小杰深度学习(fifteen)——视觉-经典神经网络——MobileNetV1
1. 网络的背景
传统的卷积神经网络要想有一个很好的效果的话,需要很大的参数量,同时由于参数量大,导致网络在预测时要求的算力也是非常大,那么对于手机、嵌入式等设备是非常不友好的。为能够在移动端进行部署。
MobileNet网络由谷歌团队在2017年提出,专注于移动端或者嵌入式设备中轻量级的卷积神经网络,相比传统的卷积神经网络呢,在准确率小幅降低的前提下,大大减少我们模型的参数以及运算量。
MobileNet全称是:Efficient Convolutional Natural Networks for Mobile Vision Applications。
论文地址:https://arxiv.org/pdf/1704.04861
Efficient Convolutional Natural Networks for Mobile Vision Applications.pdf
2. 网络的创新
2.1 Depthwise Separable Convolution(深度可分离卷积)
深度可分离卷积是一种全新的卷积方式,先看一下经典的卷积。
2.1.1经典卷积过程如下:
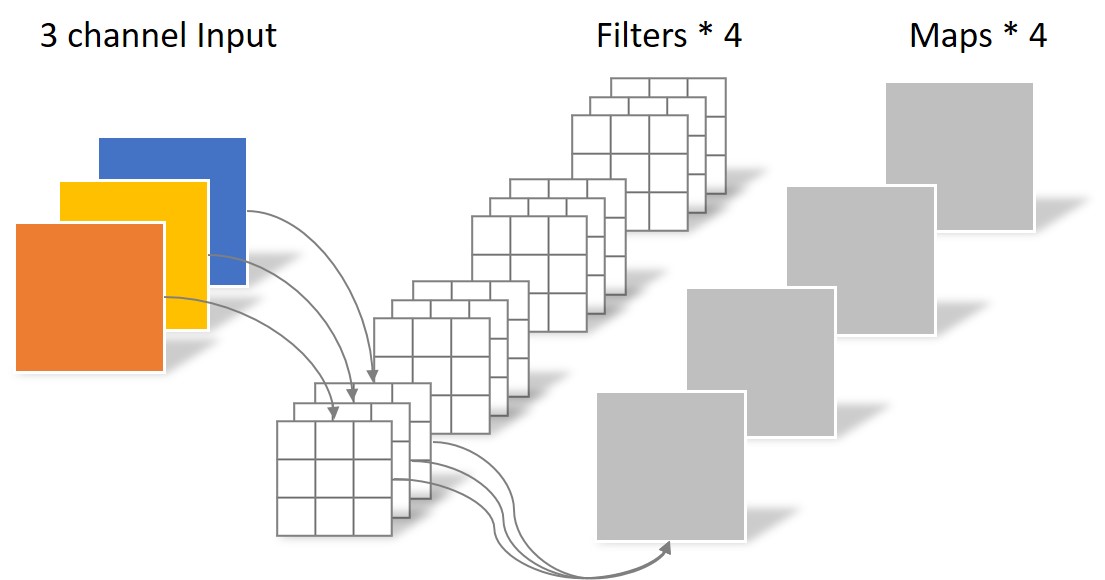
在上图中,输入是3个channel的矩阵,经过4个卷积核,每个卷积核包括3个3 x 3的卷积,得到了拥有4个输出矩阵。这是经典的卷积过程。也可以总结为:
卷积核的channel = 输入特征矩阵的channel
输出特征矩阵的channel = 卷积核个数
2.1.2深度可分离卷积操作过程如下:
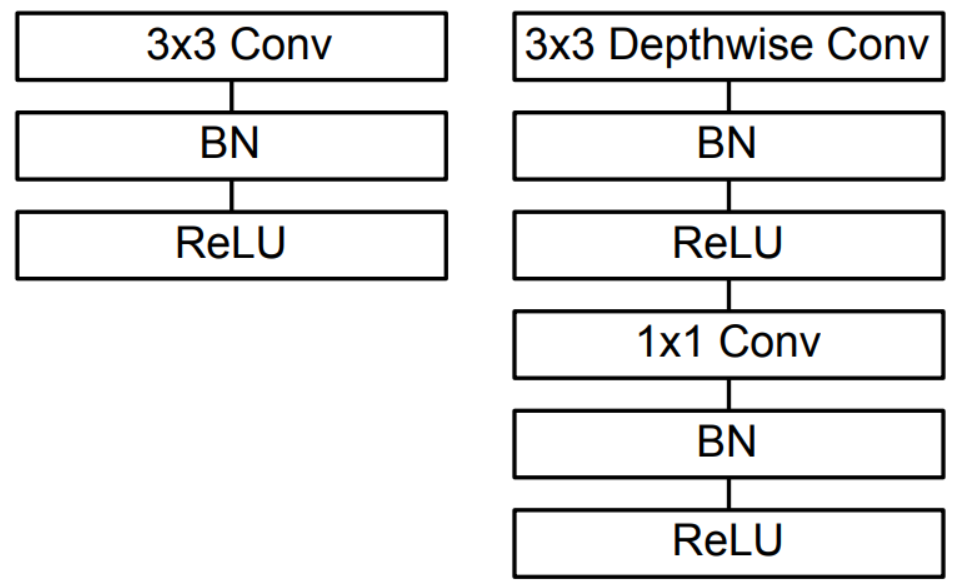
深度可分离卷积(Depthwise Separable Conv),是由两种卷积组成的,包括DW卷积(Depthwise Convolution,深度卷积)和PW卷积(Pointwise Conv,逐点卷积也就是1x1 Conv)组成,如下图所示。
1.DW卷积(Depthwise Convolution,深度卷积)
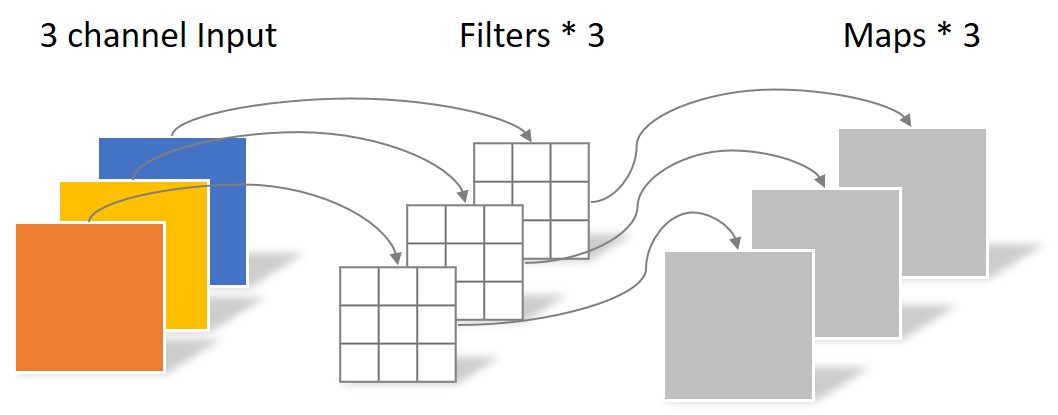
DW卷积的卷积核深度,即channel和传统的卷积不同,它的channel不等于输入特征矩阵的channel,而是等于1。
DW卷积的每一个卷积核负责一个输入特征矩阵的channel,那么总结下来:输入特征矩阵的channel = 卷积核个数 = 输出特征矩阵的channel
2.PW卷积(Pointwise Conv,逐点卷积)
在DW卷积之后,结果作为PW卷积的输入,PW卷积如下图所示:
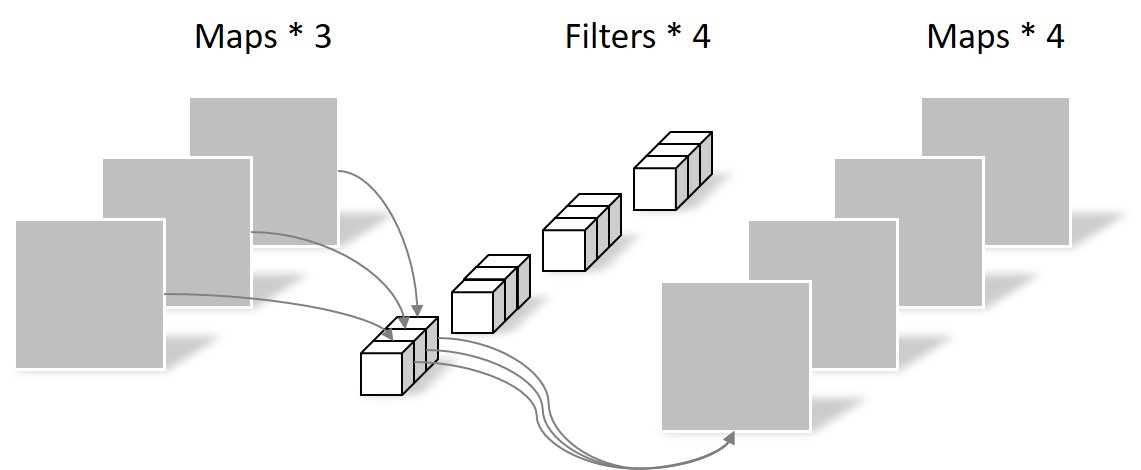
在上图中可以看到,卷积核的channel与输入特征矩阵的channel相同,输出特征矩阵的深度与卷积核的个数是相同的。可以看出,PW卷积和普通卷积是一样的,只是卷积核的大小为1。
2.1.3深度可分离卷积和常规卷积运算量对比
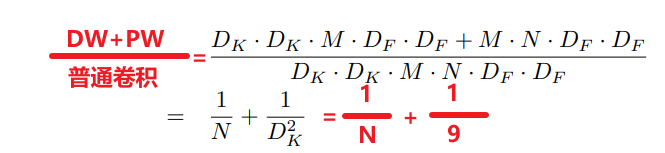

2.2 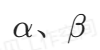 的引入
的引入
![]() 是卷积核个数的倍率,用来控制卷积过程中卷积核的个数,当取不同的
是卷积核个数的倍率,用来控制卷积过程中卷积核的个数,当取不同的![]()
的时候,准确率、计算量和参数量是不一样的,Table 6中给出了不同![]() 的对比,如下图:
的对比,如下图:
.
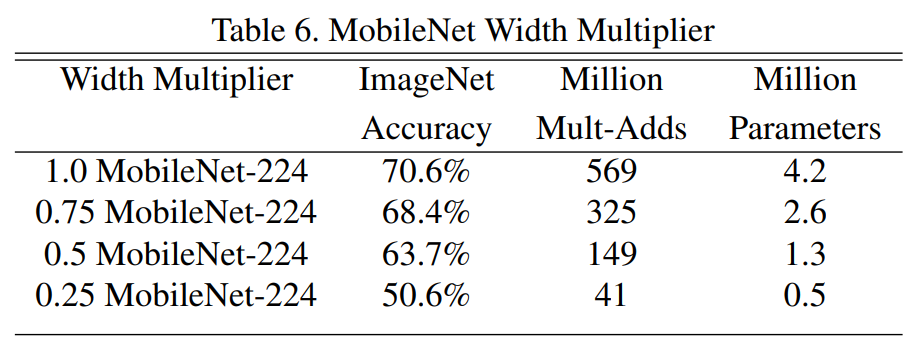
![]() 是分辨率参数,即输入图像尺寸的参数,当对输入的图像大小变为原始图像的
是分辨率参数,即输入图像尺寸的参数,当对输入的图像大小变为原始图像的![]()
倍数时,会使得后继所有层的输入特征图都会缩小![]() 。 需要注意的一点是,改变分辨率,只会对整个网络的计算量有影响,对参数量是不受影响的。下图是随着分辨率的减少,计算量也随之减少。Table 7中给出了不同
。 需要注意的一点是,改变分辨率,只会对整个网络的计算量有影响,对参数量是不受影响的。下图是随着分辨率的减少,计算量也随之减少。Table 7中给出了不同 ![]() 的对比,如下图:
的对比,如下图:
3. 网络的问题
部分DW卷积核的参数会为0,主要有以下几个原因:
1.卷积核、通道数量以及权重数量太少,感受野太单薄;
2.Relu激活函数,会将小于 0 的值置为 0 。DW 卷积输出通道数相对少,特征维度低 。在低维特征上使用 ReLU ,大量特征值可能被置为 0 ,造成信息丢失 。
3.当使用如 float16、int8 低精度浮点数时,数值表示范围和精度受限 。训练中,参数更新量可能因低精度表示无法准确记录,导致更新不精确 。
4.1 结构
在paper中的Table 1中给出了网络结构的图,如下图所示:
注意:原paper中有一处的步长写错了,应该是s1而不是s2,我在图中用红字做了标注。
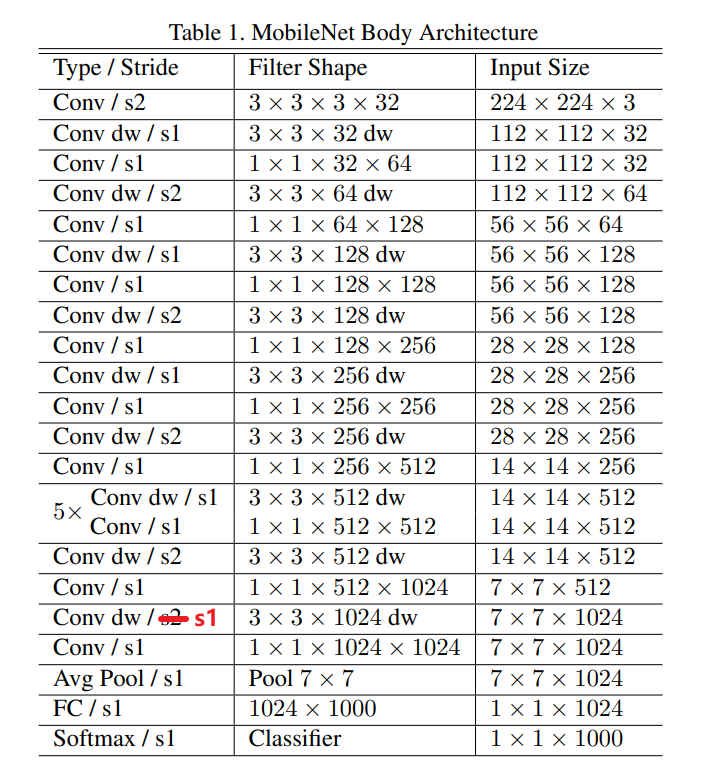
结合虚拟仿真的组件,对MobileNetV1的网络结构进行分析。
4.2 结构组件介绍
注意:这里的类似于第二层-DW卷积和第三层-卷积一起组成了深度可分卷积,但是由于paper中的网络结构表格并没有将它们直接放在一起,所以这我们也将其分开处理。
4.2.1 卷积
输入特征矩阵是(224 x 224 x 3),本层卷积核的宽、高、通道、个数是(3 x 3 x 3 x 32),步长为2,padding方式为SAME,经过计算可知,输出特征矩阵为(112 x 112 x 32)。
本层之后要经过batchNorm进行归一化,以及Relu激活函数,如下图:
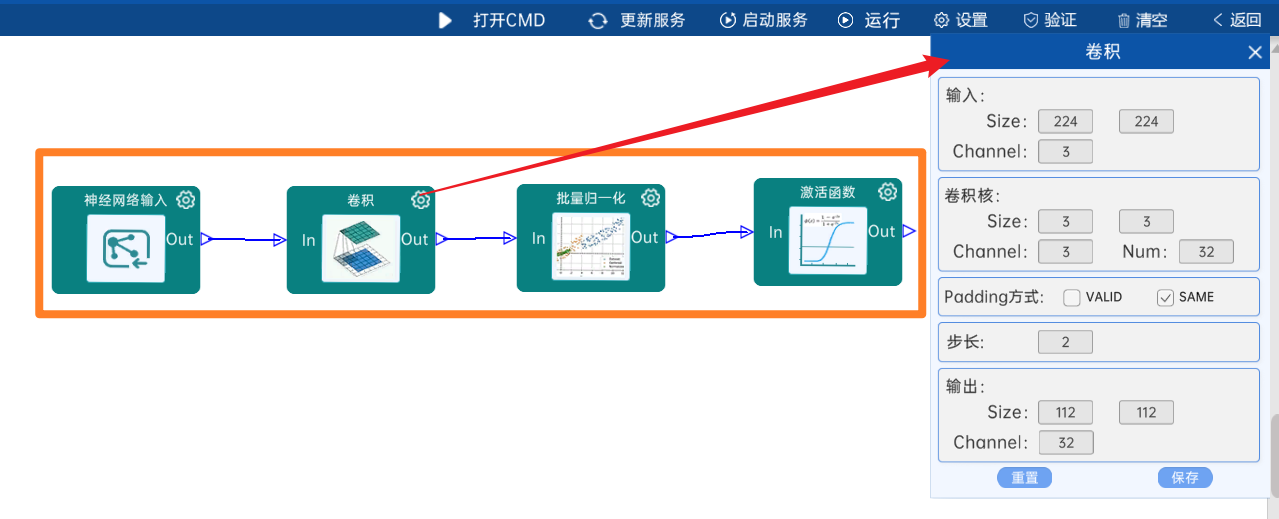
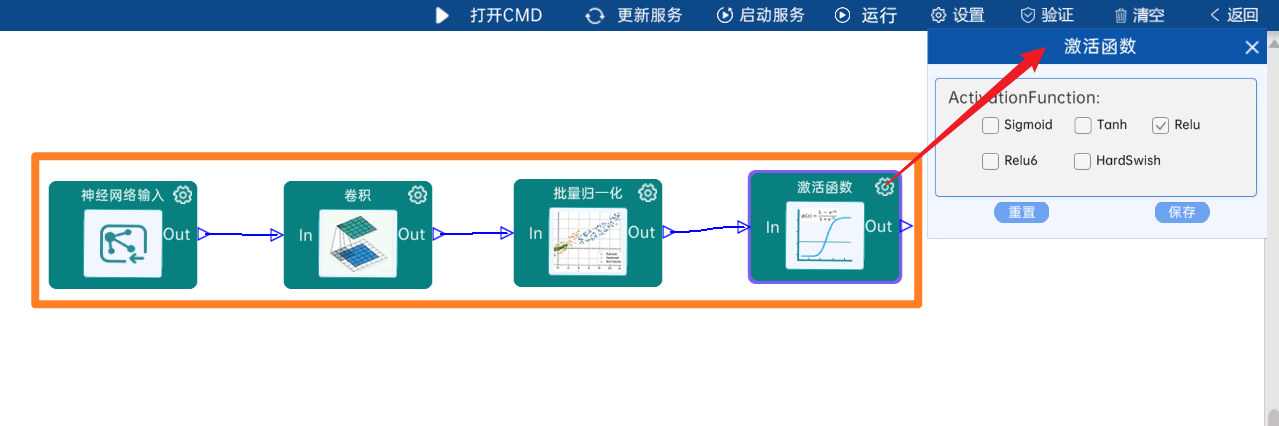
4.2.2 DW卷积
输入特征矩阵是(112 x 112 x 32),本层卷积核的宽、高、个数是(3 x 3 x 32),步长为1,padding方式为SAME,经过计算可知,输出特征矩阵为(112 x 112 x 32)。
本层之后要经过batchNorm进行归一化,以及Relu激活函数,如下图:
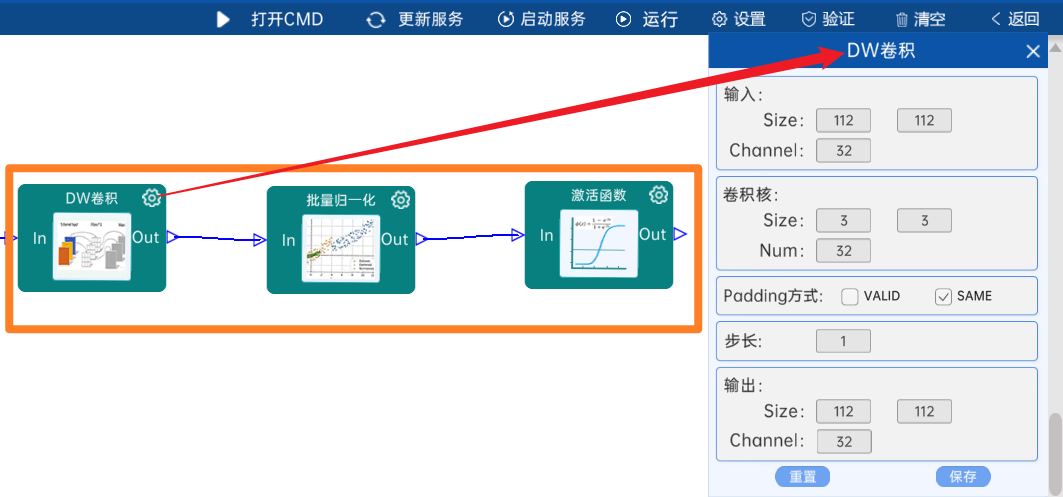
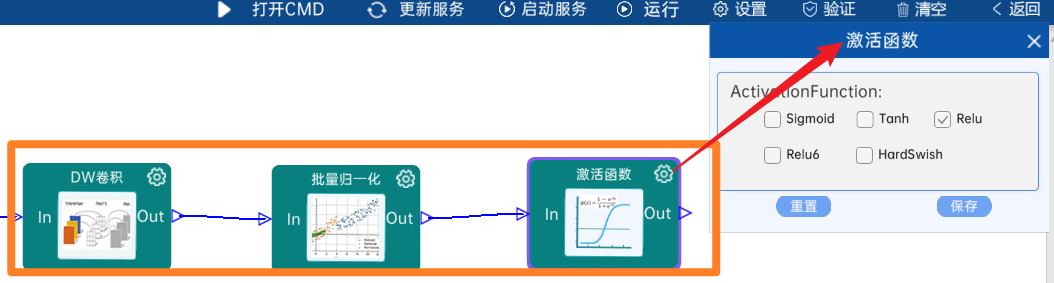
4.2.3 卷积
输入特征矩阵是(112 x 112 x 32),本层卷积核的宽、高、通道、个数是(1 x 1 x 32 x 64),步长为1,padding方式为SAME,经过计算可知,输出特征矩阵为(112 x 112 x 64)。
本层之后要经过batchNorm进行归一化,以及Relu激活函数,如下图:
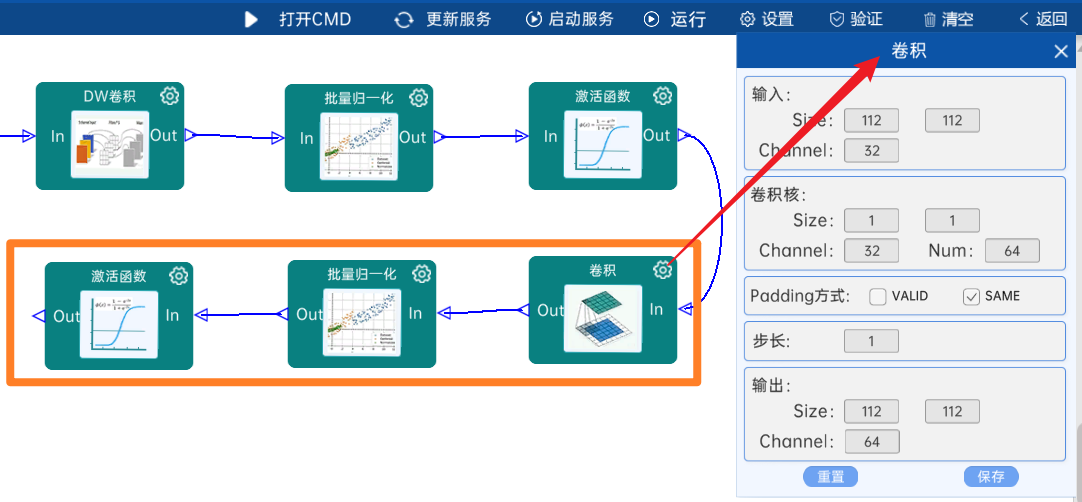
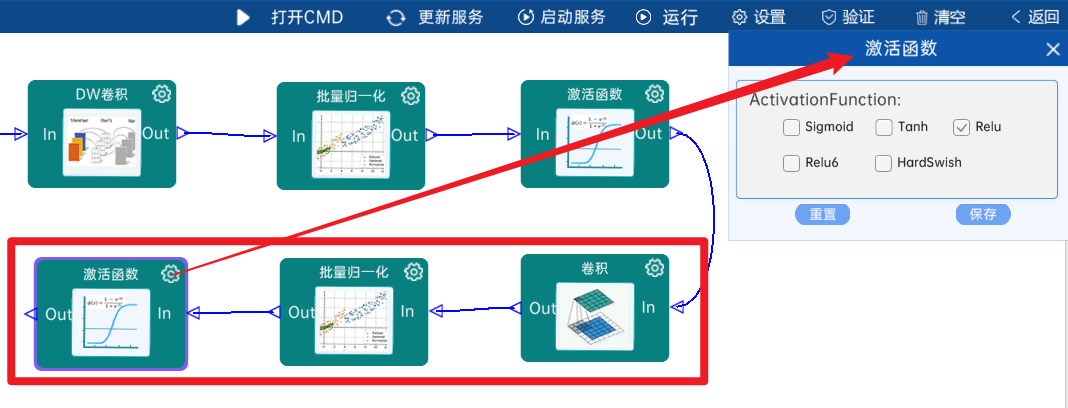
4.2.4 DW卷积
输入特征矩阵是(112 x 112 x 64),本层卷积核的宽、高、个数是(3 x 3 x 64),步长为2,padding方式为SAME,经过计算可知,输出特征矩阵为(56 x 56 x 64)。
本层之后要经过batchNorm进行归一化,以及Relu激活函数,如下图:
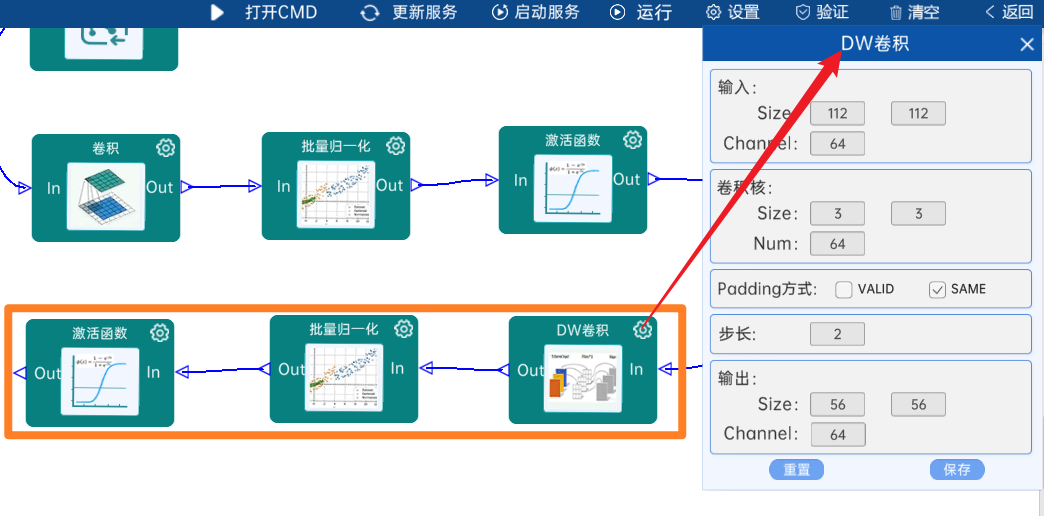
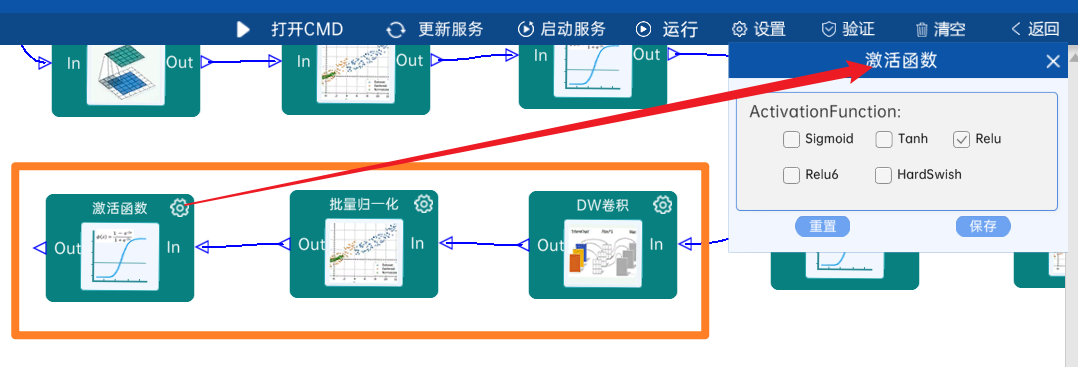
4.2.5 卷积
输入特征矩阵是(56 x 56 x 64),本层卷积核的宽、高、通道、个数是(1 x 1 x 64 x 128),步长为1,padding方式为SAME,经过计算可知,输出特征矩阵为(56 x 56 x 128)。
本层之后要经过batchNorm进行归一化,以及Relu激活函数,如下图:
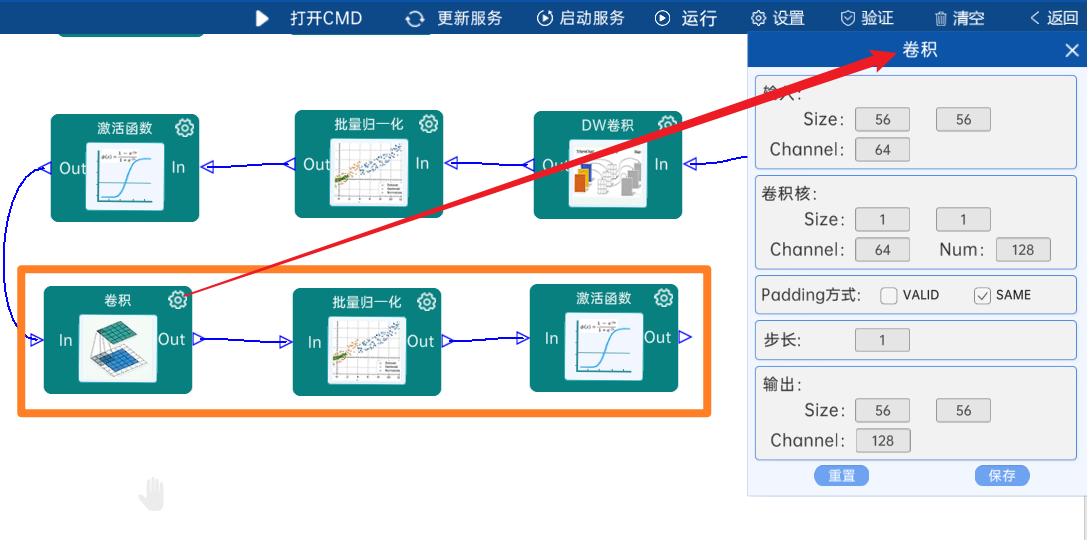
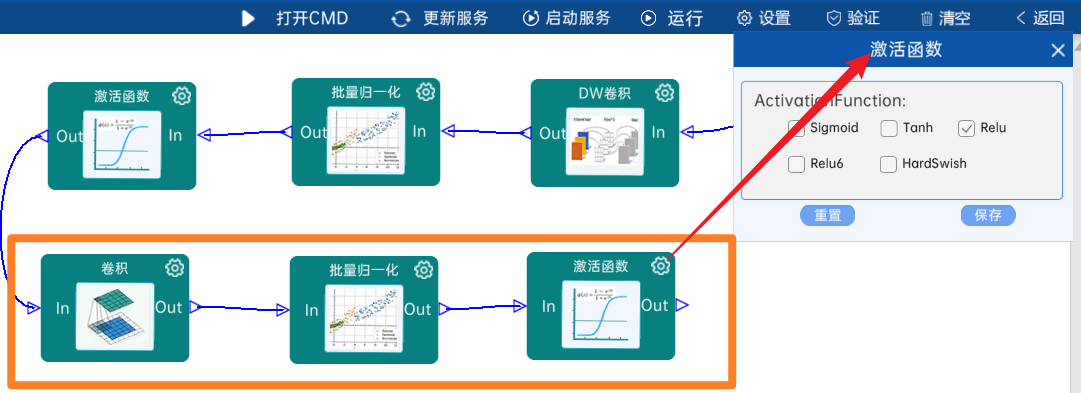
4.2.6 DW卷积
输入特征矩阵是(56 x 56 x 128),本层卷积核的宽、高、个数是(3 x 3 x 128),步长为1,padding方式为SAME,经过计算可知,输出特征矩阵为(56 x 56 x 128)。
本层之后要经过batchNorm进行归一化,以及Relu激活函数,如下图:
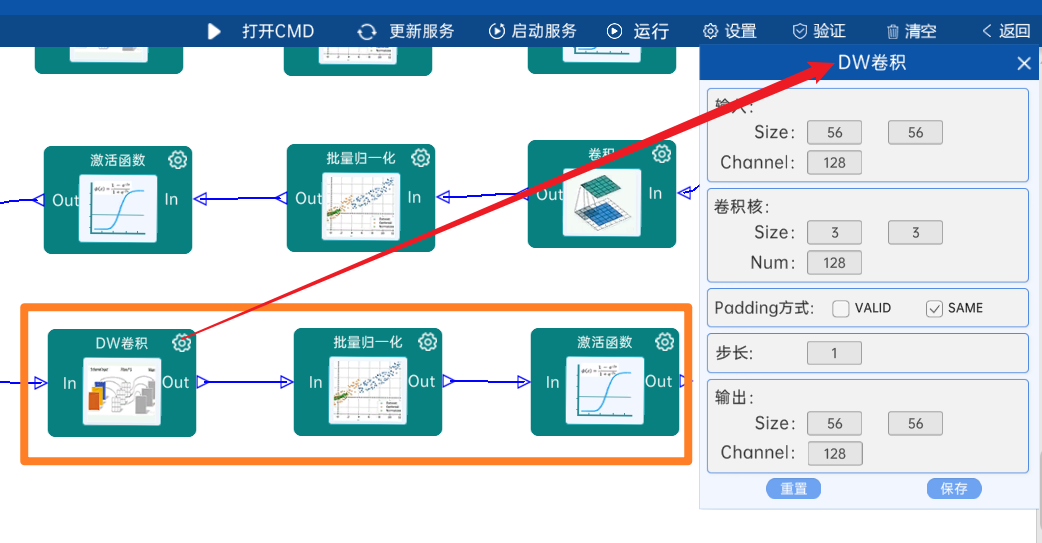
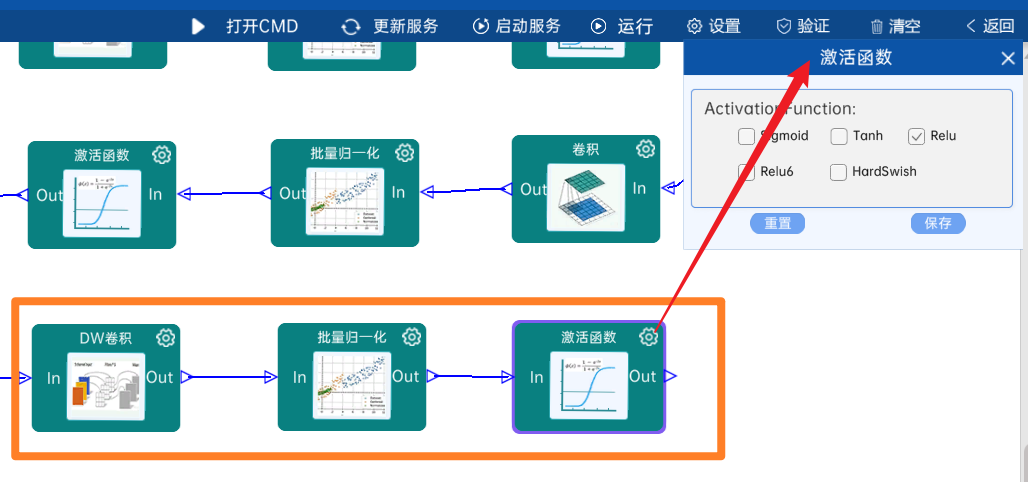
4.2.7 卷积
输入特征矩阵是(56 x 56 x 128),本层卷积核的宽、高、通道、个数是(1 x 1 x 128 x 128),步长为1,padding方式为SAME,经过计算可知,输出特征矩阵为(56 x 56 x 128)。
本层之后要经过batchNorm进行归一化,以及Relu激活函数,如下图:
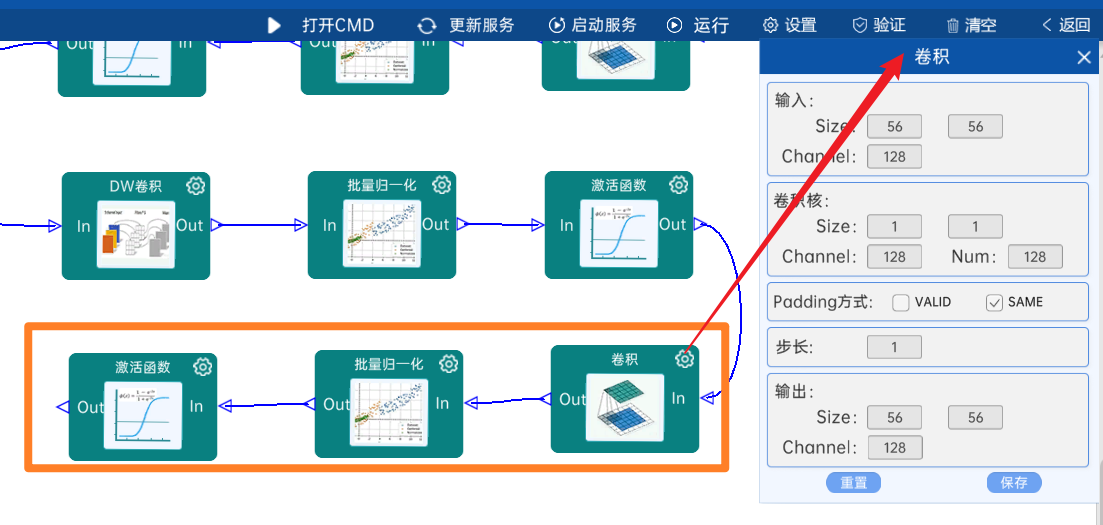
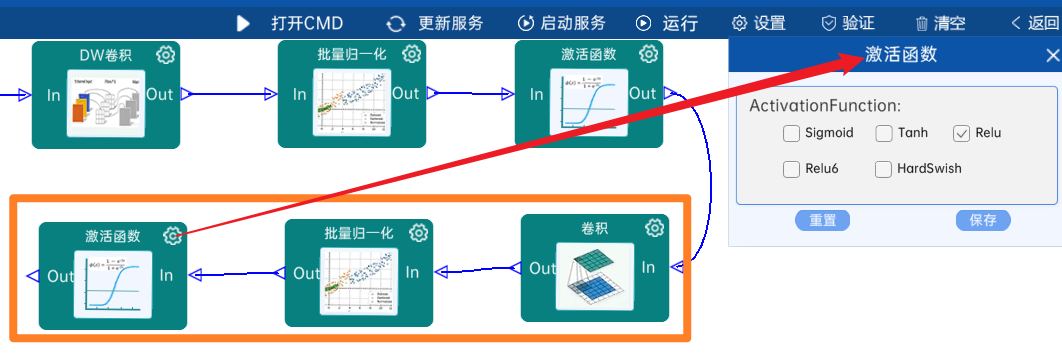
4.2.8 DW卷积
输入特征矩阵是(56 x 56 x 128),本层卷积核的宽、高、个数是(3 x 3 x 128),步长为2,padding方式为SAME,经过计算可知,输出特征矩阵为(28 x 28 x 128)。
本层之后要经过batchNorm进行归一化,以及Relu激活函数,如下图:
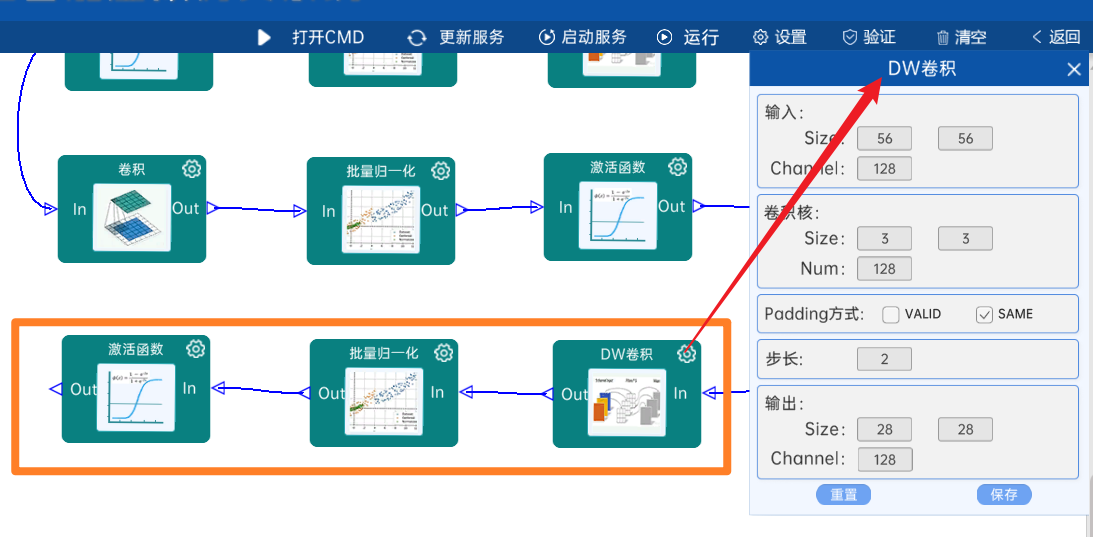
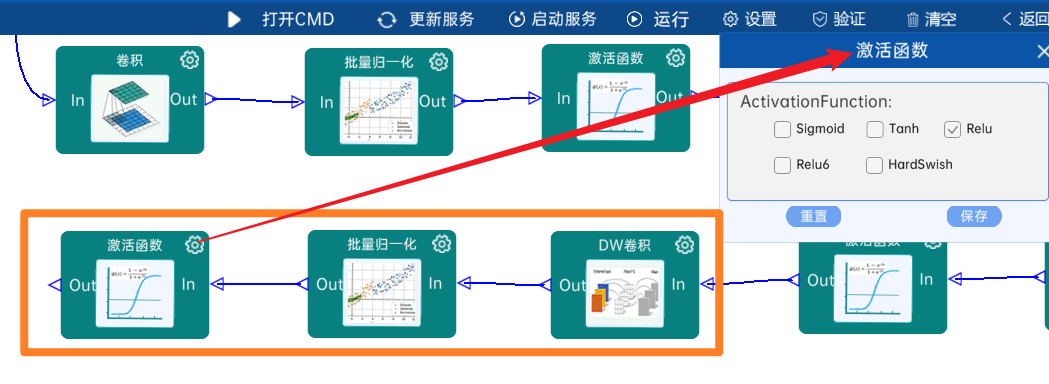
4.2.9 卷积
输入特征矩阵是(28 x 28 x 128),本层卷积核的宽、高、通道、个数是(1 x 1 x 128 x 256),步长为1,padding方式为SAME,经过计算可知,输出特征矩阵为(28 x 28 x 256)。
本层之后要经过batchNorm进行归一化,以及Relu激活函数,如下图:
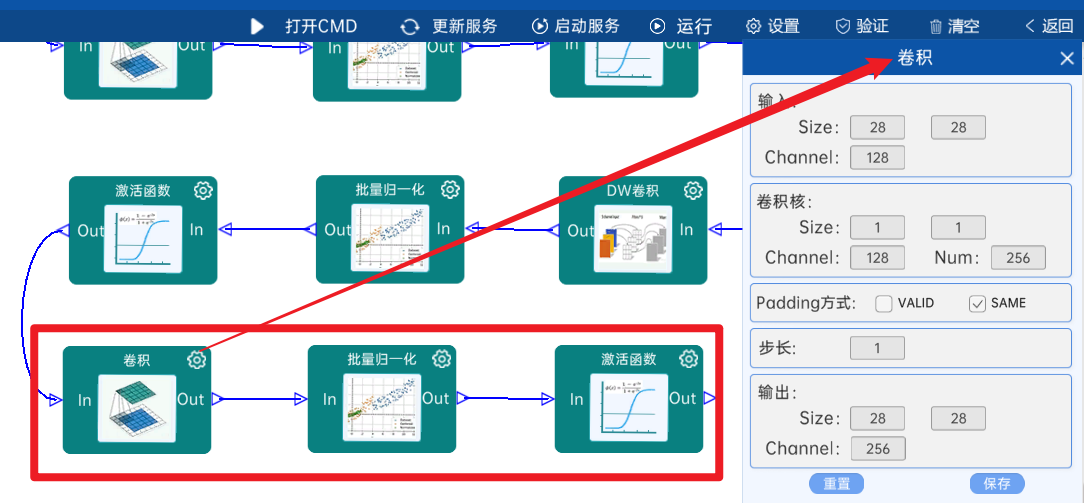
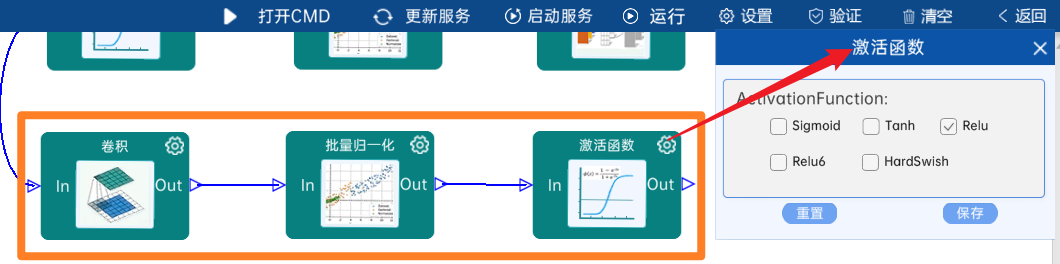
4.2.10 DW卷积
输入特征矩阵是(28 x 28 x 256),本层卷积核的宽、高、个数是(3 x 3 x 256),步长为1,padding方式为SAME,经过计算可知,输出特征矩阵为(28 x 28 x 256)。
本层之后要经过batchNorm进行归一化,以及Relu激活函数,如下图:
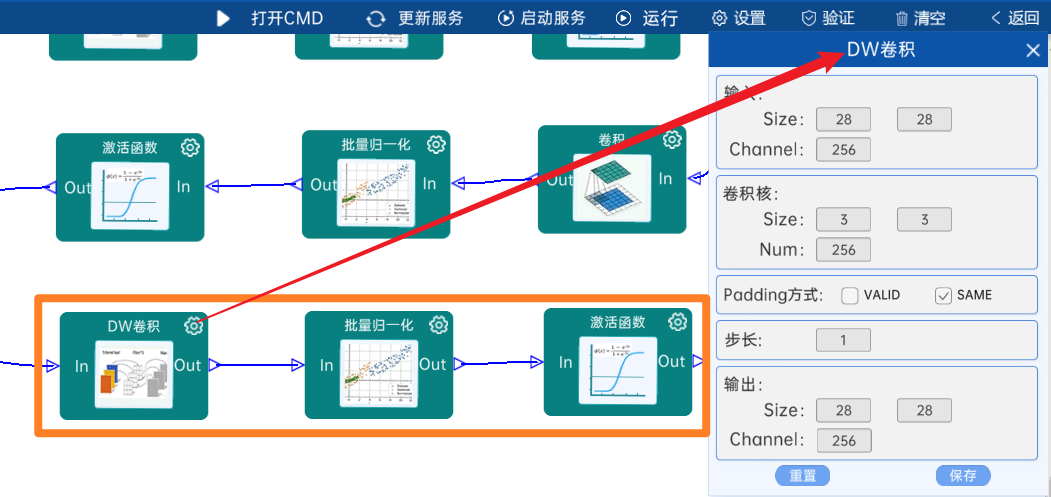
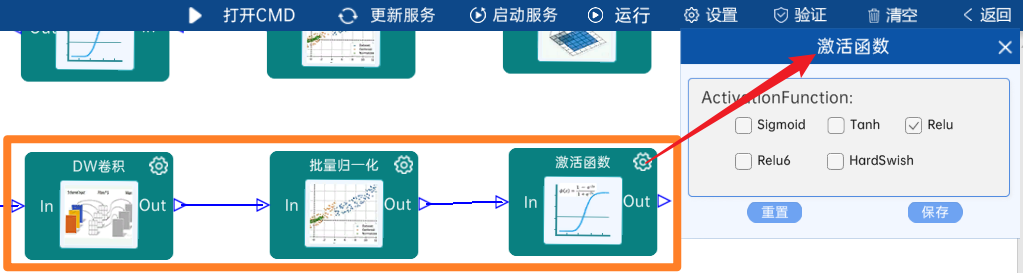
4.2.11 卷积
输入特征矩阵是(28 x 28 x 256),本层卷积核的宽、高、通道、个数是(1 x 1 x 256 x 256),步长为1,padding方式为SAME,经过计算可知,输出特征矩阵为(28 x 28 x 256)。
本层之后要经过batchNorm进行归一化,以及Relu激活函数,如下图:
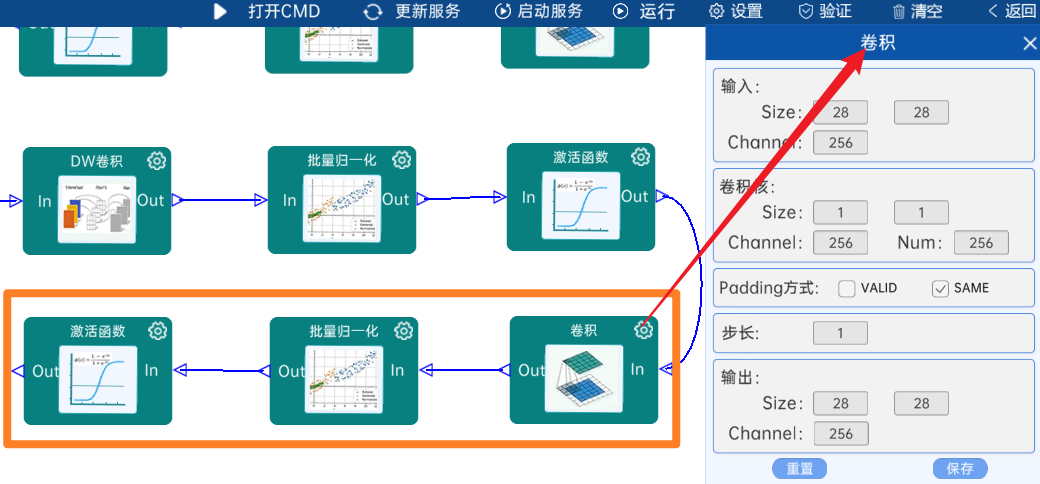
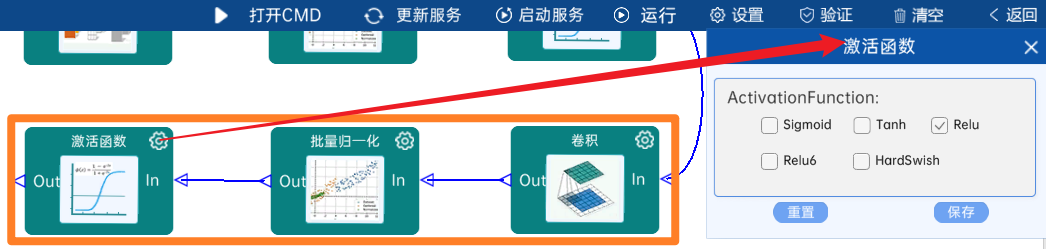
4.2.12 DW卷积
输入特征矩阵是(28 x 28 x 256),本层卷积核的宽、高、个数是(3 x 3 x 256),步长为2,padding方式为SAME,经过计算可知,输出特征矩阵为(14 x 14 x 256)。
本层之后要经过batchNorm进行归一化,以及Relu激活函数,如下图:
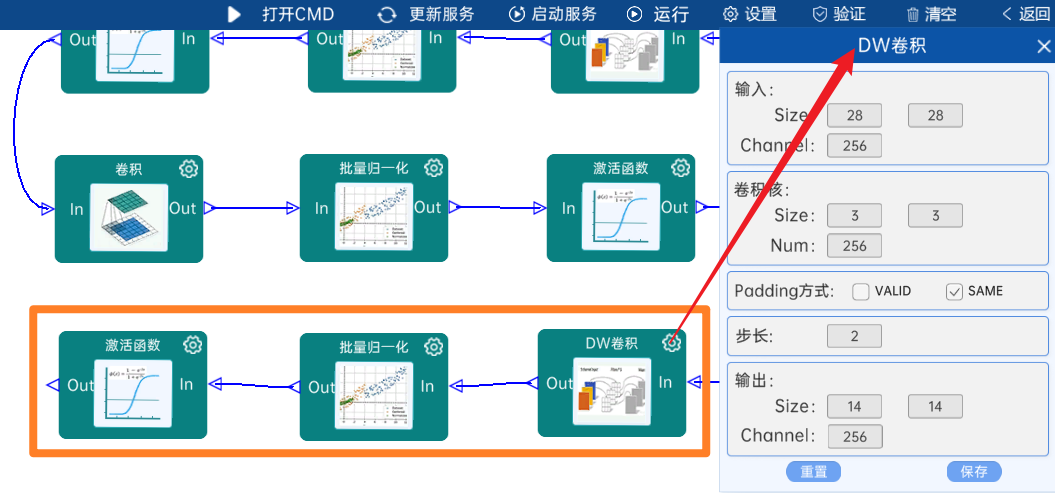
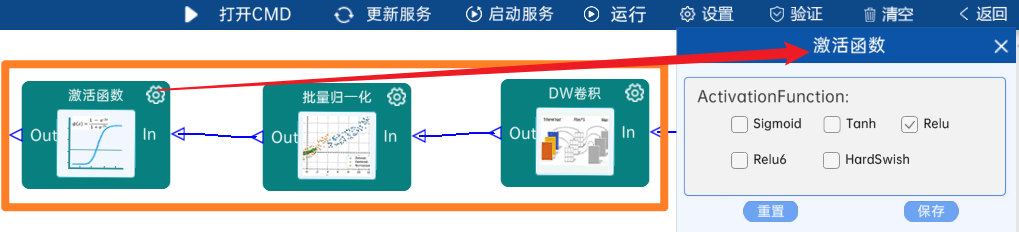
4.2.13 卷积
输入特征矩阵是(14 x 14 x 256),本层卷积核的宽、高、通道、个数是(1 x 1 x 256 x 512),步长为1,padding方式为SAME,经过计算可知,输出特征矩阵为(14 x 14 x 512)。
本层之后要经过batchNorm进行归一化,以及Relu激活函数,如下图:
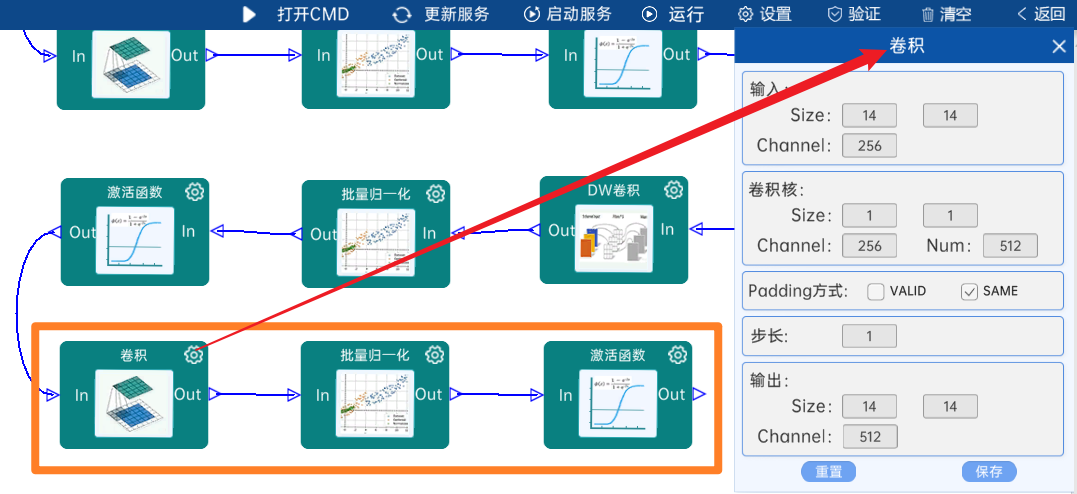
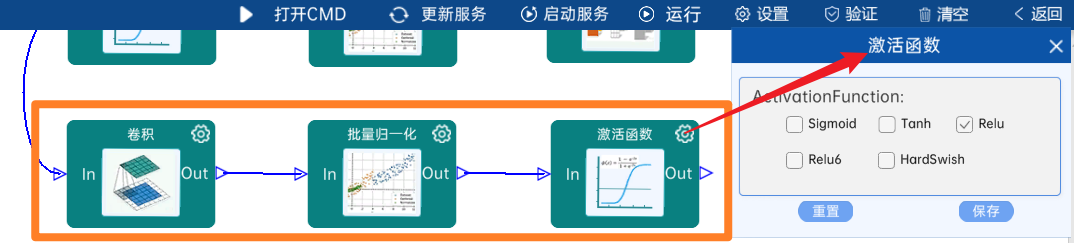
4.2.14 DW卷积
输入特征矩阵是(14 x 14 x 512),本层卷积核的宽、高、个数是(3 x 3 x 512),步长为1,padding方式为SAME,经过计算可知,输出特征矩阵为(14 x 14 x 512)。
本层之后要经过batchNorm进行归一化,以及Relu激活函数,如下图:
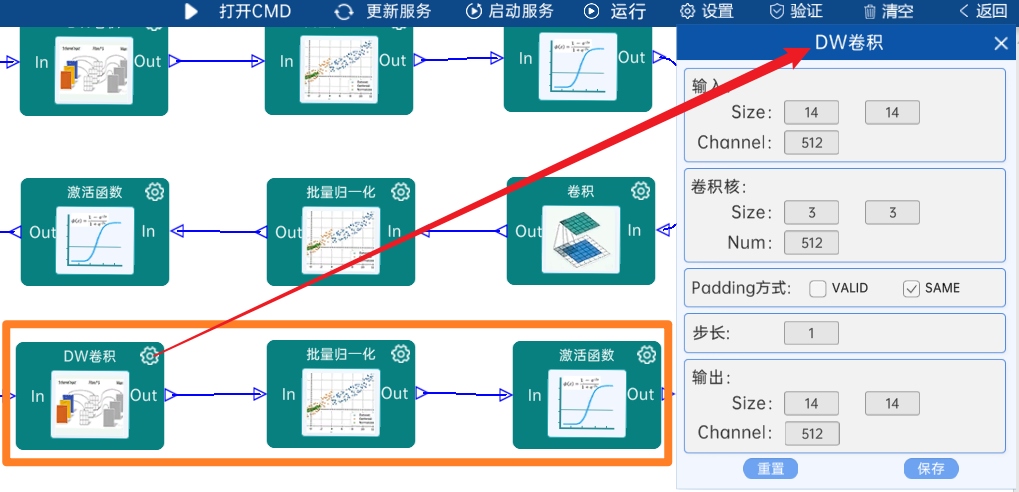
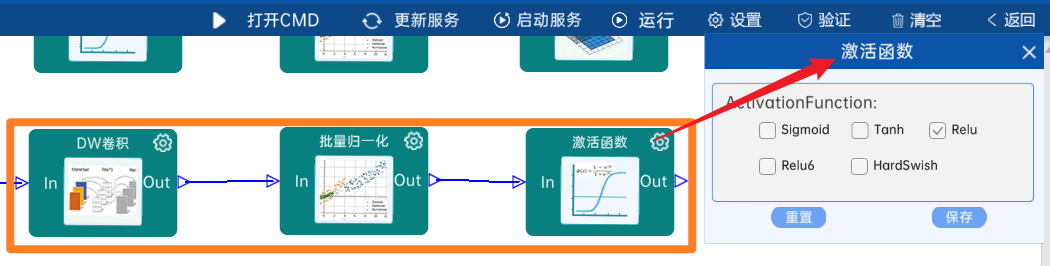
4.2.15 卷积
输入特征矩阵是(14 x 14 x 512),本层卷积核的宽、高、通道、个数是(1 x 1 x 512 x 512),步长为1,padding方式为SAME,经过计算可知,输出特征矩阵为(14 x 14 x 512)。
本层之后要经过batchNorm进行归一化,以及Relu激活函数,如下图:
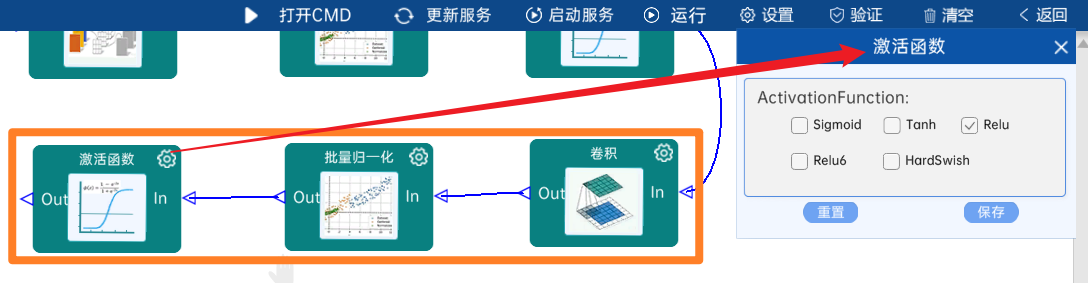
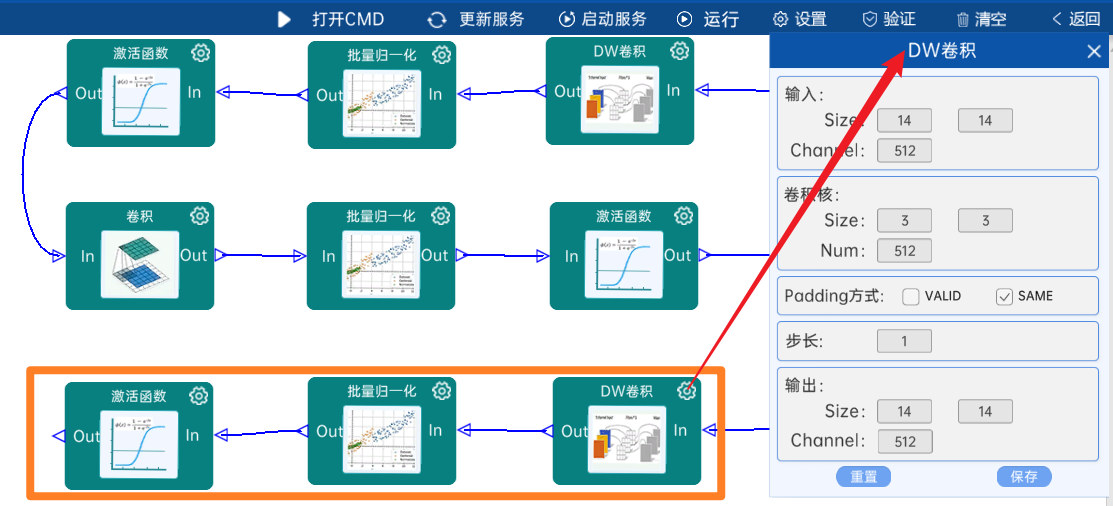
4.2.16 DW卷积
输入特征矩阵是(14 x 14 x 512),本层卷积核的宽、高、个数是(3 x 3 x 512),步长为1,padding方式为SAME,经过计算可知,输出特征矩阵为(14 x 14 x 512)。
本层之后要经过batchNorm进行归一化,以及Relu激活函数,如下图:
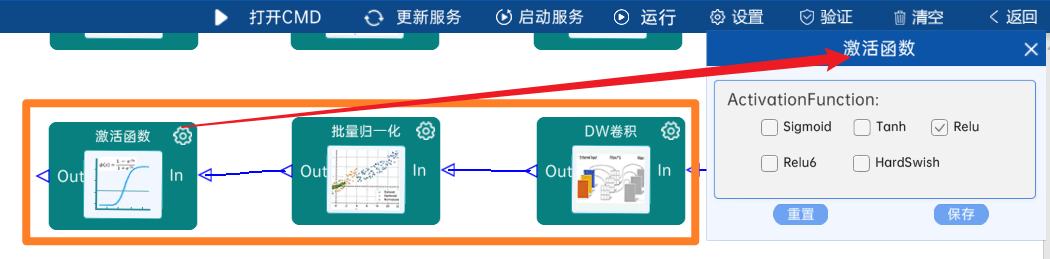
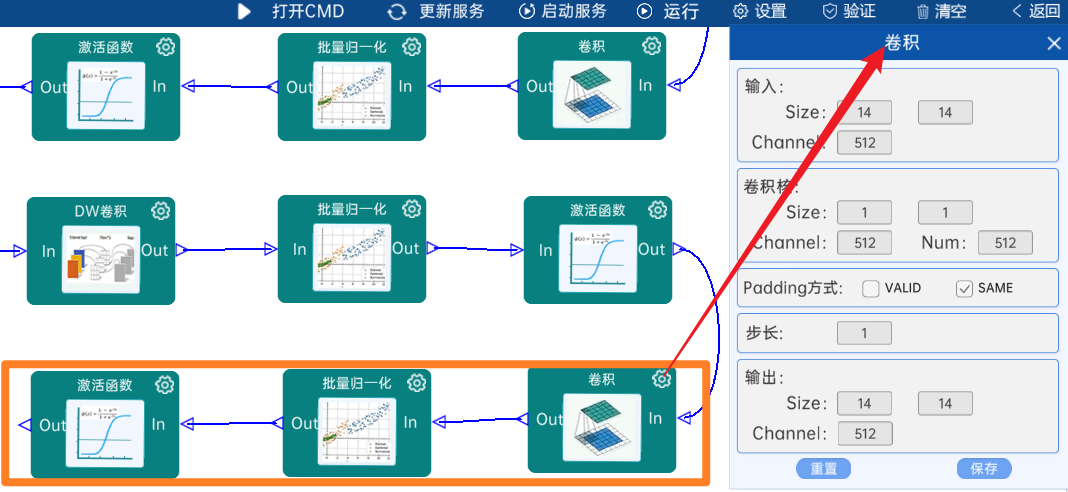
4.2.17 卷积
输入特征矩阵是(14 x 14 x 512),本层卷积核的宽、高、通道、个数是(1 x 1 x 512 x 512),步长为1,padding方式为SAME,经过计算可知,输出特征矩阵为(14 x 14 x 512)。
本层之后要经过batchNorm进行归一化,以及Relu激活函数,如下图:
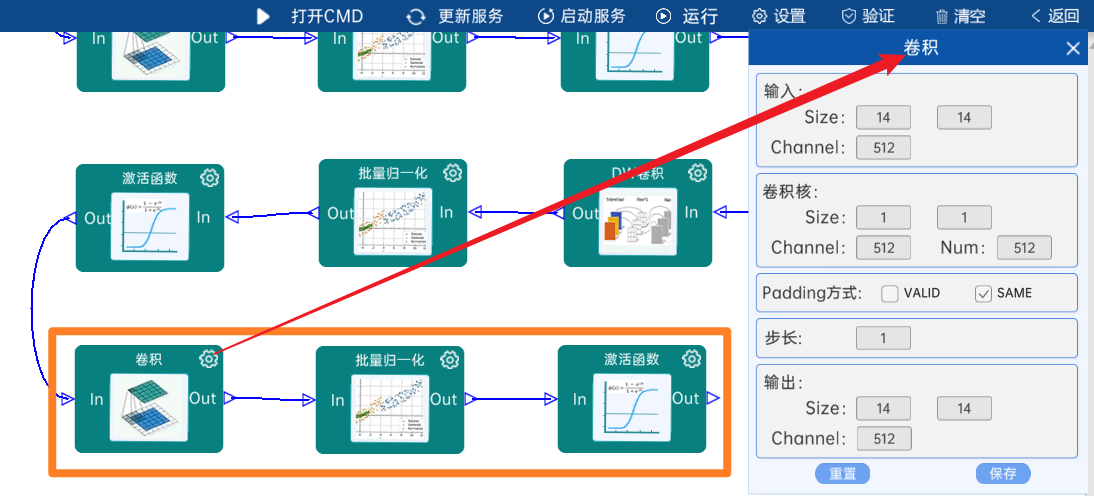
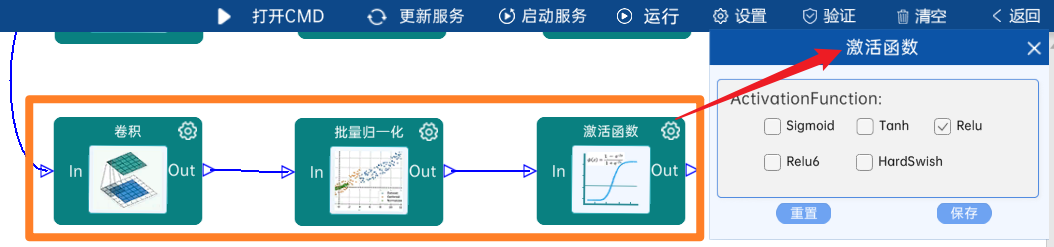
4.2.18 DW卷积
输入特征矩阵是(14 x 14 x 512),本层卷积核的宽、高、个数是(3 x 3 x 512),步长为1,padding方式为SAME,经过计算可知,输出特征矩阵为(14 x 14 x 512)。
本层之后要经过batchNorm进行归一化,以及Relu激活函数,如下图:
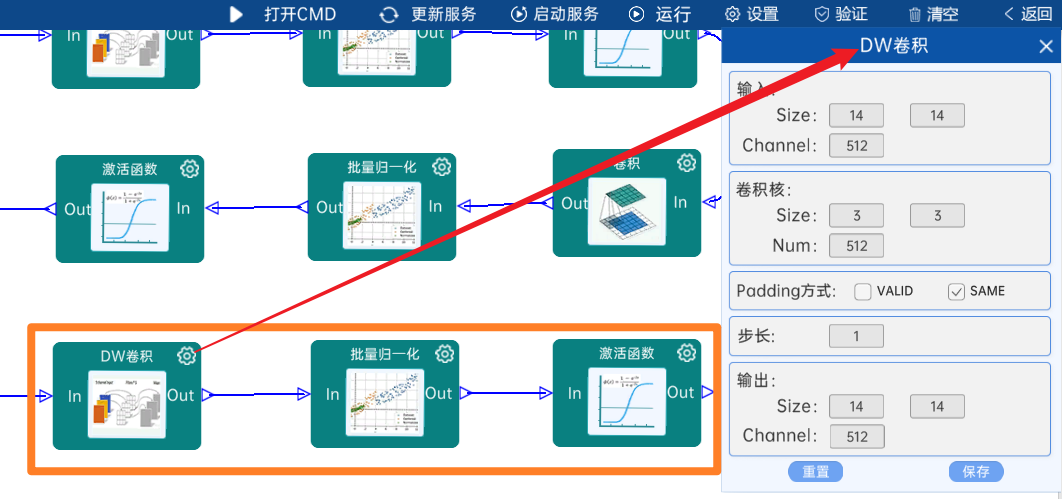
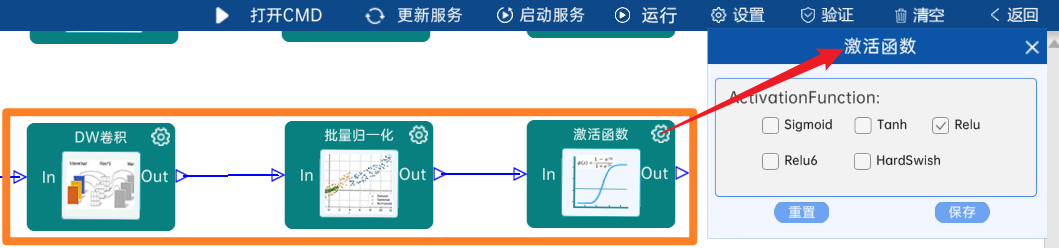
4.2.19 卷积
输入特征矩阵是(14 x 14 x 512),本层卷积核的宽、高、通道、个数是(1 x 1 x 512 x 512),步长为1,padding方式为SAME,经过计算可知,输出特征矩阵为(14 x 14 x 512)。
本层之后要经过batchNorm进行归一化,以及Relu激活函数,如下图:
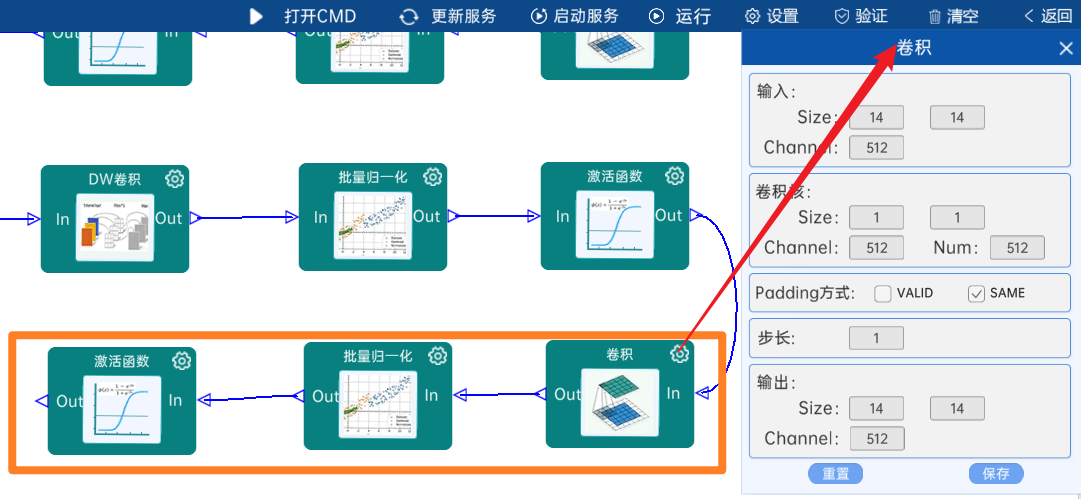
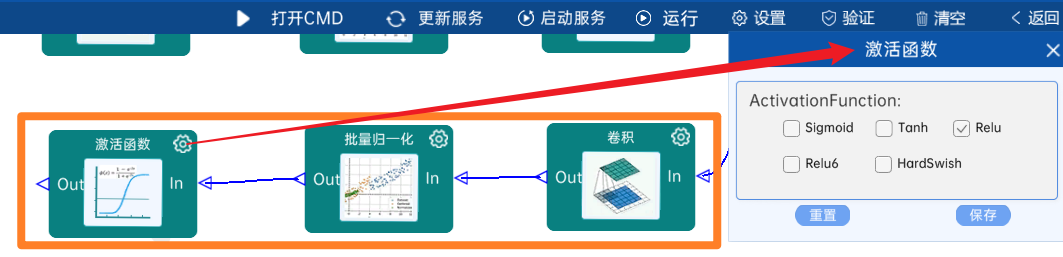
4.2.20 DW卷积
输入特征矩阵是(14 x 14 x 512),本层卷积核的宽、高、个数是(3 x 3 x 512),步长为1,padding方式为SAME,经过计算可知,输出特征矩阵为(14 x 14 x 512)。
本层之后要经过batchNorm进行归一化,以及Relu激活函数,如下图:
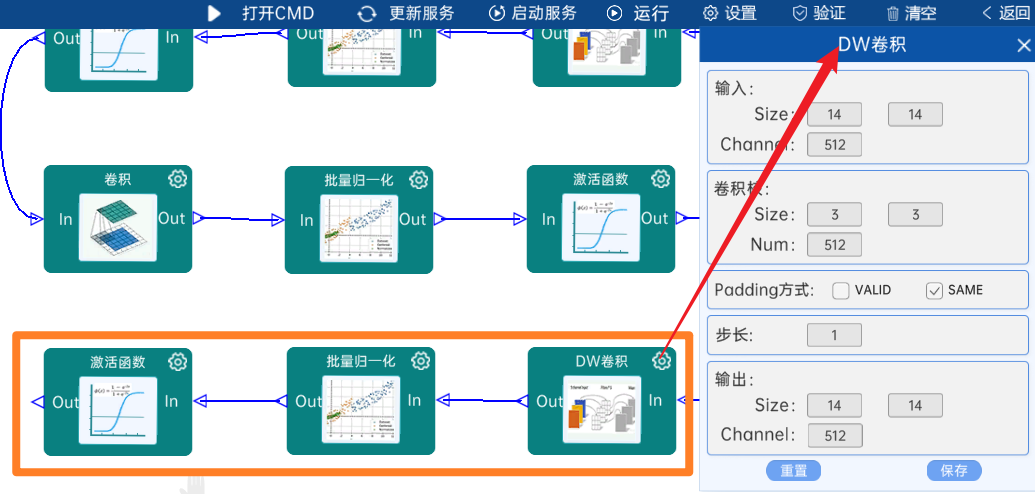
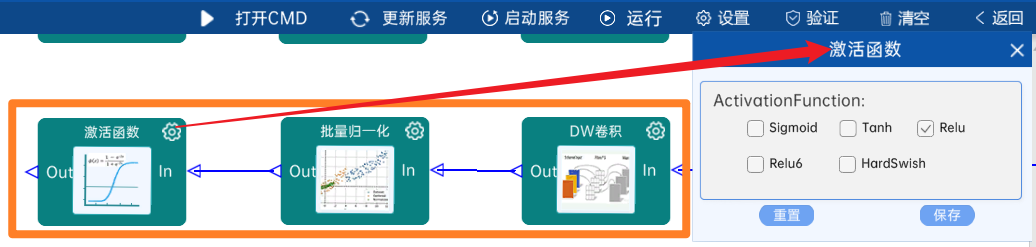
4.2.21 卷积
输入特征矩阵是(14 x 14 x 512),本层卷积核的宽、高、通道、个数是(1 x 1 x 512 x 512),步长为1,padding方式为SAME,经过计算可知,输出特征矩阵为(14 x 14 x 512)。
本层之后要经过batchNorm进行归一化,以及Relu激活函数,如下图:
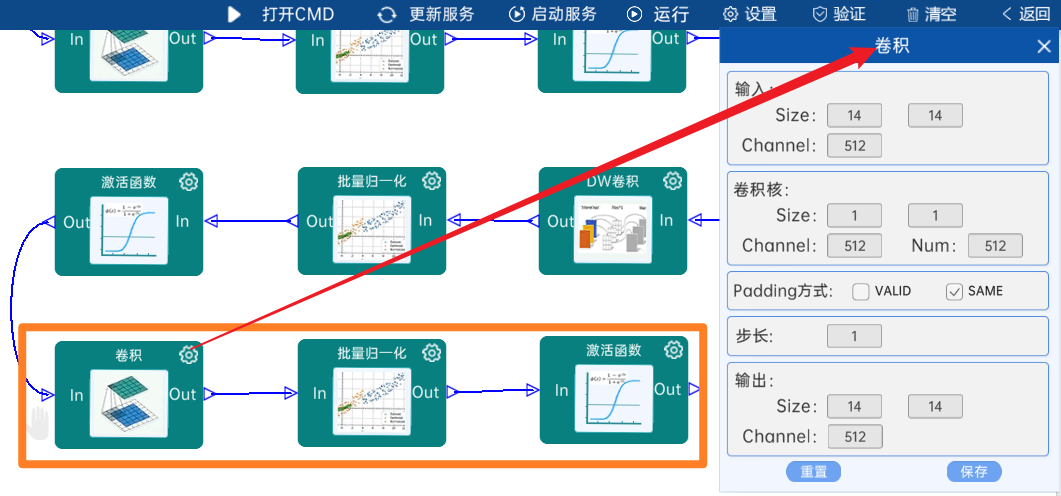
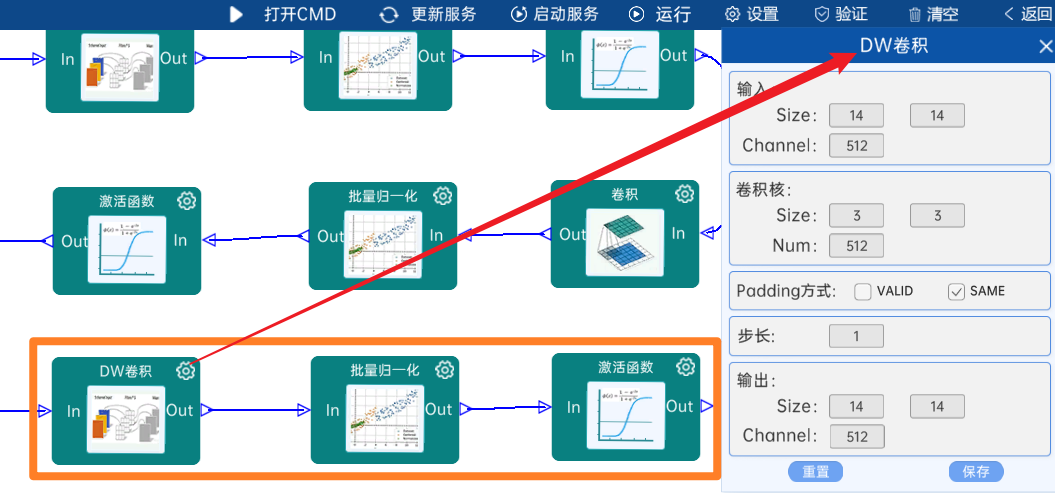
4.2.22 DW卷积
输入特征矩阵是(14 x 14 x 512),本层卷积核的宽、高、个数是(3 x 3 x 512),步长为1,padding方式为SAME,经过计算可知,输出特征矩阵为(14 x 14 x 512)。
本层之后要经过batchNorm进行归一化,以及Relu激活函数,如下图:
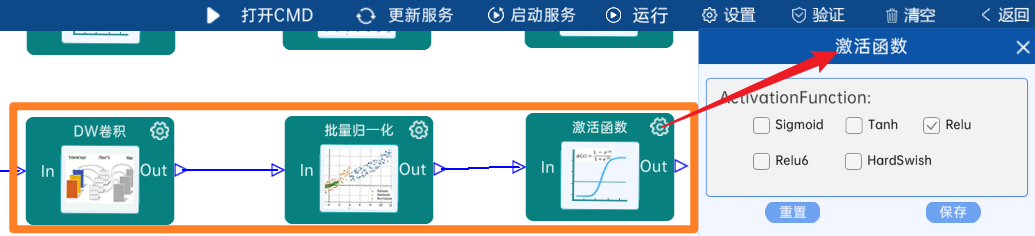
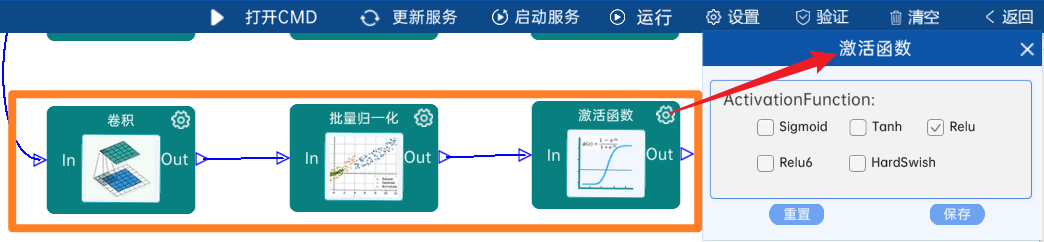
4.2.23 卷积
输入特征矩阵是(14 x 14 x 512),本层卷积核的宽、高、通道、个数是(1 x 1 x 512 x 512),步长为1,padding方式为SAME,经过计算可知,输出特征矩阵为(14 x 14 x 512)。
本层之后要经过batchNorm进行归一化,以及Relu激活函数,如下图:
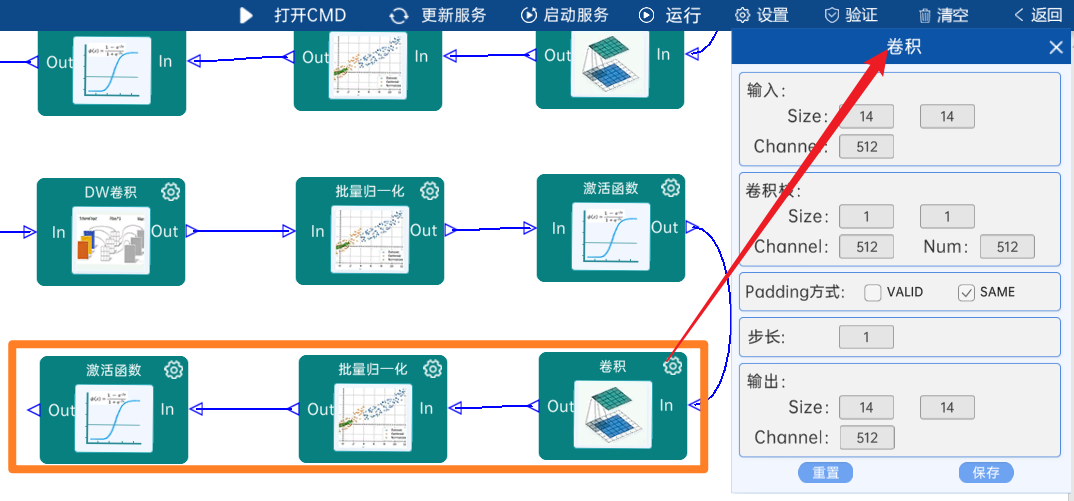
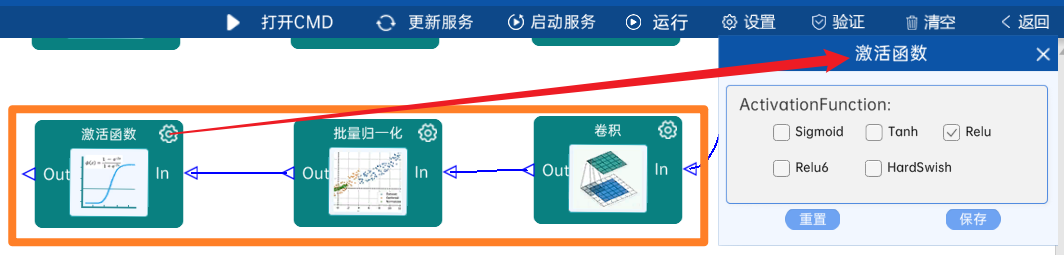
4.2.24 DW卷积
输入特征矩阵是(14 x 14 x 512),本层卷积核的宽、高、个数是(3 x 3 x 512),步长为2,padding方式为SAME,经过计算可知,输出特征矩阵为(7 x 7 x 512)。
本层之后要经过batchNorm进行归一化,以及Relu激活函数,如下图:
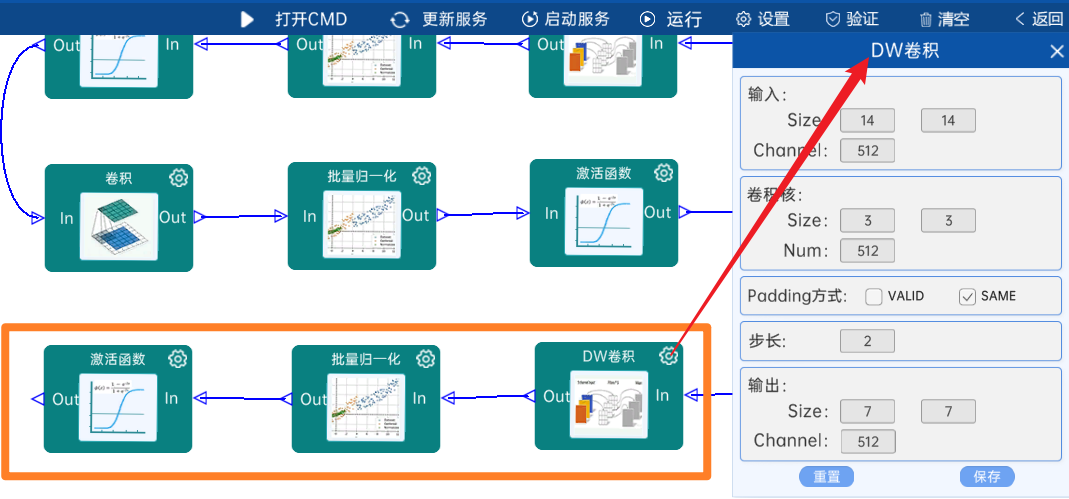
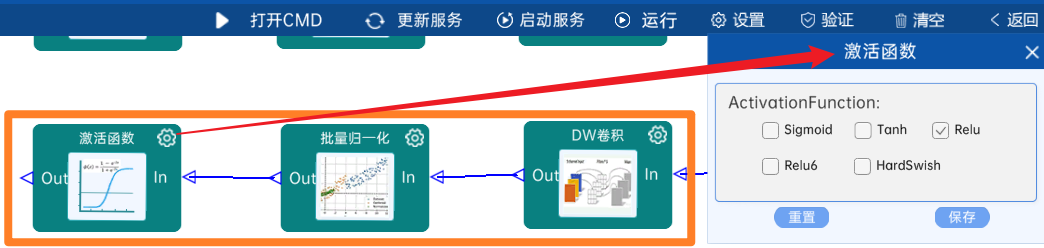
4.2.25 卷积
输入特征矩阵是(7 x 7 x 512),本层卷积核的宽、高、通道、个数是(1 x 1 x 512 x 1024),步长为1,padding方式为SAME,经过计算可知,输出特征矩阵为(7 x 7 x 1024)。
本层之后要经过batchNorm进行归一化,以及Relu激活函数,如下图:
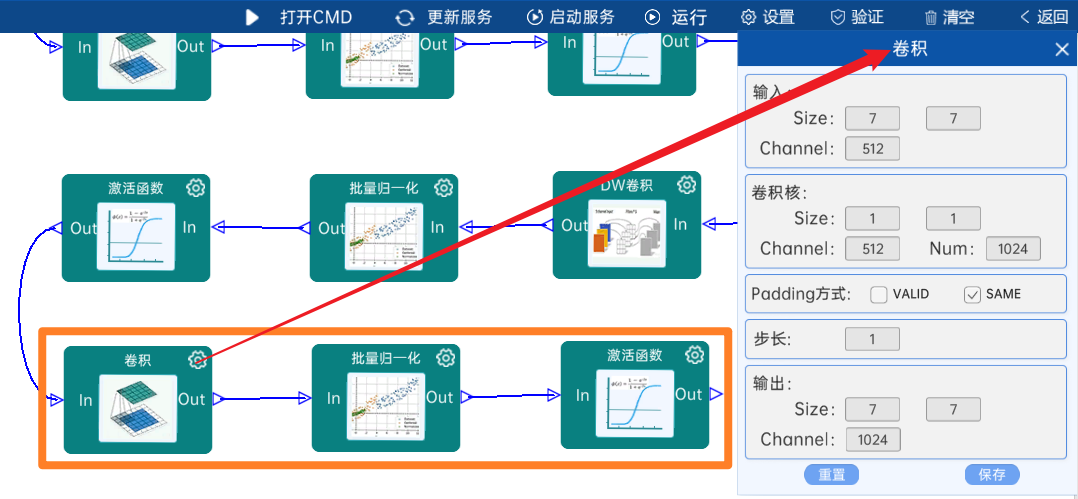
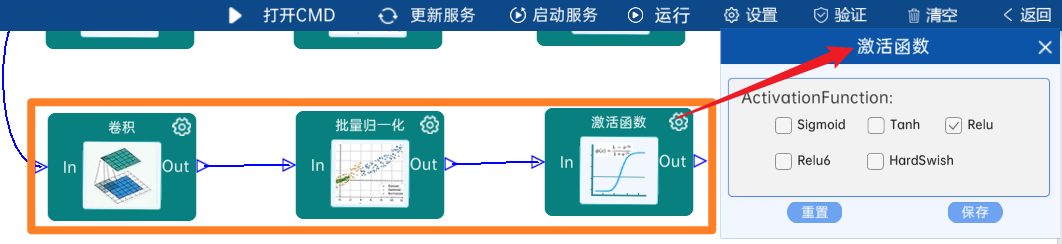
4.2.26 DW卷积
输入特征矩阵是(7 x 7 x 1024),本层卷积核的宽、高、个数是(3 x 3 x 1024),步长为1,padding方式为SAME,经过计算可知,输出特征矩阵为(7 x 7 x 1024)。
本层之后要经过batchNorm进行归一化,以及Relu激活函数,如下图:
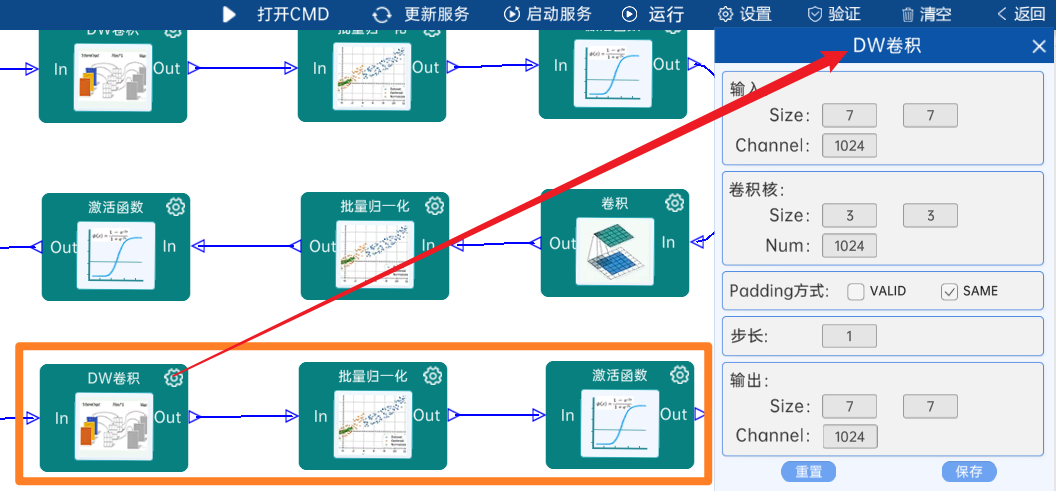
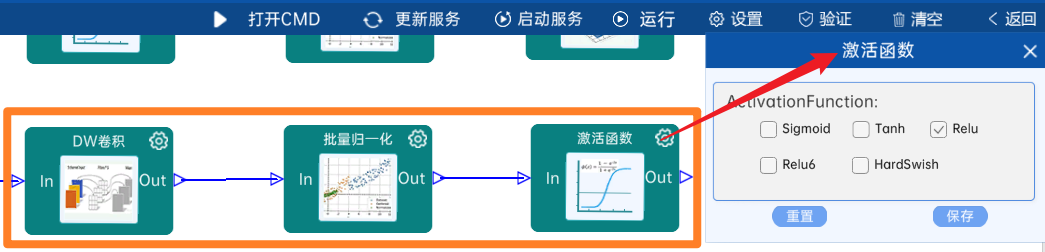
4.2.27 卷积
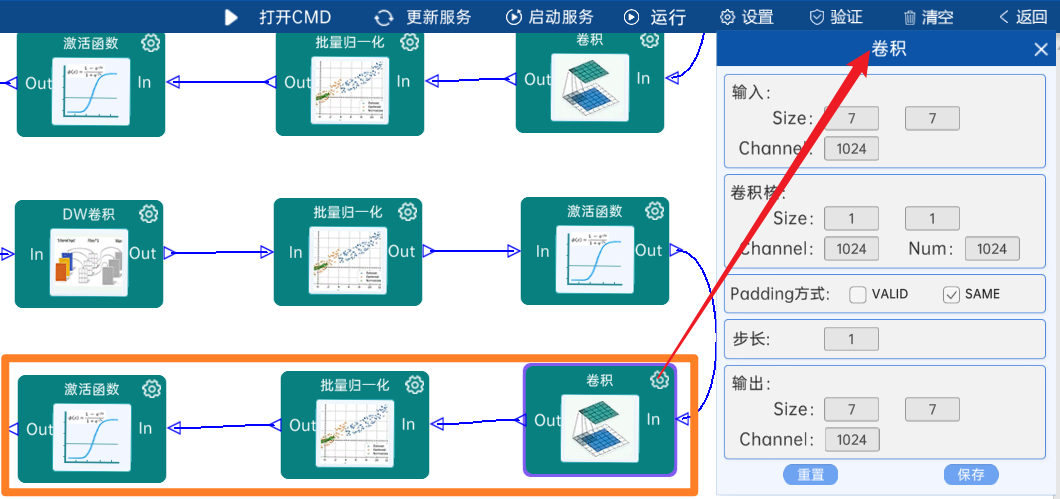
输入特征矩阵是(7 x 7 x 1024),本层卷积核的宽、高、通道、个数是(1 x 1 x 1024 x 1024),步长为1,padding方式为SAME,经过计算可知,输出特征矩阵为(7 x 7 x 1024)。
本层之后要经过batchNorm进行归一化,以及Relu激活函数,如下图:
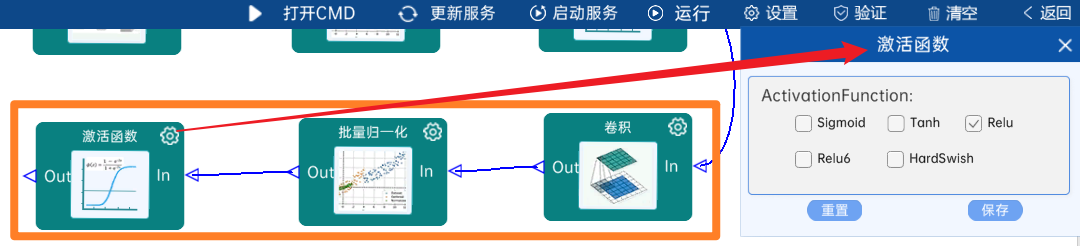
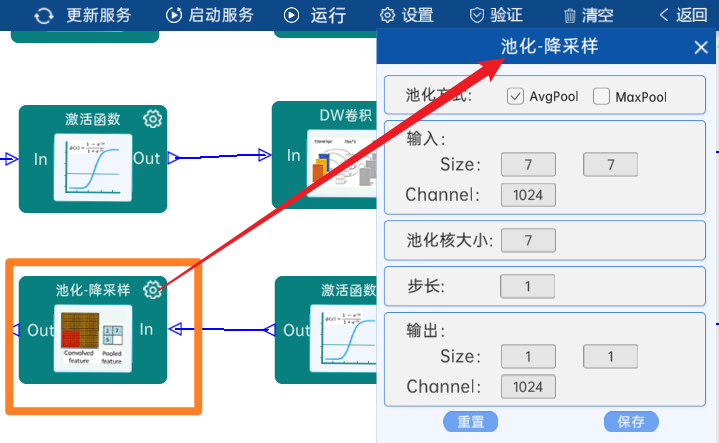
4.2.28 池化-降采样
池化方式为AvgPool,输入特征矩阵是(7 x 7 x 1024),池化核大小为7,步长为1,经过计算可知,输出特征矩阵为(1 x 1 x 1024)。
本层之后要Squeeze进行展平,即使输出矩阵(1 x 1 x 1024)转换成1024个节点,如下图:
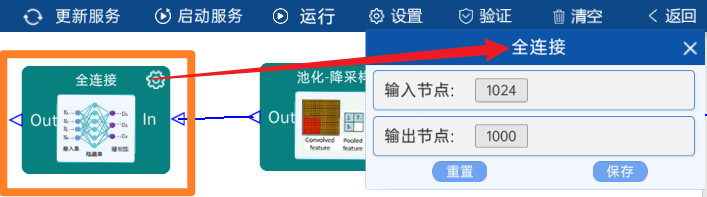
4.2.29 全连接
输入节点是1024,paper中是按照ImageNet数据集做的,所以分类为1000类,输出节点为1000。
如下图:
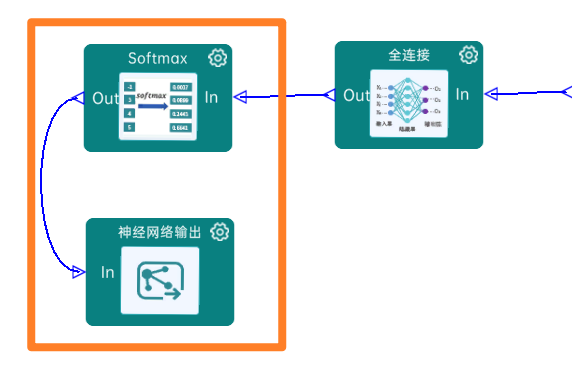
4.2.30 Softmax:
最后通过Softmax实现将多分类的输出值转换为范围在[0, 1]和为1的概率分布,如下图:
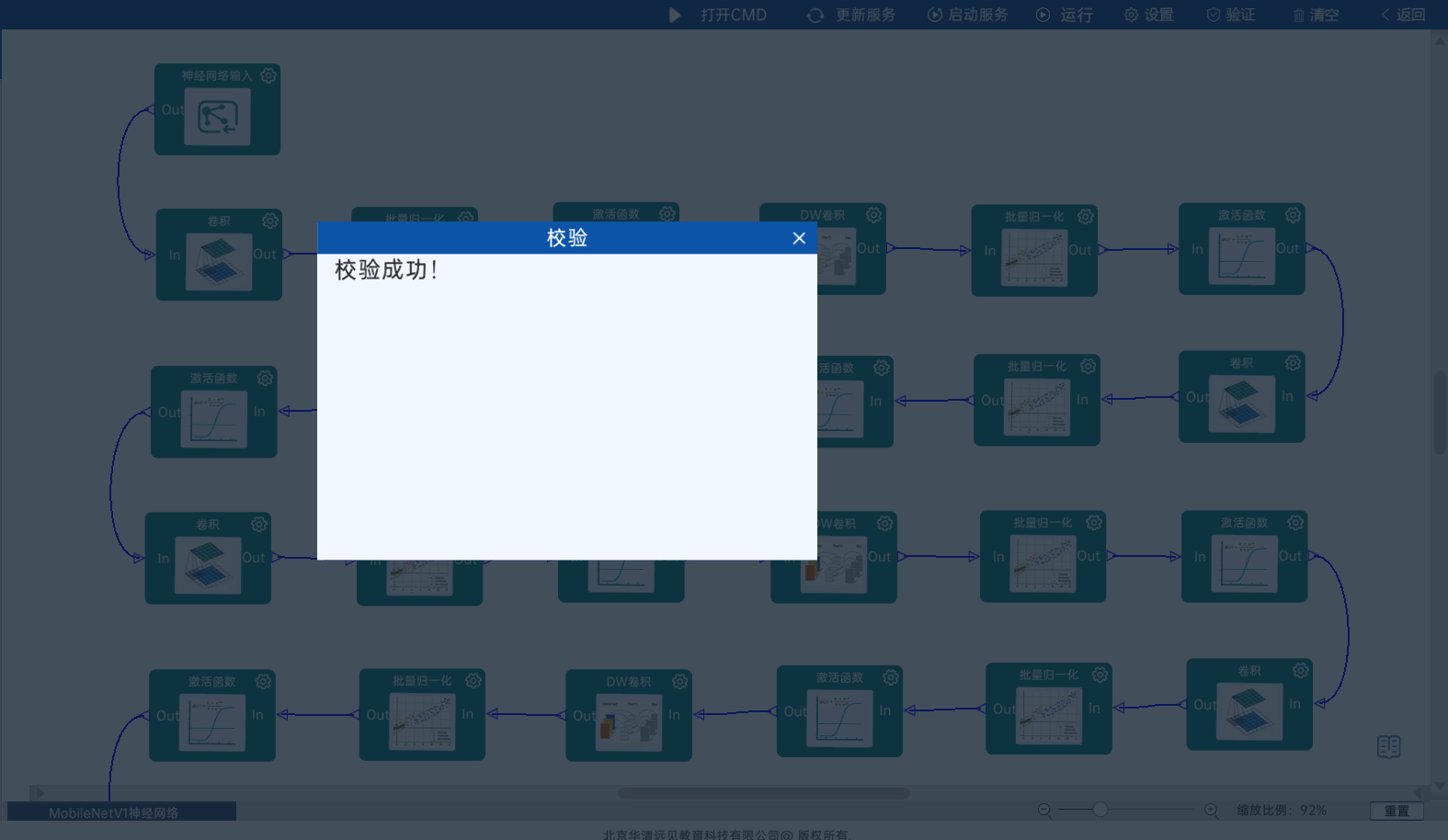
4.2.31 实验验证
本实验主要学习MobileNetV1的网络的相关知识,最后需要进行点击“验证”,验证成功即代表网络结构连接是正确的。
5.代码实现
import torch
import torch.nn as nndef BottleneckV1(in_channels,out_channels,stride):return nn.Sequential(#深度卷积 groups参数设置为in_channels实现深度卷积nn.Conv2d(in_channels=in_channels,out_channels=in_channels,kernel_size=3,stride=stride,padding=1,groups=in_channels),nn.BatchNorm2d(in_channels),#relu6超过6就截断nn.ReLU6(inplace=True),#逐点卷积,1x1卷积用于改变通道数nn.Conv2d(in_channels=in_channels,out_channels=out_channels,kernel_size=1,stride=1),nn.BatchNorm2d(out_channels),nn.ReLU6(inplace=True))class MobileNetV1(nn.Module):def __init__(self,num_classes=1000):super(MobileNetV1,self).__init__()self.first_conv=nn.Sequential(nn.Conv2d(in_channels=3,out_channels=32,kernel_size=3,stride=2,padding=1),nn.BatchNorm2d(32),nn.ReLU(inplace=True))self.bottleneck=nn.Sequential(BottleneckV1(32,64,stride=1),BottleneckV1(64, 128, stride=2),BottleneckV1(128, 128, stride=1),BottleneckV1(128, 256, stride=2),BottleneckV1(256, 256, stride=1),BottleneckV1(256, 512, stride=2),# 连续5个相同结构的瓶颈层BottleneckV1(512, 512, stride=1),BottleneckV1(512, 512, stride=1),BottleneckV1(512, 512, stride=1),BottleneckV1(512, 512, stride=1),BottleneckV1(512, 512, stride=1),BottleneckV1(512, 1024, stride=2),BottleneckV1(1024, 1024, stride=1))self.avg_pool=nn.AvgPool2d(kernel_size=7,stride=1)self.linear=nn.Linear(in_features=1024,out_features=num_classes)self.dropout = nn.Dropout(p=0.2)self.softmax = nn.Softmax(dim=1)def forward(self,x):x = self.first_conv(x)x = self.bottleneck(x)x = self.avg_pool(x)x = x.view(x.size(0), -1)x = self.dropout(x)x = self.linear(x)out = self.softmax(x)return out
if __name__ == '__main__':model = MobileNetV1()print(model)input = torch.randn(1, 3, 224, 224)out = model(input)print(out.shape)