一套针对金融领域多模态问答的自适应多层级RAG框架-VeritasFi
现有金融 RAG 的两大痛点 :一是多模态数据(文本 / 表格 / 图表)的统一处理,二是通用金融知识与公司特异性需求的平衡。金融领域的问答(如分析 SEC 10-K 报告中的供应链风险、季度毛利率)需要 “精准结合多模态数据、兼顾通用规则与公司特性、快速响应高频查询与实时需求。
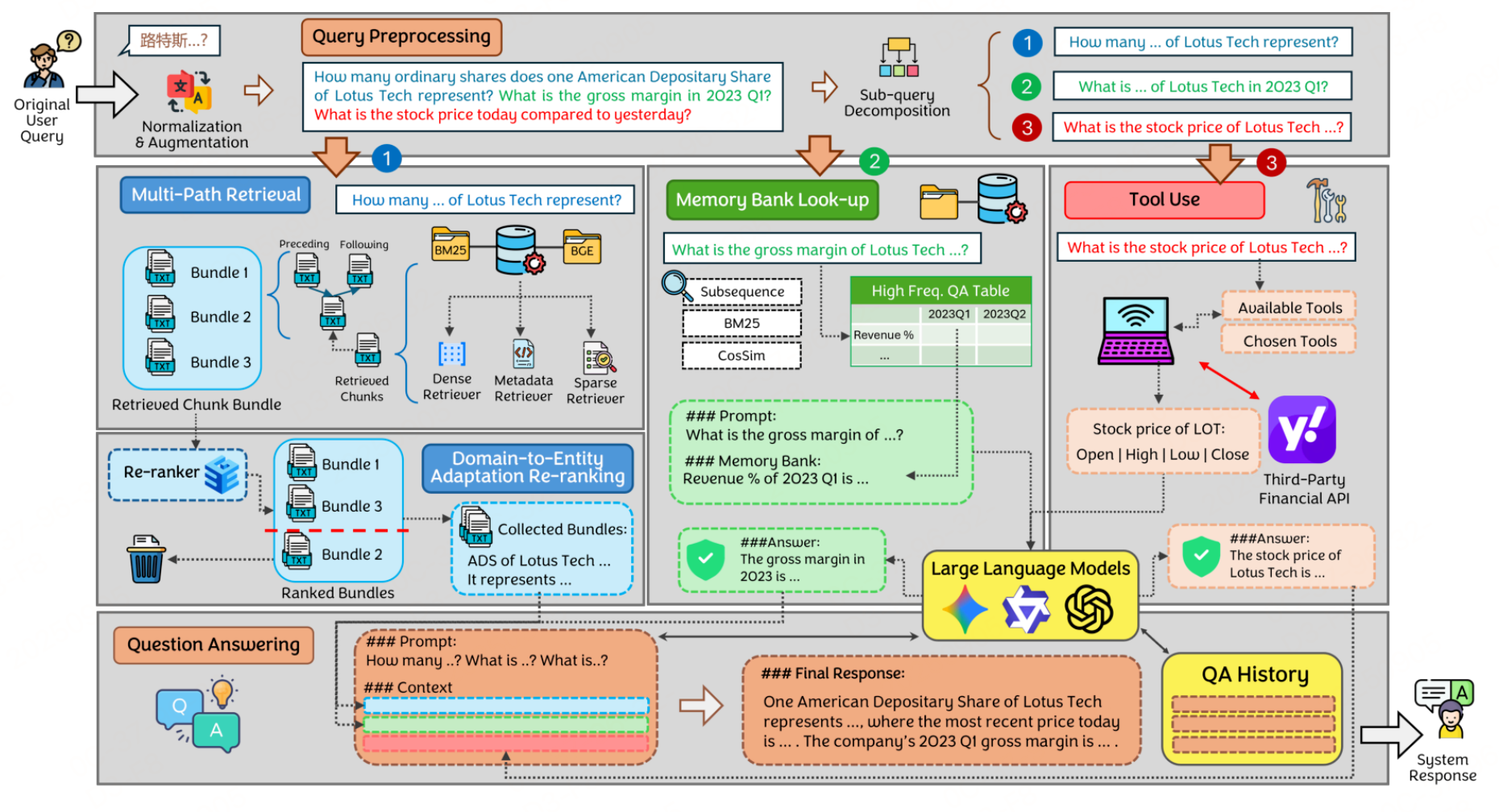
围绕金融领域多模态问答RAG框架VeritasFi展开,核心是解决“多模态数据处理”与“通用金融知识-公司特异性平衡”两大痛点,VeritasFi是端到端多层级RAG框架,针对金融场景(如SEC文件分析),通过“预处理-检索-重排序”流水线,实现问答,性能超越GraphRAG、LightRAG等基线。
- 三大核心模块:
-
CAKC(上下文感知知识处理):作为数据底座(文档解析),将“文本+表格+图表”多模态文档转为结构化知识库——先拆分文档并通过GPT-4o统一非文本模态为文本,再经去重、共指消解、元数据生成增强语义,同时构建高频记忆库(缓存定量查询答案)并完成索引。
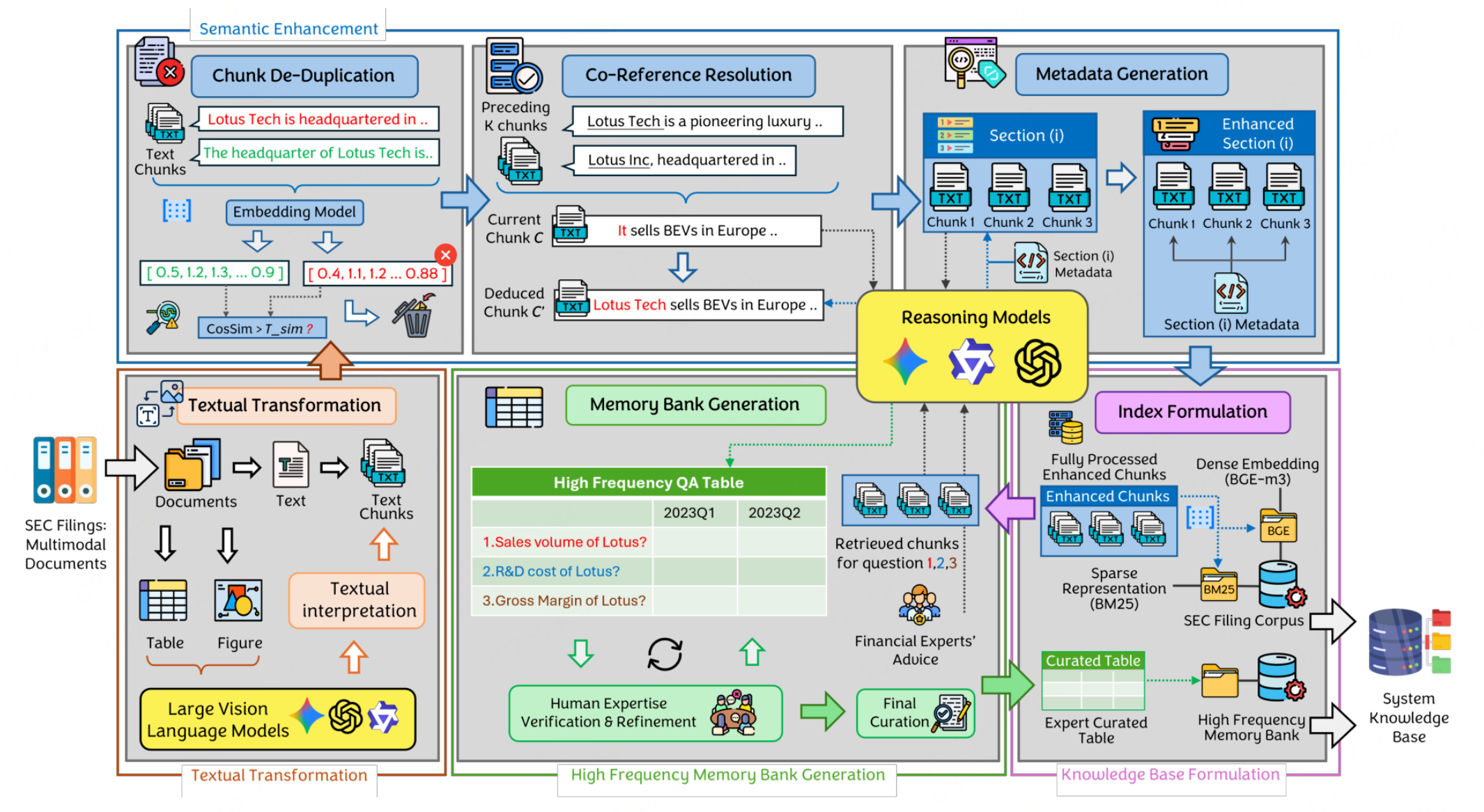
-
THR(三方混合检索):检索核心,先预处理查询(归一化、分解子查询并路由),再并行三条路径:多路径检索(BM25+Dense+元数据,深度分析文档)、高频记忆库(快速响应定量查询)、工具调用(获取实时数据,如股价),确保覆盖全面需求。
-
DAR(域到实体两阶段重排序):优化检索结果,先训通用金融重排序模型(用抽象数据掩盖实体特异性),再通过自动化标注数据微调为公司专用模型,用对比损失提升相关性判断,平衡泛化性与特异性。
-
通过多模态统一处理、三方并行检索、两阶段重排序,实现“高事实正确性+低延迟+强公司适配性”,在FinanceBench、FinQA及内部数据集(Lotus、Zeekr)上表现优异。
实验性能
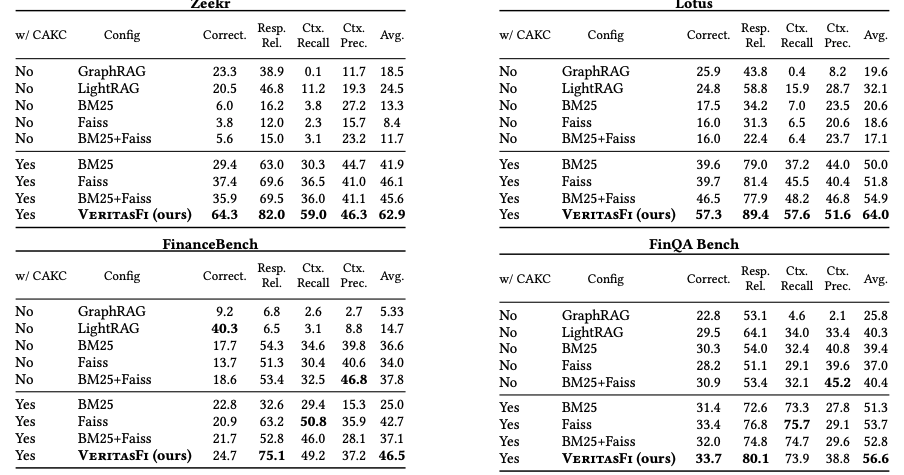
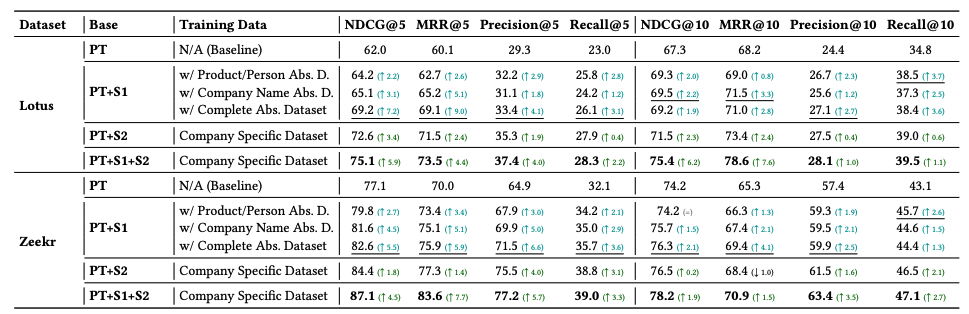
参考文献:VeritasFi: An Adaptable, Multi-tiered RAG Framework for Multi-modal Financial Question Answering,https://arxiv.org/pdf/2510.10828v1
代码暂未开源