【完整源码+数据集+部署教程】行人和斑马线检测系统源码和数据集:改进yolo11-RFCBAMConv
背景意义
随着城市化进程的加快,交通安全问题日益凸显,尤其是行人和斑马线的安全问题引起了广泛关注。行人作为交通参与者之一,其安全性直接关系到城市交通的和谐与稳定。近年来,智能交通系统的快速发展为行人和斑马线的检测提供了新的解决方案。YOLO(You Only Look Once)系列模型因其高效的实时检测能力而受到青睐,其中YOLOv11作为最新版本,进一步提升了检测精度和速度,成为行人和斑马线检测的理想选择。
本研究旨在基于改进的YOLOv11模型,构建一个高效的行人和斑马线检测系统。通过利用4500张图像的数据集,该系统将能够有效识别行人和斑马线,为交通管理和安全监控提供重要支持。数据集中包含的“person”和“zebra crossing”两个类别,能够帮助模型学习到行人与斑马线的特征,从而提高检测的准确性和鲁棒性。
此外,随着深度学习技术的不断进步,改进YOLOv11模型不仅可以提高检测精度,还能在复杂的交通环境中实现实时监控。这对于减少交通事故、提高行人过马路的安全性具有重要意义。通过本研究,期望能够为智能交通系统的建设提供理论支持和技术保障,为城市交通安全管理提供有效的解决方案,从而推动智慧城市的发展。
图片效果
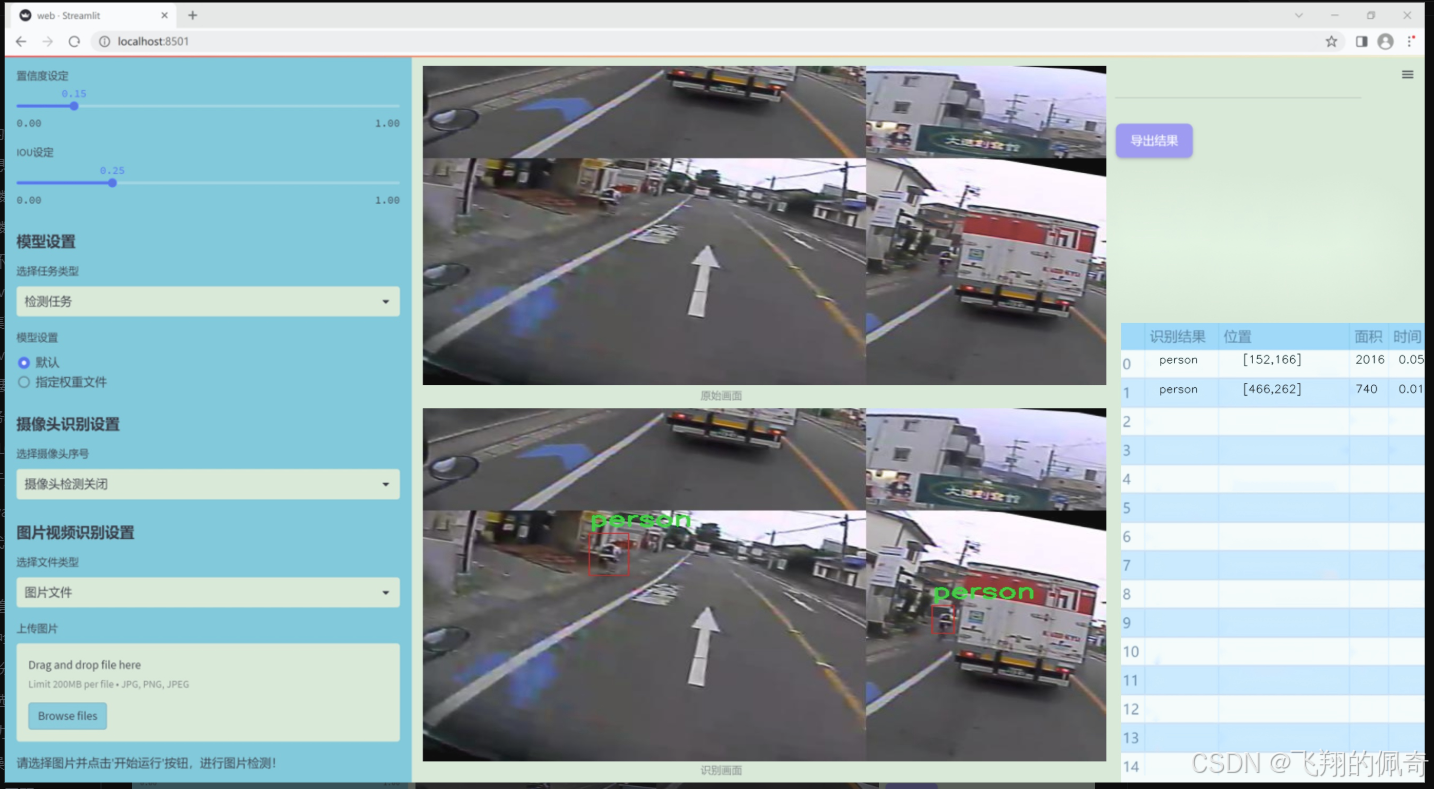
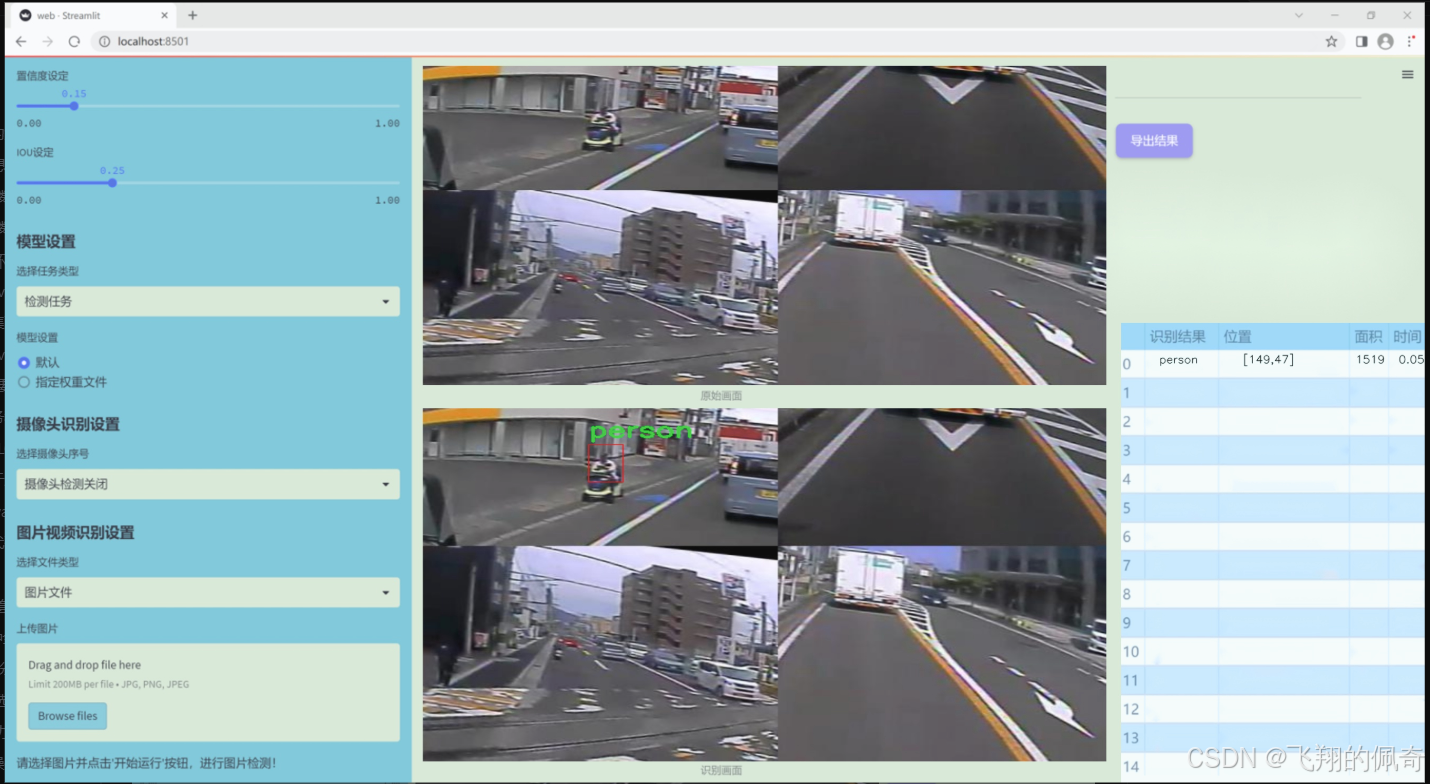
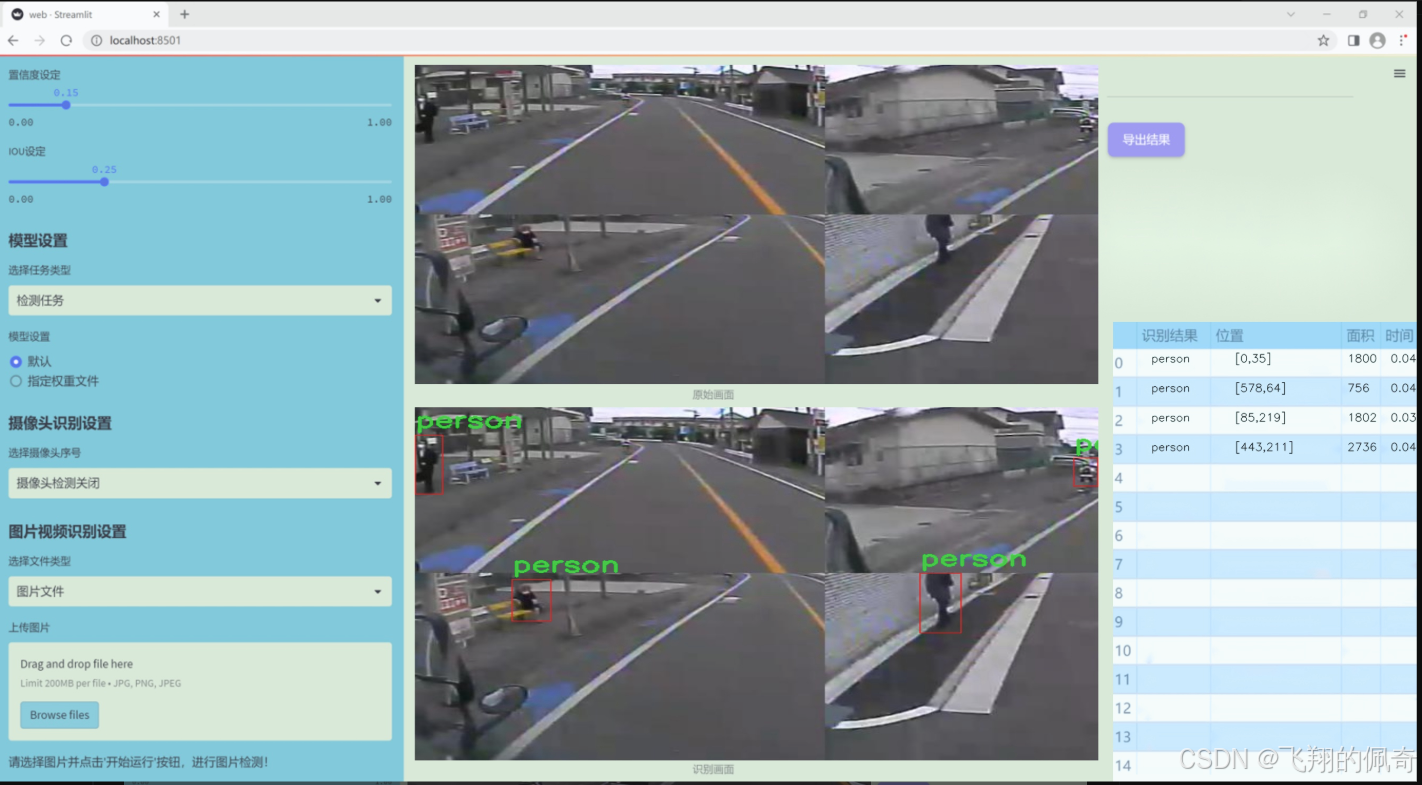
数据集信息
本项目所使用的数据集是为了解决特定领域内的图像识别和分类问题而精心构建的。该数据集包含了来自多个来源的高质量图像,涵盖了多种类别和场景,旨在为深度学习模型的训练提供丰富的样本支持。数据集中的图像经过严格筛选和标注,确保每一张图像都具备准确的标签信息,以便于后续的模型训练和评估。
数据集的构建过程遵循了标准的数据采集和处理流程。首先,通过网络爬虫技术从多个开放资源中获取了大量的图像数据,随后对这些图像进行了去重和清洗,以保证数据的独特性和有效性。接着,专业的标注团队对图像进行了详细的标注工作,确保每个类别的样本数量均衡,涵盖了不同的拍摄角度、光照条件和背景环境,从而提高模型的泛化能力。
此外,为了增强数据集的多样性,我们还采用了数据增强技术,包括旋转、缩放、翻转等多种变换方式,以生成更多的训练样本。这种方法不仅丰富了数据集的内容,还有效地提高了模型在面对不同场景时的鲁棒性。
数据集的设计目标是为研究人员和开发者提供一个可靠的基础,以便于他们在图像识别领域进行深入的研究和开发。通过使用该数据集,研究人员可以更好地理解不同算法在实际应用中的表现,并为未来的研究提供有价值的参考和数据支持。整体而言,本项目的数据集在质量、数量和多样性上都达到了较高的标准,期待能为相关领域的研究贡献力量。





核心代码
以下是经过简化并添加详细中文注释的核心代码部分:
import torch
import torch.nn as nn
import torch.nn.functional as F
class OmniAttention(nn.Module):
def init(self, in_planes, out_planes, kernel_size, groups=1, reduction=0.0625, kernel_num=4, min_channel=16):
super(OmniAttention, self).init()
# 计算注意力通道数
attention_channel = max(int(in_planes * reduction), min_channel)
self.kernel_size = kernel_size
self.kernel_num = kernel_num
self.temperature = 1.0 # 温度参数,用于控制注意力的平滑程度
# 定义网络层self.avgpool = nn.AdaptiveAvgPool2d(1) # 自适应平均池化self.fc = nn.Conv2d(in_planes, attention_channel, 1, bias=False) # 全连接层self.bn = nn.BatchNorm2d(attention_channel) # 批归一化self.relu = nn.ReLU(inplace=True) # ReLU激活函数# 通道注意力self.channel_fc = nn.Conv2d(attention_channel, in_planes, 1, bias=True)self.func_channel = self.get_channel_attention# 过滤器注意力if in_planes == groups and in_planes == out_planes: # 深度可分离卷积self.func_filter = self.skipelse:self.filter_fc = nn.Conv2d(attention_channel, out_planes, 1, bias=True)self.func_filter = self.get_filter_attention# 空间注意力if kernel_size == 1: # 点卷积self.func_spatial = self.skipelse:self.spatial_fc = nn.Conv2d(attention_channel, kernel_size * kernel_size, 1, bias=True)self.func_spatial = self.get_spatial_attention# 核心注意力if kernel_num == 1:self.func_kernel = self.skipelse:self.kernel_fc = nn.Conv2d(attention_channel, kernel_num, 1, bias=True)self.func_kernel = self.get_kernel_attentionself._initialize_weights() # 初始化权重def _initialize_weights(self):# 权重初始化for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)if isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)@staticmethod
def skip(_):return 1.0 # 跳过操作,返回1def get_channel_attention(self, x):# 计算通道注意力channel_attention = torch.sigmoid(self.channel_fc(x).view(x.size(0), -1, 1, 1) / self.temperature)return channel_attentiondef get_filter_attention(self, x):# 计算过滤器注意力filter_attention = torch.sigmoid(self.filter_fc(x).view(x.size(0), -1, 1, 1) / self.temperature)return filter_attentiondef get_spatial_attention(self, x):# 计算空间注意力spatial_attention = self.spatial_fc(x).view(x.size(0), 1, 1, 1, self.kernel_size, self.kernel_size)spatial_attention = torch.sigmoid(spatial_attention / self.temperature)return spatial_attentiondef get_kernel_attention(self, x):# 计算核心注意力kernel_attention = self.kernel_fc(x).view(x.size(0), -1, 1, 1, 1, 1)kernel_attention = F.softmax(kernel_attention / self.temperature, dim=1)return kernel_attentiondef forward(self, x):# 前向传播x = self.avgpool(x) # 自适应平均池化x = self.fc(x) # 全连接层x = self.bn(x) # 批归一化x = self.relu(x) # ReLU激活return self.func_channel(x), self.func_filter(x), self.func_spatial(x), self.func_kernel(x) # 返回各类注意力
class AdaptiveDilatedConv(nn.Module):
“”“自适应扩张卷积类,封装了可调节的卷积操作”“”
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True):super(AdaptiveDilatedConv, self).__init__()# 初始化卷积层self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)self.omni_attention = OmniAttention(in_planes=in_channels, out_planes=out_channels, kernel_size=kernel_size) # 实例化OmniAttentiondef forward(self, x):# 前向传播attention_outputs = self.omni_attention(x) # 计算注意力x = self.conv(x) # 进行卷积操作# 将注意力应用到卷积结果上return x * attention_outputs[0] # 使用通道注意力调整卷积输出
代码说明:
OmniAttention类:实现了一个多种注意力机制的模块,包括通道注意力、过滤器注意力、空间注意力和核心注意力。通过对输入特征进行处理,生成不同的注意力权重。
AdaptiveDilatedConv类:自适应扩张卷积层,结合了可调节的卷积操作和OmniAttention模块。它通过注意力机制来调整卷积的输出,增强模型的表达能力。
注意:
以上代码是核心部分,去掉了其他不必要的实现细节和辅助函数,专注于注意力机制和自适应卷积的实现。
这个程序文件 fadc.py 是一个深度学习模型的实现,主要使用 PyTorch 框架,包含了一些自定义的卷积层和注意力机制。代码中涉及的主要组件包括 OmniAttention、FrequencySelection、AdaptiveDilatedConv 和 AdaptiveDilatedDWConv。
首先,OmniAttention 类实现了一种全局注意力机制,能够对输入的特征图进行通道、过滤器、空间和内核的注意力计算。构造函数中定义了多个卷积层和激活函数,用于生成不同类型的注意力权重。forward 方法中首先对输入进行平均池化,然后通过一系列卷积层计算出不同的注意力权重,最后返回这些权重。
接下来,generate_laplacian_pyramid 函数用于生成拉普拉斯金字塔,这是一种图像处理技术,可以提取图像的不同频率成分。该函数通过逐层下采样输入张量,计算每一层的拉普拉斯图像,并将其存储在金字塔列表中。
FrequencySelection 类实现了一种频率选择机制,允许模型在不同频率范围内选择特征。构造函数中定义了多个卷积层和池化层,支持不同的池化类型(如平均池化和拉普拉斯池化)。forward 方法中根据选择的池化类型处理输入特征,并计算出相应的频率权重。
AdaptiveDilatedConv 和 AdaptiveDilatedDWConv 类是自定义的可调稀疏卷积层,分别用于标准卷积和深度可分离卷积。它们的构造函数中定义了偏移量卷积和掩码卷积,支持不同的填充模式和频率选择机制。在 forward 方法中,首先计算偏移量和掩码,然后使用 modulated_deform_conv2d 函数进行可调卷积操作。
整体来看,这个文件实现了一个复杂的卷积神经网络模块,结合了注意力机制和频率选择技术,旨在提高模型对不同频率特征的敏感性和表达能力。代码中使用了多种深度学习技术,适合用于图像处理、计算机视觉等领域的研究和应用。
10.4 SMPConv.py
以下是经过简化和注释的核心代码部分:
import torch
import torch.nn as nn
import torch.nn.functional as F
定义相对位置函数,生成一个相对位置的坐标张量
def rel_pos(kernel_size):
tensors = [torch.linspace(-1, 1, steps=kernel_size) for _ in range(2)]
kernel_coord = torch.stack(torch.meshgrid(*tensors), dim=-0) # 生成网格坐标
kernel_coord = kernel_coord.unsqueeze(0) # 增加一个维度
return kernel_coord
定义SMP卷积层
class SMPConv(nn.Module):
def init(self, planes, kernel_size, n_points, stride, padding, groups):
super().init()
self.planes = planes
self.kernel_size = kernel_size
self.n_points = n_points
self.init_radius = 2 * (2/kernel_size) # 初始化半径
# 生成相对位置坐标kernel_coord = rel_pos(kernel_size)self.register_buffer('kernel_coord', kernel_coord) # 注册为缓冲区,不会被优化# 权重坐标初始化weight_coord = torch.empty(1, n_points, 2)nn.init.trunc_normal_(weight_coord, std=0.2, a=-1., b=1.) # 截断正态分布初始化self.weight_coord = nn.Parameter(weight_coord) # 注册为可训练参数# 半径参数初始化self.radius = nn.Parameter(torch.empty(1, n_points).unsqueeze(-1).unsqueeze(-1))self.radius.data.fill_(value=self.init_radius)# 权重初始化weights = torch.empty(1, planes, n_points)nn.init.trunc_normal_(weights, std=.02)self.weights = nn.Parameter(weights)def forward(self, x):kernels = self.make_kernels().unsqueeze(1) # 生成卷积核x = x.contiguous() # 确保输入张量是连续的kernels = kernels.contiguous()# 根据输入数据类型选择合适的深度可分离卷积实现if x.dtype == torch.float32:x = _DepthWiseConv2dImplicitGEMMFP32.apply(x, kernels)elif x.dtype == torch.float16:x = _DepthWiseConv2dImplicitGEMMFP16.apply(x, kernels)else:raise TypeError("Only support fp32 and fp16, get {}".format(x.dtype))return x def make_kernels(self):# 计算卷积核diff = self.weight_coord.unsqueeze(-2) - self.kernel_coord.reshape(1, 2, -1).transpose(1, 2) # 计算差值diff = diff.transpose(2, 3).reshape(1, self.n_points, 2, self.kernel_size, self.kernel_size)diff = F.relu(1 - torch.sum(torch.abs(diff), dim=2) / self.radius) # 应用ReLU激活函数# 计算最终的卷积核kernels = torch.matmul(self.weights, diff.reshape(1, self.n_points, -1)) # 加权卷积核kernels = kernels.reshape(1, self.planes, *self.kernel_coord.shape[2:]) # 调整形状kernels = kernels.squeeze(0)kernels = torch.flip(kernels.permute(0, 2, 1), dims=(1,)) # 反转维度return kernels
定义SMPBlock模块
class SMPBlock(nn.Module):
def init(self, in_channels, dw_channels, lk_size, drop_path, n_points=None, n_points_divide=4):
super().init()
self.pw1 = nn.Sequential(
nn.Conv2d(in_channels, dw_channels, kernel_size=1, stride=1, padding=0, groups=1, bias=False),
nn.BatchNorm2d(dw_channels),
nn.ReLU()
)
self.pw2 = nn.Conv2d(dw_channels, in_channels, kernel_size=1, stride=1, padding=0, groups=1, bias=False)
self.large_kernel = SMPConv(in_channels=dw_channels, out_channels=dw_channels, kernel_size=lk_size,
stride=1, groups=dw_channels, n_points=n_points, n_points_divide=n_points_divide)
self.drop_path = nn.Identity() # 可选的drop path
def forward(self, x):out = self.pw1(x) # 第一个1x1卷积out = self.large_kernel(out) # 大卷积核out = self.pw2(out) # 第二个1x1卷积return x + self.drop_path(out) # 残差连接
代码说明:
rel_pos函数:生成一个给定大小的相对位置坐标张量,用于卷积核的相对位置计算。
SMPConv类:自定义的卷积层,使用深度可分离卷积,支持动态生成卷积核。包含初始化权重、半径和相对位置坐标的逻辑。
make_kernels方法:计算卷积核的逻辑,使用权重和位置差值生成最终的卷积核。
SMPBlock类:构建一个包含两个1x1卷积和一个SMP卷积的模块,支持残差连接。
这个程序文件 SMPConv.py 实现了一个自定义的卷积神经网络模块,主要包括了一个名为 SMPConv 的卷积层以及一些辅助的类和函数,用于构建更复杂的网络结构。以下是对代码的详细讲解。
首先,程序导入了必要的库,包括 PyTorch 的核心模块、深度学习中的常用功能模块,以及一些自定义的模块和层。特别是,尝试导入深度可分离卷积的实现,如果导入失败则会忽略。
rel_pos 函数用于生成相对位置的坐标,输入为卷积核的大小,输出为一个包含相对位置的张量。
SMPConv 类是核心卷积模块的实现。其构造函数中定义了多个参数,包括输出通道数、卷积核大小、采样点数、步幅、填充和分组卷积的参数。该类还定义了卷积核的相对位置和权重坐标,并初始化了一些参数。forward 方法实现了前向传播,使用深度可分离卷积的实现来处理输入数据。
make_kernels 方法生成卷积核。它通过计算权重坐标与卷积核坐标之间的差异,应用 ReLU 激活函数,并通过加权平均生成最终的卷积核。
radius_clip 方法用于限制半径的范围,确保其在指定的最小值和最大值之间。
get_conv2d 函数根据输入参数决定返回自定义的 SMPConv 或标准的 nn.Conv2d 卷积层。
enable_sync_bn 和 get_bn 函数用于控制批归一化的类型,支持同步批归一化和标准批归一化。
conv_bn 和 conv_bn_relu 函数分别构建带有批归一化和激活函数的卷积层,简化了网络结构的定义。
fuse_bn 函数用于将卷积层和批归一化层融合,以提高推理速度。
SMPCNN 类是一个包含自定义卷积层和小卷积层的网络模块。它在前向传播中将两个卷积的输出相加,形成最终的输出。
SMPCNN_ConvFFN 类实现了一个前馈网络,包含两个逐点卷积层和一个非线性激活函数。它使用 DropPath 技术来实现随机丢弃路径的功能。
SMPBlock 类是一个基本的块结构,包含两个逐点卷积层和一个大型卷积层,使用 ReLU 激活函数和 DropPath 技术来增强网络的表达能力。
总体来说,这个文件实现了一个灵活且可扩展的卷积神经网络模块,结合了自定义的卷积操作和常规的卷积层,适用于各种深度学习任务。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻