学习Python 03
八、 列表
序列是 Python 中最基本的数据结构。
序列中的每个值都有对应的位置值,称之为索引,第一个索引是 0,第二个索引是 1,依此类推。
Python 有 6 个序列的内置类型,但最常见的是列表和元组。
列表都可以进行的操作包括索引,切片,加,乘,检查成员。
此外,Python 已经内置确定序列的长度以及确定最大和最小的元素的方法。
列表是最常用的 Python 数据类型,它可以作为一个方括号内的逗号分隔值出现。
列表的数据项不需要具有相同的类型
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。
例如:
list1 = ["wcm", "i", "love", "you", "1314"] print(list1) #['wcm', 'i', 'love', 'you', '1314']
使用下标索引来访问列表中的值,同样你也可以使用方括号 [] 的形式截取字符,如下所示:
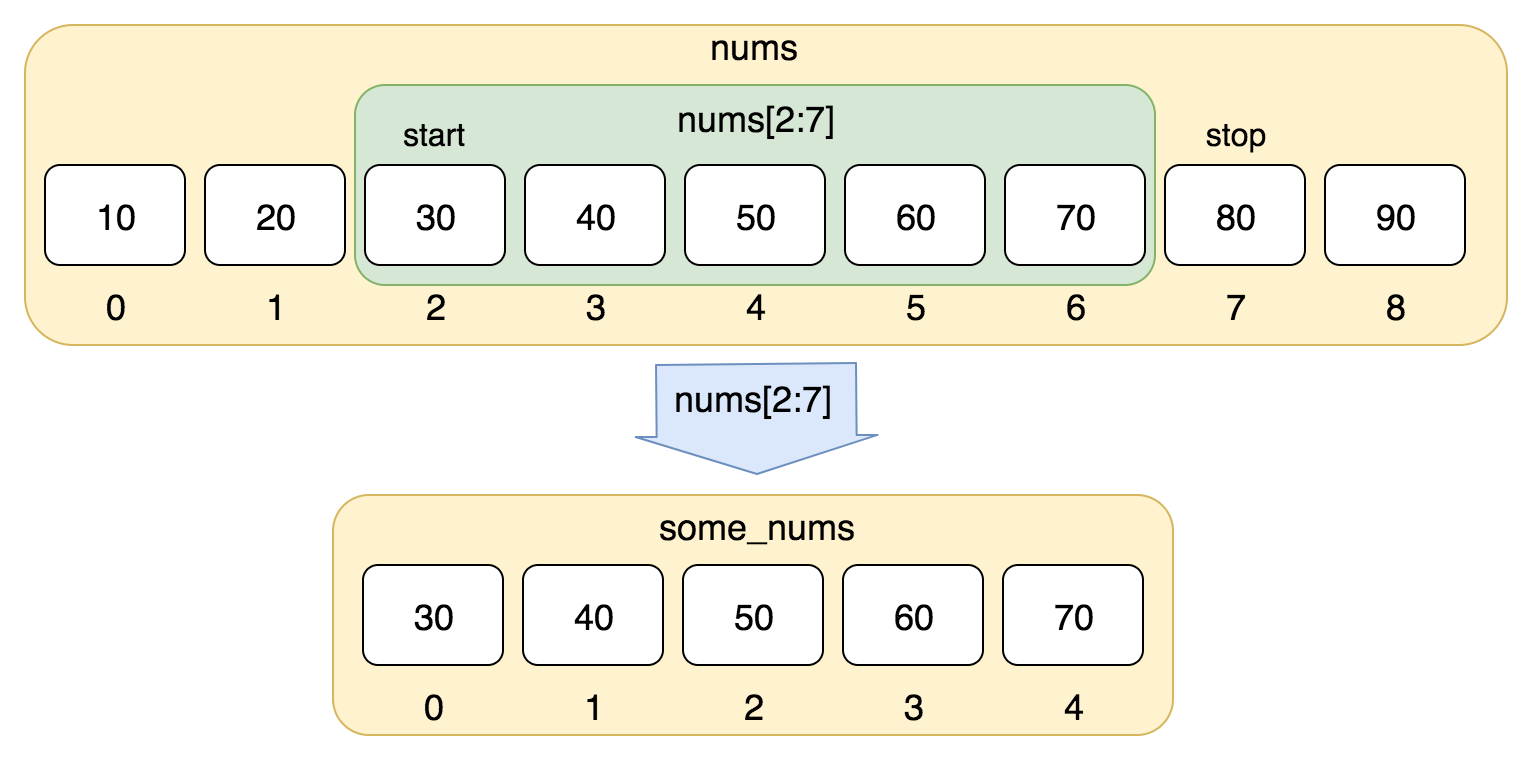
1、 更新列表
你可以对列表的数据项进行修改或更新,你也可以使用 append() 方法来添加列表项,如下所示:
list = ["wcm", "i", "love", "you", "1314"]
print("第三个元素为 : ", list[2])
list[2] = "like" #可以直接修改
print("更新后的第三个元素为 : ", list[2])
list1 = ['wcm', 'wmk', 'love']
list1.append('1314') #在末尾添加
print("更新后的列表 : ", list1)
输出结果
第三个元素为 : love 更新后的第三个元素为 : like 更新后的列表 : ['wcm', 'wmk', 'love', '1314']
2、 删除列表元素
可以使用 del 语句来删除列表的的元素,如下实例:
list = ["wcm", "i", "love", "you", "1314"]
print ("原始列表 : ", list)
del list[4]
print ("删除第五个元素 : ", list)
输出结果
原始列表 : ['wcm', 'i', 'love', 'you', '1314'] 删除第五个元素 : ['wcm', 'i', 'love', 'you']
3、 Python列表脚本操作符
列表对 + 和 * 的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表。
如下所示:
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len([1, 2, 3]) | 3 | 长度 |
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 组合 |
| [‘Hi!’] * 4 | [‘Hi!’, ‘Hi!’, ‘Hi!’, ‘Hi!’] | 重复 |
| 3 in [1, 2, 3] | True | 元素是否存在于列表中 |
| for x in [1, 2, 3]: print(x, end=" ") | 1 2 3 | 迭代(遍历) |
4、 拼接列表
list = ["wcm"] list += ["i", "love", "you", "1314"] print(list) #['wcm', 'i', 'love', 'you', '1314']
5、 嵌套列表(多维列表)
使用嵌套列表即在列表里创建其它列表,例如:
list = ["wcm",["我","喜欢"],"你"] print(list) # ['wcm', ['我', '喜欢'], '你']
6、 列表比较
列表比较需要引入 operator 模块的 eq 方法(详见:Python operator 模块):
# 导入 operator 模块
import operator
a = [1, 2]
b = [2, 3]
c = [2, 3]
print("operator.eq(a,b): ", operator.eq(a,b))
print("operator.eq(c,b): ", operator.eq(c,b))
输出结果
operator.eq(a,b): False #不相等 operator.eq(c,b): True # 相等
7、 Python列表函数&方法
Python包含以下函数:
| 序号 | 函数 |
|---|---|
| 1 | len(list) 列表元素个数 |
| 2 | max(list) 返回列表元素最大值 |
| 3 | min(list) 返回列表元素最小值 |
| 4 | list(seq) 将元组、字符串转换为列表 |
Python包含以下方法:
| 序号 | 方法 |
|---|---|
| 1 | list.append(obj) 在列表末尾添加新的对象 |
| 2 | list.count(obj) 统计某个元素在列表中出现的次数 |
| 3 | list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| 4 | list.index(obj) 从列表中找出某个值第一个匹配项的索引位置 |
| 5 | list.insert(index, obj) 将对象插入列表 |
| 6 | list.pop([index=-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| 7 | list.remove(obj) 移除列表中某个值的第一个匹配项 |
| 8 | list.reverse() 反向列表中元素 |
| 9 | list.sort( key=None, reverse=False) 对原列表进行排序 |
| 10 | list.clear() 清空列表 |
| 11 | list.copy() 复制列表 |
九、 元组
Python 的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号 ( ),列表使用方括号 [ ]。
元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
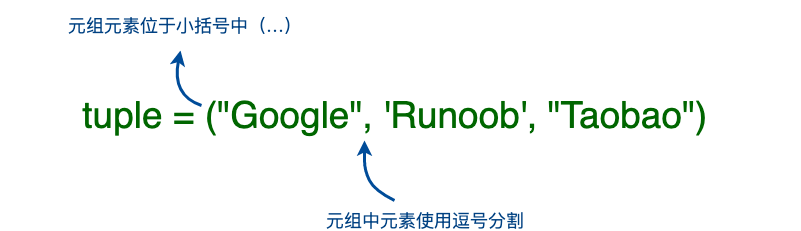
tup1 = ('wcm', 'wmk', 2003, 2004)
tup2 = (1, 2, 3, 4, 5 )
tup3 = "a", "b", "c", "d" # 不需要括号也可以
print(tup1)
print(tup2)
print(tup3)
输出结果
('wcm', 'wmk', 2003, 2004)
(1, 2, 3, 4, 5)
('a', 'b', 'c', 'd')
元组中只包含一个元素时,需要在元素后面添加逗号 , ,否则括号会被当作运算符使用
t1=(50) #int类型 t2=
元组可以使用下标索引来访问元组中的值
1、 修改元组
元组中的元素值是不允许修改的,但我们可以对元组进行连接组合,如下实例:
tup1 = ("wcm",)#必须要有逗号,不然就成了String类型了
tup2 = ("i","love")
tup3 = tup1 + tup2
print(tup1) #('wcm',)
print(tup2) #('i', 'love')
print(tup3)# ('wcm', 'i', 'love')
2、 删除元组
元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组,如下实例:
tup1 = ("wcm","i","love")
print(tup1,type(tup1))
del tup1
print(tup1)
输出结果:
第二个print输出会有异常,因为tup1元素已经被删除,不存在了
('wcm', 'i', 'love') <class 'tuple'>
Traceback (most recent call last):File "E:pythonProjectvenv4 数据类型转换.py", line 193, in <module>print(tup1)^^^^
NameError: name 'tup1' is not defined. Did you mean: 'tuple'?
Process finished with exit code 1
3、 元组运算符
与字符串一样,元组之间可以使用 +、+=和 * 号进行运算。这就意味着他们可以组合和复制,运算后会生成一个新的元组。
| Python 表达式 | 结果 | 描述 |
|---|---|---|
len((1, 2, 3)) | 3 | 计算元素个数 |
>>> a = (1, 2, 3) >>> b = (4, 5, 6) >>> c = a+b >>> c (1, 2, 3, 4, 5, 6) | (1, 2, 3, 4, 5, 6) | 连接,c 就是一个新的元组,它包含了 a 和 b 中的所有元素。 |
>>> a = (1, 2, 3) >>> b = (4, 5, 6) >>> a += b >>> a (1, 2, 3, 4, 5, 6) | (1, 2, 3, 4, 5, 6) | 连接,a 就变成了一个新的元组,它包含了 a 和 b 中的所有元素。 |
('Hi!',) * 4 | (‘Hi!’, ‘Hi!’, ‘Hi!’, ‘Hi!’) | 复制 |
3 in (1, 2, 3) | True | 元素是否存在 |
for x in (1, 2, 3): print (x, end=" ") | 1 2 3 | 迭代 |
4、 元组索引,截取
因为元组也是一个序列,所以我们可以访问元组中的指定位置的元素,也可以截取索引中的一段元素,如下所示:
元组:
tup = ('Google', 'python3', 'Taobao', 'Wiki', 'Weibo','Weixin')
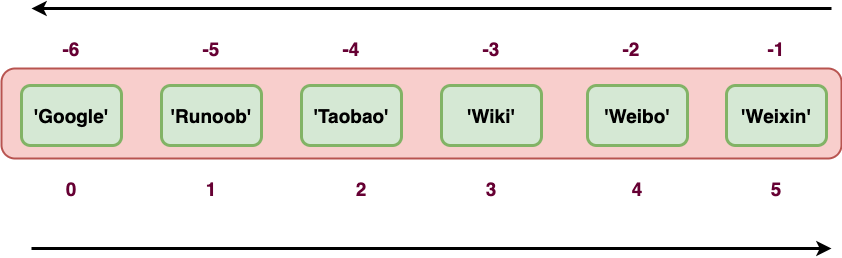
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| tup[1] | ‘python3’ | 读取第二个元素 |
| tup[-2] | ‘Weibo’ | 反向读取,读取倒数第二个元素 |
| tup[1:] | (‘python3’, ‘Taobao’, ‘Wiki’, ‘Weibo’, ‘Weixin’) | 截取元素,从第二个开始后的所有元素。 |
| tup[1:4] | (‘python3’, ‘Taobao’, ‘Wiki’) | 截取元素,从第二个开始到第四个元素(索引为 3)。 |
5、 元组内置函数
Python元组包含了以下内置函数
| 序号 | 方法及描述 | 实例 |
|---|---|---|
| 1 | len(tuple) 计算元组元素个数。 | >>> tuple1 = ('Google', 'python3', 'Taobao') >>> len(tuple1) 3 >>> |
| 2 | max(tuple) 返回元组中元素最大值。 | >>> tuple2 = ('5', '4', '8') >>> max(tuple2) '8' >>> |
| 3 | min(tuple) 返回元组中元素最小值。 | >>> tuple2 = ('5', '4', '8') >>> min(tuple2) '4' >>> |
| 4 | tuple(iterable) 将可迭代系列转换为元组。 | >>> list1= ['Google', 'Taobao', 'python3', 'Baidu'] >>> tuple1=tuple(list1) >>> tuple1 ('Google', 'Taobao', 'python3', 'Baidu') |
6、 关于元组是不可变的
所谓元组的不可变指的是元组所指向的内存中的内容不可变
tup1 = ("wcm","i","love")
print(tup1,id(tup1))
# tup1[0]="wmk" 不能直接修改元组成员的值 否则会报错
tup1 = ("wmk","yyds") #可以允许重新赋值,这将会产生一个新的元组,即id改变了
print(tup1,id(tup1))
tup2 = ("good","you")
tup1 += tup2 #允许进行运算,不过这也将会产生一个新的元组,即id改变了
print(tup1,id(tup1))
输出结果
('wcm', 'i', 'love') <class 'tuple'>
('wcm', 'i', 'love') 2671072672640
('wmk', 'yyds') 2671073673920
('wmk', 'yyds', 'good', 'you') 2671073633808
从以上实例可以看出,重新赋值的元组 tup,绑定到新的对象了,不是修改了原来的对象。
十、 字典
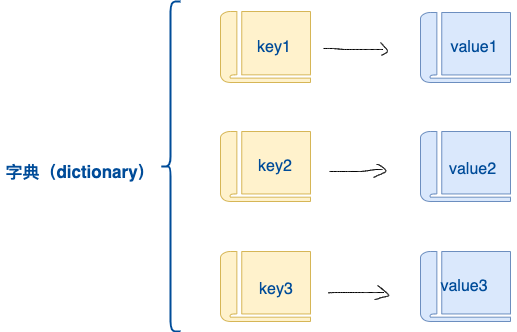
字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值 key=>value 对用冒号 : 分割,每个对之间用逗号(,)分割,整个字典包括在花括号 {} 中 ,格式如下所示:
d = {key1 : value1, key2 : value2, key3 : value3 }
注意:**dict** 作为 Python 的关键字和内置函数,变量名不建议命名为 dict。
键必须是唯一的,但值则不必。
值可以取任何数据类型,但键必须是不可变的,如字符串,数字。
一个简单的字典实例:
tinydict = {'name': 'python3', 'likes': 123, 'url': 'www.python3.com'}
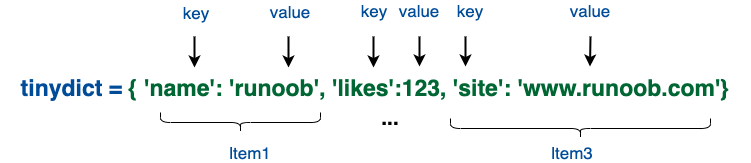
也可如此创建字典:
tinydict1 = { 'abc': 456 }
tinydict2 = { 'abc': 123, 98.6: 37 }
1、 创建空字典
使用大括号 { } 创建空字典:
# 使用大括号 {} 来创建空字典
emptyDict = {}
# 打印字典
print(emptyDict)
# 查看字典的数量
print("Length:", len(emptyDict))
# 查看类型
print(type(emptyDict))
输出结果
{}
Length: 0
<class 'dict'>
使用内建函数 dict() 创建字典:
emptyDict = dict()
# 打印字典
print(emptyDict)
# 查看字典的数量
print("Length:",len(emptyDict))
# 查看类型
print(type(emptyDict))
2、 访问字典里的值
把相应的键放入到方括号中,如下实例:
di1 = {"wcm":18,"wmk":19,"relation":"friend"}
print(di1["wcm"]) # 18
如果用字典里没有的键访问数据,会报错
3、 修改字典
向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对如下实例:
di1 = {"wcm":18,"wmk":19,"relation":"friend"}
print(di1["wcm"])
di1["wcm"] = 20
di1["school"] = "SDUFE"
print(di1)
输出结果
18
{'wcm': 20, 'wmk': 19, 'relation': 'friend', 'school': 'SDUFE'}
4、 删除字典元素
能删单一的元素也能清空字典,清空只需一项操作。
显式删除一个字典用del命令,如下实例:
tinydict = {'Name': 'python3', 'Age': 7, 'Class': 'First'}
del tinydict['Name'] # 删除键 'Name'
tinydict.clear() # 清空字典
del tinydict # 删除字典
4.1、字典键的特性
字典值可以是任何的 python 对象,既可以是标准的对象,也可以是用户定义的,但键不行。
两个重要的点需要记住:
1)不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住
2)键必须不可变,所以可以用数字,字符串或元组充当,而用列表就不行
4.2、字典内置函数&方法
Python字典包含了以下内置函数:
| 序号 | 函数及描述 | 实例 |
|---|---|---|
| 1 | len(dict) 计算字典元素个数,即键的总数。 | >>> tinydict = {'Name': 'python3', 'Age': 7, 'Class': 'First'} >>> len(tinydict) 3 |
| 2 | str(dict) 输出字典,可以打印的字符串表示。 | >>> tinydict = {'Name': 'python3', 'Age': 7, 'Class': 'First'} >>> str(tinydict) "{'Name': 'python3', 'Class': 'First', 'Age': 7}" |
| 3 | type(variable) 返回输入的变量类型,如果变量是字典就返回字典类型。 | >>> tinydict = {'Name': 'python3', 'Age': 7, 'Class': 'First'} >>> type(tinydict) <class 'dict'> |
Python字典包含了以下内置方法:
| 序号 | 函数及描述 |
|---|---|
| 1 | dict.clear() 删除字典内所有元素 |
| 2 | dict.copy() 返回一个字典的浅复制 |
| 3 | dict.fromkeys() 创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 |
| 4 | dict.get(key, default=None) 返回指定键的值,如果键不在字典中返回 default 设置的默认值 |
| 5 | key in dict 如果键在字典dict里返回true,否则返回false |
| 6 | dict.items() 以列表返回一个视图对象 |
| 7 | dict.keys() 返回一个视图对象 |
| 8 | dict.setdefault(key, default=None) 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| 9 | dict.update(dict2) 把字典dict2的键/值对更新到dict里 |
| 10 | dict.values() 返回一个视图对象 |
| 11 | [pop(key,default]) 删除字典 key(键)所对应的值,返回被删除的值。 |
| 12 | popitem() 返回并删除字典中的最后一对键和值。 |
十一、 集合(不讲)
集合(set)是一个无序的不重复元素序列。
集合中的元素不会重复,并且可以进行交集、并集、差集等常见的集合操作。
可以使用大括号 { } 创建集合,元素之间用逗号 , 分隔, 或者也可以使用 set() 函数创建集合。
创建格式:
parame = {value01,value02,...}
或者
set(value)
以下是一个简单实例:
set1 = {1, 2, 3, 4} # 直接使用大括号创建集合
set2 = set([4, 5, 6, 7]) # 使用 set() 函数从列表创建集合
注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
1、 集合的基本操作
1)添加元素
语法格式如下:
s.add( x )
将元素 x 添加到集合 s 中,如果元素已存在,则不进行任何操作。
x 可以有多个,用逗号分开。
2)移除元素
语法格式如下:
s.remove( x )
将元素 x 从集合 s 中移除,如果元素不存在,则会发生错误。
此外还有一个方法也是移除集合中的元素,且如果元素不存在,不会发生错误。格式如下所示:
s.discard( x )
我们也可以设置随机删除集合中的一个元素,语法格式如下:
s.pop()
多次执行测试结果都不一样。
set 集合的 pop 方法会对集合进行无序的排列,然后将这个无序排列集合的左面第一个元素进行删除。
3)计算集合元素个数
语法格式如下:
len(s)
计算集合 s 元素个数
4)清空集合
语法格式如下:
s.clear()
5)判断元素是否在集合中存在
语法格式如下:
x in s
判断元素 x 是否在集合 s 中,存在返回 True,不存在返回 False。
2、 集合内置方法完整列表
| 方法 | 描述 |
|---|---|
| add() | 为集合添加元素 |
| clear() | 移除集合中的所有元素 |
| copy() | 拷贝一个集合 |
| difference() | 返回多个集合的差集 |
| difference_update() | 移除集合中的元素,该元素在指定的集合也存在。 |
| discard() | 删除集合中指定的元素 无不报错 |
| intersection() | 返回集合的交集 |
| intersection_update() | 返回集合的交集。 |
| isdisjoint() | 判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。 |
| issubset() | 判断指定集合是否为该方法参数集合的子集。 |
| issuperset() | 判断该方法的参数集合是否为指定集合的子集 |
| pop() | 随机移除元素 |
| remove() | 移除指定元素无报错 |
| symmetric_difference() | 返回两个集合中不重复的元素集合。 |
| symmetric_difference_update() | 移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。 |
| union() | 返回两个集合的并集 |
| update() | 给集合添加元素 |
十二、 条件判断
Python 条件语句是通过一条或多条语句的执行结果(True 或者 False)来决定执行的代码块。
可以通过下图来简单了解条件语句的执行过程:
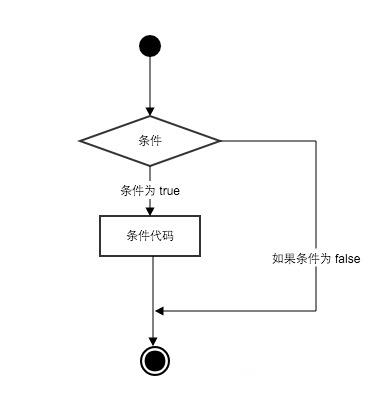
代码执行过程:

1、 if 语句
Python中if语句的一般形式如下所示:
a = int(input())
if a == 1314:print(1314)print("你是个好人")
elif a == 520:print(520)
else:print("单身狗")
Python 中用 elif 代替了 else if,所以if语句的关键字为:if – elif – else。
注意:
-
1、每个条件后面要使用冒号 :,表示接下来是满足条件后要执行的语句块。
-
2、使用缩进来划分语句块,相同缩进数的语句在一起组成一个语句块。
-
3、在 Python 中没有 switch…case 语句,但在 Python3.10 版本添加了 match…case,
2、 if 嵌套
在嵌套 if 语句中,可以把 if…elif…else 结构放在另外一个 if…elif…else 结构中。
if 表达式1:语句if 表达式2:语句elif 表达式3:语句else:语句 elif 表达式4:语句 else:语句
实例:
a = int(input())
if a == 1314:print(1314)if True:print("你是个好人")else:print("你是个人")
elif a == 520:print(520)
else:print("单身狗")
3、 match…case
Python 3.10 增加了 match…case 的条件判断,不需要再使用一连串的 if-else 来判断了。
match 后的对象会依次与 case 后的内容进行匹配,如果匹配成功,则执行匹配到的表达式,否则直接跳过,_ 可以匹配一切。
语法格式如下:
match subject:case <pattern_1>:<action_1>case <pattern_2>:<action_2>case <pattern_3>:<action_3>case _:<action_wildcard>
case _: 类似于 C 和 Java 中的 default:,当其他 case 都无法匹配时,匹配这条,保证永远会匹配成功。
示例:
love = input()
match love:case "520":print("我爱你")case "呵呵":print("扎心了")case _:print("还有机会吗")
输出结果:
520 我爱你
十三、 循环语句
本章节将为大家介绍 Python 循环语句的使用。
Python 中的循环语句有 for 和 while。
Python 循环语句的控制结构图如下所示:
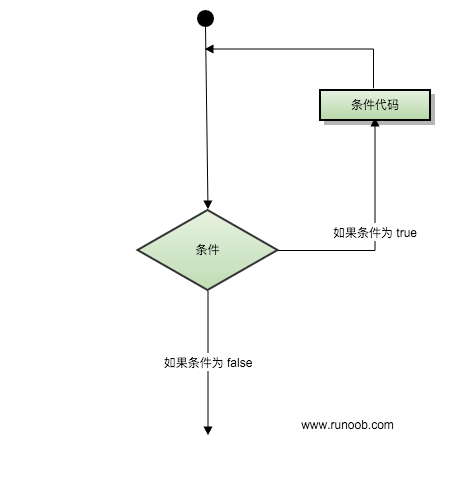
1、 while 循环
Python 中 while 语句的一般形式:
while 判断条件(condition):执行语句(statements)……
执行流程图如下:
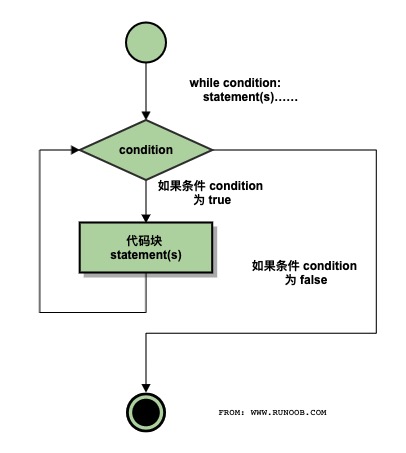
执行 Gif 演示:

同样需要注意冒号和缩进。另外,在 Python 中没有 do…while 循环。
以下实例使用了 while 来计算 1 到 520 的总和:
i = 1 sum = 0 while i <= 520:sum+=ii+=1 print(sum) #135460
2、 while 循环使用 else 语句
如果 while 后面的条件语句为 false 时,则执行 else 的语句块。
语法格式如下:
while <expr>:<statement(s)> else:<additional_statement(s)>
expr 条件语句为 true 则执行 statement(s) 语句块,如果为 false,则执行 additional_statement(s)。
循环输出数字,并判断大小:
count = 0 while count < 5:print (count, " 小于 5")count = count + 1 else:print (count, " 大于或等于 5")
执行以上脚本,输出结果如下:
0 小于 5 1 小于 5 2 小于 5 3 小于 5 4 小于 5 5 大于或等于 5
3、 简单语句组
类似 if 语句的语法,如果你的 while 循环体中只有一条语句,你可以将该语句与 while 写在同一行中, 如下所示:
flag = 1
while (flag): print ('欢迎访问我的博客!')
print ("Good bye!")
注意:以上的无限循环你可以使用 CTRL+C 来中断循环。
3、 for 语句
Python for 循环可以遍历任何可迭代对象,如一个列表或者一个字符串。
for循环的一般格式如下:
for <variable> in <sequence>:<statements> else:<statements>
实例如
list = ["wcm", "i", "love", "you", "1314"] for li in list:print(li)
输出结果:
wcm i love you 1314
也可用于打印字符串中的每个字符:
word = 'wcm' for letter in word:print(letter)
输出结果:
w c m
整数范围值可以配合 range() 函数使用:
# 1 到 5 的所有数字: for number in range(1, 6):print(number)
4、 for…else
在 Python 中,for…else 语句用于在循环结束后执行一段代码。
语法格式如下:
for item in iterable: # 循环主体 else: # 循环结束后执行的代码
当循环执行完毕(即遍历完 iterable 中的所有元素)后,会执行 else 子句中的代码,如果在循环过程中遇到了 break 语句,则会中断循环,此时不会执行 else 子句。
5、range() 函数
如果你需要遍历数字序列,可以使用内置 range() 函数。它会生成数列,例如:
for i in range(5):print(i)
输出结果:
0 1 2 3 4
你也可以使用 range() 指定区间的值:
for i in range(3, 7): #左闭右开print(i)
输出结果:
3 4 5 6
也可以使 range() 以指定数字开始并指定不同的增量(甚至可以是负数,有时这也叫做’步长’):
for i in range(0, 10, 2): print(i)
输出结果:
2 4 6 8
6、 break 和 continue 语句及循环中的 else 子句
break 执行流程图:
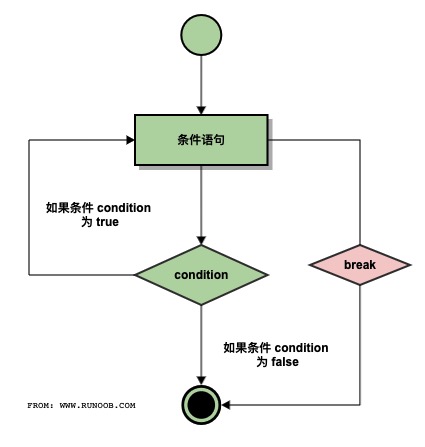
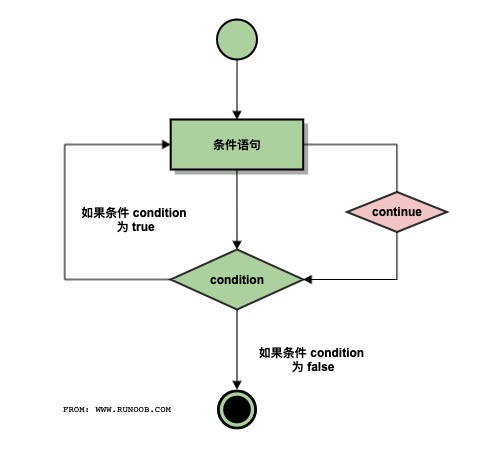
continue 执行流程图:
while 语句代码执行过程:
for 语句代码执行过程:

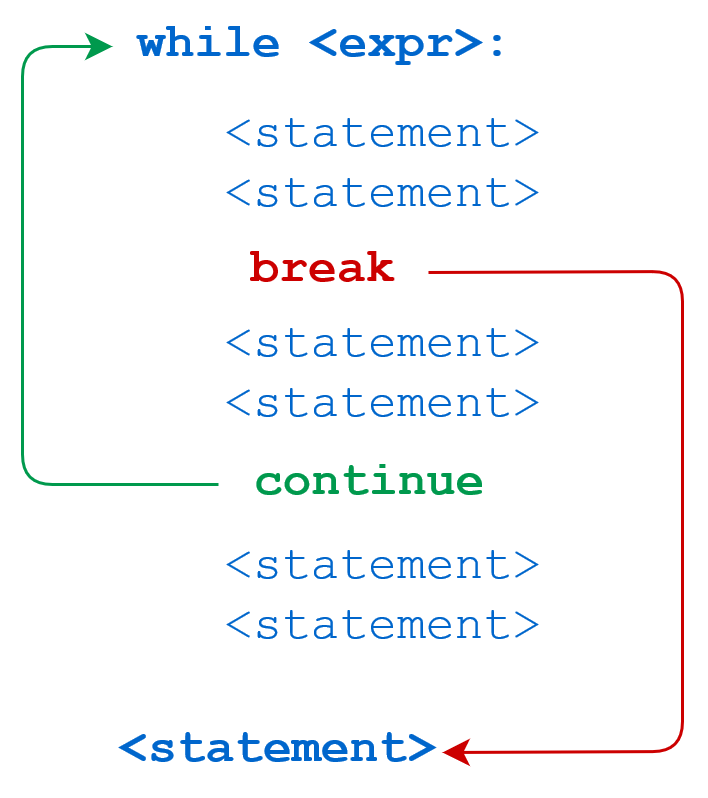
break 语句可以跳出 for 和 while 的循环体。如果你从 for 或 while 循环中终止,任何对应的循环 else 块将不执行。
continue 语句被用来告诉 Python 跳过当前循环块中的剩余语句,然后继续进行下一轮循环。
7、 pass 语句
Python pass是空语句,是为了保持程序结构的完整性。
pass 不做任何事情,一般用做占位语句,如下实例
if letter == 'c':passprint('执行 pass 块')else:print('当前字母 :', letter)
输出结果:
当前字母 : w 执行 pass 块 当前字母 : m
十四、函数
1、简介
函数 是一组执行操作的指令块,一旦定义,就可以被重复使用。函数使代码更加模块化,允许您反复使用相同的代码。
Python 中有许多内置函数,您可能熟悉其中一些,包括:
-
print()用于将对象打印到终端 -
int()用于将字符串或数字数据类型转换为整数数据类型 -
len()返回对象的长度
函数名称包括括号,并且可能包括参数。
在本教程中,我们将介绍如何定义自己的函数以在编码项目中使用。
2、先决条件
您应该已经安装了 Python 3,并在计算机或服务器上设置了编程环境。如果您还没有设置编程环境,可以参考适用于您的操作系统(Ubuntu、CentOS、Debian 等)的本地编程环境或服务器编程环境的安装和设置指南。
3、定义函数
让我们从将经典的“Hello, World!”程序转换为函数开始。
我们将在我们选择的文本编辑器中创建一个新的文本文件,并将程序命名为 hello.py。然后,我们将定义函数。
使用 def 关键字定义函数,后面跟着您选择的名称,然后是一组括号,其中包含函数将接受的任何参数(它们可以为空),最后以冒号结尾。
在这种情况下,我们将定义一个名为 hello() 的函数:
def hello():
这设置了创建函数的初始语句。
接下来,我们将添加第二行,缩进 4 个空格,以提供函数执行的指令。在这种情况下,我们将在控制台打印 Hello, World!:
def hello():print("Hello, World!")
我们的函数现在已经完全定义,但是如果此时运行程序,将不会发生任何事情,因为我们没有调用函数。
因此,在我们定义的函数块之外,让我们使用 hello() 调用函数:
def hello():print("Hello, World!")
hello()
现在,让我们运行程序:
python hello.py
您应该收到以下输出:
Hello, World!
函数可以比我们上面定义的 hello() 函数更复杂。例如,我们可以在函数块内部使用 for 循环、条件语句等。
例如,下面定义的函数利用条件语句检查 name 变量的输入是否包含元音字母,然后使用 for 循环迭代 name 字符串中的字母。
# 定义函数 names()
def names():# 使用输入设置 name 变量name = str(input('输入您的姓名:'))# 检查 name 是否包含元音字母if set('aeiou').intersection(name.lower()):print('您的姓名包含元音字母。')else:print('您的姓名不包含元音字母。')
# 迭代 namefor letter in name:print(letter)
# 调用函数
names()
我们上面定义的 names() 函数设置了一个条件语句和一个 for 循环,展示了如何在函数定义中组织代码。但是,根据我们的程序意图以及我们想要如何设置代码,我们可能希望将条件语句和 for 循环定义为两个单独的函数。
在程序中定义函数使我们的代码模块化和可重用,这样我们可以在不重写它们的情况下调用相同的函数。
4、使用参数
到目前为止,我们已经看过了不带参数的函数,但是我们可以在函数定义中的括号内定义参数。
参数 是函数定义中的命名实体,指定函数可以接受的参数。
让我们创建一个小程序,接受参数 x、y 和 z。我们将创建一个函数,以不同的配置将这些参数相加。然后函数将打印这些和。然后我们将调用函数并将数字传递给函数。
def add_numbers(x, y, z):a = x + yb = x + zc = y + zprint(a, b, c) add_numbers(1, 2, 3)
我们为 x 参数传递了数字 1,为 y 参数传递了数字 2,为 z 参数传递了数字 3。这些值与它们给出的顺序中的每个参数相对应。
程序基本上根据我们传递给参数的值执行以下数学运算:
a = 1 + 2 b = 1 + 3 c = 2 + 3
函数还打印 a、b 和 c,根据上面的数学运算,我们期望 a 等于 3,b 等于 4,c 等于 5。让我们运行程序:
python add_numbers.py3 4 5
当我们将 1、2 和 3 作为参数传递给 add_numbers() 函数时,我们收到了预期的输出。
参数通常在函数定义中被定义为变量。当您运行方法时,可以为它们分配值,将参数传递给函数。
关键字参数
除了按顺序调用参数外,您还可以在函数调用中使用关键字参数,在这种情况下,调用者通过参数名称标识参数。
使用关键字参数时,您可以无序使用参数,因为 Python 解释器将使用提供的关键字将值与参数匹配。
让我们创建一个函数,用于显示用户的个人资料信息。我们将以 username(预期为字符串)和 followers(预期为整数)的形式向其传递参数。
# 使用参数定义函数
def profile_info(username, followers):print("用户名:" + username)print("粉丝数:" + str(followers))
在函数定义语句中,username 和 followers 包含在 profile_info() 函数的括号中。函数的代码块打印有关用户的信息作为字符串,利用这两个参数。
现在,我们可以调用函数并为其分配参数:
def profile_info(username, followers):print("用户名:" + username)print("粉丝数:" + str(followers))
# 使用上述分配的参数调用函数
<^>profile_info("sammyshark", 945)<^>
# 使用关键字参数调用函数
<^>profile_info(username="AlexAnglerfish", followers=342)<^>
在第一个函数调用中,我们填写了用户名为 sammyshark,粉丝数为 945 的信息,而在第二个函数调用中,我们使用了关键字参数,为参数变量分配了值。
让我们运行程序:
python profile.py用户名:sammyshark 粉丝数:945 用户名:AlexAnglerfish 粉丝数:342
输出显示了两个用户的用户名和粉丝数。
这也允许我们修改参数的顺序,就像在下面的相同程序的不同调用示例中一样:
def profile_info(username, followers):print("用户名:" + username)print("粉丝数:" + str(followers))
# 更改参数的顺序
<^>profile_info(followers=820, username="cameron-catfish")<^>
当我们再次使用 python profile.py 命令运行程序时,我们将收到以下输出:
用户名:cameron-catfish 粉丝数:820
因为函数定义保持了 print() 语句的相同顺序,如果我们使用关键字参数,传递参数的顺序就不重要。
默认参数值
我们还可以为一个或两个参数提供默认值。让我们为 followers 参数创建一个默认值为 1 的默认值:
def profile_info(username, <^>followers=1<^>):print("用户名:" + username)print("粉丝数:" + str(followers))
现在,我们可以仅为用户名函数分配值,并且粉丝数将自动默认为 1。如果我们愿意,我们也可以更改粉丝数。
def profile_info(username, followers=1):print("用户名:" + username)print("粉丝数:" + str(followers))
profile_info(username="JOctopus")
profile_info(username="sammyshark", followers=945)
当我们使用 python profile.py 命令运行程序时,我们将收到以下输出:
用户名:JOctopus 粉丝数:1 用户名:sammyshark 粉丝数:945
通过为具有默认值的每个参数跳过定义值,可以让我们跳过为每个参数定义值。
5、返回值
您可以将参数值传递给函数,函数也可以生成一个值。
函数可以使用 return 语句生成一个值,该语句将退出函数并可选地将表达式传递回调用者。如果使用没有参数的 return 语句,函数将返回 None。
到目前为止,我们在函数中使用了 print() 语句而不是 return 语句。让我们创建一个程序,该程序不是打印而是返回一个变量。
在一个名为 square.py 的新文本文件中,我们将创建一个程序,该程序将参数 x 的平方并返回变量 y。我们发出一个调用以打印 result 变量,该变量是通过运行 square() 函数并传入 3 得到的。
def square(x):y = x ** 2return y result = square(3) print(result)
我们可以运行程序并收到输出:
python square.py9
整数 9 作为输出返回,这是我们期望 Python 找到 3 的平方的结果。
为了进一步理解 return 语句的工作原理,我们可以注释掉程序中的 return 语句:
def square(x):y = x ** 2# return y result = square(3) print(result)
现在,让我们再次运行程序:
python square.pyNone
在这里没有使用 return 语句,程序无法返回一个值,因此该值默认为 None。
另一个例子,在上面的 add_numbers.py 程序中,我们可以将 print() 语句替换为 return 语句。
def add_numbers(x, y, z):a = x + yb = x + zc = y + zreturn a, b, c sums = add_numbers(1, 2, 3) print(sums)
在函数之外,我们将变量 sums 设置为函数接受 1、2 和 3 作为参数的结果。然后我们调用了 sums 变量的打印。
现在让我们再次运行程序,因为它有了 return 语句:
python add_numbers.py(3, 4, 5)
我们收到了与之前使用 print() 语句在函数中收到的相同的数字 3、4 和 5 作为输出,这次它作为一个元组返回,因为 return 语句的表达式列表至少有一个逗号。
函数在遇到 return 语句时立即退出,无论它们是否返回一个值。
def loop_five():for x in range(0, 25):print(x)if x == 5:# 在 x == 5 时停止函数returnprint("此行将不会执行。")
loop_five()
在 for 循环中使用 return 语句结束了函数,因此在循环之外的行将不会运行。如果我们使用 break 语句,只有循环会在那时退出,并且最后的 print() 行将运行。
return 语句退出函数,并在发出参数时可能返回一个值。## 使用 main() 作为一个函数
虽然在 Python 中,你可以在程序的末尾调用函数并且它会运行(就像我们在上面的例子中所做的那样),但是许多编程语言(比如 C++ 和 Java)要求必须有一个 main 函数才能执行。虽然不是必需的,但是包含一个 main() 函数可以以一种逻辑的方式构建我们的 Python 程序,将程序的最重要的组件放入一个函数中。这也可以使得我们的程序更容易让非 Python 程序员阅读。
我们将从在上面的 hello.py 程序中添加一个 main() 函数开始。我们将保留我们的 hello() 函数,然后定义一个 main() 函数:
def hello():print("Hello, World!")
<^>def main():<^>
在 main() 函数中,让我们包含一个 print() 语句来让我们知道我们在 main() 函数中。另外,让我们在 main() 函数中调用 hello() 函数:
def hello():print("Hello, World!")
def main():<^>print("This is the main function")<^><^>hello()<^>
最后,在程序的末尾我们将调用 main() 函数:
def hello():print("Hello, World!")
def main():print("This is the main function.")hello()
<^>main()<^>
此时,我们可以运行我们的程序:
python hello.py
我们将收到以下输出:
This is the main function. Hello, World!
因为我们在 main() 中调用了 hello() 函数,然后只调用了 main() 来运行,所以 Hello, World! 文本只打印了一次,在告诉我们我们在主函数中的字符串之后。
接下来,我们将要使用多个函数,因此值得回顾一下全局变量和局部变量的变量作用域。如果你在一个函数块内定义一个变量,你只能在该函数内使用该变量。如果你想要在多个函数之间使用变量,最好声明一个全局变量。
在 Python 中,'__main__' 是顶层代码将执行的作用域的名称。当从标准输入、脚本或交互式提示符中运行程序时,它的 __name__ 被设置为 '__main__'。
因此,有一个约定使用以下结构:
if __name__ == '__main__':# 当这是主程序时要运行的代码
这使得程序文件可以被用作:
-
主程序并运行
if语句后面的内容 -
作为一个模块而不运行
if语句后面的内容。
任何不包含在此语句中的代码将在运行时执行。如果你将你的程序文件用作模块,那么在运行次要文件时,不在此语句中的代码也将被执行。
让我们扩展上面的 names.py 程序,并创建一个名为 more_names.py 的新文件。在这个程序中,我们将声明一个全局变量,并修改我们原来的 names() 函数,使得指令在两个不同的函数中。
第一个函数 has_vowel() 将检查 name 字符串是否包含元音字母。
第二个函数 print_letters() 将打印 name 字符串的每个字母。
# 声明全局变量 name 以便在所有函数中使用
name = str(input('输入你的名字:'))
# 定义函数来检查名字是否包含元音字母
def has_vowel():if set('aeiou').intersection(name.lower()):print('你的名字包含元音字母。')else:print('你的名字不包含元音字母。')
# 遍历名字字符串中的每个字母
def print_letters():for letter in name:print(letter)
有了这个设置,让我们定义 main() 函数,其中将调用 has_vowel() 和 print_letters() 函数。
# 声明全局变量 name 以便在所有函数中使用
name = str(input('输入你的名字:'))
# 定义函数来检查名字是否包含元音字母
def has_vowel():if set('aeiou').intersection(name.lower()):print('你的名字包含元音字母。')else:print('你的名字不包含元音字母。')
# 遍历名字字符串中的每个字母
def print_letters():for letter in name:print(letter)
# 定义调用其他函数的主方法
<^>def main():<^><^>has_vowel()<^><^>print_letters()<^>
最后,我们将在文件的末尾添加 if __name__ == '__main__': 结构。对于我们的目的,因为我们已经把我们想要在 main() 函数中做的所有函数都放在了 main() 函数中,我们将在这个 if 语句后面调用 main() 函数。
# 声明全局变量 name 以便在所有函数中使用 name = str(input('输入你的名字:')) # 定义函数来检查名字是否包含元音字母 def has_vowel():if set('aeiou').intersection(name.lower()):print('你的名字包含元音字母。')else:print('你的名字不包含元音字母。') # 遍历名字字符串中的每个字母 def print_letters():for letter in name:print(letter) # 定义调用其他函数的主方法 def main():has_vowel()print_letters() # 执行 main() 函数 if __name__ == '__main__':main() 现在我们可以运行这个程序:
python more_names.py
程序将显示与 names.py 程序相同的输出,但是这里的代码更有组织性,可以以模块化的方式使用而无需修改。
如果你不想声明一个 main() 函数,你也可以像这样结束程序:
... if __name__ == '__main__':has_vowel()print_letters()
使用 main() 作为一个函数和 if __name__ == '__main__': 语句可以以一种逻辑的方式组织你的代码,使得它更易读和模块化。
6、结论
函数是程序中执行操作的代码块,有助于使我们的代码可重用和模块化。
十五、 Python 推导式(了解)
Python 推导式是一种独特的数据处理方式,可以从一个数据序列构建另一个新的数据序列的结构体。
Python 支持各种数据结构的推导式:
-
列表(list)推导式
-
字典(dict)推导式
-
集合(set)推导式
-
元组(tuple)推导式
1、 列表推导式
列表推导式格式为:
[表达式 for 变量 in 列表] [out_exp_res for out_exp in input_list] 或者 [表达式 for 变量 in 列表 if 条件] [out_exp_res for out_exp in input_list if condition]
-
out_exp_res:列表生成元素表达式,可以是有返回值的函数。
-
for out_exp in input_list:迭代 input_list 将 out_exp 传入到 out_exp_res 表达式中。
-
if condition:条件语句,可以过滤列表中不符合条件的值。
过滤掉长度小于或等于3的字符串列表,并将剩下的转换成大写字母:
names = ["wcm","i","love","you","一生一世"] new_names = [name.upper() for name in names if len(name)>3] print(new_names)
输出结果:
['LOVE', '一生一世']
计算 30 以内可以被 3 整除的整数:
multiples = [i for i in range(30) if i % 3 == 0] print(multiples) #[0, 3, 6, 9, 12, 15, 18, 21, 24, 27]
2、 字典推导式
字典推导基本格式:
{ key_expr: value_expr for value in collection }
or
{ key_expr: value_expr for value in collection if condition }
使用字符串及其长度创建字典:
list1 = ['wcm', 'wmk', 'love']
newdict = {key:len(key) for key in list1}
print(newdict)
#{'wcm': 3, 'wmk': 3, 'love': 4
3、 集合推导式
集合推导式基本格式:
{ expression for item in Sequence }
或
{ expression for item in Sequence if conditional }
计算数字 1,2,3 的平方数:
setnew = {i**2 for i in (1,2,3)}
判断不是 abc 的字母并输出:
a = {x for x in 'abracadabra' if x not in 'abc'}
print(a)
4、 元组推导式(生成器表达式)
元组推导式可以利用 range 区间、元组、列表、字典和集合等数据类型,快速生成一个满足指定需求的元组。
元组推导式基本格式:
(expression for item in Sequence ) 或 (expression for item in Sequence if conditional )
元组推导式和列表推导式的用法也完全相同,只是元组推导式是用 () 圆括号将各部分括起来,而列表推导式用的是中括号 [],另外元组推导式返回的结果是一个生成器对象。
例如,我们可以使用下面的代码生成一个包含数字 1~9 的元组:
a = (x for x in range(1,10)) print(a) #输出的是生成器 a = tuple(a) # 使用 tuple() 函数,可以直接将生成器对象转换成元组 print(a) #输出 #<generator object <genexpr> at 0x000001A6265481E0> #(1, 2, 3, 4, 5, 6, 7, 8, 9)