ptmalloc原理(简)
一. 简单概述
学习内存管理肯定是绕不开malloc、free这两位的,所以就来了解一下malloc和free两者在底层的运作原理。这里主要看glibc版本下实现的ptmalloc(glibc下默认的内存管理器)。
因为频繁得向操作系统申请内存,会导致很大的性能开销,所以内存池都会预先向操作系统申请过量的内存空间,然后自己进行管理,在用户进行malloc时,再从内存池中分配内存给到用户,在用户将内存free时,内存池会将用户free掉的这部分内存重新管理起来。
-
这样将内存管理起来,就可以尽可能的减少内存碎片,以及提高用户申请内存的效率。
↓简单描绘一下进程地址空间↓
栈区以及mmap映射区都是自顶向下增长的,堆区是自底向上增长的,直至mmap映射区与堆区耗尽中间的空余内存,当mmap映射区与堆区碰头时,可能会导致程序崩溃(一般只会发生在32位操作系统)。
二. ptmalloc内存管理
-
malloc的分配策略
malloc底层会根据情况调用两个函数:
-
第一个就是brk,这里有配套的sbrk,在申请的内存小于mmap的分配阈值时(通常为128KB),会调用sbrk(主分配区)
-
brk函数用于设置堆区的新上界地址,它是直接修改内核数据结构,它也是原子性的,一般用在需要精确控制堆顶的情况,正常情况下多使用sbrk,它的参数
const void *addr传的是绝对地址。 -
sbrk函数,参数是申请内存的大小,它通过上移堆顶指针(_edata_)来实现扩容,通过sbrk申请的内存在free时不会直接还给操作系统,而是缓存在ptmalloc中,以反复使用 。
-
int brk(const void *addr);
void* sbrk(intptr_t incr);-
第二个就是mmap,当申请的内存大于mmap的阈值时就会调用mmap来分配内存,它有配套的清理函数
-
mmap出来的内存,通过munmap函数清理时,会直接还给操作系统。
-
mmap有两种映射的方式:
-
第一种是将磁盘中的文件映射到内存中。
-
第二种是匿名映射,只向操作系统申请内存,而不映射文件,malloc调用的就是这种。
-
-
void* mmap(void* addr, size_t length, int prot, int flags, int fd, off_t offset);
int munmap(void& addr, size_t length);-
内存管理结构
在ptmalloc中为了减缓多线程中锁冲突的问题,内存分配分为主分配区(main_area)以及非主分配区(non_main_area),主分配在堆上,使用sbrk以及mmap来分配内存,非主分配区,位于mmap segment分配区。
在ptmalloc中管理内存的基本单位是malloc_chunk,这里采用边界标记法来管理从操作系统那预申请的内存,通过将各类不同的chunk,大小和功能相近的chunk挂到各个链表上管理起来,这个链表就叫bin。
-
主存区以及非主存区是用环形链表链接起来的。
-
每个分配区都配有互斥锁。
-
分配内存时,分配区一旦增多就不会减少。
-
分配产生的内存碎片,ptmalloc在对它们进行整理时,也需要加锁。
-
主分配区只能有一个,非主分配区可有多个。
堆区以及分配区的chunk是由ptmalloc统一管理的。ptmalloc为了提高效率还划分了不同的bin,划分为fast bins、unsorted bins、small bins、large bins,它们分别管理着不同大小的chunks。
2.1 malloc_chunk结构
struct malloc_chunk {INTERNAL_SIZE_T prev_size; // 前一个chunk大小(若空闲)INTERNAL_SIZE_T size; // 当前chunk大小及标志位struct malloc_chunk *fd; // 链表前驱指针(空闲时有效)struct malloc_chunk *bk; // 链表后继指针(空闲时有效)// Large Bins专用struct malloc_chunk *fd_nextsize; // 前一个更大chunkstruct malloc_chunk *bk_nextsize; // 后一个更小chunk
};
解释一下
fd_nextsize链:A → B → CA的fd_nextsize指向B(比A小)B的fd_nextsize指向C(比B小)
bk_nextsize链:C → B → AC的bk_nextsize指向B(比C大)B的bk_nextsize指向A(比B大)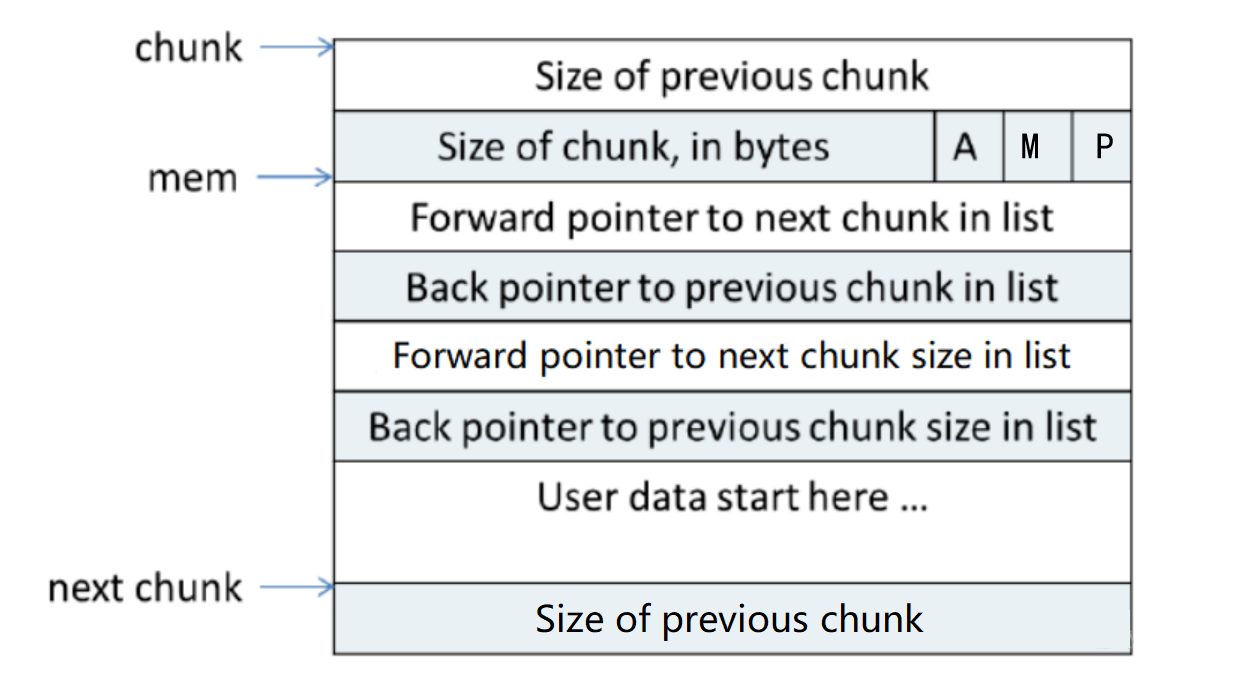
-
prev_size:表示前一个chunk的大小,通过当前chunk地址减去prev_size就可以得到前一个chunk的地址。prev_size只在前一个chunk空闲时才有效,否则无效。
-
size:记录了当前chunk的大小,以及其他一些信息:
-
这里的A表示是否为主分配区,A为0则是主分配区,1则是非主分配区。
-
M为1则表示该chunk为mmap区,0表示chunk来自heap区。
-
P表示前一个chunk是否在使用,1表示前一个chunk在使用,0表示空闲。当前一个chunk正在使用时,prev_size则处于无效状态,这时前一个chunk就可以使用这个prev_size所占的空间。(空间复用)
-
ptmalloc分配的第一个块内的P为1,这是为了防止程序引用到错误位置。
-
-
fd与bk:当前chunk空闲时才有用,用于链表中管理chunk而存在。
-
fd_nextsize与bk_nextsize:在large bins中使用,在large bins中,chunk是根据大小排序的,若有多个相同大小的chunk排在一起,增加这两个指针可以加快查找chunk的效率。
2.2 其它chunk
这里的chunk不会在bins中找到,它们属于特殊的chunk
-
top chunk:当用户申请的内存bins不能满足时,如果top chunk大于这个申请的内存,top chunk就会分为user chunk 和 remainder chunk,user chunk给用户去使用,remainder chunk会成为新的top chunk;当用户申请的内存大于top chunk时,就会调用sbrk或mmap去申请内存。
-
last remainder chunk:和top chunk类似,当用户需要申请一块小内存,而在small chunk中找不到时,就会去找last remainder chunk,若last remainder chunk的大小大于所需分配内存的大小,last remainder chunk就会分裂为两块内存,一块交给用户,另一块成为新的last remainder chunk。
-
mmaped chunk:当分配的内存大于mmap阈值时(假设128KB),就会调用mmap直接进行内存分配,这时chunk设置的M=1,mmaped chunk在释放时直接还给操作系统。
注:非主分配区的数量通常与线程数相关,而mmaped chunk是申请的内存超出mmap的阈值才调用的mmap。非主分配区是为了解决多线程并发下的竞争问题而存在的。
2.3 空闲链表bins
ptmalloc为减小内存分配时的开销,在malloc_state使用了空闲链表,在用户申请内存时,并不会直接调用sbrk和mmap,而是先到空闲链表bins中寻找合适的chunk,这样可以降低使用sbrk和mmap系统调用的频率。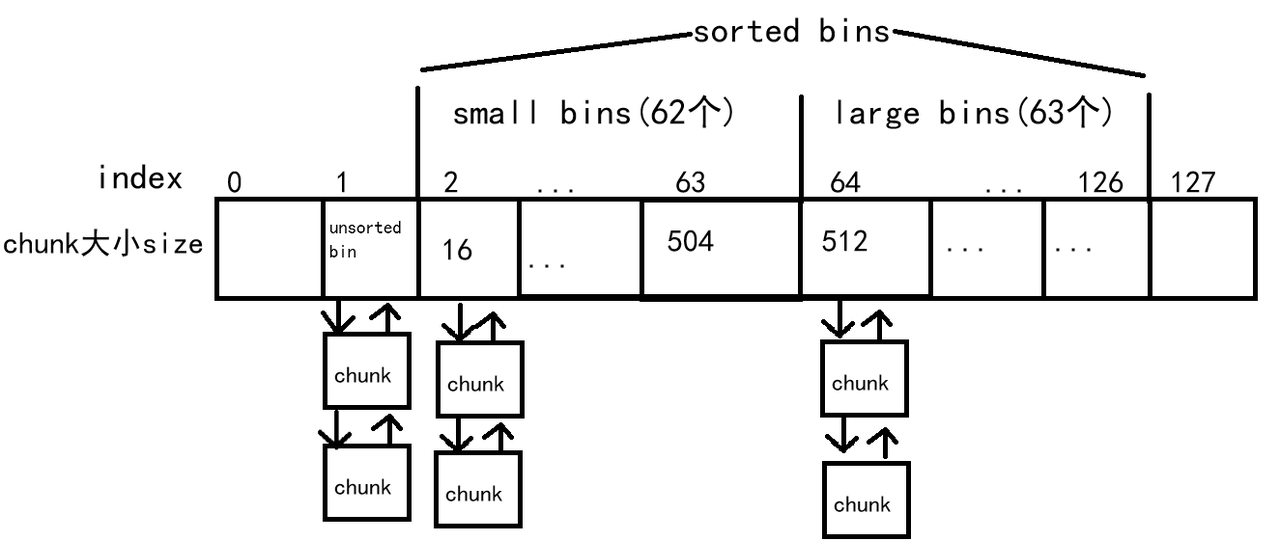
在32位操作系统下,bin[0]和bin[127]是不存在的,index为1的是unsorted bin,2-126为sorted bin。每个bin管理着大小相近的chunk双向链表。
-
fast bin:为了提高存取小块内存的效率。
-
作为bins的高速缓冲区,在用户需要分配一些较小的内存(小于等于max_fast-->64B)时,会先到fast bin中查找。
-
fast bin是单链表结构,采用头插法(FIFO),插入和分配都在头部取用。在32位操作系统下fast bin约有10个bin,在64位操作系统下约有16个bin。
-
分配时,遍历fast bin,直接返回链表头部元素;释放时,不会检查前后空闲的块,不作合并。
-
fast bin会定期清理,将相邻的空闲的chunk合并,并链入unsorted bin中。
-
-
unsorted bin:位于bin[1],作为bins的缓冲区。
-
顾名思义就是为排序的bin,当用户释放内存大于max_fast或fast bin合并内存时,会将chunk链到unsorted chunk,其中chunk的大小不受限。
-
延后的清理机制,在用户分配内存进入到unsorted bin时,若有合适大小的chunk则则分割返回相应大小的chunk,分割剩下的chunk重新链入unsorted chunk;若没有合适大小的chunk,则将unsorted bin链入small bins或large bins,再到sorted bins中查找。
-
-
small bins:大于64B小于512B的chunk会被放入到small bins中管理,每个small bin差8B(32位下)。
-
同一个small bin下的chunk大小相同,分配时从链表尾部取块(先进先出,FIFO)。在释放时会立即检查前后块是否空闲,若空闲则合并前后块,合并后的chunk会重新链入small binsk或unsorted bin(超出small bins的大小时)中。
-
-
large bins:大小大于512B的chunk会被链入large bins中,large bins中的步长并不相同,呈递增态势。
-
large bins中的每个bin都包含了一定范围大小的chunk,按大小和时间降序排序,大的排前面,相同大小的按最近使用时间排序,便于快速查找最接近请求大小的块。
-
分配时,采用best fit策略,遍历large bins,找到一个最小且合适的chunk,若恰好合适则直接返回,若大于,则进行分割,分割后的块,一部分返回给用户,一部分重新链入samll bins或large bins。
-
释放策略与small bins类似。
-
-
内存分配与释放
3.1 初始化
-
初始时,堆区的start_brk == brk,堆区分配的内存为0。
-
主分配区:初始化时预先用sbrk分配一块较大的内存(例如128KB + chunk_size,对齐4KB),来初始化heap。
-
非主分配区:由多个sub_heap组成,每个sub_heap通过mmap进行内存映射(32位操作系统默认1MB,64位下默认64MB)。第一个sub_heap的顶部是heap_info,接下来是malloc_state实例和chunk数据。
-
当分配时的内存小于mmap的阈值(128KB)时,但heap的空间有不足时,会调用sbrk来增加堆的空间大小,非主分配区会调用mmap来映射一块新的sub_heap来增加top chunk的大小,每次heap增加的大小都会对齐4KB(即一页)。
-
当所需分配的内存大于mmap的阈值时 ,并且在sbrk失败或top chunk的空间不足时,ptmalloc会尝试调用mmap直接映射一块内存到地址空间内。使用mmap直接映射到内存的chunk(mmaped chunk)在释放时,会直接还给操作系统,若再次访问这段空间,则会产生段错误(Segment Fault)。在heap或top chunk中申请的内存,释放时会保留在heap或top chunk,以备下次使用。
3.2 内存的分配与释放
-
内存分配malloc的过程:
-
获取分配区的锁,每个进程只有一个malloc管理器,防止线程冲突。
-
计算所需分配内存的大小,优先到本线程的分配区中查找若没有相应的分配区,则去寻找其他空闲的分配区,并尝试获取它们的锁,若没有相应的分配区,则会调用mmap映射一块分配区,并链入全局循环链表中。
-
如果内存的大小小于64B,优先去fast bins中查找,如果有则将fast bins中的chunk返回;若没有,转到e。
-
如果内存的大小小于512B,则回去small bins中查找,若存在则返回,分配结束;若没有则尝试到unsorted bin中查找,若存在则切割并返回相应的chunk,若不存,则转到e。
-
若需要的是一块大内存且在small bins中未找到相应的chunk:
-
去到fast bins尝试合并空闲的chunk,并链入到unsorted bin中。
-
到unsorted bin查找是否有相应的chunk,如果有则分割并返回对应大小的chunk,若没有则将unsorted bin中的chunk链入small bins、large bins中,之后转到f。
-
-
若分配的是一块大内存且small bins中未找到,unsorted bin已经fast bins中已作合并处理,未满足条件,则在large bins中找一个合适的内存进行切割,返回合适的内存,将切割剩余的remainder chunk链入到unsorted bin中。
-
若在fast bins和bins中找不到合适的内存,则到top chunk中进行分配,如果top chunk中的内存足够,则切割top chunk,将合适的内存返回给用户,剩下的remainder chunk成为新的top chunk。
-
如果top chunk内存不足需要扩容,则需要调用sbrk(主分配区)或mmap(非主分配区)进行扩容,再进行分配。
-
-
如果所需分配的内存超出了mmap的阈值,则直接使用系统调用mmap去映射一块内存(mmaped chunk,分配时对其 4KB)给到用户。
-
-
内存释放free的流程:
-
获取相应分配的锁。
-
当指针为空时,直接返回。
-
若当前的chunk是由mmap分配的,即mmaped chunk,则使用munmap进行释放,内存直接还给操作系统。
-
若chunk与top chunk相连,则与top chunk合并,转到h。
-
若chunk的大小大于max_fast,放入unsorted bin中,检查是否有合并情况:
-
若没有合并条件,直接free。
-
若存在合并条件或与top chunk相连,则会与top chunk合并,则转到h。
-
-
若chunk大小小于max_fast(64B),则放入fast bins中,检查是否有合并条件:
-
若没有合并条件,则推给延迟合并机制或选择free。
-
若有合并条件,就将前后空闲的块合并,放入unsorted bin中,转到g。
-
-
在fast bins中,若这个chunk处于空闲状态,则会触发合并机制,去遍历fast bins,尝试合并前后空闲的chunk,如果合并后的chunk大于max_fast(64B),则会链入unsorted bin中,如果合并后的chunk与top chunk相连,则会与top chunk合并,转到h。
-
若top chunk的大小大于mmap的收缩阈值(128KB),主分配区的top chunk会尝试归还一部分内存给操作系统。
-
-
注意:
-
ptmalloc的内存收缩是从top chunk开始的,若与top chunk相邻的chunk未得到释放,其下方的chunk都无法回收给操作系统。
-
ptmalloc不适合管理持续不定期分配和释放的长生命周期内存(例如缓存),容易导致内存暴增。
-
多线程环境下的程序不适合使用ptmalloc来做内存管理,更适合用内存池来管理,ptmalloc在多线程方面的效率并不出色。
-
ptmalloc对chunk的连续性十分敏感,根据其回收机制,若出现非连续性内存释放如中间的某chunk被释放,那么与它相邻的空闲chunk就都无法释放。
三. 随便唠
ptmalloc尽管在多线程等的特殊环境下的性能不佳,但它毕竟不是为多线程等专门设计的,它扮演的是一个通用的内存管理机制。它的成熟、稳定不应该被忽视,它使用的自由链表、延迟绑定、清理机制等的技术依旧值得学习。
多线程环境下Google TCMalloc的性能更加出色,tcmalloc通过使用本地缓存、TLS等的技术来减少多线程多锁的竞争,从而提高性能。
当然优秀的还有jemalloc,这里对jemalloc了解的不多,就不过多赘述。
参考文献:
-
ptmalloc底层原理剖析-CSDN博客
-
内存管理#4-ptmalloc(bins) - 知乎
-
还有其它相关的优秀文章
