大模型后训练(Post-Training)指南
看到一篇博客,写的不错,原文:A hitchhiker’s guide into LLM post-training,https://tokens-for-thoughts.notion.site/post-training-101
本文仅作译记录。
概述
本文档旨在作为理解大语言模型(LLM)后训练基础的指南,涵盖了从预训练模型到指令微调模型的完整流程。指南将梳理后训练的全生命周期,探讨以下内容:
- 从“下一个token预测”到“指令遵循”的转变过程
- 有监督微调(Supervised Fine-Tuning, SFT)基础,包括数据集构建与损失函数
- 各类强化学习技术(RLHF、RLAIF、RLVR)及奖励模型的详细解析
- 用于评估模型质量的评估方法
1. 从预训练模型到指令微调模型的过程
基础模型(或预训练模型)通常通过在大规模文本和图像数据上进行预训练得到[1][2]。预训练的核心目标是将世界(狭义上指互联网)的知识编码到模型中,其训练目标非常直接:让模型在大量不同序列上学习预测“下一个token”[1]。然而,尽管基础模型可能具备丰富知识,但“下一个token预测”的训练目标使其在多数实际应用中实用性较低[3]。
下图(图1)的概念对比可帮助您大致理解两类模型的行为差异。当输入相同的问题——“What is the capital city of U.S”(注意此处用户输入末尾没有问号)时:
- 左侧的预训练模型(因训练目标是预测下一个token)会先预测出问号(即“?”),再继续完成后续句子;
- 右侧的指令微调模型则会直接回答“华盛顿哥伦比亚特区(Washington, D.C.)”,因为这类模型的训练目标通常是响应用户问题,而非延续文本[4]。
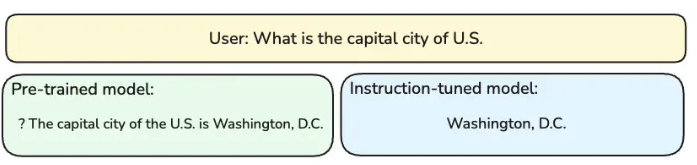
图1:从预训练到指令微调模型的过程
为让大语言模型(LLM)能真正助力回答问题,我们通常会以基础模型为起点,进行后训练(也称为微调)。与预训练使用的互联网爬取文本语料不同,后训练数据的规模通常小得多,且经过更精心的筛选[5]。后训练的目的是让模型行为与需求对齐(具备有用性、诚实性、无害性),并提升其在预训练阶段已初步具备的能力。目前主流的后训练技术包括有监督微调(SFT)、基于人类反馈的强化学习(RLHF)等。在DeepSeek R1模型[6]推出后,基于可验证奖励的强化学习(RLVR)技术逐渐兴起,该技术在提升模型推理和代码能力方面效果显著[7]。
后续章节将深入探讨这些技术的细节。
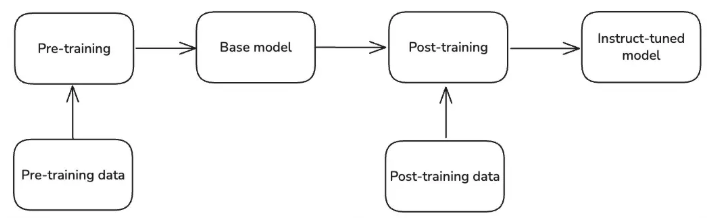
图2:从预训练到指令微调模型的过程
有时您可能还会听到“持续预训练(continued pre-training)”或“中期训练(mid-training)”等术语。这些属于非官方(或较不正式)的表述,指的是在高质量数据集和/或特定领域语料上对基础模型进行进一步预训练,以提升模型在这些特定领域的能力。由于预训练并非本文重点,此处不展开详述。
2. 后训练的端到端(E2E)生命周期
从宏观角度看,后训练是将基础模型转化为对用户既有帮助又安全的指令微调模型的过程(图3)。后训练通常主要包含两类训练技术:有监督微调(SFT)和强化学习(RL)[4]。在Instruct-GPT(GPT-3.5的前身)问世时,OpenAI提出了包含SFT和RLHF两个阶段的后训练流程[3]。2024年,深度求索(DeepSeek)推出DeepSeek V3模型,该模型大量采用RLVR技术——其中“VR”代表可验证奖励(也称为基于规则的奖励或准确性奖励)[8]。随后,深度求索又发布了R1模型,提出“R1-zero”方案(直接在基础模型上应用强化学习),以及最终的R1模型(采用两阶段强化学习:(1)面向推理的强化学习,(2)“全场景”强化学习(与人类偏好对齐))[6]。后训练领域的研究仍在快速发展——随着研究社区不断取得突破,所谓的“最佳实践”往往会很快被新方法取代。
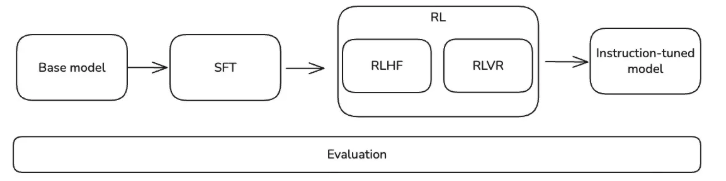
图3:后训练的端到端生命周期
无论是SFT阶段还是RL阶段,大部分核心工作都围绕后训练数据的构建与实验展开。这些数据既可以从数据供应商(如数据标注公司)处获取并筛选,也可以通过其他模型合成生成[3, 10]。后训练中最重要的因素无疑是后训练数据的质量[5]。Gemini 2.5 Pro的相关论文特别强调:“自Gemini 1.5首次发布以来,我们的后训练方法取得了显著进步,这得益于我们在有监督微调(SFT)、奖励建模(RM)和强化学习(RL)全阶段对数据质量的持续关注”[9]。在后续章节中,我们也将探讨对提升最终模型质量至关重要的后训练数据质量相关因素。
在整个后训练生命周期中,每个阶段得到的模型都需要经过某种形式的评估:
- 研究人员会使用自动评估方法(如用于评估知识的MMLU基准、用于评估指令遵循能力的IFEval基准)来了解每个训练阶段和模型单独调整带来的影响[11, 12];
- 人工评估(让人类与模型交互,并根据标注准则对模型输出打分)在评估模型的“有用性”和“对齐程度”方面仍不可或缺[3]。
评估相关细节将在后续章节展开。
3. 什么是有监督微调(SFT)?
有监督微调(Supervised Fine-Tuning, SFT)的作用是将在预训练阶段积累了大量知识的模型,转化为能够遵循用户指令、具备通用实用性的模型[3, 4]。实现这一目标的核心思路是向模型提供我们期望的行为示例[4, 5]:首先收集包含“指令-响应”对的数据集(例如输入提示及其理想答案),然后在该数据集上对预训练模型进行微调[10]。最终得到的模型具备以下特点:
- 学会遵循用户指令
- 能以正确的格式和语气生成输出
- 可作为偏好优化和强化学习(RL)的基础模型
SFT数据集
从本质上讲,SFT属于监督学习:为模型提供一组输入查询,并告知其“正确”输出。学习过程中,模型需根据输入前缀生成后续token序列,然后通过计算生成token与目标token之间的交叉熵损失来优化模型参数[13](与多分类问题的训练方式完全一致)。
因此,SFT数据集是“指令-响应”对((x, y))的集合,其中:
x表示输入指令或提示(prompt)y表示目标输出(由人类编写或高质量模型生成)
🔍 数据示例
用户提示(User prompt):
响应(Response):
图4:SFT数据示例。此处的响应通常被视为由人类专家或“教师模型”编写的“黄金响应”。
JSON格式(JSON Format):
{"prompt":[{"role": "system", "content":"你是一个有帮助、诚实的助手。(You are a helpful, honest assistant.)"},{"role":"user", "content":"美国的首都是什么?(What is the capital city of U.S.)"},],"completion":[{"role": "assistant","content":"美国的首都是华盛顿哥伦比亚特区。(The capital of the United States is Washington, D.C.)"}],
}
SFT数据集中的数据质量
有监督微调的效果完全取决于其背后数据集的质量。与预训练不同(预训练中数据的规模优势可在一定程度上掩盖噪声),SFT数据集通常规模较小(样本数量多在1万到10万级别),且经过高度筛选[5, 10],因此对数据缺陷极为敏感:即使只有一小部分低质量样本,也可能导致模型学习到错误行为。这也是近期公开的SFT方案均强调“严格筛选”和“去污染”的原因[7]。尤其对于推理类模型,低质量数据可能导致“不可靠推理链”——例如,模型给出的推理过程无法支撑其最终答案[14]。高质量的SFT数据应满足:事实准确、风格一致、无无关冗余信息,且与模型需学习的能力高度匹配。
SFT数据集中最常见的问题可归为三类:标签噪声、分布不匹配和虚假推理。
- 标签噪声:由人类标注者或模型生成的答案存在错误、不完整或不一致的情况[16];
- 分布不匹配:SFT数据覆盖范围过窄(例如仅包含数学题或短答案类样本),导致模型在真实场景中表现不佳[15];
- 虚假推理:推理步骤看似连贯,但实际存在逻辑漏洞、误导性捷径甚至复制粘贴的模板内容[14]。
这些问题都会限制模型的泛化能力,并降低后续RL对齐阶段的效果。
为降低这些风险,研究者通常会结合使用筛选(filtering)、验证(validation)和增强(augmentation)三种方法:
- 筛选:包括自动质量检查(如验证数学答案正确性、代码可执行性、推理链与最终答案的一致性)或人工审核[17, 14];
- 验证:通常会保留一组高质量的“黄金数据”作为验证集,用于持续监测模型训练过程中的性能偏移[7];
- 增强:通过增加多样化任务样本、让高质量教师模型生成推理步骤、将噪声样本重写为清晰格式等方式,平衡数据分布[10]。
在实际操作中,最有效的方案是构建“反馈循环”:收集数据→执行质量筛选→评估模型行为→迭代优化数据集,直至SFT阶段能为后续偏好优化提供稳健的基础模型。
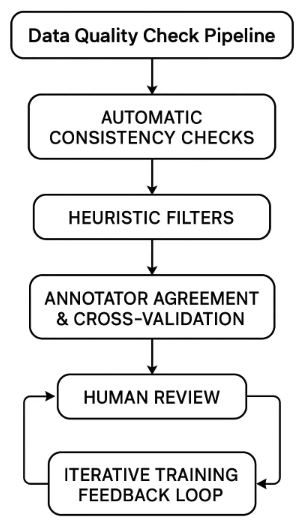
图5:数据质量检查流程
通常会引入一个或多个高性能LLM作为“评判者”,以识别各类数据问题。以下是SFT数据集常见问题的检查清单(可通过LLM评判者、代码/外部工具及其他分类器组合识别):
| 维度(Dimension) | 要求(Expectation) |
|---|---|
| 正确性(Correctness) | 每个答案必须事实准确、逻辑严谨,且与提示内容一致 |
| 一致性(Consistency) | 所有样本的风格、格式和推理结构需保持统一 |
| 完整性(Completeness) | 响应需完整完成任务,不得仅提供部分答案或捷径式答案 |
| 清晰度(Clarity) | 无无关冗余内容、填充文本或矛盾的推理步骤 |
| 覆盖度(Coverage) | 数据集需涵盖不同领域、复杂度和推理深度的任务,而非局限于单一类型 |
| 可验证性(Verifiability) | 在可能的情况下,输出应可验证(如数学结果可重新计算、代码可执行、推理过程可追溯) |
| 平衡性(Balance) | 包含短/简单任务与长/复杂任务,避免模型过度拟合单一格式 |
| 对齐性(Alignment) | 输出需符合期望语气(有用、简洁、安全),这在为RLHF阶段做准备时尤为重要 |
SFT数据的批处理(Batching)与填充(Padding)
收集完SFT所需的“指令-响应”对后,下一个挑战是如何高效地将数据输入GPU进行训练。语言模型需处理固定形状的张量:同一批次(batch)中的所有样本必须具有相同长度[19]。但真实文本的长度差异很大——有的答案仅12个token,有的则长达240个token。为解决这一问题,需将数据打包成批次并进行填充(同时设置固定的最大序列长度T)[19, 18];许多大规模训练方案还会将较短样本拼接后分割为固定长度的序列,以减少填充带来的冗余[18, 20]。
批处理(Batching) 指将多个样本分组,以便并行处理。例如,批次大小为16意味着模型一次处理16个“提示+响应”对。这种方式能提高GPU利用率,并使梯度更新更稳定[21]。但由于样本长度不同,需以批次中最长样本的长度为标准,将其他样本调整至相同长度[20]。
这就需要引入填充(Padding):填充token是一种特殊的“空token”(通常记为PAD),会被添加到较短序列的末尾,使同一批次中所有序列长度一致[20]。模型会通过注意力掩码(attention mask) 忽略这些填充token,确保它们不影响损失计算[22]。具体示例如下:
- 样本1:
[The, cat, sat]→ 长度3 - 样本2:
[Dogs, bark, loudly, at, night]→ 长度5 - 若将两者分为同一批次,需将样本1填充至长度5:
[The, cat, sat, PAD, PAD]
在训练中,注意力掩码会设为[1, 1, 1, 0, 0],确保损失仅基于真实token计算。这种方式既能保证梯度计算的准确性,又能使张量满足“矩形结构”要求。
在实际操作中,批处理和填充策略对训练吞吐量(throughput)影响显著,常见优化策略包括:
- 动态批处理(分桶,Dynamic batching / bucketing):将长度相近的样本分组,减少填充量;
- 序列打包(Packed sequences):将多个短样本拼接成一个长序列(用特殊token分隔),减少空间浪费;
- 掩码(Masking):确保仅“真实token”对梯度更新产生贡献。
SFT损失函数——负对数似然函数(Negative Log Likelihood Function)
由于SFT本质上是多分类问题(类别数量 = 词汇表大小,number of classes = vocab_size),其训练所用的损失函数是“给定输入x时,模型生成正确序列y的负对数似然(NLL)”[13]。在实现时,通常采用“模型预测类别与数据集中真实类别之间的交叉熵”来计算(对输出token序列的每个位置分别计算)[13, 1]。
从数学角度,其表达式如下:
L S F T ( θ ) = − E ( x , y ) ∼ D ∑ t = 1 T log p θ ( y t ∣ x , y < t ) \mathcal{L}_{SFT}(\theta) = -\mathbb{E}_{(x, y) \sim \mathcal{D}} \sum_{t=1}^T \log p_{\theta} (y_t | x, y_{< t}) LSFT(θ)=−E(x,y)∼Dt=1∑Tlogpθ(yt∣x,y<t)
其中:
- θ \theta θ 表示模型参数
- y t y_t yt 表示目标响应中的第 t t t个token
- y < t y_{< t} y<t 表示目标响应中第 t t t个token之前的前缀(即前序token)
- p θ ( ⋅ ) p_\theta(\cdot) pθ(⋅) 表示模型输出的概率分布
在实际实现中,该损失函数通常以交叉熵形式计算[13, 22]。在序列的第 t t t步,设 y t ∗ y_t^* yt∗为数据集中的真实token( ground-truth token), log p θ ( y t ∗ ∣ x , y < t ) \log p_{\theta}(y_t^* | x, y_{< t}) logpθ(yt∗∣x,y<t) 为参数为 θ θ θ的模型生成该真实token的对数概率,则模型需优化的目标函数为[13]:
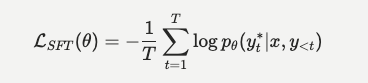
数值稳定性(Numerical Stability)
为保证数值稳定性,该函数通常基于模型最后一层的logits(即LLM最后一层输出、未经过sigmoid函数转换的值)实现[23]。设 V V V为词汇表大小, z t ∈ R V z_t \in \mathbb{R}^V zt∈RV表示序列第 t t t步最后一层的logits,则模型对真实token y t ∗ y_t^* yt∗的预测概率可表示为[22, 23]:
p θ ( y t ∗ ∣ x , y < t ) = exp ( z t , y t ∗ ) ∑ v = 1 V exp ( z t , v ) p_{θ}(y_t^* | x, y_{< t}) = \frac{\exp(z_{t, y_t^*})}{\sum_{v=1}^V \exp(z_{t,v})} pθ(yt∗∣x,y<t)=∑v=1Vexp(zt,v)exp(zt,yt∗)
由此,SFT损失可简化为:
L S F T ( θ ) = − 1 T ∑ t = 1 T ( z t , y t ∗ − log ∑ v = 1 V exp ( z t , v ) ) \mathcal{L}_{SFT}(θ) = - \frac{1}{T} \sum_{t=1}^T \left( z_{t, y_t^*} - \log \sum_{v=1}^V \exp(z_{t, v}) \right) LSFT(θ)=−T1t=1∑T(zt,yt∗−logv=1∑Vexp(zt,v))
式中的第二项即为常见的“log-sum-exp”项。为确保数值稳定,通常采用“log-sum-exp技巧”计算该项:
log ∑ v = 1 V exp ( z t , v ) = m + log ∑ v = 1 V exp ( z t , v − m ) \log \sum_{v=1}^V \exp(z_{t, v}) = m + \log \sum_{v=1}^V \exp(z_{t, v}-m) logv=1∑Vexp(zt,v)=m+logv=1∑Vexp(zt,v−m)
其中:
m = max v = 1 V z t , v m = \max_{v=1}^V z_{t, v} m=v=1maxVzt,v
由于 z t , v − m ≤ 0 z_{t,v} - m \leq 0 zt,v−m≤0,因此 exp ( z t , v − m ) ≤ 1 \exp(z_{t,v}-m) \leq 1 exp(zt,v−m)≤1,可避免整数溢出问题;而整数下溢会被安全地舍入为0,符合预期计算行为。综合以上,最终的SFT损失函数为:
L S F T ( θ ) = − 1 T ∑ t = 1 T ( z t , y t ∗ − m − log ∑ v = 1 V exp ( z t , v − m ) ) \mathcal{L}_{SFT}(\theta) = - \frac{1}{T} \sum_{t=1}^T \left( z_{t, y_t^*} - m - \log \sum_{v=1}^V \exp(z_{t, v}-m) \right) LSFT(θ)=−T1t=1∑T(zt,yt∗−m−logv=1∑Vexp(zt,v−m))
注意事项(Notes):
- 与预训练损失的关系:该损失函数与预训练阶段使用的损失函数完全相同。两者的核心区别在于:预训练输入的是原始文本,而后训练输入的是结构清晰的“指令-响应”对,通过这种约束使模型学习生成“问答格式”的token序列。
- 消息结束特殊token(End of Message Special Token):若不加以约束,模型会无限生成响应;而损失计算会在“最大序列长度 T T T”处截断。因此,需通过在真实答案末尾添加“消息结束特殊token”,教会模型生成长度≤ T T T的完整答案。
- 过拟合风险与灾难性遗忘(Overfitting risk & Catastrophic forgetting):由于SFT数据集规模通常远小于预训练数据集,模型容易发生过拟合;此外,过度微调可能导致模型丢失预训练阶段习得的通用知识。常见的缓解方法包括: dropout(随机失活)、权重衰减(weight decay)、早停(early stopping)和使用更小的学习率。
- 课程设计(Curriculum design):训练数据的结构对模型性能影响显著。有效的策略是:先使用简单指令训练,再逐步引入复杂的多轮交互任务;同时,先使用短上下文数据集,再逐步增加数据集的上下文长度(这对需要生成更长推理过程以提高正确性的模型尤为重要)。
- PyTorch实现:在PyTorch框架中,
F.cross_entropy(..)函数已实现上述具备数值稳定性的SFT损失计算(需输入logits和目标token),无需手动计算最大logits和log-sum-exp项。
综上,SFT是后训练的基础阶段,也是后训练流程的第一步。在SFT中,数学原理简洁明了,数据质量是核心关键,而实际操作的精髓在于:在不破坏预训练基础的前提下,平衡数据质量、训练效率和覆盖范围。
下一章将深入探讨后训练的主要阶段之一:强化学习(Reinforcement Learning)。
4. 常见的强化学习(RL)训练技术有哪些?
后训练中的强化学习(RL)可能是后训练流程中最复杂的部分,也被认为是当前微调模型最有效的方法之一。在传统强化学习中,核心可理解为“智能体(agent)根据环境状态,从策略(policy,即模型)中采样动作(action),以最大化奖励(reward)”的循环[24]。将这一框架适配到后训练的强化学习中:
- 以SFT模型作为“策略(policy)”;
- 将“提示(prompt)”视为“环境(environment)”;
- 定义或学习一个“标量奖励(scalar reward)”来量化目标(如偏好、可验证结果或步骤级分数);
- 通过KL正则化策略梯度(KL-regularized policy gradients) 对策略进行“采样-评分-更新”,使模型行为向高奖励方向优化,同时锚定参考模型以避免性能偏移[3, 6, 25]。
注意:本节大量借鉴并浓缩了Nathan Lambert所著《RLHF Book》[26]中的核心概念。若需了解更多细节,建议参考原书(https://rlhfbook.com)。
RL奖励(RL Rewards)
奖励(Reward) 是衡量“动作或状态的合意程度”的标量值,通常记为 r r r。在LLM后训练的强化学习中,我们以SFT模型作为初始策略 π π π,并设定一个冻结的参考模型 π 0 π₀ π0(通常为初始SFT模型)。对于给定的提示 x x x和模型输出 y y y,可定义标量奖励 r ( x , y ) r(x,y) r(x,y)来衡量 y y y的合意程度。随后,我们优化一个KL正则化目标函数——即通过策略梯度更新模型,同时惩罚模型与参考模型的偏离(避免性能偏移);奖励信号可反映偏好、可验证结果甚至步骤级(过程)分数[3, 25]。
目标函数表达式如下:
max π E y ∼ π ( ⋅ ∣ x ) [ r ( x , y ) ] − β K L ( π ( ⋅ ∣ x ) ∥ π 0 ( ⋅ ∣ x ) ) \max_{\pi}\;\mathbb{E}_{y\sim \pi(\cdot\mid x)}\big[r(x,y)\big]\;-\;\beta\,\mathrm{KL}\!\left(\pi(\cdot\mid x)\,\|\,\pi_{0}(\cdot\mid x)\right) πmaxEy∼π(⋅∣x)[r(x,y)]−βKL(π(⋅∣x)∥π0(⋅∣x))
该式的目标是“最大化期望奖励”,同时通过KL散度(Kullback-Leibler divergence,KL divergence)进行正则化约束。式中:
- 第一项: r ( x , y ) r(x,y) r(x,y)是在生成完整答案后计算的“响应级标量奖励”, π ( y ∣ x ) π(y|x) π(y∣x)是当前策略(即待训练的模型)[3];
- KL散度:用于衡量两个概率分布(当前策略 π π π与参考模型 π 0 π₀ π0)的差异,反映当前模型与初始SFT模型的偏离程度[27];
- β β β:超参数,用于控制正则化强度[3]。
目前有多种类型的奖励可有效实现模型对齐并提升模型能力,主要包括:
- RLHF(基于人类偏好的强化学习):通过从人类偏好中训练的奖励模型(RM),帮助模型在通用对话中表现更优,并实现安全/风格层面的行为对齐[3];
- RLAIF(基于AI反馈的强化学习):也称为Anthropic提出的“宪法AI(Constitutional AI)”,通过LLM结合书面“宪法(constitution)”实现监督规模化,并生成偏好信号[28];
- RLVR(基于可验证奖励的强化学习):通过真值答案、单元测试和代码执行等精准信号,显著提升模型的数学推理和代码能力[8];
- 过程监督强化学习(Process-supervised RL):比RLVR更精细,通过“过程奖励模型(PRM)”对长任务中的中间步骤进行评分,提供步骤级奖励[25];
- 基于评分准则的奖励(Rubrics-guided rewards):通过检查模型响应是否满足明确的评分准则来计算奖励[29, 30]。通常会设置多个评分准则,最终奖励为各准则分数的聚合(如加权和/平均值)[32]。
在实际应用中,现代后训练通常采用混合多阶段方案,在不同阶段融合多种奖励类型(例如:SFT → 偏好优化 → 结合可验证/评分准则信号的RL)[7]。
| 奖励类别(Reward family) | 奖励定义(What the reward is) | 标签来源(Where labels come from) | 典型任务(Typical tasks) | 优缺点(Pros and Cons) |
|---|---|---|---|---|
| RLHF(人类偏好) | 基于成对比较的奖励模型(RM)输出的标量 + 相对于参考模型的KL散度 | 人类对模型采样输出的比较标注 | 通用对话、安全/风格对齐 | 优点:鲁棒性强、研究成熟、覆盖范围广;缺点:奖励模型偏移/奖励黑客攻击、标注者偏见、数据成本高 |
| RLAIF / 宪法AI | 基于LLM评判者(遵循“宪法”/评分准则)比较结果训练的RM输出 + KL散度 | AI评判的比较结果(辅以少量人类抽查) | 可规模化的有用性/无害性微调 | 优点:规模化成本低、迭代速度快;缺点:评判者偏见/反馈循环、领域不匹配 |
| RLVR(可验证结果) | 程序化奖励(精确匹配、单元测试、执行结果) + KL散度 | 真值答案、测试用例、确定性检查器 | 数学、代码、事实性问答 | 优点:信号精准、噪声低;对推理任务提升显著;缺点:奖励稀疏、检查器易被利用、覆盖范围有限 |
| 过程监督RL(PRM) | 过程奖励模型(PRM)对思维链(CoT)步骤评分的步骤级奖励 + KL散度 | 人类/AI的步骤级标注、启发式规则、执行轨迹 | 长文本推理、工具使用 | 优点:奖励信用分配更精细、推理可信度更高;缺点:步骤级标注成本高、PRM在分布外(OOD)场景鲁棒性差 |
| 基于评分准则的奖励 | 通过LLM评判者分数、PRM步骤分数或可执行检查将评分准则转化为标量 + KL散度 | LLM评判者的准则评分;与准则对齐的步骤标注;基于准则的程序化验证器 | 有用性/安全性审核、风格/格式合规性;若准则可执行,也适用于数学/代码 | 优点:奖励与目标意图对齐、跨任务灵活性强;缺点:易出现“古德哈特定律”(过度优化加权准则)、易被关键词/冗余文本欺骗、评判者校准偏移 |
奖励模型与偏好(Reward Models and Preferences)
在LLM的RLHF技术兴起之初,Instruct-GPT论文推广了“从人类偏好排序中训练奖励模型(RM)”的方法,如今这已成为RLHF的核心组成部分[3, 31]。最常见的奖励模型(RM)可预测“给定提示下,候选响应与人类偏好的接近程度”,其训练数据来自包含偏好标注的“提示-响应”对[3, 33]。换句话说,RM的核心作用是估算“在给定标注准则下,人类标注者更偏好哪个输出”。
偏好数据的收集流程如下:
- 采样一个提示和多个模型响应;
- 标注者对这些输出进行排序(从最优到最差,图4);
- 用这些排序数据训练RM;
- 在RL微调阶段,由RM提供标量奖励[3, 33]。
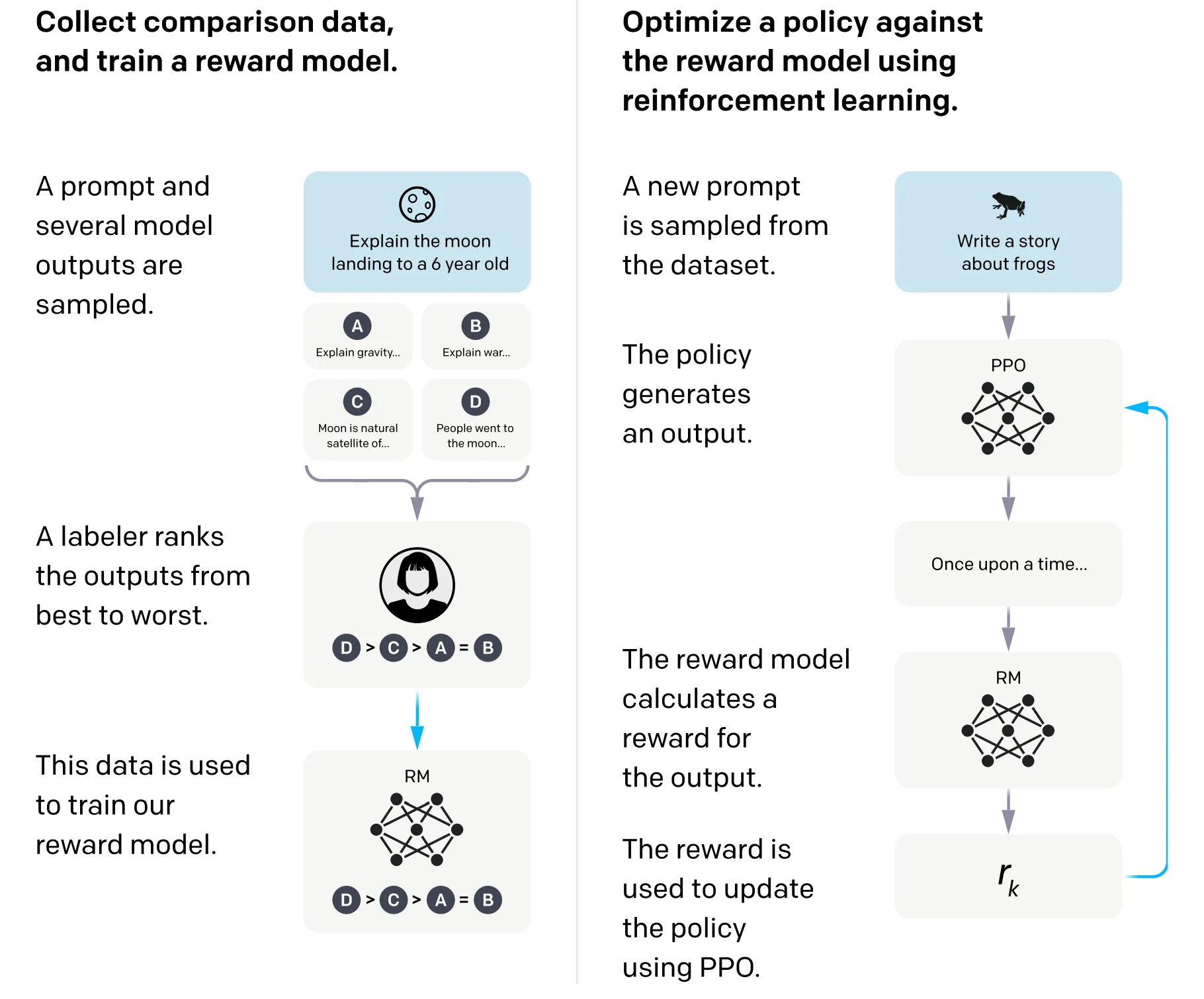
图6:奖励模型(RM)训练(左)与基于近端策略优化的强化学习(右)。该图源自OpenAI 2022年论文《Training language models to follow instructions with human feedback》(《通过人类反馈训练语言模型遵循指令》)。
偏好数据是什么样的?(What does preference data look like?)
以本文开头的简单示例说明:最基础的偏好数据包含“一个提示 + 两个响应”的成对组合——向人类标注者展示用户提示(和/或对话历史)及两个模型响应(响应A、响应B),标注者需判断“A是否优于B”(或反之)[31, 33]。这种成对比较方案可扩展到“多个响应”场景:通过对多个候选响应排序,或对任意成对组合记录判断结果,许多RLHF流程会采用这种方式构建奖励模型的训练数据[3, 34]。
🔍 数据示例
用户提示(User prompt):
响应A(Response A):
?美国的首都是华盛顿哥伦比亚特区。(? The capital city of U.S. is Washington D.C.)
响应B(Response B):
华盛顿哥伦比亚特区。(Washington D.C.)
图7:偏好数据示例。人类标注者需判断“响应A是否优于响应B”,若优于,则需进一步判断“显著优于”还是“略微优于”,反之亦然。
JSON格式(JSON Format):
{"prompt": [{"system":"你是一个有帮助、诚实的助手。(You are a helpful, honest assistant.)"},{"role": "user", "content": "天空是什么颜色的?(What color is the sky?)"},],"chosen": [{"role": "assistant", "content": "华盛顿哥伦比亚特区。(Washington, D.C.)"}],"rejected": [{"role": "assistant", "content": "?美国的首都是华盛顿哥伦比亚特区。(? The capital of the United States is Washington, D.C.)"}],
}
在部分场景中,还会采用“列表排序(list-wise ranking)”而非上述“成对排序(pairwise ranking)”来建模偏好。当每个提示对应多个响应时,列表排序会根据预定义的评分尺度,为每个候选响应分配一个分数。
奖励模型的训练(Training rewards models)
训练奖励模型(RM)的标准方法源自偏好建模的布拉德利-特里模型(Bradley-Terry model)[38]。该模型用于衡量“从同一分布中抽取的两个事件(记为 i i i和 j j j)满足 i > j i > j i>j( i i i优于 j j j)的概率”,表达式如下:
P ( i > j ) = p i p i + p j P(i > j) = \frac{p_i} {p_i + p_j} P(i>j)=pi+pjpi
在“成对奖励/偏好”场景(包含两个样本)中,上述 i i i和 j j j对应模型对同一提示 x x x生成的两个完成序列 y 1 y_1 y1和 y 2 y_2 y2。通过模型 r θ r_\theta rθ对两个响应打分后,奖励模型在成对场景中的“判断正确概率”可表示为:
P ( y 1 > y 2 ) = exp ( r ( y 1 ) ) exp ( r ( y 1 ) ) + exp ( r ( y 2 ) ) ) P(y_1 > y_2) = \frac{\exp(r(y_1))}{\exp(r(y_1)) + \exp(r(y_2)))} P(y1>y2)=exp(r(y1))+exp(r(y2)))exp(r(y1))
通过最大化上述函数的对数似然,可推导出奖励模型的损失函数:
L p a i r ( θ ) = − E [ log σ ( r θ ( x , y w ) − r θ ( x , y l ) ) ] \mathcal{L}_{pair}(\theta) = -\mathbb{E}[\log~\sigma \left(r_\theta(x, y_w) - r_\theta(x, y_l)\right)] Lpair(θ)=−E[log σ(rθ(x,yw)−rθ(x,yl))]
(其中 y w y_w yw表示“更优响应”, y l y_l yl表示“较差响应”, σ \sigma σ为sigmoid函数)
确定奖励模型的损失函数后,需选择“骨干模型(backbone model)”进行初始化训练:
- 通常选择与“策略模型(即待微调的模型)”同系列的骨干模型;
- 更常见的做法是使用“SFT前的预训练模型”作为骨干。
通常会在“最后一个token的隐藏状态”上添加一个标量头(scalar head)(或单个线性层/多层感知机(MLP))。为分别考虑不同维度和准则,奖励模型也可采用“多头(multi-head)”结构。
对于偏好数据中的每一条比较记录,需按以下步骤重新格式化以用于训练:
- 编码提示:
prompt_ids = apply_chat_template(messages, add_generation_prompt=True)(使用对话模板对提示编码,添加生成提示标记); - 编码答案:
chosen_ids = tok(chosen, add_special_tokens=False)(对“更优响应”编码,不添加特殊token),对“较差响应(rejected)”执行相同操作; - 添加EOS token:若模型要求,在响应末尾添加一个EOS(End of Sequence)token(需确保对话模板未提前添加);
- 组合序列:
- “更优序列”:
pos = prompt_ids + chosen_ids + [eos?](提示编码 + 更优响应编码 + [EOS token(可选)]) - “较差序列”:
neg = prompt_ids + rejected_ids + [eos?](提示编码 + 较差响应编码 + [EOS token(可选)])
- “更优序列”:
- 生成注意力掩码:真实token对应位置设为1,填充token对应位置设为0。建议采用右填充(right padding),以便简化“最后一个token”的索引定位。
RL提示与数据(RL Prompts and Data)
以下将提供不同奖励类型对应的RL提示数据示例。
可验证奖励(Verifiable rewards)
适用场景:存在可靠的自动检查器(checker)可验证正确性或合规性的任务。
最适配领域:数学、代码、结构化提取/格式化、有真值的检索任务、结果可验证的工具使用场景
🔍 数据示例
用户提示(User prompt):
评分器(Grader):
def math_grader(answer: str):# 标准化空格,解析数字gold = [-5, 2/3] # 真值答案try:pred = [float(s) for s in answer.replace(' ','').split(',')] # 解析模型输出的答案return int(sorted(pred) == gold) # 若排序后与真值一致,返回1;否则返回0except:return 0 # 解析失败时返回0
JSON格式(JSON Format):
{"prompt": [{"system":"你是一个有帮助、诚实的助手。(You are a helpful, honest assistant.)"},{"role": "user", "content": "求解方程:(3x - 2)(x + 5) = 0。仅需提供根,按升序用逗号分隔。(Solve: (3x - 2)(x + 5) = 0. Provide only the roots separated by commas in ascending order.)"},],"metadata": ["ground truth response": "-5, 0.6666667", # 真值响应"reward": 1.0, # 奖励值"scorer:" math_grader # 评分器函数],
}
用户提示(User prompt):
以测试用例作为验证器(Tests as the verifier):
TESTS = [("racecar", True), ("A man, a plan, a canal: Panama!", True),("hello", False), ("", True) # 测试用例列表:(输入字符串,期望返回值)
]def code_grader(fn):passed = sum(fn(inp)==out for inp,out in TESTS) # 统计通过的测试用例数量return passed / len(TESTS) # 奖励值:通过比例(范围[0,1])
JSON格式(JSON Format):
{"prompt": [{"system":"你是一个有帮助、诚实的助手。(You are a helpful, honest assistant.)"},{"role": "user", "content": "实现函数is_palindrome(s: str) -> bool,需忽略大小写和非字母数字字符。(Implement is_palindrome(s: str) -> bool. Ignore case and non-alphanumerics.)"},],"metadata": ["scorer": code_grader, # 评分器函数"suite": { # 测试套件信息"suite_id": "palindrome_001_v3", # 测试套件ID"suite_hash": "sha256:e2b4...9d", # 测试套件哈希值(用于版本控制)"entry_point": "is_palindrome", # 待测试函数入口"runtime": {"image": "python:3.11", "timeout_s": 4, "mem_mb": 1024}, # 运行环境配置:镜像、超时时间、内存限制"public_tests_count": 4, # 公开测试用例数量"hidden_tests_count": 18 # 隐藏测试用例数量},],
}
偏好奖励(Preference reward)
适用场景:无明确检查器的开放式质量评估(如有用性、语气、安全性)。
最适配领域:通用对话/帮助类任务、摘要、改写、风格/语气调整、安全/无害性评估
🔍 数据示例
用户提示(User prompt):
用10岁孩子能理解的语言解释什么是VPN。(Explain what a VPN is to a 10-year-old.)
JSON格式(JSON Format):
{"prompt": [{"system":"你是一个有帮助、诚实的助手。(You are a helpful, honest assistant.)"},{"role": "user", "content": "用10岁孩子能理解的语言解释什么是VPN。(Explain what a VPN is to a 10-year-old.)"},],"metadata": ["scorer": { # 评分器信息"rm_id":"rm_helpfulness_v3", # 奖励模型ID"rm_hash":"sha256:1f9c...b83", # 奖励模型哈希值 "rm_checkpoint_path":"s3://.../rm_v3.safetensors", # 奖励模型检查点路径},"calibration": { # 校准信息:原始分数→奖励值的转换规则"method":"zscore_per_prompt", # 校准方法:按提示的z分数标准化"group_stats":{"mu":1.24,"sigma":0.51}, # 分组统计信息:均值(mu)、标准差(sigma)"length_penalty":0.01 # 长度惩罚系数:避免模型生成冗余文本},],
}
基于评分准则的奖励(Rubrics-guided rewards)
适用场景:存在明确“规范(spec)”(如事实性、有用性、安全性、简洁性),且希望奖励与规范对齐的任务。评分准则可支持:
- 偏好标注(由LLM作为评判者或人类标注者依据准则进行标注);
- 过程奖励(依据准则对中间步骤评分);
- 可执行检查(将准则转化为验证器)。
🔍 数据示例
用户提示(User prompt):
用10岁孩子能理解的语言解释什么是VPN。(Explain what a VPN is to a 10-year-old.)
JSON格式(JSON Format):
{"prompt": [{"system":"你是一个有帮助、诚实的助手。(You are a helpful, honest assistant.)"},{"role": "user", "content": "用10岁孩子能理解的语言解释什么是VPN。(Explain what a VPN is to a 10-year-old.)"},],"metadata": ["rubric": { # 评分准则"scale": {"min": 1, "max": 7}, # 评分尺度:1-7分"criteria": [ # 具体评分维度{"id": "factuality", "weight": 0.5, # 维度ID:事实性;权重:0.5"definition": "表述正确、无误导性。(Correct, non-misleading statements.)","guidelines": ["无虚构事实(No made-up facts)", "不确定时需注明(Cite if uncertain)", "无矛盾内容(No contradictions)"]},{"id": "helpfulness", "weight": 0.3, # 维度ID:有用性;权重:0.3"definition": "直接响应用户需求,提供有用的背景/示例。(Directly answers the user’s ask; useful context/examples.)","guidelines": ["符合用户年龄/意图(Addresses age/intent)", "清晰且具有可操作性(Actionable and clear)"]},{"id": "concision", "weight": 0.2, # 维度ID:简洁性;权重:0.2"definition": "无冗余内容,表述精炼,无重复。(No fluff; tight phrasing; avoids repetition.)","guidelines": ["优先使用短句(Prefer short sentences)", "去除元对话内容(Remove meta-chatter)"]}],"hard_rules": [ # 硬性规则:不满足则触发惩罚{"if": "safety < 4", "then": "overall = 0", "reason": "不安全内容导致总分归零(Unsafe content gates overall to zero)"}],"aggregate": "overall = 0.5*factuality + 0.3*helpfulness + 0.2*concision", # 总分计算方式:加权和"notes": "权重总和为1。安全性为门槛维度(不计入加权和)。(Weights sum to 1. Safety is a gating criterion (not in the sum).)"},"judge": { # 评判者配置"model_id": "gpt-4o-2025-06-01", # 评判者模型ID"temperature": 0.0, # 温度参数:0表示确定性输出"seed": 17, # 随机种子:确保结果可复现"prompt_template": "judge_v3" # 评判提示模板},],
}
RL算法(RL Algorithms)
下表概述了LLM后训练中常用的RL算法。研究社区最初主要使用PPO(近端策略优化)[35],但自DeepSeek-V3推出后,GRPO(分组相对策略优化) 逐渐成为主流选择[8]。两者的核心区别在于:GRPO取消了独立的价值(评论家)网络(value (critic) network),转而通过分组采样(group sampling) 估算相对优势,从而降低内存和计算成本[8]。REINFORCE是经典RL算法,同样无需评论家网络,且实现简单[37]。最后需注意——尽管DPO(直接偏好优化) 在技术上不属于RL算法,但因其无需奖励模型、成本低且稳定性高,且通常基于固定偏好数据进行离线策略(off-policy) 训练,因此也被广泛应用[36]。
| 算法(Algorithm) | 是否使用评论家(Uses a critic?) | 是否需要奖励模型/验证器(Needs a reward model / verifier?) | 是否为在线策略(On-policy?) | KL控制(KL control) | 最适配场景(Best for) |
|---|---|---|---|---|---|
| PPO - 近端策略优化 | 是(需价值函数,value fn) | 是 | 是 | 全局或逐token | RLHF/RLAIF(偏好类任务)、混合任务 |
| GRPO - 分组相对策略优化 | 否(无评论家,critic-free) | 是 | 是 | 逐token | RLVR(可验证数学/代码任务)、长思维链(CoT)任务 |
| REINFORCE / RLOO | 否(仅需基线,baseline only) | 是 | 是 | 逐token | 简单场景、多轮采样的高吞吐量RL任务 |
| DPO(非RL算法) | 否 | 无需RM(直接使用偏好数据) | 否(离线策略) | 通过参考logits内置 | 低成本、稳定的偏好微调 |
给定提示 x x x、当前策略 π θ π_θ πθ、冻结参考模型 π 0 π_0 π0和响应级奖励 r ( x , y ) r(x,y) r(x,y),RL的优化目标如下:
max π E y ∼ π ( ⋅ ∣ x ) [ r ( x , y ) ] − β K L ( π ( ⋅ ∣ x ) ∥ π 0 ( ⋅ ∣ x ) ) \max_{\pi}\;\mathbb{E}_{y\sim \pi(\cdot\mid x)}\big[r(x,y)\big]\;-\;\beta\,\mathrm{KL}\!\left(\pi(\cdot\mid x)\,\|\,\pi_{0}(\cdot\mid x)\right) πmaxEy∼π(⋅∣x)[r(x,y)]−βKL(π(⋅∣x)∥π0(⋅∣x))
PPO(近端策略优化)
PPO在逐token级别优化“裁剪代理目标函数(clipped surrogate objective)”。设 r t = exp ( log Π θ ( y t ∣ s t ) − log Π o l d ( y t ∣ s t ) ) r_t=\exp(\log~\Pi_{\theta}(y_t∣s_t)−\log \Pi_{old}(y_t∣s_t)) rt=exp(log Πθ(yt∣st)−logΠold(yt∣st))(当前策略与旧策略在第 t t t个token的概率比的指数), A t A_t At为token级优势(通常对整个答案使用单一广播标量 A A A),则PPO的策略损失为:
L p o l i c y = − E t [ min ( r t A t , c l i p ( r t , 1 − ϵ , 1 + ϵ ) A t ] \mathcal{L}_{policy} = -\mathbb{E}_t [\min (r_t A_t , \mathtt{clip} (r_t, 1-\epsilon, 1 + \epsilon) A_t] Lpolicy=−Et[min(rtAt,clip(rt,1−ϵ,1+ϵ)At]
(其中 ϵ \epsilon ϵ为裁剪系数,通常取0.1或0.2,用于限制策略更新幅度)
控制模型与参考模型的偏移通常有两种方式:
- 增加全局 β K L ( π θ ∥ π 0 ) \beta KL(π_θ∥π_0) β KL(πθ∥π0)惩罚项;
- 逐token KL调整(shaping),将下式添加到回报(return)中:
r ~ t = − β ( l o g π θ ( y t ∣ s t − l o g π 0 ( y t ∣ s t ) ) \tilde{r}_t =- \beta ( log π_θ(y_t|s_t − logπ_0(y_t|s_t) ) r~t=−β(logπθ(yt∣st−logπ0(yt∣st))
PPO还需训练一个评论家(critic) V ϕ ( s t ) Vϕ(s_t) Vϕ(st),用于预测期望回报,以构建优势函数并降低方差。
PPO训练循环(PPO training loop):
- 采样:从旧策略 π o l d π_{old} πold中为每个提示采样 K K K个答案(使用中等温度/token采样概率(top-p));
- 评分:通过奖励源(如RM、验证器)为每个答案打分,得到 r ( x , y i ) r(x,y_i) r(x,yi);
- 计算优势: A = r − b A=r−b A=r−b(其中 b b b为评论家预测值或“分组基线”——即该提示下 K K K个样本的均值);
- 更新策略与评论家:使用裁剪损失更新策略网络,通过均方误差(MSE)训练评论家以拟合目标回报;
- 控制KL散度:调整 β \beta β以维持KL散度在目标范围内;
- 更新旧策略:将 π o l d π_{old} πold更新为当前策略 π θ π_θ πθ,重复上述步骤。
GRPO(分组相对策略优化)
GRPO是专为LLM设计的无评论家(critic-free) 策略梯度方法。其核心流程为:
- 为每个提示采样 K K K个答案;
- 为这些答案打分;
- 通过减去“分组基线”(通常为 K K K个答案的奖励均值)为每个答案分配相对优势;
- 对“奖励高于基线”的答案,提升其token的对数概率;对“奖励低于基线”的答案,降低其token的对数概率;
- 同时通过KL锚定(KL anchor) 绑定到冻结参考模型(如SFT模型),避免性能偏移。
具体而言,对于提示 x x x:
- 从当前策略中采样 K K K个响应 { y i } i = 1 K \{ y_i \}^{K}_{i=1} {yi}i=1K;
- 通过奖励源(RM、验证器、评判者)为这些响应打分,得到 { r i } \{ r_i \} {ri};
- 定义分组基线: r ˉ = 1 N ∑ r i \bar{r}= \frac{1}{N} \sum{r_i} rˉ=N1∑ri(所有响应的奖励均值)或“留一法基线” r ˉ − i \bar{r}_{-i} rˉ−i(排除第 i i i个响应后的均值);
- 计算第 i i i个响应的优势: A i = r i − r ˉ A_i = r_i - \bar{r} Ai=ri−rˉ(或 A i = r i − r ˉ − i A_i = r_i - \bar{r}_{-i} Ai=ri−rˉ−i)。
逐token KL调整(抗偏移,Per-token KL shaping (anti-drift)):
为使策略贴近参考模型 π 0 π_0 π0,需在回报中添加逐token KL调整项:
r ~ t K L = − β ( l o g π θ ( y t ∣ s t ) − l o g π 0 ( y t ∣ s t ) ) \tilde{r}_t^{KL} = −\beta (log π_θ(y_t∣s_t)−logπ_0(y_t∣s_t)) r~tKL=−β(logπθ(yt∣st)−logπ0(yt∣st))
GRPO训练循环(GRPO training loop):
- 采样:为每个提示采样 K K K个答案(使用中等温度/top-p);
- 评分:为每个答案打分,得到响应级奖励 r i r_i ri;
- 计算优势: A i = r i − r ˉ A_i = r_i - \bar{r} Ai=ri−rˉ(随后进行“提示内标准化”:z分数或排序);
- 更新策略:使用REINFORCE算法逐token更新策略,结合优势 A i A_i Ai和KL调整项(锚定参考模型);
- 调整KL参数:调整 β \beta β以维持逐token KL散度在目标范围内,重复上述步骤。
5. 如何评估后训练模型?
后训练模型的评估形式多样,因为这是一个高度多维度的问题——模型需在多个维度上被评估“有用性”,同时还需确保“安全性”。传统指标(如困惑度(perplexity))无法反映“有用性”,而人工评估成本高且主观性强。在实际操作中,有效的评估需结合多种方法,分别覆盖模型质量的不同维度。
后训练评估方法可分为以下两类:
- 自动评估(Automatic Evaluation)
- 基于真值的评估(Ground Truth Based Eval)
- 基于LLM评判者的评估(LLM-Judge Based Eval)
- 人工评估(Human Evaluation)
- 点式评估(Point-wise Eval)
- 基于偏好的评估(Preference Based Eval)
自动评估(Auto evaluation)
自动评估通常速度快、成本低,无需人工参与。一套完整的自动评估方案包含以下核心组件:
- 提示/对话(Prompt/Conversation):用于获取待评估模型输出的输入集合;
- 验证器(Verifier):给定提示和模型输出,对“输出是否满足评估目标”进行打分的组件。在可验证领域,验证器通常是解析和字符串匹配代码;在开放式领域,验证器是“LLM评判者”,需依据预定义评分准则对输出打分;
- 评分准则(Rubrics):所有评估集均需包含评分准则(可为单提示专属或全提示通用),明确“有用/正确答案”的构成要素。通常会涵盖输出的主观性维度,以及长输出中可验证的中间步骤;
- [可选] 真值(Ground Truth):在数学、代码、多选题(MCQ)等可验证领域,评估集需提供“期望正确答案”,通常为可与模型输出进行精确匹配的短字符串(例如“最终答案:\boxed{\frac{1}{2}}”)。
基于真值的评估(Ground truth based eval)
基于真值的评估适用于“评估集包含可通过字符串匹配验证的真值”的场景。这类评估的核心价值在于:无需人工参与即可大规模计算客观准确率指标,避免人工标注的成本和偏见。其最适用于边界清晰的任务(如数学解题、代码挑战、多选题推理)——这些任务的“正确性”可自动验证。但对于开放式对话类任务(可能存在多个有效答案),这类评估则不太适用。
各领域常用的基于真值的基准测试集(Benchmark):
| 领域(Domain) | 基准测试集(Benchmark) | 指标(Metric) | 描述(Description) |
|---|---|---|---|
| 数学(Math) | GSM8K | 精确匹配准确率(Exact match accuracy) | 包含需分步推理的算术文字题 |
| 代码(Code) | HumanEval | 通过率@k(Pass@k,单元测试成功率) | 包含需通过单元测试验证的代码生成任务 |
| 多选题推理(MCQ reasoning) | MMLU | 准确率(Accuracy,多选题正确率) | 涵盖57个学科领域,测试通用知识与推理能力 |
| 通用事实性(General factuality) | TruthfulQA | 真实性分数/精确匹配(Truthfulness score / exact match) | 评估答案的事实准确性,检测是否存在常见误解 |
🔍 数据示例
提示(Prompt):
真值(Ground truth):
验证器(Verifier):
def grade_gsm8k(gt_answer: int, model_output: str) -> dict:"""GSM8K数据集的简单评分器。- 优先查找输出中最后一个\boxed{...}内的整数;- 若未找到,则取文本中最后一个整数;- 将结果与真值整数比较。"""# 1) 尝试提取\boxed{...}中的内容boxed = re.findall(r"\\boxed\{\s*([0-9,]+)\s*\}", model_output)if boxed:pred = int(boxed[-1].replace(",", "")) # 移除逗号并转为整数else:# 2) 若未找到\boxed{},则提取最后一个整数nums = re.findall(r"\b[0-9][0-9,]*\b", model_output)pred = int(nums[-1].replace(",", "")) if nums else None # 若未找到整数,pred为Nonereturn {"gt": gt_answer, # 真值"pred": pred, # 模型预测值"correct": pred == gt_answer if pred is not None else False, # 是否正确}
被判定为“正确”的示例输出(Example Completion Graded as Correct):
- 每辆汽车有4个轮胎;
- 15辆汽车的总轮胎数:15×4=60。
最终答案:\boxed{60}
被判定为“错误”的示例输出(Example Completion Graded as Incorrect):
- 每辆汽车有4个轮胎;
- 15辆汽车的总轮胎数:15×4=60。
最终答案:\boxed{55}
基于LLM评判者的评估(LLM-judge based eval)
基于LLM的评估使用高性能LLM作为“评判者”,对其他模型的输出进行打分或排序。其核心流程是:向评判者LLM输入“任务提示、候选响应(有时还包括参考答案或评分准则)”,由评判者输出分数或偏好结果。这类评估的优势在于速度快、成本低、可规模化,且若设计得当,其结果与专家评判的相关性较高。
其最适用于开放式任务(如摘要、对话、推理、创意写作)——这些任务可能存在多个有效答案,但仍可评估“有用性、正确性、清晰度、安全性”等维度。但需注意其局限性:评判者可能偏好冗长输出、倾向于同系列模型的输出,或在未明确评分准则的情况下遗漏细微的安全问题。
各场景常用的基于LLM的评估方案:
- 成对比较(Pairwise comparisons):评判者从响应A和响应B中选择更优者(如“对话竞技场(Chatbot Arena)”);
- 点式评分(Pointwise scoring):评判者依据评分准则对单个响应打分;
- 参考感知评分(Reference-aware grading):评判者将候选响应与已知参考答案比较(如事实性问答);
- 安全红队测试(Safety red-teaming):评判者检测输出中是否存在不安全、有偏见或违反政策的内容。
基于真值的评估 vs 基于LLM的评估(Ground Truth vs LLM-Based Evaluations)
| 维度(Aspect) | 基于真值的评估(Ground Truth–Based Evals) | 基于LLM的评估(LLM-Based Evals) |
|---|---|---|
| 定义(Definition) | 将模型输出与固定的“已知正确答案”比较 | 使用高性能LLM作为“评判者”对输出打分或排序 |
| 最适配场景(Best for) | 边界清晰、有明确正确性标准的任务(数学、代码、多选题) | 开放式任务(摘要、对话、推理、安全性) |
| 指标类型(Metric type) | 精确匹配、准确率、通过率@k | 基于评分准则的分数(1–7分)、偏好结果(A vs B)、JSON结构化结果 |
| 优势(Strengths) | 客观、可复现、计算成本低 | 可规模化、速度快、能捕捉主观性维度(有用性、清晰度) |
| 局限性(Limitations) | 不适用于开放式任务、灵活性低 | 易受偏见影响(风格、模型系列、顺序)、需与人工校准 |
🔍 数据示例
提示(Prompt):
用一句话总结以下段落:
“亚马逊雨林常被称为‘地球之肺’,它产生了全球20%的氧气,并且是无数物种的家园。然而,由农业和伐木活动导致的森林砍伐,正对其生存构成严重威胁。”
(Summarize the following passage in one sentence:
“The Amazon rainforest, often referred to as the lungs of the planet, produces 20% of the world’s oxygen and is home to an incredible diversity of species. However, deforestation driven by agriculture and logging poses a severe threat to its survival.”)
评分准则(Rubrics):
验证器(Verifier):
You are an evaluator judging candidate responses.(你是评估候选响应的评判者。)TASK PROMPT:(任务提示:)
{prompt}CANDIDATE RESPONSE:(候选响应:)
{response}RUBRIC:(评分准则:)
- 有用性(Helpfulness,1–7分):摘要是否涵盖核心事实?
- 事实性(Factuality,1–7分):信息是否准确?
- 清晰度(Clarity,1–7分):响应是否清晰简洁? Return JSON:(返回JSON格式结果:)
{"helpfulness": int, # 有用性分数"factuality": int, # 事实性分数"clarity": int, # 清晰度分数"composite": float, # 综合分数(如三者平均值)"rationale": "short explanation" # 简短理由
}被判定为“优秀”的示例输出(Example Completion Graded as Good):
亚马逊雨林能产生全球20%的氧气且拥有丰富的生物多样性,但农业和伐木导致的森林砍伐正严重威胁其生存。
(The Amazon rainforest, which produces 20% of the world’s oxygen and hosts immense biodiversity, is under severe threat from deforestation.)
被判定为“较差”的示例输出(Example Completion Graded as Bad):
亚马逊雨林是个很酷的地方,有很多动物和树。
(The Amazon rainforest is a cool place with lots of animals and trees.)
人工评估(Human evaluation)
人工评估指人类标注者直接依据“有用性、事实准确性、安全性、清晰度”等准则,对模型输出(有时还包括提示本身)进行评判。它是衡量LLM输出“主观性维度”的黄金标准——这些维度无法通过“真值匹配”或“自动评判”完全捕捉。人工评估尤其适用于开放式或敏感任务(例如评估响应是否礼貌、有创意,或是否存在有害偏见)。但需注意:人工评估是成本最高、耗时最长的评估方式,且结果可能因标注者偏见、文化背景差异或准则理解不一致而产生波动。
各场景常用的人工评估方案:
- 成对偏好评估(Pairwise preference):标注者从两个候选响应中选择更优者;
- 李克特量表评分(Likert-scale ratings):标注者依据1–5分或1–7分量表,对响应的“有用性”“安全性”等属性打分;
- 专家评估(Expert evaluations):由领域专家评估特定领域(如医学、法律、金融)的正确性;
- 用户研究与用户体验研究(User studies & UXR):通过真实用户的实时实验,衡量“满意度、信任度、可用性”等指标。
人工评估的核心设计决策之一是:“编写提示的人是否也应参与评分”。下表对比了不同场景下的设计选择:
| 方案(Setup) | 提示编写者(Who writes prompts) | 评分者(Who grades responses) | 噪声水平(Noise level) | 适用场景(When to use) |
|---|---|---|---|---|
| 专家标注者(同一人编写并评分) | 专家 | 同一专家 | 低——评分准则应用一致,领域知识可减少歧义 | 专业领域(如医学、法律、代码),正确性需专业知识判断的场景 |
| 专家标注者(不同人编写与评分) | 专家 | 另一专家 | 中——两者均具备专业能力,但准则理解可能存在细微差异 | 大规模专家评估,需交叉验证一致性的场景 |
| 用户自写自评(User as writer & grader) | 终端用户 | 同一终端用户 | 高——易受主观偏好影响,评分标准不一致 | 早期产品测试,需直接捕捉“用户中心满意度”的场景 |
| 混合方案(用户写提示,专家评分) | 终端用户 | 专家 | 中–低——提示反映真实使用场景,评分采用统一标准 | 产品导向评估,需“真实提示+严谨评分”的场景 |
| 混合方案(专家设计提示,用户评分) | 专家 | 终端用户 | 中——提示清晰可减少歧义,但评分仍存在噪声 | 大规模偏好收集(如RLHF),专家无法覆盖数百万样本的场景 |
后续章节将介绍两种常见的人工标注流程(点式评估和基于偏好的评估)。在实际应用中,这两种方案常结合使用以获取更全面的信号。
点式评估(Point-wise eval)
点式人工评估指“标注者依据预定义评分准则,对单个模型响应进行独立评分”。与“成对比较”不同,标注者需为响应分配一个数值分数(如1–5分或1–7分),评分维度包括“有用性、事实性、清晰度、安全性”等。这种方案可生成绝对质量分数,比相对偏好更易解读,且能判断模型是否“足够好”。
点式评估尤其适用于诊断性分析(例如识别模型在“安全性”或“指令遵循”方面的系统性问题),但相比成对评估,其噪声更高——不同标注者对同一评分尺度的理解可能存在差异。因此,点式评估通常需要结合以下措施来降低噪声:清晰的评分准则、每个样本由多名标注者评分、以及标注前的校准培训。
🔍 数据示例
1. 模型响应优秀的案例
提示(Prompt):
用简短的语言解释天空为什么是蓝色的。(Write a short explanation of why the sky appears blue.)
人工标注准则(Human Annotation guidelines):
- 仔细阅读响应内容;
- 从事实准确性、清晰度、有用性三个维度评分(1–7分,1分最差,7分最优);
- 若响应存在明显错误或无关内容,可适当降低分数。
响应(Response):
天空呈现蓝色是因为空气分子会散射太阳光,而波长较短的蓝色光比波长较长的红色光散射得更强烈。这种现象被称为瑞利散射(Rayleigh scattering),正是它让我们看到的天空呈蓝色。
人工评分示例(Sample Human Rating):
- 有用性(Helpfulness):7
- 事实准确性(Factuality):7
- 清晰度(Clarity):7
- 综合分数(Composite Score):7.0
- 评分理由(Rationale):“事实准确、简洁明了,且清晰解释了瑞利散射的原理。”
2. 模型响应较差的案例
提示(Prompt):
用简短的语言解释天空为什么是蓝色的。(Write a short explanation of why the sky appears blue.)
人工标注准则(Human Annotation guidelines):
- 仔细阅读响应内容;
- 从事实准确性、清晰度、有用性三个维度评分(1–7分,1分最差,7分最优);
- 若响应存在明显错误或无关内容,可适当降低分数。
响应(Response):
天空是蓝色的,因为它反射了海洋的颜色。
人工评分示例(Sample Human Rating):
- 有用性(Helpfulness):2
- 事实准确性(Factuality):1
- 清晰度(Clarity):5
- 综合分数(Composite Score):2.7
- 评分理由(Rationale):“表达清晰但事实错误,重复了‘天空蓝色源于海洋反射’这一常见误解。”
评估集上的聚合方法——均值评分(Aggregation on the eval set - Mean Score)
在获取所有提示的评分后,最终指标通常是“各维度的平均分数”及“综合平均分数”。这种方法对大多数评估集都简单易用,但缺点是:对于性能相近的两个模型,均值评分的区分度可能不足。因此,实际中常将其与“偏好评估”结合,以弥补这一缺陷。
偏好评估(Preference eval)
成对人工评估是后训练模型质量衡量中应用最广泛的方法之一。在这种方案中,人类标注者会看到同一个提示及两个不同的模型响应,并需判断“哪个响应更优”(或标记为“两者相当”)。这种设计能生成相对偏好数据,不仅易于收集,还能为模型排名或奖励模型训练提供重要依据。
与“数值量表评分”相比,成对评估能减少标注者的犹豫(无需纠结“给4分还是5分”),且通过“ELO分数”或“布拉德利-特里模型(Bradley–Terry models)”等聚合方法,可将大量个体比较结果转化为稳健的模型排名。其主要缺点是无法提供绝对质量分数,只能判断“哪个模型更优”,但这种权衡使其成为大多数后训练流程中高效且可规模化的评估方案。
🔍 数据示例
提示(Prompt):
用简短的语言解释天空为什么是蓝色的。(Write a short explanation of why the sky appears blue.)
人工标注准则(Human Annotation guidelines):
- 仔细阅读两个响应;
- 结合事实准确性、清晰度、有用性判断哪个响应更优;
- 若两者质量相当或均差,则标记为“平局”。
响应A(Response A):
天空呈现蓝色是因为空气分子会散射太阳光,而波长较短的蓝色光比波长较长的红色光散射得更强烈。这种现象被称为瑞利散射(Rayleigh scattering),正是它让我们看到的天空呈蓝色。
响应B(Response B):
天空是蓝色的,因为它反射了海洋的颜色。
人工评分示例(Sample Human Rating):
| 标注者A(Rater A) | 标注者B(Rater B) | 标注者C(Rater C) |
|---|---|---|
最终评分(多数投票,Final Rating (Majority vote)):
响应A胜出(3票赞成,0票反对)
评估集上的聚合方法——净胜率与ELO分数(Aggregation on the eval set - Net Win Rate, ELO Scores)
1. 净胜率(Net Win Rate)
要在整个评估集上聚合偏好数据,最简单且应用最广的方法是净胜率。对于某个模型,统计其在“与其他模型的成对比较”中“胜出次数(W)”与“失败次数(L)”,净胜率可通过以下公式计算,用于概括模型的相对偏好表现:
净胜率( N e t W i n R a t e ) = W − L W + L \mathtt{净胜率(Net Win Rate)} = \frac{W - L}{W + L} 净胜率(NetWinRate)=W+LW−L
- 分数为**+1.0**:模型每次比较均胜出;
- 分数为0.0:模型胜出与失败次数相等;
- 分数为**-1.0**:模型每次比较均失败。
2. ELO分数(ELO Score)
尽管“净胜率”能简单概括偏好数据,但许多团队更倾向于使用ELO分数——这种源自国际象棋排名的方法能为多个模型提供更稳定的排名。ELO的核心逻辑是:模型在比较中的得分不仅取决于“是否胜出”,还取决于“对手的强弱”(击败更强的模型会获得更多分数,输给较弱的模型会失去更多分数),因此更适用于“对话竞技场(Chatbot Arena)”等多模型排名场景。
具体计算逻辑如下(假设模型A的初始分数为 R A R_A RA,模型B的初始分数为 R B R_B RB):
- 计算模型A的预期胜率:
E A = 1 1 + 1 0 R B − R A 400 E_A = \frac{1}{1 + 10^{\frac{R_B - R_A}{400}}} EA=1+10400RB−RA1 - 根据实际比较结果,为模型A分配实际得分 S A S_A SA:
- 若A胜出, S A = 1 S_A=1 SA=1;
- 若两者平局, S A = 0.5 S_A=0.5 SA=0.5;
- 若A失败, S A = 0 S_A=0 SA=0;
- 更新模型A的分数:
R A ′ = R A + K ⋅ ( S A − E A ) R_A' = R_A + K \cdot (S_A - E_A) RA′=RA+K⋅(SA−EA)
(其中 K K K为常数,用于控制分数更新幅度,通常取16–32)
模型B的分数会根据对称逻辑更新。最终,ELO分数更高的模型被认为性能更优。
污染(Contamination)
评估中一个关键问题是污染——即“评估集中的样本同时出现在模型的训练数据中”。污染会导致评估结果虚高,因为模型可能只是“记忆并复述”训练过的答案,而非真正展现推理或泛化能力。这一问题在GSM8K、MMLU、HumanEval等公开基准测试集中尤为突出(这些数据集被广泛用于各实验室的模型训练)。
为防范污染,研究团队通常会采取以下措施:
- 检查训练数据与评估集的重叠情况(如文本相似度匹配);
- 使用私有或新收集的评估集;
- 对异常高的评估分数保持警惕(可能暗示污染)。
实际应用中,污染不仅会扭曲模型排名,还可能误导产品决策,因此必须谨慎处理。
6. 总结(Summary)
大语言模型(LLM)的后训练是一个快速发展的领域,技术与方法持续创新。本文涵盖了从预训练模型到指令微调模型的完整流程,深入探讨了有监督微调(SFT)、基于人类反馈的强化学习(RLHF)及其他强化学习方法。尽管技术细节看似复杂,但核心原则始终一致:让模型与人类偏好对齐、确保事实准确性、优化模型的有用性。
在后续系列中,我们还将讨论更进阶的主题,例如DeepSeek V3和DeepSeek R1的后训练方法。
参考文献(Reference)
- Brown, T. B., et al. “Language Models are Few-Shot Learners.” NeurIPS 2020. https://papers.nips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html NeurIPS会议论文集
- Gemini团队(Google). “Gemini: A Family of Highly Capable Multimodal Models.” arXiv:2312.11805, 2023. https://arxiv.org/abs/2312.11805 [arXiv预印本]
- Ouyang, L., et al. “Training language models to follow instructions with human feedback.” NeurIPS 2022. https://proceedings.neurips.cc/paper_files/paper/2022/file/b1efde53be364a73914f58805a001731-Paper-Conference.pdf [NeurIPS会议论文集]
- Wei, J., et al. “Finetuned Language Models Are Zero-Shot Learners (FLAN).” ICLR 2022. https://arxiv.org/pdf/2109.01652 [arXiv预印本]
- Zhou, C., et al. “LIMA: Less Is More for Alignment.” arXiv 2023. https://arxiv.org/pdf/2305.11206 [arXiv预印本]
- Guo, D., et al. “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.” arXiv 2025. https://arxiv.org/pdf/2501.12948 [arXiv预印本]
- Lambert, N., et al. “Tülu 3: Pushing Frontiers in Open Language Model Post-Training.” arXiv 2024. https://arxiv.org/pdf/2411.15124 [arXiv预印本]
- Liu, A., et al. “DeepSeek-V3 Technical Report.” arXiv:2412.19437, 2024. https://arxiv.org/pdf/2412.19437 [arXiv预印本]
- Gemini团队(Google). “Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next-Generation Agentic Capabilities.” 2025. https://storage.googleapis.com/deepmind-media/gemini/gemini_v2_5_report.pdf [技术报告]
- Wang, Y., et al. “Self-Instruct: Aligning Language Models with Self-Generated Instructions.” arXiv:2212.10560, 2022. https://arxiv.org/abs/2212.10560 [arXiv预印本]
- Hendrycks, D., et al. “Measuring Massive Multitask Language Understanding (MMLU).” ICLR 2021. https://arxiv.org/abs/2009.03300 [arXiv预印本]
- Zhou, J., et al. “Instruction-Following Evaluation for Large Language Models (IFEval).” arXiv:2311.07911, 2023. https://arxiv.org/abs/2311.07911 [arXiv预印本]
- Raffel, C., et al. “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (T5).” JMLR 2020. https://jmlr.org/papers/volume21/20-074/20-074.pdf [《机器学习研究期刊》论文]
- Turpin, M., Michael, J., Perez, E., Bowman, S. R. “Language Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting.” NeurIPS 2023. [NeurIPS 2023会议论文]
- Lin, B. Y., et al. “WildBench: Benchmarking LLMs with Challenging Tasks from Real Users in the Wild.” arXiv:2406.04770, 2024. https://arxiv.org/abs/2406.04770 [arXiv预印本]
- Luo, J., et al. “RobustFT: Robust Supervised Fine-tuning for Large Language Models under Noisy Response.” arXiv:2412.14922, 2024. https://arxiv.org/abs/2412.14922 [arXiv预印本]
- Chen, M., et al. “Evaluating Large Language Models Trained on Code.” arXiv:2107.03374, 2021. https://arxiv.org/pdf/2107.03374 [arXiv预印本]
- Chowdhery, A., et al. “PaLM: Scaling Language Modeling with Pathways.” arXiv:2204.02311, 2022. https://arxiv.org/pdf/2204.02311 [arXiv预印本]
- Liu, H., Peng, Q., Yang, Q., Liu, K., Xu, H. “Bucket Pre-training is All You Need.” arXiv:2407.07495, 2024. https://arxiv.org/abs/2407.07495 [arXiv预印本]
- Krell, M. M., Kosec, M., Perez, S. P., Fitzgibbon, A. “Efficient Sequence Packing without Cross-contamination: Accelerating Large Language Models without Impacting Performance.” arXiv:2107.02027, 2021. https://arxiv.org/abs/2107.02027 [arXiv预印本]
- McCandlish, S., Kaplan, J., Amodei, D., OpenAI Dota Team. “An Empirical Model of Large-Batch Training.” arXiv:1812.06162, 2018. https://arxiv.org/abs/1812.06162 [arXiv预印本]
- Vaswani, A., et al. “Attention Is All You Need.” NeurIPS 2017. https://arxiv.org/abs/1706.03762 [NeurIPS 2017会议论文]
- Goodfellow, I. “Numerical Computation (Deep Learning lecture slides).” 2017. https://www.deeplearningbook.org/slides/04_numerical.pdf [深度学习课程幻灯片]
- Sutton, R. S., & Barto, A. G. Reinforcement Learning: An Introduction (2nd ed.). MIT Press, 2018. https://incompleteideas.net/book/the-book-2nd.html [书籍]
- Lightman, H., Kosaraju, V., Burda, Y., et al. “Let’s Verify Step by Step: Improving Mathematical Reasoning with Process Supervision.” arXiv:2305.20050, 2023. https://arxiv.org/abs/2305.20050 [arXiv预印本]
- Lambert, N. Reinforcement Learning from Human Feedback (The RLHF Book). 2025. https://arxiv.org/abs/2504.12501 [书籍]
- Kullback, S., & Leibler, R. A. “On Information and Sufficiency.” Annals of Mathematical Statistics, 1951. https://projecteuclid.org/journals/annals-of-mathematical-statistics/volume-22/issue-1/On-Information-and-Sufficiency/10.1214/aoms/1177729694.full [《数理统计年刊》论文]
- Bai, Y., et al. “Constitutional AI: Harmlessness from AI Feedback.” arXiv:2212.08073, 2022. https://arxiv.org/abs/2212.08073 [arXiv预印本]
- Gunjal, A., et al. “Rubrics as Rewards: Reinforcement Learning Beyond Preference Pairs.” arXiv:2507.17746, 2025. https://arxiv.org/abs/2507.17746 [arXiv预印本]
- Kim, S., et al. “Prometheus: Inducing Fine-grained Evaluation Capability in LLMs.” arXiv:2310.08491, 2023. https://arxiv.org/abs/2310.08491 [arXiv预印本]
- De Langis, K., et al. “Dynamic Multi-Reward Weighting for Multi-Style Generation.” EMNLP 2024. https://aclanthology.org/2024.emnlp-main.386.pdf [EMNLP 2024会议论文]
- Christiano, P. F., et al. “Deep Reinforcement Learning from Human Preferences.” NeurIPS 2017. https://arxiv.org/abs/1706.03741 [NeurIPS 2017会议论文]
- Stiennon, N., et al. “Learning to Summarize with Human Feedback.” NeurIPS 2020. https://arxiv.org/pdf/2009.01325 [NeurIPS 2020会议论文]
- Zhu, B., et al. “Principled Reinforcement Learning with Human Feedback.” ICML 2023 (PMLR v202). https://proceedings.mlr.press/v202/zhu23f.html [ICML 2023会议论文]
- Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O. “Proximal Policy Optimization Algorithms.” arXiv:1707.06347, 2017. https://arxiv.org/abs/1707.06347 [arXiv预印本]
- Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C. D., Finn, C. “Direct Preference Optimization: Your Language Model is Secretly a Reward Model.” 2023. https://arxiv.org/abs/2305.18290 [arXiv预印本]
- Williams, R. J. “Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning (REINFORCE).” Machine Learning, 1992. https://link.springer.com/article/10.1007/BF00992696 [《机器学习》期刊论文]
- Bradley, R. A., & Terry, M. E. “Rank Analysis of Incomplete Block Designs: I. The Method of Paired Comparisons.” Biometrika 39(3–4), 1952. https://doi.org/10.1093/biomet/39.3-4.324 [《生物计量学》期刊论文]