ClickHouse 数据更新策略深度解析:突变操作与最佳实践
1. 引言
在传统OLTP数据库中,对单条记录的UPDATE和DELETE是基础操作。然而,ClickHouse 作为一个为大规模数据分析而设计的列式OLAP数据库,其核心架构并非为高频、单点更新而优化。数据在磁盘上按列存储,并被打包成不可变的压缩数据块,这种设计带来了极致的查询性能,但也使得原地更新变得异常昂贵。
尽管如此,在实际业务中,数据更新和删除的需求依然存在(如用户信息修正、状态更新、GDPR合规删除等)。ClickHouse 通过 “突变”(Mutation) 操作来满足这类需求。理解其工作原理并掌握高效的使用策略至关重要。
核心要点: 在 ClickHouse 中,应将“突变”视为一种重量级的后台操作,而非轻量级的实时工具。

2. 什么是“突变”?
“突变”是 ClickHouse 中对表数据进行修改(ALTER TABLE ... UPDATE)和删除(ALTER TABLE ... DELETE)操作的统称。它并非原地修改已有数据,而是通过重写整个数据部分(Part) 来实现。
2.1. 核心工作原理
- 触发命令: 当执行一条
ALTER TABLE [db.]table UPDATE ...或ALTER TABLE [db.]table DELETE ...语句时,ClickHouse 并不会立即执行。 - 创建突变条目: 该命令被记录到 ZooKeeper(对于复制表)或磁盘(对于非复制表)的一个队列中,并立即返回给客户端。这是一个异步操作。
- 后台执行: ClickHouse 在后台异步地启动一个进程,扫描所有涉及目标数据的数据部分。
- 数据重写: 对于每一个包含目标数据的数据部分,ClickHouse:
- 创建一个新的、修改后的数据部分副本。
- 在副本中应用变更(更新指定列的值或标记行为已删除)。
- 这个重写过程是以整个部分为单位的,即使你只修改其中一行。
- 部分替换: 一旦新的数据部分准备好,系统会用新的部分原子性地替换旧的部分。旧的部分最终会被垃圾回收。
2.2. 一个简单的例子
假设我们有一张表 user_activity:
CREATE TABLE user_activity
(user_id UInt64,timestamp DateTime,action String,status String
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(timestamp)
ORDER BY (user_id, timestamp);
更新操作:
-- 将用户123在特定时间后的所有行为状态更新为 ‘processed’
ALTER TABLE user_activity
UPDATE status = 'processed'
WHERE user_id = 123 AND timestamp > '2023-10-01 00:00:00';
删除操作:
-- 删除所有测试用户的数据
ALTER TABLE user_activity
DELETE WHERE user_id LIKE 'test%';
执行后,你可以通过 system.mutations 表来查看突变的状态。
SELECT database, table, command, is_done, create_time, latest_fail_reason
FROM system.mutations
WHERE NOT is_done
ORDER BY create_time DESC;
3. 突变的性能影响与挑战
突变操作最大的挑战在于其资源密集性和潜在的性能影响。
- 高 I/O 和 CPU 开销: 重写整个数据部分意味着需要读取旧数据、在内存中处理、写入新数据,并进行压缩。这会产生大量的磁盘 I/O 和 CPU 消耗。
- 执行速度慢: 重写速度与涉及的数据量成正比。对于一个包含数亿行的大数据部分,一次突变可能需要几分钟甚至数小时。
- 对并发查询的影响: 在突变执行期间,它会与正常查询竞争系统资源(CPU、磁盘带宽、内存),可能影响查询性能。
- 部分爆炸(Part Proliferation): 频繁的小范围突变会导致大量小数据部分的产生,因为每次突变只重写受影响的部分。这会降低后续查询效率,因为 MergeTree 需要打开更多的文件句柄。后台的合并(Merge)进程虽然会合并这些小部分,但如果突变频率高于合并速度,问题会加剧。
- 阻塞后续突变: 对于同一张表,突变是顺序执行的。如果一个大型突变正在运行,后续的突变必须等待它完成,这可能导致变更延迟。
4. 高效数据更新策略与最佳实践
鉴于突变的特性,我们应该从表引擎选择和数据操作模式上规避其缺点。
4.1. 选择合适的表引擎
这是最关键的决策。根据你的更新需求,选择正确的表引擎。
A. ReplacingMergeTree
适用场景: 需要根据主键去重,或实现“最终一致性”的更新。适用于数据流中可能存在重复,但最终只需要保留最新版本的情况(如用户画像、物化视图的目标表)。
工作原理: 在后台数据合并时,它会根据 ORDER BY 键对重复的数据行进行去重,仅保留最后插入的那一行(或通过 VER 列指定版本)。
示例:
CREATE TABLE user_profile
(user_id UInt64,username String,email String,last_updated DateTime
)
ENGINE = ReplacingMergeTree(last_updated)
PARTITION BY intDiv(user_id, 1000)
ORDER BY (user_id);-- 插入或更新用户123的信息
INSERT INTO user_profile VALUES (123, 'old_user', 'old@email.com', now());
INSERT INTO user_profile VALUES (123, 'new_user', 'new@email.com', now());-- 查询时,可能仍会看到两行,因为合并尚未发生
SELECT * FROM user_profile WHERE user_id = 123;-- 确保最终结果的正确查询方式
SELECTuser_id,argMax(username, last_updated) as username,argMax(email, last_updated) as email,max(last_updated) as final_updated
FROM user_profile
WHERE user_id = 123
GROUP BY user_id;
最佳实践: 查询时使用 FINAL 关键字(但可能有性能代价)或使用 argMax 类聚合函数进行分组查询,以获取最新状态。
B. CollapsingMergeTree & VersionedCollapsingMergeTree
适用场景: 需要高效地存储和更新可变状态或可累加指标,例如用户的余额、商品的库存、实时在线人数。
工作原理: 通过一个“符号”(Sign)列来标记行是“状态”(+1)还是“取消状态”(-1)。合并时,符号相反的行会被折叠(删除)。VersionedCollapsingMergeTree 通过一个版本列解决了乱序写入导致的折叠错乱问题,是更安全的选择。
示例(库存更新):
CREATE TABLE inventory
(product_id UInt64,warehouse_id UInt64,quantity Int32,sign Int8,version UInt64
)
ENGINE = VersionedCollapsingMergeTree(sign, version)
PARTITION BY warehouse_id
ORDER BY (product_id, warehouse_id);-- 初始入库 100 件
INSERT INTO inventory VALUES (101, 1, 100, 1, 1);-- 售出 10 件:先取消旧状态,再插入新状态
-- 这是一种“双写”模式
INSERT INTO inventory VALUES(101, 1, 100, -1, 1), -- 取消旧状态(version=1)(101, 1, 90, 1, 2); -- 插入新状态(version=2)-- 查询当前库存的正确方式
SELECTproduct_id,warehouse_id,sum(quantity * sign) AS current_quantity
FROM inventory
GROUP BY product_id, warehouse_id
HAVING current_quantity > 0;
4.2. 操作层面的最佳实践
-
批量操作,而非频繁单点更新:
- 劣: 每分钟执行一次只影响几十行的突变。
- 优: 每小时或每天执行一次,将多个小变更聚合成一个大的批量突变。这显著减少了部分爆炸和总体开销。
-
利用分区剪枝:
- 在
WHERE条件中尽可能指定分区键。这能让 ClickHouse 只重写特定分区中的数据,极大减少工作量。 - 示例:
ALTER TABLE ... UPDATE ... WHERE partition_key = X AND ...
- 在
-
监控
system.mutations表:- 定期检查是否有突变失败(
latest_fail_reason)或堆积。 - 关注
parts_to_do列,了解剩余工作量。
- 定期检查是否有突变失败(
-
避免在高峰期执行大型突变:
- 在业务低峰期(如夜间)调度大型数据更新或删除任务。
-
考虑使用
ALTER TABLE ... MODIFY QUERY重构物化视图:- 如果你的更新逻辑源于物化视图的源表,有时重构物化视图比直接更新目标表更高效。
5. 总结与决策流程图
| 特性/引擎 | ReplacingMergeTree | CollapsingMergeTree | 突变(Mutation) |
|---|---|---|---|
| 更新方式 | 插入新行,后台合并去重 | 插入“取消”和“新状态”行,后台合并折叠 | 后台重写数据部分 |
| 一致性 | 最终一致 | 最终一致 | 最终一致(执行完成后) |
| 开销 | 低(仅插入+合并) | 低(仅插入+合并) | 高(重写部分) |
| 适用场景 | 去重、版本化数据 | 状态变化、指标更新 | 一次性、大范围、不频繁的更新/删除 |
决策流程图
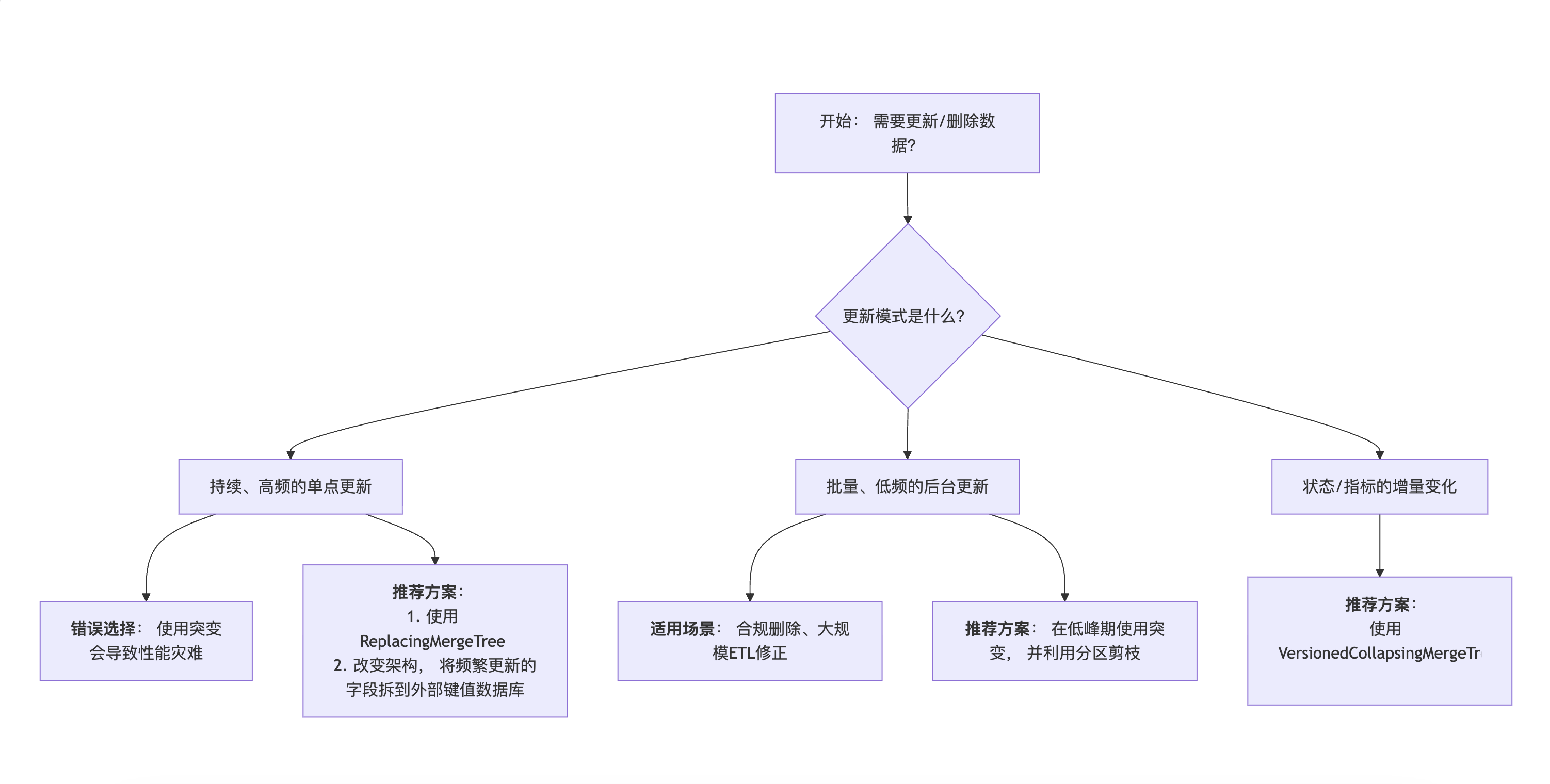
最终建议:
- 设计时优先考虑: 在表设计阶段,就根据数据的更新模式选择合适的 MergeTree 引擎(如
ReplacingMergeTree,VersionedCollapsingMergeTree),从根源上避免使用突变。 - 将突变作为最后手段: 仅当上述引擎无法满足需求,或进行一次性、大规模、不频繁的数据修正和清理时,才使用突变操作,并严格遵守最佳实践。
通过理解 ClickHouse 的架构哲学并采用正确的策略,你可以在享受其卓越查询性能的同时,优雅地处理数据更新的挑战。
核心问题:ClickHouse为什么不喜欢“单行更新”?
ClickHouse是一个为大规模数据分析而设计的列式数据库。它的强项是快速插入和高速查询海量数据。为了实现这个目标,它做了两个关键设计:
-
数据不可变性:数据一旦写入,最好就不再修改。这简化了存储结构,使得压缩、索引和查询都非常高效。
-
批量操作:所有操作(写、读、合并)都针对大批量数据块进行,这能最大化利用I/O和CPU资源。
基于这两个设计,像 ALTER TABLE … UPDATE 这样的“单行更新”命令,就与它的底层架构格格不入。这个命令在ClickHouse里被称为 “Mutation” 操作。
Mutation操作(ALTER TABLE … UPDATE/DELETE)的真相
当你执行一个 UPDATE 或 DELETE 时,ClickHouse并不会去磁盘上找到那一行数据然后修改或删除它。这样做是随机I/O,性能极差。
Mutation操作实际上是这样工作的:
-
标记,而非重写: 系统会为要更改的数据打上一个“删除”或“更新”的标记,但原始数据文件本身纹丝不动。
-
后台重写: 在后台,ClickHouse会启动一个异步的合并过程。当它合并数据部件时,会创建一个全新的、不包含被标记数据的新部件,并最终丢弃旧的部件。
重量级后果:
-
高I/O压力: 需要读取整个分区的老数据,应用更改,再写入整个分区的新数据。
-
高CPU压力: 需要重新压缩和索引数据。
-
慢: 对于大表,这个过程可能非常漫长,并且会排队,影响后续的Mutation操作。
结论: Mutation操作是重量级的,不适合频繁或实时更新的场景。