C++语言编程规范-程序效率
01
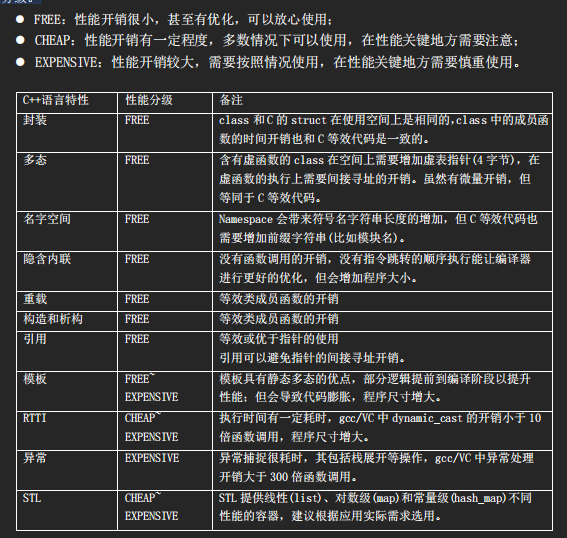
9.1 C++语言特性的性能分级
影响软件性能的因素众多,包括软件架构、运行平台(操作系统/编译器/硬件平台)等。很多时候,程序的性能在框架设计完成时就已经确定了。因此当一个程序的性能需要提高时,首先需要做的是用性能检测工具对其运行的时间分布进行一个准确的测量,找出关键路径和真正的瓶颈所在,然后针对瓶颈进行分析和优化,而不是一味盲目地将性能低劣归咎于所采用的语言。事实上,如果框架设计不做修改,即使用 C 语言或者汇编语言重新改写,也并不能保证提高总体性能。C++对性能的设计原则是零开销(zero overhead),其含义是你不用为你不选择的而付费(you don’t pay for what you don’tuse),因此需要了解各种 C++语言特性的性能开销。C++语言特性的性能描述采 FREE/CHEAP/EXPENSIVE的分级。
02
03
9.2 C++语言的性能优化指导
原则 9.1 先测量再优化,避免不成熟的优化
说明:性能涉及到非常多因素,目标不明确的语言层面优化很难显著地改善性能。建议首先测量到性能瓶颈,再对这些性能瓶颈进行针对性的优化。初学者常犯的一个错误,就是编写代码时着迷于过度优化,牺牲了代码的可理解性。
原则 9.2 选用合适的算法和数据结构
说明:代码优化应该从选择合适的算法和数据结构开始。对于元素个数超过 1000 的数据,其顺序查找算法效率要远低于对数性能的查找算法。
std::vector<int>的占用空间约是 N*sizeof(int),
而std::list<int>的占用空间约是 3N*sizeof(int)。
std::map 提供了对数级的查找算法,
而 hash_map 则更高,提供了常数级的查找算法,但 hash_map 需要选择合适的 hash 算法和桶大小。
建议 9.1 在构造函数中用初始化代替赋值
说明:通过成员初始化列表来进行初始化总是合法的,效率也高于在构造函数体内赋值。
示例:
class A{string s1_;public:A(){s1_ = "Hello,world "; }};
实际上,生成的构造函数代码类似如下:
A():s1_(){s1 = "Hello, world"; }成员 s1_的缺省构造函数已被隐式调用,构造函数体中的初始化实际上上在调用 operator=而初始化列表只需调用一次 s1_的构造函数,相对效率更高。
A():s1_("Hello,world "){}建议 9.2 当心空的构造函数或析构函数的开销
说明:空构造函数的开销不一定是 0,空构造函数也包括基类构造、类内部成员对象的构造等。如果对象的构造函数或析构函数有相当的开销,建议避免临时对象的使用,并在性能关键路径上考虑避免非临时对象的构造和析构,比如 Lazy/Eager/Partial Acquisition 设计模式。
class Y{C c;D d;};class Z : public Y{E e;F f;public:Z() { };};Z z; //initialization of c, d, e, f
04
建议 9.3 对象参数尽量传递引用(优先)或指针而不是传值
说明:对于数值类型的 int、char 等传值既安全又简单;但对于自定义的 class、struct、union 等对象 来说,传引用效率更高:
⚫
不需要拷贝。class 等对象的尺寸一般都大于引用,尤其可能包含隐式的数据成员,虚函数指针等,所以传值的拷贝的代价远远大于引用。
⚫
不需要构造和析构。如果传值,传入是调用拷贝构造函数,函数退出时还要析构。
⚫
有利于函数支持派生类。
示例:
void f(T x) //badvoid f(T const* x) //goodvoid f(T const& x) //good,prefer
建议 9.4 尽量减少临时对象
说明:临时对象的产生条件包括:表达式、函数返回、默认参数以及后缀++等等,临时对象都需要创建和删除。对于那些非小型的对象,创建和删除在处理时间和内存方面的代价不菲。采用如下方法可以减少临时对象的产生。
⚫
用引用或指针类型的参数代替直接传值;
⚫
用诸如+=代替+
⚫
使用匿名的临时对象;
⚫
避免隐式转换;
示例:
Matrix a;a = b + c; //bad: (b + c) creates a temporaryMatrix a = b;a += c; //good: no temporary objects created
建议 9.5 优先采用前置自增/自减
说明:后置++/--是将对象拷贝到临时对象中,自身++/--,然后再返回临时对象。此过程在非简单数据类型时较为耗时(简单数据类型编译器可以优化)
示例:
for (list<X>::iterator it = mylist.begin(); it != mylist.end();++it) //good: rather than it++{//...}
05
建议 9.6 简单访问方法尽量采用内联函数
说明:小函数频繁跳转会带来性能上的损失,内联可以避免性能损失。
class X{private:int value_;double* array_;size_t size_;public:inline int value() { return value_; }inline size_t size() { return size_; }};
06
建议 9.7 要审视标准库的性能规格
说明:std::string 是个巨大类,若使用不当(比如大量的+操作)会导致性能迅速下降;
std::list<T>::size()在某些实现版本中是线性的,所以在 if(myList.size()==0)时可以考虑用
if(myList.empty())替换;
标准输入输出是性能瓶颈,如果不混用 C++和 C 的标准输入输出库,可以考虑关掉同步:std::ios_base::sync_with_stdio(false)。
建议 9.8 用对象池重载动态内存管理器
说明:系统调用 new 和 delete 涉及到系统调用等复杂处理,时间和空间开销都较大。建议对于特定类的申请和释放,采用自定义的对象池机制管理该对象的申请和释放,而不用操作系统的内存管理机制。对象
池的大小需要预先确定或是采用类似 std::vector.resize()的方法可以动态增长。
07
建议 9.9 注意大尺寸数组的初始化效率
说明:我们常这么初始化数组:
char szAccount[MAX_ACCOUNT_LEN] = {0};//数组大小 16对于字符串确保有结束符即可,故要初始化也应该用“szAccount[0] = 0;”替换之,当然在非关键路径,上述的一行代码完成初始化代码更简洁,也能够被接受。
char chTempBuff[MAX_MSG_LEN] = {0};//数组大小为 40K而对于如此大的一块内存清 0,应该用 memset 等库函数替代之。编译器不优化情况下,对于{0}的初始化,通常是一个字节逐一赋值为 0,而 memset 在 64 位平台下很可能是一次 8 个字节。故当数组大于 10 个 字节时,两者的性能差距在 2~8 倍,根据数组大小而定。特别是生成或者删除大尺寸的对象数组,每个数组成员的构造函数或析构函数度要被调用一次,花费的时间更多。
08
建议 9.10 避免在函数内部的小块内存分配
例子:某函数内部,根据消息长度分配内存,然后做相关操作,函数退出前释放内存,如下:
char *pMsg = new char[msgLen];
其实 pMsg 的生命周期仅仅在函数内,它所指向的内存其实应该是一个临时变量,如果我们能够预测其
最大长度远小于线程栈空间,比如最大几十 K,或者只有几十字节,那么就应该声明一个足够大的临时数
组,如下:
assert(msgLen <= MAX_MSG_LEN);//某些情况下可能需要if检测,而断言检测可能不充分。
char chMsg[MAX_MSG_LEN];//不会有失败和释放的处理,效率也完全不在一个数量级
09
技术再好,不会拍马屁还是寸步难行啊。这些年我尝试了考心理咨询师,软考。还是对自我的提升不大,最近又在学这个了。