MySQL的中继日志(relay-log)的实践
目录
1、中继日志
1.1、定义
1.2、作用
1.3、工作原理
1.4、对比
2、binlog
2.1、格式
2.2、交互流程
2.3、查看命令
2.4、实际应用
2.5、注意事项
前言
在高可用、读写分离、数据灾备等现代数据库架构中,MySQL 主从复制(Replication) 几乎是标配。
如下所示:
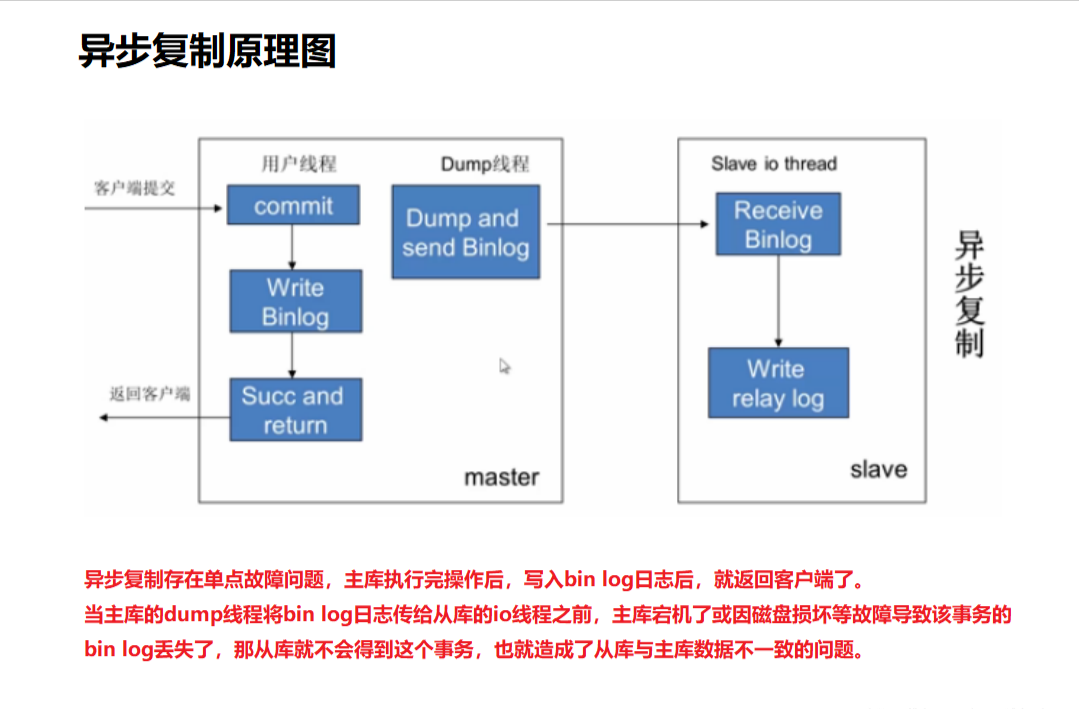
你可能已经熟悉 binlog(二进制日志)作为主库的“操作记录仪”,但你是否思考过:
从库是如何安全、高效地“拿到”并“重放”这些变更的?
答案的关键,藏在一个常被忽视却至关重要的组件中——中继日志(Relay Log)。
中继日志是 MySQL 从库(Slave/Replica)上的临时日志文件,它充当了主库 binlog 与从库数据之间的“中转站”。没有它,主从复制将无法实现异步、可靠的数据同步。
以下是对中继日志的详细介绍:
1、中继日志
1.1、定义
是 MySQL 主从复制(Replication)机制中的一个关键组件。
如下所示:

主要用于从服务器(Slave/Replica)。从服务器用来暂存主服务器二进制日志事件的中间日志文件,是实现异步复制的关键缓冲区。 它解耦了“接收日志”和“执行日志”两个过程,提高了复制的稳定性和灵活性。
中继日志相关文件:在从服务器的数据目录下。
通常会看到如下文件:
- relay-log.info:记录当前中继日志的执行位置(类似 master.info)。
主机名-relay-bin.00001等:实际的中继日志文件。主机名-relay-bin.index:记录所有中继日志文件的索引。
⚠️注意:
可通过show slave status查看中继日志的读取(Relay_Log_File, Relay_Log_Pos)和执行位置(Exec_Master_Log_Pos)。
1.2、作用
临时存储从主服务器(Master)接收到的二进制日志(Binary Log)事件,供从服务器的 SQL 线程回放执行,从而实现数据同步。
如下所示: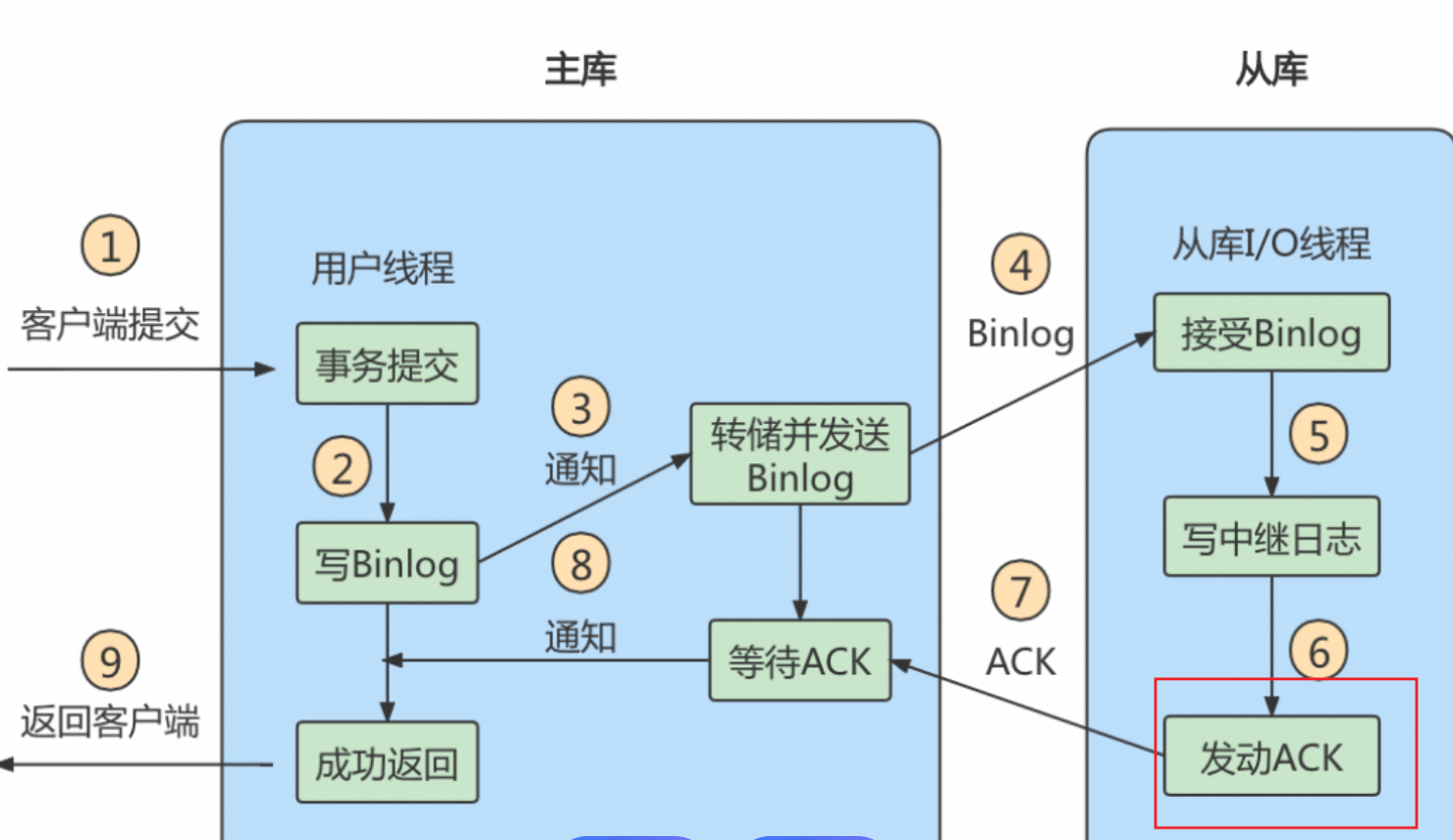
注意事项
会占用磁盘空间,如果从服务器长时间无法应用(如 SQL 线程报错停止),中继日志可能不断累积。
1.3、工作原理
在 MySQL 主从复制架构中,复制过程通常包含2个线程(在从服务器上):
如下所示: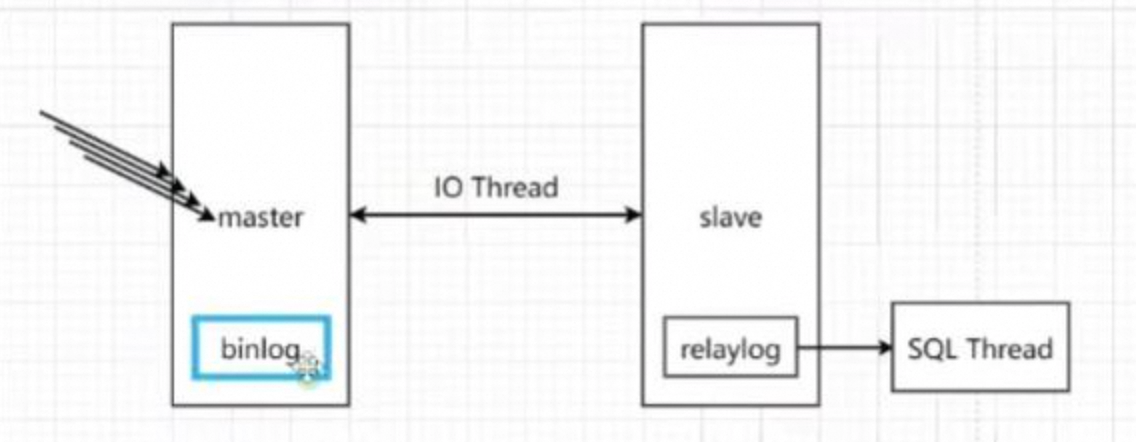
1、I/O 线程(I/O Thread):
连接到主服务器,请求并接收主服务器的二进制日志事件。将这些事件写入本地的**中继日志(Relay Log)**文件中。
2、SQL 线程(SQL Thread):
读取中继日志中的事件。在从服务器上依次执行这些事件(如 INSERT、UPDATE、DELETE 等),使从服务器的数据与主服务器保持一致。
注:在 MySQL 5.6+ 中,还可以启用多线程复制(基于数据库或基于逻辑时钟),此时会有多个 SQL 线程并行执行中继日志中的事件。
1.4、对比
如下所示:
| 项目 | 二进制日志(Binary Log) | 中继日志(Relay Log) |
|---|---|---|
| 存在位置 | 主服务器(也可在从服务器上开启) | 仅存在于从服务器 |
| 内容来源 | 本地执行的写操作(DML/DDL) | 从主服务器复制过来的二进制日志事件 |
| 用途 | 数据恢复、主从复制的数据源 | 供从服务器 SQL 线程回放,实现数据同步 |
| 文件格式 | 二进制格式,可通过 mysqlbinlog 查看 | 格式与二进制日志几乎相同 |
2、binlog
2.1、格式
在 MySQL 中,binlog 的默认格式取决于 MySQL 的版本。
以下是各主要版本的默认 binlog_format:
| MySQL 版本 | 默认 binlog_format |
|---|---|
| MySQL 5.7.7 之前 | statement |
| MySQL 5.7.7 及之后(包括 5.7.7) | row |
| MySQL 8.0 | row |
2.2、交互流程
IO 线程 + SQL 线程的分工是固定的,与 binlog 格式无关。
如下所示:
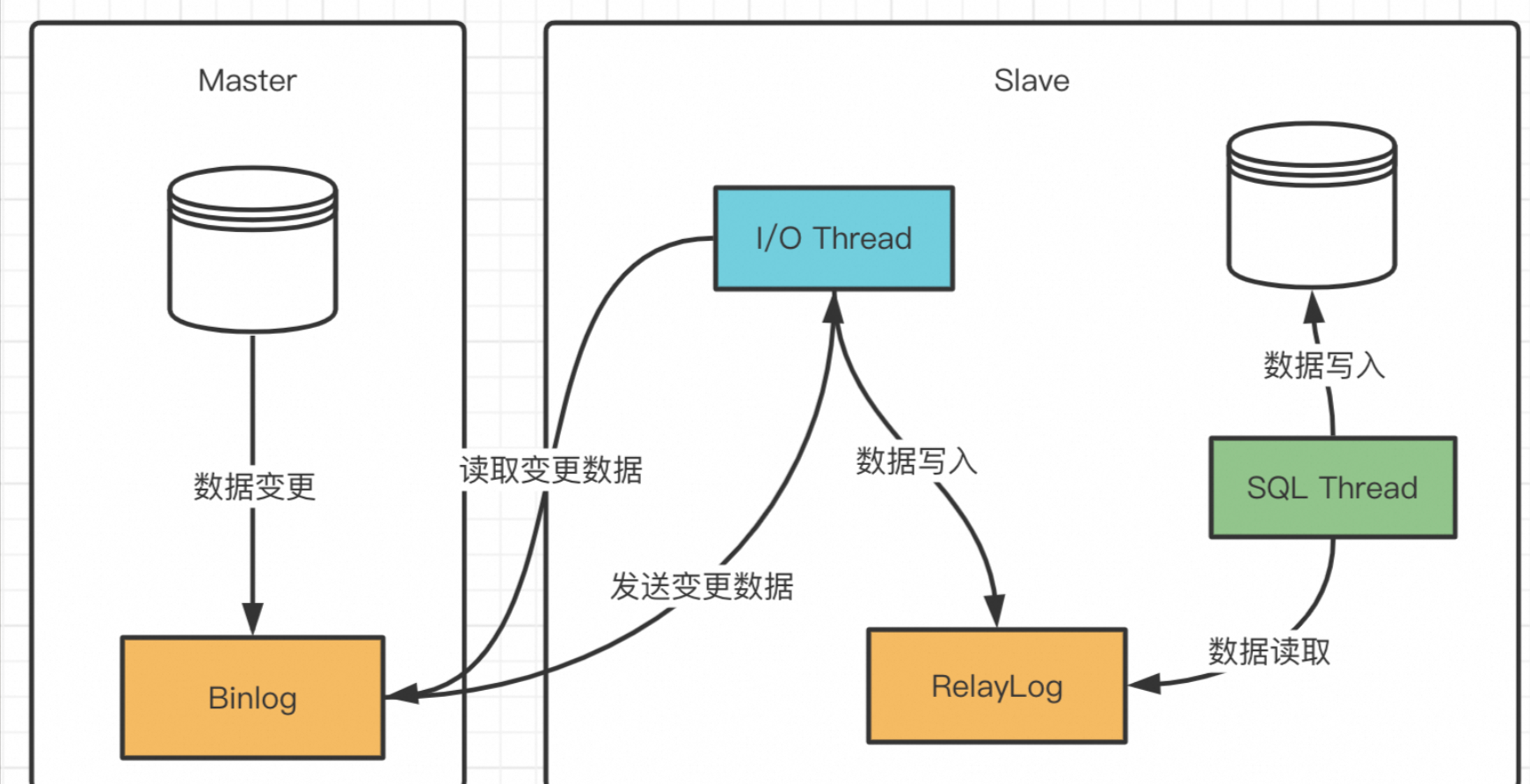
当binlog的日志格式是不同类型的时候,SQL线程的工作模式,如下:
| 格式 | SQL 线程如何执行 |
|---|---|
| statement | 直接执行 SQL 语句(如 insert into...)。 ⚠️ 有风险:如果语句包含 NOW()、Rand() 等非确定性函数,主从可能不一致。 |
ROW | 不执行原始 SQL,而是逐行应用数据变更。 ✅ 更安全、一致性更强,但日志体积更大。 |
MIXED | MySQL 自动在 statement 和 row 之间切换。 SQL 线程会根据每个事件的实际格式来决定如何执行。 |
2.3、查看命令
如下所示:
SHOW VARIABLES LIKE 'binlog_format';输出示例:+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| binlog_format | ROW |
+---------------+-------+binlog_format 是一个动态变量,可以在会话级别或全局级别修改(需 SUPER 权限):
代码如下所示:
SET GLOBAL binlog_format = 'ROW';
-- 或
SET SESSION binlog_format = 'STATEMENT';
2.4、实际应用
生产环境推荐使用 row 格式。
为什么 MySQL 改为默认使用 row?
1、更强的一致性保障:
避免 statement 模式下因非确定性函数(如 now(), Rand(), UUID())导致主从数据不一致。
2、更精确的变更记录:
row 记录的是实际修改的行,便于审计、闪回、数据恢复。
3、支持更多复制特性:
如并行复制(基于主键的并行回放)、GTID 安全性等。
4、减少复制错误:
很多在 statement 模式下会失败的语句(如涉及临时表、自定义函数),在 row 模式下可以安全复制。
| 格式 | 记录内容 | 本质 |
|---|---|---|
| statement | 原始 SQL 语句(update t set a =now()) | 记录“操作过程” |
| row | 实际被修改的行数据(如 “将 id=1 的行 a 字段从 NULL 改为 '2024-06-01 10:00:00'”) | 记录“操作结果” |
关键区别:
- statement 模式下,从库要重新执行 SQL,依赖执行环境(函数、变量、数据状态等);
- row 模式下,从库直接应用数据变更,不关心 SQL 是怎么写的,只关心“改成了什么”。
为什么 statement 容易导致主从不一致?
场景 1:非确定性函数
UPDATE users SET last_login = NOW() WHERE id = 1;
- 主库执行时间:2024-06-01 10:00:00
- 从库执行时间(延迟 2 秒):2024-06-01 10:00:02
- ❌ 结果:主从 last_login 值不同!
其他类似函数:Rand(), UUID() 等。
2024-06-01 10:00:00
场景 2:依赖当前会话变量
SET @counter = 1;
UPDATE logs SET seq = @counter := @counter + 1;
- 主库 @counter 从 1 开始;
- 从库是另一个会话,@counter 可能未定义或值不同;
- 结果:主从 seq 值序列不一致。
场景 3:WHERE 条件依赖当前数据状态
假设主库和从库在复制前已有微小差异(比如某行被误删):
UPDATE t SET status = 'done' WHERE create_time < '2024-01-01';
- 主库匹配 100 行;
- 从库因数据缺失只匹配 99 行;
- ❌ 结果:主从数据进一步偏离。
这种“雪崩效应”在 statement 模式下很难避免。
为什么 row 能避免这些问题?
在 row 模式下,上述例子的 binlog 记录如下:
示例:update users set last_login = now() where id =1 ;
binlog 中实际记录的是:
Table: users
Before Image: {id: 1, last_login: NULL}
After Image: {id: 1, last_login: '2024-06-01 10:00:00'}
从库收到后,直接将 id=1 的行的 last_login 改为 '2024-06-01 10:00:00',完全不调用NOW()!
结果:主从数据绝对一致。
同理:
- Rand()、UUID() 等函数的结果在主库执行时已确定,row 直接记录结果值;
- 会话变量的影响在主库执行时已体现为具体数据,从库只改数据,不重跑逻辑;
- 即使从库数据有差异,row 模式会严格按主库的行变更来覆盖(前提是主键存在且一致)。
2.5、注意事项
虽然 row 更安全,但日志体积通常更大(尤其在批量 UPDATE/DELETE 时)。某些工具(如旧版 pt-table-checksum)在 row 模式下可能需要额外配置。如果你的应用依赖基于语句的复制(极少见),才考虑用 statement 或
MIXED。
总结
中继日志以其独特的缓冲和同步机制,默默地支撑着 MySQL 复制的稳定运行。它让我们无需担心主从之间的瞬时网络延迟,也使得从库的 SQL 线程能够以更灵活、更健壮的方式处理数据变更。
参考文章:
1、https://blog.csdn.net/GreatSQL2021/article/details/128608814?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522615f55cc5a74aee5a4199803aceb8995%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=615f55cc5a74aee5a4199803aceb8995&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-2-128608814-null-null.142^v102^control&utm_term=%E4%B8%AD%E7%BB%A7%E6%97%A5%E5%BF%97%EF%BC%88relay%20log%EF%BC%89&spm=1018.2226.3001.4187![]() https://blog.csdn.net/GreatSQL2021/article/details/128608814?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522615f55cc5a74aee5a4199803aceb8995%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=615f55cc5a74aee5a4199803aceb8995&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-2-128608814-null-null.142^v102^control&utm_term=%E4%B8%AD%E7%BB%A7%E6%97%A5%E5%BF%97%EF%BC%88relay%20log%EF%BC%89&spm=1018.2226.3001.4187
https://blog.csdn.net/GreatSQL2021/article/details/128608814?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522615f55cc5a74aee5a4199803aceb8995%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=615f55cc5a74aee5a4199803aceb8995&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-2-128608814-null-null.142^v102^control&utm_term=%E4%B8%AD%E7%BB%A7%E6%97%A5%E5%BF%97%EF%BC%88relay%20log%EF%BC%89&spm=1018.2226.3001.4187