大模型微调(二):使微调保持稳定的策略
下面我们进入微调中最棘手、最活跃的部分之一:当模型开始出现问题迹象时,该怎么办?困惑度上升、损失函数震荡、过拟合,或者普遍感觉它“学错了东西”。
在某种程度上,这时训练不像雕塑,更像是园艺,修剪、调整、适量浇水。所有这些都不需要把植物拔掉再重新开始。
1. 学习率调整,倾听地形
最简单、最强大的杠杆是学习率 η。如果困惑度突然上升,通常意味着模型的更新过于激进,优化路线正在越过谷底,而不是平稳下降。
因此,训练器在检测到不稳定性时会动态降低学习率,这有时被称为学习率衰减或计划退火。
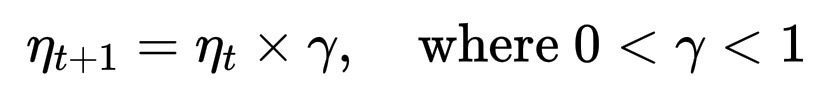
\eta_{t+1} = \eta_t \times \gamma, \quad \text{where } 0 < \gamma < 1
效果如何?模型的步长变小了,可以更平缓地探索曲率,无需重新开始训练就能稳定困惑度。
2. 梯度裁剪,控制情绪
当梯度爆炸时,较大的更新会导致损失飙升,训练器会对其进行裁剪,其中 \tau 是一个阈值。
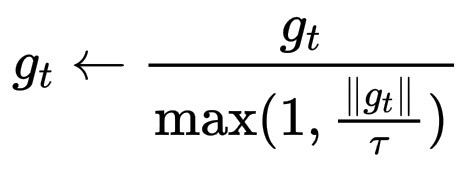
g_t \leftarrow \frac{g_t}{\max(1, \frac{\|g_t\|}{\tau})}
这就像老师说:“冷静下来,不要反应太强烈”,即使某些样本过于偏向某一方向,这也能保持训练的稳定性。
3. 提前停止和检查点,学习何时暂停
训练器会定期检查验证集困惑度。如果验证集困惑度开始上升,而训练集困惑度持续下降,那就是过拟合的明显迹象。这时,模型记忆力太差,而不是理解。
这时工程师们会提前暂停训练(在过拟合恶化之前)。或是,回滚到上一个有效的检查点,那里保存了参数 θ_t 快照。这有点像在迷宫中折返到路径仍然合理的最后一个位置。
4. 梯度累积和批次混合,在决策之前洞察更多
如果更新噪声过大,困惑度可能会剧烈波动。为了解决这个问题,训练器会在多个小批量数据上累积梯度,或者混合不同来源的数据,这样每次更新之前,模型都能拥有更广阔、更冷静的视角。这就像在行动之前多问几个朋友的意见,而不是轻易采纳第一个意见。
5. 自适应优化器,感知曲率
虽然我们无法计算 Hessian 矩阵,但像 Adam 和 Adafactor 这样的优化器会使用梯度的一阶和二阶矩来间接估计曲率:
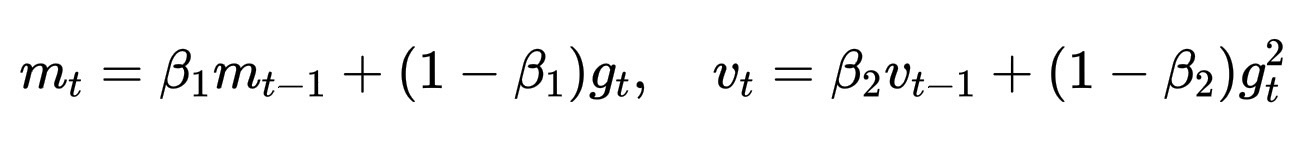
m_t = \beta_1 m_{t-1} + (1-\beta_1) g_t, \quad v_t = \beta_2 v_{t-1} + (1-\beta_2) g_t^2
然后,它们通过 \sqrt{v_t} 对更新进行归一化,沿着尖锐的维度采取较小的步长,沿着平坦的维度采取较大的步长,有效地“感知”地形的形状。这就是模型如何感知曲率,却从未见过完整的 Hessian 矩阵。
当困惑度上升时,模型的语言仿佛变得模糊不清,输出变得不确定,梯度下降迷失方向。于是,老师们降低了他们的声音(降低了学习率),稳定了模型的呼吸(削减了梯度),并提醒模型之前所知道的知识(恢复检查点)。一步步,迷雾消散了。