RAG(检索增强生成)详解:让大模型更“博学”更“靠谱”
1. 什么是 RAG?为什么需要它?
想象一下,你是一位学识渊博的专家,但被关在了一个没有互联网、没有书籍、没有最新资料的房间里。别人问你关于最近新闻或者某家公司内部文件的问题,你只能依靠自己的记忆(即模型训练时学到的知识)来回答,这显然不够准确和及时。
这就是传统大语言模型(如 ChatGPT 基于 GPT-3.5/4)的核心局限:
-
知识滞后性 (Static Knowledge): 模型的训练数据有截止日期,无法知晓之后的事件。
-
幻觉问题 (Hallucination): 当模型遇到其训练数据中未包含的内容时,可能会“编造”出看似合理但实则错误的答案。
-
无法访问私有/域外知识 (No Access to Private Data): 模型无法看到你的个人文档、公司内部wiki、数据库等非公开信息。
RAG (Retrieval-Augmented Generation,检索增强生成) 就是为了解决这些问题而诞生的。它相当于给这位“专家”配了一个强大的外部知识库助理和一套高效的检索工具。每当有问题来时,助理会先快速地去资料库(知识库)里查找最相关的资料,然后把资料和问题一起交给专家,专家再基于这些最新的、准确的资料来组织语言回答问题。
核心价值: 将LLM的通用推理能力与外部知识源的信息相结合,生成更准确、可追溯、时效性强的答案。
2. RAG 的工作流程(图文解析)
RAG 的工作流程可以清晰地分为两个主要阶段:数据索引准备(Indexing) 和 运行时检索与生成(Retrieval & Generation)。
为了更直观地理解,我们先来看一张全局的工作流程图,它清晰地展示了RAG如何将外部知识库与LLM的生成能力相结合:
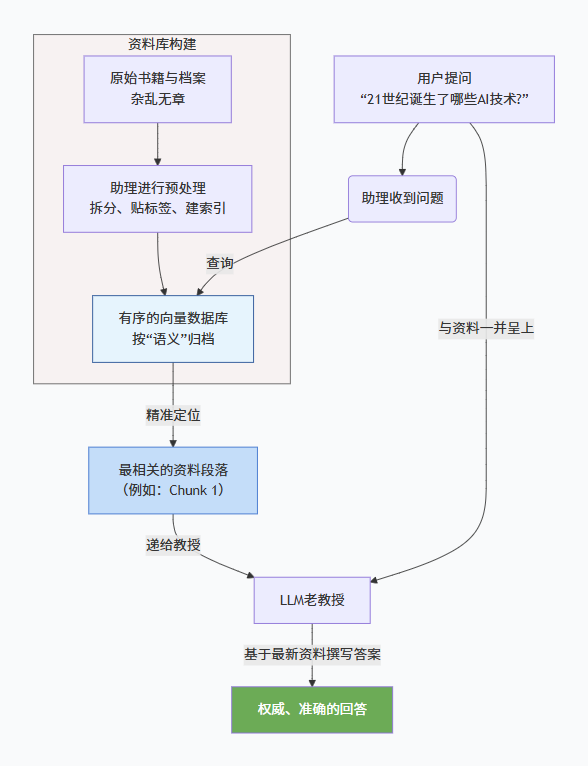
上述流程可以分解为以下几个关键环节:
阶段一:数据索引准备 (Indexing) - “修建图书馆”
这个阶段是离线进行的,目的是将杂乱无章的原始数据整理成一个LLM可以快速查询的结构化“图书馆”(即向量数据库)。
-
加载数据 (Loading): 从各种数据源(如PDF、Word、PPT、MySQL、网页、公司内部文档等)获取原始数据。
-
分割文档 (Splitting):将加载的长文档拆分成更小的、语义上有意义的“块”(Chunks)。这是因为LLM有上下文长度限制,且小块信息更易于精准检索。
-
嵌入向量化 (Embedding):使用嵌入模型(Embedding Model)(如
text-embedding-ada-002、BGE、M3E)将每个文本块转换成一个高维数值向量(Vector)。这个向量可以理解为该文本片段的“数学指纹”,语义相近的文本指纹也相近。 -
存储向量 (Storing): 将上一步生成的所有“向量-文本”对存储到向量数据库(Vector Database) 中。常见的向量数据库有
Chroma、Pinecone、Weaviate、Qdrant等
阶段二:运行时检索与生成 (Retrieval & Generation) - “问答过程”
这个阶段是在用户提问时实时发生的。
-
检索 (Retrieval)
-
用户提问: 用户提出一个问题(Query)。
-
查询向量化: 使用同一个Embedding模型将用户的问题也转换为一个查询向量(Query Vector)。
-
相似性搜索: 将这个查询向量送到向量数据库中,进行相似度计算(通常使用余弦相似度等度量方法),找出与问题最相关的 Top-K 个文本块。
-
-
增强 (Augmentation)
-
内容: 将上一步检索到的Top-K个文本块(Context)和用户的原始问题(Query)组合成一个增强后的提示(Prompt),递给大语言模型(LLM)。
-
提示词模板(Prompt Template)示例:
请严格根据以下提供的信息来回答问题。如果信息中不包含答案,请直接说“根据已有资料无法回答该问题”,不要编造。【提供的资料】 {context}【问题】 {question}
-
-
生成 (Generation)
-
内容: LLM接收到这个精心设计的Prompt后,它会严格遵守指令,基于提供的资料(Context)而不是仅凭内部记忆来生成答案(Answer)。
-
优势: 答案质量高、来源可追溯(可注明引用来源)、极大减少幻觉。
-