LoRA微调
LoRA(Low-Rank Adaptation)是近年在大模型微调中提出的一种高效技术,主要用于大规模预训练语言模型(如GPT、BERT等)的微调。其基本思想是在微调过程中,不直接更新整个模型的所有参数,而是引入低秩矩阵来对预训练模型进行适应,从而大幅减少训练参数量和计算开销。
1. 概念
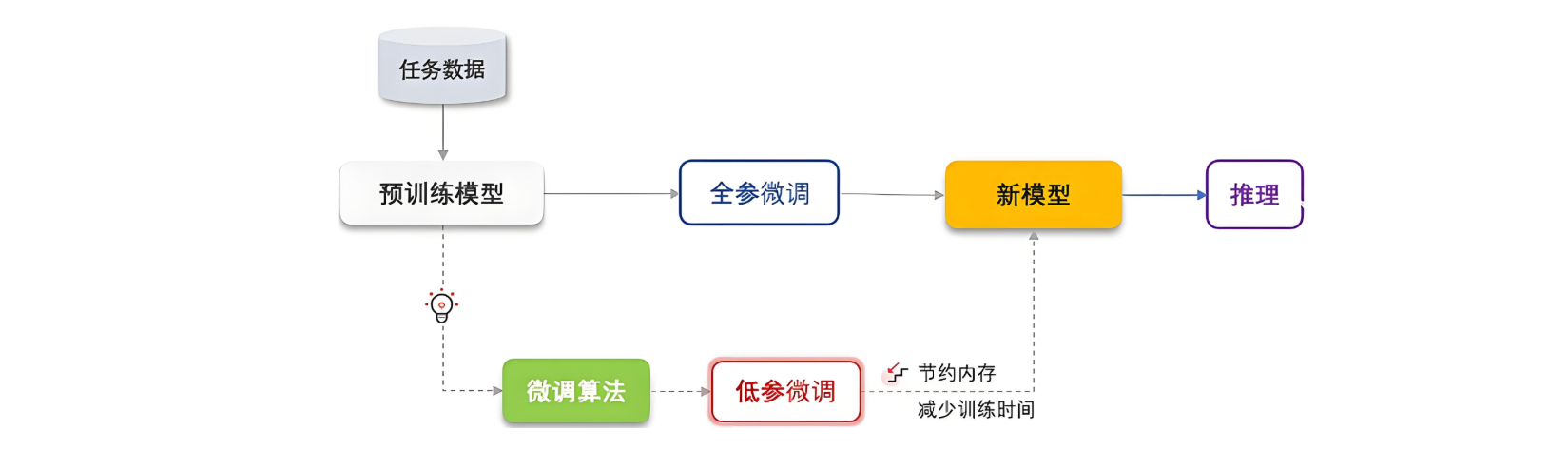
LoRA(低秩适配)是一种针对大模型的参数高效微调技术。其核心思想是通过低秩矩阵调整模型参数,而非修改整个模型,从而大幅降低训练成本。
2. 核心原理
-
低秩矩阵: LoRA方法在原始网络参数更新过程中,通过引入低秩矩阵近似原始权重的更新
-
将网络的某些权重矩阵分解为两个较小的矩阵乘积,也就是低秩矩阵
-
这些小矩阵是需要微调的参数,而原始的预训练权重则保持不变。
-
-
减少计算和存储需求: 只需要调整相对较少的参数,同时又能实现与完全微调大模型类似的性能效果。
-
适应性:通过低秩矩阵的引入,使得微调过程可以更高效地适应特定任务,提升任务的表现,而不需大规模参数更新。
3. 功能
-
节省资源:
-
计算成本低:训练参数仅为原模型的 0.1%~1%,GPU 显存需求下降 50% 以上。
-
训练速度快:微调时间从几天缩短到几小时。
-
-
保留通用能力:
-
冻结原模型参数,避免微调后模型“遗忘”原有知识(如通用对话能力)。
-
-
灵活适配多任务:
-
可同时训练多个 LoRA 模块(如医学、法律、编程),按需切换。
-
-
适合小数据场景:
-
在数据量较少时(如 1 万条医学问答),仍能有效微调。
-
4. 对比传统微调
| 方法 | 训练参数数 | 显存占用 | 任务切换成本 | 适用场景 |
|---|---|---|---|---|
| 全参数微调 | 100% | 极高 | 高(保持多个大模型) | 数据充分、资源丰富 |
| LoRA | 0.1%~1% | 低 | 低(切换简单) | 数据稀缺、多任务适应 |
| 迁移微调(Adapter) | 1%~5% | 中 | 中 | 中等复杂任务 |
5. 典型应用
-
领域适应:让通用大模型学会医学诊断、法律咨询。
-
个性化需求:为不同用户定制对应话术(如重型模型、幽默型)。
-
轻量化部署:在手机端运行较大的模型(如LoRA量化技术)。
6. 原理
LoRA的核心思想是将权重变化(ΔW)分解成低秩表示,这样可以更高效地使用参数
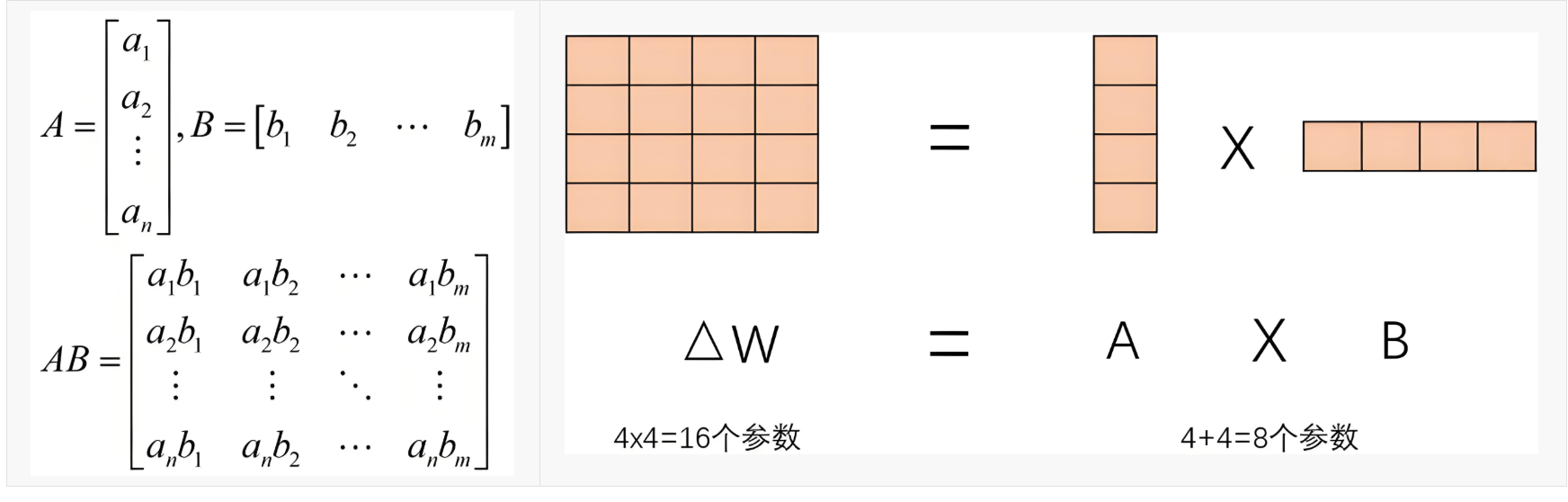
LoRA的核心思想是将这个权重矩阵分解为两个较小的矩阵
-
一个低秩矩阵 A ,维度为 (d, r)
-
另一个低秩矩阵 B,维度为 (r, k)
其中,r 是低秩的秩,通常远小于原矩阵的维度 d 和 k。
LoRA 的精髓之一:以最小扰动介入原模型行为,助于模型稳定收敛,并仅通过训练少量参数(A 和 B)来适配新任务。
7. 消融实验
在机器学习中,它指通过有控制地改变模型的某个特定组件、设置或特征,来评估该组件的重要性。
LoRA微调消融实验就是通过系统性地改变LoRA配置中的一个或多个变量(即“移除”或“修改”它们),来研究这些变量对微调最终效果的影响。
LoRA有很多超参数,消融实验通常围绕它们展开:
- 1.秩(
r)的消融 - 2.目标模块(
target_modules)的消融 - 3.Alpha参数(
lora_alpha)的消融 - 4.Dropout(
lora_dropout)的消融