基于ArcGIS的生态敏感性分析案例 | 绿水青山就是金山银山
前言
这一篇,我们从农科专家华丽转身,以一个生态保护学者的身份,来处理生态敏感性分析这一类问题。
本文依然是案例驱动。首先引入案例背景,跟大家介绍本篇所基于的现实背景、已有数据、任务要求以及所要实现的目标。之后在第二部分给出对本实验的总体分析,以流程图的形式将我们要做的处理给到大家。然后在第三部分,将给出详细的基于arcmap的具体实现流程,小编也会将实操过程中小编积累的经验和需要注意避坑的操作误区分享给大家。
还是那句话,废话放到最后说,现在直接上干货!
一、案例引入
(一)案例背景
生态文明建设已经上升为一项国家战略,生态环境保护对发展的重要性越来越多的受到重视,某地区为响应国家号召,计划从地形、植被、水体三个方面对当地的生态环境进行敏感性分析,为后续生态保护措施的制定提供科学指导。
(二)数据说明
| 数据名称 | 数据类型 | 坐标系 | 说明 |
| dem | .tif | Beijing_1954_3_Degree_GK_CM_102E | 研究区数字高程模型 |
| vegetation | .tif | Beijing_1954_3_Degree_GK_CM_102E | 研究区植被覆盖信息 |
(三)任务要求
基于试题所给数据,计算出地形、植被、水体三方面的生态因子,然后根据各个生态因子对研究区敏感性等级表和分类方法,为各因子的敏感性赋值后加权综合,得到整体敏感性结果,最后绘制能够直观反映研究区生态敏感性等级分布专题图,为未来决策提供依据。
根据提供的数字高程模型:
- 1、计算“vegetation”图层范围内的坡度、坡向;
- 2、提取“vegetation”图层范围内的河流线数据(不考虑图层范围外部的影响,汇流临界值为1000);
- 3、在“vegetation”图层范围内,计算每个栅格到最近河流栅格的直线距离值;
- 4、地形、植被、水体方面的生态因子及其对该地区的敏感性等级见表1和表2。请根据表1中各因子权重值,加权计算该区域的生态敏感性信息,并按照表3的敏感性等级分类方法,绘制该地区的生态敏感性等级分布专题图。
-
表1 生态因子及其影响范围所赋属性值
生态因子
二级因子
分类
敏感性等级
权重
地形因子
坡度(单位:度)
>60
极高敏感
0.2
45-60
高敏感
25-45
中敏感
10-25
低敏感
0-10
非敏感
高程(单位:米)
>3000
极高敏感
0.1
2500-3000
高敏感
1500-2500
中敏感
1000-1500
低敏感
<1000
非敏感
坡向
正北
极高敏感
0.1
东北、西北
高敏感
正东、正西
中敏感
东南、西南
低敏感
平地、正南
非敏感
植被因子
植被
0(有植被)
高敏感
0.3
-1(裸地)
非敏感
水体因子
水系
1(河流)
高敏感
0.2
0(无)
非敏感
河流缓冲(单位:米)
>150
极高敏感
0.1
100-150
高敏感
50-100
中敏感
25-50
低敏感
<25
非敏感
表2 敏感性量化
敏感性等级
敏感性数值
极高敏感
5
高敏感
4
中敏感
3
低敏感
2
非敏感
1
表3 敏感性等级分类方法
敏感性数值区间
敏感性等级
大于4,小于等于5
极高敏感
大于3,小于等于4
高敏感
大于2,小于等于3
中敏感
大于1,小于等于2
低敏感
大于等于0,小于等于1
非敏感
- 3、在“vegetation”图层范围内,计算每个栅格到最近河流栅格的直线距离值;
- 2、提取“vegetation”图层范围内的河流线数据(不考虑图层范围外部的影响,汇流临界值为1000);
二、任务分析与处理流程
本实验可以分为三个部分来进行处理。首先进行生态因子的构建,从所给的dem数据提取出坡度、坡向等地形因子和水系等水文因子,连同vegetation数据形成六大生态因子。然后按照所给生态敏感性等级分布表和分类规则,对单因子以及加权叠加得到的综合结果进行分类分级,得到研究区生态敏感性等级分布图层。最后制作基于前步得到的研究区生态敏感性图层的专题图,直观展示敏感性的空间分布规律,辅助生态决策。
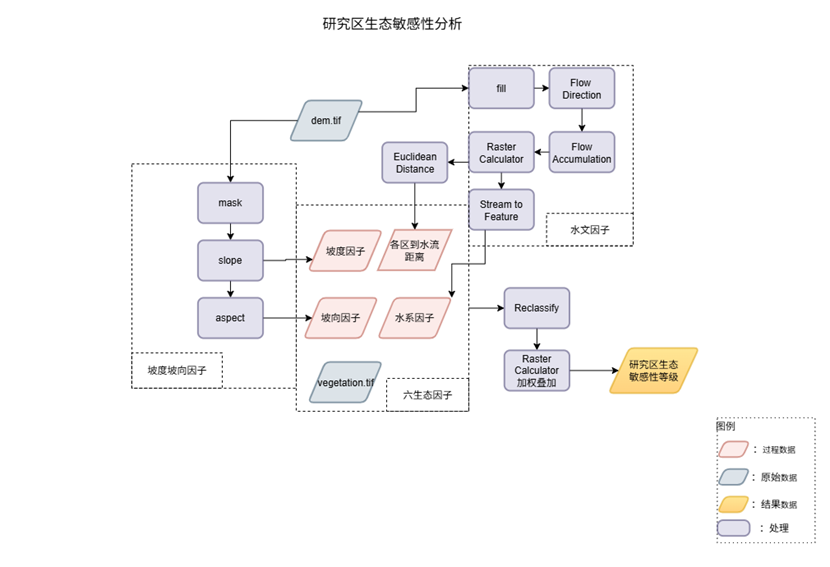
图 1实验整体流程图
三、arcmap完整实现
关于原始数据的载入和环境配置相关的操作此处不再赘述,需要的宝子可以点击下面的链接,这篇文章有讲当我们准备做一个项目的时候,怎么做好第一步的环境配置相关的内容哦👇
基于ArcGIS的作物适宜区分析案例 | 当GIS化身农科月老
(一)计算vegetation图层范围内的坡度、坡向
在这里首先明确求解范围,即vegetation图层覆盖的区域。因此首先对dem按掩膜提取,然后用结果dem来进行坡度、坡向求解,得到vegetation图层覆盖范围的坡度和坡向信息,作为本研究的地形生态因子,参与后续敏感性分析。
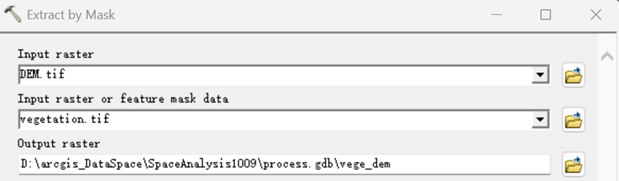
1.按掩膜提取植被范围dem
执行【Spatial Analyst->Extraction->Extract by Mask】,在弹出的按掩膜提取对话框,按如下进行设置。
得到只保留了植被覆盖范围的dem数据,之后的地形因子计算都将基于此。
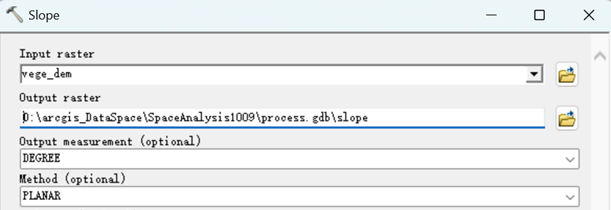
2.求解植被图层覆盖区坡度
然后再来计算坡度,执行【Spatial Analyst->Surface->Slope】,在弹出的坡度计算对话框,按如下设置。
求解得到坡度结果如下。
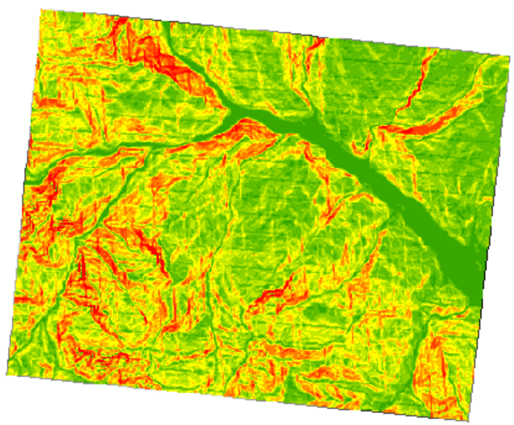
3.求解植被图层覆盖区坡向
再来求解和坡度如影随形的坡向。在与坡度相同的工具箱中找到aspect,进行如下设置。
得到坡向结果。

(二)提取vegetation图层范围内的河流线数据
这一问就是做水文分析。用dem来模拟水流。题目假定不考虑图层范围外部的影响,因此此处直接利用掩膜处理后的dem进行求解。首先对其进行填洼,抚平凹陷,然后用填洼结果dem计算水流流向、汇流累积量,再利用栅格计算器筛选得到河流区域栅格,最后将河流栅格转换为矢量线数据,即得到目标河流线。
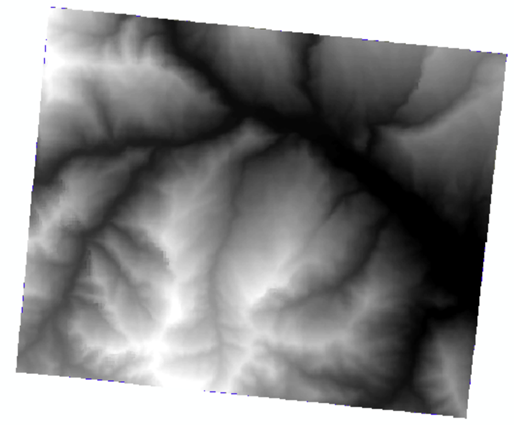
1.dem填洼
执行【Spatial Analyst->Hydrology->Fill】,在弹出的填洼工具窗口进行如下设置。
得到填洼后的dem。
2.计算流向
执行【Spatial Analyst->Hydrology->Flow Direction】,在弹出的流向计算对话框里进行如下设置。
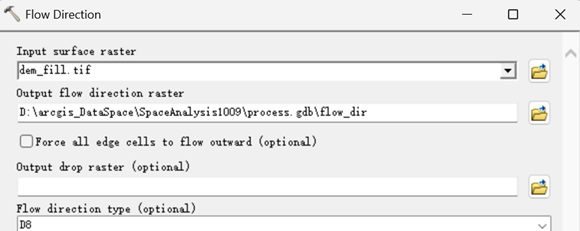
得到流向数据

3.计算汇流累积量
执行【Spatial Analyst->Hydrology->Flow Accumulation】,在弹出的汇流累积量计算窗口,按如下设置。
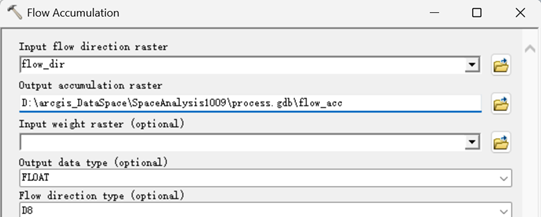
得到流量数据。

4.提取河流栅格并矢量化
首先筛选汇流累积量≥1000的区域,得到河流栅格。执行【Spatial Analyst->Map Algebra->Raster Calculator】,在弹出的地图代数对话框,进行如下设置。
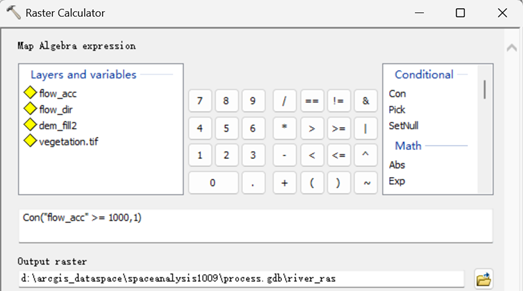
得到河流栅格如下
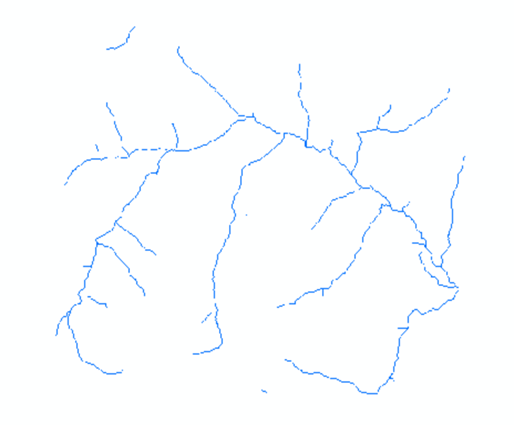
现在将河流栅格转换为矢量线数据。执行【Spatial Analyst->Hydrology->Stream to Feature】,在弹出的矢量化河网对话框按如下设置。
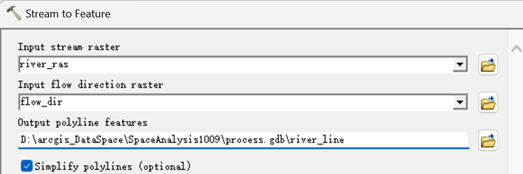
得到河流线数据。
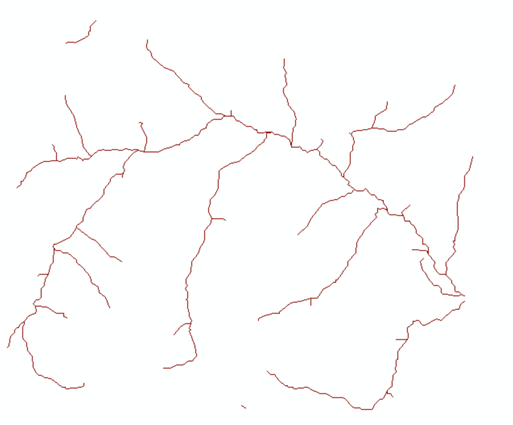
(三)计算vegetation图层范围内每个栅格到最近河流栅格的直线距离
要获取直线距离,我们用欧氏距离工具来做。执行【Spatial Analyst->Euclidean Distance】,在弹出的距离计算对话框,按如下设置。
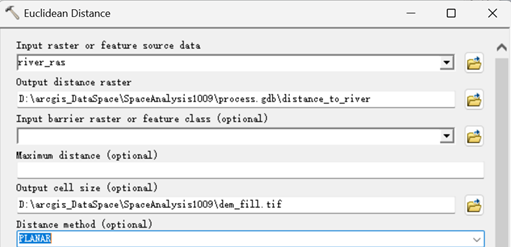
得到每个像元到河流的距离,如下。
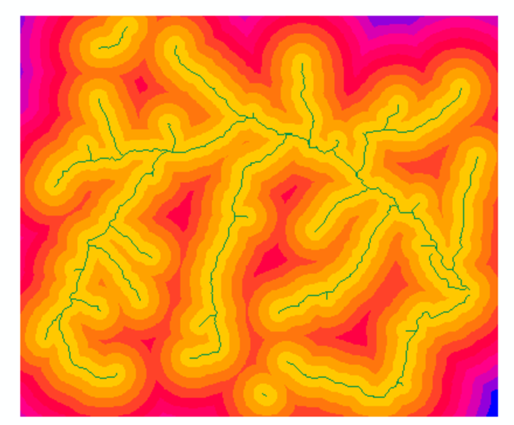
(四)加权计算生态敏感性
这一步的核心处理流程,就是首先对各个生态因子按照题目中所给表1进行重分类,然后再根据表2赋新值,再由表1提供的权重进行加权叠加,得到研究区各地的敏感性数值,再次利用重分类来将数值转换为表3对应敏感性等级,最终得到的就是研究区的各个区域的敏感性等级栅格,就是本实验的结果目标。
1.对6个生态因子重分类
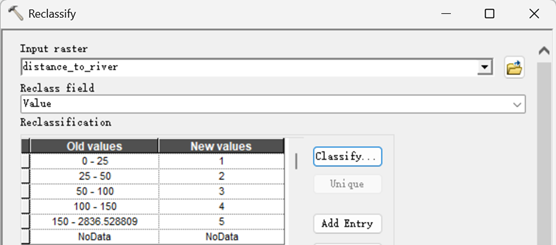
所有的重分类操作都是基于【Spatial Analyst->Reclass->Reclassify】导航到的重分类工具完成的。这里只在坡度重分类处详细给出具体实施过程,其余因子的处理相似,故只给出结果。
1)坡度重分类
按照表1来进行赋值如下。
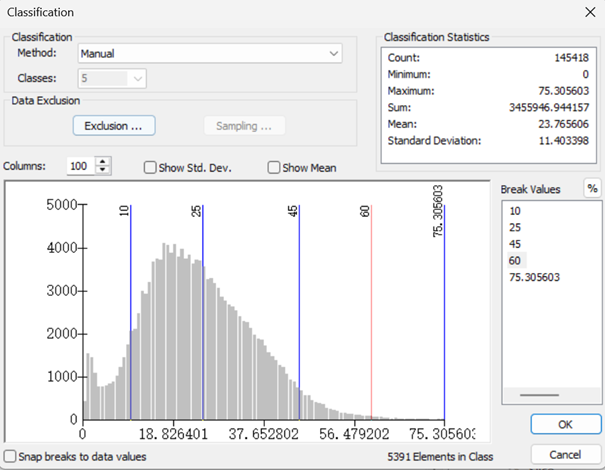
然后返回主工具窗口,这里对应的新值1-5,就是表1对应的非敏感—极高敏感。
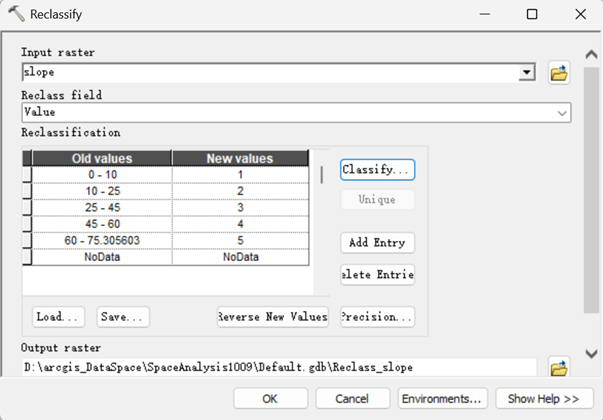
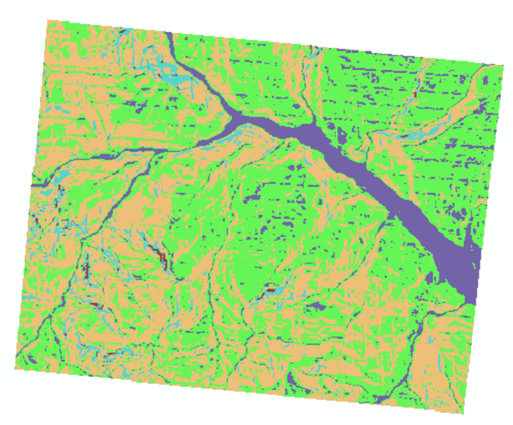
得到重分类结果如下。
2)高程重分类
主界面设置如下。
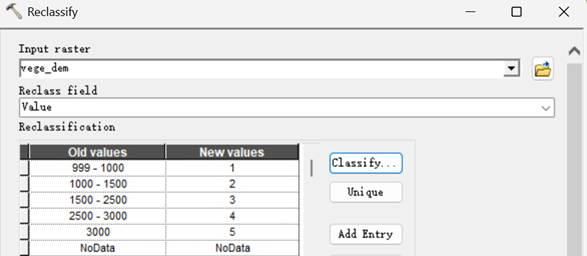
重分类结果如下。
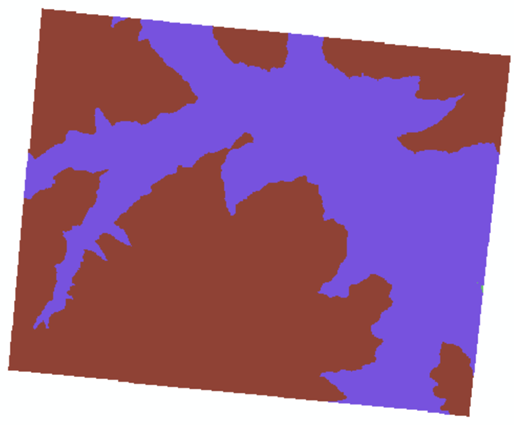
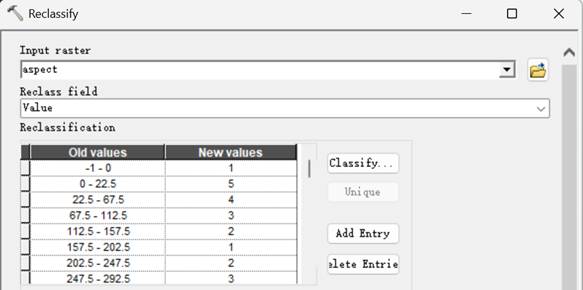
3)坡向重分类
主窗口设置如下。
重分类结果如下。

4)植被重分类
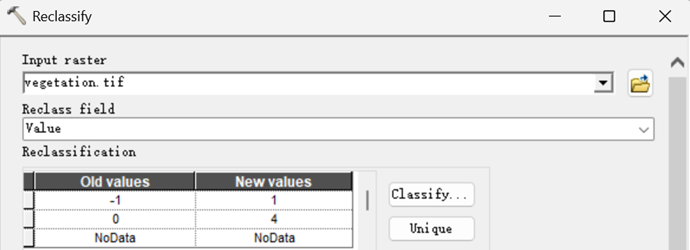

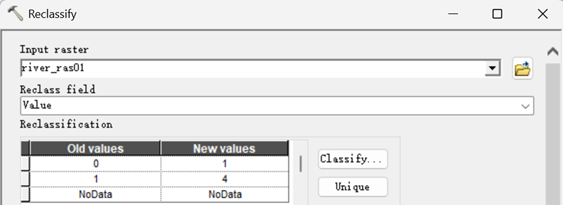
5)水系重分类
注意,在此利用栅格计算器得到河流的二值栅格数据(前面是直接利用Con提取出来水系栅格,但重分类处还要为非水系赋值,故要再操作),0即无,1即河流。然后基于这一栅格来进行重分类。
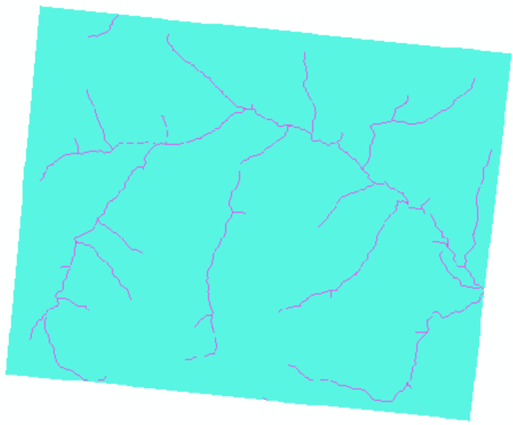
6)河流缓冲
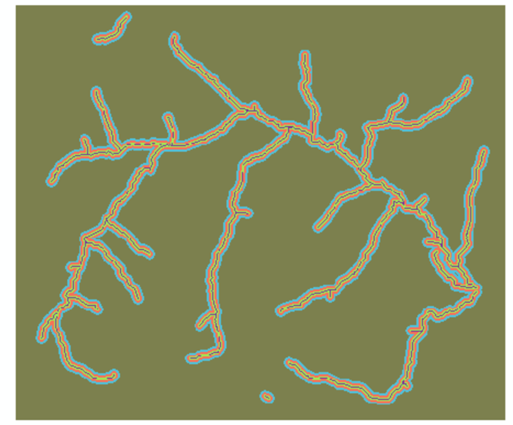
2.加权叠加求解敏感值
利用栅格计算器来进行加权叠加。执行【Spatial Analyst->Map Algebra->Raster Calculator】,按如下设置。
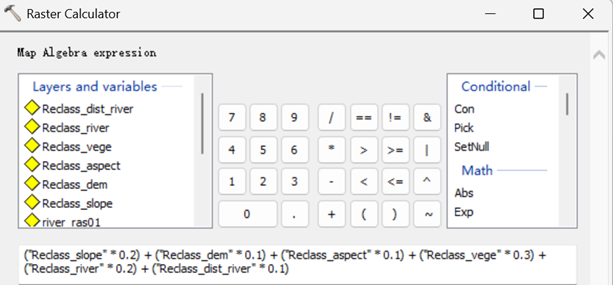
得到敏感性值。

3.对敏感值重分类,得到敏感性等级
执行【Spatial Analyst->Reclass->Reclassify】,按如下执行。
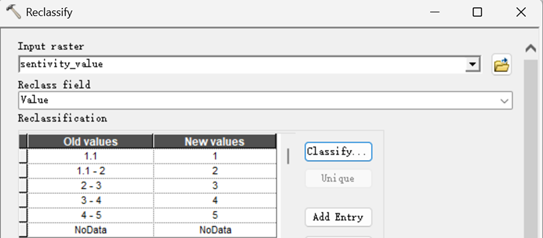
得到敏感性等级。

(五)绘制专题图
最后转入到布局视图,逐个插入图例、指北针、比例尺等要素并合理排布,得到研究区生态敏感性等级分布专题图,如下。

四、唠唠叨叨
感谢大家能看到这里!
这是空间分析专栏的新成员,小编有一个愿望,就是把各个类型的案例都分析个遍哈哈,构建一套知识库,构建一棵知识树。
大家在阅读过程中如果发现小编有不严谨的地方或者出现错误的地方,欢迎大家批评指正,小编一定虚心受教,也欢迎大家私信或者在评论区分享大家的思路和看法,我们一起进步!