【表格对比分析】Java集合体系、Java并发编程、JVM核心知识、Golang go-zero微服务框架
文章目录
- 一、Java集合体系
- 1. List接口(有序可重复)
- 2. Set接口(无序不可重复)
- 3. Map接口(键值对)
- 二、Java并发编程
- 1. 锁机制对比及选择
- 2. 线程池参数配置及实践
- 3. 线程通信与安全问题
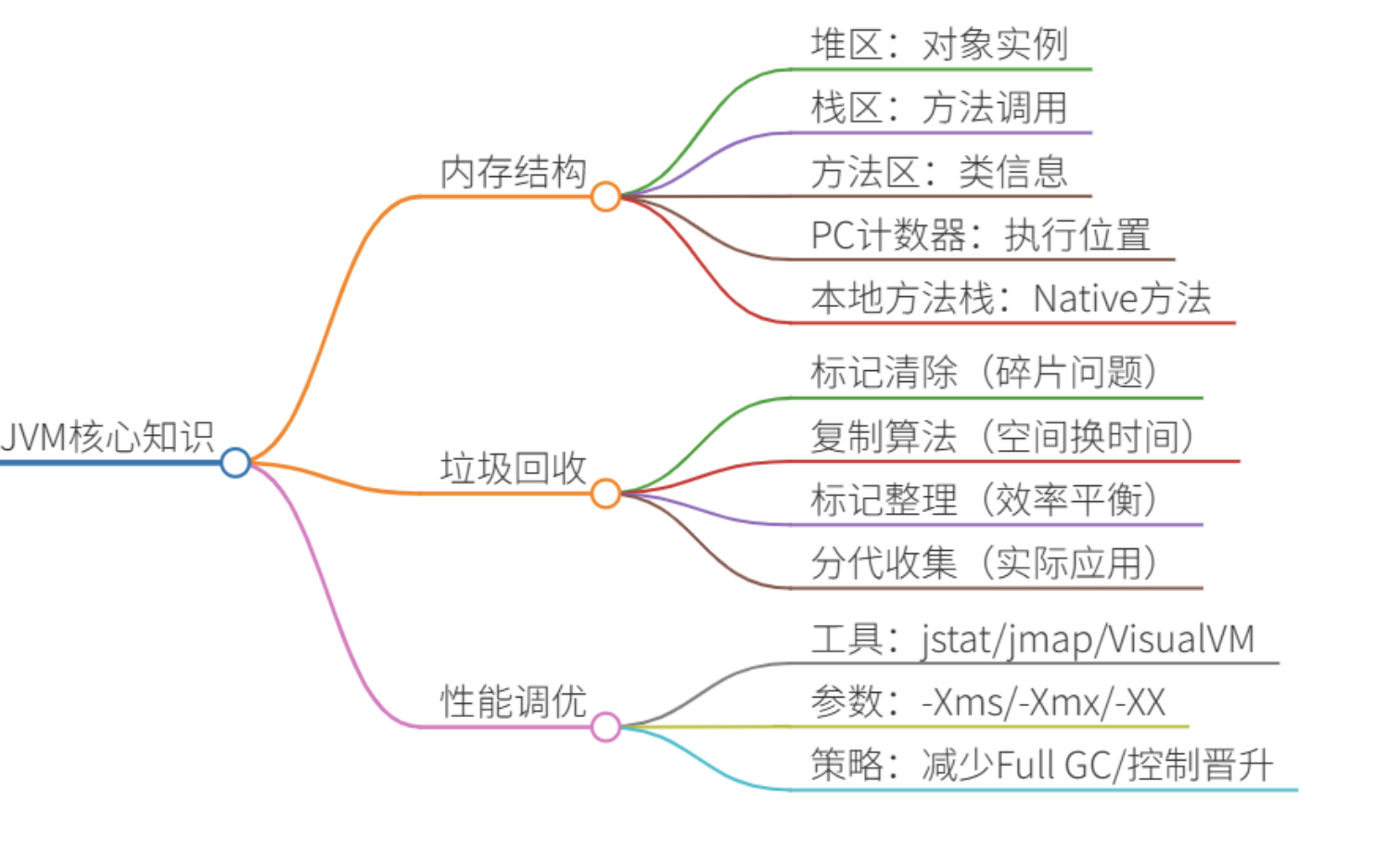
- 三、JVM核心知识
- 1. 运行时数据区及OOM案例
- 2. 垃圾收集器对比及选择
- 3. JVM调优步骤及工具
- 四、Golang go-zero微服务框架
- 1. 核心组件及作用
- 2. 开发流程及注意事项
- 总结
若对您有帮助的话,请点赞收藏加关注哦,您的关注是我持续创作的动力!有问题请私信或联系邮箱:funian.gm@gmail.com
一、Java集合体系
1. List接口(有序可重复)
| 实现类 | 底层结构 | 初始容量 | 扩容机制 | 核心操作复杂度 | 线程安全 | 适用场景 |
|---|---|---|---|---|---|---|
| ArrayList | 动态数组 | 10 | 容量不足时,新容量=旧容量*1.5(JDK8) | 随机访问(O(1))、中间增删(O(n)) | 否 | 读多写少、需随机访问 |
| LinkedList | 双向链表 | 无 | 无(链表节点动态创建) | 随机访问(O(n))、中间增删(O(1)) | 否 | 写多(中间增删频繁)、队列操作 |
| Vector | 动态数组 | 10 | 容量不足时,新容量=旧容量*2 | 同ArrayList(但加锁开销) | 是 | 需线程安全但性能要求低 |
| CopyOnWriteArrayList | 数组(写时复制) | 无 | 写操作时复制新数组(旧数组不变) | 读(O(1))、写(O(n)) | 是 | 读极多写极少(如配置缓存) |
开发注意事项:
-
ArrayList:
- 初始化时指定容量(如
new ArrayList<>(100)),避免频繁扩容(扩容需复制数组,成本高)。 - 避免在循环中使用
remove(int)(索引会前移,可能漏删),推荐用迭代器Iterator.remove()。 - 超大数组(如百万级元素)慎用,可能导致OOM(堆内存不足)。
- 初始化时指定容量(如
-
LinkedList:
- 不适合随机访问(如
get(1000)需遍历),需随机访问时优先用ArrayList。 - 作为队列使用时,优先用
offer()/poll()(不抛异常)替代add()/remove()(抛异常)。
- 不适合随机访问(如
-
线程安全选择:
- 读多写少用
CopyOnWriteArrayList(写操作加锁,读无锁)。 - 高并发读写用
Collections.synchronizedList()(全量加锁,性能一般)或ReentrantLock手动控制。
- 读多写少用
2. Set接口(无序不可重复)
| 实现类 | 底层结构 | 去重依据 | 核心操作复杂度 | 线程安全 | 适用场景 |
|---|---|---|---|---|---|
| HashSet | 哈希表(HashMap封装) | hashCode()+equals() | 增删查(O(1)) | 否 | 无需排序、去重场景 |
| LinkedHashSet | 哈希表+双向链表 | 同HashSet | 增删查(O(1)) | 否 | 需保留插入顺序的去重场景 |
| TreeSet | 红黑树(TreeMap封装) | 自然排序或Comparator | 增删查(O(log n)) | 否 | 需排序的去重场景(如排行榜) |
| ConcurrentSkipListSet | 跳表 | 同TreeSet | 增删查(O(log n)) | 是 | 高并发排序去重场景 |
开发注意事项:
-
去重关键:
- 存储自定义对象时,必须重写
hashCode()和equals(),且逻辑一致(如equals()为true时,hashCode()必须相等)。 - TreeSet依赖排序逻辑去重(
compareTo()返回0视为重复),需保证排序逻辑与业务一致。
- 存储自定义对象时,必须重写
-
性能对比:
- 无排序需求时,HashSet性能优于TreeSet(O(1) vs O(log n))。
- 高并发场景用
ConcurrentSkipListSet,避免用synchronizedSet(性能差)。
3. Map接口(键值对)
| 实现类 | 底层结构 | key特性 | 核心操作复杂度 | 线程安全 | 适用场景 |
|---|---|---|---|---|---|
| HashMap | 哈希表(数组+链表/红黑树) | 无序,允许1个null key | 增删查(O(1)) | 否 | 通用键值对存储(如缓存) |
| LinkedHashMap | 哈希表+双向链表 | 保留插入/访问顺序 | 同HashMap | 否 | LRU缓存(accessOrder=true) |
| TreeMap | 红黑树 | 有序(排序逻辑),无null key | 增删查(O(log n)) | 否 | 需排序的键值对(如区间查询) |
| Hashtable | 哈希表 | 无序,无null key/value | 同HashMap(加锁) | 是 | 淘汰(被ConcurrentHashMap替代) |
| ConcurrentHashMap | 分段锁(JDK7)/CAS+同步(JDK8) | 无序,允许null value | 增删查(接近O(1)) | 是 | 高并发键值对存储 |
开发注意事项:
-
HashMap:
- 初始容量建议设为2的幂(如16、32),减少哈希冲突(哈希表长度为2^n时,取模运算可优化为位运算)。
- 避免存储大量相同hashCode的key(如String前缀相同),会导致链表过长(红黑树转换阈值为8),性能退化至O(n)。
- 遍历过程中禁止修改结构(如
put/remove),否则抛ConcurrentModificationException(迭代器快速失败机制)。
-
LinkedHashMap:
- 启用LRU(最近最少使用)策略时,
accessOrder=true,每次访问(get)会将节点移至链表尾部,适合缓存淘汰。
- 启用LRU(最近最少使用)策略时,
-
ConcurrentHashMap:
- JDK8中
size()为近似值(无需全量加锁),精确计数需用mappingCount()。 - 高并发下
put操作可能触发扩容,但不阻塞读(读操作无锁)。
- JDK8中
二、Java并发编程
1. 锁机制对比及选择
| 锁类型 | 加解锁方式 | 公平性支持 | 中断支持 | 条件变量(Condition) | 性能(无竞争) | 性能(高竞争) | 适用场景 |
|---|---|---|---|---|---|---|---|
| synchronized | JVM自动 | 非公平 | 不支持 | 不支持(依赖wait/notify) | 高(偏向锁优化) | 低(重量级锁) | 简单同步(如单例、简单计数器) |
| ReentrantLock | 手动(try-finally) | 支持(构造参数) | 支持 | 支持(多条件) | 中(轻量级锁) | 中(比synchronized好) | 复杂同步(如超时获取、中断) |
| ReentrantReadWriteLock | 手动 | 支持 | 支持 | 支持 | 高(读共享) | 中 | 读多写少(如缓存、配置) |
| StampedLock | 手动 | 非公平 | 支持 | 支持 | 极高(乐观读) | 高 | 高并发读(读远多于写) |
开发注意事项:
-
synchronized最佳实践:
- 锁粒度越小越好(如锁对象而非方法,避免锁住整个对象)。
- 避免锁String/Integer等常量(常量池复用导致锁范围扩大),推荐用
new Object()作为锁对象。
-
ReentrantLock使用规范:
- 必须在
try-finally中释放锁(lock.unlock()),避免死锁。 - 公平锁性能低于非公平锁(需排队),非特殊需求用非公平锁。
- 必须在
-
StampedLock风险:
- 乐观读(
tryOptimisticRead())需校验版本戳(validate(stamp)),失败需升级为悲观读,否则可能读取脏数据。
- 乐观读(
2. 线程池参数配置及实践
| 参数 | 含义 | 配置建议(Web服务) | 极端值风险 |
|---|---|---|---|
| corePoolSize | 核心线程数(常驻) | CPU核心数*2(IO密集型)/CPU核心数(计算密集型) | 过小:任务排队过长;过大:线程切换开销大 |
| maximumPoolSize | 最大线程数 | 核心线程数+临时线程数(视队列长度而定) | 过大:OOM(线程栈内存累加) |
| keepAliveTime | 临时线程空闲超时时间 | 30秒(IO密集型)/5秒(计算密集型) | 过短:频繁创建临时线程;过长:资源浪费 |
| workQueue | 任务队列 | bounded队列(如ArrayBlockingQueue,容量1000) | 无界队列(如LinkedBlockingQueue):OOM |
| threadFactory | 线程工厂 | 自定义(命名线程+设置daemon=false) | 线程名混乱:排查问题困难 |
| RejectedExecutionHandler | 拒绝策略 | 非核心服务用DiscardOldestPolicy;核心服务用CallerRunsPolicy(降级) | AbortPolicy:直接抛异常中断服务 |
开发注意事项:
-
禁止使用Executors工具类:
FixedThreadPool/SingleThreadPool用无界队列,任务过多会OOM。CachedThreadPool最大线程数无界,高并发下创建大量线程导致OOM。
-
线程池监控:
- 自定义线程池需集成监控(如暴露
getActiveCount()/getQueue().size()指标),避免任务积压。 - 结合业务峰值调整参数(如秒杀场景临时调大maximumPoolSize)。
- 自定义线程池需集成监控(如暴露
-
任务特性适配:
- 长耗时任务(如IO操作):核心线程数可设大,队列容量适中。
- 短耗时任务(如计算):核心线程数接近CPU核心数,队列容量可设大。
3. 线程通信与安全问题
| 通信方式 | 实现 | 注意事项 | 常见错误 |
|---|---|---|---|
| wait()/notify() | 基于对象监视器(synchronized) | 1. 必须在synchronized块中调用 2. wait()需在循环中校验条件(防止虚假唤醒) | 1. 未加锁调用wait()(抛IllegalMonitorStateException) 2. 用if而非while判断条件(虚假唤醒后逻辑错误) |
| Condition | 基于Lock接口 | 1. 需关联Lock(lock.newCondition())2. 支持多条件队列(如生产者/消费者分离) | 未释放锁调用await()(导致死锁) |
| Thread.join() | 等待线程终止 | 可指定超时时间(避免无限等待) | 循环调用join()导致性能问题 |
线程安全常见问题及解决:
- 竞态条件:多线程读写共享变量(如
i++非原子操作)→ 用AtomicInteger(CAS)或加锁。 - 死锁:线程相互持有对方需要的锁 → 按固定顺序获取锁、设置超时时间(
tryLock(timeout))。 - 内存可见性:线程看不到其他线程修改的变量 → 用
volatile(禁止指令重排序+强制刷新缓存)或加锁。
三、JVM核心知识
1. 运行时数据区及OOM案例
| 区域 | 存储内容 | OOM触发场景 | 排查工具/参数 |
|---|---|---|---|
| 虚拟机栈 | 方法栈帧(局部变量、操作数栈) | 1. 递归调用过深(StackOverflowError) 2. 线程过多(栈内存总和超堆) | -Xss(设置栈大小,默认1M)、jstack |
| 堆 | 对象实例、数组 | 1. 大对象(如100MB数组) 2. 内存泄漏(如静态集合未清理) | -Xms/-Xmx(堆大小)、jmap + MAT |
| 方法区(元空间) | 类信息、常量、静态变量 | 1. 动态生成大量类(如CGLIB代理) 2. 常量池过大 | -XX:MetaspaceSize/-XX:MaxMetaspaceSize、jinfo |
| 程序计数器 | 字节码行号 | 无(唯一不会OOM的区域) | - |
开发注意事项:
-
堆内存优化:
- 避免创建超大对象(如一次性加载10万条数据到内存),分批处理。
- 排查内存泄漏:用MAT分析堆快照,找“存活但无用”的对象(如未关闭的连接、静态List缓存未清理)。
-
元空间配置:
- 生产环境必须设置
-XX:MaxMetaspaceSize(如256M),否则可能耗尽物理内存(元空间默认无上限)。 - 框架(如Spring)会动态生成类,需预留足够元空间(避免频繁Full GC)。
- 生产环境必须设置
2. 垃圾收集器对比及选择
| 收集器 | 分代收集 | 回收算法 | STW时间 | 内存支持 | 适用场景 | JVM参数 |
|---|---|---|---|---|---|---|
| SerialGC | 是(年轻代+老年代) | 复制(年轻代)+标记-整理(老年代) | 长(单线程) | 小堆(<1GB) | 客户端应用(如桌面程序) | -XX:+UseSerialGC |
| ParallelGC | 是 | 同SerialGC | 中(多线程) | 中小堆(<10GB) | 批处理任务(吞吐量优先) | -XX:+UseParallelGC |
| CMS | 是 | 标记-清除(老年代) | 短(并发) | 中堆(10-40GB) | Web服务(响应时间优先) | -XX:+UseConcMarkSweepGC |
| G1 | 逻辑分代 | 区域化+标记-整理 | 短(可控) | 大堆(4GB-100GB) | 通用场景(兼顾吞吐和延迟) | -XX:+UseG1GC |
| ZGC | 不分代 | 标记-复制 | 毫秒级 | 超大堆(TB级) | 高并发低延迟(如金融交易) | -XX:+UseZGC(JDK11+) |
开发注意事项:
-
GC日志必开:
- 配置
-Xlog:gc*:file=gc.log:time,level,tags,记录GC时间、耗时、内存变化,便于分析问题。
- 配置
-
STW时间控制:
- Web服务STW需控制在100ms内(用户无感知),推荐G1(
-XX:MaxGCPauseMillis=50)。 - 超大堆(如50GB以上)用ZGC/Shenandoah,避免CMS的碎片化和G1的停顿过长。
- Web服务STW需控制在100ms内(用户无感知),推荐G1(
-
年轻代大小调整:
- 年轻代过小:Minor GC频繁;过大:老年代变小,Full GC频繁。通常设为堆的1/3~1/2。
3. JVM调优步骤及工具
| 调优阶段 | 目标 | 核心工具 | 关键指标 |
|---|---|---|---|
| 监控 | 发现性能瓶颈 | jstat(GC统计)、VisualVM(可视化) | 1. GC频率(Minor GC>1次/秒需优化) 2. STW时间(>100ms需优化) |
| 分析 | 定位问题原因 | jmap(堆快照)、jstack(线程栈)、MAT(内存分析) | 1. 大对象占比 2. 线程阻塞状态 3. 类加载数量 |
| 优化 | 调整参数/代码 | JVM参数调整、代码重构 | 1. 降低GC频率 2. 减少STW时间 3. 消除内存泄漏 |
实战调优案例:
-
案例1:频繁Minor GC
现象:每秒多次Minor GC,年轻代内存骤升骤降。
原因:创建大量短期对象(如循环中new对象)。
优化:1. 扩大年轻代(-Xmn);2. 对象池复用(如StringBuilder)。 -
案例2:OOM(Java heap space)
现象:堆内存溢出,日志显示OutOfMemoryError。
原因:内存泄漏(如静态Map缓存未清理)。
优化:1. 用jmap -dump生成快照;2. MAT分析泄漏对象;3. 修复缓存清理逻辑。
四、Golang go-zero微服务框架
1. 核心组件及作用
| 组件 | 作用 | 关键特性 | 依赖工具/服务 |
|---|---|---|---|
| API层 | 处理HTTP请求,定义接口契约 | 基于api IDL自动生成路由、参数校验代码 | goctl(代码生成工具) |
| RPC层 | 内部服务通信(基于gRPC) | 基于proto IDL生成客户端/服务端代码,支持负载均衡 | etcd(服务发现)、protoc |
| 中间件(Middleware) | 横切逻辑(日志、限流、认证) | 可自定义,支持链式调用 | - |
| 配置中心 | 动态配置管理 | 支持etcd/nacos,配置热更新 | etcd/nacos |
| 服务治理 | 限流、熔断、降级、超时控制 | 基于令牌桶(限流)、熔断器模式(熔断) | - |
| 监控告警 | 指标收集与可视化 | 集成Prometheus+Grafana,默认暴露/metrics | Prometheus、Grafana |
2. 开发流程及注意事项
| 开发阶段 | 核心步骤 | 注意事项 |
|---|---|---|
| IDL设计 | 1. 定义api/proto文件(接口、数据结构) 2. 生成骨架代码( goctl api/proto go) | 1. 字段名用驼峰(与JSON保持一致) 2. 必选参数加 required,避免后续兼容问题 |
| 业务实现 | 1. 在handler(API)/logic(RPC)中实现逻辑 2. 依赖注入(如数据库、缓存) | 1. 业务逻辑与框架代码分离(便于测试) 2. 用 go-zero的xorm/sqlx操作数据库,避免原生SQL |
| 服务治理配置 | 1. 限流:Limit: 100(每秒100请求)2. 熔断: Timeout: 300ms | 1. 限流值需压测确定(避免过严/过松) 2. 熔断阈值设置合理(如失败率>50%触发) |
| 部署与监控 | 1. 部署etcd(服务发现)、Prometheus 2. 配置Grafana面板 | 1. 服务名唯一(避免etcd注册冲突) 2. 监控关键指标(QPS、延迟、错误率) |
常见问题及解决方案:
- 代码生成失败:检查IDL语法(如字段类型错误)、goctl版本(需与框架匹配)。
- 服务调用超时:1. 调整
Timeout配置;2. 排查下游服务性能(是否慢查询)。 - 限流不生效:确认配置文件中
Limit是否正确,且中间件已注册(s.Use(middleware.Limit()))。
总结
各技术领域的核心在于“场景匹配”:
- 集合选择需权衡读写性能、线程安全需求;
- 并发编程需控制锁粒度、合理配置线程池;
- JVM调优需结合业务监控,避免盲目调参;
- go-zero开发需遵循IDL规范,充分利用其内置治理能力。
实际开发中,需结合压测和监控数据动态优化,而非依赖固定模板。