基于pycharm和anaconda的yolo简单部署测试
目录
基本环境准备(配环境):
1.1.conda安装
1.2.conda虚拟环境
1.3.pycharm配置conda编译器
1.3.1. 新项目
1.3.2.已有项目
数据集处理:
2.1.数据标注
2.2.标签转换
2.3.数据集配置
简单测试和调试
3.1.引入测试数据
3.2.模型使用和测试
3.2.1.初此运行
3.2.2.继续运行
3.2.3.调超参
本次测试着重于如何使用yolo完成:数据集的标注,数据集的使用,yolo的运行测试,yolo的调参。
基本环境准备(配环境):
1.1.conda安装
下载网站: Download Anaconda Distribution | Anaconda
需要登陆请自行登录,登录后耐心等待

整个安装过程全部默认即可,修改安装地址也不影响,无需安装python,因为我们会在conda虚拟环境中配置。
上述不是重点,如有疑惑请参考其他conda配置文章。
1.2.conda虚拟环境
创建虚拟环境:在Anaconda中创建一个虚拟环境(非C盘向)_conda虚拟环境必须创建在c盘吗-CSDN博客
安装cuda和torch:
基于Anacoda安装cuda和torch(GPU向)_conda,cpuda12.6,12.8,12.9应该安哪个-CSDN博客
配置好后conda prompt不要关掉,后续需要安装什么库直接在这里输入指令就行(pycharm终端也行,但是管理员方式打开可以避免权限问题)
1.3.pycharm配置conda编译器
1.3.1. 新项目
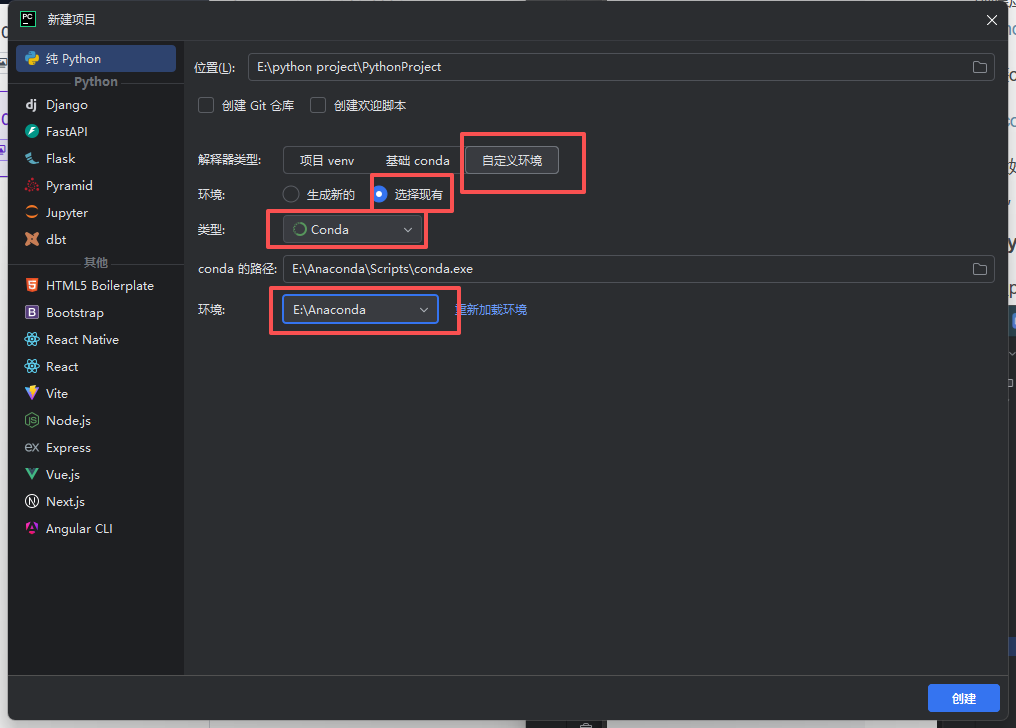
进入pycharm,创建新项目,如此选择。
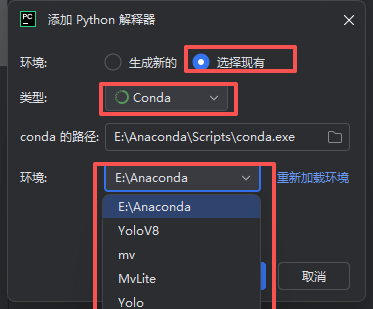
点击对应选项,使其设置为:选择现有,类型为conda,不用修改conda路径,点击环境就会显示你配置好的conda环境,如果没有点击“重新加载环境”。选择完确定即可。
1.3.2.已有项目
看右下角,一开始显示的可能是“无编译器”或者其他编译器,点击
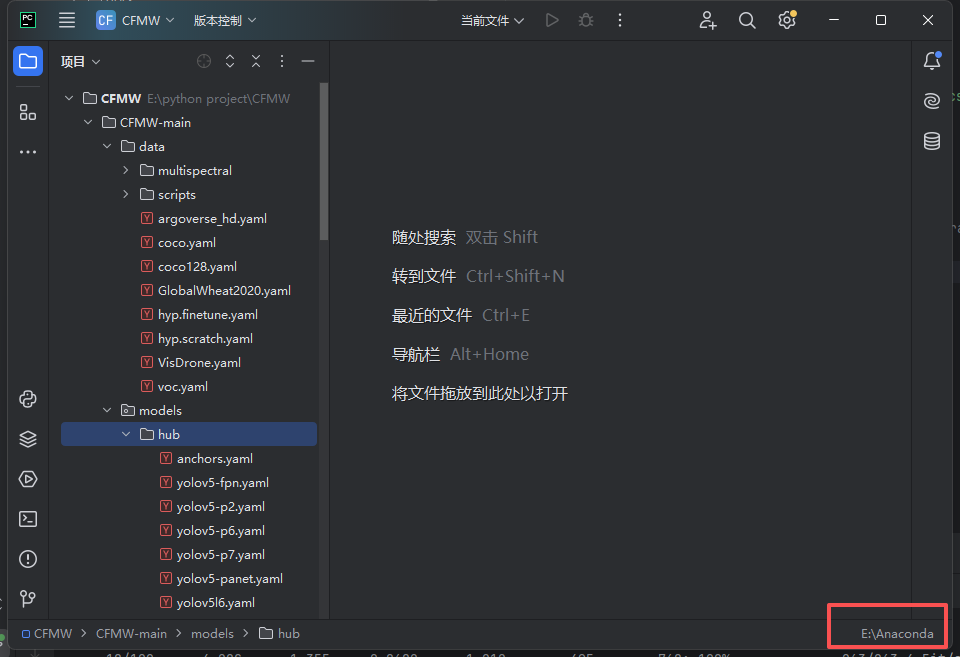
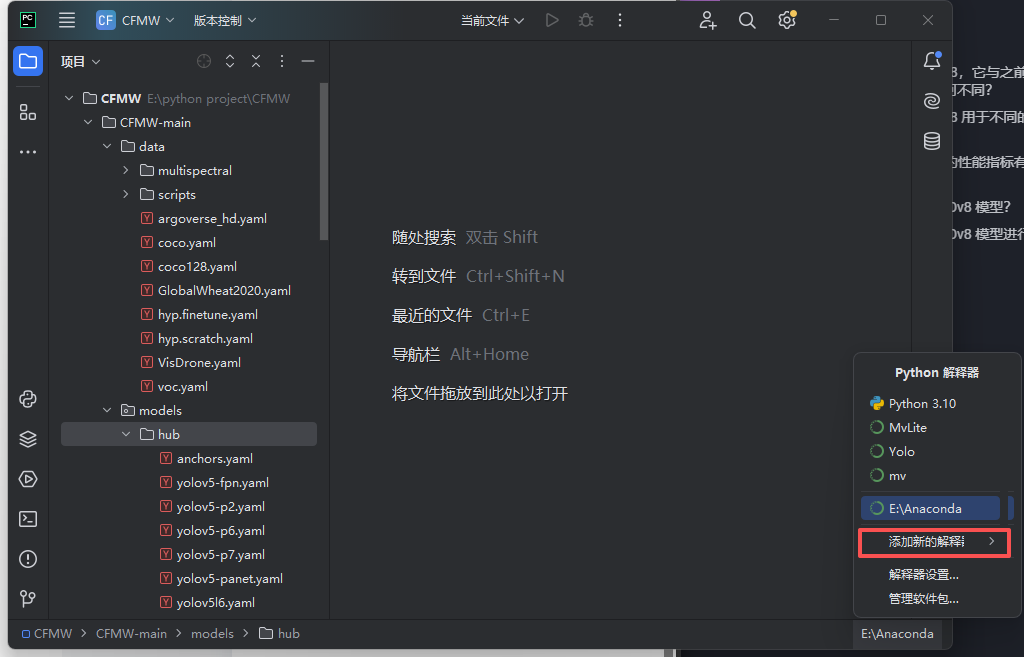
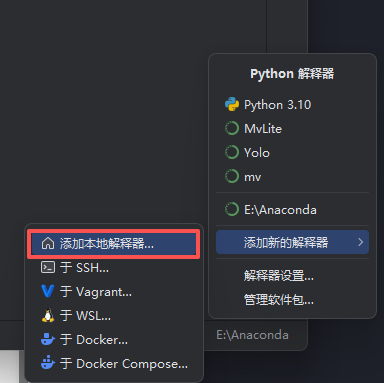
点击对应选项,使其设置为:选择现有,类型为conda,不用修改conda路径,点击环境就会显示你配置好的conda环境,如果没有点击“重新加载环境”。选择完确定即可。
数据集处理:
2.1.数据标注
本文介绍采用labelme打标签,在终端/conda命令行激活conda环境,输入指令安装labelme
pip install labelme labelme2yolo
启动标注页面
labelme
打开你想标注图片所在的文件夹。
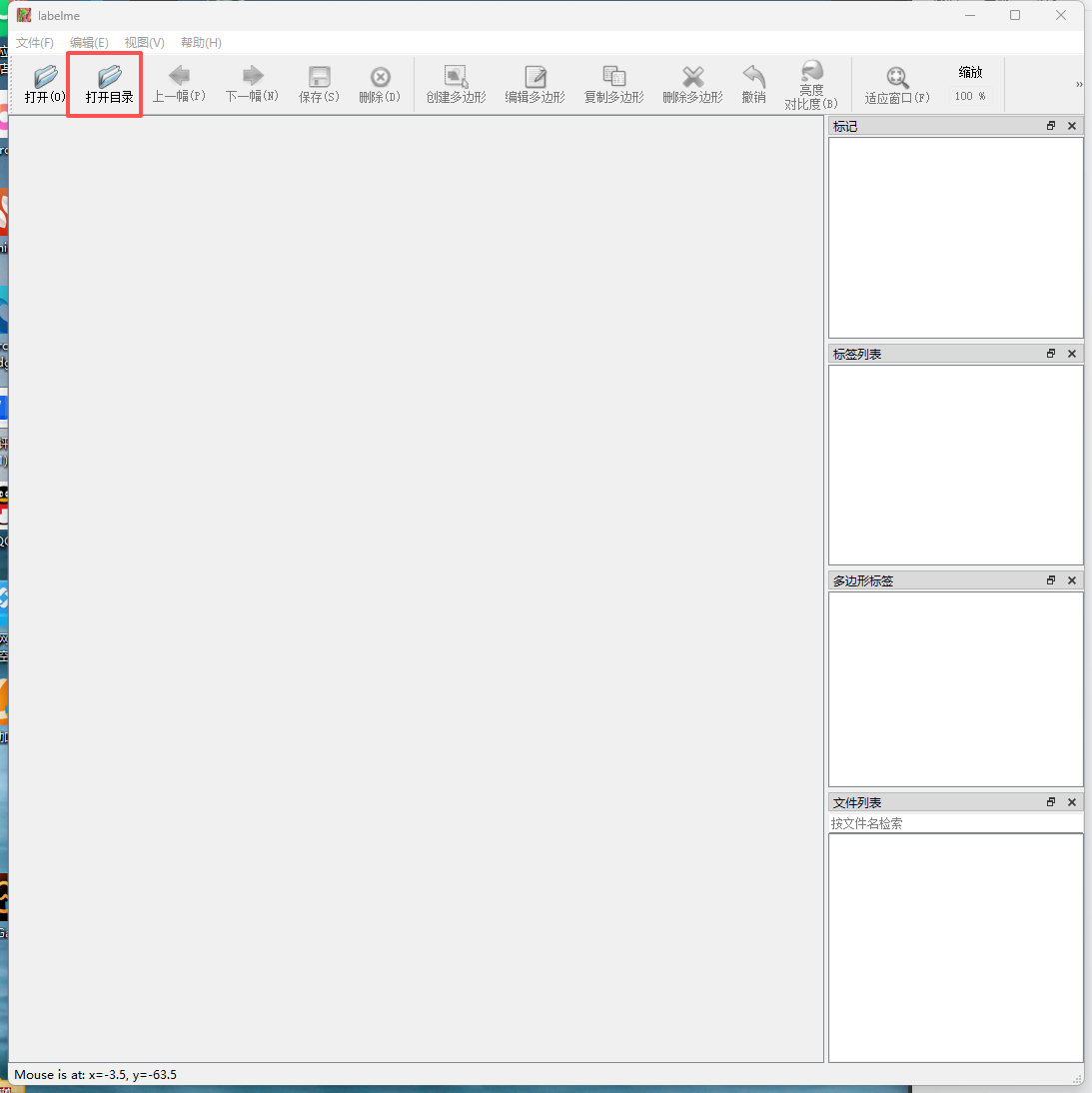
选择好后会自动出现第一张图片,可以通过点击上一幅和下一幅切换图片。点击左上角编辑,找到创建矩形。
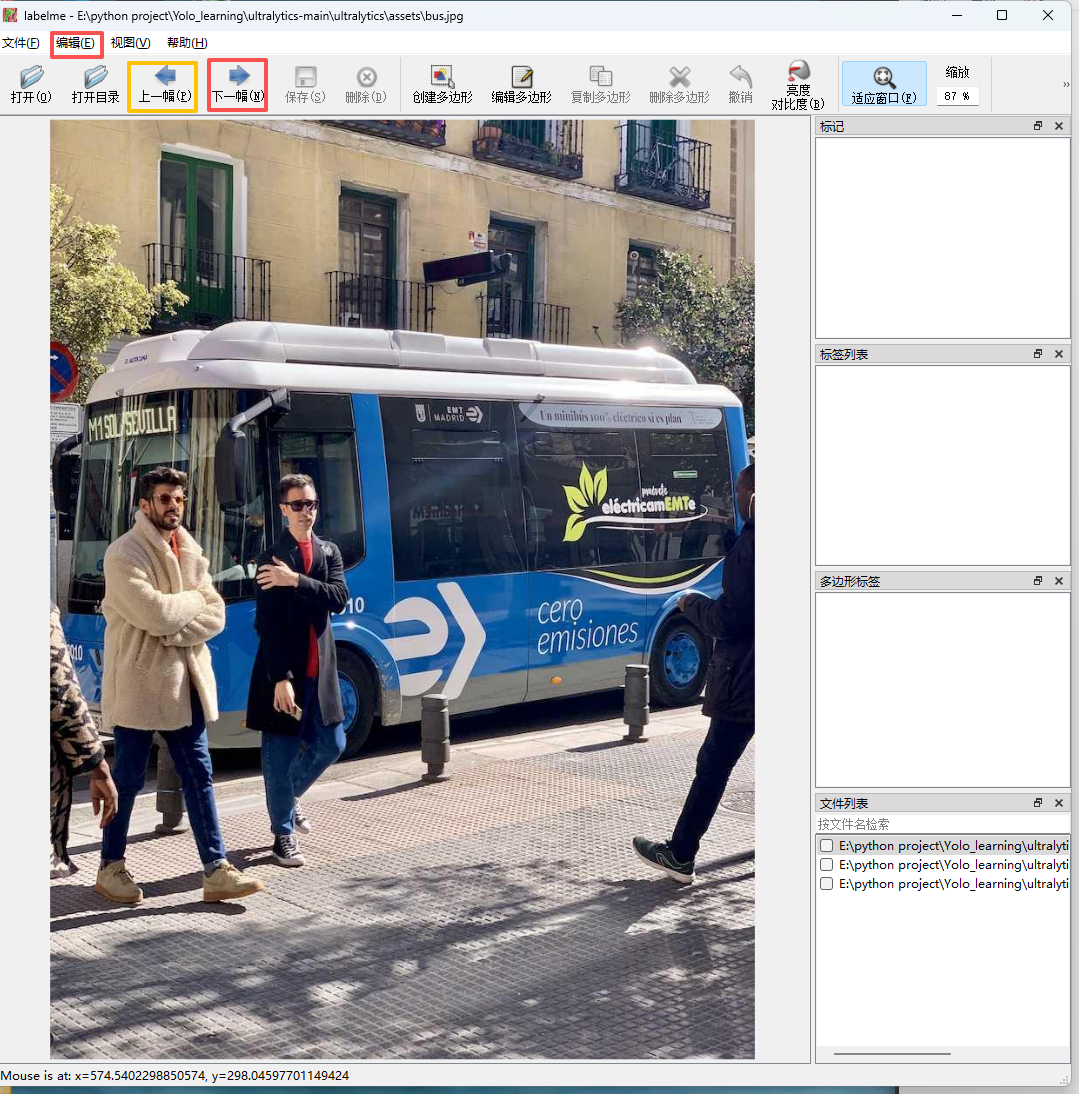
点击图片中的某个点开始拉伸矩形框,再点一下结束拉伸,出现编辑标签界面。矩形框应该尽量准确,不要过多框入无关背景。
设置人的类号为0,所有”人“的类号是一样的。点击ok确认。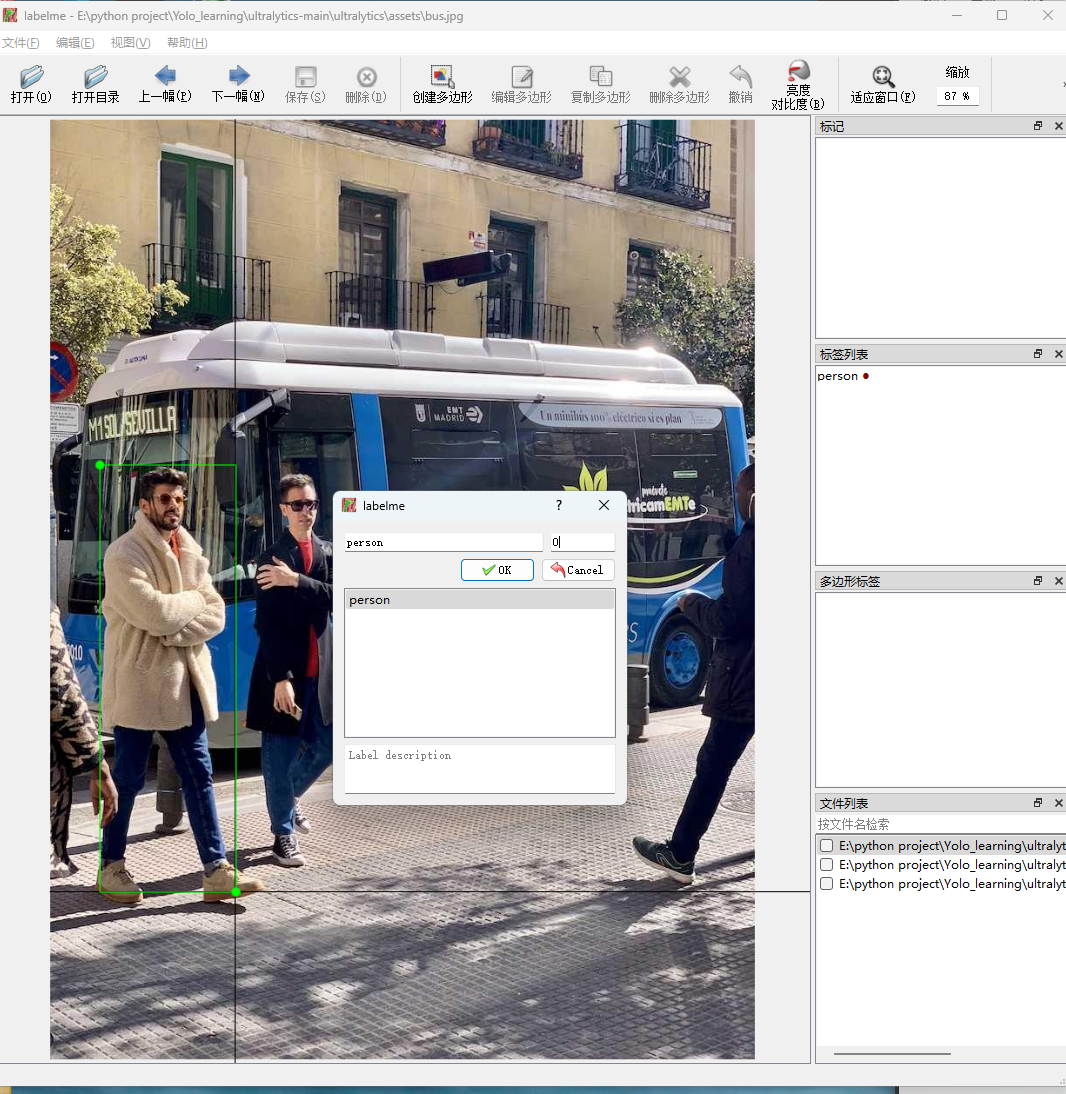
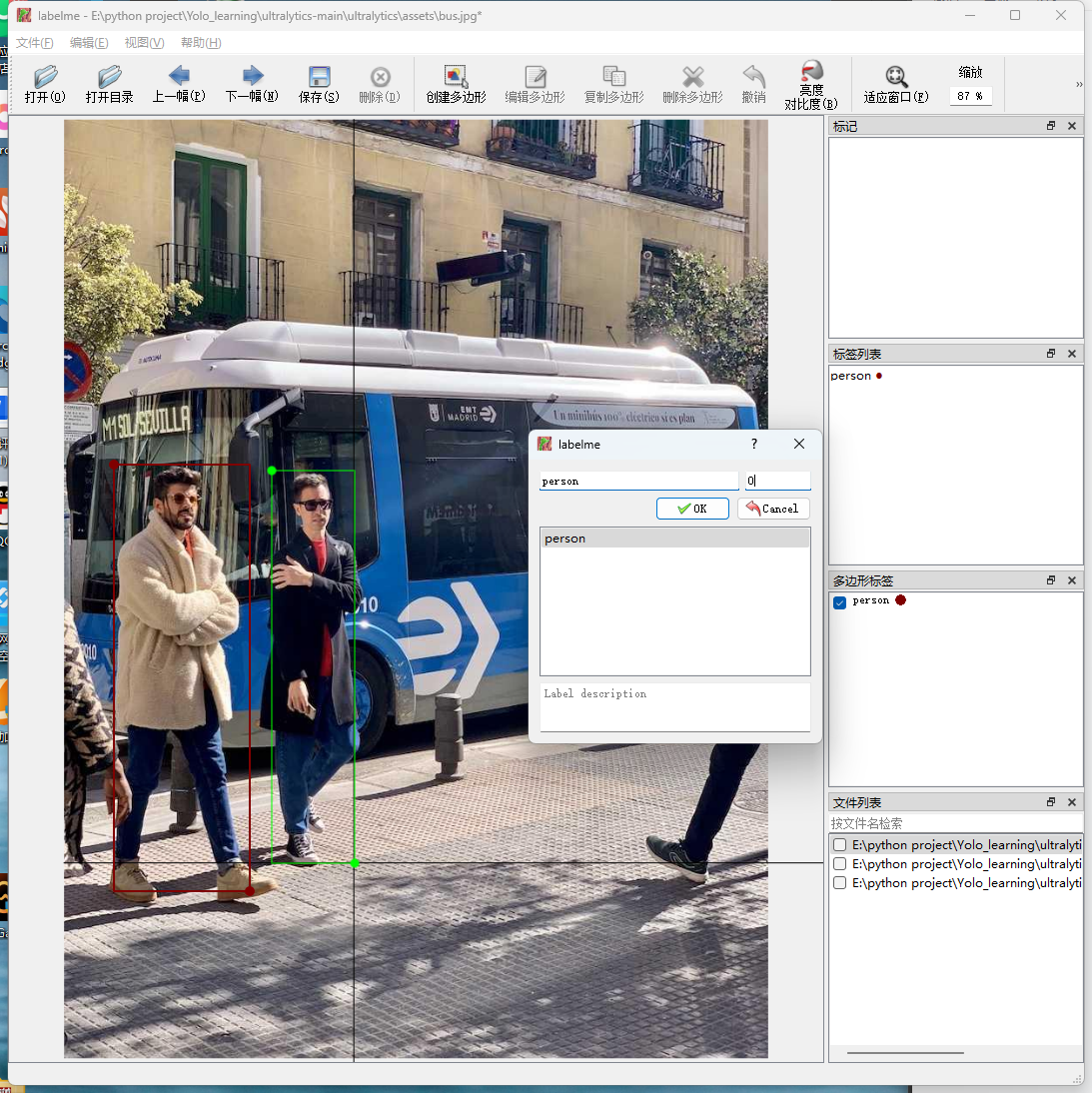
标注一个公交车,类号为1,标注一个禁止标志,类号为2。
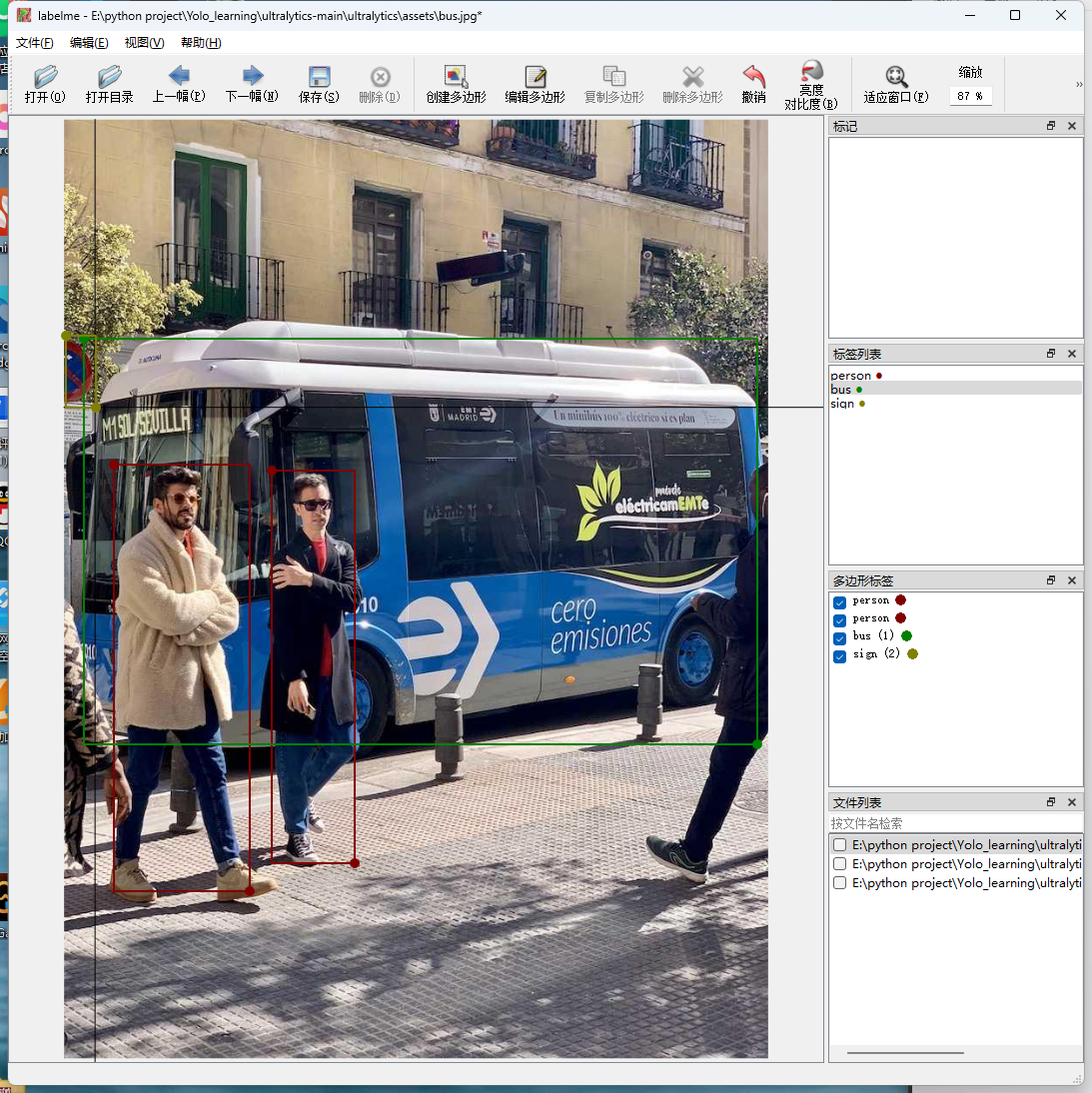
ctrl+s 保存,查看json文件。
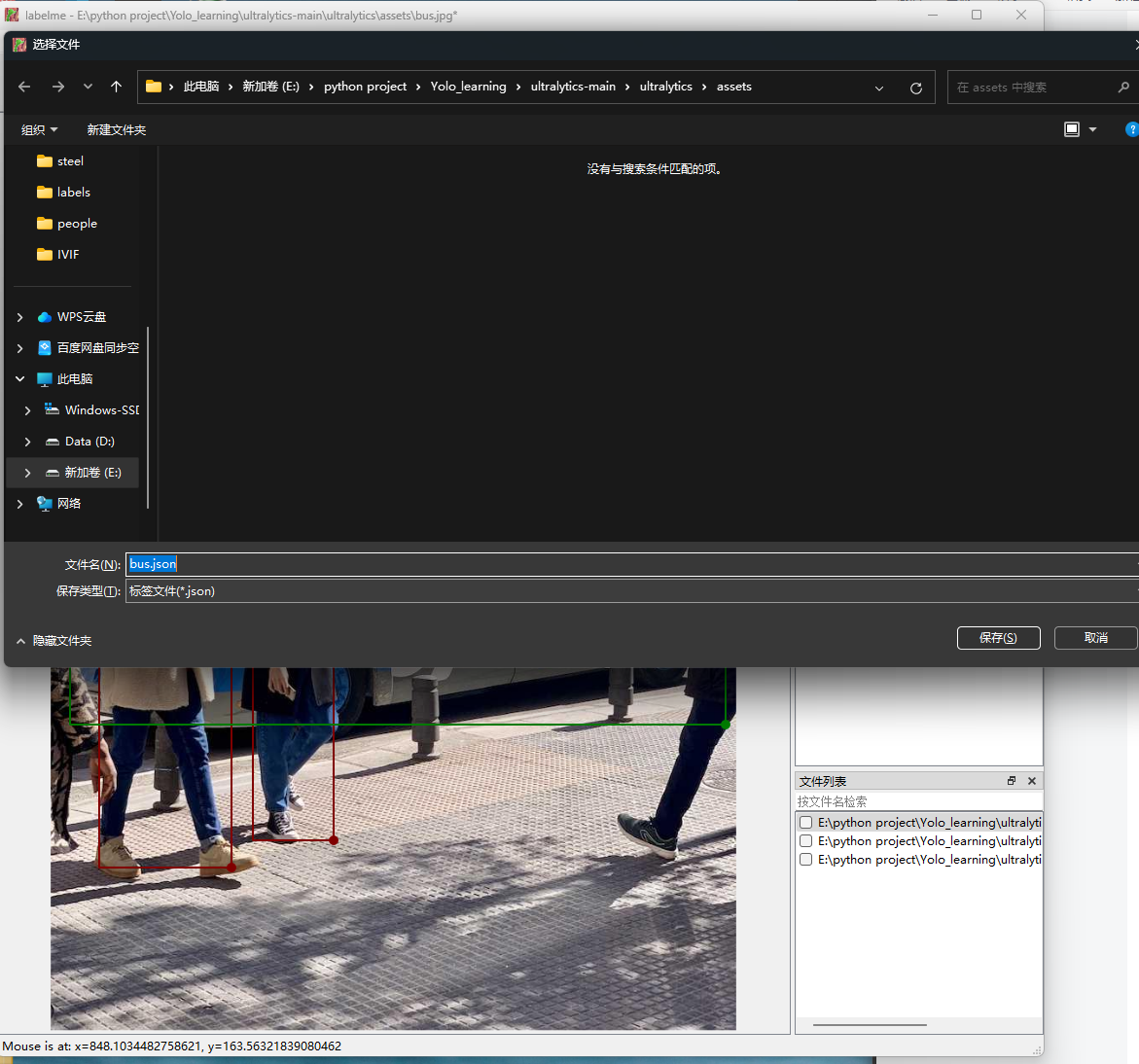
json文件显示如下:
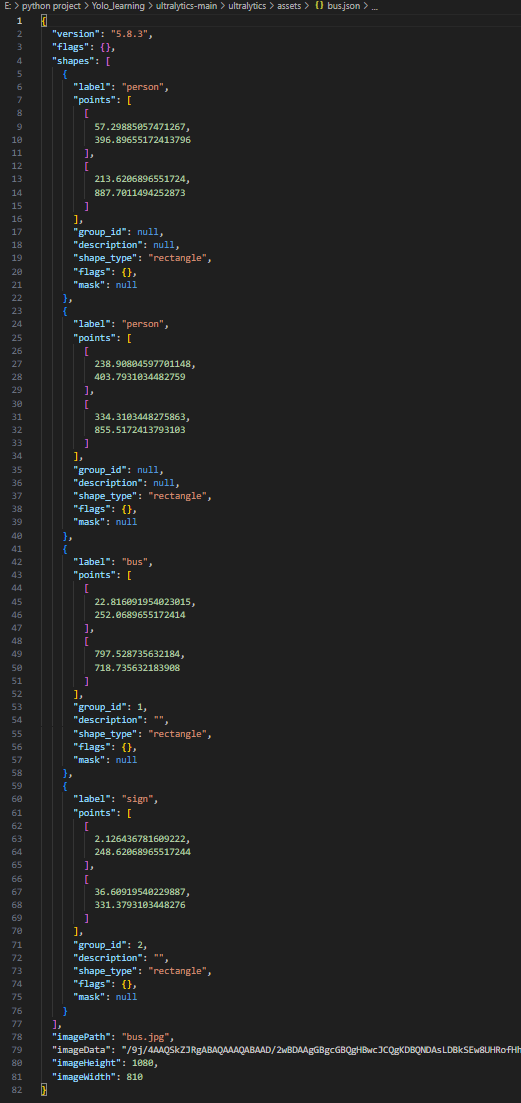
正如代码中所描述的,组号group_id,标签框的形状shape_type,标签名label。
为什么标注时类号为0时 json文件里显示group_id为null?
这个细节其实涉及到 LabelMe 的 JSON 结构设计理念,group_id是给分割、多形状任务(如 instance segmentation)用的,不影响 YOLO 检测训练
| 字段名 | 含义 | 举例 | 是否影响 YOLO |
|---|---|---|---|
label | 类别名称(你选的类名) | "T-beam", "I-beam" | 是 YOLO 类别依据 |
group_id | 实例组编号(用于“同一目标多形状”情况) | null 或 1, 2, … | YOLO 不使用 |
因此,这个id在矩形标注时是自动分配的,意义不大。
2.2.标签转换
刚打好的标签是json格式的,而yolo的输入是需要txt格式的,因此我们采用一个简单的脚本把一个文件夹中的所有json文件转换成yolo可以接受的形式。
注意将json_dir和out_dir改成自己需要的内容。
import json, os
from pathlib import Pathjson_dir = Path(r"E:\dataset\labelme_json")
out_dir = Path(r"E:\dataset\yolo_labels"); out_dir.mkdir(exist_ok=True)
for jpath in json_dir.glob("*.json"):data = json.load(open(jpath, encoding="utf-8"))W, H = data["imageWidth"], data["imageHeight"]out = ""for shp in data["shapes"]:pts = [(x/W, y/H) for x, y in shp["points"]]cls = 0 # 或按类别名映射out += f"{cls} " + " ".join([f"{x:.6f} {y:.6f}" for x, y in pts]) + "\n"open(out_dir / f"{jpath.stem}.txt", "w", encoding="utf-8").write(out)
运行后查看我们刚才标注好的图片.json转换成的.txt。
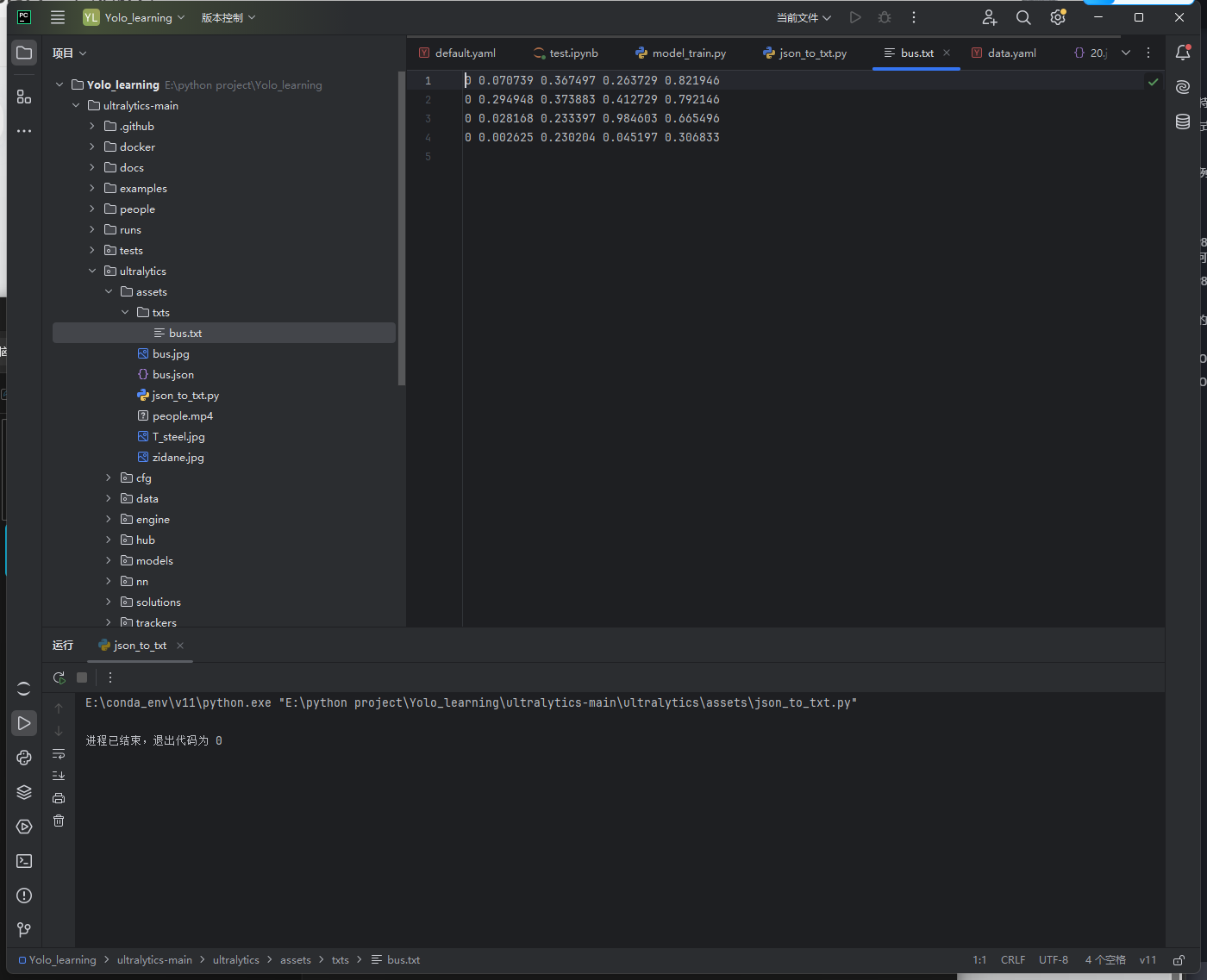
到这里数据集标注就完成了。
2.3.数据集配置
数据集设计好了,是需要让模型识别,并找到对应的比如,train,test,valid。那么需要给出一个配置文件,标准命名为:data.yaml。
一般格式:
1. 把图片放在一个文件夹中,把标签放在另一个文件夹中,分别命名为images和labels。
2.给出train,test,valid,每个文件夹中都有images和labels。
3.不规范的命名,需要修改yaml文件中的路径为绝对地址,有不识别风险,不推荐。
在images和labels文件内,一般存在train,valid和test文件夹,分别存储用来训练,验证和测试的图片集/标签集。其结构应如下:
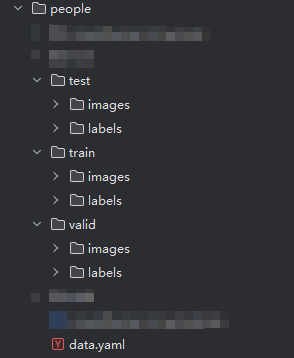
如图所示,这是两个data.yaml文件,都是合法的:
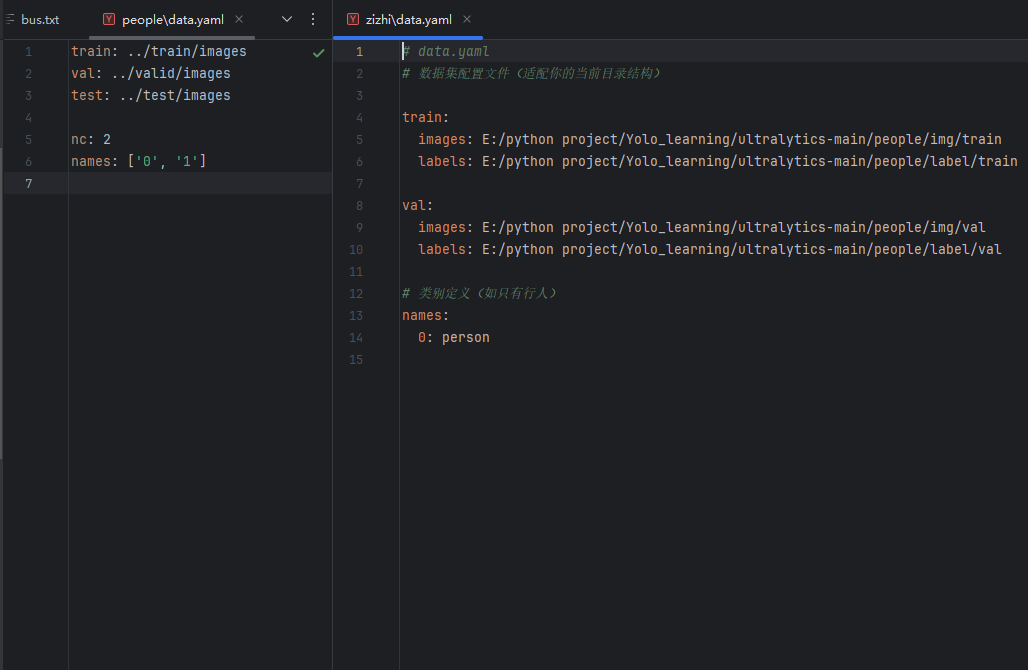
其中,左侧文件定义了三个路径,分别是训练/验证/测试集的位置,定义了两个类0和1,采用的是相对路径,这意味着,data.yaml必须如上图目录中的位置放置。(从bash语法上看,先定位到data.yaml所在文件夹,然后进入train——images,其他同理)
对于右侧文件,定义了一个类并声明了类名,同时在train和val中均给出了图片和标签的绝对路径,而且其绝对路径中的文件夹命名并不标准,如img、val这种,也就是说如果使用了不标准的命名,存在模型无法识别的风险,因此需要绝对路径,这也是不推荐这种方法的原因。
为什么左侧没有明确给出标签的路径?
这也是yolo默认的规则,给出了图片的地址,他会去检索同级文件夹中是否存在labels文件,如果你是按images和labels中分别存储,它同样会检测images的统计文件夹。
简单测试和调试
3.1.引入测试数据
此处我们采用开源的人物数据集:https://universe.roboflow.com/objectdetection-1gccs/crowdhuman-dtwxp/dataset/1/
可能会有注册界面,在本处不提了。
我们下载一个yolov11的对应数据集,点击YOLOV11
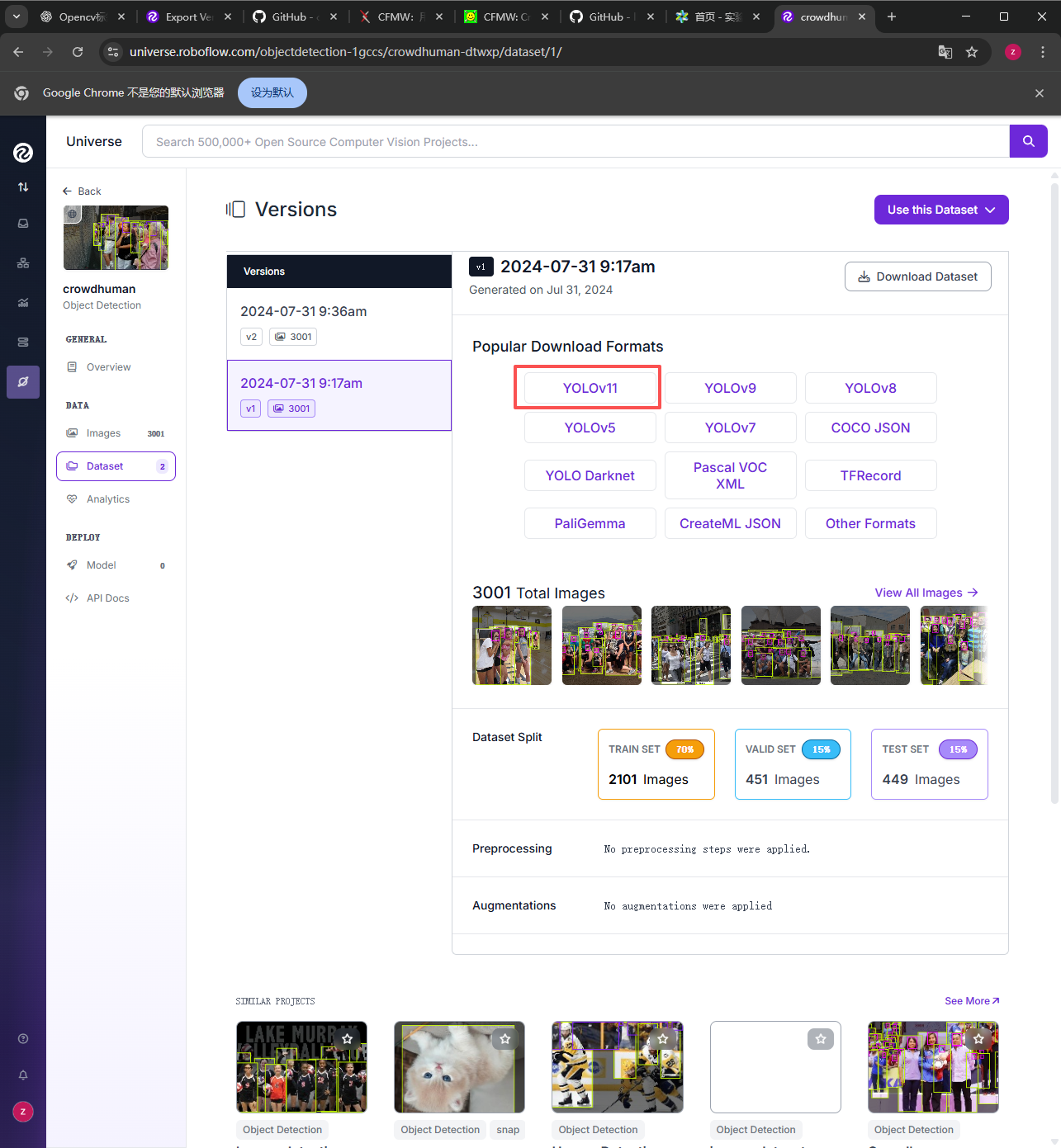
点击下载为压缩包形式,然后点击continue继续。
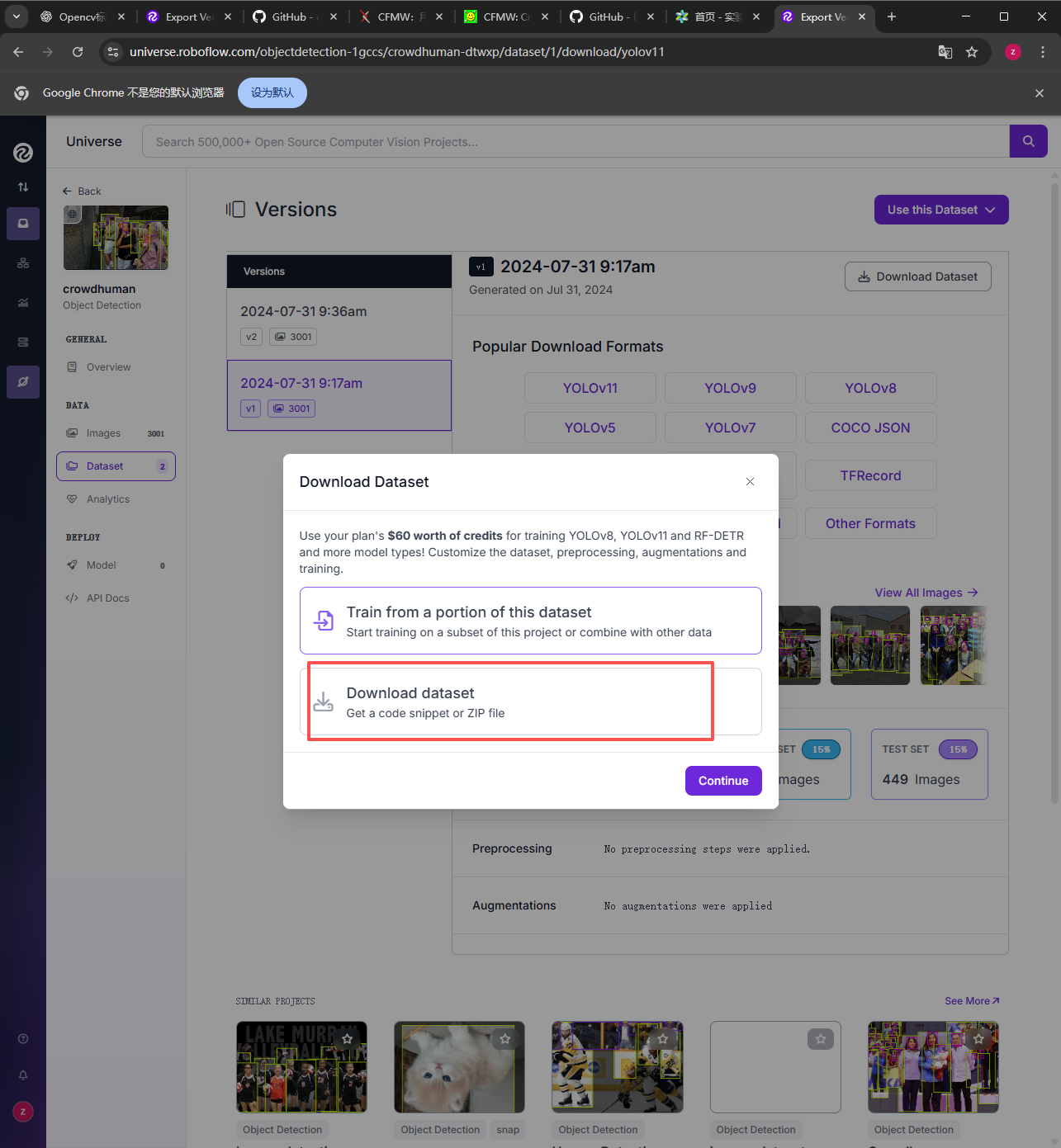
弹出下载界面选择下载压缩包到电脑,然后continue继续。
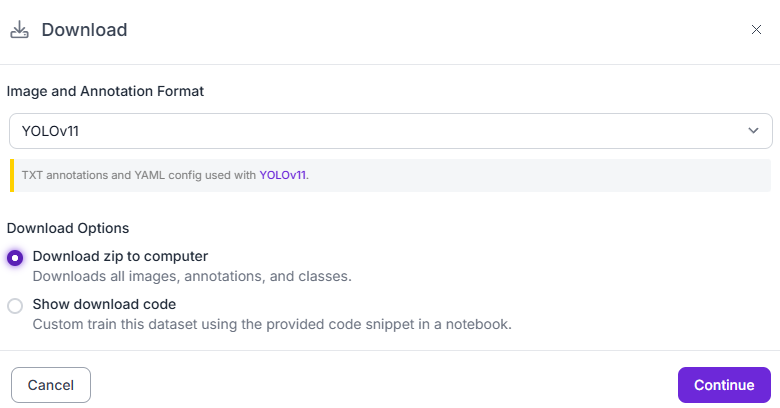
等待加载界面后开始下载,下载后解压,解压后载入到pycharm,结构应是如此:
正如我们刚才所说,数据集的格式,配置都是标准形式可以直接使用。上图给的是以前下载过的yolov8数据集的文件结构,大体都一样,不用在意。
3.2.模型使用和测试
3.2.1.初此运行
首先安装必须的yolo库,现在改名为ultralytics。
pip install ultralytics# model_train.py
from ultralytics import YOLOif __name__ == "__main__":# 1. 加载模型(检测或分割)model = YOLO("yolo11n.pt") # 或 yolov11n-seg.pt# 2. 开始训练model.train(data="E:/python project/Yolo_learning/ultralytics-main/people/data.yaml",epochs=100, # 训练轮数imgsz=768, # 图片尺度batch=8, # 特征图数量device=0, # GPU:若无GPU则改为 "cpu"workers=0, # Windows设 0 避免报错name="train_person_y11"# 输出保存到 ../runs/detect/train_person_y11)
我们给出了一个简单的采用官方训练好的模型进行训练的代码,其中设置了几个默认参数,注意修改data为自己想要的绝对路径,这样无论是我们这个脚本在哪,只要有conda环境的加持就能顺利运行。
因为采用了官方模型,所以第一次运行需要从官网获取pt文件,然后由于这个数据集比较大,建议不要把epoch给的太高,并且如果你的显卡的显存小于6G,那么建议你把imgsz调小防止爆显存。
3.2.2.继续运行
在上一轮运行完之后,我们应该在data.yaml所在的文件夹的中,也就是母文件夹中找到一个
runs/detect/train_person_y11路径,如下图,这是第一次训练的结果。
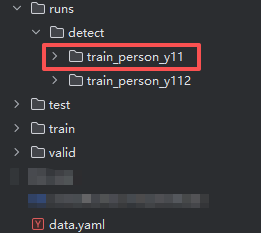
我们可以在这个文件夹中的weights文件夹中找到上一轮训练最优的pt文件,这里储存着最优结果出现时的网络参数。(如果你学过神经网络和CNN可以明白)
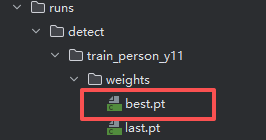
我们修改代码如下,将原来的官方模型换成我们上一轮的最优模型:
# model_train.py
from ultralytics import YOLOif __name__ == "__main__":# 1. 加载模型(检测或分割)model = YOLO(r"E:\python project\Yolo_learning\ultralytics-main\people\runs\detect\train_person_y11\weights\best.pt") # 或 yolov11n-seg.pt# 2. 开始训练model.train(data="E:/python project/Yolo_learning/ultralytics-main/people/data.yaml",epochs=100,imgsz=768,batch=8,device=0, # GPU:0,若无GPU则改为 "cpu"workers=0, # Windows 建议设 0 避免多进程报错name="train_person_y11"# 输出保存到 runs/detect/train_person_y11)
注意把里面model的路径换成你自己项目中best.pt的绝对路径。那么同时,你也可以换成那个last.pt,也就是上一轮最后一次训练后你神经网络中的参数。
name是可以不用修改的,正如上面图片所示,出现了_y11和_y112,也就是说你第二次训练会自动给文件标号。
3.2.3.调超参
对于不同任务,train,predict等,能调的超参是有所不同的,因此我们应该参照:主页 - Ultralytics YOLO 文档
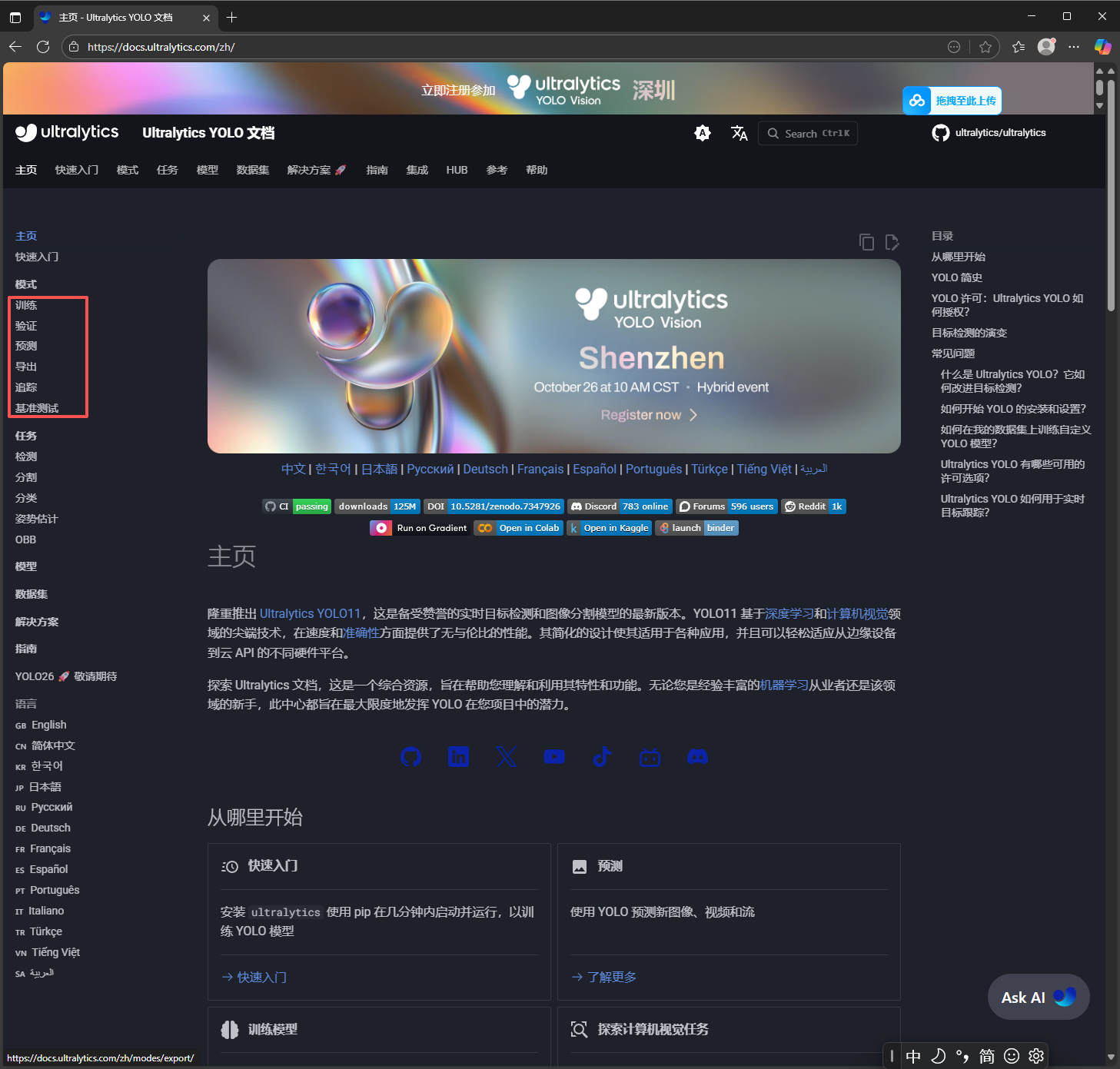
左侧圈中的就是几类基本的任务,点进去往下翻任务中的参数的解释和初始值都给出来了:
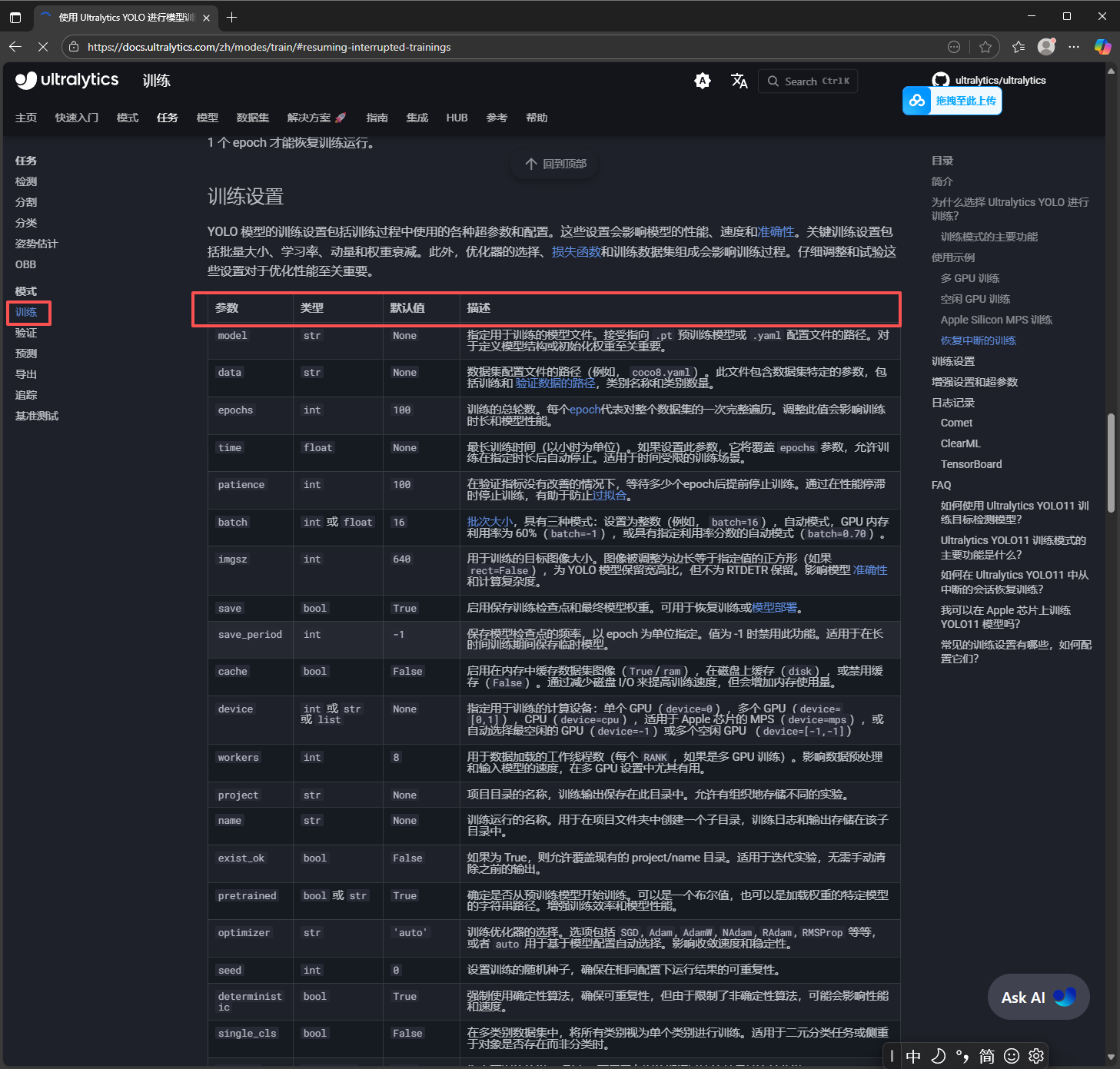
因此可以根据喜好设置任务和超参数。
如果我想修改网络的底层逻辑和内容,比如定义网络的大小层数怎么办?
这个确实是官方模型不具有的特点,因此我们需要获取其默认的配置文件进行编辑才能达到对整个流程的编辑,以便于创新和添加功能(比如注意力)。
以后的文章中会详细测试。