深度学习模型训练的一些常见指标
一、回归任务指标(预测连续值,如房价、温度)
回归任务的核心是衡量「模型预测值与真实值的误差大小」,常用指标如下:
1. MSE(Mean Squared Error,均方误差)
核心含义:计算预测值与真实值「差值的平方」的平均值,惩罚较大误差(平方放大了大误差的影响)。
计算公式:

其中 n是样本数量。
特点:
优点:可导、数学性质好,便于梯度下降优化(MLP 等神经网络训练常用)。
缺点:对异常值敏感(异常值的差值平方会显著拉高 MSE)。
适用场景:常规回归任务(如预测销量、股价),且数据中异常值较少的场景。
2. MAE(Mean Absolute Error,平均绝对误差)
核心含义:计算预测值与真实值「差值的绝对值」的平均值,对异常值更鲁棒(无平方放大)。
计算公式:

特点:
优点:对异常值不敏感,直观反映平均误差大小(单位与目标值一致)。
缺点:在误差为 0 处不可导,需用次梯度优化(部分场景下收敛效率略低于 MSE)。
适用场景:数据中存在较多异常值的回归任务(如预测用户消费金额,可能有少数高额消费异常值)。
3. RMSE(Root Mean Squared Error,均方根误差)
核心含义:对 MSE 开平方,将误差单位转换为与目标值一致(解决 MSE 单位 “平方化” 的问题)。
计算公式:
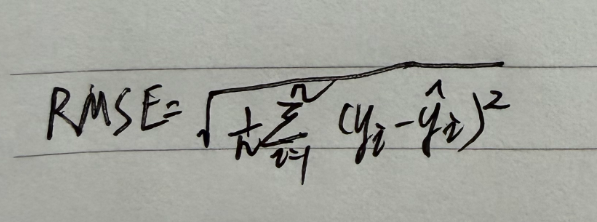
特点:继承 MSE 对大误差的惩罚性,同时单位与真实值一致(如真实值是 “元”,RMSE 也是 “元”),更易解释。
适用场景:需要直观理解误差大小的回归任务(如预测房屋面积,RMSE=5 表示平均误差 5 平方米)。
4. R^2(决定系数)
核心含义:衡量模型「解释真实值变异」的能力,取值范围 (−∞,1],越接近 1 说明模型拟合效果越好。
计算公式:
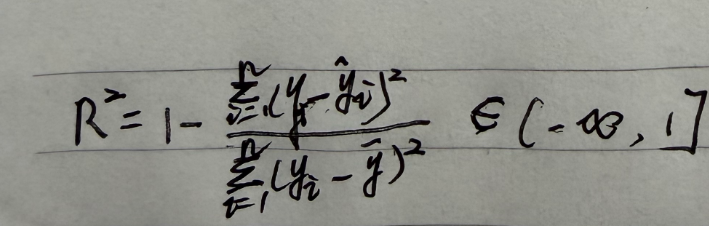
特点:不仅能反映误差,还能对比模型相对于 “基准(均值)” 的提升,适合评估模型的整体拟合能力。
适用场景:需要量化模型解释力的场景。
以上主要是回归任务的一些指标信息(拟合任务)
对于分类任务,我们主要的指标包括准确率,精确率,召回率三种.
1. 准确率(Accuracy)
核心含义:预测正确的样本数占总样本数的比例,最直观的分类指标。
2. 精确率(Precision)与召回率(Recall)
核心含义:解决类别不平衡问题,分别从 “预测准确性” 和 “真实覆盖性” 两个维度评估模型:
精确率(查准率):预测为正类的样本中,真实为正类的比例(关注 “预测对的正类占比”,避免误判)。
召回率(查全率):真实为正类的样本中,被预测为正类的比例(关注 “真实正类被找到的比例”,避免漏判)。
3. F1-Score
核心含义:精确率和召回率的「调和平均数」,综合两者的性能,避免单一指标的偏差。
第一个比较明确,但是精确率和召回率有点难以理解,因为我们的分类任务可能是多分类任务,此时我们去预测图片中的结果.此时有以下四种预测的结果:
真实情况 \ 预测结果 预测为 “猫”(正类预测) 预测为 “狗 / 鸟 / 车”(负类预测)
真实是 “猫”(正类) 真阳性(TP):模型对了 假阴性(FN):模型漏判了
真实是 “狗 / 鸟 / 车”(负类) 假阳性(FP):模型误判了 真阴性(TN):模型对了
此时每个类别都会有自己的精确率和召回率了.
举具体数据(假设模型预测结果):
25 张真实猫图:20 张被正确预测为 “猫”(TP=20),5 张被误判为 “狗 / 鸟”(FN=5);
75 张真实非猫图(狗 + 鸟 + 车):8 张被误判为 “猫”(FP=8),67 张被正确预测为 “狗 / 鸟 / 车”(TN=67)。
精确率(猫类):预测为 “猫” 的样本中,真实是 “猫” 的比例 → 20/(20+8)=71.4%(说明模型判为 “猫” 的图里,7 成多真的是猫,误判少);
召回率(猫类):真实是 “猫” 的样本中,被正确预测为 “猫” 的比例 → 20/(25)=80%(说明 8 成的真实猫图被模型找到了,漏判少)。