高并发系统架构设计原则:无状态、水平扩展、异步化、缓存优先
高并发系统架构设计原则:无状态、水平扩展、异步化、缓存优先
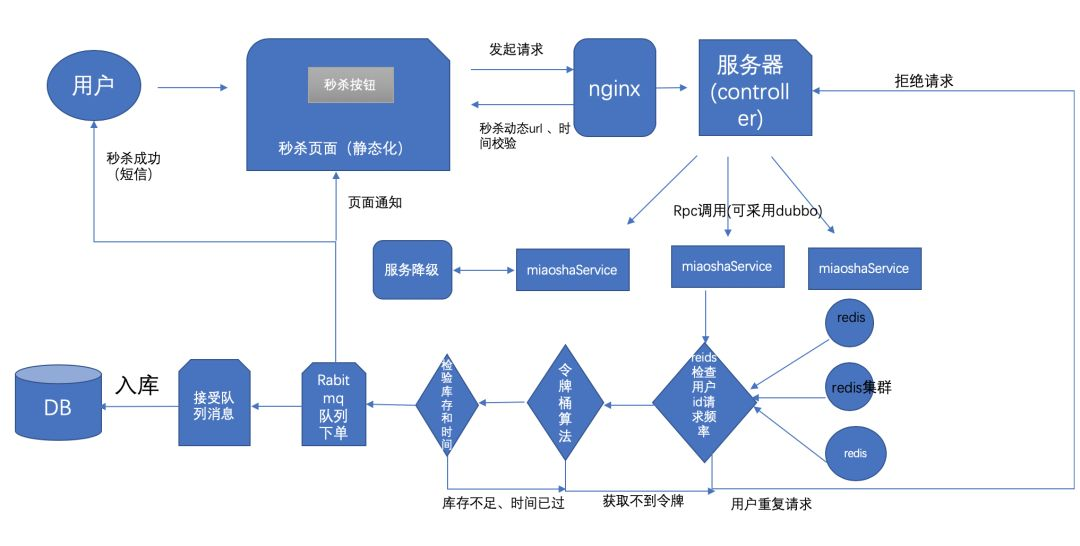
在互联网技术飞速发展的今天,高并发场景早已不再是大型互联网企业的 “专属难题”。从电商平台的 “双 11” 大促,到短视频 App 的热点事件爆发,再到政务系统的高峰期服务访问,稍有不慎,系统就可能出现响应缓慢、卡顿甚至崩溃的情况。作为架构师,掌握高并发系统的核心设计原则,是保障系统稳定运行、提升用户体验的关键。本文将从高并发基础认知出发,深入解析 “无状态、水平扩展、异步化、缓存优先” 四大核心设计原则,为大家搭建高并发架构设计的基础框架。
一、高并发基础认知:先搞懂 “是什么” 和 “难在哪”
在聊架构设计原则之前,我们首先要明确 “高并发” 的核心概念,以及它给系统带来的具体挑战。只有先认清问题本质,才能更好地找到解决方案。
1. 高并发的定义:不是 “绝对数量”,而是 “相对压力”
很多人会误以为 “高并发” 就是 “大量用户访问”,但实际上,高并发的本质是系统在单位时间内需要处理的请求量,超过了其默认架构的承载能力。举个例子:一个日均访问量 1000 的企业官网,突然因某事件单日访问量飙升到 10 万,这对它来说就是高并发;而对于淘宝、京东这类平台,日常百万级的并发访问只是 “常规操作”。
简单来说,高并发没有统一的 “数量标准”,它是相对于系统自身承载能力的 “压力概念”—— 当请求量超过系统当前的处理极限,导致性能下降时,就进入了高并发场景。
2. 衡量高并发的 4 个核心指标:别只看 “并发数”
判断一个系统是否处于高并发状态,以及高并发下的性能表现,需要通过具体指标来衡量。这 4 个核心指标,是架构师日常监控和优化的重点:
-
吞吐量(Throughput):单位时间内系统处理的请求总数(通常以 “QPS”—— 每秒查询数,或 “TPS”—— 每秒事务数为单位)。比如,一个接口每秒能处理 5000 个请求,其吞吐量就是 5000 QPS。
-
响应时间(Response Time):从用户发起请求到系统返回结果的总时间。对用户而言,响应时间直接决定体验 —— 超过 3 秒的页面加载,就可能导致用户流失。
-
并发用户数(Concurrent Users):同一时间内正在使用系统的用户数(注意:不是 “总用户数”,而是 “活跃用户数”)。比如,某 App 同时有 10 万用户在刷首页,这就是 10 万并发用户数。
-
错误率(Error Rate):单位时间内请求失败的比例(如超时、500 错误等)。错误率是系统稳定性的 “红线”—— 一旦错误率超过 0.1%,就需要立即排查问题。
3. 高并发下的 3 大核心挑战:性能、一致性、稳定性
高并发之所以难,本质是它会放大系统的潜在问题,主要集中在 3 个方面:
-
性能瓶颈凸显:高并发下,CPU、内存、磁盘 IO、网络带宽等硬件资源容易被耗尽,比如数据库频繁执行复杂查询导致 CPU 占用率 100%,进而引发所有请求阻塞。
-
数据一致性风险:当多个请求同时操作同一份数据时,容易出现 “脏读”“幻读”“数据覆盖” 等问题。比如,电商平台的库存扣减,若处理不当,可能出现 “超卖” 或 “少卖” 的情况。
-
系统稳定性下降:单点故障、网络波动、资源泄漏等问题,在高并发下会被无限放大。比如,一个核心服务节点宕机,若没有容错机制,可能导致整个业务链路瘫痪。
二、四大核心设计原则:高并发架构的 “基石”
面对高并发的挑战,架构设计并非 “天马行空”,而是有章可循。“无状态、水平扩展、异步化、缓存优先” 这四大原则,是经过无数实践验证的 “黄金法则”,也是构建高并发系统的基础。
1. 无状态原则:让服务 “可复制”,摆脱单点依赖
(1)什么是 “无状态”?
无状态服务指的是服务本身不存储任何业务数据,所有与用户相关的状态(如登录信息、会话数据)都存储在外部组件中(如 Redis、数据库)。换句话说,用户的每次请求,都包含了服务处理所需的全部信息,无论请求被分配到哪个服务节点,结果都是一致的。
反例:如果服务将用户会话存储在本地内存中(如 Tomcat 的 Session),那么当用户再次请求时,必须被分配到同一个节点才能正常处理 —— 这就是 “有状态” 服务,一旦该节点宕机,用户会话就会丢失。
(2)无状态的核心价值:为 “水平扩展” 铺路
无状态服务最大的优势在于可复制性—— 当请求量增加时,我们只需简单地增加服务节点数量(如通过 K8s 扩容),就能提升系统的整体处理能力。因为所有节点都是 “对等” 的,请求可以被负载均衡器(如 Nginx、SLB)随机分配,无需担心状态不一致的问题。
(3)实践案例:Web 服务的无状态改造
以电商的商品详情页服务为例,早期可能将用户的浏览记录存储在服务本地内存中,导致无法扩容。改造后,服务不再存储任何状态:
-
用户登录信息存储在 Redis 中,请求时通过 Token 从 Redis 获取;
-
商品数据从数据库或缓存中读取,不落地到服务本地;
-
浏览记录实时写入数据库,服务仅负责 “转发” 请求。
改造后,即使扩容到 10 个、100 个服务节点,也能正常处理请求,且不会出现数据不一致。
2. 水平扩展原则:用 “加机器” 解决 “性能不够”,而非 “换更好的机器”
(1)水平扩展 vs 垂直扩展:别走进 “升级硬件” 的误区
面对高并发,提升系统性能的思路有两种:
-
垂直扩展(Scale Up):通过升级硬件来提升单个节点的性能,比如将 CPU 从 8 核换成 32 核,内存从 16G 换成 128G,磁盘从机械硬盘换成 SSD。
-
水平扩展(Scale Out):通过增加节点数量来提升整体性能,比如将 1 个服务节点增加到 10 个,1 个数据库实例增加到 3 个(主从架构)。
垂直扩展的优点是 “简单”,但缺点也很明显:有上限(硬件性能不可能无限提升)、成本高(高端服务器价格是普通服务器的数倍)、单点风险高(一旦单个节点宕机,服务就中断)。
而水平扩展则没有上限 —— 理论上,只要增加足够多的节点,就能承载无限的请求量(当然,实际中会受限于数据库、缓存等组件的瓶颈),且成本低、抗风险能力强。因此,高并发架构设计的核心思路,是优先采用水平扩展。
(2)水平扩展的 3 个关键层级:从 “接入层” 到 “服务层”
水平扩展不是 “只加服务节点”,而是需要覆盖系统的多个层级,形成 “全链路扩容” 能力:
-
接入层水平扩展:通过负载均衡器(如阿里云 SLB、Nginx 集群)实现请求分发,同时增加负载均衡器节点,避免接入层成为瓶颈;
-
服务层水平扩展:基于无状态原则,通过容器化(Docker+K8s)或虚拟机(VM)快速扩容服务节点,比如电商大促前,将商品服务从 10 个节点扩容到 50 个;
-
数据层水平扩展:通过数据库分库分表(如 Sharding-JDBC)、缓存集群(如 Redis Cluster)等方式,将数据分散到多个节点,避免数据层成为瓶颈。
(3)注意点:水平扩展的 “前提” 是无状态
需要强调的是,水平扩展的前提是服务无状态—— 如果服务有状态(如本地存储会话),即使增加再多节点,也无法正常处理请求(因为请求必须分配到特定节点)。因此,无状态原则是水平扩展的 “基石”,两者相辅相成。
3. 异步化原则:用 “削峰填谷” 解决 “请求拥堵”,提升响应速度
(1)什么是 “异步化”?
同步处理指的是请求发起后,必须等待前一个操作完成,才能执行下一个操作—— 比如用户下单后,系统需要同步完成 “库存扣减”“订单创建”“支付回调”“物流通知” 4 个操作,只有全部完成,才返回给用户 “下单成功”。
这种模式下,一旦某个环节(如物流通知)耗时较长,整个请求的响应时间就会被拉长,在高并发下很容易导致 “请求堆积”。
而异步化处理指的是将非核心流程从主流程中剥离,通过消息队列(如 RabbitMQ、Kafka)实现 “解耦”—— 主流程只完成 “库存扣减”“订单创建” 2 个核心操作,完成后立即返回 “下单成功”;而 “支付回调”“物流通知” 等非核心操作,通过消息队列异步执行,即使这些操作耗时较长,也不会影响主流程的响应速度。
(2)异步化的核心价值:削峰填谷 + 解耦
-
削峰填谷:高并发下,请求量会出现 “峰值”(如大促开始的前 10 分钟),消息队列可以将峰值请求暂时存储起来,然后按照系统的处理能力 “匀速” 消费,避免系统被峰值压垮;
-
解耦:主流程与非核心流程通过消息队列通信,无需关心对方的实现细节 —— 比如订单服务无需关心物流服务的接口变化,只需发送 “订单创建成功” 的消息即可,降低了系统的耦合度。
(3)实践场景:电商下单的异步化改造
改造前(同步流程):
用户下单 → 库存扣减(同步)→ 订单创建(同步)→ 支付回调(同步)→ 物流通知(同步)→ 返回结果
响应时间:500ms(若物流通知耗时 200ms,占比 40%)
改造后(异步流程):
用户下单 → 库存扣减(同步)→ 订单创建(同步)→ 发送 “订单创建成功” 消息到 MQ → 立即返回结果
同时,MQ 异步触发:
-
支付服务消费消息 → 处理支付回调;
-
物流服务消费消息 → 发送物流通知。
响应时间:300ms(减少了 200ms,主流程性能提升 40%)
4. 缓存优先原则:用 “热点数据前置” 减轻数据库压力,提升访问速度
(1)为什么需要 “缓存优先”?
在高并发系统中,数据库是最容易成为瓶颈的环节—— 因为数据库的 IO 操作(尤其是磁盘 IO)速度远慢于内存操作(内存读写速度是磁盘的 1000 倍以上)。而大部分业务场景中,80% 的请求都集中在 20% 的 “热点数据” 上(如电商的热门商品、短视频的热门视频)。
如果每次请求都直接查询数据库,即使是高性能的数据库,也难以承受百万级的并发访问。而缓存优先原则,就是将热点数据存储在内存级缓存中(如 Redis、本地缓存),用户请求先查询缓存,缓存命中则直接返回,未命中再查询数据库并更新缓存—— 通过这种方式,大幅减少数据库的访问量,提升系统响应速度。
(2)缓存的 3 个核心层级:从 “用户端” 到 “服务端”
缓存不是 “只加一个 Redis”,而是需要构建 “多层缓存体系”,覆盖从用户端到服务端的全链路,最大化减轻数据库压力:
-
浏览器缓存:将静态资源(如 CSS、JS、图片)缓存到用户浏览器中,用户再次访问时无需从服务器下载,直接从本地读取(通过 HTTP 头的 Cache-Control、Expires 字段控制);
-
CDN 缓存:将静态资源和热点动态数据(如商品详情页)缓存到 CDN 节点(分布在全国甚至全球的节点),用户请求时优先从最近的 CDN 节点获取,减少跨地域网络传输耗时;
-
服务端缓存:分为本地缓存(如 Caffeine、Guava Cache,适用于单机热点数据)和分布式缓存(如 Redis Cluster,适用于多机共享热点数据),服务查询数据时先查本地缓存,再查分布式缓存,最后查数据库。
(3)注意点:缓存的 “一致性” 和 “穿透、击穿、雪崩” 问题
缓存优先虽然能提升性能,但也会带来新的问题,需要重点处理:
-
缓存一致性:当数据库数据更新时,如何保证缓存数据同步更新?通常采用 “更新数据库后删除缓存”(而非 “更新缓存”)的策略,避免并发场景下的数据不一致;
-
缓存穿透:恶意请求查询不存在的数据(如查询 ID=-1 的商品),导致缓存未命中,所有请求都落到数据库。解决方案:缓存空值、布隆过滤器过滤无效请求;
-
缓存击穿:热点数据的缓存过期(如某热门商品的缓存刚好失效),导致大量请求同时落到数据库。解决方案:互斥锁(只让一个请求去更新缓存)、热点数据永不过期;
-
缓存雪崩:大量缓存同时过期(如设置所有商品缓存的过期时间为凌晨 2 点),或缓存集群宕机,导致所有请求落到数据库。解决方案:缓存过期时间加随机值(避免同时过期)、构建缓存集群(主从 + 哨兵,避免单点故障)。
三、总结:四大原则的 “协同关系” 与实践建议
高并发系统架构设计不是 “单一原则的堆砌”,而是 “四大原则的协同配合”:
-
无状态是基础:只有服务无状态,才能实现水平扩展;
-
水平扩展是核心手段:通过增加节点,解决 “请求量过大” 的问题;
-
异步化是性能优化关键:通过削峰填谷,减少请求阻塞,提升响应速度;
-
缓存优先是数据库保护屏障:通过热点数据前置,减轻数据库压力,避免数据层成为瓶颈。
对于架构师而言,在实践中需要注意以下 3 点:
-
不要 “过度设计”:高并发架构需要结合业务场景 —— 如果业务日均访问量只有 1 万,就没必要一上来就搞 Redis Cluster、分库分表,先从 “无状态服务 + 简单缓存” 做起,后续再逐步迭代;
-
重视 “监控和容错”:即使架构符合四大原则,也需要完善的监控体系(如 Prometheus+Grafana 监控吞吐量、响应时间)和容错机制(如服务降级、熔断、限流),应对突发情况;
-
持续迭代优化:高并发是 “动态变化” 的 —— 今天的架构能承载 10 万并发,明天可能就需要承载 100 万。因此,需要定期复盘性能瓶颈,持续优化架构(如从单库到分库分表,从单机缓存到分布式缓存)。
总之,高并发系统架构设计是一门 “平衡的艺术”—— 平衡性能与成本、平衡复杂度与可维护性、平衡当前需求与未来扩展。掌握 “无状态、水平扩展、异步化、缓存优先” 四大原则,是架构师应对高并发挑战的 “基本功”,也是构建稳定、高效系统的核心保障。