Transformer模型
1 Transformer背景介绍
模型被提出时间
2018年10月,Google发出一篇论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》, BERT模型横空出世, 并横扫NLP领域11项任务的最佳成绩!
- 论文地址: https://arxiv.org/pdf/1810.04805.pdf
而在BERT中发挥重要作用的结构就是Transformer, 之后又相继出现XLNET,roBERT等模型击败了BERT,但是他们的核心没有变,仍然是:Transformer。
模型优势
1、能够实现并行计算,提高模型训练效率
2、更好的特征提取能力
2 Transformer模型架构
架构图展示
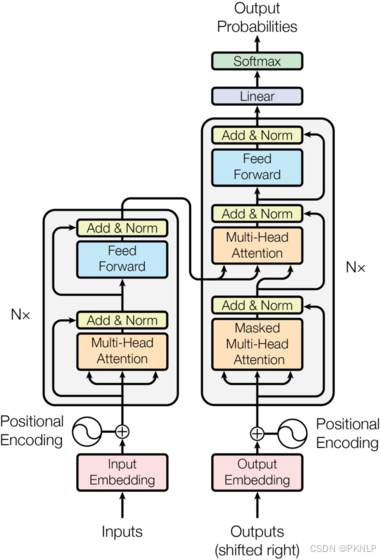
2.1 整体架构
主要组成部分
1、输入部分
2、编码器部分
3、解码器部分
4、输出部分
2.2 输入部分
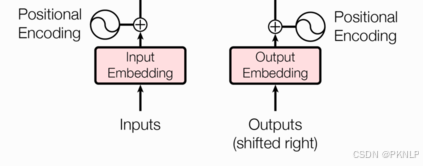
word Embeddding + Positional Encoding
词嵌入层+位置编码器层
2.3 输出部分
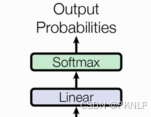
1、Linear层
2、softmax层
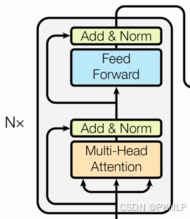
2.4 编码器部分
结构图
组成部分
1、N个编码器层堆叠而成
2、每个编码器有两个子层连接结构构成
3、第一个子层连接结构:多头自注意力层+规范化层+残差连接层
4、第二个子层连接结构:前馈全连接层+规范化层+残差连接层
2.5 解码器部分
结构图
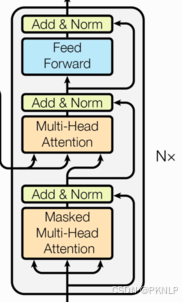
组成部分
1、N个解码器堆叠而成
2、每个解码器有三个子层连接结构构成
3、第一个子层连接结构:多头自注意力层+规范化层+残差连接层
4、第二个子层连接结构:多头注意力层+规范化层+残差连接层
5、第三个子层连接结构:前馈全连接层+规范化层+残差连接层
3 输入部分
文本嵌入层作用:word_embedding
将文本词汇进行张量(向量)表示
3.1 文本词嵌入的代码实现
注意:为什么embedding之后要乘以根号下d_model
- 原因1:为了防止position encoding的信息覆盖我们的word embedding,所以进行一个数值增大
- 原因2:符合标准正态分布
代码实现
# todo 定义函数, 实现: 输入部分之 -> 词嵌入层
class Embeddings(nn.Module): # 叫Embeddings的目的是为了和Python的类名做区分, 实际开发写: Embedding# 1. 初始化函数# 参1: 词汇表大小(去重后单词的总个数), 参2: 词嵌入的维度def __init__(self, vocab_size, d_model):# 1.1 初始化父类信息.super().__init__()# 1.2 定义变量, 接收: 词汇表大小, 词嵌入的维度self.vocab_size = vocab_sizeself.d_model = d_model# 1.3 定义词嵌入层, 将单词索引映射为词向量.self.embed = nn.Embedding(vocab_size, d_model)# 2. 定义前向传播方法def forward(self, x):# 将输入的单词索引映射为词向量, 并乘以 根号d_model进行缩放.# 缩放的目的: 为了平衡梯度, 避免梯度消失或梯度爆炸.return self.embed(x) * math.sqrt(self.d_model)3.2 位置编码器的代码实现
作用
Transformer编码器或解码器中缺乏位置信息,因此加入位置编码器,将词汇的位置可能代表的不同特征信息和word_embedding进行融合,以此来弥补位置信息的缺失。
位置编码器实现方式:三角函数来实现的,sin\cos函数
为什么使用三角函数来进行位置编码
1、保证同一词汇随着所在位置不同它对应位置嵌入向量会发生变化
2、正弦波和余弦波的值域范围都是1到-1这又很好的控制了嵌入数值的大小, 有助于梯度的快速计算
代码实现
# todo 定义函数, 实现: 输入部分之 -> 位置编码层
class PositionEncoding(nn.Module):# 1. 初始化函数.# 参1: 词向量的维度(ed:512), 参2: 随机失活概率. 参3: 最大句子长度.def __init__(self, d_model, dropout, max_len=60):# 1.1 初始化父类成员.super().__init__()# 1.2 定义dropout层, 防止过拟合.self.dropout = nn.Dropout(p=dropout)# 1.3 定义pe, 用于保存位置编码结果. 形状: [max_len, d_model] -> [60, 512]pe = torch.zeros(max_len, d_model)# 1.4 定义一个位置列向量, 从0 到 max_len - 1# 形状改变: [60] -> [60, 1]position = torch.arange(0, max_len).unsqueeze(1) # 形状: [60, 1]# 1.5 定义1个转换(变化矩阵), 本质是公式里的: 1 / 10000^(2i/d_model)# 公式推导: 10000^(2i/d_model) = e^((2i/d_model) * ln(10000))# 1/上述内容, 所以求倒数: e^((2i/d_model) * -ln(10000)) -> e^(2i * -ln(10000)/d_model)# torch.arange(0, d_model, 2) -> [0, 2, 4, 6, 8.....510] 偶数维度# [0, 2, 4, 6, 8.....510] + 1 -> [1, 3, 5, 7, 9.....511] 奇数维度div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model)) # 形状: [1, 256]# 1.6 计算三角函数里面的值.# position形状: [max_len, 1] -> [60, 1]# div_term形状: [1, 256]# position * div_term = [60, 256]position_value = position * div_term# 1.7 进行pe的赋值, 偶数位置使用 正弦函数(sin)# pe形状: [60, 512], position_value形状: [60, 256]pe[:, 0::2] = torch.sin(position_value) # 形状: [60, 256]# 1.8 进行pe的赋值, 奇数位置使用 余弦函数(cos)pe[:, 1::2] = torch.cos(position_value) # 形状: [60, 256]# 1.9 将pe进行升维, 增加1个批次维度.pe = pe.unsqueeze(0) # [1, 60, 512]# 1.10 将pe注册到模型的缓冲区, 利用它, 但是不更新它的参数.# 回顾: sin(α + β) = sin(α)cos(β) + cos(α)sin(β), cos(α + β) = cos(α)cos(β) - sin(α)sin(β)# 带入: sin(5) = sin(3 + 2) = ....# pe会作为模型的一部分, 在模型保存, 加载的时候会被处理, 而在模型训练时它的值不会被优化器更新(因为: 位置编码是固定规则)self.register_buffer('pe', pe)# 2. 前向传播.def forward(self, x):# 1. 这段代码是位置编码的核心逻辑, 负责把 '词向量' 和 '位置编码' 融合(相加)# 参数x: 词向量, 形状为: [batch_size, seq_len, d_model] -> [1, 60, 512]# self.pe 的形状: [1, max_len, d_model] -> 假设: [1, 1000, 512]x = x + self.pe[:, :x.size(1)] # [1, 60, 512] + [1, 60, 512]# 2. 随机失活, 不改变形状, 形状还是: [batch_size, seq_len, d_model] -> [1, 60, 512]return self.dropout(x)
4 编码部分
4.1 编码部分组成
由N个编码器层组成
1、每个编码器层由两个子层连接结构
2、第一个子层连接结构:多头自注意力机制层+残差连接层+规范化层
3、第二个子层连接结构:前馈全连接层+残差连接层+规范层
4.2 掩码张量
作用
掩码:掩就是遮掩、码就是张量。掩码本身需要一个掩码张量,掩码张量的作用是对另一个张量进行数据信息的掩盖。一般掩码张量是由0和1两种数字组成,至于是0对应位置或是1对应位置进行掩码,可以自己设定
掩码分类:
PADDING MASK: 句子补齐的PAD,去除影响
SETENCES MASK:解码器端,防止未来信息被提前利用
实现方式
# 返回下三角矩阵 torch.from_numpy(1 - my_mask )
def subsequent_mask(size):# 产生上三角矩阵 产生一个方阵subsequent_mask = np.triu(m = np.ones((1, size, size)), k=1).astype('uint8')# 返回下三角矩阵return torch.from_numpy(1 - subsequent_mask)
4.3 注意力机制
计算规则
自注意力机制,规则:Q乘以K的转置,然后除以根号下D_K,然后再进行Softmax,最后和V进行张量矩阵相乘
注意力计算
代码实现
# 定义函数, 进行注意力的计算.
# 参数: query/key/value: 注意力的三个核心输入, 形状通常是: [batch_size, seq_len, d_model]
# mask: 掩码张量(一般是 Decoder解码器中的未来位置要被掩码)
# dropout: 随机失活概率
def attention(query, key, value, mask=None, dropout=None):# 1. 求查询张量的特征维度 d_kd_k = query.size()[-1] # 词向量维度.# 2. 计算原始注意力分数, 模拟: Q * K^T / sqrt(d_k)# key.transpose(-2, -1), 维度从 [batch_size, seq_len, d_model] -> [batch_size, d_model, seq_len]# query @ key.transpose(-2, -1) -> [batch_size, seq_len, d_model] @ [batch_size, d_model, seq_len] -> [batch_size, seq_len, seq_len]# 除以 sqrt(d_k) -> 缩放操作, 避免内积过大, 导致梯度消失...scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)# 3. 掩码处理(可选), 遮挡不需要关注的位置.if mask is not None:scores = scores.masked_fill(mask == 0, -1e9)# 4. 计算注意力权重 和 归一化.# dim=-1: 最后1维 -> seq_len_kp_attn = F.softmax(scores, dim=-1)# 5. 随机失活(可选)if dropout is not None:p_attn = dropout(p_attn)# 6. 计算最终注意力输出, 权重加权求和.# torch.matmul(p_attn, value): 用注意力权重p_attn 对 value加权求和.# p_attn: 注意力权重(用于可视化 或者 调试)return torch.matmul(p_attn, value), p_attn
4.4 多头注意力机制
概念
将模型分为多个头, 可以形成多个子空间, 让模型去关注不同方面的信息, 最后再将各个方面的信息综合起来得到更好的效果.
架构图
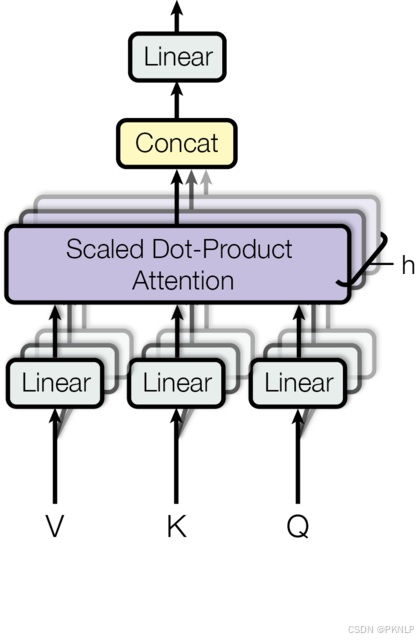
代码实现
# 深度copy模型 输入模型对象和copy的个数 存储到模型列表中
def clones(module, N):return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])class MultiHeadAttention(nn.Module):# 1. 初始化函数.# 参1: 词向量的维度. 参2: 多头个数. 参3: 随机失活概率.def __init__(self, embed_dim, head, dropout_p=0.1):# 1. 初始化父类成员.super().__init__()# 2. 确保能整除, 即: 分头成功.assert embed_dim % head == 0# 3. 计算每个头的词嵌入维度self.d_k = embed_dim // head # 例如: 512/8 = 64self.head = head # 例如: 8# 4. 定义4个线性层, 前3个 -> 用于Q, K, V的投影, 最后1个 -> 用于输出(多头注意力结果)的投影.self.linears = clones(nn.Linear(embed_dim, embed_dim), 4)# 5. 定义随机失活层.self.dropout = nn.Dropout(dropout_p)# 6. 保存注意力权重, 用于可视化或者分析.self.atten = None# 2. 前向传播函数 -> 实现多头注意力计算流程.def forward(self, query, key, value, mask=None):# 1. 判断是否需要掩码.# query, key, value的形状: [batch_size, seq_len, d_model] -> [2, 4, 512]# mask的形状: [batch_size, seq_len, seq_len] -> [1, batch_size, seq_len, seq_len]if mask is not None:mask = mask.unsqueeze(0)# 2. 获取batch_size(批量大小)self.batch = query.size(0)# 3. 线性变换: Q, K, V -> 多头注意力计算.# mode(x): 通过线性层将 输入 投影到 embed_dim维度, 即: 512维# view(...): 将投影结果重塑为: [batch_size, seq_len, head, d_k] -> [2, 4, 8, 64]# transpose(1, 2): 转置, 形状: [batch_size, seq_len, head, d_k] -> [batch_size, head, seq_len, d_k] -> [2, 8, 4, 64]query, key, value = [model(x).view(self.batch, -1, self.head, self.d_k).transpose(1, 2)for model, x in zip(self.linears, (query, key, value))]# 4. 多头注意力计算.# x的形状: [batch_size, head, seq_len, d_k] -> [2, 8, 4, 64]# atten的形状: [batch_size, head, seq_len, seq_len] -> [2, 8, 4, 4]x, self.atten = attention(query, key, value, mask, self.dropout)# 5. 将多头注意力结果 -> 合并.# x的形状: [batch_size, seq_len, head * d_k] -> [2, 4, 512]atten_x = x.transpose(1, 2).contiguous().view(self.batch, -1, self.head * self.d_k)# 6. 通过最后1个线性层处理, 返回结果.return self.linears[-1](atten_x)
4.5 前馈全连接层
概念
两个全连接层
作用
增强模型的拟合能力
代码实现
class PositionwiseFeedForward(nn.Module):def __init__(self, d_model, d_ff, dropout=0.1):# d_model 第1个线性层输入维度# d_ff 第2个线性层输出维度super(PositionwiseFeedForward, self).__init__()# 定义线性层w1 w2 dropoutself.w1 = nn.Linear(d_model, d_ff)self.w2 = nn.Linear(d_ff, d_model)self.dropout = nn.Dropout(p= dropout)def forward(self, x):# 数据依次经过第1个线性层 relu激活层 dropout层,然后是第2个线性层return self.w2(self.dropout(F.relu(self.w1(x))))
4.6 规范化层
作用
随着网络深度的增加,模型参数会出现过大或过小的情况,进而可能影响模型的收敛,因此进行规范化,将参数规范致某个特征范围内,辅助模型快速收敛。
代码实现
class LayerNorm(nn.Module):def __init__(self, features, eps=1e-6):# 参数features 待规范化的数据# 参数 eps=1e-6 防止分母为零super(LayerNorm, self).__init__()# 定义a2 规范化层的系数 y=kx+b中的kself.a2 = nn.Parameter(torch.ones(features))# 定义b2 规范化层的系数 y=kx+b中的bself.b2 = nn.Parameter(torch.zeros(features))self.eps = epsdef forward(self, x):# 对数据求均值 保持形状不变# [2,4,512] -> [2,4,1]mean = x.mean(-1,keepdims=True)# 对数据求方差 保持形状不变# [2,4,512] -> [2,4,1]std = x.std(-1, keepdims=True)# 对数据进行标准化变换 反向传播可学习参数a2 b2# 注意 * 表示对应位置相乘 不是矩阵运算y = self.a2 * (x-mean)/(std + self.eps) + self.b2return y
4.7 子层连接结构
结构图
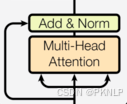
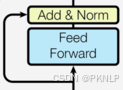
代码实现
class SublayerConnection(nn.Module):def __init__(self, size, dropout=0.1):# 参数size 词嵌入维度尺寸大小# 参数dropout 置零比率super(SublayerConnection, self).__init__()# 定义norm层self.norm = LayerNorm(size)# 定义dropoutself.dropout = nn.Dropout(dropout)def forward(self, x, sublayer):# 参数x 代表数据# sublayer 函数入口地址 子层函数(前馈全连接层 或者 注意力机制层函数的入口地址)# 方式1 # 数据self.norm() -> sublayer()->self.dropout() + xmyres = x + self.dropout(sublayer(self.norm(x)))# 方式2 # 数据sublayer() -> self.norm() ->self.dropout() + x# myres = x + self.dropout(self.norm(sublayer(x)))return myres
4.8 编码器层
结构图
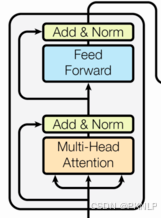
作用
每个编码器层完成一次对输入的特征提取过程, 即编码过程.
代码实现
class EncoderLayer(nn.Module):def __init__(self, size, self_atten, feed_forward, dropout):super(EncoderLayer, self).__init__()# 实例化多头注意力层对象self.self_attn = self_atten# 前馈全连接层对象feed_forwardself.feed_forward = feed_forward# size词嵌入维度512self.size = size# clones两个子层连接结构 self.sublayer = clones(SublayerConnection(size,dropout),2)self.sublayer = clones(SublayerConnection(size, dropout) ,2)def forward(self, x, mask):# 数据经过第1个子层连接结构# 参数x:传入的数据 参数lambda x... : 子函数入口地址x = self.sublayer[0](x, lambda x:self.self_attn(x, x, x, mask))# 数据经过第2个子层连接结构# 参数x:传入的数据 self.feed_forward子函数入口地址x = self.sublayer[1](x, self.feed_forward)return x
4.9 编码器
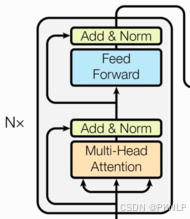
代码实现
class Encoder(nn.Module):def __init__(self, layer, N):# 参数layer 1个编码器层# 参数 编码器层的个数super(Encoder, self).__init__()# 实例化多个编码器层对象self.layers = clones(layer, N)# 实例化规范化层self.norm = LayerNorm(layer.size)def forward(self, x, mask):# 数据经过N个层 x = layer(x, mask)for layer in self.layers:x = layer(x, mask)# 返回规范化后的数据 return self.norm(x)return self.norm(x)
5 解码器部分
结构图
组成部分
1、N个解码器层堆叠而成
2、每个解码器层由三个子层连接结构组成
3、第一个子层连接结构:多头自注意力(masked)层+ 规范化层+残差连接
4、第二个子层连接结构:多头注意力层+ 规范化层+残差连接
5、第三个子层连接结构:前馈全连接层+ 规范化层+残差连接
5.1 解码器层
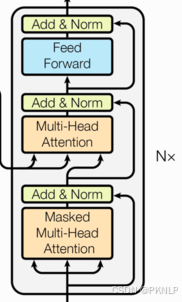
作用
作为解码器的组成单元, 每个解码器层根据给定的输入向目标方向进行特征提取操作
代码实现
class DecoderLayer(nn.Module):def __init__(self, size, self_attn, src_attn, feed_forward, dropout):super(DecoderLayer, self).__init__()# 词嵌入维度尺寸大小self.size = size# 自注意力机制层对象 q=k=vself.self_attn = self_attn# 一遍注意力机制对象 q!=k=vself.src_attn = src_attn# 前馈全连接层对象self.feed_forward = feed_forward# clones3子层连接结构self.sublayer = clones(SublayerConnection(size, dropout), 3)def forward(self, x, memory, source_mask, target_mask):m = memory# 数据经过子层连接结构1x = self.sublayer[0](x, lambda x:self.self_attn(x, x, x, target_mask))# 数据经过子层连接结构2x = self.sublayer[1](x, lambda x:self.src_attn (x, m, m, source_mask))# 数据经过子层连接结构3x = self.sublayer[2](x, self.feed_forward)return x
5.2 解码器
作用
根据编码器的结果以及上一次预测的结果, 对下一次可能出现的'值'进行特征表示
代码实现
class Decoder(nn.Module):def __init__(self, layer, N):# 参数layer 解码器层对象# 参数N 解码器层对象的个数super(Decoder, self).__init__()# clones N个解码器层self.layers = clones(layer, N)# 定义规范化层self.norm = LayerNorm(layer.size)def forward(self, x, memory, source_mask, target_mask):# 数据以此经过各个子层for layer in self.layers:x = layer(x, memory, source_mask, target_mask)# 数据最后经过规范化层return self.norm(x)
6 输出部分
作用:通过线性变化得到指定维度的输出
代码
class Generator(nn.Module):def __init__(self, d_model, vocab_size):# 参数d_model 线性层输入特征尺寸大小# 参数vocab_size 线层输出尺寸大小super(Generator, self).__init__()# 定义线性层self.project = nn.Linear(d_model, vocab_size)def forward(self, x):# 数据经过线性层 最后一个维度归一化 log方式x = F.log_softmax(self.project(x), dim=-1)return x
7 模型搭建
完整的编码器-解码器结构
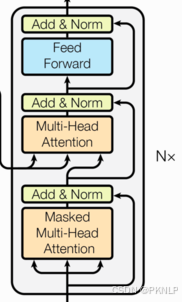
7.1 编码器-解码器结构的代码实现
# 使用EncoderDecoder类来实现编码器-解码器结构
class EncoderDecoder(nn.Module):def __init__(self, encoder, decoder, source_embed, target_embed, generator):"""初始化函数中有5个参数, 分别是编码器对象, 解码器对象, 源数据嵌入函数, 目标数据嵌入函数, 以及输出部分的类别生成器对象"""super(EncoderDecoder, self).__init__()# 将参数传入到类中self.encoder = encoderself.decoder = decoderself.src_embed = source_embedself.tgt_embed = target_embedself.generator = generatordef forward(self, source, target, source_mask, target_mask):"""在forward函数中,有四个参数, source代表源数据, target代表目标数据, source_mask和target_mask代表对应的掩码张量"""# 在函数中, 将source, source_mask传入编码函数, 得到结果后,# 与source_mask,target,和target_mask一同传给解码函数return self.generator(self.decode(self.encode(source, source_mask), source_mask, target, target_mask))def encode(self, source, source_mask):"""编码函数, 以source和source_mask为参数"""# 使用src_embed对source做处理, 然后和source_mask一起传给self.encoderreturn self.encoder(self.src_embed(source), source_mask)def decode(self, memory, source_mask, target, target_mask):"""解码函数, 以memory即编码器的输出, source_mask, target, target_mask为参数"""# 使用tgt_embed对target做处理, 然后和source_mask, target_mask, memory一起传给self.decoderreturn self.decoder(self.tgt_embed(target), memory, source_mask, target_mask)
7.2 Tansformer模型构建代码
def make_model(source_vocab, target_vocab, N=6, d_model=512, d_ff=2048, head=8, dropout=0.1):c = copy.deepcopy# 实例化多头注意力层对象attn = MultiHeadedAttention(head=8, embedding_dim= 512, dropout=dropout)# 实例化前馈全连接对象ffff = PositionwiseFeedForward(d_model=d_model, d_ff=d_ff, dropout=dropout)# 实例化 位置编码器对象positionposition = PositionalEncoding(d_model=d_model, dropout=dropout)# 构建 EncoderDecoder对象model = EncoderDecoder(# 编码器对象Encoder( EncoderLayer(d_model, c(attn), c(ff), dropout), N),# 解码器对象Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff),dropout), N),# 词嵌入层 位置编码器层容器nn.Sequential(Embeddings(d_model, source_vocab), c(position)),# 词嵌入层 位置编码器层容器nn.Sequential(Embeddings(d_model, target_vocab), c(position)),# 输出层对象Generator(d_model, target_vocab))for p in model.parameters():if p.dim() > 1:nn.init.xavier_uniform_(p)return model
import torch
import torch.nn as nnclass My_Model(nn.Module):# def __init__(self, vocab_size, d_model, output_size=10):# super().__init__()# self.embed = nn.Embedding(vocab_size, d_model)# self.linear1 = nn.Linear(d_model, 8)# self.linear2 = nn.Linear(8, output_size)def __init__(self, vocab_size, d_model, output_size=10):super().__init__()self.sqeuen = nn.Sequential( nn.Embedding(vocab_size, d_model),nn.Linear(d_model, 8),nn.Linear(8, output_size))# def forward(self, x):# x = self.embed(x)# x = self.linear1(x)# x = self.linear2(x)# return xdef forward(self, x):x = self.sqeuen(x)return xif __name__ == '__main__':x = torch.tensor([[1,2,3],[4,5,6]], dtype=torch.long)my_model = My_Model(20, 4)result = my_model(x)print(result)print(result.shape)