Transformer的核心组成:编码器(Encoder)和解码器(Decoder)
Transformer 的编码器(Encoder)和解码器(Decoder)是其核心组成部分,最初由 Vaswani 等人在 2017 年的论文《Attention Is All You Need》中提出。下面我们将逐层、逐模块详细解析它们的架构、功能、数学原理和工作流程。
🌐 一、整体结构概览
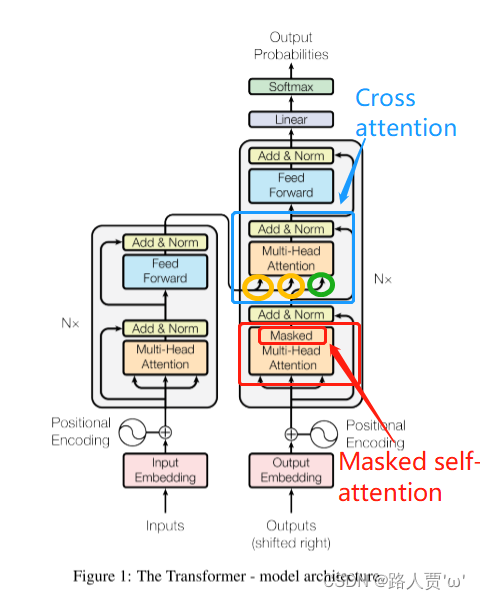
✅ Encoder-Decoder 架构主要用于序列到序列任务(Seq2Seq),如机器翻译、文本摘要等。
而像 BERT 这类模型只用 Encoder,GPT 等只用 Decoder。
🔧 二、共享基础:Positional Encoding
由于 Transformer 没有 RNN 的时序结构,必须显式引入位置信息。
公式(正弦/余弦位置编码):
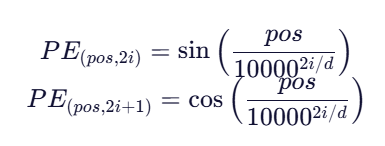
pos:token 在序列中的位置(0, 1, 2, ...)i:维度索引(0 到 d/2)d:模型隐藏维度(如 512)
✅ 位置编码与词嵌入相加后输入 Encoder/Decoder。
🏗️ 三、Encoder 详细架构(每层重复 N 次,通常 N=6)
每个 Encoder Block 包含两个子层:
1. Multi-Head Self-Attention(多头自注意力)
功能:
让每个 token 能“看到”整个输入序列,动态计算与其他 token 的相关性。
计算流程:

✅ 所有 token 并行计算,无顺序依赖。
2. Add & Norm + Feed-Forward Network(FFN)
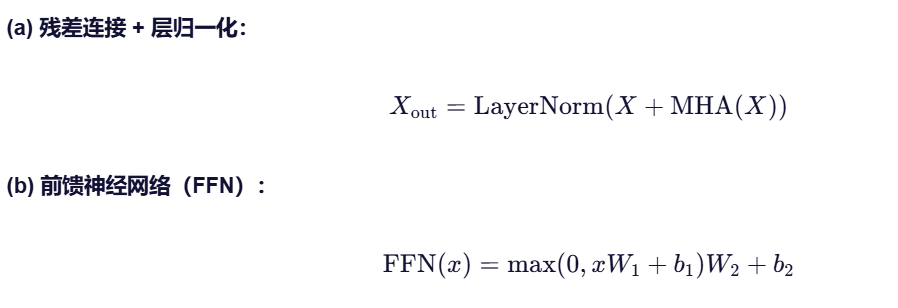
- 两层全连接,中间 ReLU
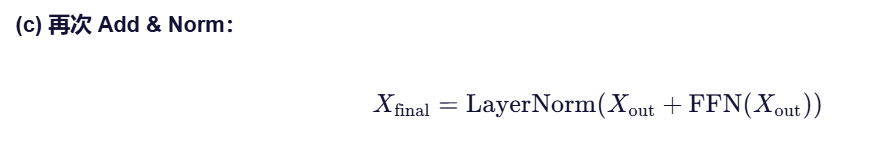
- 每个位置独立处理
- 中间维度通常为 4d4d(如 d=512 → 2048)
✅ FFN 引入非线性,增强表达能力。
🏗️ 四、Decoder 详细架构(每层重复 N 次)
每个 Decoder Block 包含三个子层:
1. Masked Multi-Head Self-Attention
与 Encoder 的区别:加了掩码(Mask)
- 在训练时,防止 Decoder “偷看”未来 token(保证自回归性质)
- 掩码方式:将未来位置的注意力分数设为 −∞,经 softmax 后为 0
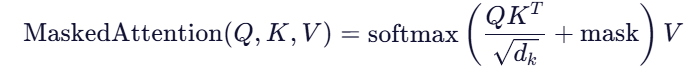
✅ 例如:预测第 3 个词时,只能看到第 1、2 个词。
2. Multi-Head Cross-Attention
功能:让 Decoder 关注 Encoder 的输出(即源序列)
- Query 来自 Decoder 的上一层输出
- Key 和 Value 来自 Encoder 的最终输出
![]()
✅ 这是 Encoder-Decoder 之间的“桥梁”,实现源-目标对齐(如翻译中“cat” → “猫”)。
3. Add & Norm + FFN(与 Encoder 相同)
- 残差连接 + LayerNorm
- FFN 结构完全一致
📊 五、Encoder vs Decoder 对比表
| 组件 | Encoder | Decoder |
|---|---|---|
| Self-Attention | 标准多头自注意力 | Masked 多头自注意力 |
| Cross-Attention | ❌ 无 | ✅ 有(Query 来自自身,Key/Value 来自 Encoder) |
| 输入 | 源序列(如英文句子) | 目标序列(如中文句子,右移一位) |
| 输出用途 | 供 Decoder 查询 | 用于预测下一个 token |
| 并行性 | 完全并行 | 训练时并行(因有目标序列),推理时自回归(逐个生成) |
🔁 六、训练 vs 推理的区别
训练阶段(Teacher Forcing):
- Decoder 输入是真实目标序列(右移一位)
- 所有 token 并行计算(因有完整目标)
- 例如:目标是
[BOS] 我 爱 你 [EOS],输入为[BOS] 我 爱 你,预测我 爱 你 [EOS]
推理阶段(自回归生成):
- 每次只生成一个 token
- 将已生成的 token 作为下一次输入
- 速度慢,但无需真实标签
🧠 七、参数规模示例(原始 Transformer)
| 参数 | 数值 |
|---|---|
| 层数(Encoder/Decoder) | 6 |
| 隐藏维度 dd | 512 |
| 注意力头数 | 8 |
| FFN 中间维度 | 2048 |
| 词汇表大小 | 37000 |
| 总参数量 | ≈ 60M |
✅ 八、总结:核心思想
| 模块 | 作用 |
|---|---|
| Encoder | 将输入序列编码为富含上下文的表示,供 Decoder 查询 |
| Decoder | 1) 自回归生成输出;2) 通过 cross-attention 聚焦源序列相关信息 |
| Self-Attention | 捕捉序列内部依赖 |
| Cross-Attention | 实现源-目标对齐 |
| Positional Encoding | 引入顺序信息 |
| 残差 + LayerNorm | 支持深层网络训练 |
📌 附:现代变体
- BERT:仅用 Encoder,用于理解任务(分类、问答)
- GPT:仅用 Decoder(无 cross-attention),用于生成任务
- T5 / BART:Encoder-Decoder,用于生成式 NLP(摘要、翻译)
- Vision Transformer (ViT):将图像视为序列,用纯 Encoder 处理