【力扣 SQL 50】聚合函数篇
目录
1.有趣的电影
2.平均售价
3.项目员工 I
4.各赛事的用户注册率
5.查询结果的质量和占比
6.每月交易I
7.即时食物配送II
8.游戏玩法分析IV
题目来源:高频 SQL 50 题(基础版) - 学习计划 - 力扣(LeetCode)全球极客挚爱的技术成长平台
1.有趣的电影
题目:

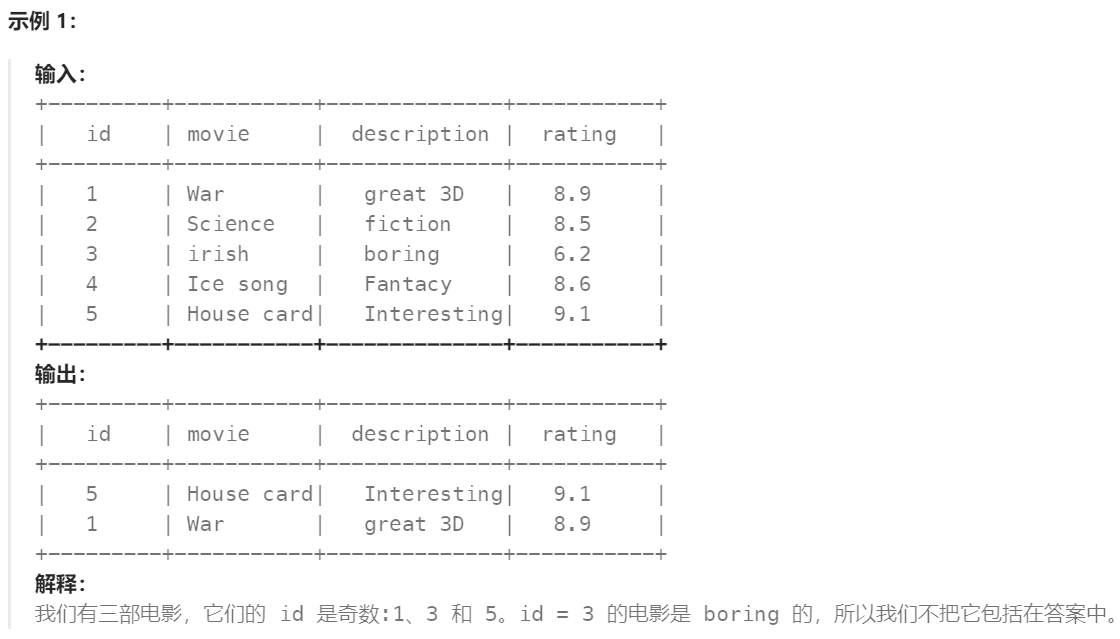
编写解决方案,找出所有影片描述为 非 boring (不无聊) 的并且 id 为奇数 的影片。
返回结果按 rating 降序排列。
结果格式如下示例。
思路:
这里主要是不等号“<>”的使用,还有使用位运算来判断奇数,id&1若id为奇数则结果为1,否则为0,还有注意倒排desc
代码:
#位运算+排倒序
select *from cinemawhere description <> 'boring'and id&1order by rating desc2.平均售价
题目:

编写解决方案以查找每种产品的平均售价。average_price 应该 四舍五入到小数点后两位。如果产品没有任何售出,则假设其平均售价为 0。
返回结果表 无顺序要求 。
结果格式如下例所示。

思路:
这里先把两个表按时间关系用左连接连起来(考虑右表可能没数据,但是也要计算),右表的id的下单时间必须在左表对应id的时间段内,因此需要三个连接条件。
然后按id分组,因为这里的平均值是加权平均值,因此不能用avg(),需要分别求出分子sum(p.price*u.units)和分母sum(u.units),保留两位小数,最后使用一个ifnull()函数来保证没有订单的情况下的平均值为0(注意是0,不需要保留两位小数!)
代码:
# 左连接+求和+求平均值+空值判断
select p.product_id, ifnull(round(sum(p.price*u.units)/sum(u.units),2),0) average_price from Prices pleft join UnitsSold u on p.product_id=u.product_idand u.purchase_date >= p.start_dateand u.purchase_date <= p.end_dategroup by p.product_id3.项目员工 I
题目:

请写一个 SQL 语句,查询每一个项目中员工的 平均 工作年限,精确到小数点后两位。
以 任意 顺序返回结果表。
查询结果的格式如下。

思路:
就是简单的计算平均值,先进行全连接,然后按project_id分组,最后使用avg()统计experience_years列即可
代码:
# 全连接+求平均值
select p.project_id, round(avg(experience_years),2) average_years from Project pinner join Employee e on p.employee_id = e.employee_id group by p.project_id4.各赛事的用户注册率
题目:

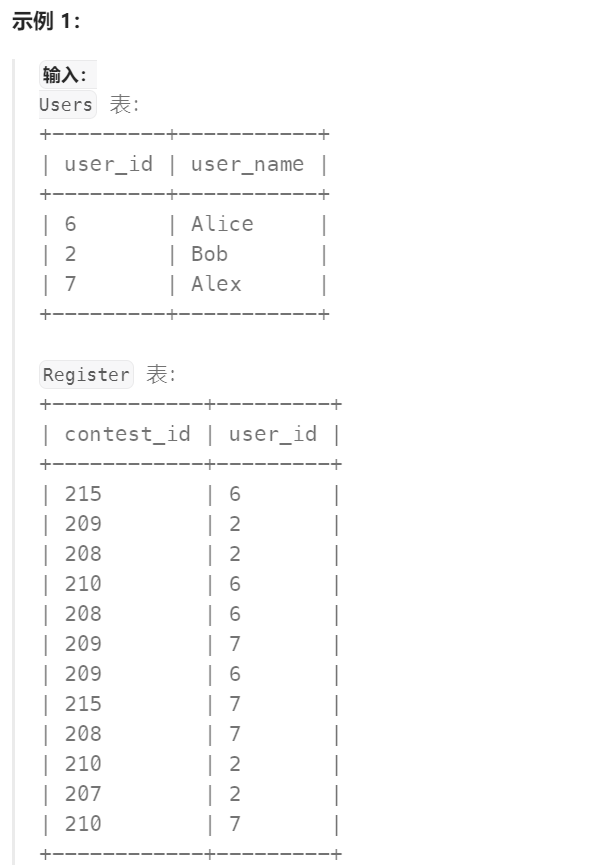
编写解决方案统计出各赛事的用户注册百分率,保留两位小数。
返回的结果表按 percentage 的 降序 排序,若相同则按 contest_id 的 升序 排序。
返回结果如下示例所示。

思路:
版本一:
不进行连接,就单纯使用Register表,跟据id进行分组、二重排序,每个组都计算一遍Users表的数量,然后统计比率count(*)/(select count(*) from Users)。
版本二:
先对Users表进行统计id数量,将结果定义为一个新的表u,然后使用Register表对该表u进行交叉连接(因为没有匹配列,所以只能使用cross而不是inner),这样每行数据都自带一个总用户数量列,然后也是按照id分组、二重排序,最后计算比率count(*)/u.total,跟上面相比性能提高了不少,只需要计算一次用户数量即可
为什么不能使用avg(if())?
一开始我就是使用Register左连接Users,连接条件是id,以为一个赛事id没注册的用户会显示null,然而是错误的,如下图
select *
from Register r
left join Users u on r.user_id=u.user_id
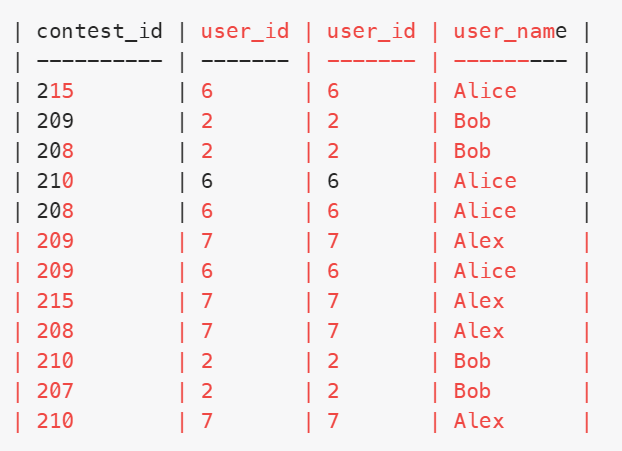
这是因为Register的user_id列里面的数据都是在Users表里面存在的,所以一定能匹配上,不会出现null,也就无法统计没注册的用户,因此avg(if(u.user_id is null,0,1))就失效了,统计的比率全是100%
代码:
版本一:
# 二重排序
select contest_id, round(count(*)/(select count(*) from Users) * 100, 2) percentagefrom Registergroup by contest_idorder by percentage desc, contest_id版本二:
# 二重排序+计算
select r.contest_id, round(100*count(*)/u.total, 2) percentagefrom Register rcross join (select count(*) total from Users) ugroup by r.contest_idorder by percentage desc, r.contest_id5.查询结果的质量和占比
题目:

将查询结果的质量 quality 定义为:
各查询结果的评分与其位置之间比率的平均值。
将劣质查询百分比 poor_query_percentage 定义为:
评分小于 3 的查询结果占全部查询结果的百分比。
编写解决方案,找出每次的 query_name 、 quality 和 poor_query_percentage。
quality 和 poor_query_percentage 都应 四舍五入到小数点后两位 。
以 任意顺序 返回结果表。
结果格式如下所示:

思路:
这里题目看着复杂,其实看样例基本就懂了,就是先按name分组,然后按要求计算平均值,第一个要求是先求每行数据的rating/position比值,然后按组来分别计算该值的平均值,第二个要求是求出每组的rating<3的行的比率,使用avg(if(...))即可
代码:
# 分组+求平均值+比率
select query_name, round(avg(rating/position),2) quality , round(100*avg(if(rating<3,1,0)),2) poor_query_percentagefrom Queries group by query_name 6.每月交易I
题目:

编写一个 sql 查询来查找每个月和每个国家/地区的事务数及其总金额、已批准的事务数及其总金额。
以 任意顺序 返回结果表。
查询结果格式如下所示。

思路:
这题看着输出的表的列挺多的,其实就是求同一个月且同一个国家的所有订单、通过的订单、所有金额、通过的金额。
因此只需要同时对时间、国家进行分组即可,但是这里要注意月份要先转换!
接下来就是求和、带条件求和
代码:
# 求和+二重分组
select date_format(trans_date,'%Y-%m') month,country,count(*) trans_count ,sum(if(state='approved',1,0)) approved_count,sum(amount) trans_total_amount,sum(if(state='approved',amount,0)) approved_total_amount from Transactionsgroup by country, month 7.即时食物配送II
题目:

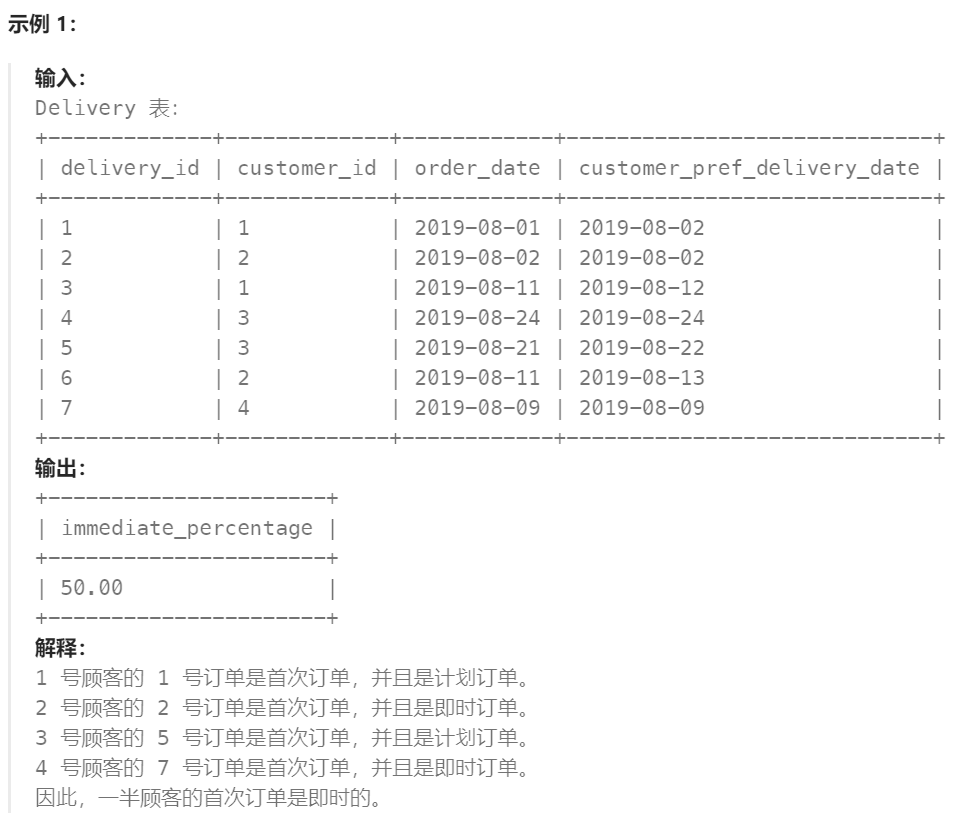
如果顾客期望的配送日期和下单日期相同,则该订单称为 「即时订单」,否则称为「计划订单」。
「首次订单」是顾客最早创建的订单。我们保证一个顾客只会有一个「首次订单」。
编写解决方案以获取即时订单在所有用户的首次订单中的比例。保留两位小数。
结果示例如下所示:
思路:
这里关键是找到每个用户的首次订单,找到后简单地求比率即可
首先我们在查询条件使用一个子查询来规范customer_id(用户id)和order_date(下单时间)的范围,这个子查询主要是查一次原表,跟据用户id进行分组,然后使用min()函数来找出最小的日期,也就是首次下单日期,这样就把用户id和下单时间范围确定下来了(现在的条件就是确定了每个用户的最早下单时间)。
剩下的就是一个avg(if())计算比率了(因为现在跟据这个条件查出来的都是每个用户的首次订单,只需判断是否为即时订单即可)
代码:
# 求比率+子查询
select round(avg(if(order_date=customer_pref_delivery_date,1,0))*100,2) immediate_percentagefrom Deliverywhere (customer_id,order_date) in (select customer_id, min(order_date)from Delivery group by customer_id)
8.游戏玩法分析IV
题目:

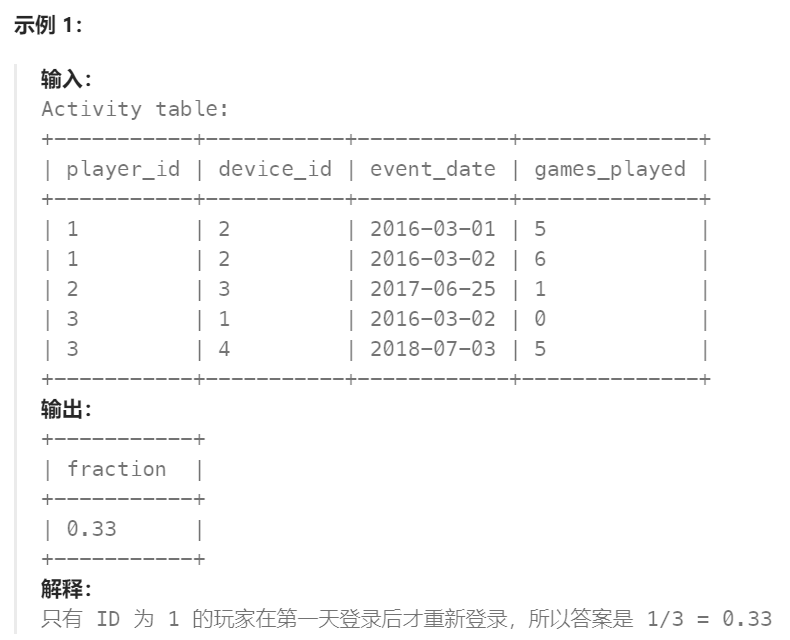
编写解决方案,报告在首次登录的第二天再次登录的玩家的 比率,四舍五入到小数点后两位。换句话说,你需要计算从首次登录后的第二天登录的玩家数量,并将其除以总玩家数。
结果格式如下所示:
思路:
这题主要是求首次登录游戏且第二天依然连续登录游戏的人的所占总用户的比率。
因此我们重点是要找到第二天依然登录的用户(多隔一天都不要),需要规范用户id和登录时间这两个字段,所以我们就使用一个子查询,来筛选出第二天登录的用户,比如date_add(min(event_date),interval 1 day),表达的意思是找到最早登录时间,然后+1,就是第二天的时间,如下(这些是每个用户首次登录的后一天,不是答案):
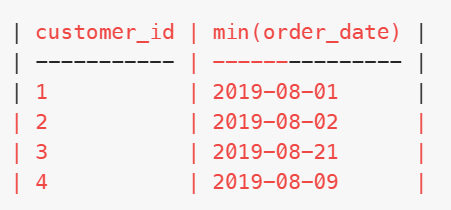
只要(player_id,event_date) in (...)在这个范围,那就是符合条件的,
范围已经确定了,然后就使用count(*)统计刚筛选出的总符合时间点的条数,再使用一个查询来统计用户的数量,这样一比就出答案了,如下(只有一个用户符合):

代码:
# 子查询+计算比率
select round(count(*)/(select count(distinct player_id) from Activity),2) fractionfrom Activitywhere (player_id,event_date) in (select player_id, date_add(min(event_date),interval 1 day) from Activitygroup by player_id)本篇文章到此结束,如果对你有帮助可以点个赞吗~
个人主页有很多个人总结的 Java、MySQL 等相关的知识,欢迎关注~