初次使用基于K3S的大数据平台
文章目录
- 1. CloudEon概述
- 2. 查看公有镜像
- 3. 基于镜像创建云主机
- 4. 大数据服务管理
- 4.1 启动cloudeon服务
- 4.2 进入集群管理后台
- 4.3 查看集群服务状况
- 5. 玩一玩HDFS
- 5.1 HDFS WebUI
- 5.2 HDFS Shell
- 5.2.1 查看所有命名空间的Pod
- 5.2.2 进入名称节点的Pod容器内部
- 5.2.3 HDFS目录文件操作
- 5.2.4 运行词频统计程序
- 5.2.5 退出名称节点的Pod容器
- 6. 实战总结
1. CloudEon概述
- CloudEon 是一款面向大数据与云原生融合场景的智能管理平台,旨在简化 Hadoop、Spark、Hive 等开源大数据组件在 Kubernetes(如 K3s)环境中的部署、运维与监控。它提供图形化界面,支持集群一键安装、服务启停、配置管理、状态监控和日志查看,降低运维复杂度。CloudEon 深度集成 K3s 轻量级 Kubernetes 集群,适用于边缘计算、私有云及混合云环境,助力企业快速构建和管理容器化大数据平台,提升资源利用率与系统稳定性。
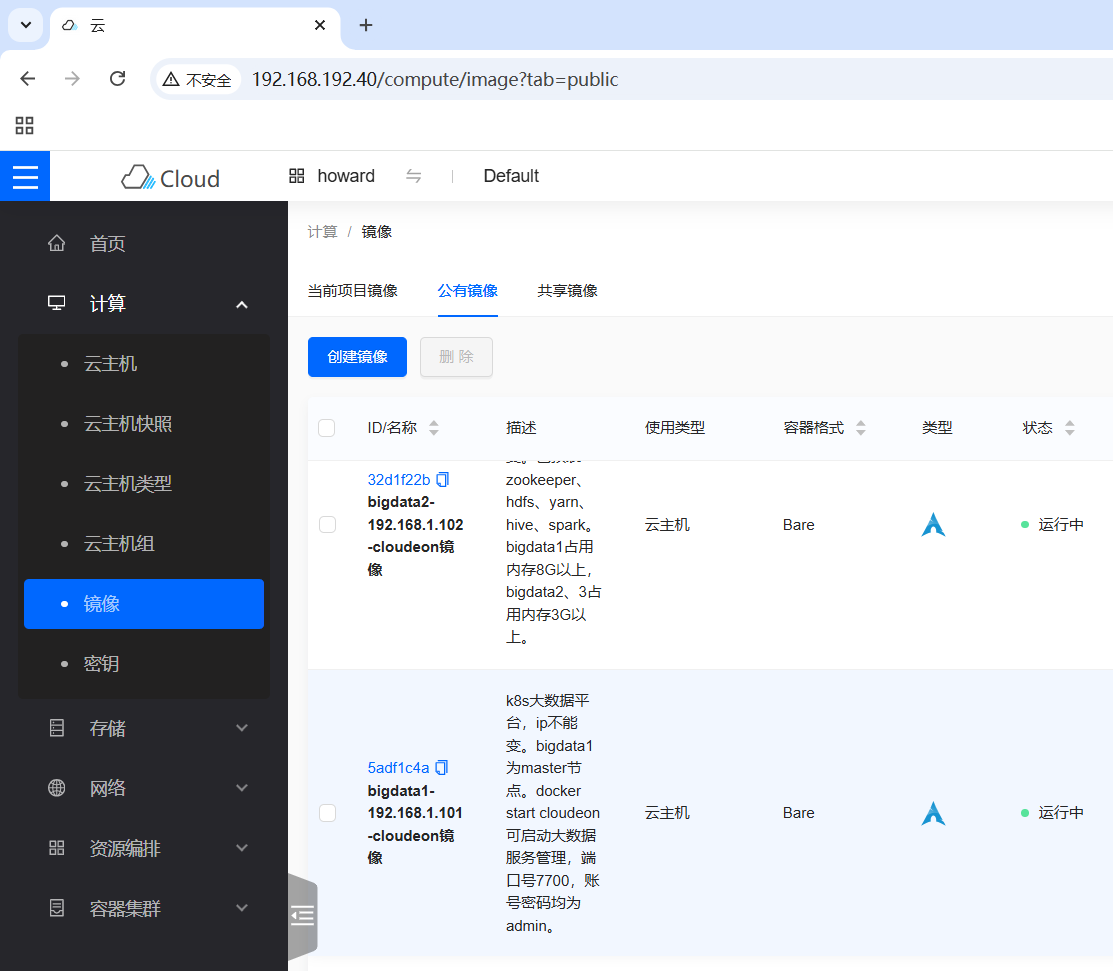
2. 查看公有镜像
- 登录实训云,单击[镜像],选择[公有镜像]选项卡
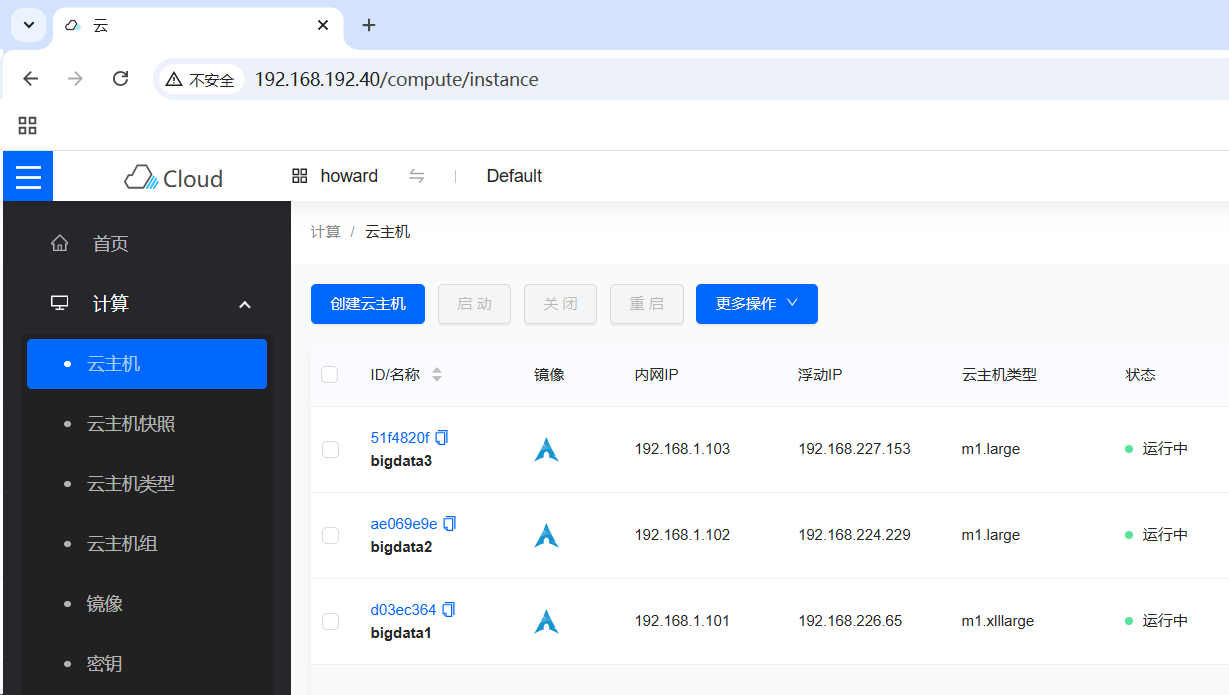
3. 基于镜像创建云主机
- 创建三个云主机,绑定浮动IP地址
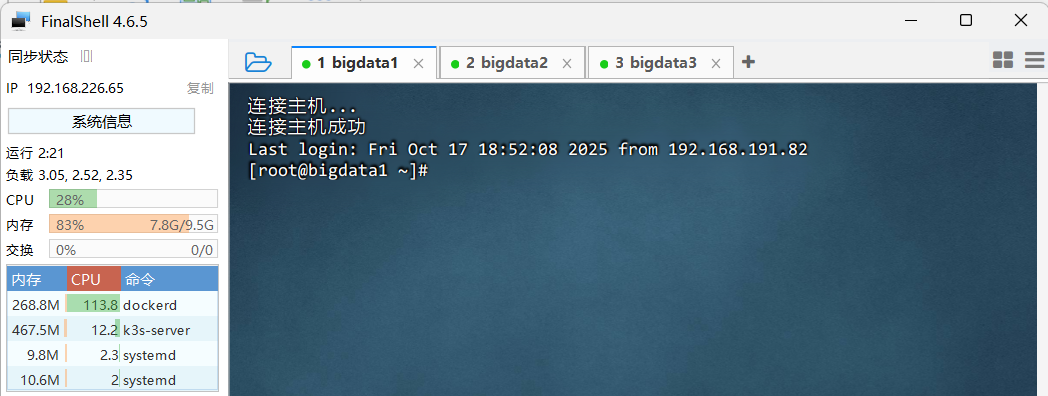
- 利用FinalShell远程连接三台云主机
4. 大数据服务管理
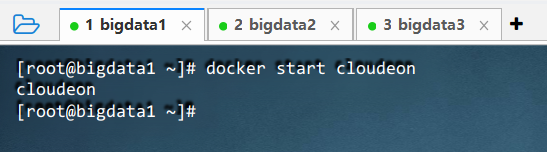
4.1 启动cloudeon服务
- 执行命令:
docker start cloudeon
4.2 进入集群管理后台
- 访问
http://bigdata1:7700/
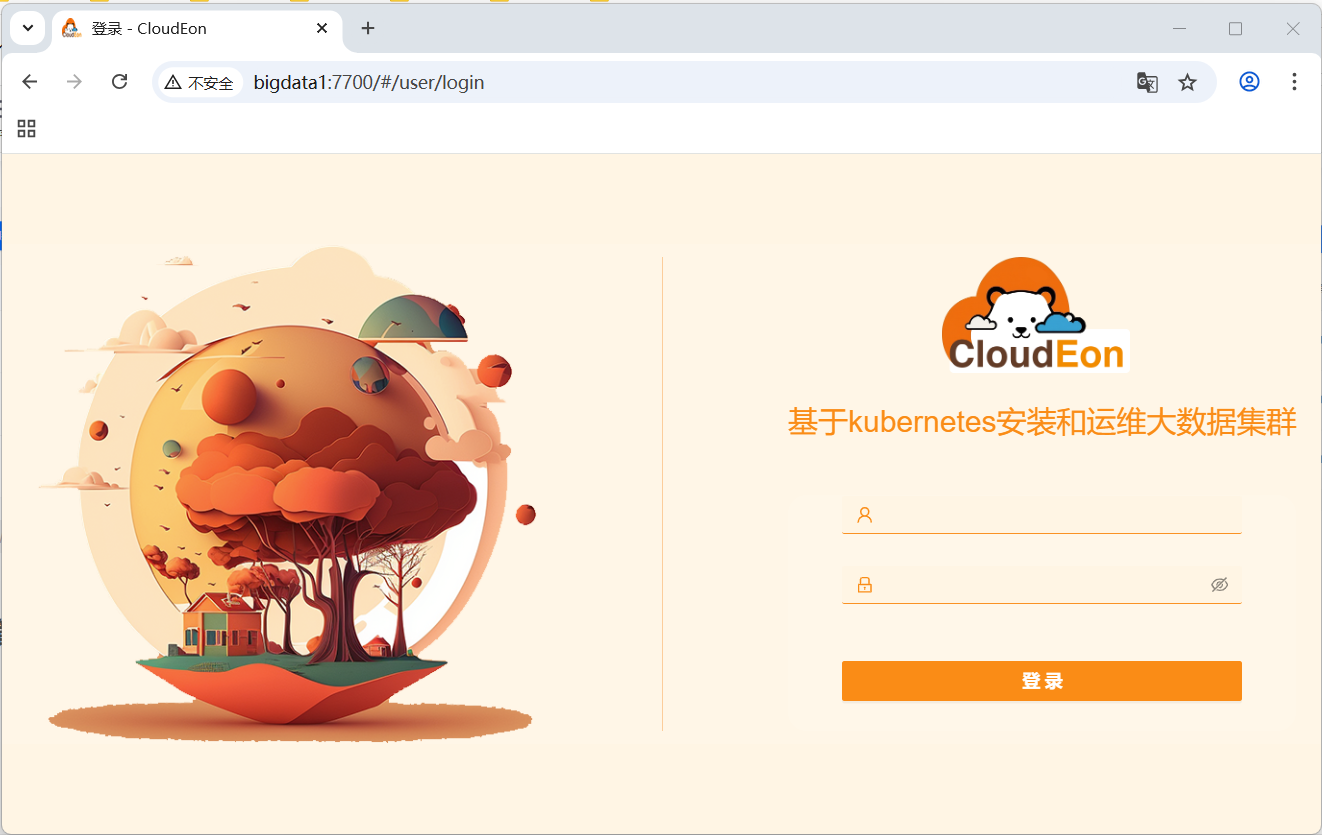
- 输入用户名和密码(都是
admin),单击【登录】按钮,首先看到集群管理界面
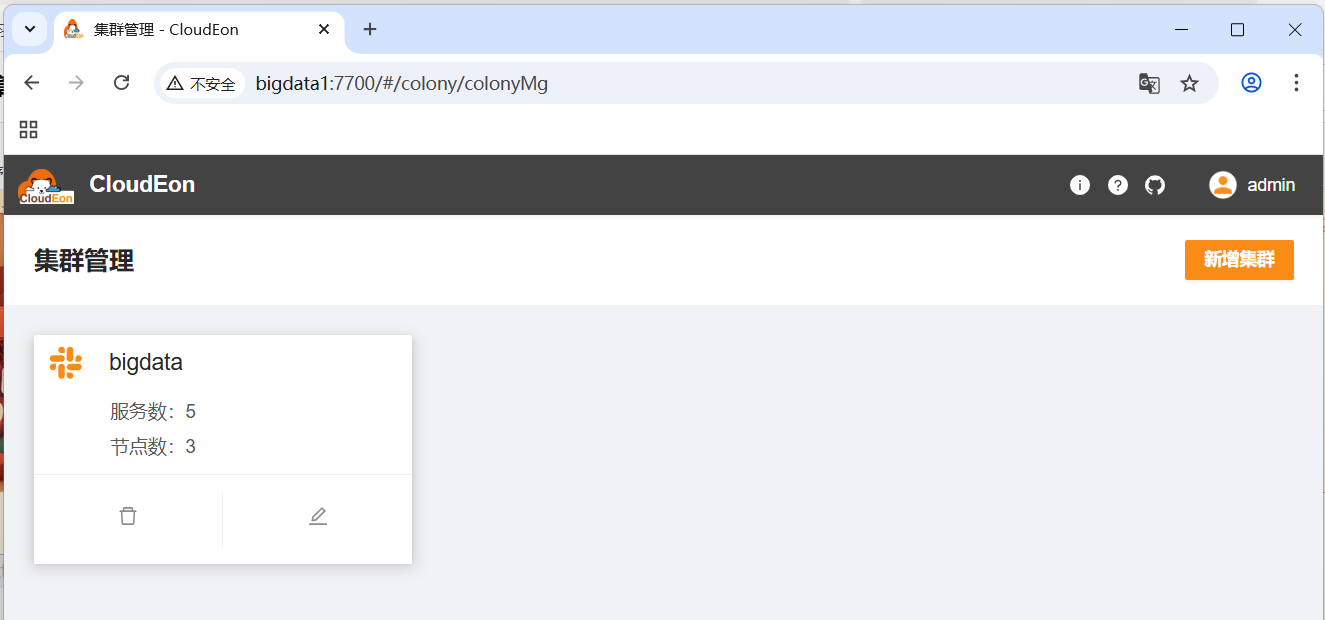
- 单击【bigdata】,查看当前集群详情
4.3 查看集群服务状况
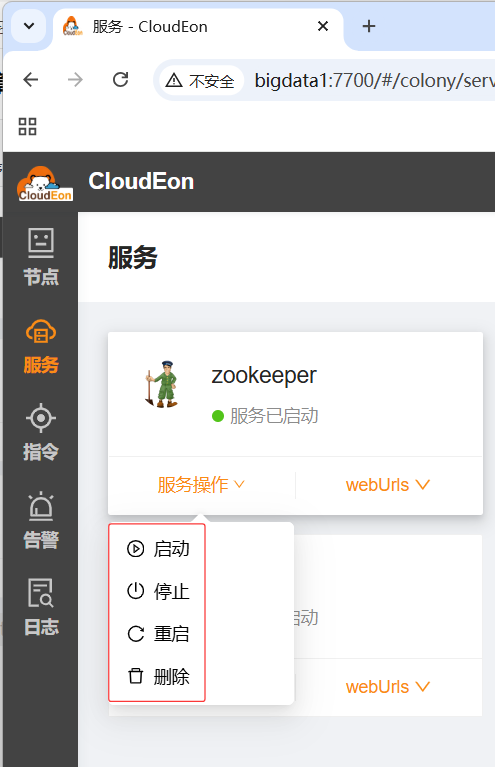
- 单击左边栏的【服务】选项卡
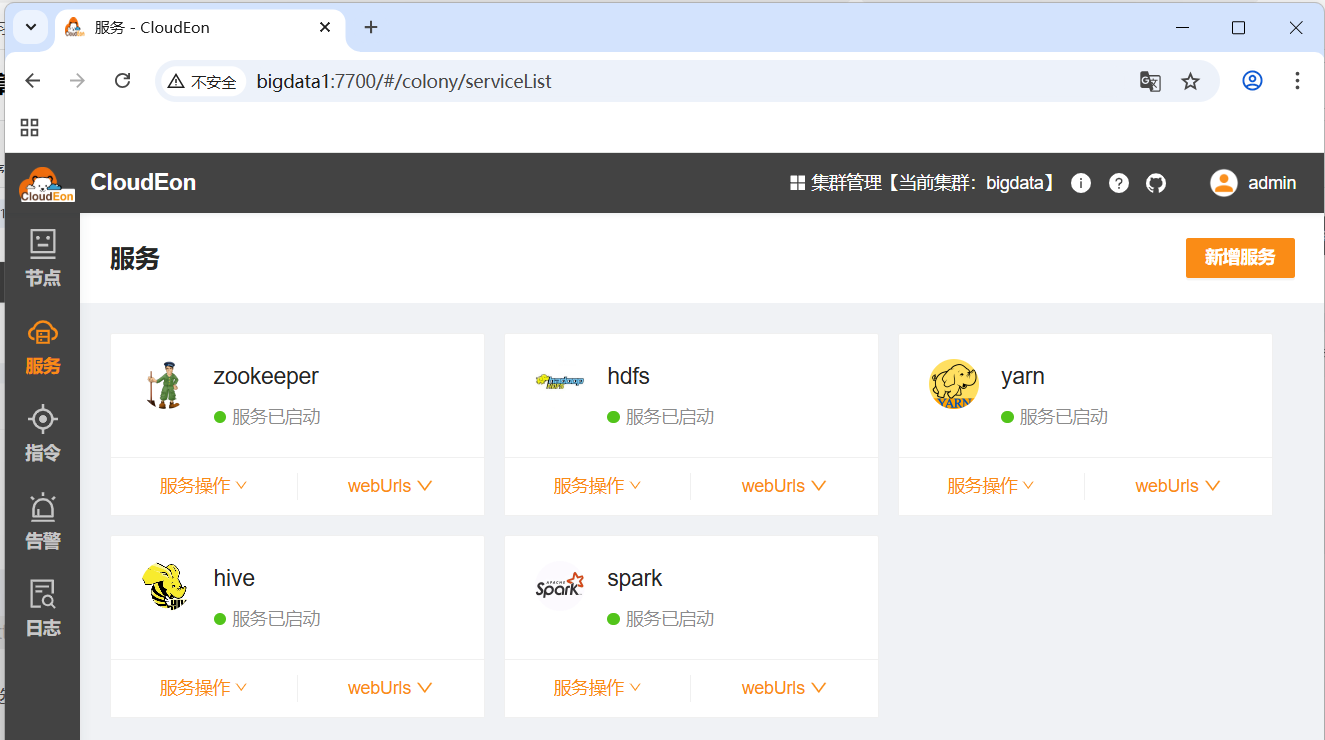
- 可以方便地对服务进行各种操作
5. 玩一玩HDFS
5.1 HDFS WebUI
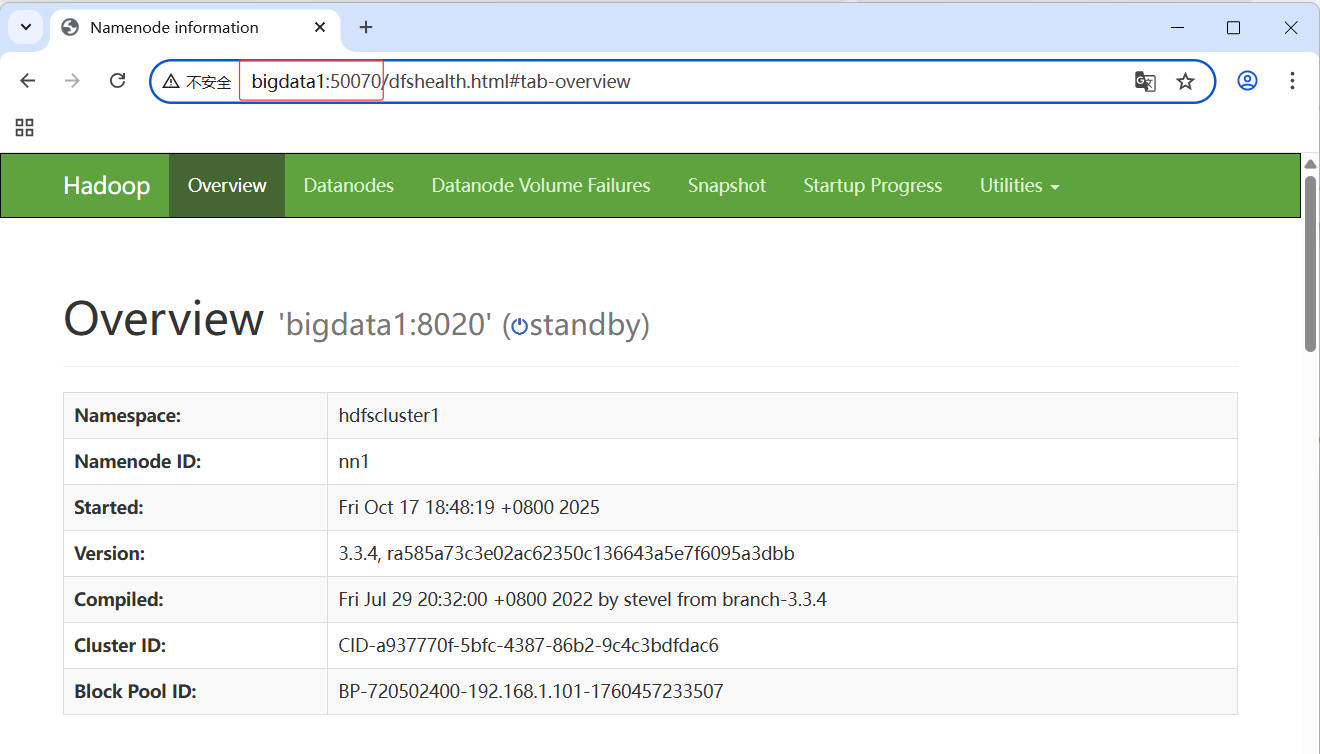
- 访问
http://bigdata1:50070/,备用主节点
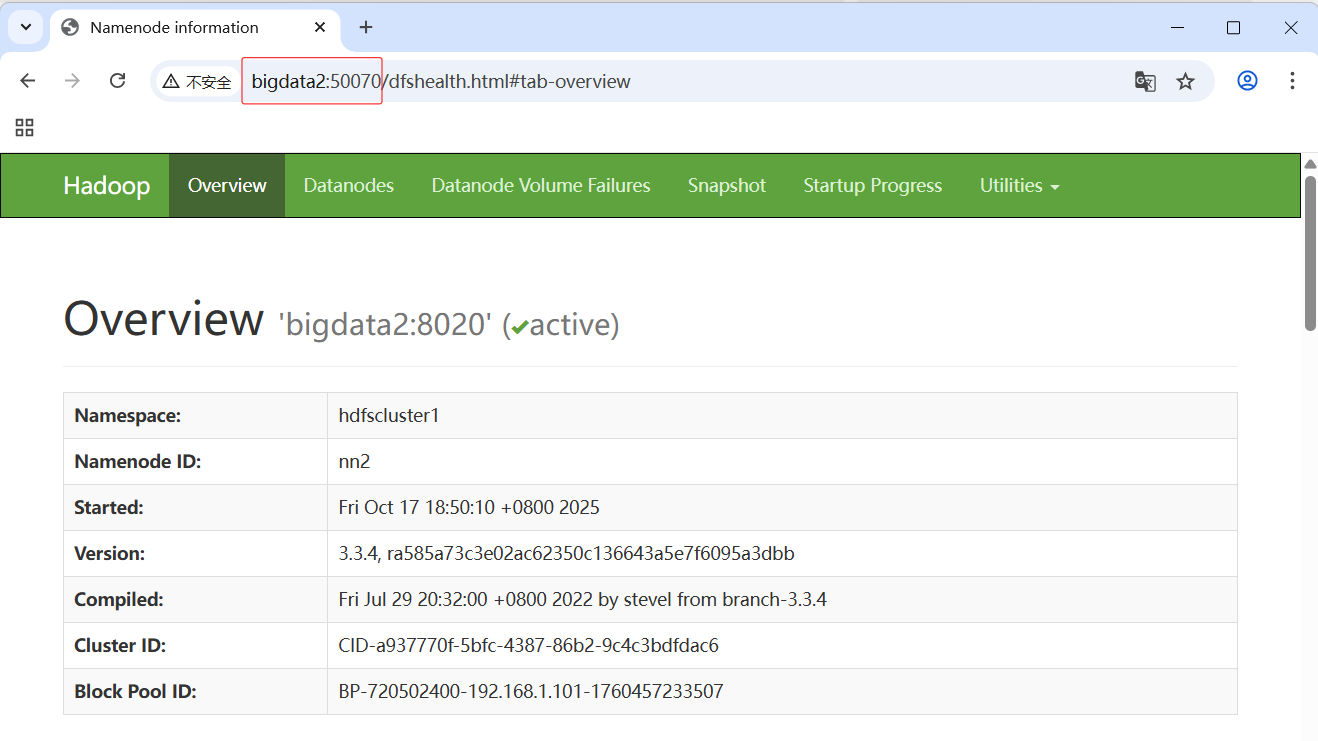
- 访问
http://bigdata2:50070/,当前主节点
- 演示目录和文件操作

5.2 HDFS Shell
5.2.1 查看所有命名空间的Pod
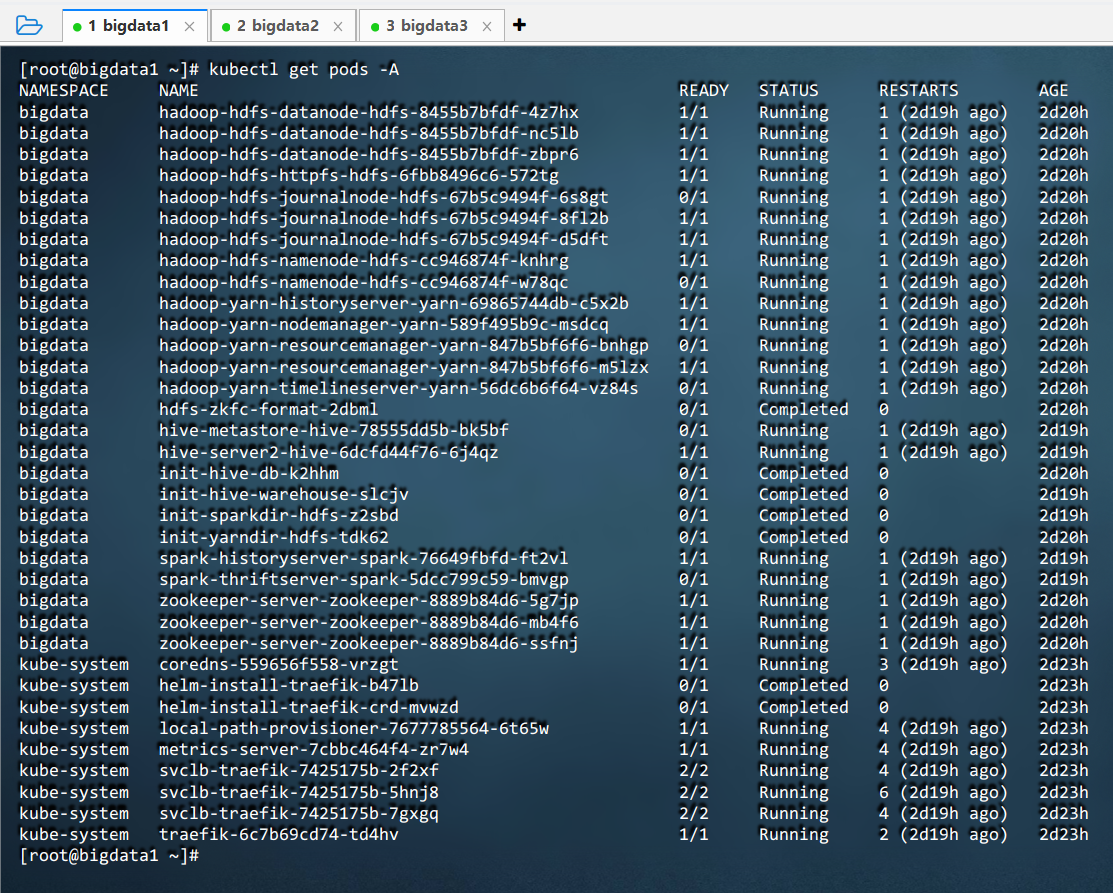
- 执行命令:
kubectl get pods -A
- 命令说明:
kubectl get pods -A是 Kubernetes 命令,用于列出所有命名空间(Namespace)中的 Pod。它显示每个 Pod 的名称、所属命名空间、就绪状态、重启次数和运行时长,是检查集群中容器化应用运行情况的常用诊断命令,帮助用户快速识别异常或未就绪的 Pod。
5.2.2 进入名称节点的Pod容器内部
- 查看列表中的namenode:
bigdata hadoop-hdfs-namenode-hdfs-cc946874f-knhrg 1/1 - 执行命令:
kubectl exec -it hadoop-hdfs-namenode-hdfs-cc946874f-knhrg -n bigdata -- bash

- 命令说明:该命令用于进入 HDFS NameNode 的 Pod 容器内部。
kubectl exec -it表示以交互式终端方式执行,hadoop-hdfs-namenode-hdfs-cc946874f-knhrg是目标 Pod 名称,-n bigdata指定命名空间,-- bash表示在容器中启动 bash 命令行,便于执行 HDFS 管理命令或排查问题。 - 进入 HDFS NameNode 容器后,可直接执行
hdfs dfs等命令管理 HDFS 文件系统。结果将显示在终端,如目录列表、操作成功/失败提示。通过此方式可进行文件读写、权限设置、集群状态检查等运维操作,便于调试和验证 HDFS 服务是否正常运行。
5.2.3 HDFS目录文件操作
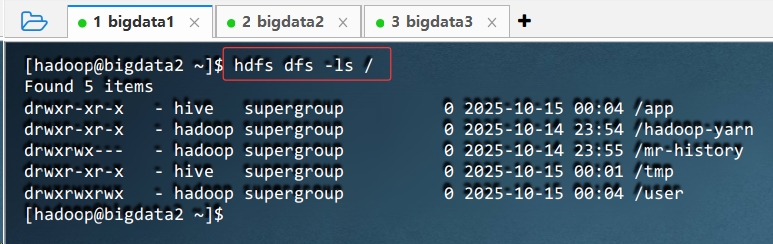
- 查看目录
- 执行命令:
hdfs dfs -ls /
- 执行命令:
- 创建目录
- 执行命令:
hdfs dfs -mkdir -p /wordcount/input

- 执行命令:
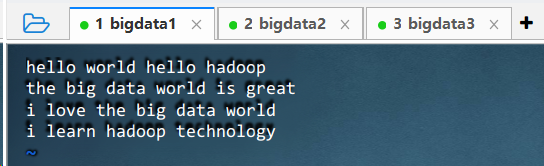
- 上传文件
- 执行命令:
vim words.txt,创建本地文件
- 执行命令:
hdfs dfs -put words.txt /wordcount/input

- 执行命令:
5.2.4 运行词频统计程序
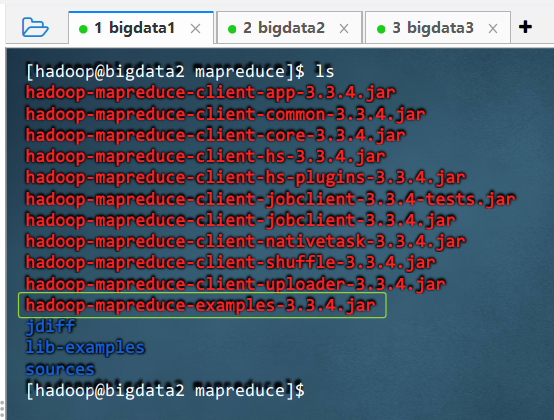
- 查看Hadoop自带示例jar包
- 执行命令:
cd $HADOOP_HOME/share/hadoop/mapreduce
 `
` - 执行命令:
ls
- 执行命令:
- 运行示例jar包里的词频统计
- 执行命令:
hadoop jar ./hadoop-mapreduce-examples-3.3.4.jar wordcount /wordcount/input/words.txt /wordcount/output
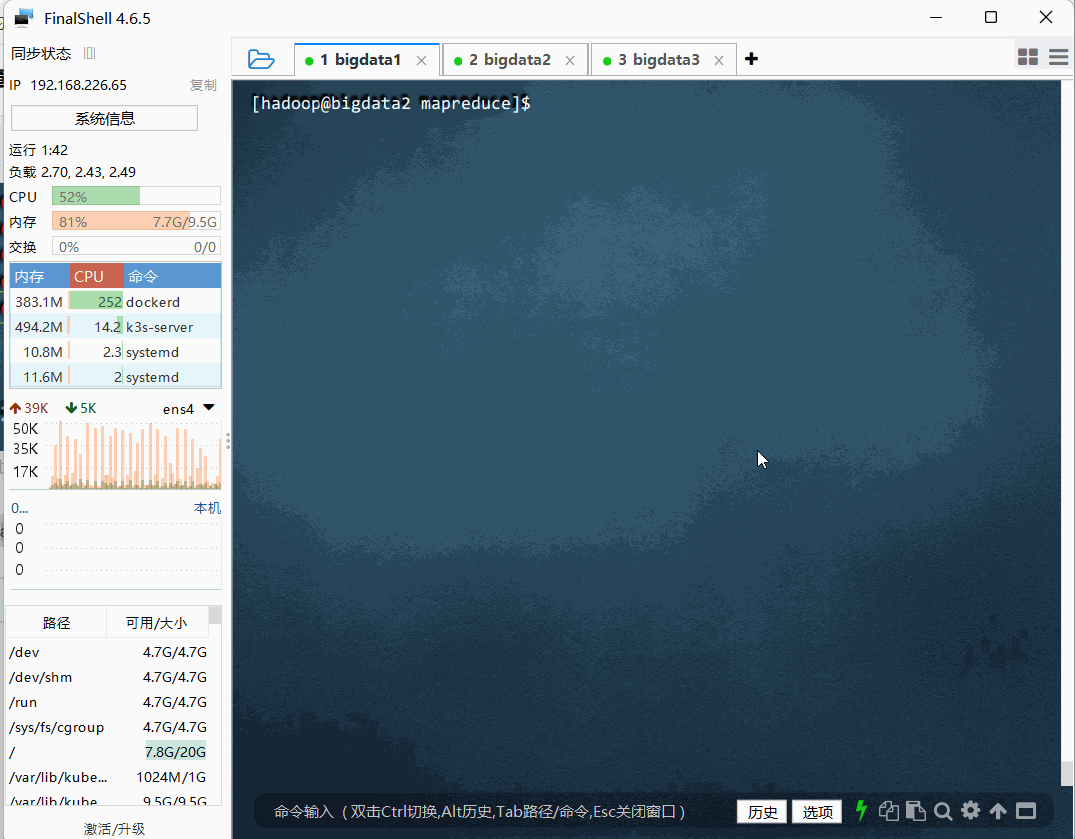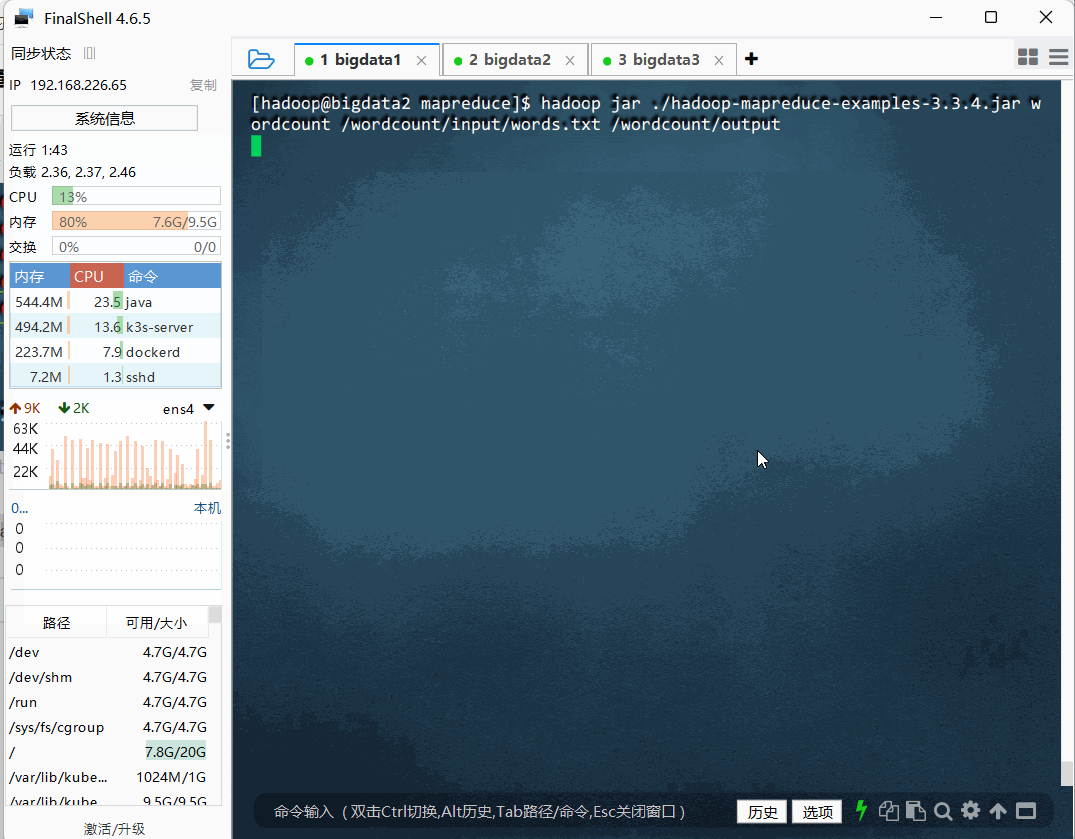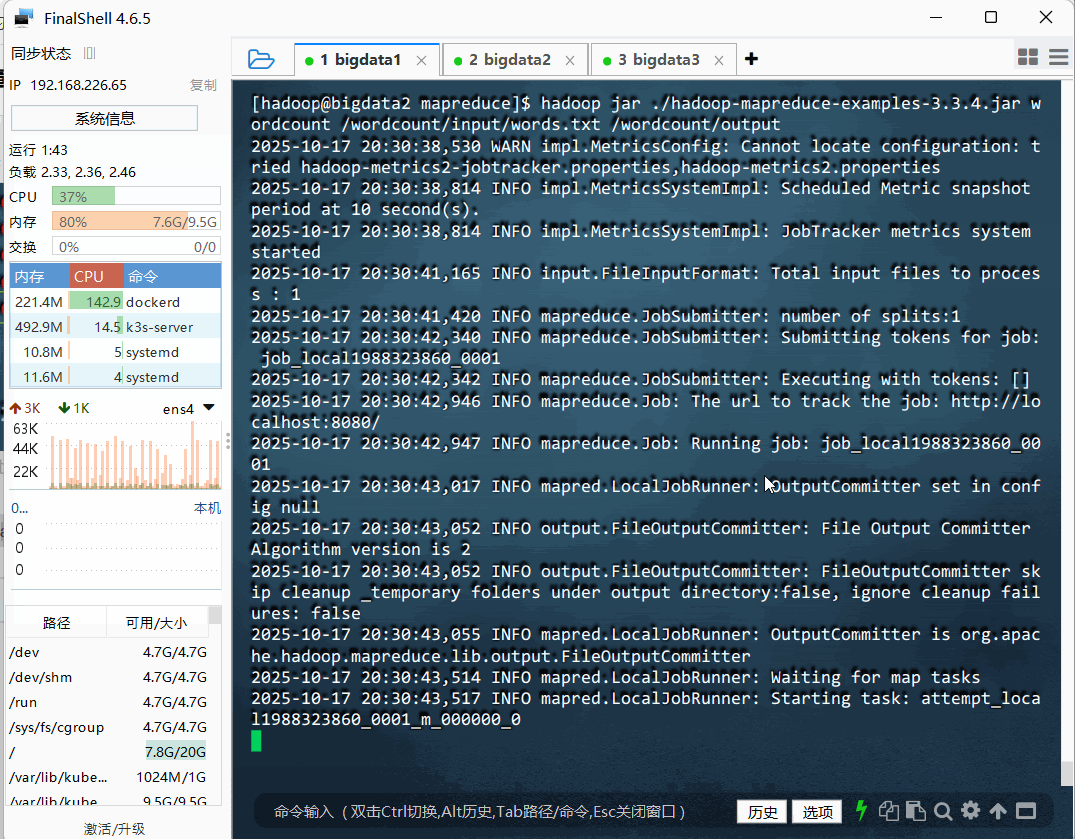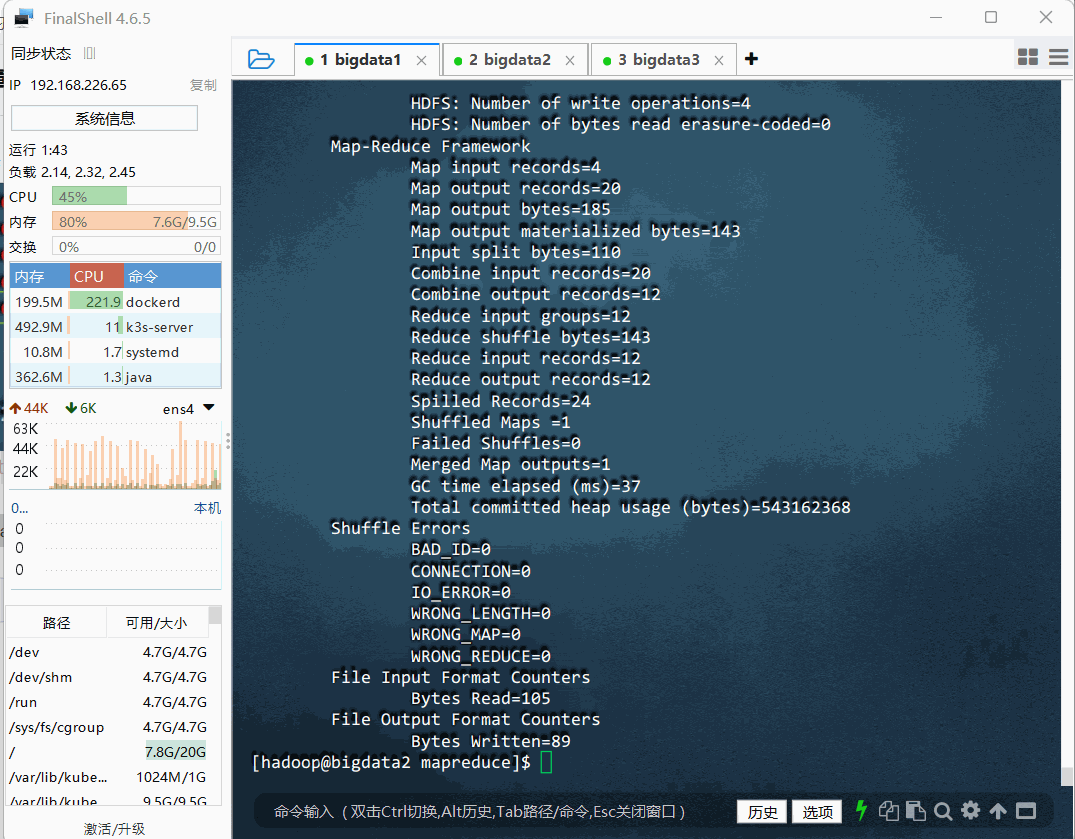
- 执行命令:
- 查看词频统计结果
- 执行命令:
hdfs dfs -ls /wordcount/output

- 执行命令:
hdfs dfs -cat /wordcount/output/*
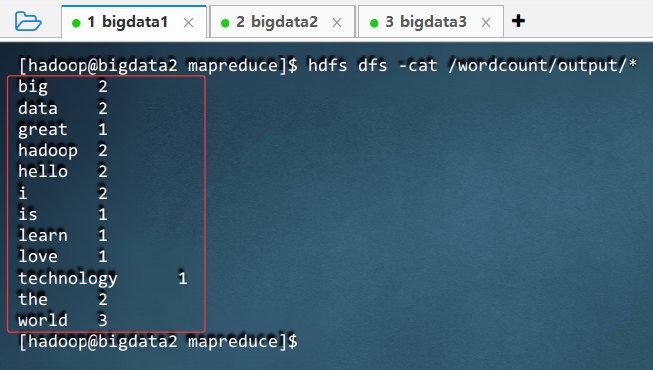
- 执行命令:
5.2.5 退出名称节点的Pod容器
- 执行命令:
exit
6. 实战总结
- 通过本次实训,掌握了基于 K3S 和CloudEon构建容器化大数据平台的核心流程。从云主机创建、服务部署到 HDFS 实际操作,全面体验了云原生环境下大数据组件的管理与使用。通过 WebUI 和 Shell 两种方式操作 HDFS,完成了文件上传、目录管理及 MapReduce 词频统计任务,验证了集群功能的完整性。不仅加深了对 Kubernetes Pod、容器执行命令等底层机制的理解,也提升了对 Hadoop 生态在现代化架构中应用的认知,为后续学习分布式计算与大数据运维打下坚实基础。