【AI论文】面向高效规划与工具使用的流程内智能体系统优化
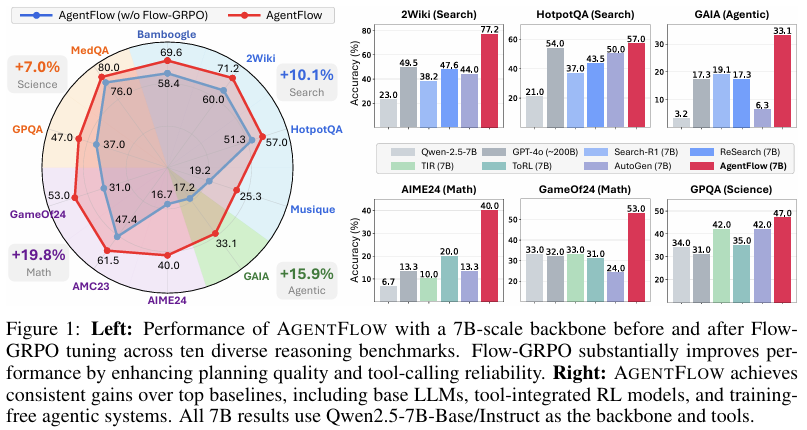
摘要:以结果为导向的强化学习推动了大型语言模型(LLMs)中的推理能力发展,但当前主流的工具增强方法仅训练一个单一、整体的策略,该策略在完整上下文中交替进行思考与工具调用;这种方式在处理长周期任务和多样化工具时扩展性较差,且难以泛化到新场景。智能体系统通过将任务分解到多个专业模块中,提供了一种有前景的替代方案,但大多数现有方法要么无需训练,要么依赖与多轮交互实时动态脱节的离线训练。我们提出了AgentFlow,这是一个可训练的、流程内的智能体框架,它通过动态演进的记忆机制协调四个模块(规划器、执行器、验证器、生成器),并直接在多轮交互循环中优化其规划器。为了在实时环境中进行在线策略训练,我们提出了基于流程的分组细化策略优化(Flow-based Group Refined Policy Optimization, Flow-GRPO),该方法通过将多轮优化转化为一系列可处理的单轮策略更新,解决了长周期、稀疏奖励下的信用分配问题。它将单一、可验证的轨迹级结果传播到每一轮,使局部规划器决策与全局成功对齐,并通过组归一化优势函数稳定学习过程。在十个基准测试中,采用70亿参数骨干模型的AgentFlow在搜索、智能体任务、数学和科学任务上的平均准确率分别比表现最优的基线模型提升了14.9%、14.0%、14.5%和4.1%,甚至超越了GPT-4o等更大规模的专有模型。进一步分析证实了流程内优化的优势,包括规划能力提升、工具调用可靠性增强,以及随着模型规模和推理轮数的增加呈现出的正向扩展性。Huggingface链接:Paper page,论文链接:2510.05592
研究背景和目的
研究背景:
近年来,大型语言模型(LLMs)在自然语言处理领域取得了显著进展,特别是在基于结果反馈的强化学习(RL)推动下,LLMs展现出了强大的推理能力。
然而,现有的工具增强型LLMs(TIR)通常训练一个单一的全局策略,该策略在多轮交互中交织思考和工具调用,这种方式在长程规划和工具多样性增加时,训练效果会变得不稳定,且在面对未见过的任务或工具时,推理能力的泛化性较弱。此外,传统的多模块智能体系统虽然能够将问题分解为子目标,并通过共享内存和模块间通信来协调处理,但这些系统大多未经训练,依赖手工设计的逻辑或提示,无法有效捕捉模块间协作的动态变化,也难以从下游任务的成功或失败中学习。
研究目的:
本研究旨在解决上述问题,提出一种名为AGENT FLOW的可训练、流式智能体系统框架。该框架通过协调四个专门模块(规划器、执行器、验证器和生成器)的工作,并直接在多轮循环中优化其规划器,以提高智能体在复杂推理任务中的表现。
具体研究目的包括:
- 提高规划质量:通过流式优化,使规划器能够生成更精确的子目标和工具调用决策。
- 增强工具调用可靠性:通过优化规划器,提高智能体在执行任务时调用工具的准确性和可靠性。
- 提升跨域泛化能力:使智能体能够在未见过的任务和工具上展现出更好的推理和泛化能力。
- 验证优化方法的有效性:通过实验验证流式优化方法(Flow-GRPO)在提升智能体性能方面的有效性。
研究方法
为了实现上述研究目的,本研究采用了以下研究方法:
1. AGENT FLOW框架设计:
AGENT FLOW框架由四个专门模块组成:规划器、执行器、验证器和生成器。这些模块通过共享的演化内存和工具集进行交互和协调。规划器负责生成子目标和选择工具,执行器调用所选工具并执行操作,验证器评估执行结果并决定是否需要进一步操作,生成器则根据查询和累积的记忆生成最终答案。
2. 流式优化方法(Flow-GRPO):
为了解决长程信用分配问题,本研究提出了Flow-based Group Refined Policy Optimization (Flow-GRPO)算法。
该算法将多轮RL问题转化为一系列可处理的单轮策略更新,通过广播一个可验证的轨迹级结果到每一轮,使局部规划器决策与全局成功对齐,并通过组归一化优势稳定学习过程。
3. 实验设计:
在十个基准测试集上评估AGENT FLOW的性能,包括知识密集型搜索任务(如Bamboogle、2Wiki、HotpotQA)、智能体推理任务(如GAIA)、数学推理任务(如AIME2024、AMC23、GameOf24)和科学推理任务(如GPQA、MedQA)。
实验中,所有模块均使用Qwen2.5-7B-Instruct模型,仅规划器通过Flow-GRPO进行训练。
研究结果
1. 性能提升:
AGENT FLOW在多个基准测试集上显著优于顶级基线模型,包括专门的工具集成推理模型和未经训练的智能体系统。例如,在7B骨干模型上,AGENT FLOW的平均准确率比第二好的基线模型高出14.9%(搜索任务)、14.0%(智能体任务)、14.5%(数学任务)和4.1%(科学任务),甚至超越了参数量大得多的专有模型如GPT-4o。
2. 工具调用可靠性增强:
Flow-GRPO优化显著提高了工具调用的可靠性。
例如,在MedQA任务上,Flow-GRPO优化后的模型减少了66.2%的Google搜索调用,同时增加了19.5%的特定网页搜索调用,显示出模型能够根据任务需求更智能地选择工具。
3. 规划质量提升:
通过分析具体案例,发现经过Flow-GRPO优化的AGENT FLOW能够更有效地制定初始计划,并在面对复杂任务时展现出更强的适应性和鲁棒性。
例如,在解决一个涉及多步推理的物理问题时,优化后的模型能够正确识别核心挑战并应用适当的物理公式进行计算。
研究局限
尽管AGENT FLOW在多个方面展现出显著优势,但本研究仍存在以下局限:
1. 训练数据依赖:
AGENT FLOW的性能高度依赖高质量的训练数据。
在数据稀缺或质量不高的情况下,模型的性能可能会受到影响。
2. 模块间交互复杂性:
虽然AGENT FLOW通过共享内存和工具集实现了模块间的交互,但这种交互方式在面对更复杂的任务时可能会变得难以管理,需要更精细的协调机制。
3. 泛化能力验证不足:
尽管AGENT FLOW在多个基准测试集上表现出色,但其在真实世界复杂任务上的泛化能力仍有待进一步验证。
未来研究方向
针对上述局限,未来研究可从以下几个方面展开:
1. 探索更高效的训练方法:
研究如何在数据稀缺或质量不高的情况下,通过半监督学习、自监督学习或迁移学习等方法,提高AGENT FLOW的训练效率和性能。
2. 优化模块间交互机制:
设计更高效的模块间通信和协调机制,如引入注意力机制或图神经网络,以更好地捕捉模块间的依赖关系和动态变化。
3. 增强泛化能力:
通过引入更复杂的真实世界任务和数据集,进一步验证和提升AGENT FLOW的泛化能力。同时,研究如何将AGENT FLOW应用于跨域推理任务,如从文本到图像的推理。
4. 结合其他先进技术:
探索将AGENT FLOW与知识图谱、符号推理等先进技术相结合,以构建更强大的混合推理系统。
同时,研究如何将AGENT FLOW应用于实际场景,如智能助手、自动驾驶等。