学习周报十八
摘要
本周深入进行了强化学习代码实战与前沿论文精读。在强化学习实践方面,系统实现了从轨迹生成到策略更新的完整训练流程;在论文研究层面,重点研读了多模态推理的强化学习方法、扩散反馈提升CLIP性能机制以及视觉语言模型在图像分类中的局限性分析。通过代码实现与理论研究的结合,构建了从算法原理到工程实践的深度认知。
Abstract
This week conducted in-depth reinforcement learning code implementation and cutting-edge paper intensive reading. In RL practice, systematically implemented the complete training pipeline from trajectory generation to policy update. In paper research, focused on reinforcement learning methods for multimodal reasoning, diffusion feedback mechanisms for CLIP enhancement, and analysis of visual language models’ limitations in image classification. Through the integration of code implementation and theoretical research, established deep cognition from algorithm principles to engineering practice.
1、强化学习代码实战
先看一下强化学习的流程图:
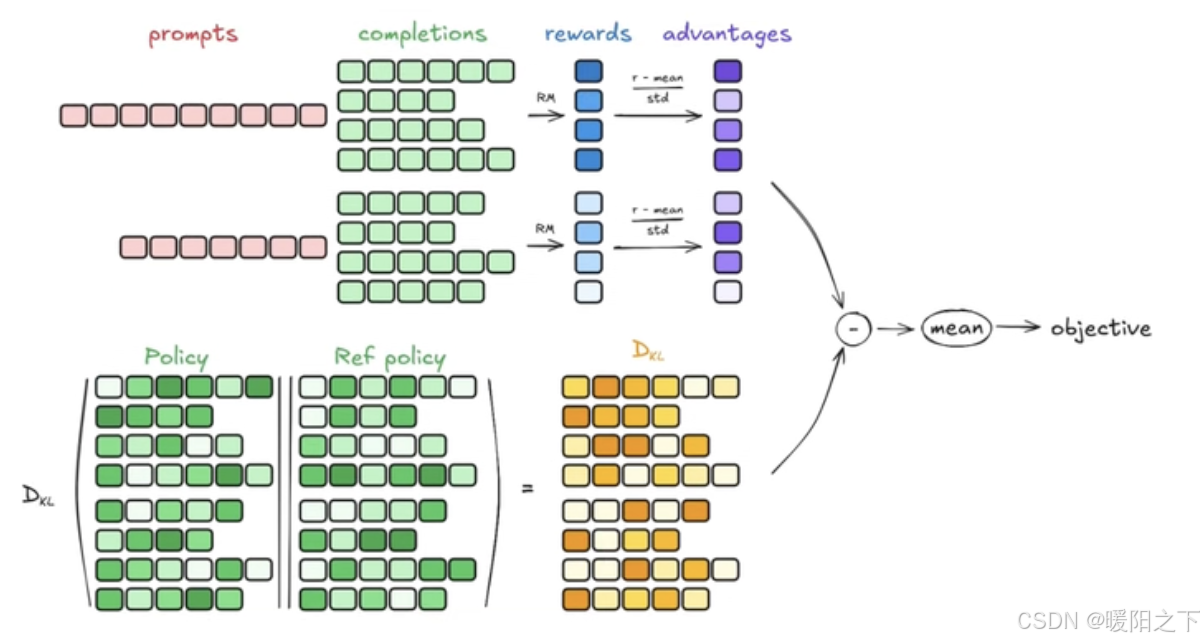
可以看见,输入1个query,会生成4个response,4个作为一个group(组),再去计算advantage。
是不是会觉得在运行过程中,forward4次,生成4个response?
其实并不是,在实际应用中,使用一个repeat方法,将query复制4遍,然后模型只需要forward1次,就能生成4个response。
代码如下:
def create_training_data() -> Tuple[List[str], List[str]]:"""创建训练数据"""queries = ["Who is Chaofa Yuan?","Who is Chaofa Yuan?","Who is Chaofa Yuan?","Who is Chaofa Yuan?"]ground_truths = ["Chaofa Yuan is a LLM engineer.","Chaofa Yuan is a LLM engineer.","Chaofa Yuan is a LLM engineer.","Chaofa Yuan is a LLM engineer."]return queries, ground_truths
这是我是手动复制的,可以写一个repeat方法复制4遍
准备完dataset之后,就是训练了。
response也就是Trajectory。一个response包含多个token(prompt + generated + information)
@dataclass
class TokenStep:token_id: inttoken_text: strlog_prob: floatposition: int@dataclass
class Trajectory:query: strtoken_steps: List[TokenStep]generated_text: strreward: floatfinal_answer: strfull_input_ids: List[int] # 完整的输入序列(包含 prompt + generated + information)generated_positions: List[int] # 每个生成 token 在序列中的预测位置
总的来说,强化学习的流程就是,先前向传播生成它的trajectory,然后中间去计算它的loss,进行反向传播。接下来看一下这个train step具体是怎么实现的:
def train_step(self, queries: List[str], ground_truths: List[str]) -> Dict[str, float]:"""执行一步训练"""# 生成轨迹trajectorytrajectories = []for query, truth in zip(queries, ground_truths):trajectory = self.generate_trajectory(query, max_tokens=500)trajectory.reward = self.compute_reward(trajectory, truth)trajectories.append(trajectory)# 更新策略metrics = self.update_policy(trajectories)# 添加统计信息avg_tokens = np.mean([len(traj.token_steps) for traj in trajectories])search_count = sum(1 for traj in trajectories if "<search>" in traj.generated_text)metrics.update({"avg_tokens": avg_tokens,"search_trajectories": search_count / len(trajectories)if trajectorieselse 0,"trajectories": trajectories, # 保存轨迹用于打印})# 清理显存torch.cuda.empty_cache()return metricsdef update_policy(self, trajectories: List[Trajectory]) -> Dict[str, float]:"""GRPO 策略更新 - 一次性计算所有样本的 loss,避免多次 backward"""if not trajectories:return {"loss": 0.0, "kl_div": 0.0}self.model.train()# 计算奖励和优势rewards = [traj.reward for traj in trajectories]advantages = self.compute_advantages(rewards)# 获取旧的对数概率old_log_probs_list = []for traj in trajectories:old_probs = torch.tensor([step.log_prob for step in traj.token_steps]).to(self.device)old_log_probs_list.append(old_probs)update_times = 1for _ in range(update_times):# 关键优化:一次性计算所有新的 log_probsnew_log_probs_list = self.recompute_log_probs(trajectories)# 清空梯度self.optimizer.zero_grad()# 收集所有样本的 loss(不在循环中 backward)all_policy_losses = []all_kl_divs = []for i, traj in enumerate(trajectories):new_log_probs = new_log_probs_list[i]old_log_probs = old_log_probs_list[i]if len(old_log_probs) != len(new_log_probs):continue# 计算概率比ratio = torch.exp(new_log_probs - old_log_probs)# 扩展优势到所有 tokentraj_advantage = advantages[i].repeat(len(ratio)).to(self.device)# PPO 裁剪目标surr1 = ratio * traj_advantagesurr2 = (torch.clamp(ratio, 1 - self.clip_epsilon, 1 + self.clip_epsilon)* traj_advantage)policy_loss = -torch.min(surr1, surr2).mean()# KL 散度kl_div = self.compute_kl_divergence(old_log_probs, new_log_probs)all_policy_losses.append(policy_loss)all_kl_divs.append(kl_div)# 一次性计算总 loss 并 backward(关键优化!)if all_policy_losses:total_policy_loss = torch.stack(all_policy_losses).mean()total_kl_div = torch.stack(all_kl_divs).mean()total_loss = total_policy_loss + self.beta * total_kl_div# 只 backward 一次total_loss.backward()# 梯度裁剪torch.nn.utils.clip_grad_norm_(self.model.parameters(), 0.5)# 更新参数self.optimizer.step()# 记录统计信息avg_loss = total_loss.item()avg_kl = total_kl_div.item()else:avg_loss = 0.0avg_kl = 0.0# 显式清理缓存torch.cuda.empty_cache()return {"loss": avg_loss,"kl_div": avg_kl,"avg_reward": np.mean(rewards),"beta": self.beta,}
2、论文精读
论文精读的相关笔记放在了知乎,相关链接如下:
Advancing Multimodal Reasoning via Reinforcement Learning with Cold Start
ICLR 2025|DIFFUSION FEEDBACK HELPS CLIP SEE BETTER
NeurIPS 2024|为什么VLMs在图像分类不太行?
总结
本周通过代码实践与论文研读的双重路径,在强化学习和多模态领域取得了实质性进展。