视频生成的背后机理:Wan2技术报告分析
引言
之前写过图像生成中 Diffusion 相关的原理解读,本文将更进一步,将视角瞄向视频生成领域,主要解决三个问题:
- 视频生成是怎么做的,基础模型架构是什么?
- 视频生成需要准备怎么样的数据?
- 如何让生成的视频既有画面又有声音?
视频生成模型现状
想要了解视频生成的基础架构,首先看最出圈的Sora。然而,作为闭源Sora商用项目,在其技术博客[1]没有披露模型架构和训练信息。
在 Github 上,有两个开源项目试图用开源的方式还原 Sora 的效果,分别是 HPC-AI 主导的 Open-Sora[2] 和 北京大学(PKU) 主导的 Open-Sora-Plan[3]。
然而,尽管这两个项目公开了源码,但技术报告写得相对较简略,无法从有限的信息中一窥全貌。
于是转向 LMArena 竞技场[4],看看文生视频领域当前的排行现状,结果如下图所示:
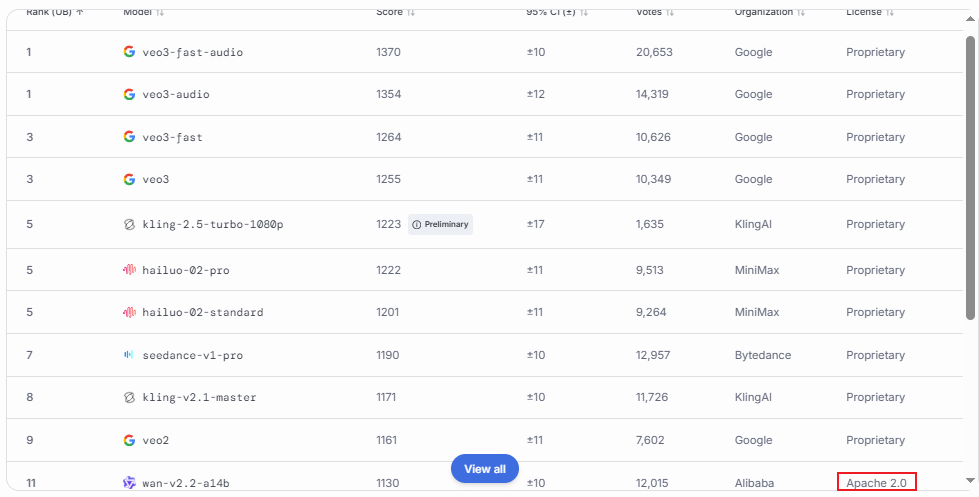
图中发现,veo3一骑绝尘,可灵、海螺、字节的模型紧随其后,然而这些模型都是闭源的,而开源的第一名是阿里的wan-v2.2-a14b。
阿里的 Wan2.2[5] 除了代码和模型开源之外,其技术报告[6]也写得比较详细,本文来详细看一下。
由于 Wan2.2 在 Wan2.1 的基础上,没有比较大的架构改动,因此两者所链接的是同一份 Wan2.1 的技术报告。
视频生成模型相关工作
基于扩散的视频生成模型通常建立在Stable Diffusion架构之上,主要包含三个关键模块:
- 将原始视频映射到潜在空间的自动编码器
- 提取文本嵌入的文本编码器
- 通过扩散模型优化以学习视频潜在分布的神经网络
自动编码器方面,最初普遍用的是 VAE,之后也开始采用 VAE 的改进版,即 VQ-VAE 和 VQGAN,取得了更好的重建和压缩效果。
文本编码器方面,常规做法是采用 T5 和 CLIP 结合使用,也有一些人采用多模态大模型实现文本嵌入与视觉特征间更鲁棒的对齐。
神经网络方面,最初是 U-Net 加上时间维度来适配视频生成。之后,完全依赖Transformer模块的 DiT 超越了 U-Net,成为了新一代基础模型。目前,其进而衍生出两种变体:使用交叉注意力处理文本嵌入的原始 DiT 和 将文本嵌入与视觉嵌入拼接进行全注意力处理的 MM-DiT。
在满足基础生成模型的要求后,还存在一些下游任务,包括修复、编辑、可控生成、帧参考生成,主要采用的方案是基于适配器和类 ControlNet 架构。
数据集构建
为了构建高质量的图像和视频数据集,作者团队在预训练数据和后训练数据上分别应用了不同的策略。
预训练数据筛选
预训练数据筛选采用了以下方式进行:
- 文本检测:用轻量级OCR检测器量化文本覆盖率,有效排除文字元素过多的视频与图像
- 美学评估:使用业界广泛采用的LAION-5B美学分类器对图像进行初步质量评估,快速过滤低质量数据
- 安全评估:使用内部安全评估模型,计算NSFW评分,评估并过滤不当内容
- 水印与标识检测:检测视频或图像是否包含水印与标识,并在训练过程中对这些元素进行裁剪处理
- 黑边检测:利用基于启发式的检测方法自动裁剪多余黑边,确保聚焦于内容核心区域
- 过曝检测:经过训练的专家分类器会评估并过滤色调分布异常的数据,保证训练数据集具有最佳视觉品质
- 合成图像检测:即使仅混入少量生成图像(< 10%)也会显著降低模型性能。因此训练了专家分类器来过滤这些"污染性"图像
- 模糊检测:通过内部开发的模型量化模糊分数,清除视觉模糊内容
- 时长与分辨率:强制要求视频时长必须超过4秒,并应用分辨率阈值以过滤低质量数据
- 视觉质量:通过聚类和评分(人工打分+专家评估模型打分)的方式来判别视觉质量,筛选高质量数据
- 运动质量:通过人工判断,移除摄影机晃动或手持手机拍摄的晃动镜头
- 视觉文本数据扩充:为了提升视频的文字生成质量,采用在纯白背景上渲染汉字的方式进行数据合成,并进一步筛选大量含文本图像,通过Qwen2-VL实现图像中文本的自然描述
经过上述方式处理,预训练数据的规模达到数十亿量级,作者未披露具体数值。
后训练数据集构建
后训练阶段的核心目标是提升生成视频的视觉保真度与运动动态效果,为此,分别对图像数据和视频数据做如下处理:
图像数据:基于专家模型,预测画质、构图和细节的综合分数在20%的图像,同时通过人工方式从多类别数据源中采集顶级质量图像,填补数据集中缺失的概念,以增强模型的泛化能力,通过此方式,得到数百万张精选图像。
视频数据:和图像数据的筛选方式类似,同时补充运动质量评估维度的筛选,整体从技术、动物、艺术、人类、车辆等12个主要类别中筛选数据。
密集视频描述
虽然前面筛选出的视频是有一些基本描述信息的,但是信息比较简略。
DALL-E 3的研究表明,通过使用高度描述性的生成式视觉标注进行训练,能显著提升视觉生成模型遵循提示词的能力。
因此,作者又额外开发了内部标注模型,为数据集中的每张图像和视频生成密集标注。
内部标注模型主要包括事件(Event)、动作(Action)、镜头角度(Camera Angle)等描述,具体如下图所示。
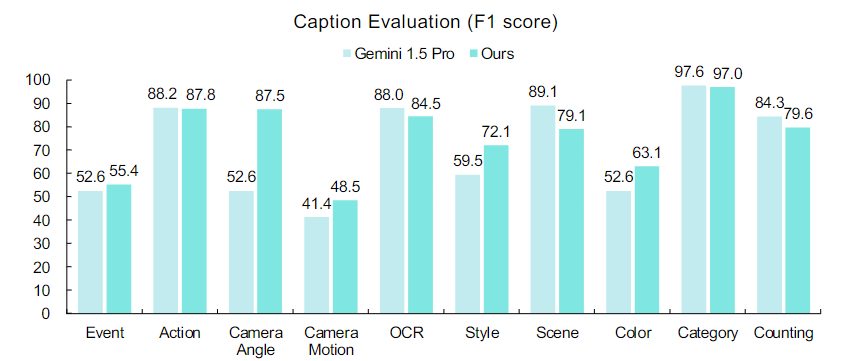
标注模型的整体性能与 Gemini 1.5 Pro 大致相当。
模型结构
模型结构按照相关工作的划分,分成自动编码器、文本编码器、神经网络
时空变分自编码器
为实现高维像素空间与低维潜在空间之间的双向映射,作者构建了时空变分自编码器(Wan-VAE),结构如下图所示:
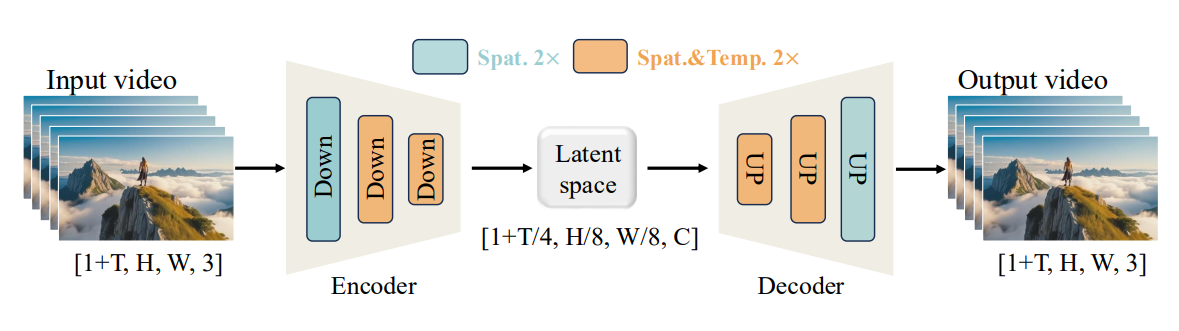
对于输入视频帧,Wan-VAE 将其时间维度T压缩成1/4,空间维度H、W,压缩成 1/8,通道数C拓展至16。
在架构层面,为了保证时序因果性,将 GroupNorm 层替换成 RMSNorm 层,整个模型的参数量为 127M。
完整模型结构
完整的 Wan 模型如下图所示,上一节的 Wan-VAE 就是下图中 Wan-Encoder 和 Wan-Decoder 的结构。
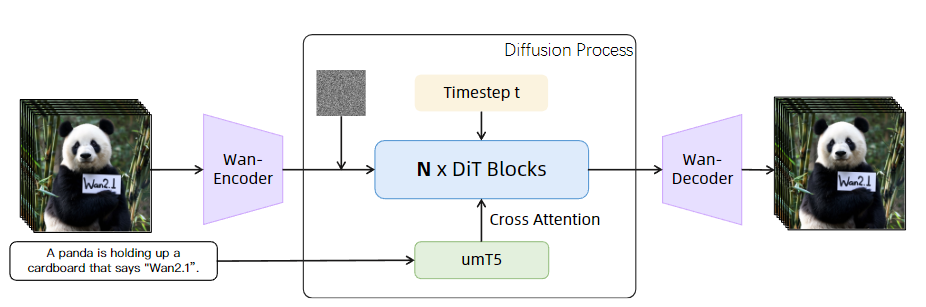
文本编码器是直接用的umT5,没有特殊改进,其可以有效理解中英文,文字通过该编码器,编码成 T-Tokens。
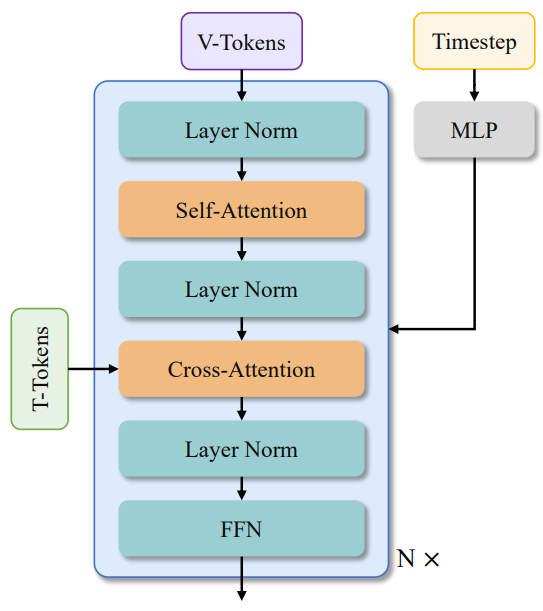
神经网络用的是 DiT 的结构,具体如下图所示,输入视频帧使用(1,2,2)的3D卷积再展平形成(B,L,D)形状的 V-Tokens。
B表示批处理大小(Batch),L = (1 + T/4) × H/16 × W/16,表示序列长度,D表示潜在维度。
文本信息通过交叉注意力的方式(Cross-Attention)实现嵌入。
下游应用
下游应用指的是在 Wan 这套框架的基础上,进一步进行拓展,以满足不同任务。
图像生成视频
基础模型的任务形式是输入文本,输出视频。
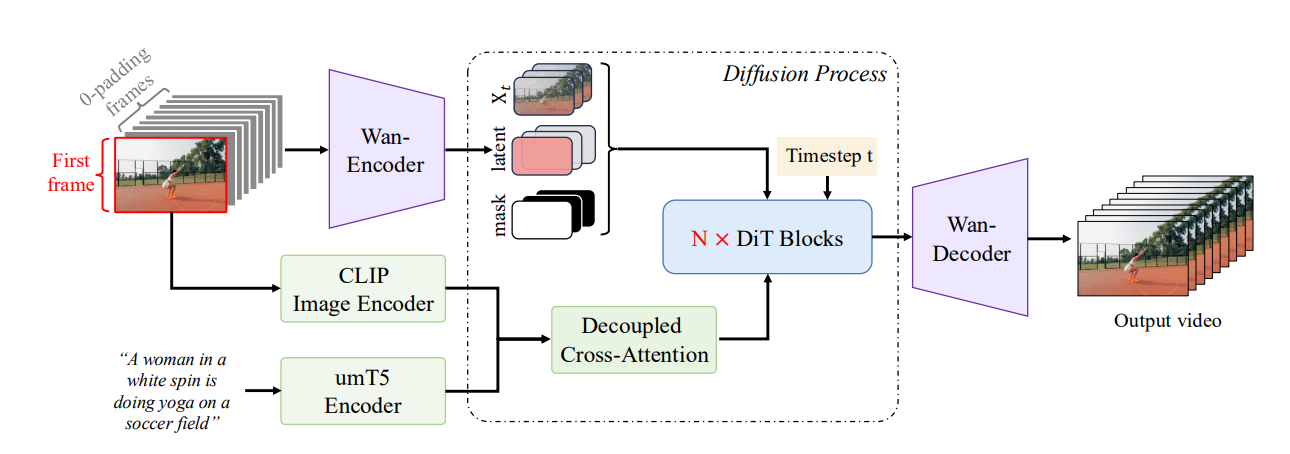
图像生成视频(I2V)任务是,输入文本和参考图,输出视频。
具体做法是,将参考图像作为视频的第一帧,同时利用 CLIP 从图像中提取特征表示,使用解耦交叉注意力机制将其结合文本的特征表示注入到Dit模型。
视频编辑
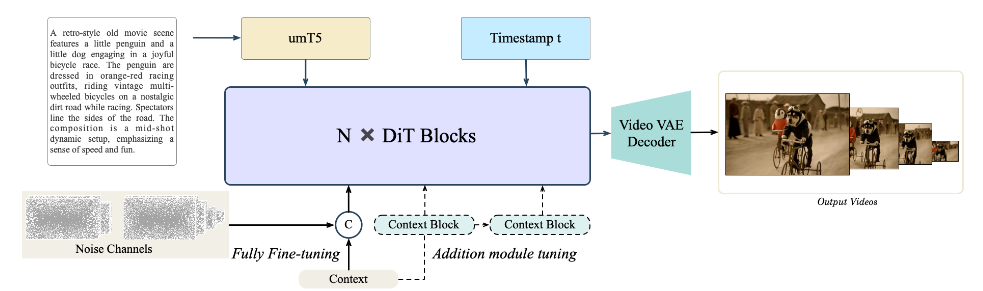
视频编辑(VACE)是指对视频的内容进行可控编辑,比如,输入一段视频,然后用文字对其内容进行编辑,再输出编辑完的视频。
这里作者没有披露更多细节,只是放了一个结构,意思是通过额外添加的模块对参数进行微调。
音频生成
音频生成(V2A)指的是输入视频,文本,视频自带的声音,生成环境音和背景音乐。
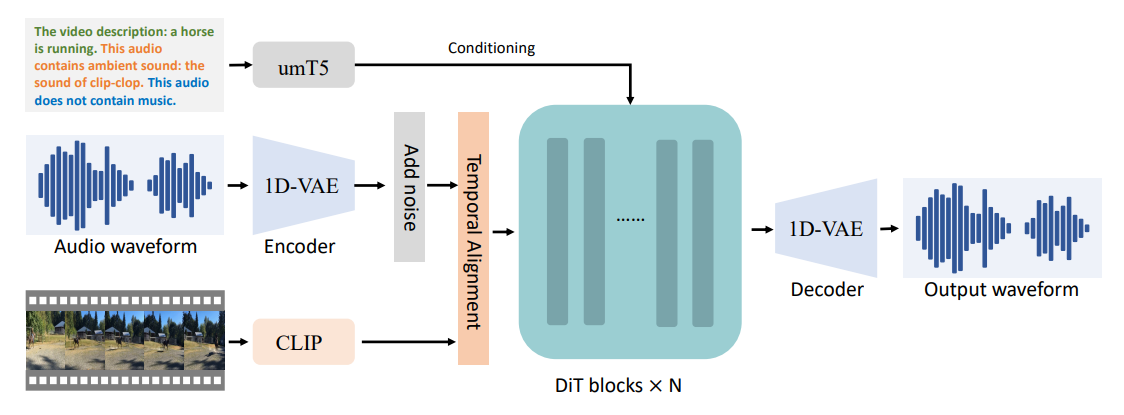
目前,该模型最长可生成12秒的音频。
其它任务
其它任务文章描述得比较简略,这里顺带一提,还包括:
- 文生图:根据输入文本生成图像
- 视频个性化:生成与用户提供的参考保持身份一致性的视频
- 相机运动控制:利用相机轨迹精确匹配视频的运动与视角
- 实时视频生成:通过流式管道适配和推理加速等策略实现视频实时生成
总结
Wan2 不仅是一个模型,而是一套模型基础框架,在此框架上,可以衍生出各种下游任务。
因此,有的视频生成网页,上传参考图或不上传参考图,背后所用的完全是不同的模型管线。
此外,从这篇报告中还能获取以下信息:
- 视频生成的基础架构就是三部分组合,视频生成是在图像生成的基础上,引入时间维度信息,本质上仍然是扩散模型,这就能解释几乎所有生成的视频都有难以避免的噪点闪烁。
- 训练视频生成模型,高质量数据集是关键,需要花费大量的时间进行数据筛选和构建,一些低质量的数据,例如生成数据,容易显著降低模型性能。
- 数据集不仅是视频,也可以是图像,图像可以视作时间步为1的视频。
- Wan2.1的模型参数包括14B和1.3B两个版本,相比于语言模型,视频模型的参数量很难堆上去,因为视频所占用的Token比文本高很多。VAE 是一种压缩取巧的方式,但压缩不可避免地会带来信息损失。如果算力得到进一步扩充,可能会出现用更少损失的方式生成高保真的视频。
参考
[1] Sora Blog - Video generation models as world simulators:https://openai.com/index/video-generation-models-as-world-simulators
[2] Open-Sora:https://github.com/hpcaitech/Open-Sora
[3] Open-Sora-Plan:https://github.com/PKU-YuanGroup/Open-Sora-Plan
[4] Text-to-Video Arena:https://lmarena.ai/leaderboard/text-to-video
[5] Wan2.2:https://github.com/Wan-Video/Wan2.2
[6] https://arxiv.org/pdf/2503.20314