网页设计课程主要内容网站关键词怎样优化
大家好!欢迎来到 Flink 的奇妙世界!如果你正对实时数据处理充满好奇,或者已经厌倦了传统批处理的漫长等待,那么你找对地方了。本系列文章将带你使用优雅的 Scala 语言,一步步掌握强大的流处理引擎——Apache Flink。
今天,我们先来打个前站,深入浅出地了解 Flink 的基本概念和核心优势,为后续的实战打下坚实的基础。
目录
一、Flink 简介
二、流处理 vs 批处理:数据世界的“实时”与“离线”
三、Flink 的架构:幕后英雄的协作
四、有状态流处理的核心优势:让你的数据流拥有“记忆”
五、案例演示
六、总结
一、Flink 简介
Apache Flink 是一个开源的流处理引擎,最早诞生于批处理系统演进而来,但它的核心设计目标是解决实时流数据处理问题。Flink 能够高效地处理无界数据流,同时也支持批处理任务。其高吞吐、低延迟、可扩展性和容错能力使其在实时数据处理、事件驱动应用和复杂事件处理等场景中得到了广泛应用。
简单来说,Apache Flink 是一个 分布式、高性能、始终可用、且准确的流处理和批处理框架。你没看错,它不仅擅长处理源源不断到来的实时数据流,也能高效地处理存储在文件系统或数据库中的静态数据。
你可以把 Flink 想象成一家“数据工厂”,它能接收各种各样的数据“原材料”,然后按照你设定的“生产线”进行加工处理,最终产出你需要的“产品”——比如实时的业务指标、异常告警、个性化推荐等等。

二、流处理 vs 批处理:数据世界的“实时”与“离线”
在深入 Flink 之前,我们先来区分一下两种主要的数据处理模式:流处理和批处理。
批处理 (Batch Processing)
-
场景: 想象一下你每天晚上下班后,需要统计今天所有的销售数据,生成一份日报表。你需要收集齐所有的数据,然后一次性进行分析计算。
-
特点:
-
处理的数据是静态的、有界的 (Bounded)。 所有数据都事先收集好,形成一个“批次”。
-
处理过程通常有明确的开始和结束。
-
延迟较高。 你只能在整个批次处理完成后才能看到结果。
-
典型代表: Hadoop MapReduce、Spark Batch。
-
流处理 (Stream Processing)
-
场景: 想象一下一个电商平台的实时监控系统,需要实时监测用户下单、支付、浏览等行为,一旦发现异常操作(比如短时间内大量异地登录),立即发出警报。
-
特点:
-
处理的数据是动态的、无界的 (Unbounded)。 数据源源不断地到来,没有明确的结束。
-
处理是持续进行的。 一旦有新数据到达,就会被立即处理。
-
延迟极低。 可以实现毫秒级的实时响应。
-
典型代表: Apache Flink、Apache Kafka Streams、Apache Storm。
-
可以用一个简单的生活例子来理解:
批处理: 像整理你一学期的照片,你需要等所有照片都拍完才能开始整理、分类。
流处理: 像观看一场直播,画面和声音是实时传输和播放的,你不需要等待所有内容结束后再观看。
让我们用一张图来更形象地展示它们的区别
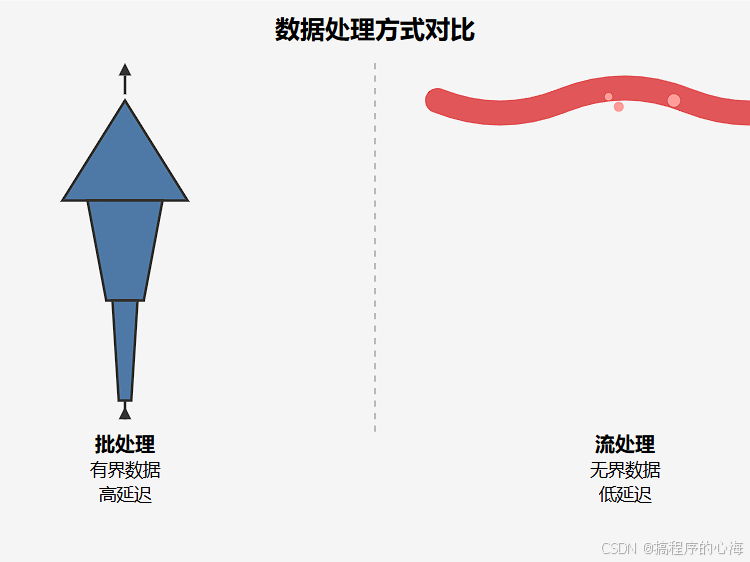
虽然批处理在历史上有其重要性,但在很多现代应用场景下,我们更需要实时地响应数据变化,这就凸显了流处理的重要性。而 Flink,正是流处理领域的佼佼者。
三、Flink 的架构:幕后英雄的协作
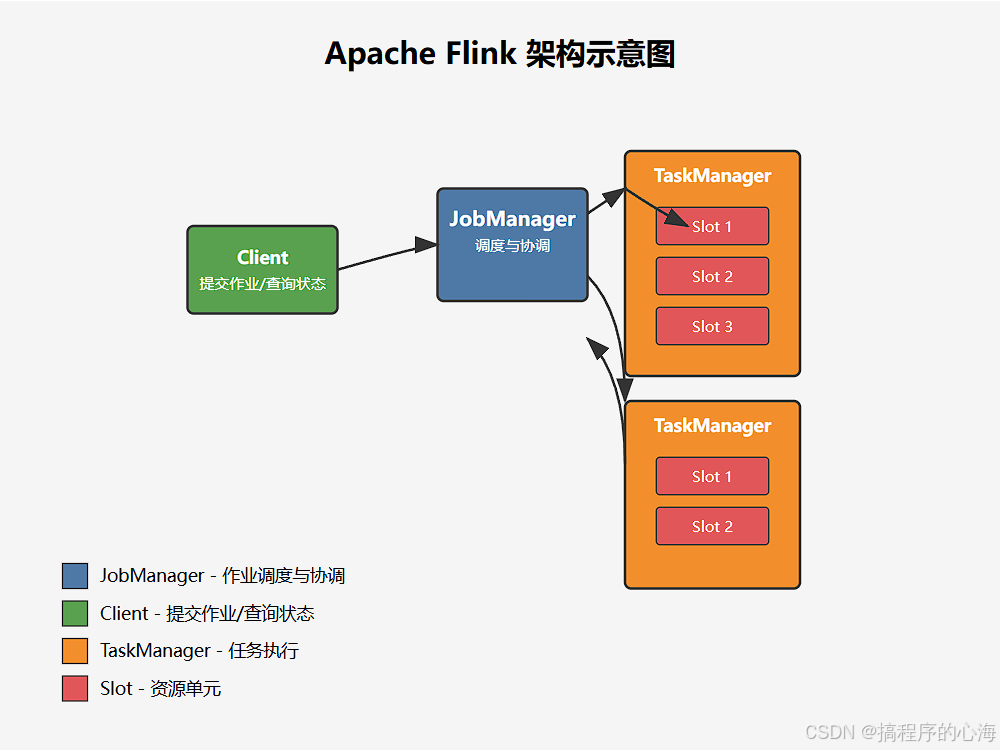
Flink 的强大功能背后,是一套精心设计的分布式架构。理解其主要组件及其职责,能帮助我们更好地理解 Flink 的工作原理。Flink 的主要组件包括:
-
JobManager:集群的大脑
JobManager 是 Flink 集群的协调者,负责接收用户提交的作业 (Job),并将作业分解成多个任务 (Task),然后将这些任务分配给 TaskManager 执行。它还负责作业的生命周期管理、资源管理、以及维护整个集群的状态信息。
你可以把 JobManager 想象成一家工厂的“总指挥部”,它接收生产订单(用户提交的作业),然后将订单拆解成具体的生产步骤(任务),并安排给不同的“生产线”(TaskManager)去执行。
-
TaskManager:干活的工人
TaskManager 是 Flink 集群中真正执行任务的工作节点。它接收来自 JobManager 的任务,并负责在自己的 slots (资源槽) 中执行这些任务。每个 TaskManager 可以管理多个 slots,每个 slot 可以运行一个 Task 的一部分或者一个完整的 Task。
继续上面的比喻,TaskManager 就是工厂里的“生产线”,它接收 JobManager 分配的任务,利用自己的“工人”(slots)来完成具体的生产工作。
-
Client:与集群的交互入口
Client 是用户与 Flink 集群交互的接口。用户可以通过 Client 提交作业给 JobManager,也可以查询作业的状态和集群的信息。Client 本身不是 Flink 集群运行的一部分,它可以在任何可以访问 Flink 集群的地方运行。
Client 就像是工厂的“客户服务中心”,用户通过它下达生产指令(提交作业)或查询生产进度(查看作业状态)。
让我们用一张图来展示 Flink 的基本架构:
四、有状态流处理的核心优势:让你的数据流拥有“记忆”
传统的数据处理往往是无状态的,这意味着每次处理数据都像是一个全新的开始,不记得之前发生过什么。但在很多实际应用中,我们需要记住过去的状态,才能做出更准确的判断和决策。
Flink 提供了强大的有状态流处理能力,这正是其核心优势之一。
什么是状态 (State)?
在流处理中,状态是指应用程序在处理数据流的过程中需要记住的信息。它可以是简单的计数器、最近的事件、聚合的结果,甚至是更复杂的数据结构。
为什么有状态流处理如此重要?
考虑以下几个场景:
-
实时统计: 计算过去 5 分钟内每个用户的点击次数。这需要记录每个用户的点击计数状态,并在新的点击事件到来时更新。
-
复杂事件处理 (CEP): 检测符合特定模式的事件序列。例如,连续三次登录失败后尝试支付,这需要记住之前的登录状态和支付尝试状态。
-
会话分析: 分析用户的会话行为,例如用户在网站上的点击路径和停留时间。这需要维护每个用户的会话状态。
-
Exactly-Once 语义: 在数据处理过程中,保证每条数据都被精确地处理一次,不多不少。这在很大程度上依赖于 Flink 强大的状态管理和容错机制。
Flink 如何管理状态?
Flink 提供了一套完善的状态管理机制,包括:
-
不同的状态后端 (State Backends): Flink 支持将状态存储在不同的后端,例如内存、文件系统、RocksDB 等,以满足不同规模和性能要求的应用。
-
Keyed State 和 Operator State:
-
Keyed State: 顾名思义,这种状态是与特定的 key 关联的。在进行有状态操作时,Flink 会根据 key 将具有相同 key 的数据路由到同一个 TaskManager 的同一个 Task 实例进行处理,从而保证了状态的局部性和一致性。这就像是按照用户 ID 来分别记录每个用户的浏览历史。
-
Operator State: 这种状态是与一个 Task 实例相关联的,而不是与特定的 key。例如,Kafka Consumer 连接器的 offset 信息就可以作为 Operator State 来管理。
-
五、案例演示
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Timeobject WindowedCount {def main(args: Array[String]): Unit = {// 创建流处理执行环境val env = StreamExecutionEnvironment.getExecutionEnvironment// 模拟数据源:每隔一秒生成一个随机整数val stream = env.socketTextStream("localhost", 9999).map(_.toInt)// 按时间窗口进行聚合(例如:每5秒统计一次总和)val aggregatedStream = stream.timeWindowAll(Time.seconds(5)).reduce(_ + _)// 输出结果aggregatedStream.print()// 启动任务env.execute("Scala Flink Windowed Count")}
}
代码解析
创建执行环境:通过
StreamExecutionEnvironment.getExecutionEnvironment获取流处理环境。数据源定义:这里使用 socket 作为数据源,开发者可以替换为 Kafka 或其他数据源。
窗口聚合:
timeWindowAll(Time.seconds(5))定义了一个5秒的滚动窗口,通过reduce方法对窗口内数据进行聚合计算。任务启动:调用
env.execute启动 Flink 作业。
六、总结
本文通过对 Flink 的基本概念、流处理与批处理的对比、架构组成和有状态流处理的优势进行了详细讲解,并配合了图示和 Scala 代码示例。希望这篇文章能帮助我们快速入门 Flink 编程,并激发我们在实时数据处理领域的探索热情。
接下来,我们可以进一步学习如何构建更加复杂的 Flink 应用,如结合 Kafka 进行实时流数据处理、利用 CEP(复杂事件处理)实现异常检测等。无论我们是初学者还是有一定基础的开发者,都能在 Flink 的生态系统中找到适合自己的解决方案。
如果这篇文章对你有所启发,期待你的点赞关注!
