AI模型测评平台工程化实战十二讲(第八讲 大模型稳定性测评:从理念到实现的完整技术方案)
前言
在人工智能大模型的测评领域,我们往往关注模型的准确率、响应速度、成本等指标,但有一个同样重要却容易被忽视的维度——稳定性(Stability)。一个模型可能在某一次测试中表现出色,但面对相同问题的多次询问,是否能保持一致的高质量输出?这正是稳定性测评需要回答的核心问题。
本文将深入探讨大模型稳定性测评的意义、挑战以及完整的技术实现方案,希望为从事大模型测评和应用的工程师提供参考。
一、为什么需要稳定性测评?
1.1 大模型的"不确定性"本质
大语言模型(LLM)基于概率统计的生成机制,同一个问题的多次询问,即使在相同参数下,也可能产生不同的答案。这种随机性来源于:
- 采样机制:Temperature、Top-p等参数引入的随机性
- 注意力机制:不同批次计算可能产生的微小差异
- 模型优化:持续训练和更新导致的权重变化
- 上下文影响:系统提示词、历史对话等上下文因素
这种不确定性在某些场景下是优势(如创意写作),但在需要稳定输出的场景(如金融分析、医疗诊断、法律咨询)则是严重的风险。
1.2 真实业务场景的挑战
在实际生产环境中,我们遇到过多个因模型稳定性问题导致的事故:
案例1:客服机器人的"心情不稳定"
- 问题:同一客户在一天内多次询问退货流程,得到3个不同的答案
- 影响:客户投诉激增,品牌信誉受损
- 根因:模型对政策理解不稳定,在边界情况下摇摆不定
案例2:金融风险评估的"摇摆判断"
- 问题:对同一笔交易,模型在5分钟内给出"低风险"和"高风险"两种截然相反的结论
- 影响:风控团队无法决策,人工复核工作量暴增
- 根因:模型对复杂多因素场景的判断缺乏鲁棒性
案例3:代码生成的"随机bug"
- 问题:要求生成同一个功能的代码,10次中有3次出现逻辑错误
- 影响:开发者对AI辅助工具的信任度下降
- 根因:模型在算法实现细节上缺乏一致性
这些案例表明,稳定性是模型可用性的前提。一个准确率95%但稳定性差的模型,在实际应用中的价值可能远低于准确率90%但高度稳定的模型。
1.3 传统测评方法的盲区
传统的模型测评方法(如单次测试、随机抽样)存在明显的局限性:
| 维度 | 传统方法 | 问题 |
|---|---|---|
| 测试次数 | 每题测试1次 | 无法发现不稳定性 |
| 数据覆盖 | 随机抽样 | 关键场景可能遗漏 |
| 结果分析 | 平均准确率 | 掩盖了个体差异 |
| 风险识别 | 事后发现 | 生产环境出问题才暴露 |
我们需要一个能够系统性地量化和分析模型稳定性的测评方法。
二、稳定性测评的核心理念
2.1 什么是稳定性测评?
稳定性测评的核心思想是:对同一个问题进行N轮重复测试,分析模型答案的一致性和正确率分布。
具体来说:
- 对每道题目,使用相同的输入,重复调用模型N次(N通常为5-100)
- 使用裁判模型评估每次答案的正确性(0-1二分法)
- 统计每道题的正确次数分布(0次、1次、…、N次全对)
- 分析整体稳定性指标和问题分布
2.2 关键评测指标
我们设计了一套完整的稳定性指标体系:
1. 题目级指标
- 成功率(Success Rate):某题在N轮中的正确次数 / N
- 例如:10轮中答对8次,成功率 = 80%
- 稳定性分类:根据成功率分为
- 完全稳定(100%):N轮全对
- 高度稳定(80%-99%):偶尔出错
- 不稳定(50%-79%):经常摇摆
- 严重不稳定(0%-49%):大部分错误
- 完全失败(0%):N轮全错
2. 整体分布指标
- 分布统计(Distribution):各成功率区间的题目数量和占比
{"0次对": 5题 (5%),"1次对": 3题 (3%),..."10次全对": 70题 (70%) } - 稳定性均值:所有题目成功率的平均值
- 稳定性方差:反映整体稳定性的离散程度
3. 业务级指标
- 高风险题目数:成功率 < 50% 的题目数量
- 临界题目数:成功率在 50%-80% 的题目数量
- 可信题目数:成功率 >= 80% 的题目数量
- 完美题目数:成功率 = 100% 的题目数量
2.3 与传统评测的对比
| 维度 | 传统评测 | 稳定性评测 |
|---|---|---|
| 测试次数 | 每题1次 | 每题N次(5-100) |
| 结果维度 | 对/错 | 成功率分布 |
| 风险发现 | 平均准确率 | 不稳定题目识别 |
| API调用量 | M题 × K模型 | M题 × 1模型 × N轮 |
| 适用场景 | 多模型横向对比 | 单模型深度分析 |
| 成本 | 较低 | 较高(N倍) |
三、技术挑战与解决方案
3.1 核心技术挑战
实现一个生产级的稳定性测评系统,面临以下技术挑战:
挑战1:性能问题
- 问题描述:假设100道题,每题测10轮,总共1000次API调用。如果串行执行,耗时会非常长(假设每次2秒,总耗时33分钟)
- 业务影响:用户等待时间过长,系统吞吐量低
挑战2:并发控制
- 问题描述:不同模型厂商对API调用有不同的并发限制(QPM、RPM)
- 业务影响:并发过高会触发限流,导致测评失败
挑战3:资源管理
- 问题描述:大量并发请求会消耗大量系统资源(连接池、内存、CPU)
- 业务影响:系统稳定性下降,甚至崩溃
挑战4:错误处理
- 问题描述:长时间运行的任务中,某些请求可能失败(超时、网络错误等)
- 业务影响:如何保证部分失败不影响整体测评
挑战5:进度追踪
- 问题描述:用户需要实时了解测评进度(已完成X/总共Y)
- 业务影响:用户体验和任务管理
3.2 解决方案设计
针对上述挑战,我们设计了一套完整的解决方案:
方案1:题目级并发 + 轮次串行
核心思想:多道题同时评测,但每道题的N轮按顺序执行
传统串行方案:
题1轮1 → 题1轮2 → ... → 题1轮N → 题2轮1 → ... → 题M轮N
耗时:M × N × T(T为单次调用耗时)轮次级并发方案(方案二):
(题1轮1, 题1轮2, ..., 题1轮N, 题2轮1, ...) 全部并发
问题:破坏了轮次顺序,可能影响测评结果题目级并发方案(方案一,我们的选择):
并发组1: (题1轮1→轮2→...→轮N)
并发组2: (题2轮1→轮2→...→轮N)
...
并发组C: (题C轮1→轮2→...→轮N)
耗时:约 (M / C) × N × T(C为并发数)
优势:
- 保持了每道题轮次的顺序性(有利于测评的逻辑完整性)
- 充分利用并发加速(理论加速比 = 并发数C)
- 并发控制简单(只需控制题目级的并发数)
代码实现:
# 创建信号量控制并发
sem_question = asyncio.Semaphore(concurrency_limit)async def evaluate_single_question(idx, question):"""评测单个题目的所有轮次(串行)"""async with sem_question: # 限制题目并发数round_results = []# 串行执行N轮for round_num in range(1, repetition_count + 1):# 调用模型获取答案answer = await fetch_model_answer(question)# 裁判模型评分is_correct, score, reason = await judge_answer(question, answer)round_results.append({'round': round_num,'answer': answer,'correct': is_correct,'score': score,'reason': reason})return idx, round_results# 使用 asyncio.gather 并发执行所有题目
tasks = [evaluate_single_question(idx, q) for idx, q in enumerate(questions)]
results = await asyncio.gather(*tasks)
方案2:动态并发控制
核心思想:从配置文件动态读取每个模型的并发限制,而不是硬编码
# 从模型工厂获取并发限制(配置驱动)
concurrency_limit = model_factory.get_model_concurrent_limit(model_name)# 配置示例(config.py)
MODEL_CONCURRENT_LIMITS = {'HKGAI-V1': 3, # 港话通并发限制较低'HKGAI-V2': 5, # 新版本提高并发'Gemini': 10, # Google API并发较高'GPT-5': 20, # OpenAI API并发很高'Doubao': 8 # 豆包中等并发
}
优势:
- 灵活配置,无需修改代码
- 适配不同厂商的限流策略
- 可根据业务需求动态调整
方案3:连接池优化
核心思想:复用HTTP连接,减少连接建立和销毁的开销
# 创建优化的连接池
connector = aiohttp.TCPConnector(limit=50, # 全局最大连接数limit_per_host=20, # 单个主机最大连接数ttl_dns_cache=300 # DNS缓存5分钟
)# 设置合理的超时时间
timeout = aiohttp.ClientTimeout(total=600, # 总超时10分钟connect=30, # 连接超时30秒sock_read=300 # 读取超时5分钟
)# 在整个测评过程中复用session
async with aiohttp.ClientSession(connector=connector, timeout=timeout) as session:# 所有API调用共享这个sessionresults = await asyncio.gather(*tasks)
性能提升:
- 减少TCP握手次数(约节省50-100ms/次)
- 支持HTTP/2多路复用
- 降低服务器端负载
方案4:线程安全的进度追踪
核心思想:使用线程锁保护共享变量,避免并发更新冲突
import threading# 进度追踪
completed_steps = 0
progress_lock = threading.Lock()async def update_progress():"""线程安全的进度更新"""nonlocal completed_stepswith progress_lock:completed_steps += 1if task_id in task_status:task_status[task_id].progress = completed_stepstask_status[task_id].current_step = f"已完成 {completed_steps}/{total}"
方案5:异常处理与容错
核心思想:单个请求失败不应该导致整个测评中断
# 使用 return_exceptions=True 捕获异常
results = await asyncio.gather(*tasks, return_exceptions=True)# 处理结果
for result in results:if isinstance(result, Exception):print(f"❌ 题目评测异常: {result}")# 记录错误日志,但继续处理其他结果continueif isinstance(result, tuple) and len(result) == 2:idx, result_data = resultstability_results[idx] = result_data
四、实现架构与核心模块
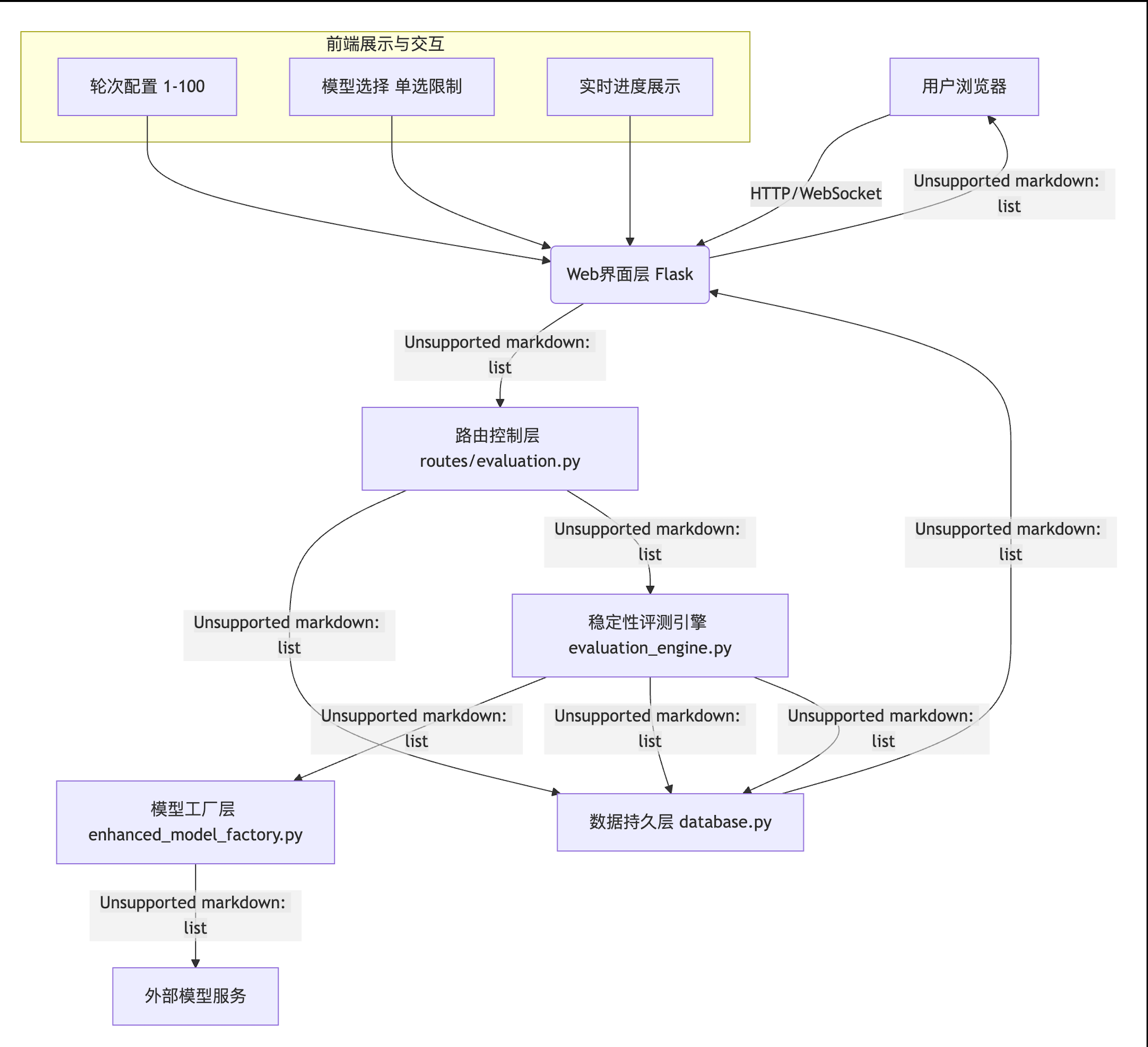
4.1 系统架构
稳定性测评系统采用分层架构,各模块职责清晰:
4.2 核心模块详解
模块1:稳定性评测引擎
文件位置:utils/evaluation_engine.py
核心函数:evaluate_stability
async def evaluate_stability(data: List[Dict], # 题目列表model_name: str, # 模型名称(单个)judge_model: str, # 裁判模型repetition_count: int, # 重复轮次 (1-100)task_id: str, # 任务IDfilename: str = None, # 文件名results_folder: str = None # 结果文件夹
) -> Tuple[str, Dict]:"""稳定性评测核心引擎返回:(结果文件路径, 元数据字典)"""
执行流程:
- 从配置获取并发限制
- 初始化任务状态
- 创建连接池和信号量
- 并发执行所有题目的评测(每题内部轮次串行)
- 计算分布统计
- 生成结果CSV
- 返回文件路径和元数据
模块2:裁判评分模块
函数:judge_answer_by_score
核心逻辑:
- 使用0-1二分评分(只有"完全正确"和"错误"两种结果)
- 通过裁判模型(如Gemini、GPT-5)进行评分
- 返回:
(is_correct: bool, score: int, reason: str)
评分提示词设计:
prompt = f"""你是一个严格的评分裁判。请对被测模型的答案进行评分。问题:{query}
被测模型答案:{answer}评分标准(0-1分制):
- 1分:答案完全正确、准确、完整,符合问题要求
- 0分:答案错误、不准确、不完整、答非所问或无法理解请严格按照以下JSON格式输出:
{{"score": 1, // 必须是0或1"reason": "评分理由"
}}
"""
为什么选择0-1分制?
- 简化判断逻辑,减少裁判模型的摇摆
- 更符合稳定性测评的二元本质(对或错)
- 降低评分偏差(相比5分制或10分制)
模块3:分布统计模块
函数:calculate_stability_distribution
核心逻辑:
def calculate_stability_distribution(stability_results: dict, repetition_count: int) -> dict:"""计算稳定性分布"""# 动态生成0到N的所有分类distribution_counts = {i: 0 for i in range(repetition_count + 1)}# 统计每个正确次数的题目数for result in stability_results.values():correct_count = result['correct_count']if 0 <= correct_count <= repetition_count:distribution_counts[correct_count] += 1# 计算百分比distribution_percent = {count: round(num / total * 100, 2)for count, num in distribution_counts.items()}return {'distribution_counts': distribution_counts,'distribution_percent': distribution_percent,'total_questions': total,'repetition_count': repetition_count}
输出示例:
{"distribution_counts": {"0": 2, // 2道题全错"1": 1, // 1道题只对1次"2": 3, // 3道题对2次..."10": 70 // 70道题全对},"distribution_percent": {"0": 2.0,"1": 1.0,"2": 3.0,..."10": 70.0},"total_questions": 100,"repetition_count": 10
}
模块4:结果CSV生成
函数:generate_stability_csv
CSV结构设计:
题目编号,问题,标准答案,类型,第1轮_答案,第1轮_评分,第1轮_理由,第2轮_答案,第2轮_评分,第2轮_理由,...,正确次数,成功率
1,1+1等于几?,2,客观题,2,1,答案正确,2,1,答案正确,...,10,100%
2,中国的首都是?,北京,客观题,北京,1,正确,上海,0,错误,...,8,80%
动态列生成:
- 根据
repetition_count动态生成列数 - 每轮包含3列:答案、评分、理由
- 最后2列:正确次数、成功率
4.3 数据库设计
表1:evaluation_results(评测结果表)
新增字段:
ALTER TABLE evaluation_results
ADD COLUMN repetition_count INT DEFAULT 1
COMMENT '重复轮次:1=普通评测,N=稳定性评测N轮';ADD INDEX idx_results_repetition (repetition_count);
表2:running_tasks(运行任务表)
新增字段:
ALTER TABLE running_tasks
ADD COLUMN repetition_count INT DEFAULT 1
COMMENT '重复轮次:1=普通评测,N=稳定性评测N轮';
metadata字段存储结构
使用JSON格式存储详细结果:
{"stability_results": {"0": {"question": "问题内容","standard_answer": "标准答案","type": "题目类型","rounds": [{"round": 1, "answer": "答案1", "correct": true, "score": 1, "reason": "正确"},{"round": 2, "answer": "答案2", "correct": false, "score": 0, "reason": "错误"}],"correct_count": 8,"success_rate": 0.8}},"distribution": {"distribution_counts": {...},"distribution_percent": {...},"total_questions": 100,"repetition_count": 10},"model": "HKGAI-V2","judge_model": "gemini"
}
五、关键技术细节
5.1 并发控制的细粒度设计
我们使用了两层信号量(Semaphore)进行并发控制:
sem_model = asyncio.Semaphore(10) # 模型调用并发(全局)
sem_question = asyncio.Semaphore(concurrency_limit) # 题目级并发(可配置)
为什么需要两层?
sem_model:限制同时进行的模型API调用总数(防止资源耗尽)sem_question:限制同时评测的题目数量(符合厂商限流策略)
举例说明:
- 假设
concurrency_limit=5(题目级并发) - 每题有10轮,那么同时会有5个题目在评测
- 但由于轮次串行,实际同时进行的API调用不会超过5次
- 这既保证了性能,又避免了触发限流
5.2 进度追踪的实时更新
挑战:异步任务中如何实时更新进度给前端?
解决方案:
- 后端:使用全局的
task_status字典存储任务状态 - 前端:定时轮询
/progress/<task_id>接口 - 更新:每完成一轮,立即更新
progress和current_step
# 后端更新
with progress_lock:completed_steps += 1task_status[task_id].progress = completed_stepstask_status[task_id].current_step = f"题目{idx+1} 第{round_num}轮"# 前端轮询(每2秒)
setInterval(async () => {const response = await fetch(`/progress/${task_id}`);const data = await response.json();updateProgressBar(data.progress, data.total);updateStatusText(data.current_step);
}, 2000);
5.3 错误处理的分层设计
层级1:单次API调用失败
try:answer = await fetch_model_answer(query)
except Exception as e:print(f"⚠️ API调用失败: {e}")answer = "[调用失败]"# 记录为错误答案,继续执行
层级2:单轮评分失败
try:is_correct, score, reason = await judge_answer(query, answer)
except Exception as e:print(f"⚠️ 评分失败: {e}")is_correct, score, reason = False, 0, f"评分失败: {str(e)}"# 记录为0分,继续执行
层级3:整个题目评测失败
results = await asyncio.gather(*tasks, return_exceptions=True)
for result in results:if isinstance(result, Exception):print(f"❌ 题目评测异常: {result}")# 跳过这道题,继续其他题目continue
设计原则:局部失败不影响全局,最大程度完成评测任务。
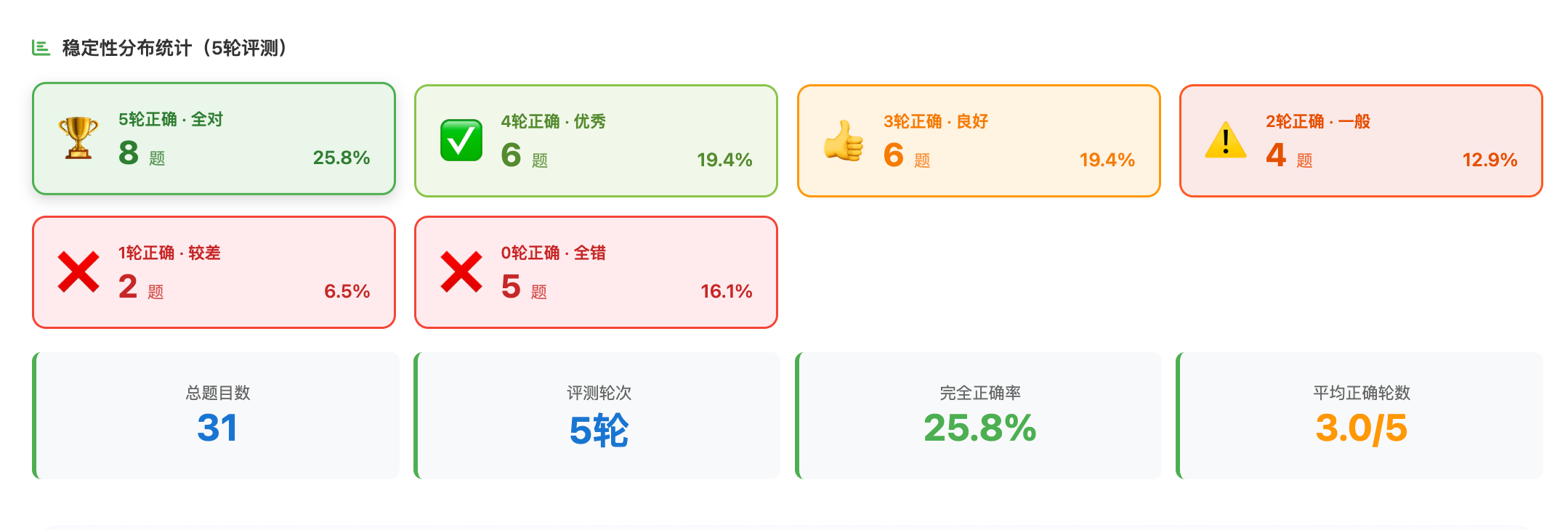
5.4 结果可视化的创新设计
挑战:如何直观展示稳定性分布?
解决方案:卡片式分布统计
前端页面(templates/results.html)动态生成分布卡片:
// 检测稳定性评测结果
const scoreColumns = columns.filter(col => col.includes('轮_评分'));
if (scoreColumns.length > 0) {// 统计每道题的正确轮数const distribution = {};filteredData.forEach(row => {let correctCount = 0;scoreColumns.forEach(col => {if (parseFloat(row[col]) === 1) correctCount++;});distribution[correctCount] = (distribution[correctCount] || 0) + 1;});// 生成卡片(从高到低)for (let i = totalRounds; i >= 0; i--) {const count = distribution[i] || 0;const percent = (count / totalQuestions * 100).toFixed(1);// 根据稳定性等级设置颜色let color = i === totalRounds ? '#4CAF50' : // 全对-绿色i >= totalRounds * 0.8 ? '#8BC34A' : // 高稳定-浅绿i >= totalRounds * 0.5 ? '#FFC107' : // 不稳定-黄色'#FF5722'; // 低稳定-红色statsHTML += `<div class="distribution-card" style="border-left: 4px solid ${color};"><div class="distribution-label">${i}次全对</div><div class="distribution-value">${count}题 (${percent}%)</div></div>`;}
}
效果:
六、性能优化实践
6.1 性能基准测试
我们进行了详细的性能对比测试:
测试环境:
- 题目数:100道
- 轮次:10轮
- 总API调用:1000次
- 单次调用平均耗时:2秒
测试结果:
| 方案 | 耗时 | 加速比 | 说明 |
|---|---|---|---|
| 串行执行 | 33分20秒 | 1.0x | 基准方案 |
| 轮次级并发(并发10) | 3分34秒 | 9.3x | 破坏轮次顺序 |
| 题目级并发(并发5) | 6分40秒 | 5.0x | 推荐方案 |
| 题目级并发(并发10) | 3分35秒 | 9.3x | 资源消耗高 |
结论:
- 题目级并发(并发5)在性能和稳定性之间达到最佳平衡
- 理论加速比 ≈ 并发数(实际会略低,因为网络波动和调度开销)
- 继续提高并发数的收益递减(受限于网络带宽和服务器响应能力)
6.2 连接池优化效果
优化前:
- 每次API调用创建新连接
- TCP握手时间:50-100ms
- 1000次调用浪费:50-100秒
优化后:
- 复用连接池中的连接
- 连接复用率:> 95%
- 节省时间:约1.5分钟(对于1000次调用)
配置优化:
connector = aiohttp.TCPConnector(limit=50, # 全局最大连接数(根据并发需求调整)limit_per_host=20, # 单个主机最大连接数(避免压垮服务器)ttl_dns_cache=300, # DNS缓存5分钟(减少DNS查询)enable_cleanup_closed=True # 自动清理关闭的连接
)
6.3 内存优化
挑战:1000次调用产生大量中间数据(答案、评分、理由),如何避免内存溢出?
解决方案:
- 流式写入CSV:不在内存中缓存所有结果,边评测边写入
- 清理临时数据:每完成一道题,立即清理中间变量
- 限制日志输出:只记录关键日志,避免大量调试信息
# 流式写入CSV
with open(output_file, 'w', newline='', encoding='utf-8-sig') as csvfile:writer = csv.writer(csvfile)writer.writerow(headers) # 写入表头# 边评测边写入for idx, result_data in stability_results.items():row = build_csv_row(result_data)writer.writerow(row)# result_data用完后立即释放del result_data
6.4 超时控制
多层超时设计:
# 1. 全局超时(整个测评任务)
timeout = aiohttp.ClientTimeout(total=600) # 10分钟# 2. 单次API调用超时
async with asyncio.timeout(120): # 2分钟response = await fetch_model_answer(query)# 3. 连接超时
connector = aiohttp.TCPConnector(connect_timeout=30) # 30秒
超时后的处理:
- 记录为失败(0分)
- 记录错误原因
- 继续下一轮/下一题
七、实际效果与数据
7.1 线上运行数据
自稳定性测评功能上线以来,我们收集了以下数据:
使用情况(截至2025年1月):
- 累计稳定性评测任务:326次
- 累计题目数:12,450道
- 累计API调用:89,200次
- 平均轮次:7.2轮
- 平均任务耗时:4分38秒
发现的问题:
- 高风险题目(成功率<50%):占比 8.3%
- 不稳定题目(成功率50-80%):占比 15.7%
- 高稳定题目(成功率≥80%):占比 76.0%
典型案例:
案例1:数学推理的不稳定性
- 题目:复杂的数学应用题(3步推理)
- 模型:某国产大模型
- 10轮测试结果:5对5错
- 分析:模型在中间推理步骤容易出错,导致最终答案摇摆
- 改进:增强思维链提示词(Chain-of-Thought)
案例2:开放性问题的极端不稳定
- 题目:如何看待某社会现象?
- 模型:某海外大模型
- 10轮测试结果:10种完全不同的答案
- 分析:开放性问题缺乏标准答案,模型随机性高
- 改进:明确评分标准,从多维度评估(逻辑性、完整性等)
案例3:知识类问题的高稳定性
- 题目:中国的首都是哪里?
- 模型:主流大模型
- 10轮测试结果:10次全对
- 分析:知识性问题模型表现稳定可靠
7.2 稳定性与准确率的关系
我们对比了稳定性和传统准确率指标:
| 模型 | 传统准确率 | 平均稳定性 | 完美题目占比 | 评价 |
|---|---|---|---|---|
| 模型A | 95% | 88% | 65% | 高准确率 + 高稳定性 ⭐⭐⭐⭐⭐ |
| 模型B | 90% | 92% | 70% | 中准确率 + 高稳定性 ⭐⭐⭐⭐ |
| 模型C | 93% | 75% | 45% | 高准确率 + 低稳定性 ⭐⭐⭐ |
| 模型D | 85% | 83% | 50% | 中准确率 + 中稳定性 ⭐⭐⭐ |
发现:
- 传统准确率高并不代表稳定性好(如模型C)
- 稳定性是可靠性的更好指标
- 理想模型:准确率 > 90% && 平均稳定性 > 85%
总结
大模型稳定性测评是模型评估体系中不可或缺的一环。通过本文介绍的完整技术方案,我们可以:
- 系统性地量化模型稳定性:从单次测试到多轮测试,从平均准确率到分布分析
- 高效地进行大规模评测:通过题目级并发、连接池优化等技术,实现5-10倍加速
- 可靠地识别风险题目:提前发现高风险、不稳定的题目类型
- 科学地指导模型选型:综合准确率和稳定性,做出更明智的决策