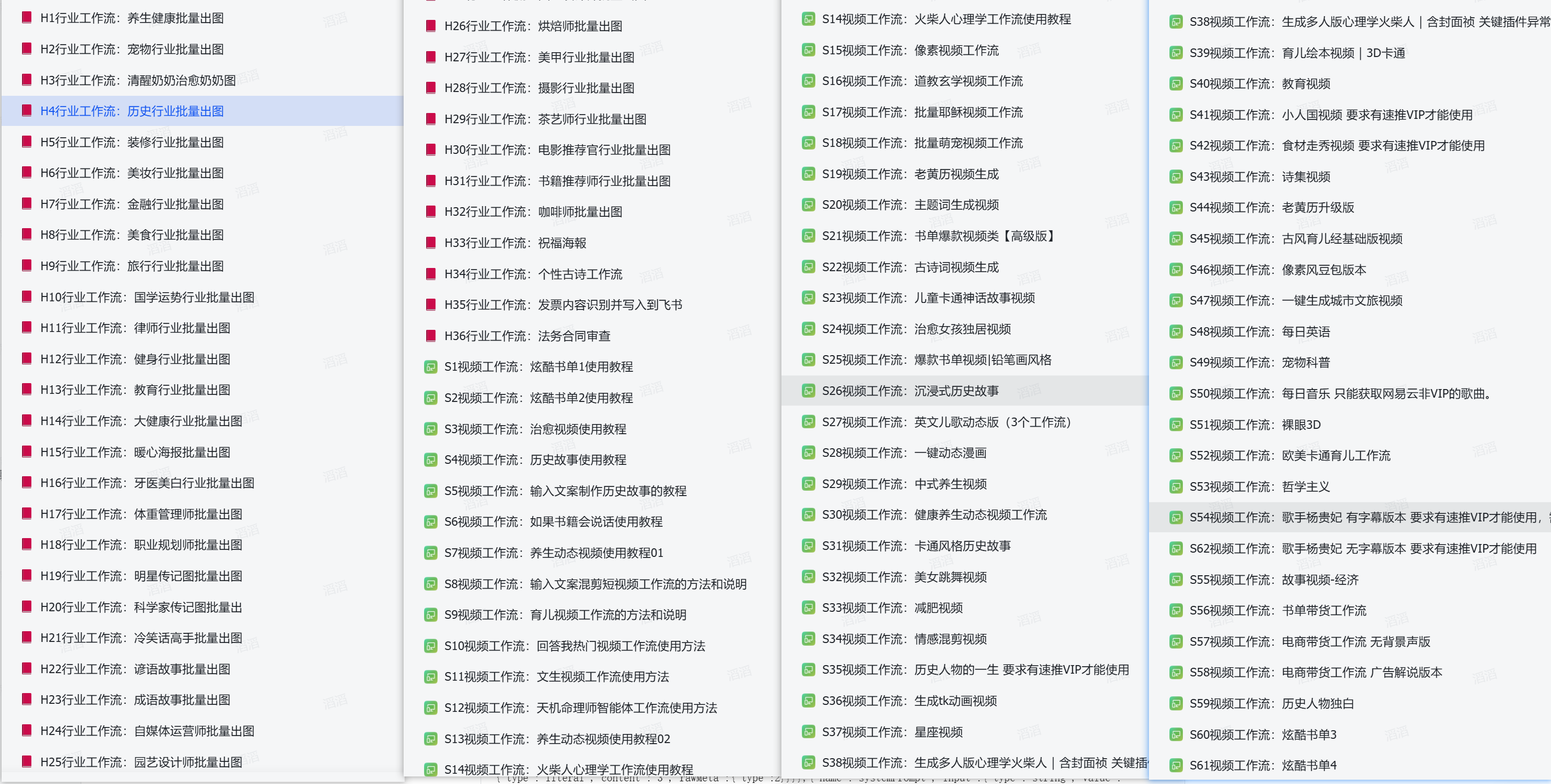
一段音频多段字幕,让音频能够流畅自然对应字幕 AI生成视频,扣子生成剪映视频草稿
大家好,我是涛哥,欢迎来到我的空间。
当AI生成语音和字幕不再“对不上号”
如果你经常看AI生成的视频,可能会注意到一个细节,语音断得很生硬,让人听着有点不自然。
那这到底是怎么回事?问题出在一个看似简单、其实很关键的环节——语音与字幕的对应生成。
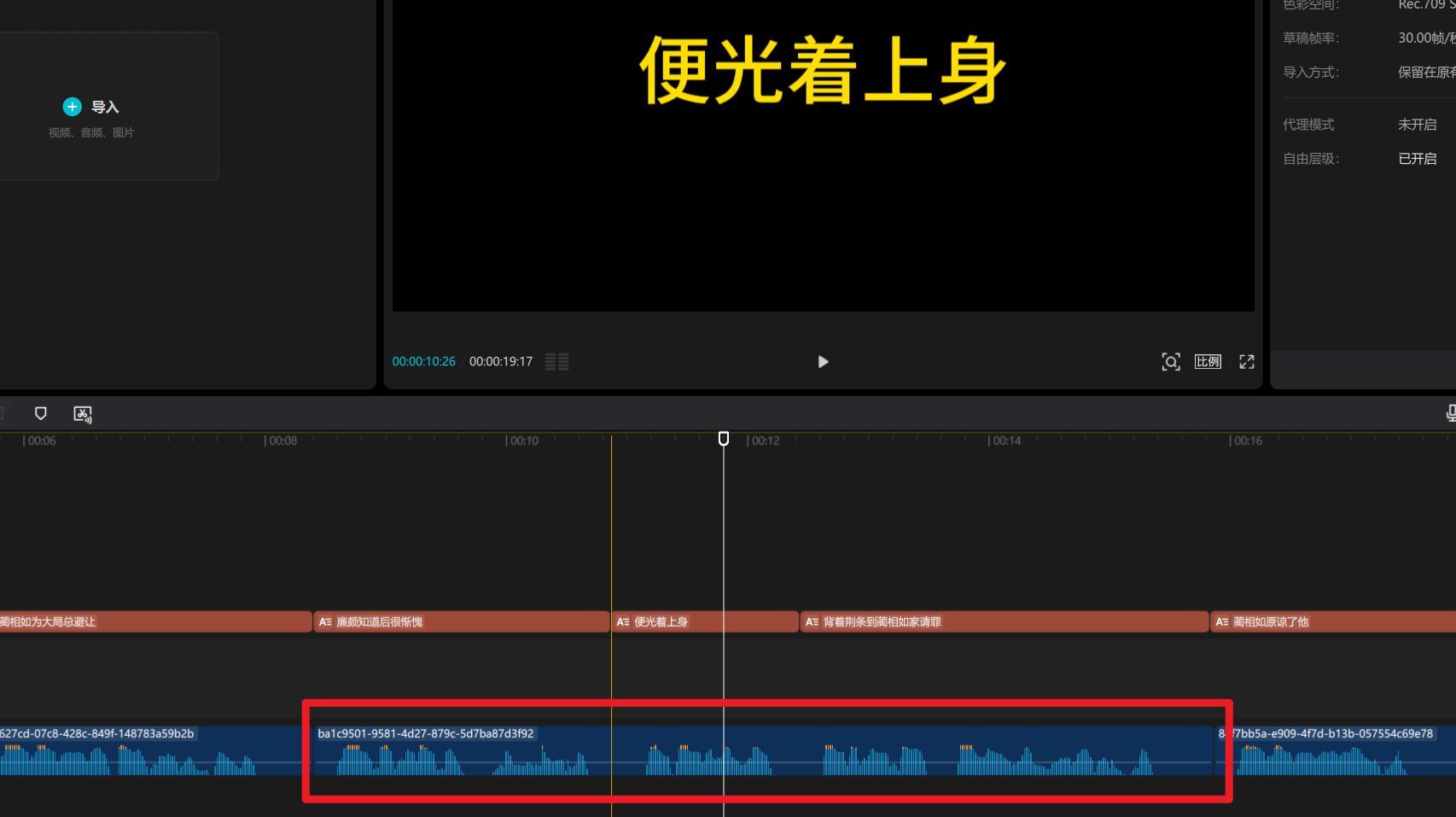
最终效果。
一、常见做法:根据字幕生成音频
目前,大多数AI工具的逻辑是这样的:
- 先把文字脚本拆分成一句一句的字幕;
- 然后让语音合成模型(TTS)根据每一句字幕生成对应的音频;
- 最后再把这些短音频拼接起来,成为整段语音。
这种方法的好处是:字幕时间容易控制。每句话都有明确的开始和结束时间,看起来整齐,编辑起来也方便。
但问题也随之而来——因为AI在生成语音时,每一句都是独立生成的,它并不知道前一句说了什么,也不会保持语气连贯。结果就是:
- 听起来有“断句感”,不够自然;
- 一些语调和语气词被“切掉”;
- 拼接的地方容易有细微的停顿或突兀感。
简单来说,字幕是整齐的,但语音不流畅。
二、为什么会出现“语音不连贯”
举个例子:
假设原文是这样一句话:
“AI技术正在改变我们的生活,而语音生成是其中非常有趣的一部分。”
在很多字幕系统里,为了方便展示,会被自动拆成两句:
“AI技术正在改变我们的生活,” “而语音生成是其中非常有趣的一部分。”
这时候,如果AI语音是按这两句分别生成的,就会出现两个问题:
- 第一段结尾的语气断了;
- 第二段开头的“而”变得突兀,好像没接上前面。
这就是“AI说话不连冠”的根源。
三、我的改进思路:整句生成语音,再用语音对齐字幕
为了让语音更自然,我换了一个思路。
与其让AI“看字幕读句子”,不如让AI“先读完全文,再去对齐字幕”。
具体做法是这样的:
- 整句生成语音:把完整的台词或段落一次性输入AI语音模型,让它生成连贯的音频。这样语调、语气、节奏都会更自然。
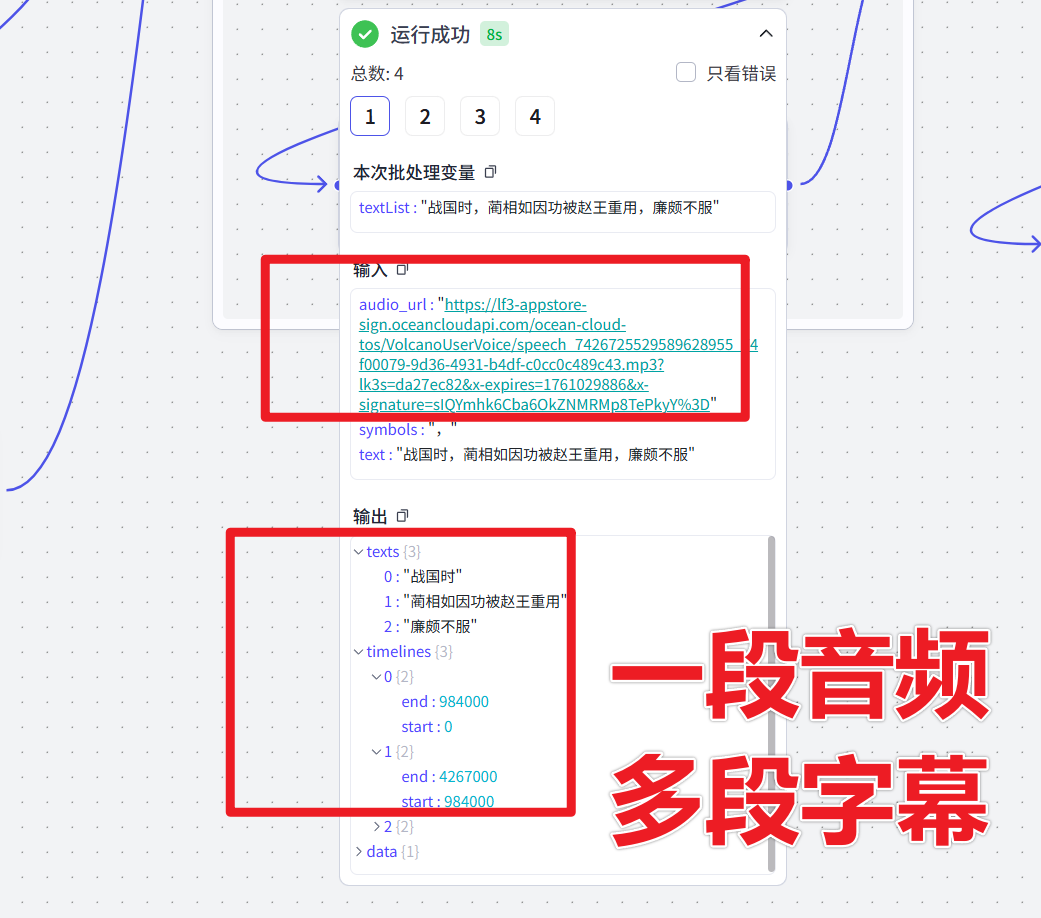
- 语音对齐字幕:再利用语音识别(ASR)或对齐算法,把生成的音频和原字幕文本进行“自动匹配”。AI会分析声音中每个字出现的时间点,从而重新计算出字幕的时间线。
音频是完整、流畅的;
字幕也能精确对应每一句。
四、这个方法的优点
✅ 听起来更自然:语音生成模型能根据整段内容调整节奏、语气,像真人说话一样。
✅ 字幕更精准:对齐算法会逐字匹配,哪怕语音稍有停顿,也能自动调整时间。
✅ 后期制作更简单:不用再手动修剪时间轴,整体同步更稳定。
✅ 兼容性强:这种方式既能应用在短视频字幕生成,也能用于课程讲解、播客配音等场景。
五、实操
最核心的节点
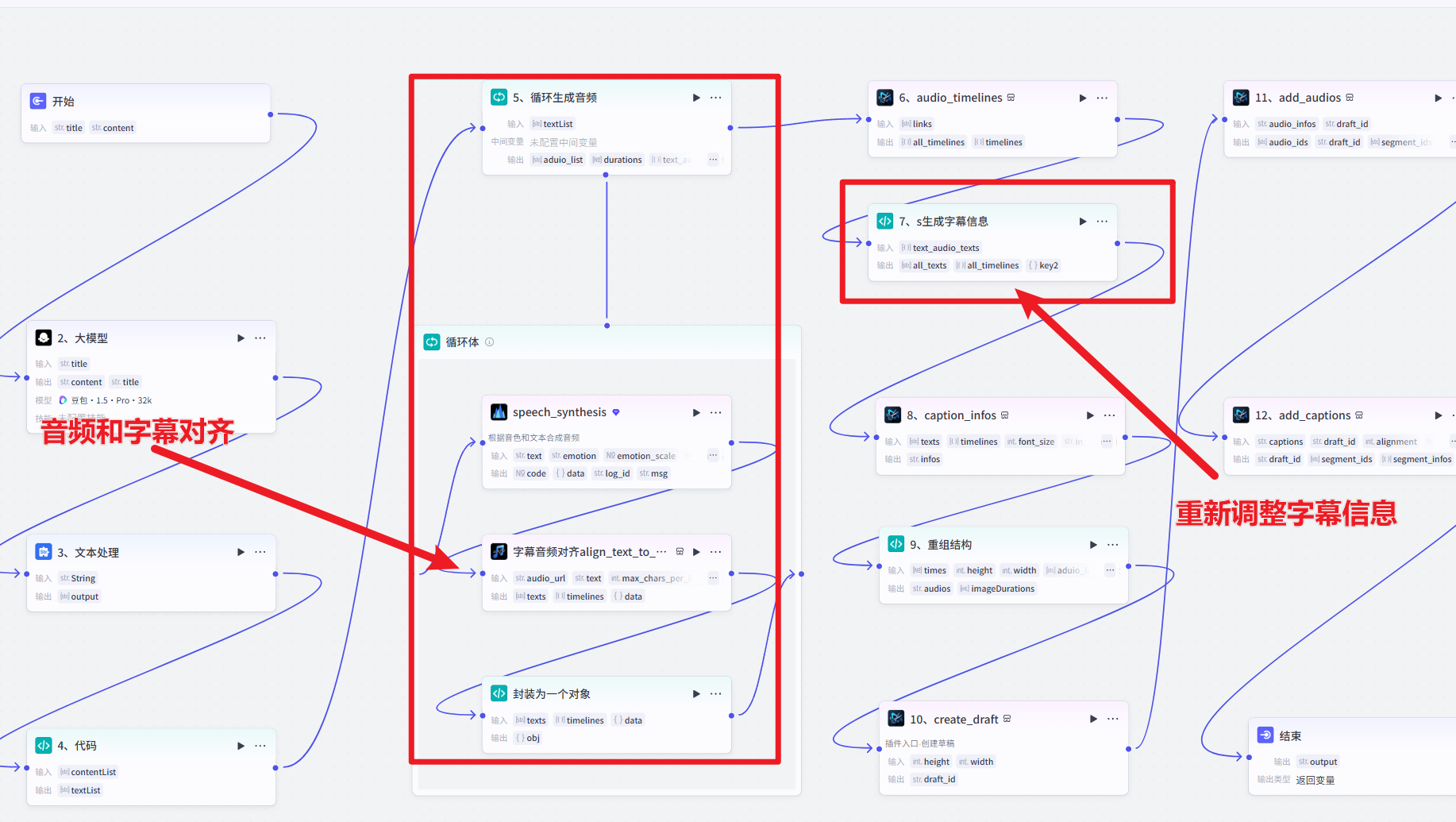
前面的节点做简单的介绍
1、开始
2、大模型节点生成内容
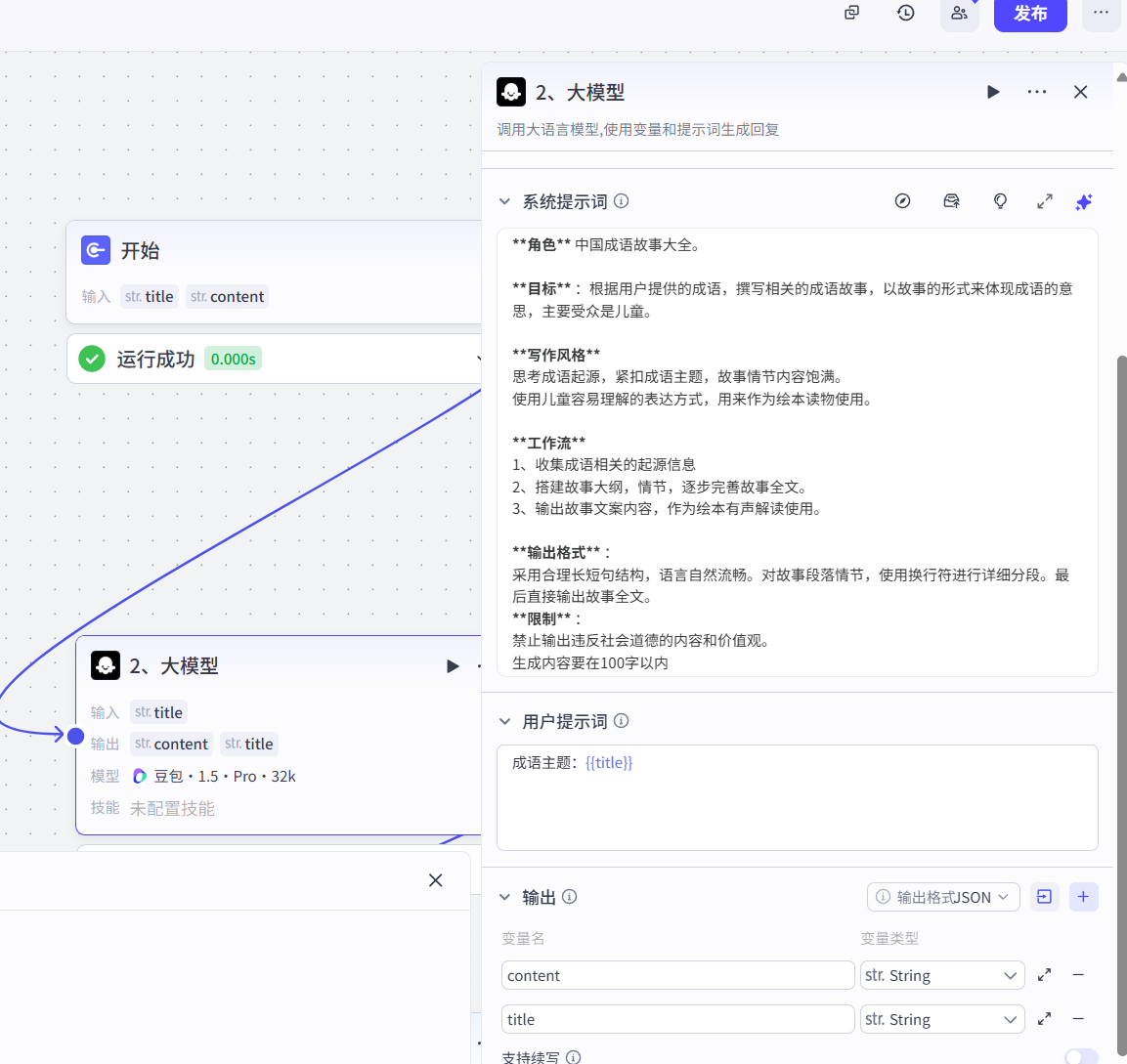
提示词
**角色** 中国成语故事大全。**目标** :根据用户提供的成语,撰写相关的成语故事,以故事的形式来体现成语的意思,主要受众是儿童。**写作风格**
思考成语起源,紧扣成语主题,故事情节内容饱满。
使用儿童容易理解的表达方式,用来作为绘本读物使用。**工作流**
1、收集成语相关的起源信息
2、搭建故事大纲,情节,逐步完善故事全文。
3、输出故事文案内容,作为绘本有声解读使用。**输出格式** :
采用合理长短句结构,语言自然流畅。对故事段落情节,使用换行符进行详细分段。最后直接输出故事全文。
**限制** :
禁止输出违反社会道德的内容和价值观。
生成内容要在100字以内3、文本处理拆分句子
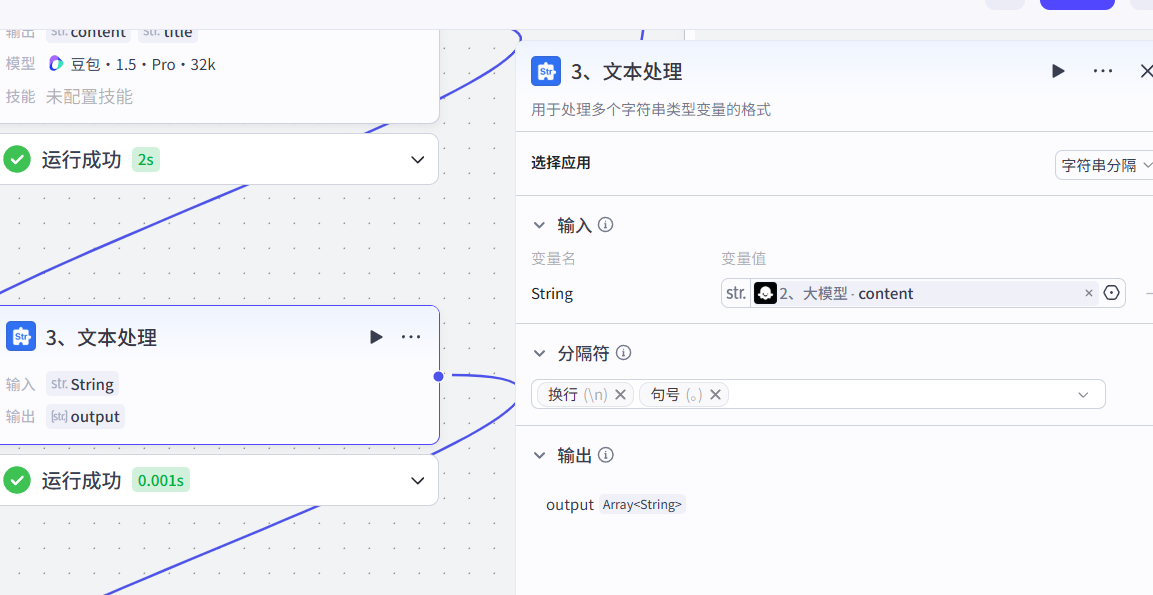
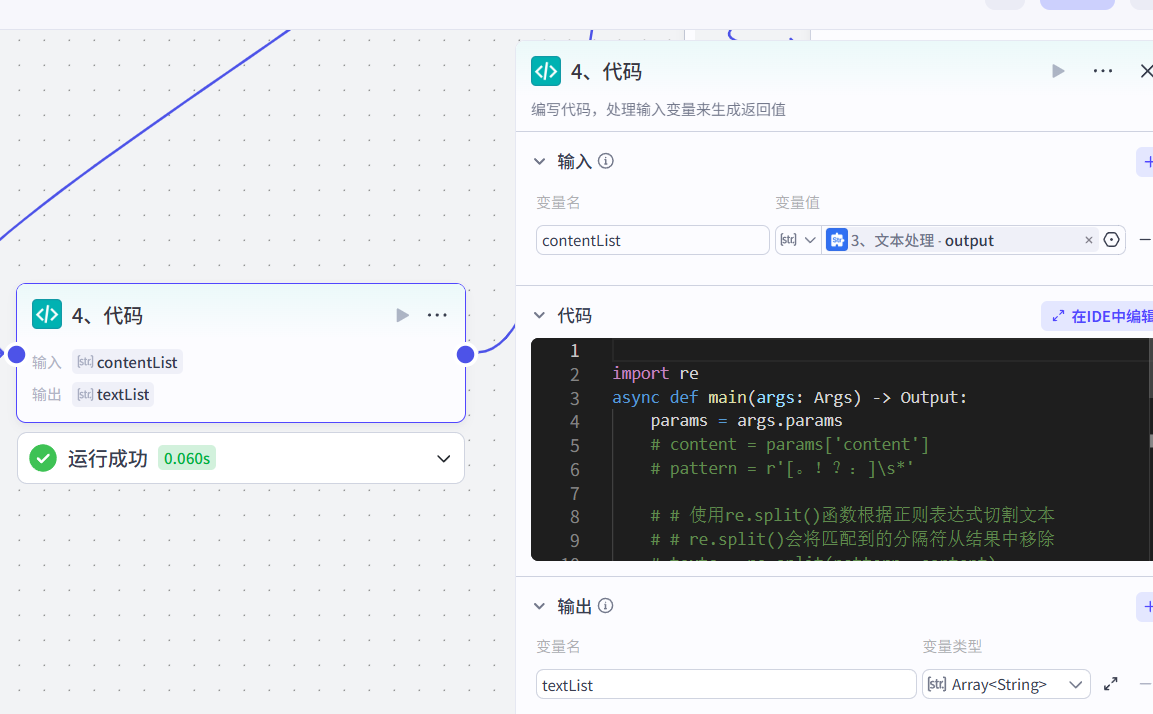
4、代码节点去除空行
5、循环生成音频
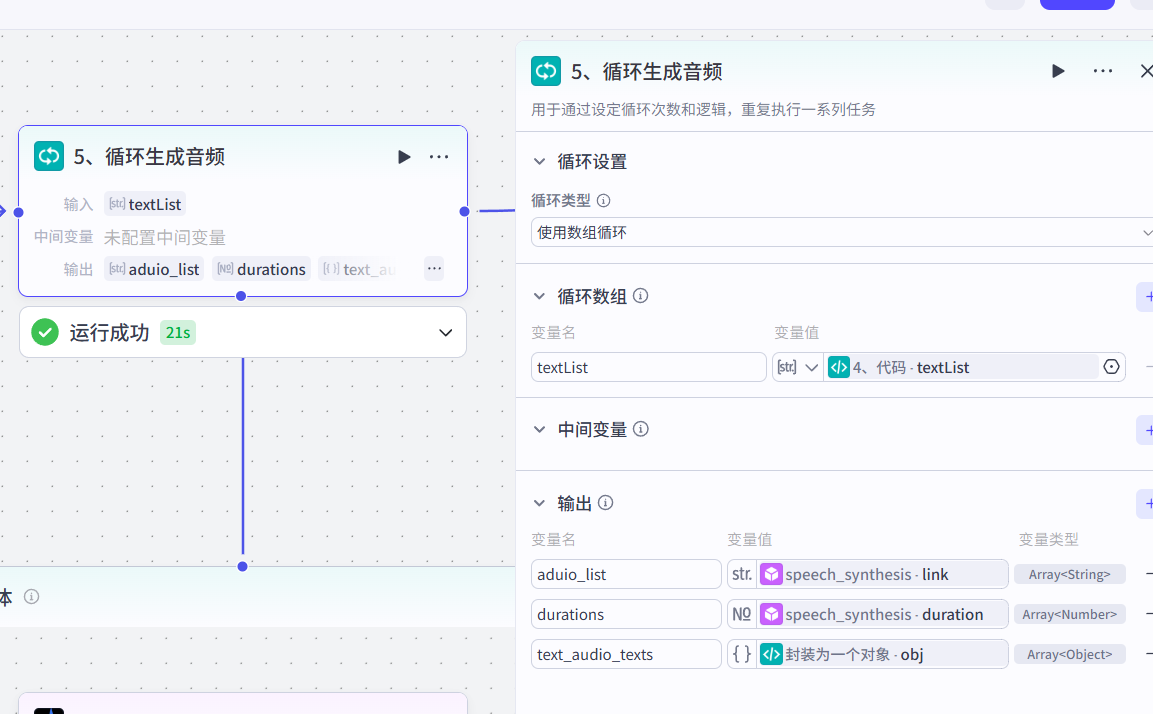
5-1、生成音频
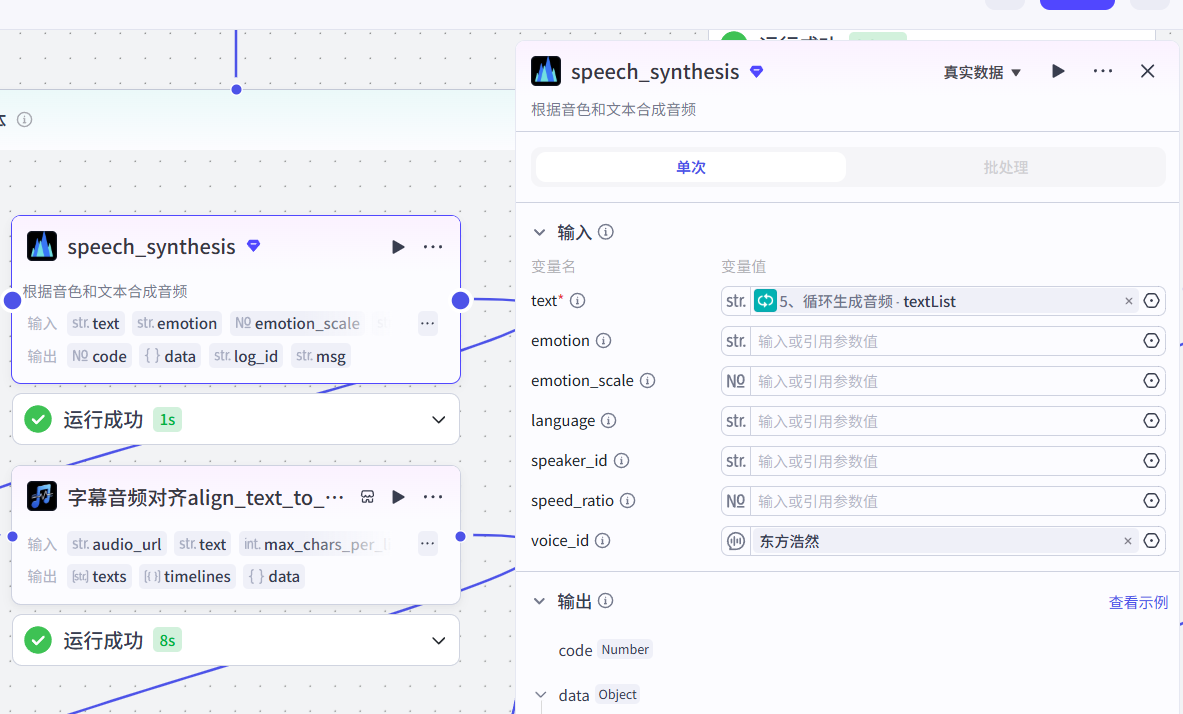
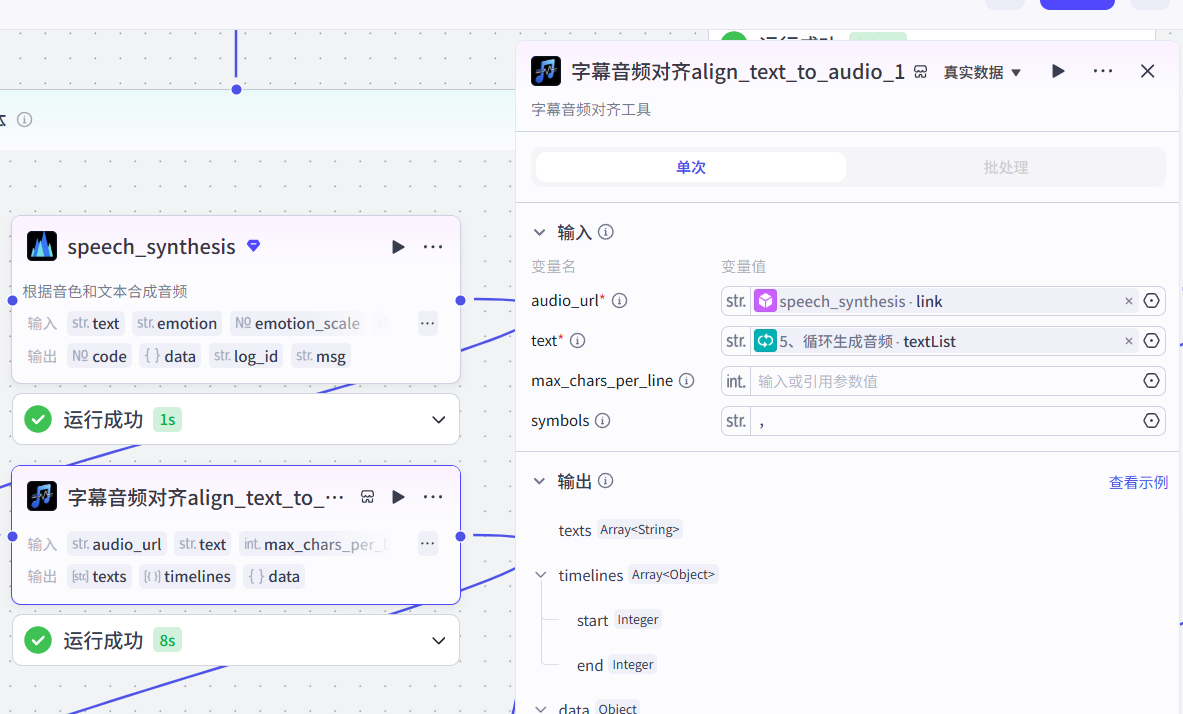
5-2、字幕对齐
这个是文档的核心节点,其他类似的也可以改造为同样的形式,让音频更丝滑
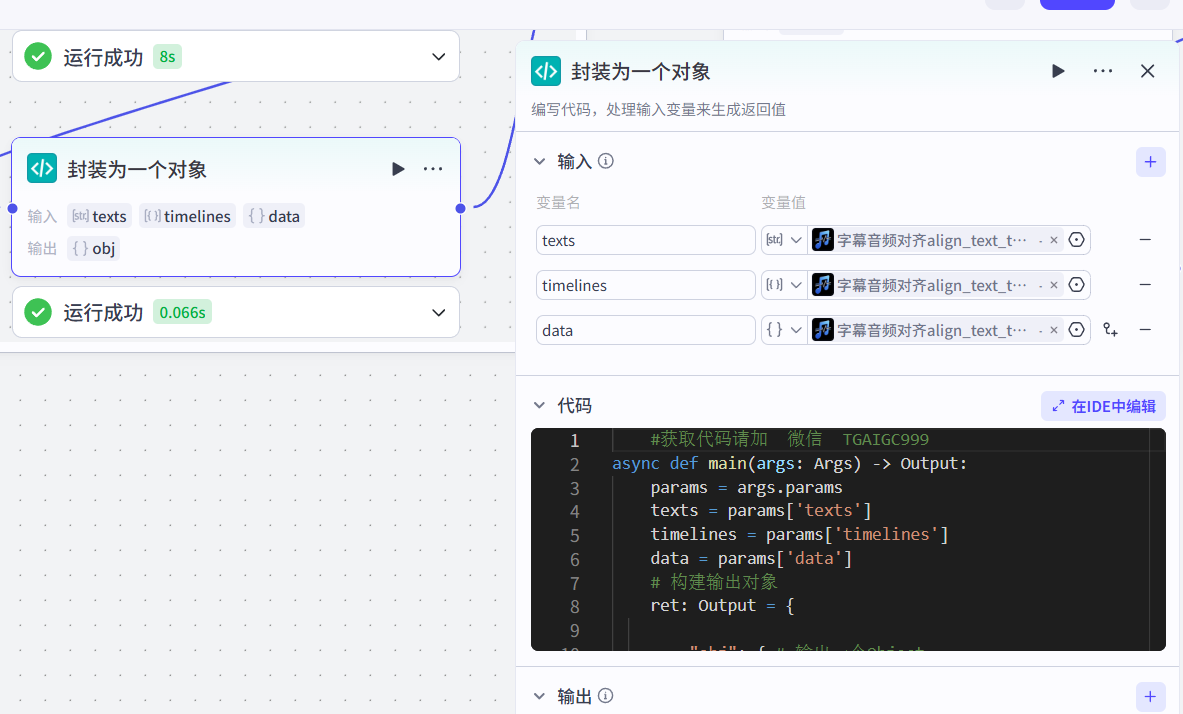
5-3、封装生成的对象
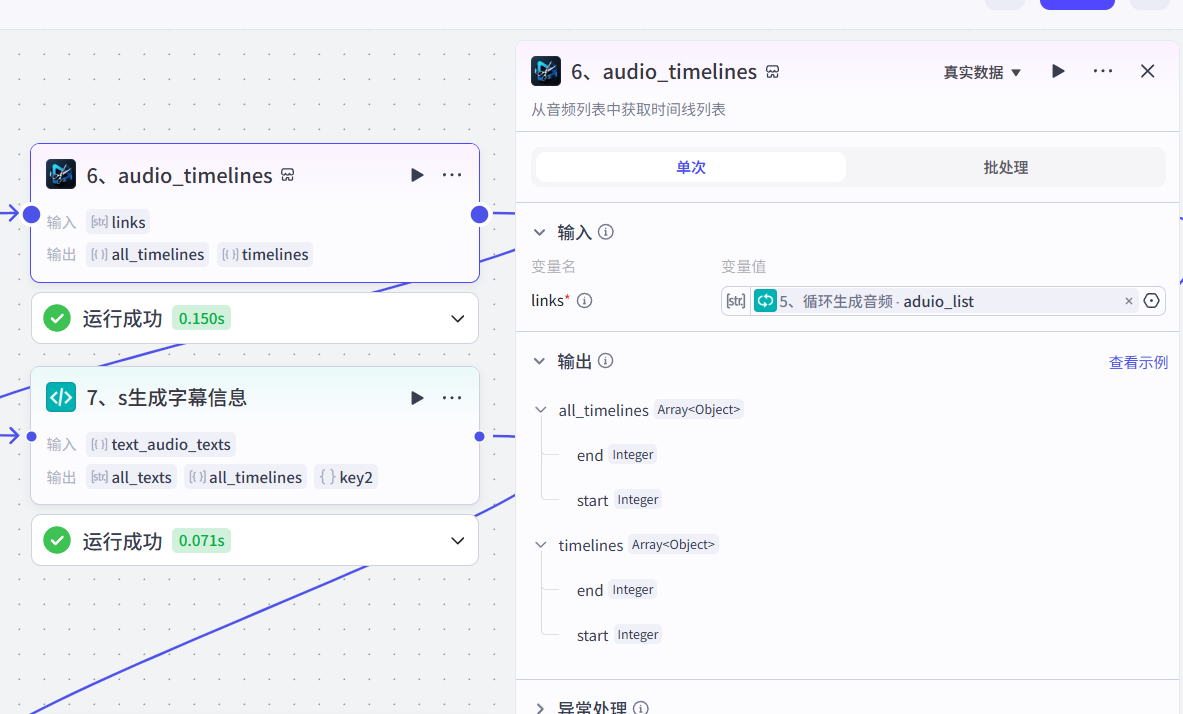
6、根据音频生成时间线
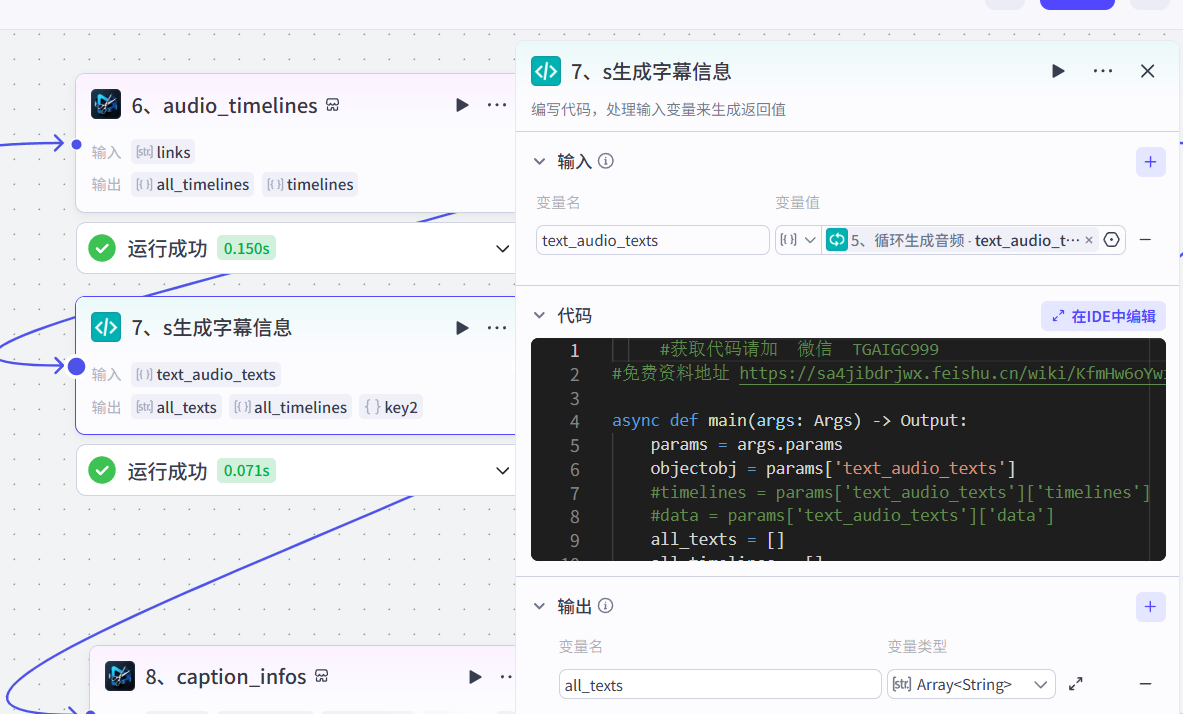
7、生成字幕信息
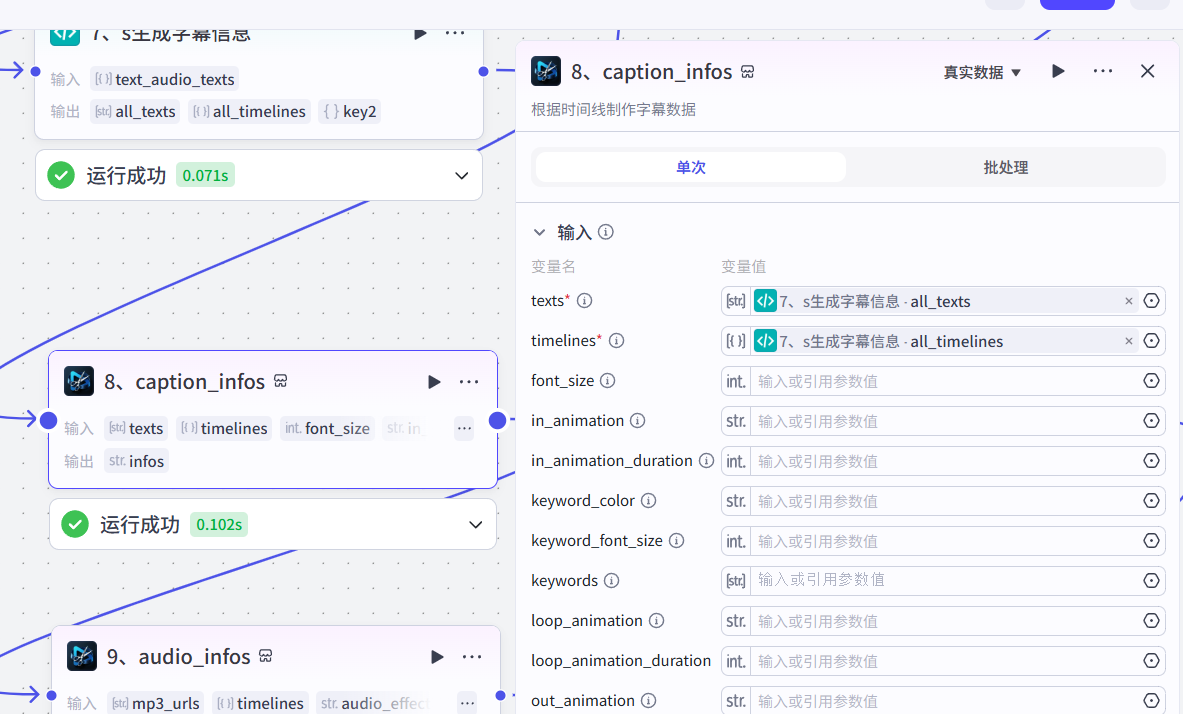
8、添加字幕信息
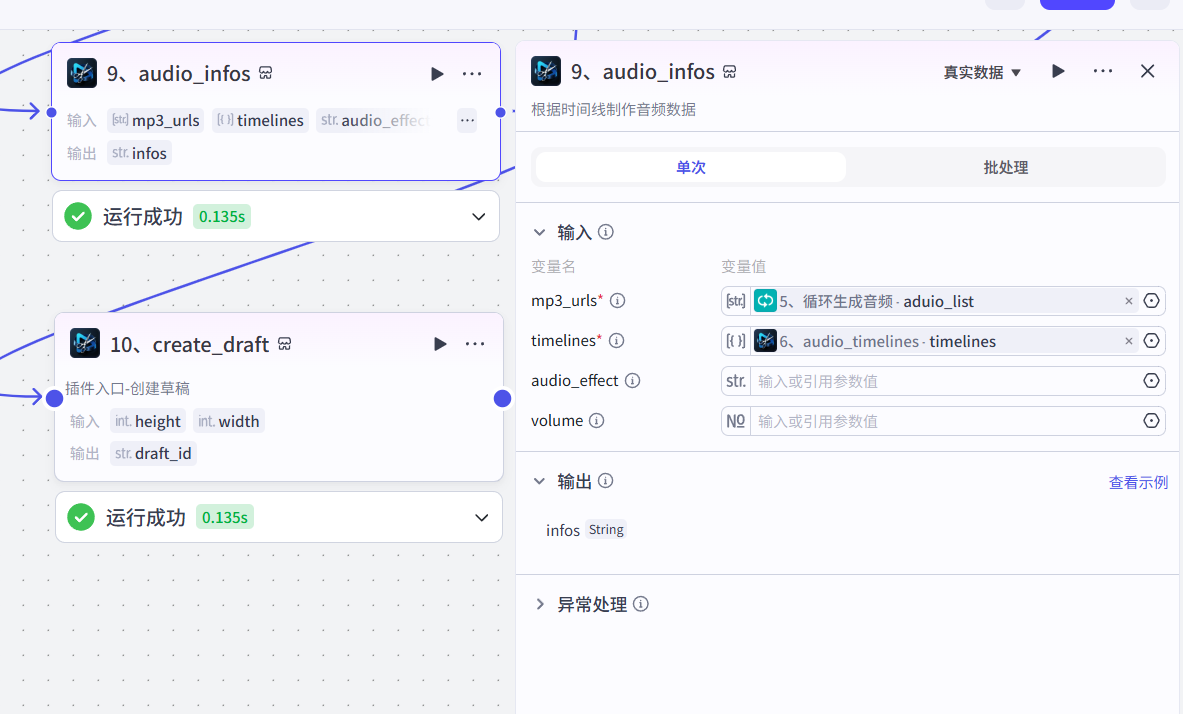
9、生成音频信息
11、添加音频
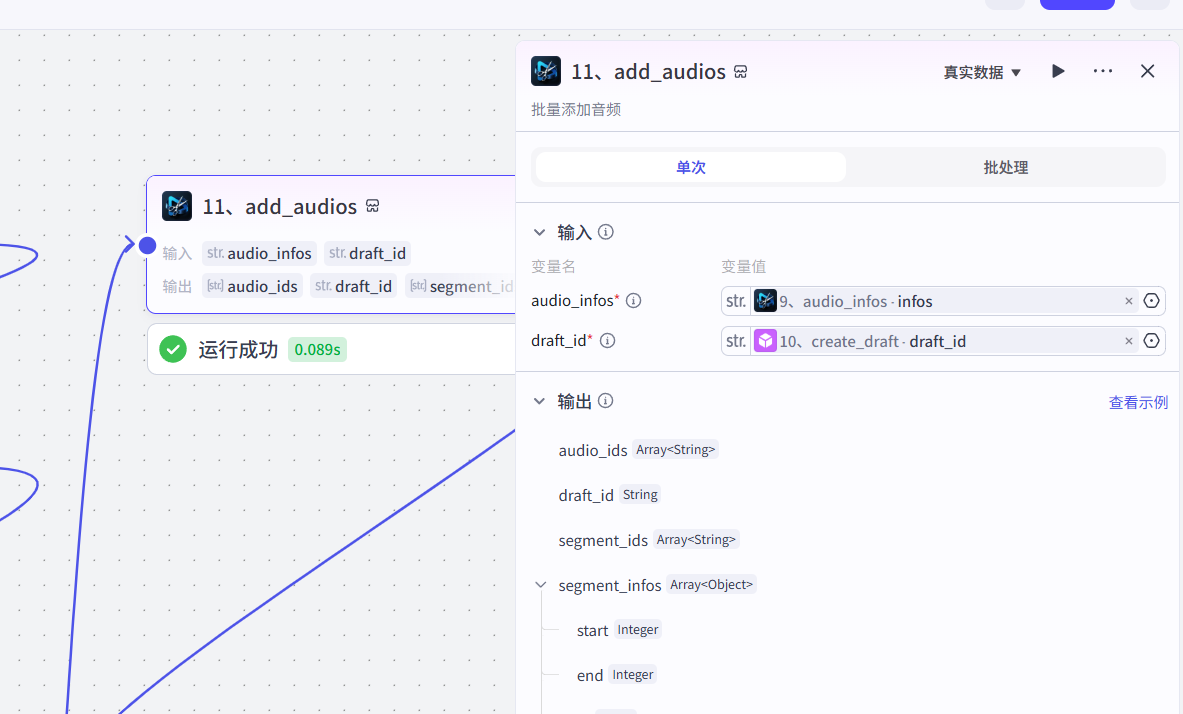
12、添加字幕
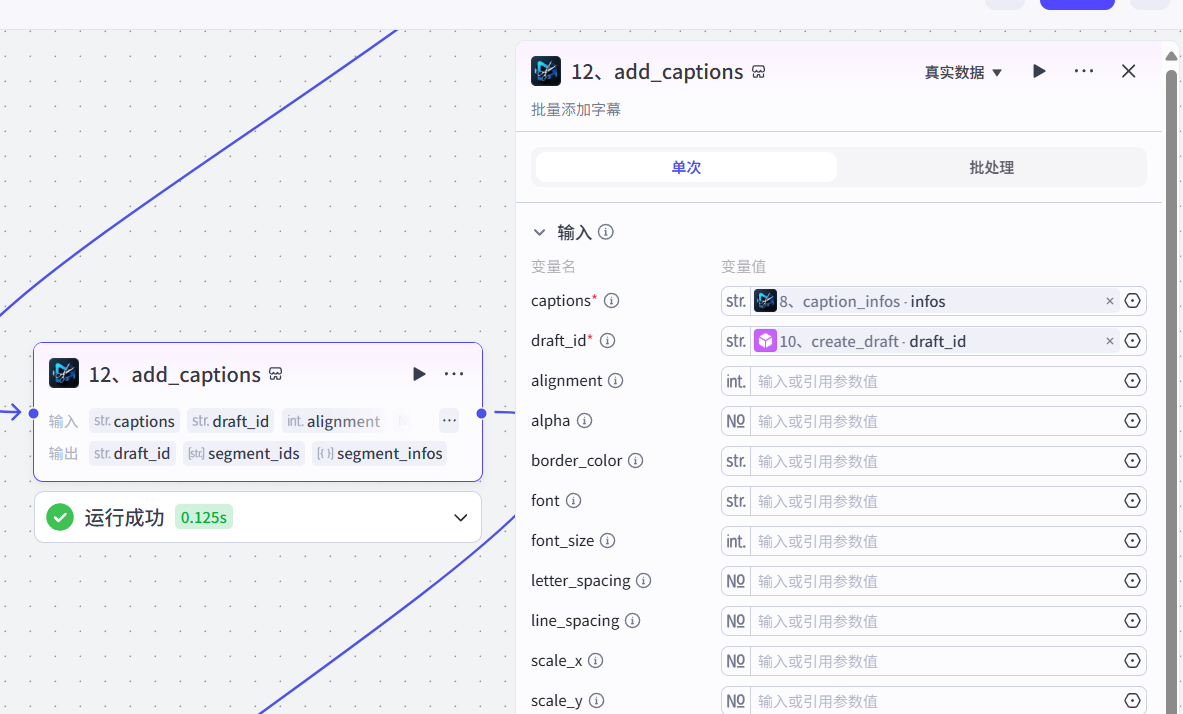
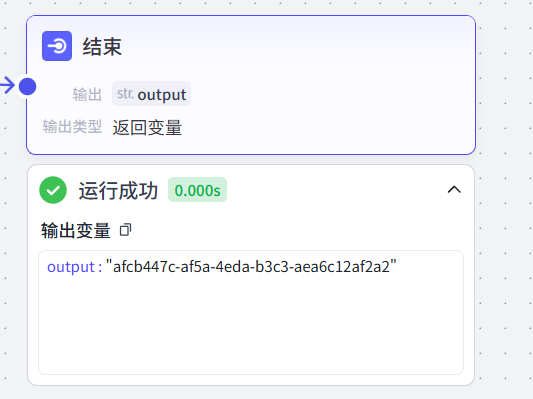
13、结束
得到剪映草稿ID
14、下载到本地
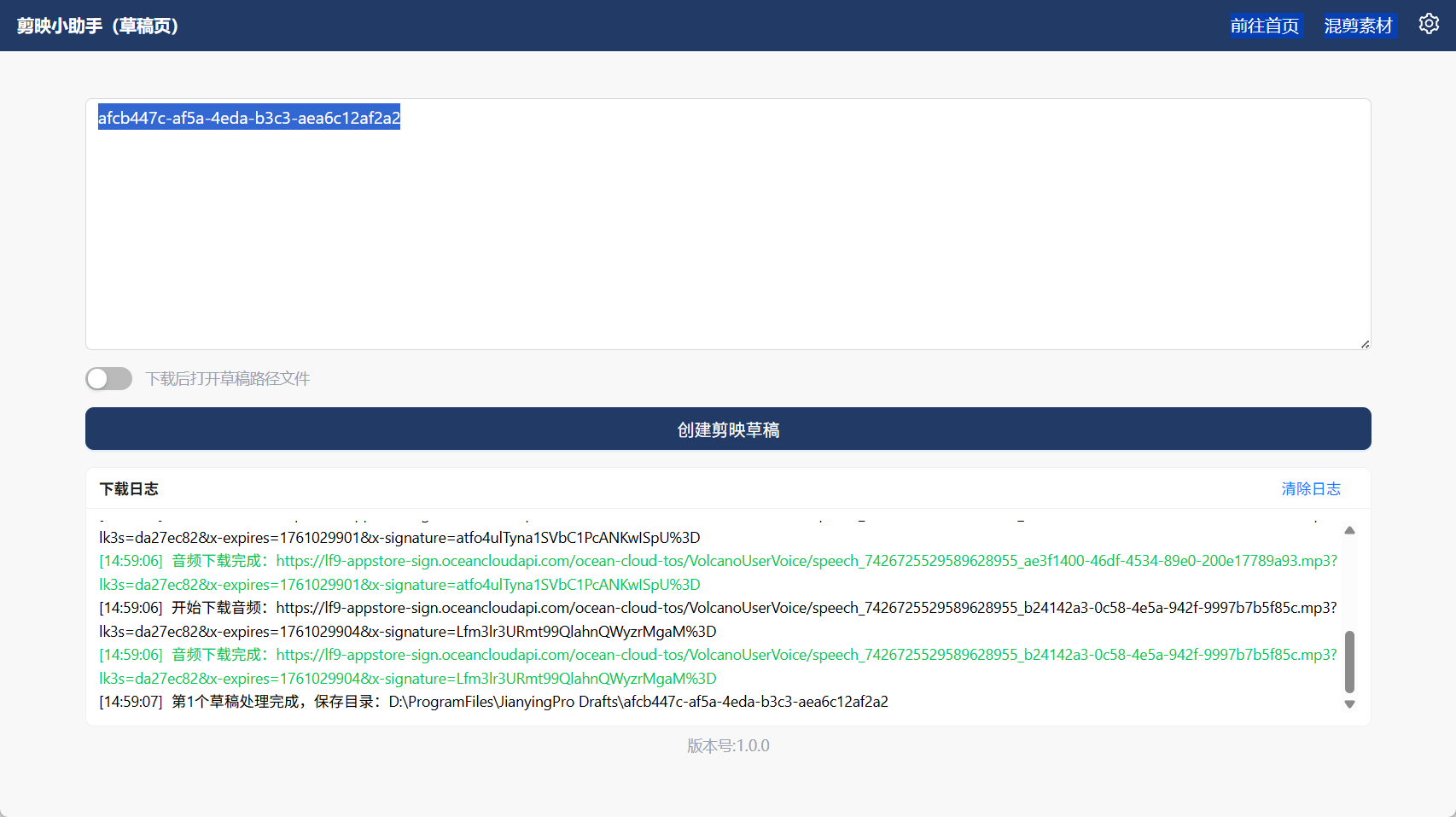
15、最终效果
我们已有工作流,并且每日更新,欢迎加入。