李宏毅机器学习笔记23
目录
摘要
Abstract
1.Encoder-Decoder
2.如何训练
摘要
本篇文章继续学习李宏毅老师2025春季机器学习课程,学习内容是Transformer中encoder和decoder中间是如何传递资讯,以及训练transformer的基本方法。
1.Encoder-Decoder
之前学习了encoder和decoder的结构及运行过程,接下来将要学习是他们中间是如何传递资讯的。
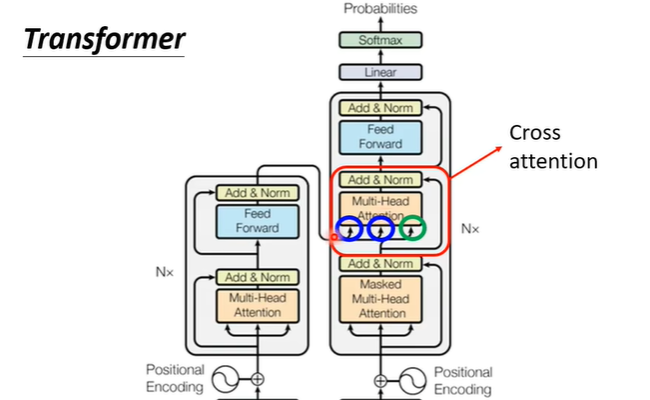
也就是之前学习decoder时,去除的部分。这一块叫做cross attention,它有两个输入来自encoder
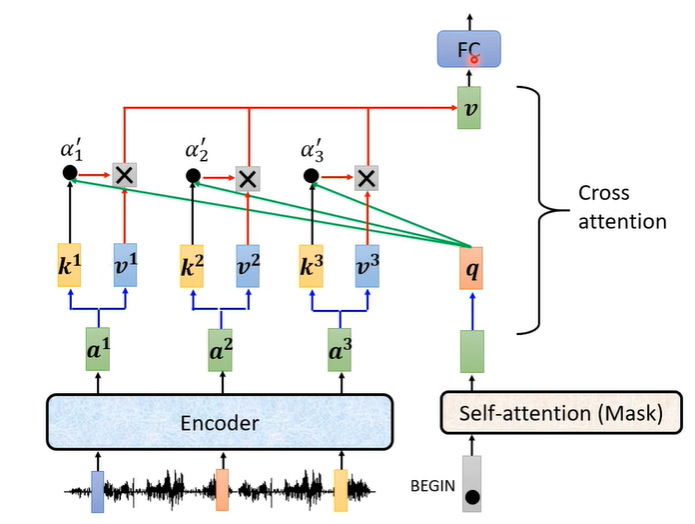
它的实际运作过程如下:encoder这边输入一排向量输出一排向量a,通过a与不同的矩阵相乘得到向量k和v,decoder这边收到begin信号产生一个向量,这个向量乘上一个矩阵得到q,之后用k,q计算他们的分数,再乘上v,最后加起来得到最终的v(整个过程类似self-attention)。
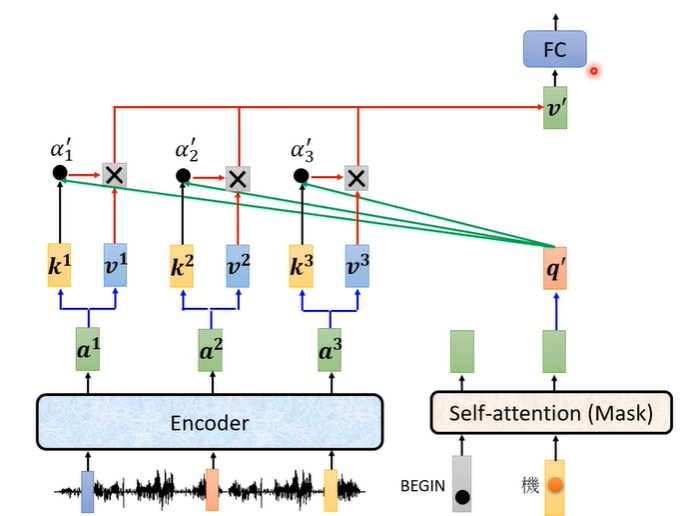
在产生第二个字时也是同样的处理,decoder得到,encoder用k,
计算他们的分数
,再乘上v,最后加起来得到最终的v。
2.如何训练
同样以语音辨识做例子,我们需要收集一大堆的声音讯号,每句声音讯号都要有工读生来听,听到这一段是“机器学习”,就将“机器学习”四个字打出来。那当我们把begin丢给decoder时,它第一个输出应该跟“机”越接近越好,“机”会被表示为一个向量,这个向量中只有“机”这个维度是1,其他都是0。我们decoder的输出是一个几率分布,我们希望这个几率分布与“机”向量越接近越好,因此我们会计算他们的cross entropy,cross entropy的值越小越好。
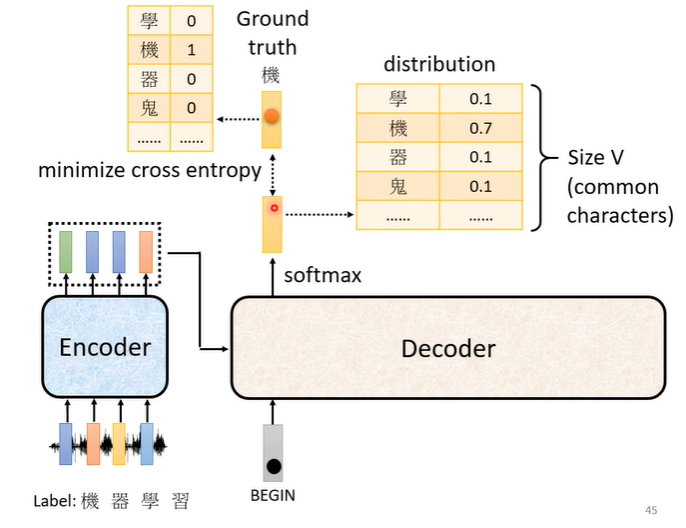
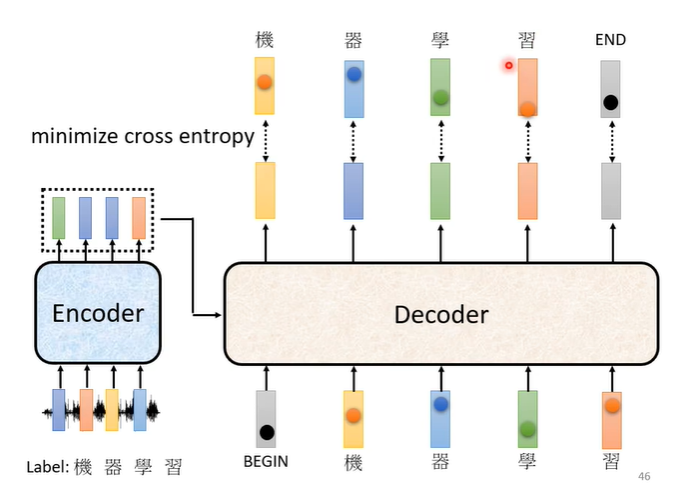
在训练时,我们已经知道输出是“机器学习”,每次输出都有一个cross entropy,我们希望四次输出的cross entropy的总和最小,但是还有END信号,因此第五个位置输出的向量应该跟END信号的cross entropy越小越好。
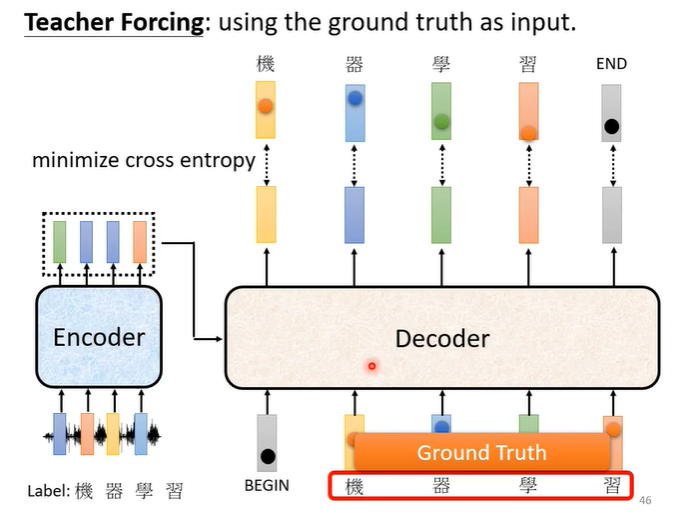
在训练时我们会给decoder看正确答案,也就是我们会告诉它,在有begin有“机”时输出“器”,在有begin,有“机”,有“器”时输出“学”,以此类推。这样的做法叫做teacher forcing。
这样会出现一个问题,训练时有正确答案,但是测试时没有正确答案可以给decoder看,在测试时decoder看到的是自己的输出,所以测试时decoder会看到一些错误的东西。训练时看到完全正确的,测试时看到有一些错误的,这种不一致的现象叫做exposure bias。假设decoder只看过正确的东西,在测试时只要有一个错,就会一步错步步错。
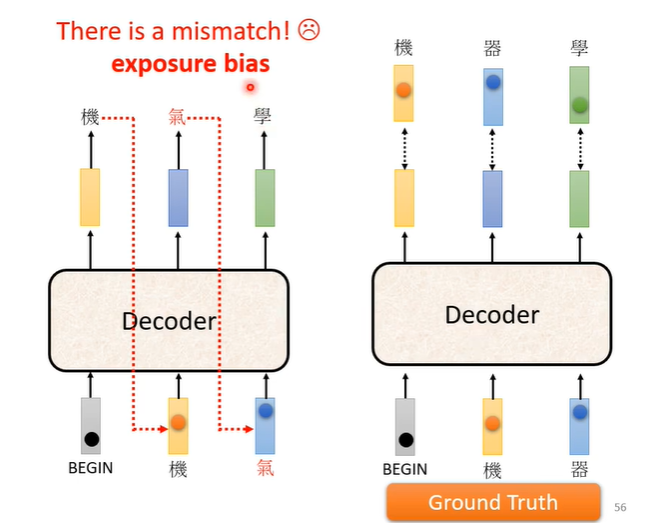
解决这个问题的一个想法是给decoder的输入加一些错误的东西,而给它一些错误的东西它反而会学的更好。