擎类型,我们重点对它进行展开,
它的 merge 方法如下所示:
public MergedResult merge() throws SQLException {//如果结果集数量为 1if (1 == queryResults.size()) {return new IteratorStreamMergedResult(queryResults);}Map<String, Integer> columnLabelIndexMap = getColumnLabelIndexMap(queryResults.get(0));selectSQLStatementContext.setIndexes(columnLabelIndexMap);//如果结果集数量大于 1,则构建不同的归并方案return decorate(build(columnLabelIndexMap));
}
这里先出现了一个判断,即当查询结果集数量为 1 时,我们只需调用遍历结果集进行归并即可,这种类型就属于遍历归并。遍历归并是我们将要介绍的第一种归并类型,也是所有归并类型中最为简单的一种。
如果结果集不是只有一个,那就意味了需要进行合并,我们会通过如下所示的 build 方法根据不同的条件构建不同的 MergedResult 并返回:
private MergedResult build(final Map<String, Integer> columnLabelIndexMap) throws SQLException {//查询语句中分组语句或者聚合函数不为空,则执行分组归并if (isNeedProcessGroupBy()) {return getGroupByMergedResult(columnLabelIndexMap);} //如果聚合中存在 Distinct 列,设置分组 Context 并执行分组归并if (isNeedProcessDistinctRow()) {setGroupByForDistinctRow();return getGroupByMergedResult(columnLabelIndexMap);} //排序语句不为空,则执行排序结果集归并if (isNeedProcessOrderBy()) {return new OrderByStreamMergedResult(queryResults, selectSQLStatementContext.getOrderByContext().getItems());} //如果都不满足归并提交,则执行遍历结果集归并return new IteratorStreamMergedResult(queryResults);
}
可以看到,这里涉及了分组归并和排序归并这两大类归并策略。然后,我们还看到有一个构建在上述 build 方法之上的 decorate 方法。这个 decorate 方法体现的就是一种装饰者归并,用于针对不同的数据库方言完成分页归并操作,我们会在下一课时中对这个方法做详细展开。
这样,我们把 ShardingSphere 中的各种归并类型通过归并引擎 MergeEngine 串联了起来,接下来的时间就来讨论各种归并类型的具体实现机制。
让我们先来看遍历归并。
最简单的归并:遍历归并
遍历归并是最为简单的归并方式,我们只需将多个数据结果集合并为一个单向链表就可以了。遍历数据的操作,就相当于是在遍历一个单向列表。而在实现上,这个遍历结果集的表现形式就是一个 IteratorStreamMergedResult 类,该类又继承自 StreamMergedResult,代表的是一种流式合并结果。
IteratorStreamMergedResult 的 next 方法如下所示:
@Override
public boolean next() throws SQLException {if (getCurrentQueryResult().next()) {return true;}if (!queryResults.hasNext()) {return false;}//流式获取结果并设置为当前的 QueryResultsetCurrentQueryResult(queryResults.next());boolean hasNext = getCurrentQueryResult().next();if (hasNext) {return true;}while (!hasNext && queryResults.hasNext()) {setCurrentQueryResult(queryResults.next());hasNext = getCurrentQueryResult().next();}return hasNext;
}
它的 getValue 方法在父类 StreamMergedResult,如下所示:
@Override
public Object getValue(final int columnIndex, final Class<?> type) throws SQLException {Object result = getCurrentQueryResult().getValue(columnIndex, type);wasNull = getCurrentQueryResult().wasNull();return result;
}
这里同样也是通过 getCurrentQueryResult 方法流式获取当前的数据项,进而获取具体的值。
最常用的归并:排序归并
我们将要介绍的第二个归并类型是排序归并,它的返回结果是一个 OrderByStreamMergedResult,该类同样继承了用于流式归并的 StreamMergedResult 类。
在介绍 OrderByStreamMergedResult 前,我们可以先想象一下排序归并的场景。
当在多个数据库中执行某一条 SQL 语句时,我们可以做到在每个库的内部完成排序功能。也就是说,我们的执行结果中保存着内部排好序的多个 QueryResult,然后要做的就是把它们放在一个地方然后进行全局的排序。因为每个 QueryResult 内容已经是有序的,因此只需要将 QueryResult 中当前游标指向的数据值进行排序即可,相当于对多个有序的数组进行排序。
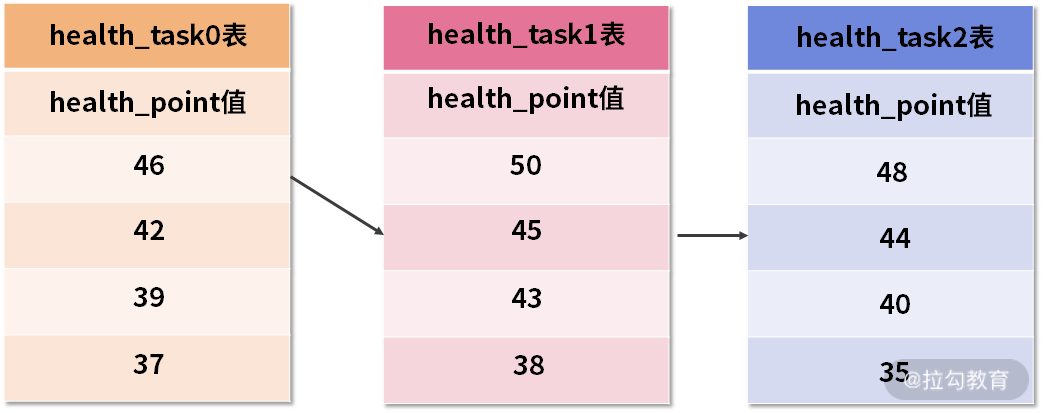
这个过程有点抽象,我们通过如下的示意图进行进一步说明。假设,在我们的健康任务 health_task 表中,存在一个健康点数字段 health_point,用于表示完成这个健康任务能够获取的健康分数。
然后,我们需要根据这个 health_point 进行排序归并,初始的数据效果如下图所示:
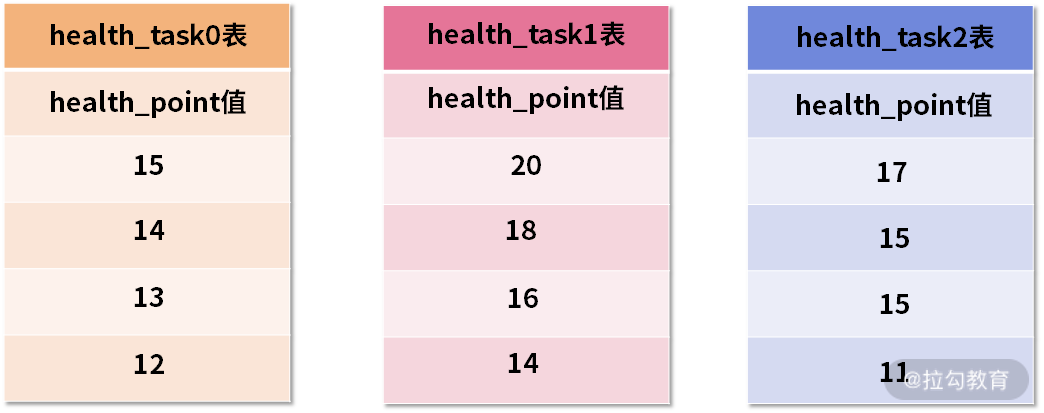
三张 health_task 表中的初始数据
上图中展示了 3 张表返回的数据结果集,每个数据结果集都已经根据 health_point 字段进行了排序,但是 3 个数据结果集之间是无序的。排序归并的做法就是将 3 个数据结果集的当前游标指向的数据值进行排序,并放入到一个排序好的队列中。
在上图中可以看到 health_task0 的第一个 health_point 最小,health_task1 的第一个 health_point 最大,health_task2 的第一个 health_point 次之,因此队列中应该按照 health_task1,health_task2 和 health_task0 的方式排序队列,效果如下:
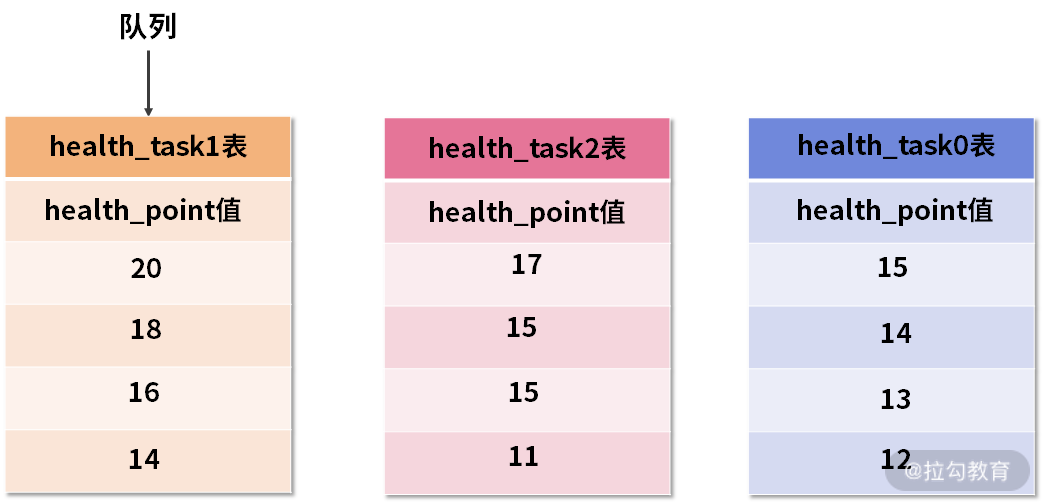 队列中已排序的三张 health_task 表
队列中已排序的三张 health_task 表
在 OrderByStreamMergedResult 中,我们可以看到如下所示的队列定义,用到了 JDK 中的 Queue 接口:
private final Queue<OrderByValue> orderByValuesQueue;
而在 OrderByStreamMergedResult 的构造函数中,我们进一步看到 orderByValuesQueue 实际上是一个 PriorityQueue:
public OrderByStreamMergedResult(final List<QueryResult> queryResults, final Collection<OrderByItem> orderByItems) throws SQLException {this.orderByItems = orderByItems;//构建 PriorityQueuethis.orderByValuesQueue = new PriorityQueue<>(queryResults.size());//初始化 PriorityQueueorderResultSetsToQueue(queryResults);isFirstNext = true;
}
讲到这里,有必要对 JDK 中的 PriorityQueue 做一下简单介绍。对于 PriorityQueue 而言,它的特性是可以对其中所包含的元素进行自动排序,既可以存放基本数据类型的包装类,也可以支持自定义类。对于基本数据类型的包装器类,优先级队列中元素默认排列顺序是升序排列,而对于自己定义的类来说,需要定义定制化的比较器。
PriorityQueue 的常用方法如下所示:
- peek():返回队首元素
- poll():返回队首元素,并且将队首元素弹出队列
- offer():添加元素
- size():返回队列元素个数
- isEmpty():判断队列是否为空
了解了 PriorityQueue 的功能特性之后,我们来看一下如何基于一个 QueryResult 列表对队列进行初始化,orderResultSetsToQueue 方法如下所示:
private void orderResultSetsToQueue(final List<QueryResult> queryResults) throws SQLException {for (QueryResult each : queryResults) {//构建 OrderByValueOrderByValue orderByValue = new OrderByValue(each, orderByItems);if (orderByValue.next()) {//添加 OrderByValue 到队列中orderByValuesQueue.offer(orderByValue);}}setCurrentQueryResult(orderByValuesQueue.isEmpty() ? queryResults.get(0) : orderByValuesQueue.peek().getQueryResult());
}
这里基于 QueryResult 构建了 OrderByValue 对象,并通过该对象的 next 方法判断是否需要将其添加到 PriorityQueue 中。
我们看到这里调用了 PriorityQueue 的 offer 方法将特定元素插入到优先级队列中。
当将所有的 OrderByValue 添加到 PriorityQueue 之后,OrderByStreamMergedResult 通过父类 StreamMergedResult 的 setCurrentQueryResult 方法将 PriorityQueue 中的第一个元素作为当前的查询结果,这时候 PriorityQueue 指向的就是全局排序好的第一个元素,也就是上图中的 50。
显然,对于 PriorityQueue 而言,这里新创建的 OrderByValue 就是自定义类,所以需要实现自定义的比较器。我们在 OrderByValue 类中看到它实现了 Java 的 Comparable 接口,compareTo 方法实现如下,针对每个排序项 OrderByItem 进行值的比对:
@Override
public int compareTo(final OrderByValue o) {int i = 0;for (OrderByItem each : orderByItems) {int result = CompareUtil.compareTo(orderValues.get(i), o.orderValues.get(i), each.getSegment().getOrderDirection(),each.getSegment().getNullOrderDirection(), orderValuesCaseSensitive.get(i));if (0 != result) {return result;}i++;}return 0;
}
根据前面示意图中的结果,当使用 PriorityQueue 每次获取下一条数据时,我们只需将队列顶端结果集的游标下移,并根据新游标重新进入优先级队列并找到自己的位置即可。
这个步骤体现在如下所示的 next 方法中:
@Override
public boolean next() throws SQLException {if (orderByValuesQueue.isEmpty()) {return false;}if (isFirstNext) {isFirstNext = false;return true;}//获取 PriorityQueue 中的第一个元素,并弹出该元素OrderByValue firstOrderByValue = orderByValuesQueue.poll();//将游标指向 firstOrderByValue 的下一个元素,并重新插入到 PriorityQueue 中,这会促使 PriorityQueue 进行自动的重排序if (firstOrderByValue.next()) {orderByValuesQueue.offer(firstOrderByValue);}if (orderByValuesQueue.isEmpty()) {return false;}//将当前结果集指向 PriorityQueue 的第一个元素setCurrentQueryResult(orderByValuesQueue.peek().getQueryResult());return true;
}
这个过程同样需要用一系列图来进行解释。当进行第一次 next 调用时,排在队列首位的 health_task1 将会被弹出队列,并且将当前游标指向的数据值 50 返回。同时,我们还会将游标下移一位之后,重新把 health_task1 放入优先级队列。而优先级队列也会根据 health_task1 的当前数据结果集指向游标的数据值 45 进行排序,根据当前数值,health_task1 将会被排列在队列的第三位。如下所示:
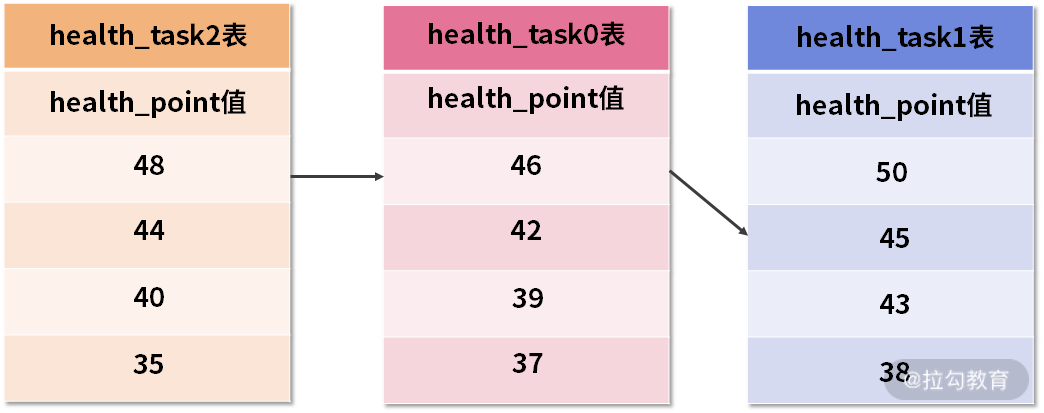
第一次 next 之后的优先级队列中的三张 health_task 表
之前队列中排名第二的 health_task2 的数据结果集则自动排在了队列首位。而在进行第二次 next 时,只需要将目前排列在队列首位的 health_task2 弹出队列,并且将其数据结果集游标指向的值返回。当然,对于 health_task2 而言,我们同样下移游标,并继续将它加入优先级队列中,以此类推。
第二次 next 之后的优先级队列中的三张 health_task 表
可以看到,基于上述的设计和实现方法,对于每个数据结果集内部数据有序、而多数据结果集整体无序的情况下,我们无需将所有的数据都加载至内存即可进行排序。
因此,ShardingSphere 在这里使用的是流式归并的方式,充分提高了归并效率。
从源码解析到日常开发
队列是我们常用的一种数据结构,而对于需要进行数据比对和排序的场景下,今天介绍的优先级队列非常有用。基于自身所具备的排序特性,处理类似 ShardingSphere 中全局性的排序场景,优先级队列的实现方案优雅而高效,可以根据需要应用到在日常开发过程中。
小结与预告
今天的内容关注于 ShardingSphere 中的归并引擎,归并是分库分表环境下处理 SQL 执行结果的最终环节。我们抽象了 ShardingSphere 的几种常见的归并类型以及实现方案。同时,给出了其中最简单的遍历归并和最常用的排序归并的设计思想和实现细节。
这里给你留一道思考题:ShardingSphere 中,分片数据基于 JDK 中的哪种数据结构完成排序的?
在下一课时中,我们将继续介绍 ShardingSphere 归并引擎中剩余的几种归并类型,包括分组归并、聚合归并以及分页归并。
25 归并引擎:如何理解流式归并和内存归并在复杂归并场景下的应用方式?
承接上一课时的内容,今天我们继续介绍 ShardingSphere 中剩余的归并策略,包括分组归并、聚合归并和分页归并。
- 其中分组归并是最复杂的一种归并类型;
- 聚合归并是在分组归并的基础上追加的归并;
- 分页归并则是典型的通过装饰器模式实现的归并类型。
最复杂的归并:分组归并
在 ShardingSphere 的所有归并机制中,分组归并的情况最为复杂,它同样可以分为流式分组归并和内存分组归并两种实现方案。
其中,流式分组归并要求 SQL 的排序项与分组项的字段,以及排序类型必须保持一致,否则只能通过内存归并才能保证其数据的正确性。
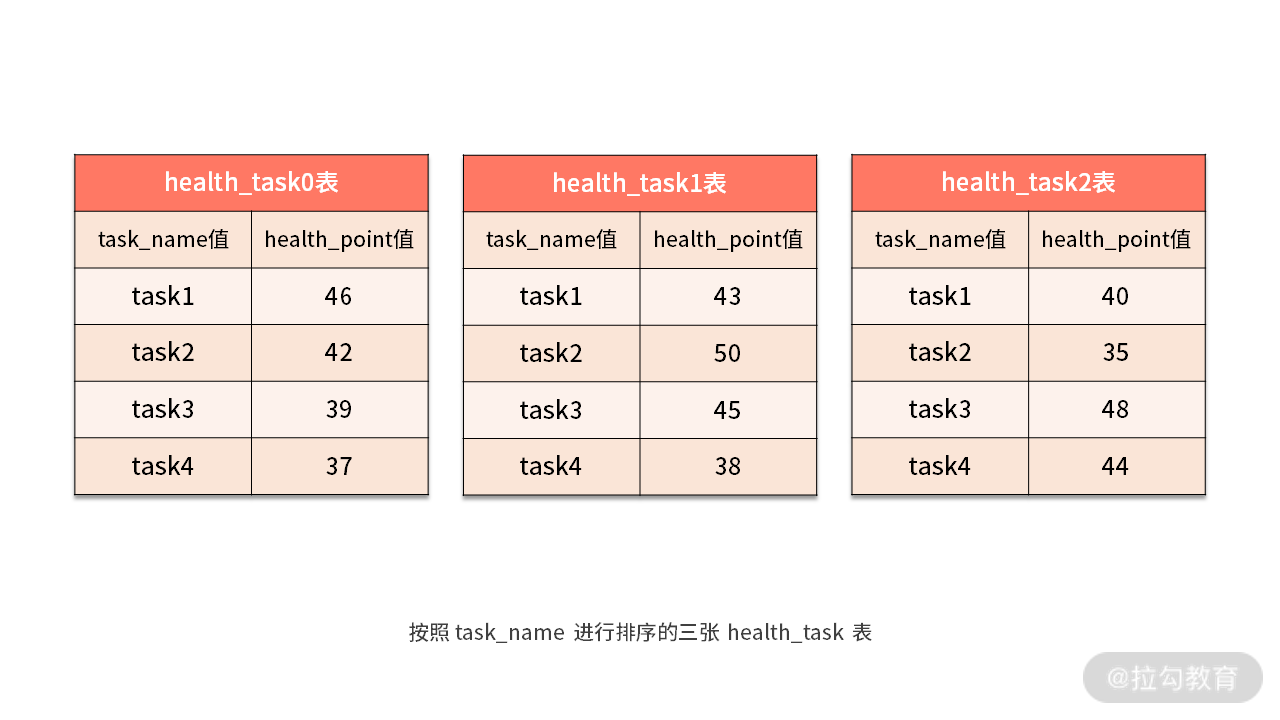
因为分组归并非常复杂,所以,我们还是继续通过一个示例然后结合源码,给大家介绍分组归并的实现过程,先看这样一句 SQL:
SELECT task_name, SUM(health_point) FROM health_task GROUP BY task_name ORDER BY task_name;
显然,上述 SQL 的分组项与排序项完全一致,都是用到了 task_name 列,所以取得的数据是连续的。这样,分组所需的数据全部存在于各个数据结果集的当前游标所指向的数据值,因此可以采用流式归并。
如下图所示,我们在每个 health_task 结果集中,根据 task_name 进行了排序:
我们先来看一些代码的初始化工作,回到 DQLMergeEngine,找到用于分组归并的 getGroupByMergedResult 方法,如下所示:
private MergedResult getGroupByMergedResult(final Map<String, Integer> columnLabelIndexMap) throws SQLException {return selectSQLStatementContext.isSameGroupByAndOrderByItems()? new GroupByStreamMergedResult(columnLabelIndexMap, queryResults, selectSQLStatementContext): new GroupByMemoryMergedResult(queryResults, selectSQLStatementContext);
}
可以看到这里有一个 isSameGroupByAndOrderByItems 判断,该判断就是用来明确分组条件和排序条件是否相同。根据前面的分析,如果分组条件和排序条件相同,则执行流式分组归并方式 GroupByStreamMergedResult,否则使用内存分组归并 GroupByMemoryMergedResult。
我们以流式归并为例来介绍 ShardingSphere 中的分组归并实现机制,在对代码进行详细展开之前,我们还是需要先从感性认识上明确流式分组归并具体要执行的步骤。这里仍然使用一系列的示意图来进行说明。
现在,我们已经在每个 health_task 结果集中根据 task_name 进行了排序,所以 health_task0、health_task1、health_task2 中的“task1”都排到了最前面,也就是队列的第一个元素。
- 第一次 next 调用
这样当进行第一次 next 调用时,排在队列首位的 health_task0 将会被弹出队列,并且将分组值同为“task1”其他结果集中的数据一同弹出队列。然后,在获取了所有的 task_name 为“task1”的 health_point 之后,我们进行了累加操作。
所以在第一次 next 调用结束后,取出的结果集是 “task1” 的分数总和,即 46+43+40=129,如下图所示:
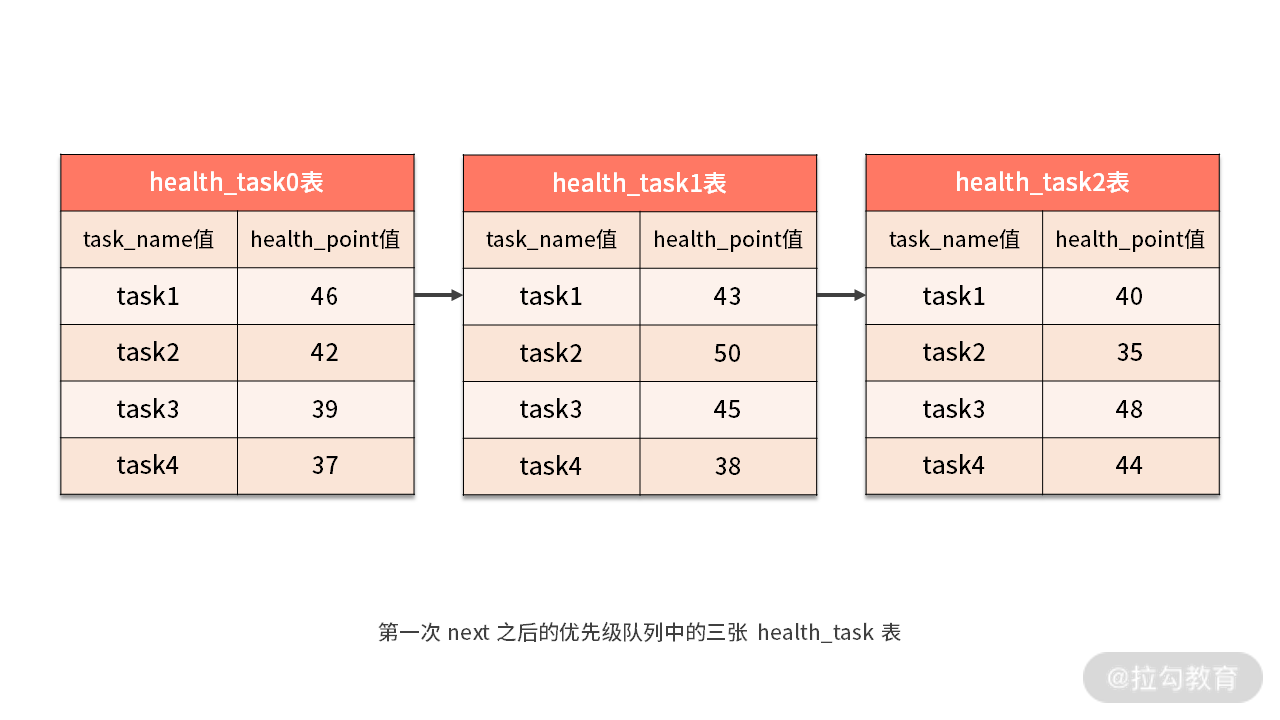
- 第二次 next 调用
与此同时,所有数据结果集中的游标都将下移至“task1”的下一个不同的数据值,并且根据数据结果集当前游标指向的值进行重排序。在上图中,我们看到第二个“task2”同时存在于 health_task0 和 health_task1 中,这样包含名字为“task2”的相关数据结果集则排在的队列的前列。
当再次执行 next 调用时,我们获取了 “task2” 的分数并进行了累加,即 42+50=92,如下图中所示:
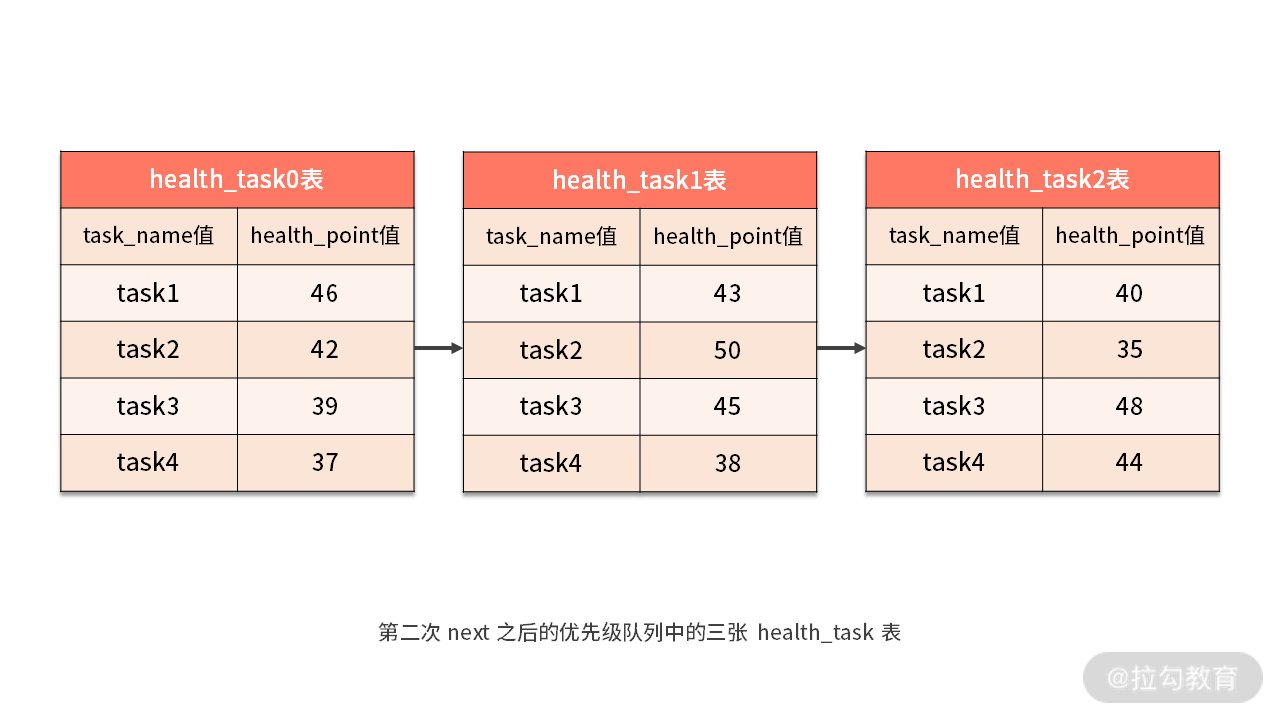
对于接下去的 next 方法,我们也是采用类似的处理机制,分别找到这三种 health_task 表中的“task3”“task4”“task5”等数据记录,并依次类推。
有了对流式分组归并的感性认识之后,让我们回到源代码。我们先来看代表结果的 GroupByStreamMergedResult,我们发现 GroupByStreamMergedResult 实际上是继承了上一课时中介绍的用于排序归并的 OrderByStreamMergedResult,因此也用到了前面介绍的优先级队列 PriorityQueue 和 OrderByValue 对象。
但考虑到需要保存一些中间变量以管理运行时状态,GroupByStreamMergedResult 中添加了如下所示的代表当前结果记录的 currentRow 和代表当前分组值的 currentGroupByValues 变量:
private final List<Object> currentRow;
private List<?> currentGroupByValues;
然后,我们来看一下 GroupByStreamMergedResult 的构造函数,如下所示:
public GroupByStreamMergedResult(final Map<String, Integer> labelAndIndexMap, final List<QueryResult> queryResults, final SelectSQLStatementContext selectSQLStatementContext) throws SQLException {super(queryResults, selectSQLStatementContext.getOrderByContext().getItems());this.selectSQLStatementContext = selectSQLStatementContext;currentRow = new ArrayList<>(labelAndIndexMap.size()); //如果优先级队列不为空,就将队列中第一个元素的分组值赋值给 currentGroupByValues 变量currentGroupByValues = getOrderByValuesQueue().isEmpty()? Collections.emptyList() : new GroupByValue(getCurrentQueryResult(), selectSQLStatementContext.getGroupByContext().getItems()).getGroupValues();
}
可以看到这里使用到了一个 GroupByValue 对象用于保存分组值,顾名思义,该对象的作用就是从结果集 QueryResult 中计算每个分组条件的值,如下所示:
public final class GroupByValue {private final List<?> groupValues;public GroupByValue(final QueryResult queryResult, final Collection<OrderByItem> groupByItems) throws SQLException {groupValues = getGroupByValues(queryResult, groupByItems);}private List<?> getGroupByValues(final QueryResult queryResult, final Collection<OrderByItem> groupByItems) throws SQLException {List<Object> result = new ArrayList<>(groupByItems.size());for (OrderByItem each : groupByItems) {//从结果集 QueryResult 中获得每个分组条件的值result.add(queryResult.getValue(each.getIndex(), Object.class));}return result;}
}
接下来,我们来看 GroupByStreamMergedResult 中的核心方法,即如下所示的 next 方法:
Override
public boolean next() throws SQLException {// 清除当前结果记录currentRow.clear();if (getOrderByValuesQueue().isEmpty()) {return false;}if (isFirstNext()) {super.next();}//顺序合并相同分组条件的记录if (aggregateCurrentGroupByRowAndNext()) {// 生成下一条结果记录分组值currentGroupByValues = new GroupByValue(getCurrentQueryResult(), selectSQLStatementContext.getGroupByContext().getItems()).getGroupValues();}return true;
}
这里出现了一个 aggregateCurrentGroupByRowAndNext 方法,从命名上可以看出该方法包含了分组聚合处理的核心处理逻辑,我们来看一下该方法的具体实现过程:
private boolean aggregateCurrentGroupByRowAndNext() throws SQLException {boolean result = false;//生成计算单元Map<AggregationProjection, AggregationUnit> aggregationUnitMap = Maps.toMap(//通过selectSQLStatementContext获取select语句所有聚合类型的项selectSQLStatementContext.getProjectionsContext().getAggregationProjections(), new Function<AggregationProjection, AggregationUnit>() {@Override//通过工厂方法获取具体的聚合单元public AggregationUnit apply(final AggregationProjection input) {return AggregationUnitFactory.create(input.getType(), input instanceof AggregationDistinctProjection);}});//循环顺序合并相同分组条件的记录while (currentGroupByValues.equals(new GroupByValue(getCurrentQueryResult(), selectSQLStatementContext.getGroupByContext().getItems()).getGroupValues())) {//计算聚合值aggregate(aggregationUnitMap);//缓存当前记录到结果记录cacheCurrentRow();//获取下一条记录,调用父类中的next方法从而使得currentResultSet指向下一个元素result = super.next();//如果值已经遍历完毕,则结束循环if (!result) {break;}}//设置当前记录的聚合字段结果setAggregationValueToCurrentRow(aggregationUnitMap);return result;
}
这段代码不是很长,但几乎每段代码都很重要。首先看到这里通过 AggregationUnitFactory 工厂创建了一个聚合单元对象 AggregationUnit,从这个工厂方法中可以看到 ShardingSphere 目前所支持的所有聚合操作,如下所示:
public static AggregationUnit create(final AggregationType type, final boolean isDistinct) {switch (type) {case MAX:return new ComparableAggregationUnit(false);case MIN:return new ComparableAggregationUnit(true);case SUM:return isDistinct ? new DistinctSumAggregationUnit() : new AccumulationAggregationUnit();case COUNT:return isDistinct ? new DistinctCountAggregationUnit() : new AccumulationAggregationUnit();case AVG:return isDistinct ? new DistinctAverageAggregationUnit() : new AverageAggregationUnit();default:throw new UnsupportedOperationException(type.name());}
}
显然,ShardingSphere 所支持的聚合操作包括 MAX、MIN、SUM、COUNT 以及 AVG 五种。其中的 MAX 和 MIN 聚合查询需要使用 ComparableAggregationUnit,SUM 和 COUNT 需要使用 AccumulationAggregationUnit,而 AVG 需要使用 AverageAggregationUnit。
这些类都实现了 AggregationUnit 接口,该接口定义如下:
public interface AggregationUnit {//合并聚合值void merge(List<Comparable<?>> values);//返回聚合值Comparable<?> getResult();
}
AggregationUnit 提供了合并聚合值和获取聚合值这两个方法。那么这个 AggregationUnit 是用来干什么的呢?这就要来看一下前面 aggregateCurrentGroupByRowAndNext 代码流程中所包含的 aggregate 方法,如下所示,注意这里的代码做了裁剪,只突出了 AggregationUnit 的作用。
private void aggregate(final Map<AggregationProjection, AggregationUnit> aggregationUnitMap) throws SQLException {for (Entry<AggregationProjection, AggregationUnit> entry : aggregationUnitMap.entrySet()) {...//计算聚合值entry.getValue().merge(values);}
}
显然,上述 aggregate 方法的核心就是调用 AggregationUnit 中的 merge 方法来完成聚合值的计算。针对今天课时中的示例 SQL,具体用到的 AggregationUnit 应该就是 AccumulationAggregationUnit。AccumulationAggregationUnit 类的实现也比较简单,可以想象它的 merge 方法就是将一系列传入的值进行求和,如下所示:
public final class AccumulationAggregationUnit implements AggregationUnit {private BigDecimal result;@Overridepublic void merge(final List<Comparable<?>> values) {if (null == values || null == values.get(0)) {return;}if (null == result) {result = new BigDecimal("0");}result = result.add(new BigDecimal(values.get(0).toString()));}@Overridepublic Comparable<?> getResult() {return result;}
}
至此,ShardingSphere 中用于分组流式合并的 GroupByStreamMergedResult 类的主体内容就介绍到这里。
下面我们继续来看由分组归并引申出来的聚合归并。
追加的归并:聚合归并
事实上,通过前面的分析,我们已经接触到了聚合归并相关的内容,我们也是站在分组归并的基础上讨论聚合归并。在这之前,我们需要明确聚合操作本身跟分组并没有关系,即除了分组的 SQL 之外,对不进行分组的 SQL 也可以使用聚合函数。另一方面,无论采用的是流式分组归并还是内存分组归并,对聚合函数的处理都是一致的。聚合归并可以理解为是在之前介绍的归并机制之上追加的一种归并能力。
MAX、MIN、SUM、COUNT,以及 AVG 这 5 种 ShardingSphere 所支持的聚合函数可以分成三大类聚合的场景,MAX 和 MIN 用于比较场景,SUM 和 COUNT 用于累加的场景,而剩下的 AVG 则用于求平均值的场景。
在 sharding-core-merge工程中,包含了对聚合引擎的实现代码。我们已经在前面介绍聚合归并时给出了 AggregationUnit 接口以及用于计算聚合值的实现类AccumulationAggregationUnit。对于其他 AggregationUnit 实现类而言,我们也不难想象其内部的实现方法。
例如,以 AverageAggregationUnit 为例,它的 merge 方法和 getResult 方法如下所示:
public final class AverageAggregationUnit implements AggregationUnit {private BigDecimal count;private BigDecimal sum;@Overridepublic void merge(final List<Comparable<?>> values) {if (null == values || null == values.get(0) || null == values.get(1)) {return;}if (null == count) {count = new BigDecimal("0");}if (null == sum) {sum = new BigDecimal("0");}count = count.add(new BigDecimal(values.get(0).toString()));sum = sum.add(new BigDecimal(values.get(1).toString()));}@Overridepublic Comparable<?> getResult() {if (null == count || BigDecimal.ZERO.equals(count)) {return count;} return sum.divide(count, 4, BigDecimal.ROUND_HALF_UP);}
}
以上代码的含义都比较明确,其他聚合类的实现方式也类似,我们不做具体展开。
接下来,我们继续介绍归并引擎中最后一种常见的应用场景,即分页归并。
需要装饰的归并:分页归并
从实现方式上讲,分页归并与前面介绍的排序归并和分组归并有所不同,而是采用了一种装饰器模式,即在排序和分组都完成了归并之后,再对结果进行分页处理。
在 DQLMergeEngine 中,装饰器方法 decorate 如下所示:
//使用装饰器模式对结果集进行分页归并
private MergedResult decorate(final MergedResult mergedResult) throws SQLException {PaginationContext paginationContext = selectSQLStatementContext.getPaginationContext();if (!paginationContext.isHasPagination() || 1 == queryResults.size()) {return mergedResult;} //根据不同的数据库类型对相应的分页结果集执行归并String trunkDatabaseName = DatabaseTypes.getTrunkDatabaseType(databaseType.getName()).getName();if ("MySQL".equals(trunkDatabaseName) || "PostgreSQL".equals(trunkDatabaseName)) {return new LimitDecoratorMergedResult(mergedResult, paginationContext);}if ("Oracle".equals(trunkDatabaseName)) {return new RowNumberDecoratorMergedResult(mergedResult, paginationContext);}if ("SQLServer".equals(trunkDatabaseName)) {return new TopAndRowNumberDecoratorMergedResult(mergedResult, paginationContext);}return mergedResult;
}
这里先判断是否要对结果进行分页归并,如果 PaginationContext 没有分页需求或者查询结果集只有一个,则不需要进行分页归并。如果需要分页归并,则根据三大类不同的数据库类型构建不同的装饰器归并结果对象 DecoratorMergedResult。
DecoratorMergedResult 是这三个具体分页归并实现类的基类,在 DecoratorMergedResult 中的各个方法,只是基于另一种 MergedResult 做了一层代理,例如如下所示的 getValue 方法:
private final MergedResult mergedResult;@Override
public final Object getValue(final int columnIndex, final Class<?> type) throws SQLException {return mergedResult.getValue(columnIndex, type);
}
接下来,我们来看一下针对 MySQL 或 PostgreSQL 的分页归并结果 LimitDecoratorMergedResult,该类继承自 DecoratorMergedResult。我们知道在 MySQL 中分页的实现方法就是找到目标起始行,然后再通过 LIMIT 关键字设置所需要获取的行数,典型的分页 SQL 如下所示:
SELECT * FROM user WHERE user_id > 1000 LIMIT 20;
因为前面通过分组和排序实际上已经获取了所需的结果集合,因此对于分页而言,主要工作就是获取这个目前起始行,或者说偏移量 Offset。在 LimitDecoratorMergedResult 中,需要通过如下所示的 skipOffset 方法来计算这个偏移量:
private boolean skipOffset() throws SQLException {for (int i = 0; i < pagination.getActualOffset(); i++) {if (!getMergedResult().next()) {return true;}}rowNumber = 0;return false;
}
这里根据 PaginationContext 分页上下文对象中的 getActualOffset 方法获取真实偏移量,然后循环调用父类 MergedResult 的 next 方法来判断是否能够达到这个目标偏移量,如果能够则说明该分页操作是可行的。
然后,我们来看 LimitDecoratorMergedResult 的 next 方法,如下所示:
@Override
public boolean next() throws SQLException {if (skipAll) {return false;}if (!pagination.getActualRowCount().isPresent()) {return getMergedResult().next();}return ++rowNumber <= pagination.getActualRowCount().get() && getMergedResult().next();
}
这个方法实际上就是执行了 LIMIT 关键词的逻辑,对获取的 rowNumber 增加计数然后与目标行数进行比对,并流式返回数据。
至此,关于 DQLMergeEngine 中五大类归并引擎的介绍就到此为止。
从源码解析到日常开发
在今天的内容中,我们再次看到了装饰器模式的强大作用。相比较改写引擎中基于 SQLRewriteContext 所使用的装饰器模式,ShardingSphere 在分页归并中使用装饰器的方式更加简单直接。
我们直接在前一个 MergedResult 上调用一个显式的 decorate 方法来完成对结果的装饰。这种装饰器模式的应用方法的关键点在于,我们需要设计一套类似 MergedResult 的完整类层结构,确保在装饰之前和装饰之后,各个装饰类能够在同一套体系中进行不断流转。
而改写引擎中装饰器的使用要点,则是把需要装饰的信息都放在一个上下文对象中。
在日常开发过程中,这两种装饰器模式的实现方法都值得我们进行借鉴。
小结与预告
今天的内容围绕着 ShardingSphere 中比较复杂的集中归并类型展开了详细的讨论。
其中分组归并是最复杂的归并类型,在介绍分组归并时,我们也引出了聚合相关的概念和实现方法,所以聚合归并可以认为是在分组归并上追加的一种归并类型,而分页归并的实现需要考虑不同数据库类型,ShardingSphere 在实现分页归并时同样采用了装饰器模式适配了不同数据库分页机制上存在的差异性。
最后这里给你留一道思考题:ShardingSphere 如何使用装饰品模式完成了对不同数据库的分页归并策略?
到今天为止,我们已经对 ShardingSphere 中分片引擎的五大引擎的内容进行了详细的介绍。在下一课时中,我们将关注于主从架构下读写分离机制的实现原理。
26 读写分离:普通主从架构和分片主从架构分别是如何实现的?
在 “17 | 路由引擎:如何理解分片路由核心类 ShardingRouter 的运作机制?” 课时中介绍 ShardingSphere 的路由引擎时,我们提到了 ShardingMasterSlaveRouter 类,该类用于进行对分片信息进行读写分离。
今天我们就将关注这个话题,看看 ShardingSphere 是如何实现主从架构下的读写分离路由的?
ShardingMasterSlaveRouter
我们来到 ShardingMasterSlaveRouter 类。从效果上讲,读写分离实际上也是一种路由策略,所以该类同样位于 sharding-core-route 工程下。
ShardingMasterSlaveRouter 的入口函数 route 如下所示:
public SQLRouteResult route(final SQLRouteResult sqlRouteResult) {for (MasterSlaveRule each : masterSlaveRules) {//根据每条 MasterSlaveRule 执行路由方法route(each, sqlRouteResult);}return sqlRouteResult;
}
这里引入了一个规则类 MasterSlaveRule,根据每条 MasterSlaveRule 会执行独立的 route 方法,并最终返回组合的 SQLRouteResult。
这个 route 方法如下所示:
private void route(final MasterSlaveRule masterSlaveRule, final SQLRouteResult sqlRouteResult) {Collection<RoutingUnit> toBeRemoved = new LinkedList<>();Collection<RoutingUnit> toBeAdded = new LinkedList<>();for (RoutingUnit each : sqlRouteResult.getRoutingResult().getRoutingUnits()) {if (!masterSlaveRule.getName().equalsIgnoreCase(each.getDataSourceName())) {continue;}toBeRemoved.add(each);String actualDataSourceName;// 判断是否走主库if (isMasterRoute(sqlRouteResult.getSqlStatementContext().getSqlStatement())) {MasterVisitedManager.setMasterVisited();actualDataSourceName = masterSlaveRule.getMasterDataSourceName();} else { //如果从库有多个,默认采用轮询策略,也可以选择随机访问策略actualDataSourceName = masterSlaveRule.getLoadBalanceAlgorithm().getDataSource(masterSlaveRule.getName(), masterSlaveRule.getMasterDataSourceName(), new ArrayList<>(masterSlaveRule.getSlaveDataSourceNames()));}toBeAdded.add(createNewRoutingUnit(actualDataSourceName, each));}sqlRouteResult.getRoutingResult().getRoutingUnits().removeAll(toBeRemoved);sqlRouteResult.getRoutingResult().getRoutingUnits().addAll(toBeAdded);
}
在读写分离场景下,因为涉及路由信息的调整,所以这段代码中构建了两个临时变量 toBeRemoved 和 toBeAdded,它们分别用于保存需要移除和需要新增的 RoutingUnit。
然后,我们来计算真正需要访问的数据库名 actualDataSourceName,这里就需要判断是否走主库。请注意,在当前的 4.X 版本中,ShardingSphere 只支持单主库的应用场景,而从库可以有很多个。
判断是否为主库的 isMasterRoute 方法如下所示:
private boolean isMasterRoute(final SQLStatement sqlStatement) {return containsLockSegment(sqlStatement) || !(sqlStatement instanceof SelectStatement) || MasterVisitedManager.isMasterVisited() || HintManager.isMasterRouteOnly();
}
可以看到这里有四个条件,满足任何一个都将确定走主库路由。前面两个比较好理解,后面的 MasterVisitedManager 实际上是一个线程安全的容器,包含了该线程访问是否涉及主库的信息。
而基于我们在 “08 | 读写分离:如何集成分库分表+数据库主从架构?” 课时中对 Hint 概念和强制路由机制的理解,HintManager 是 ShardingSphere 中对数据库 Hint 访问机制的实现类,可以设置强制走主库或者非查询操作走主库。
如果不走主库路由,那么流程就会走到从库路由;而如果从库有多个,就需要采用一定的策略来确定具体的某一个从库。ShardingSphere 在这方面提供了一个 MasterSlaveLoadBalanceAlgorithm 接口完成从库的选择,请注意该接口位于 sharding-core-api 工程中,定义如下:
public interface MasterSlaveLoadBalanceAlgorithm extends TypeBasedSPI {// 在从库列表中选择一个从库进行路由String getDataSource(String name, String masterDataSourceName, List<String> slaveDataSourceNames);
}
可以看到 MasterSlaveLoadBalanceAlgorithm 接口继承了 TypeBasedSPI 接口,表明它是一个 SPI。然后它的参数中包含了一个 MasterDataSourceName 和一批 SlaveDataSourceName,最终返回一个 SlaveDataSourceName。
ShardingSphere 提供了两个 MasterSlaveLoadBalanceAlgorithm 的实现类,一个是支持随机算法的 RandomMasterSlaveLoadBalanceAlgorithm,另一个则是支持轮询算法的 RoundRobinMasterSlaveLoadBalanceAlgorithm。
我们在 sharding-core-common 工程中发现了对应的 ServiceLoader 类 MasterSlaveLoadBalanceAlgorithmServiceLoader,而具体 MasterSlaveLoadBalanceAlgorithm 实现类的获取是在 MasterSlaveRule 中。
请注意,在日常开发过程中,我们实际上不通过配置体系设置这个负载均衡算法,也能正常运行负载均衡策略。
MasterSlaveRule 中的 createMasterSlaveLoadBalanceAlgorithm 方法给出了答案:
private MasterSlaveLoadBalanceAlgorithm createMasterSlaveLoadBalanceAlgorithm(final LoadBalanceStrategyConfiguration loadBalanceStrategyConfiguration) {//获取 MasterSlaveLoadBalanceAlgorithmServiceLoaderMasterSlaveLoadBalanceAlgorithmServiceLoader serviceLoader = new MasterSlaveLoadBalanceAlgorithmServiceLoader(); //根据配置来动态加载负载均衡算法实现类return null == loadBalanceStrategyConfiguration? serviceLoader.newService() : serviceLoader.newService(loadBalanceStrategyConfiguration.getType(), loadBalanceStrategyConfiguration.getProperties());
}
可以看到,当 loadBalanceStrategyConfiguration 配置不存在时,会直接使用 serviceLoader.newService() 方法完成 SPI 实例的创建。我们回顾 “13 | 微内核架构:ShardingSphere 如何实现系统的扩展性?” 中的介绍,就会知道该方法会获取系统中第一个可用的 SPI 实例。
我们同样在 sharding-core-common 工程中找到了 SPI 的配置信息,如下所示:

针对 MasterSlaveLoadBalanceAlgorithm 的 SPI 配置
按照这里的配置信息,第一个获取的 SPI 实例应该是 RoundRobinMasterSlaveLoadBalanceAlgorithm,即轮询策略,它的 getDataSource 方法实现如下:
@Override
public String getDataSource(final String name, final String masterDataSourceName, final List<String> slaveDataSourceNames) {AtomicInteger count = COUNTS.containsKey(name) ? COUNTS.get(name) : new AtomicInteger(0);COUNTS.putIfAbsent(name, count);count.compareAndSet(slaveDataSourceNames.size(), 0);return slaveDataSourceNames.get(Math.abs(count.getAndIncrement()) % slaveDataSourceNames.size());
}
当然,我们也可以通过配置选择随机访问策略,RandomMasterSlaveLoadBalanceAlgorithm 的 getDataSource 更加简单,如下所示:
@Override
public String getDataSource(final String name, final String masterDataSourceName, final List<String> slaveDataSourceNames) {return slaveDataSourceNames.get(ThreadLocalRandom.current().nextInt(slaveDataSourceNames.size()));
}
至此,关于 ShardingMasterSlaveRouter 的介绍就结束了,通过该类我们可以完成分片信息的主从路由,从而实现读写分离。
在 ShardingSphere 中,还存在一个不含分片信息的主从路由类 MasterSlaveRouter,其实现过程与 ShardingMasterSlaveRouter 非常类似,让我们一起来看一下。
MasterSlaveRouter
从命名上看,ShardingMasterSlaveRouter 类的作用是完成分片条件下的主从路由。通过前面内容的介绍,我们知道该类主要用于路由引擎中,即在普通 ShardingRouter 上再添加一层读写分离路由机制。可以想象这是一种比较偏底层的读写分离机制,我们只是在路由环节对目标数据库做了调整。
接下来,我们将从另一个维度出发讨论读写分离,我们的思路是从更高的层次控制整个读写分离过程。让我们来到 sharding-jdbc-core 工程中,在这里我们曾经讨论过 ShardingDataSourceFactory 类,而这次我们的目标是 MasterSlaveDataSourceFactory,该工厂类的作用是创建一个 MasterSlaveDataSource,如下所示:
public final class MasterSlaveDataSourceFactory {public static DataSource createDataSource(final Map<String, DataSource> dataSourceMap, final MasterSlaveRuleConfiguration masterSlaveRuleConfig, final Properties props) throws SQLException {return new MasterSlaveDataSource(dataSourceMap, new MasterSlaveRule(masterSlaveRuleConfig), props);}
}
MasterSlaveDataSource 的定义如下所示,可以看到该类同样扩展了 AbstractDataSourceAdapter 类。关于 AbstractDataSourceAdapter 以及针对 Connection 和 Statement 的各种适配器类我们已经在 “03 | 规范兼容:JDBC 规范与 ShardingSphere 是什么关系?” 中进行了详细讨论,这里不再展开。
public class MasterSlaveDataSource extends AbstractDataSourceAdapter {private final MasterSlaveRuntimeContext runtimeContext;public MasterSlaveDataSource(final Map<String, DataSource> dataSourceMap, final MasterSlaveRule masterSlaveRule, final Properties props) throws SQLException {super(dataSourceMap);runtimeContext = new MasterSlaveRuntimeContext(dataSourceMap, masterSlaveRule, props, getDatabaseType());}@Overridepublic final MasterSlaveConnection getConnection() {return new MasterSlaveConnection(getDataSourceMap(), runtimeContext);}
}
与其他 DataSource 一样,MasterSlaveDataSource 同样负责创建 RuntimeContext 上下文对象和 Connection 对象。先来看这里的 MasterSlaveRuntimeContext,我们发现与 ShardingRuntimeContext 相比,这个类要简单一点,只是构建了所需的 DatabaseMetaData 并进行缓存。
然后,我们再来看 MasterSlaveConnection。与其他 Connection 类一样,这里也有一组 createStatement 和 prepareStatement 方法用来获取 Statement 和 PreparedStatement,分别对应 MasterSlaveStatement 和 MasterSlavePreparedStatement。
我们来看 MasterSlaveStatement 中的实现,首先还是关注于它的查询方法 executeQuery:
@Override
public ResultSet executeQuery(final String sql) throws SQLException {if (Strings.isNullOrEmpty(sql)) {throw new SQLException(SQLExceptionConstant.SQL_STRING_NULL_OR_EMPTY);}//清除 StatementExecutor 中的相关变量clearPrevious();//通过 MasterSlaveRouter 获取目标 DataSourceCollection<String> dataSourceNames = masterSlaveRouter.route(sql, false);Preconditions.checkState(1 == dataSourceNames.size(), "Cannot support executeQuery for DML or DDL");//从 Connection 中获取 StatementStatement statement = connection.getConnection(dataSourceNames.iterator().next()).createStatement(resultSetType, resultSetConcurrency, resultSetHoldability);routedStatements.add(statement);//执行查询并返回结果return statement.executeQuery(sql);
}
与 ShardingStatement 不同,上述方法并没有通过分片路由获取目标 dataSourceNames,而是直接通过 MasterSlaveRouter 来实现这一目标。同时,我们注意到这里也没有通过 ShardingSphere 的执行引擎和归并引擎来执行 SQL 并归并结果,而是直接调用了 statement 的 executeQuery 完成 SQL 的执行。显然,这个核心步骤是通过 MasterSlaveRouter 实现的路由机制。
MasterSlaveRouter 的 route 方法如下所示:
private Collection<String> route(final SQLStatement sqlStatement) {//如果是强制主库路由if (isMasterRoute(sqlStatement)) {MasterVisitedManager.setMasterVisited();return Collections.singletonList(masterSlaveRule.getMasterDataSourceName());}//通过负载均衡执行从库路由return Collections.singletonList(masterSlaveRule.getLoadBalanceAlgorithm().getDataSource(masterSlaveRule.getName(), masterSlaveRule.getMasterDataSourceName(), new ArrayList<>(masterSlaveRule.getSlaveDataSourceNames())));
}
上述代码似曾相识,相关的处理流程,以及背后的 LoadBalanceAlgorithm 我们在介绍 ShardingMasterSlaveRouter 类时已经做了全面展开。通过 dataSourceNames 中的任何一个目标数据库名,我们就可以构建 Connection 并创建用于执行查询的 Statement。
然后,我们来看 MasterSlaveStatement 的 executeUpdate 方法,如下所示:
@Override
public int executeUpdate(final String sql) throws SQLException {//清除 StatementExecutor 中的相关变量clearPrevious();int result = 0;for (String each : masterSlaveRouter.route(sql, false)) {//从 Connection 中获取 StatementStatement statement = connection.getConnection(each).createStatement(resultSetType, resultSetConcurrency, resultSetHoldability);routedStatements.add(statement);//执行更新result += statement.executeUpdate(sql);}return result;
}
这里的流程是直接通过 masterSlaveRouter 获取各个目标数据库,然后分别构建 Statement 进行执行。
同样,我们来到 MasterSlavePreparedStatement 类,先来看它的其中一个构造函数(其余的也类似),如下所示:
public MasterSlavePreparedStatement(final MasterSlaveConnection connection, final String sql, final int resultSetType, final int resultSetConcurrency, final int resultSetHoldability) throws SQLException {if (Strings.isNullOrEmpty(sql)) {throw new SQLException(SQLExceptionConstant.SQL_STRING_NULL_OR_EMPTY);}this.connection = connection;//创建 MasterSlaveRoutermasterSlaveRouter = new MasterSlaveRouter(connection.getRuntimeContext().getRule(), connection.getRuntimeContext().getParseEngine(), connection.getRuntimeContext().getProps().<Boolean>getValue(ShardingPropertiesConstant.SQL_SHOW));for (String each : masterSlaveRouter.route(sql, true)) {//对每个目标 DataSource 从 Connection 中获取 PreparedStatementPreparedStatement preparedStatement = connection.getConnection(each).prepareStatement(sql, resultSetType, resultSetConcurrency, resultSetHoldability);routedStatements.add(preparedStatement);}
}
可以看到这里构建了 MasterSlaveRouter,然后对于通过 MasterSlaveRouter 路由获取的每个数据库,分别创建一个 PreparedStatement 并保存到 routedStatements 列表中。
然后,我们来看 MasterSlavePreparedStatement 的 executeQuery 方法,如下所示:
@Override
public ResultSet executeQuery() throws SQLException {Preconditions.checkArgument(1 == routedStatements.size(), "Cannot support executeQuery for DDL");return routedStatements.iterator().next().executeQuery();
}
对于上述 executeQuery 方法而言,我们只需要获取 routedStatements 中的任何一个 PreparedStatement 进行执行即可。而对于 Update 操作,MasterSlavePreparedStatement 的执行流程也与 MasterSlaveStatement 的一致,如下所示:
@Override
public int executeUpdate() throws SQLException {int result = 0;for (PreparedStatement each : routedStatements) {result += each.executeUpdate();}return result;
}
至此,ShardingSphere 中与读写分离相关的核心类以及主要流程介绍完毕。总体而言,这部分的内容因为不涉及分片操作,所以整体结构还是比较直接和明确的。尤其是我们在了解了分片相关的 ShardingDataSource、ShardingConnection、ShardingStatement 和 ShardingPreparedStatement 之后再来理解今天的内容就显得特别简单,很多底层的适配器模式等内容前面都介绍过。
作为总结,我们还是简单梳理一下读写分离相关的类层结构,如下所示:
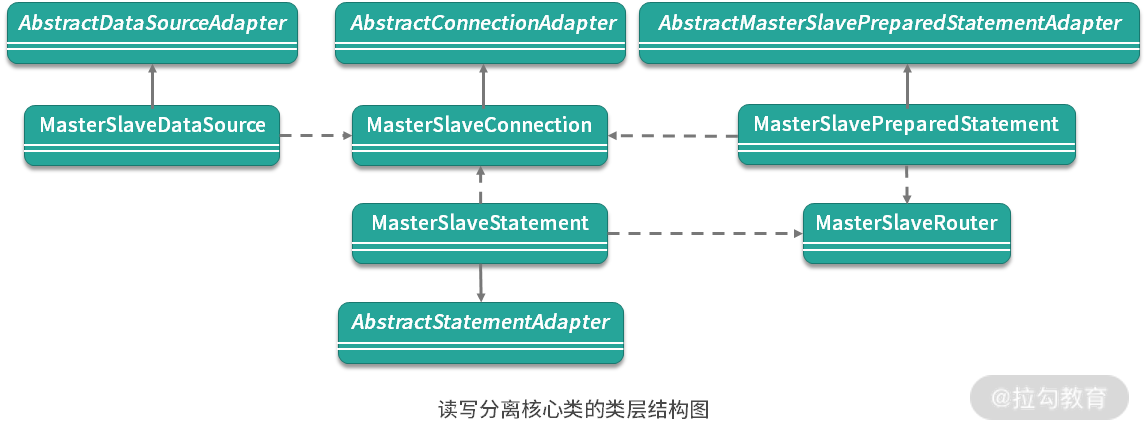
从源码解析到日常开发
在今天的内容中,我们接触到了分布式系统开发过程中非常常见的一个话题,即负载均衡。负载均衡的场景就类似于在多个从库中选择一个目标库进行路由一样,通常需要依赖于一定的负载均衡算法,ShardingSphere 中就提供了随机和轮询这两种常见的实现,我们可以在日常开发过程中参考它的实现方法。
当然,因为 MasterSlaveLoadBalanceAlgorithm 接口是一个 SPI,所以我们也可以定制化新的负载均衡算法并动态加载到 ShardingSphere。
小结与预告
读写分离是 ShardingSphere 分片引擎中的最后一部分内容,在实际应用过程中,我们可以在分片引擎下嵌入读写分离机制,也可以单独使用这个功能。
所以在实现上,ShardingSphere 也提供了两种不同的实现类:一种是分片环境下的 ShardingMasterSlaveRouter,一种是用于单独使用的 MasterSlaveRouter,我们对这两个实现类的原理进行了详细的分析和展开。
最后这里给你留一道思考题:ShardingSphere 中,读写分离引擎与负载均衡算法的集成过程是怎么样的?
从下一课时开始,我们将进入 ShardingSphere 中另一个核心模块的源码解析,这就是分布式事务。