Tiger生成式推荐
目录
1 介绍
2 架构
语义碰撞问题
Transformer模块
在本文中,我们提出了一种新的生成检索方法,其中检索模型自回归地解码目标候选者的标识符。
1 介绍
召回和排序
排序是从召回阶段的候选集中进行精排,强调了召回阶段的重要性。
我们提出了一种构建序列推荐生成检索模型的新范式。我们的方法没有使用传统的查询候选匹配方法,而是使用端到端生成模型来直接预测候选 ID。
我们的方法没有使用传统的查询候选匹配方法,而是使用端到端生成模型来直接预测候选 ID。
TIGER 的独特特征是称为“语义 ID”的项目新颖语义表示——从每个项目的内容信息派生的一系列标记。
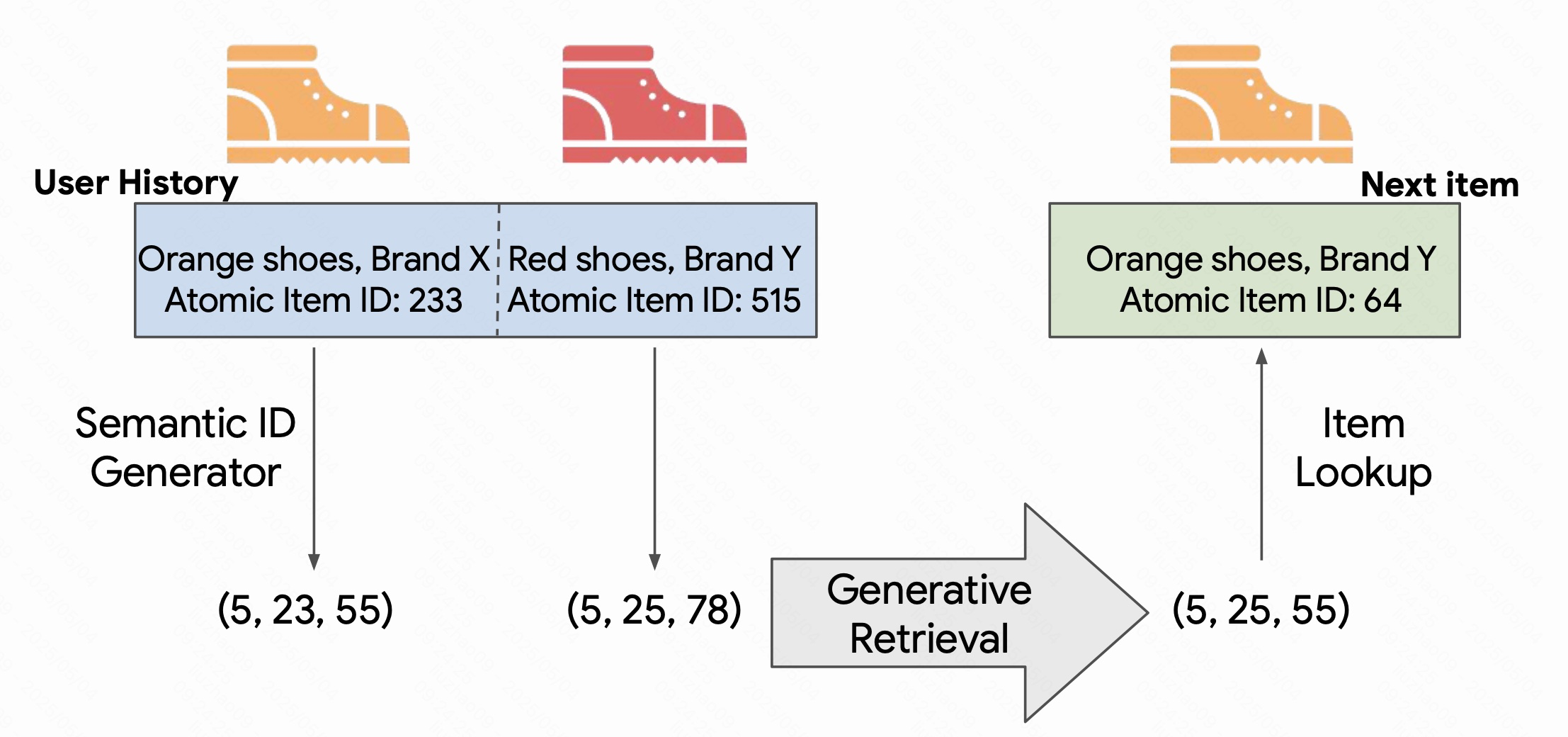
为每个item分配语义id,然后训练检索模型来预测下一个可能id,然后通过lookup来对应item。
好处:
1、可以改进冷启动问题:可以推荐新的和不常见的item
2、可以通过调参进行多样化推荐。
2 架构
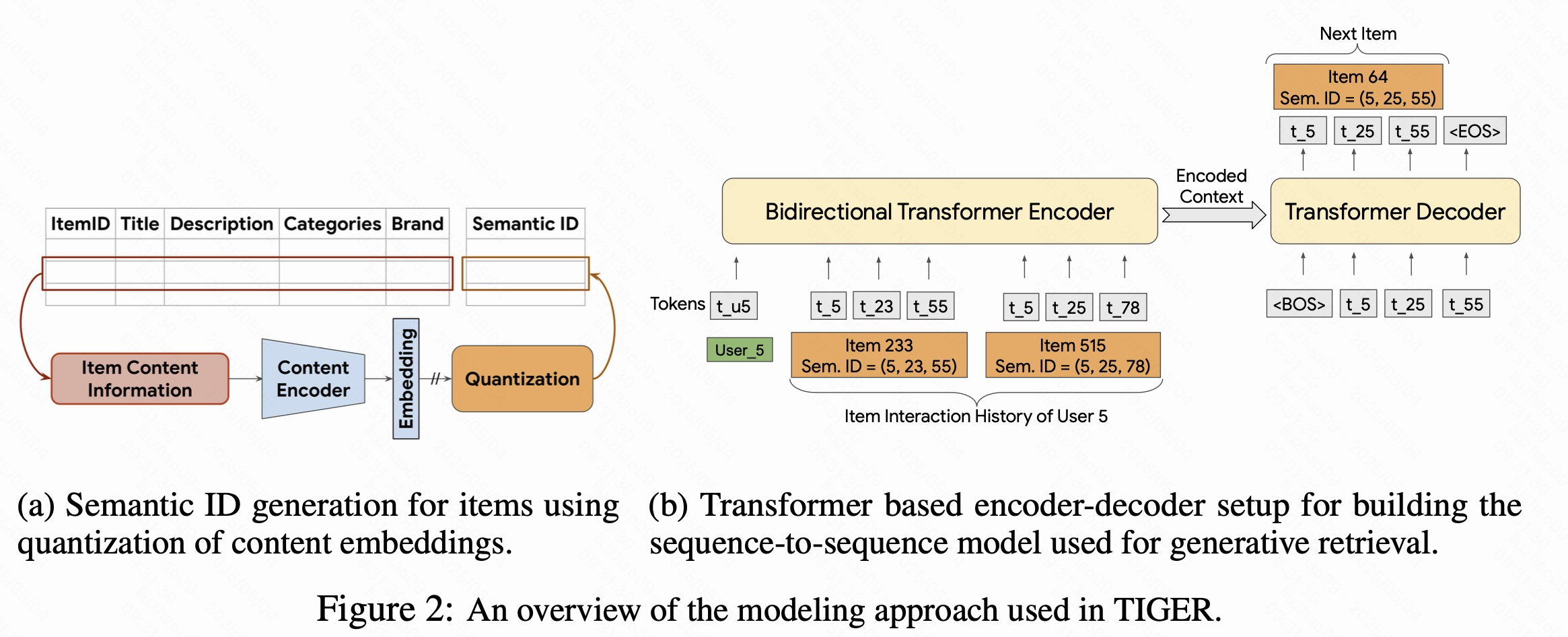
图2a,首先每个item都有内容信息,比如标题、描述、品类、品牌,将他们放到内容编码器转化为embedding向量,然后进行量化,变成语义ID。
其中,内容编码器,如预训练语言模型 SentenceT5,BERT,用于生成该物品的高维嵌入向量。这些嵌入向量包含了物品的语义信息。
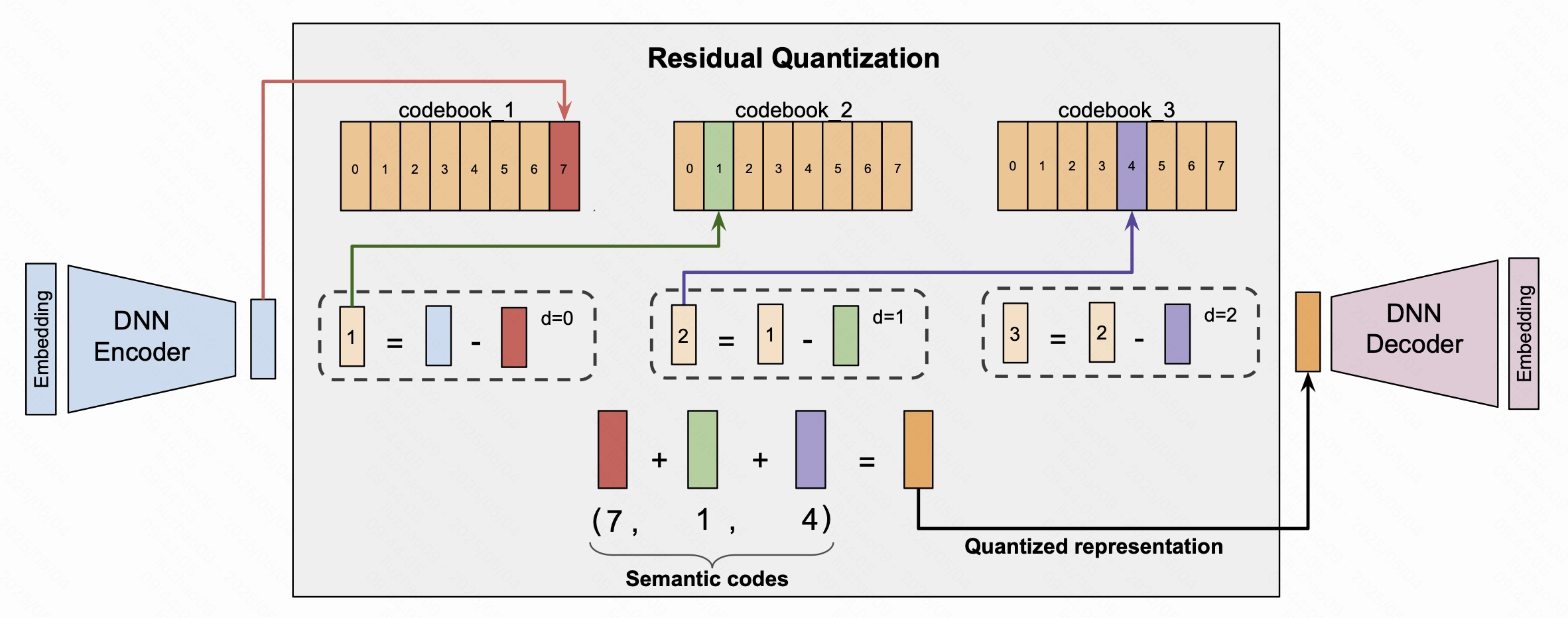
量化,即RQ-VAE技术,其核心思想是:逐层逼近,量化残差
目标,现在我们已经得到了一个物品的embedding表示,想要将它转换成包含物品信息的语义id。比如(10,20,03)。
做法,通过三个阶段来进行生成,每个阶段产生一个码字。
具体如下图。
每个阶段的损失函数:
总的来说分为重构损失L_recon和L_rqvae两部分
重构损失:L_recon := ∥x - x̂∥²,就是比较输入x和经过量化然后重构的x之间的欧氏距离,这个损失函数是为了保证量化过程中原始信息的保护。
即:确保最终生成的语义id有效,能代表原始向量。
rqvae损失:核心部分,保证量化有效。
L_rqvae的第一项 (码本损失) 负责优化码本,让码本中的向量能更好地代表数据空间中的真实分布。L_rqvae的第二项 (承诺损失) 负责优化编码器,让它生成的中间表示更容易被量化。
另外有stop-gradient操作,保证梯度被精确的引导到其该更新的部分。
语义碰撞问题
在这个ID后面再追加一个“冲突解决码”
Transformer模块
把推荐系统转换成语言翻译问题
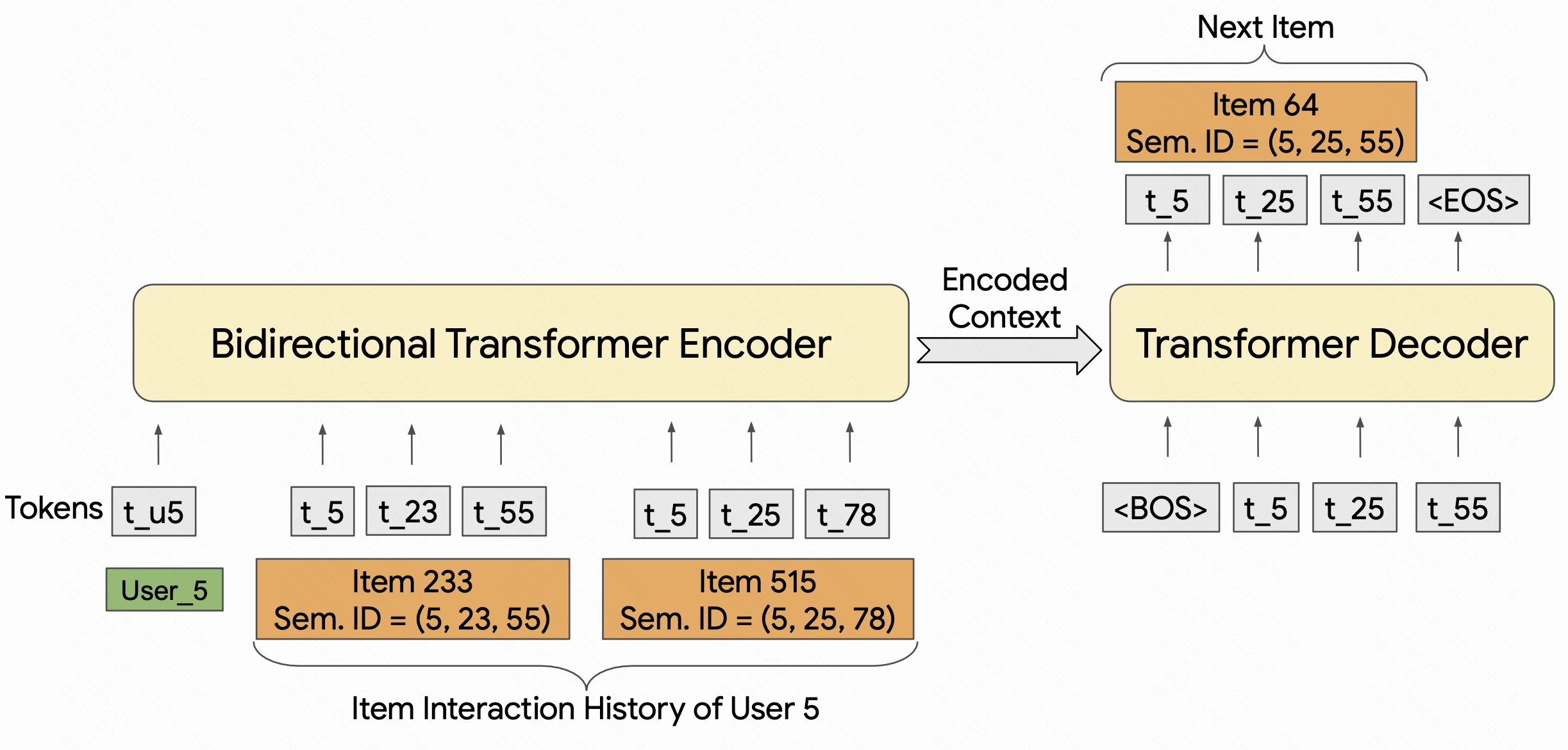
首先,我们得到用户的历史交互序列,按时间顺序。
然后将其转化为语义id,于是用户的整个行为就可以转换为一串语义token序列。
这是模型的基本输入。
在模型架构上,transformer用双向编码器进行编码用户的token序列,捕捉上下文关系,然后用解码器生成下一个物品的语义ID。(双向编码器的好处是可以获得更完整的上下文信息)