LLM 论文精读(十)The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
这是 LLM 与 RL 领域的中的另一篇综述(2025年09月02日),也是一篇长总结但核心是 Agentic 相关,全文 100 页去出参考文献还剩 50 页。
写在最前面
为了方便你的阅读,以下几点的注意事项请务必了解:
- 该系列文章每个字都是我理解后自行翻译并写上去的,可能会存在笔误与理解错误,如果发现了希望读者能够在评论区指正,我会在第一时间修正错误。
- 阅读这个系列需要你有基本的 LLM, RL 相关基础知识,有时候我会直接使用英文名词,因为这些词汇实在不容易找到符合语境的翻译。
- 原文可能因为版面限制存在图像表格与段落不同步的问题,为了更方便阅读,我会在博文中重新对图像表格进行排版,并做到引用图表的文字下方就能看到被引用的图表。因此可能会出现一张图片在博客中多处位置重复出现的情况。
- 对于原文中的图像,我会在必要时对图像描述进行翻译并附上我自己的理解,但如果图像描述不值得翻译我也不会强行写上去。
Basic Information
- 论文标题:The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
- 原文链接: https://arxiv.org/abs/2509.02547
- 发表时间:2025年09月02日
- 发表平台:arxiv
- 预印版本号:[v1] Tue, 2 Sep 2025 17:46:26 UTC (5,418 KB)
- 作者团队:Guibin Zhang, Hejia Geng, Xiaohang Yu, Zhenfei Yin, Zaibin Zhang, Zelin Tan, Heng Zhou, Zhongzhi Li, Xiangyuan Xue, Yijiang Li, Yifan Zhou, Yang Chen, Chen Zhang, Yutao Fan, Zihu Wang, Songtao Huang, Yue Liao, Hongru Wang, Mengyue Yang, Heng Ji, Michael Littman, Jun Wang, Shuicheng Yan, Philip Torr, Lei Bai
- 院校机构:
- University of Oxford;
- Shanghai AI Laboratory;
- National University of Singapore;
- University College London;
- University of Illinois Urbana-Champaign;
- Brown University;
- University of Science and Technology of China;
- Imperial College London;
- University of Bristol;
- Chinese Academy of Sciences;
- The Chinese University of Hong Kong ;
- Fudan University;
- University of Georgia;
- University of California, San Diego ;
- Dalian University of Technology;
- University of California, Santa Barbara;
- 项目链接: 【暂无】
- GitHub仓库: https://github.com/xhyumiracle/Awesome-AgenticLLM-RL-Papers
Abstract
代理强化学习 (Agentic RL) 的出现标志着 传统强化学习应用于大型语言模型 (LLM RL) 的范式转变,将 LLM 从被动序列生成器重构为嵌入复杂动态世界的自主决策代理。本综述通过将 LLM-RL 的退化单步马尔可夫决策过程 (MDP) 与定义 agentic RL 的部分可观测、时间扩展的部分可观测马尔可夫决策过程 (POMDP) 进行对比,形式化地阐述了这一概念转变。在此基础上,作者提出了一个全面的双重分类法:一个围绕 核心代理能力(包括规划、工具使用、记忆、推理、自我提升和感知)分类,另一个围绕 在不同任务领域应用 分类。论文的核心是强化学习是将这些能力从静态的启发式模块转化为自适应的、鲁棒的代理行为的关键机制。为了支持和加速未来的研究,作者将开源环境、基准和框架的概况整合成一个实用的概要。通过综合五百多篇近期研究,勾勒出了这一快速发展领域的轮廓,并强调了将影响可扩展通用人工智能代理发展的机遇和挑战。
1. Introduction
LLM 与 RL 的快速融合,促成了语言模型构想、训练和部署方式的根本性变革。早期的 LLM-R 范式主要将这些模型视为静态条件生成器,经过优化以生成与人类偏好或基准分数一致的单轮输出。尽管这些方法在对齐和指令遵循方面取得了成功,但它们忽略了支撑现实交互场景的更广泛的序列决策。这些局限性促使人们转变视角:与其将 LLM 视为被动的文本生成器,不如将 LLM 视为代理实体,即 能够在部分可观察的动态环境中感知、推理、规划、调用工具、保持记忆并在更长的时间内调整策略的自主决策者。作者将这种新兴范式定义为 代理强化学习 (Agentic RL)。为了更清晰地描述本文所研究的 agentic RL 概念与传统强化学习方法的区别,给出以下定义:
代理强化学习 (Agentic RL) 是指这样一种范式,其中 LLM 不被视为针对单轮输出对齐或基准性能优化的静态条件生成器,而是被概念化为嵌入在顺序决策循环中的可学习策略,其中 RL 赋予它们自主的代理能力,例如规划、推理、工具使用、记忆维护和自我反思,从而能够在部分可观察的动态环境中出现长远认知和交互行为。

在第二章节中更正式地、以符号为基础区分代理型强化学习和传统强化学习。先前与代理型强化学习相关的研究大致可以分为两个互补的分支:LLM agents 和 RL for LLMs,具体如下:
LLM Agents
LLM-based agents 代表了一种新兴范式,其中 LLM 充当自主或半自主的决策实体,能够推理、规划和执行动作以实现复杂目标。最近的调查试图从互补的角度描绘这一格局。Luo 等人提出了一种以方法论为中心的分类法,将架构基础、协作机制和演进路径联系起来; Plaat 等人则强调推理、行动和交互的核心能力是代理 LLM 的定义特征;工具使用,包括检索增强生成 (RAG) 和 API 利用,是一个核心范式,Li 等人对此进行了广泛讨论;Wang 等人对此进行了进一步概念化;规划和推理策略构成了另一个支柱,Masterman 等人等调查强调了计划-执行-反映循环等常见设计模式;Tao 等人则强调了基于 LLM 的代理模型,并将其扩展到自我进化,即智能体在无需大量人工干预的情况下迭代地完善知识和策略。其他方向则探索协作、跨模态和具身化环境,从多智能体系统到多模态集成,以及具有记忆和感知的受脑启发的架构。
RL for LLMs
第二个研究方向探讨如 何应用强化学习算法来改进或调整 LLM。其主要分支是面向 LLM 的强化学习 (RL),利用在线策略(例如,近端策略优化 PPO 和群体相对策略优化 GRPO)和离线策略(例如,行动者-评论家算法、Q-Learning)方法来增强指令遵循、伦理一致性和代码生成等能力。其互补方向是面向 RL 的 LLM,研究如何将 LLM 部署为规划器、奖励设计器、目标生成器或信息处理器,以提高控制环境中的样本效率、泛化能力和多任务规划能力,并参考了曹等人提供的系统分类法。强化学习也已融入 LLM 的整个生命周期:从数据生成和预训练到训练后和推理,正如 Guo 等人所研究的那样。其中最突出的分支是 训练后对齐,特别是基于人类反馈的强化学习 (RLHF),以及基于人工智能反馈的强化学习 (RLAIF) 和直接偏好优化 (DPO) 等扩展。
Research Gap and Our Contributions
近期,关于 LLM 代理和强化学习增强型 LLM 的研究激增,反映了两种互补的视角:一种视角探索 大型语言模型作为自主代理的核心能够发挥什么作用,另一种视角则侧重于 强化学习如何优化其行为。然而,尽管现有研究范围广泛,但对 agentic RL (将 LLM 概念化为嵌入序列决策过程的策略优化代理)的统一处理仍然缺乏。当前的研究通常考察孤立的能力、领域或自定义环境,术语和评估协议不一致,使得系统性比较和跨领域泛化变得困难。为了弥合这一差距,作者提出了一种将理论基础与算法方法和实际系统相结合的连贯综合方法。通过 马尔可夫决策过程 (MDP) 和 部分可观测马尔可夫决策过程 (POMDP) 抽象来形式化 agentic RL,以区别于经典的 LLM 强化学习范式,并引入以能力为中心的分类法,将规划、工具使用、记忆、推理、反思(自我提升)和交互作为强化学习可优化的组件。此外,还整合了支持代理 LLM 训练和评估的代表性任务、环境、框架和基准,并最终讨论了尚未解决的挑战,并概述了可扩展通用代理智能的光明未来方向。总而言之,本文旨在进一步明确本综述的研究范围:
Primary focus:
✅ how RL empowers LLM-based agents (or, LLMs with agentic characteristics) in dynamic environments
Out of scope (though occasionally mentioned):
❌ RL for human value alignment (e.g., RL for harmful query refusal);
❌ traditional RL algorithms that are not LLM-based (e.g., MARL);
❌ RL for boosting pure LLM performance on static benchmarks.

Structure of the Survey
本综述旨在逐步构建对 Agentic RL 的统一理解,涵盖从概念基础到实际应用的各个方面。其结构如下:Section 2 通过 MDP/POMDP 视角正式阐述了向代理强化学习 (Agentic RL) 的范式转变;Section 3 从能力视角审视 agentic RL,并对规划、推理、工具使用、记忆、自我提升、感知等关键模块进行分类;Section 4 探讨了跨领域的应用,包括搜索、GUI 导航、代码生成、数学推理和多智能体系统;Section 5 整合了支持实验和基准测试的开源环境和强化学习框架;Section 6 探讨了可扩展、自适应和可靠的代理智能所面临的挑战和未来发展方向;Section 7 对综述进行了总结。Fig.1 也展示了本综述的整体结构。
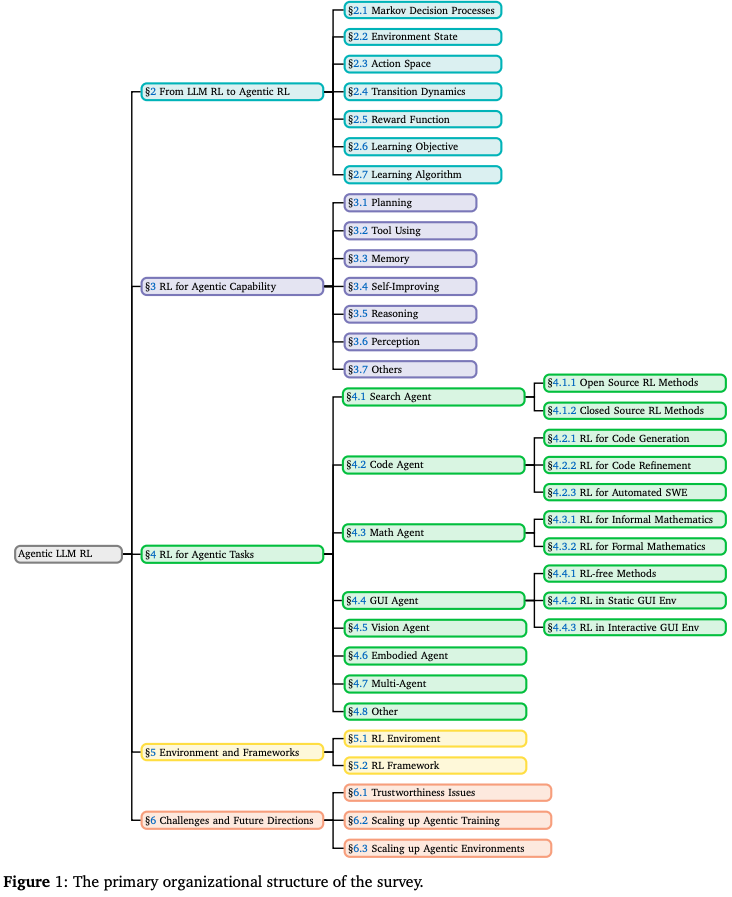
2. Preliminary: From LLM RL to Agentic RL
LLM 最初使用行为克隆进行预训练,该方法将最大似然估计 (MLE) 应用于静态数据集,例如从网络抓取的文本语料库。后续的后训练方法增强了模型能力,并使输出与人类偏好保持一致,使其超越了通用的网络数据复制器。一种常见的技术是监督微调 (SFT),即根据人工生成的(提示、响应)演示来改进模型。然而,获取足够的高质量 SFT 数据仍然具有挑战性。强化微调 (RFT) 提供了一种替代方案,它通过奖励函数来优化模型,从而避免了对行为演示的依赖。
在早期的RFT研究中,核心目标是通过人类反馈或数据偏好来优化LLM,使其与人类偏好或直接与数据偏好(如DPO)对齐。这种基于偏好的RFT(preference-based RFT, PBRFT)主要涉及在固定偏好数据集上学习LLM的奖励模型优化,或直接使用数据偏好实现该优化。随着 OpenAI o1 和 DeepSeek-R1 等具备推理能力的LLM的发布,其性能的提升和跨领域泛化能力引起了广泛关注。OpenAI o3 等既具备自进化推理能力又支持工具使用的模型的发布,研究人员开始思考如何通过强化学习方法将LLM与下游任务深度融合。随后,研究人员的关注点从旨在 优化固定偏好数据集的PBRFT转向针对特定任务和动态环境的 agentic RL。
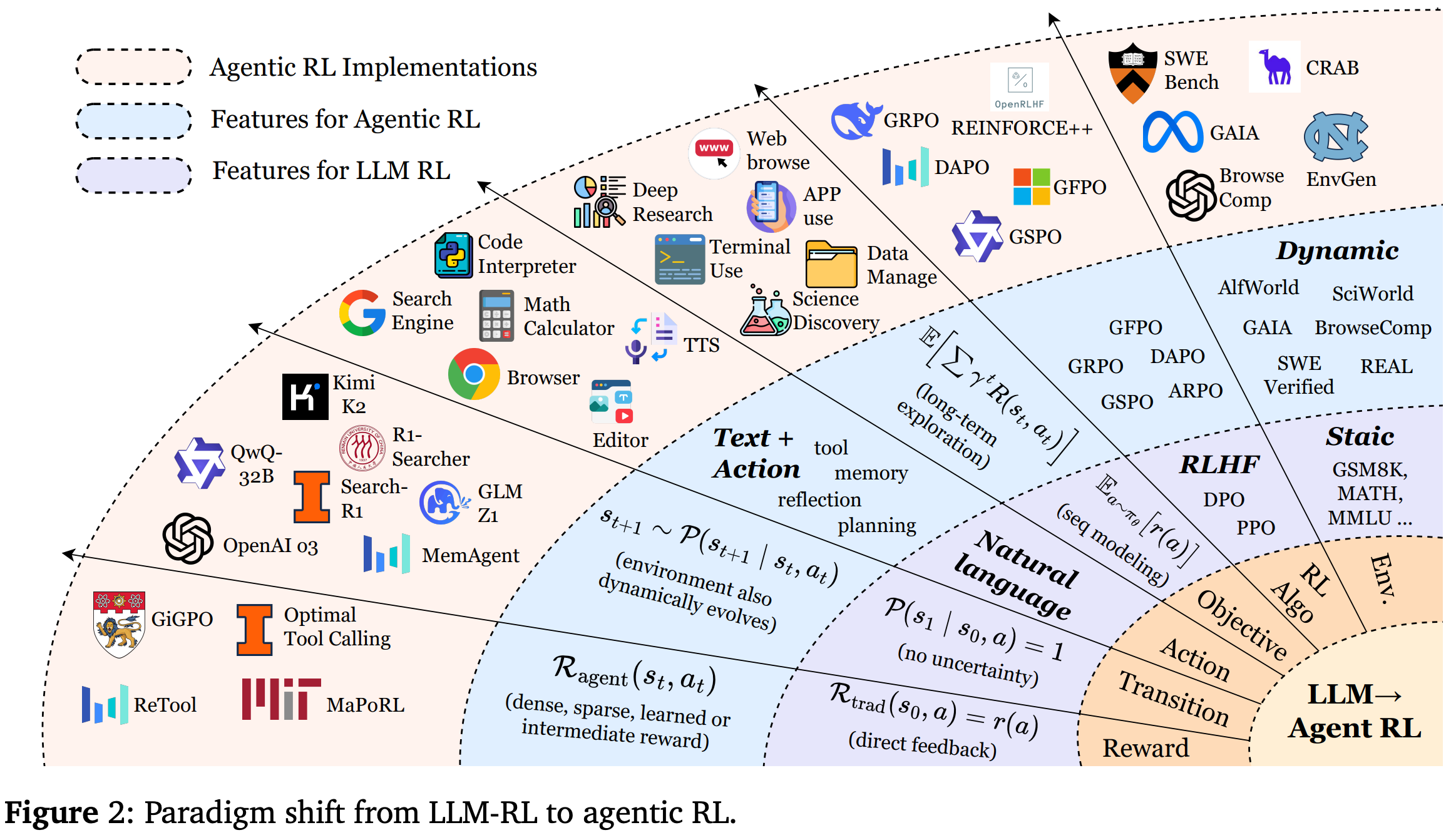
在本节中将形式化描述从 PBRFT 到新兴的代理强化学习(Agentic RL)框架的范式转变。虽然这两种方法都利用强化学习技术来提升 LLM 的性能,但它们在底层假设、任务结构和决策粒度方面存在根本差异。Fig.2 展示了从 LLM RL 到 agentic RL 的范式转变。
2.1. Markov Decision Processes
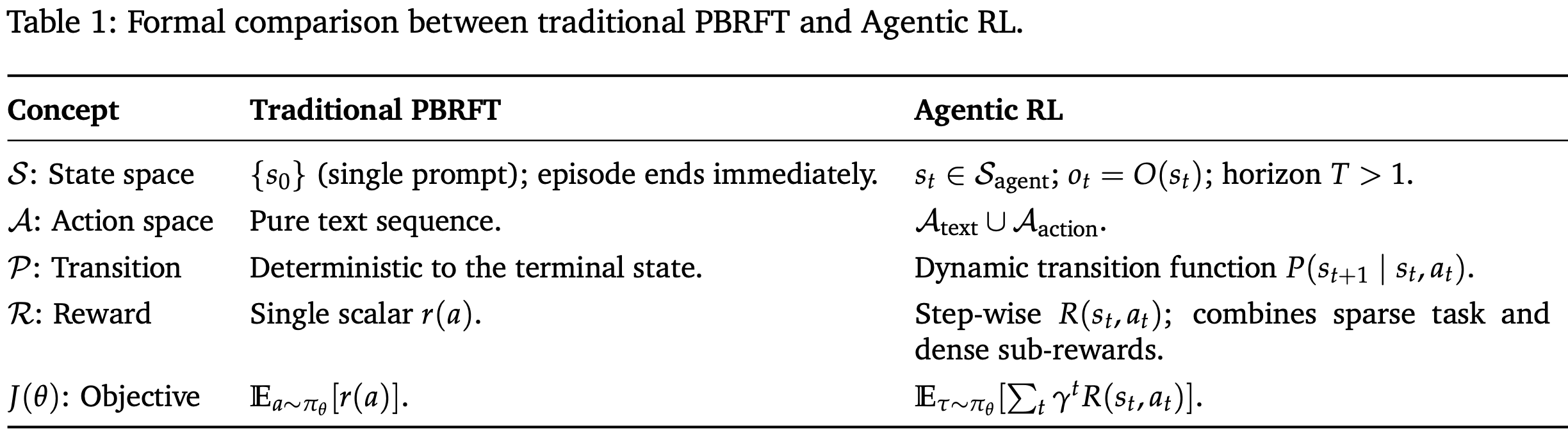
强化学习微调过程的马尔可夫决策过程 (MDP) 可以形式化为一个七元素元组 ⟨S,O,A,P,R,T,γ⟩\left \langle\mathcal{S,O,A,P,R,}T,\gamma \right \rangle⟨S,O,A,P,R,T,γ⟩,其中 S\mathcal{S}S 表示状态空间,O\mathcal{O}O 表示代理的观测空间,A\mathcal{A}A 表示动作空间,R\mathcal{R}R 定义为奖励函数,P\mathcal{P}P 表示状态转移概率,TTT 表示任务范围,γ\gammaγ 表示折扣因子。通过将基于偏好的 RFT 和 agentic RL 转化为 MDP 或 POMDP,阐明了将 LLM 视为静态序列生成器或嵌入动态环境中的交互式、具有决策能力的代理的理论含义。
PBRFT 训练过程被形式化为由以下元组定义的退化 MDP:
⟨Strad,Atrad,Ptrad,Rtrad,T=1⟩\left \langle \mathcal{S}_{trad}, \mathcal{A}_{trad}, \mathcal{P}_{trad}, \mathcal{R}_{trad}, T=1 \right \rangle ⟨Strad,Atrad,Ptrad,Rtrad,T=1⟩
Agentic RL 训练过程被建模为 POMDP:
⟨Sagent,Aagent,Pagent,Ragent,γ,O⟩\left \langle \mathcal{S}_{agent}, \mathcal{A}_{agent}, \mathcal{P}_{agent}, \mathcal{R}_{agent}, \gamma,\mathcal{O} \right \rangle ⟨Sagent,Aagent,Pagent,Ragent,γ,O⟩
其中,代理根据状态 st∈Sagents_{t}\in\mathcal{S}_{agent}st∈Sagent 接收观测值 ot∈O(st)o_{t}\in O(s_{t})ot∈O(st)。PBRFT 和 agentic RL 的主要区别如 Table.1 所示。PBRFT 在完整观测下优化固定数据集内的输出句子序列,而 agentic RL 则在以部分观测为特征的可变环境中优化语义级行为。
2.2. Environment State
PBRFT
在训练过程中,每个 episode 都从单个提示状态 s0s_{0}s0 开始;该 episode 在模型发出一个响应后立即终止。底层的 MDP 退化为一个水平 T=1T=1T=1 的单步决策问题。状态空间简化为单个静态提示输入:
Strad={prompt}\mathcal{S}_{trad}=\{\text{prompt}\} Strad={prompt}
Agentic RL
LLM agent 在 POMDP 中跨越多个时间步进行操作。设 st∈Sagents_{t}\in\mathcal{S}_{agent}st∈Sagent 表示完整的世界状态,LLM agent 基于当前状态 ot=O(st)o_{t}=\mathcal{O}(s_t)ot=O(st) 获取观测值 OtO_{t}Ot。LLM agent 根据当前观测值 oto_{t}ot 选择一个动作 ata_{t}at,状态随时间演变:
st+1∼P(st+1∣st,at)s_{t+1}\sim P(s_{t+1}|s_{t},a_{t}) st+1∼P(st+1∣st,at)
随着 agent 不断积累中间信号,例如检索到的工具结果、用户消息或环境反馈,交互本质上是动态的,并且具有时间延展性。
2.3 Action Space
在 agentic RL 中,LLM 的动作空间包含两个不相交的组件:
Aagent=Atext∪Aaction\mathcal{A}_{agent}=\mathcal{A}_{text}\cup\mathcal{A}_{action} Aagent=Atext∪Aaction
其中,Atext\mathcal{A}_{text}Atext 是通过自回归解码生成的自由格式的自然语言 tokens;Aaction\mathcal{A}_{action}Aaction 是一组结构化的非语言动作,在输出流中由特殊 token <action_start> 和 <action_end> 分隔。这些动作可以调用外部工具(例如,call("search", "Einstein"))或与环境交互(例如,move("north")),具体取决于任务需求。
这两个子空间在语义和功能角色上均有所不同:Atext\mathcal{A}_{text}Atext 生成供人类或机器解读的交流内容,而不会直接改变外部状态;而 Aaction\mathcal{A}_{action}Aaction 发出可执行命令,这些命令可以 (i) 通过工具调用获取新信息,或 (ii) 修改物理或仿真环境的状态。这种分离允许在单个强化学习框架内使用统一的策略来管理自然语言生成和操作决策。
2.4 Transition Dynamics
PBRFT
在传统的 PBRFT 中转换动态是确定性的:一旦采取行动,下一个状态就会确定,如下所示:
P(s1∣s0,a)=1,where there is no uncertainty\mathcal{P}(s_{1}|s_{0},a)=1, \text{where there is no uncertainty} P(s1∣s0,a)=1,where there is no uncertainty
Agentic RL
在 agentic RL 中,环境在不确定性下根据以下公式演变:
st+1∼P(st+1∣st,at),at∈Atext∪Aactions_{t+1}\sim\mathcal{P}(s_{t+1}|s_{t},a_{t}), a_{t}\in \mathcal{A}_{text}\cup\mathcal{A}_{action} st+1∼P(st+1∣st,at),at∈Atext∪Aaction
文本操作 Atext\mathcal{A_{text}}Atext 生成自然语言输出,且不改变环境状态。结构化操作 Aaction\mathcal{A}_{action}Aaction 由 <action_start> 和 <action_end> 分隔,可以查询外部工具或直接修改环境。这种顺序表述与 PBRFT 的一次性映射不同,它支持迭代地结合通信、信息获取和环境操作的策略。
2.5 Reward Function
PBRFT
PBRFT 通常具有可验证响应正确性的奖励函数,可以使用基于规则的验证器或神经网络参数化的奖励模型来实现。无论采用哪种实现方式,其核心都遵循以下等式:
Rtrad(s0,a)=r(a)\mathcal{R}_{trad}(s_{0},a)=r(a) Rtrad(s0,a)=r(a)
其中 r:A→Rr:\mathcal{A}\to\mathbb{R}r:A→R 是由人类或人工智能偏好模型提供的标量分数,没有中间反馈。
Agentic RL
奖励函数基于下游任务,允许密集、稀疏或学习奖励(例如,单元测试通过、符号验证器成功)。
R(agent)(st,at)={rtaskon task completion,rsub(st,at)for step-level progress,0otherwise\mathcal{R}_(agent)(s_{t},a_{t})= \begin{cases} r_{task} & \text{on task completion,} \\ r_{sub}(s_{t},a_{t}) & \text{for step-level progress}, \\ 0 & \text{otherwise} \end{cases} R(agent)(st,at)=⎩⎨⎧rtaskrsub(st,at)0on task completion,for step-level progress,otherwise
2.6 Learning Object
PBRFT
优化目标是最大化基于策略 πθ\pi_{\theta}πθ 的响应奖励,不需要折扣因子,优化类似于最大预期奖励序列建模。
Jtrad(θ)=Ea∼πθ[r(a)]J_{trad}(\theta)=\mathbb{E}_{a\sim\pi_{\theta}}[r(a)] Jtrad(θ)=Ea∼πθ[r(a)]
Agentic RL
优化目标是最大化折扣奖励,通过策略梯度或基于价值的方法进行优化,并进行探索和长期信用分配。
Jagent(θ)=Eτ∼πθ[∑t=0T−1γtRagent(st,at)],0<γ<1J_{agent}(\theta)=\mathbb{E}_{\tau\sim\pi_{\theta}}\left[ \sum^{T-1}_{t=0}\gamma^{t}R_{agent}(s_{t},a_{t}) \right], 0<\gamma<1 Jagent(θ)=Eτ∼πθ[t=0∑T−1γtRagent(st,at)],0<γ<1
PBRFT 专注于单轮文本质量对齐,无需明确的规划、工具使用或环境反馈,而 agentic RL 涉及多轮规划、自适应工具调用、状态记忆和长视界信用分配,使 LLM 能够充当自主决策代理。
2.7 RL Algorithms
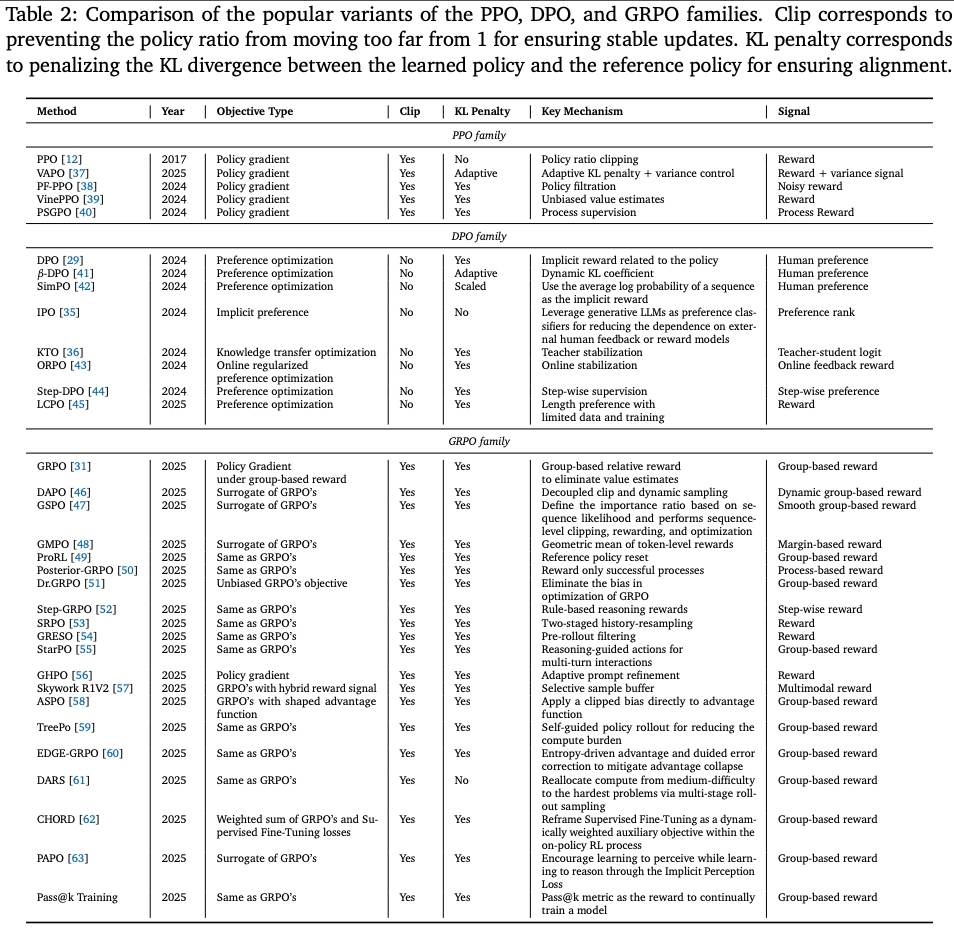
在当代研究中,强化学习算法是 PBRFT 和 agentic RL 学习框架中的关键组成部分。不同的强化学习算法展现出不同的样本效率和性能特征,每种算法都提供了独特的方法来解决将模型输出与复杂且通常主观的人类目标相一致的核心挑战。诸如 REINFORCE、PPO、GRPO 和 DPO 等经典方法,构成了从通用策略梯度到专用偏好学习的光谱。接下来,将分别介绍这三种经典算法,并在 Table.2 中比较了每个算法家族中流行的变体。
REINFORCE: The Foundational Policy Gradient
作为最早的策略梯度算法之一,REINFORCE 为训练随机策略提供了基础理论。它的运作方式是 增加导致高累积奖励的动作的概率,并降低导致低奖励的动作的概率。其目标函数如下:
∇θJ(θ)=Es0[1N∑i=1N(R(s0,a(i))−b(s0)∇θlogπθ(ai∣s0))]\nabla_{\theta}J(\theta)=\mathbb{E}_{s_{0}} \left[ \frac{1}{N} \sum^{N}_{i=1} \left( \mathcal{R}(s_{0},a^{(i)})-b(s_{0})\nabla_{\theta}\log\pi_{\theta}(a^{i}|s_{0}) \right) \right] ∇θJ(θ)=Es0[N1i=1∑N(R(s0,a(i))−b(s0)∇θlogπθ(ai∣s0))]
其中 a(i)∼πθ(a∣s0)a^{(i)}\sim\pi_{\theta}(a|s_{0})a(i)∼πθ(a∣s0) 是第 iii 个采样响应,R(s0,a)\mathcal{R}(s_{0},a)R(s0,a) 表示任务完成后获得的最终奖励,b(s)b(s)b(s) 是一个用于降低策略梯度估计方差的基线函数。通常 b(s)b(s)b(s) 可以是任何函数,包括随机变量。
Proximal Policy Optimization (PPO)
PPO 凭借其稳定性和可靠性,成为 LLM 对齐的主流强化学习算法。它通过 限制更新步长来改进 vanilla policy 梯度,从而避免策略发生过大的破坏性变化。其主要的裁剪目标函数为:
LPPO(θ)=1N∑i=1Nmin(πθ(at(i)∣st)πθold(at(i)∣st)A(st,at(i)),clip(πθ(at(i)∣st)πθold(at(i)∣st),1−ϵ,1+ϵ)A(st,at(i)))L_{PPO}(\theta)=\frac{1}{N} \sum^{N}_{i=1}\min \left( \frac{\pi_{\theta}(a^{(i)}_{t}|s_{t})}{\pi_{\theta_{old}}(a^{(i)}_{t}|s_{t})}A(s_{t},a^{(i)}_{t}), \text{clip} \left( \frac{\pi_{\theta}(a^{(i)}_{t} |s_{t})}{\pi_{\theta_{old}}(a^{(i)}_{t}|s_{t})},1-\epsilon,1+\epsilon \right) A(s_{t},a^{(i)}_{t}) \right) LPPO(θ)=N1i=1∑Nmin(πθold(at(i)∣st)πθ(at(i)∣st)A(st,at(i)),clip(πθold(at(i)∣st)πθ(at(i)∣st),1−ϵ,1+ϵ)A(st,at(i)))
其中 at(i)∼πθold(a∣st)a^{(i)}_{t}\sim\pi_{\theta_{old}}(a|s_{t})at(i)∼πθold(a∣st) 是旧策略 πθold\pi_{\theta_{old}}πθold 的第 iii 个采样响应,其更新被延迟。AtA_{t}At 是估计的优势,由下式给出:
A(st,at)=R(st,at)−V(st)A(s_{t},a_{t})=\mathcal{R}(s_{t},a_{t})-V(s_{t}) A(st,at)=R(st,at)−V(st)
其中 Vθ(s)V_{\theta}(s)Vθ(s) 是学习到的价值函数,即期望值 Ea∼πθ(a∣s)[R(s,a)]\mathbb{E}_{a\sim\pi_{\theta}(a|s)}[\mathcal{R}(s,a)]Ea∼πθ(a∣s)[R(s,a)],来自一个 与策略网络大小相同的评价网络。裁剪项可防止概率比偏离 1 过远,从而确保更新的稳定性。一个关键缺点是 依赖于单独的评价网络进行优势估计,这会大大增加训练过程中的参数数量。
Direct Preference Optimization (DPO)
DPO 代表着一项突破性的转变,它 完全绕过了对单独奖励模型的需求。将在 KL 约束下最大化奖励的问题重新定义为 基于人类偏好数据的似然函数目标。给定一个偏好数据集 D={(yw,yl)}D=\{(y_{w},y_{l})\}D={(yw,yl)},其中 ywy_{w}yw 是偏好响应,yly_{l}yl 是非偏好响应,则 DPO 损失为:
LDPO(πθ;πref)−E(x,yw,yl)∼D[logσ(βlogπθ(yw∣x)πref(yw∣x)−βlogπθ(yl∣x)πref(yl∣x))]L_{DPO}(\pi_{\theta};\pi_{ref})-\mathbb{E}_{(x,y_{w},y_{l})\sim D} \left[ \log \sigma \left( \beta\log \frac{\pi_{\theta}(y_{w}|x)}{\pi_{ref}(y_{w}|x)}- \beta\log\frac{\pi_{\theta}(y_{l}|x)}{\pi_{ref}(y_{l}|x)} \right) \right] LDPO(πθ;πref)−E(x,yw,yl)∼D[logσ(βlogπref(yw∣x)πθ(yw∣x)−βlogπref(yl∣x)πθ(yl∣x))]
其中 πref\pi_{ref}πref 是参考策略(通常是初始 SFT 模型),β\betaβ 是超参数。虽然 DPO 消除了批评者的影响,但其性能本质上与其静态偏好数据集的质量和覆盖范围息息相关。为了弥补其局限性,出现了一些变体,包括 IPO(Identity Preference Optimization),它添加了一个正则化项来防止过拟合;以及 KTO(Kahneman-Tversky Optimization),它从每个响应的二进制信号(期望/不期望)中学习,而不是严格的成对比较。更多变体请参见 Table.2。
Group Relative Policy Optimization (GRPO)
DeepSeek 取得的显著成功激发了人们对 GRPO 的浓厚研究兴趣。为了解决 PPO 大型批评家的低效问题,GRPO 引入了一种新颖的轻量级评估范式。它对一组响应进行操作,利用它们在组中的相对奖励来计算优势,从而消除了对绝对值批评家的需求。GRPO 的核心目标可以概念化为:
LGRPO=1G∑g=1Gmin(πθ(at(g)∣st(g))πθold(at(g)∣st(g))A^(st(g),at(g)),clip(πθ(at(g)∣st(g))πθold(at(g)∣st(g)),1−ϵ,1+ϵ)A^(st(g),at(g)))L_{GRPO}=\frac{1}{G}\sum^{G}_{g=1}\min \left( \frac{ \pi_{\theta}(a^{(g)}_{t}|s_{t}^{(g)}) }{\pi_{\theta_{old}}(a^{(g)}_{t}|s^{(g)}_{t})}\hat{A}(s_{t}^{(g)},a^{(g)}_{t}), \text{clip} \left( \frac{\pi_{\theta}(a_{t}^{(g)}|s_{t}^{(g)})}{\pi_{\theta_{old}}(a^{(g)}_{t}|s^{(g)}_{t})},1-\epsilon,1+\epsilon \right)\hat{A}(s_{t}^{(g)},a^{(g)}_{t}) \right) LGRPO=G1g=1∑Gmin(πθold(at(g)∣st(g))πθ(at(g)∣st(g))A^(st(g),at(g)),clip(πθold(at(g)∣st(g))πθ(at(g)∣st(g)),1−ϵ,1+ϵ)A^(st(g),at(g)))
其中,从旧策略 πθold\pi_{\theta_{old}}πθold中采样一组输出 {(so(g),a0(g),…,sT−1(g),aT−1(g))}g=1G\{(s_{o}^{(g)},a_{0}^{(g)},\dots,s_{T-1}^{(g)},a_{T-1}^{(g)})\}^{G}_{g=1}{(so(g),a0(g),…,sT−1(g),aT−1(g))}g=1G。优势函数估计如下:
A^(st,at)=R(st,at)−mean(R(st1,at1),…,R(stG,atG))std(R(st(1,at(1)),…,R(stG,atG))\hat{A}(s_{t},a_{t})= \frac{\mathcal{R}(s_{t},a_{t})-\text{mean}(\mathcal{R}(s_{t}^{1},a_{t}^{1}),\dots,\mathcal{R}(s_{t}^{G},a_{t}^{G}))} {\text{std}(\mathcal{R}(s_{t}^{(1},a^{(1)}_{t}),\dots,\mathcal{R}(s_{t}^{G},a_{t}^{G}))} A^(st,at)=std(R(st(1,at(1)),…,R(stG,atG))R(st,at)−mean(R(st1,at1),…,R(stG,atG))
这种基于群体的方法具有较高的样本效率,并降低了计算开销。因此,一系列基于GRPO框架的新算法相继被提出 Table.2,旨在显著提升强化学习方法的样本效率和渐近性能。
3. Agentic RL: The model capability perspective
在本节从概念上将 Agentic RL 描述为对自主代理的原则性训练,该代理由一组关键能力 / 模块组成,即 planning Section 3.1、tool use Section 3-2、memory Section 3.3、self-improvement Section 3-4、reasoning Section 3.5、perception Section 3.6和 others Section 3.7。
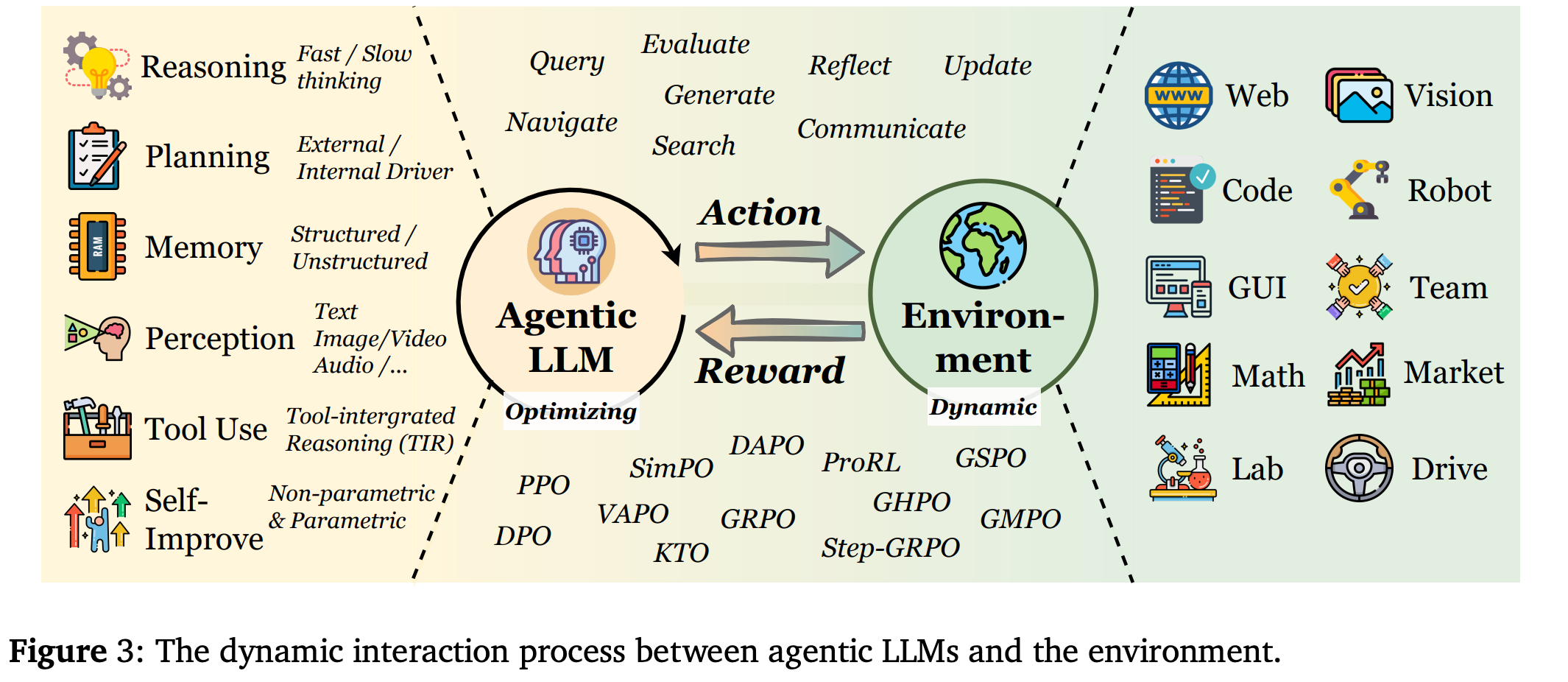
遵循经典的 LLM agent 定义,如 Fig.4 所示。传统上,agent 将 LLM 与规划(例如,任务分解和计划选择)、推理(思路链或多轮推理)、外部工具调用、长期和短期记忆以及迭代反射的机制配对,以自我纠正和改进行为。因此,Agentic RL 将这些组件视为相互依存、可联合优化的策略,而非静态流程:用于规划的强化学习学习多步决策轨迹;用于记忆形状检索和编码动态的强化学习;用于工具使用的强化学习优化调用时机和保真度;用于反思的强化学习则推动内部自监督和自我改进。在后续小节中系统地探讨强化学习如何赋能规划、工具使用、记忆、反思和推理。旨在提供强化学习在代理功能方面的应用的高级概念描述,而不是详尽列举所有相关工作。
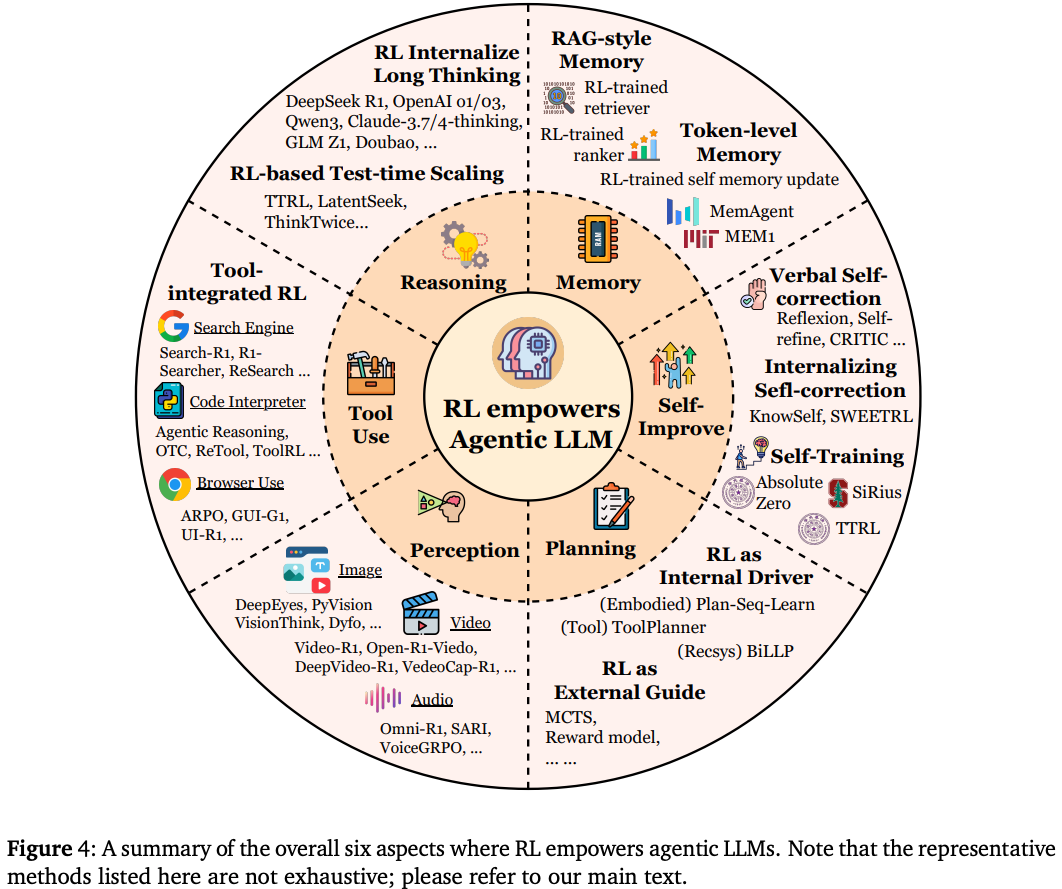
3.1 Planning
即对一系列行动进行深思熟虑以实现目标的过程,是人工智能的基石,需要复杂的 推理能力、世界知识 和 适应性。虽然最初的努力通过基于提示的方法(例如,ReAct)利用了LLM的先天能力,但这些方法缺乏通过经验进行适应的机制。强化学习(RL)已成为弥补这一差距的强大范式,使智能体能够通过学习环境反馈来改进其规划策略。强化学习与智能体规划的整合体现在两种不同的范式中,区别在于 强化学习是作为结构化规划过程的外部引导,还是 作为直接演进LLM内在规划策略的内部驱动力,将在下文详细介绍。
RL as an External Guide for Planning
一种主要的范式将强化学习构建为规划过程的外部引导,其中 LLM 的主要作用是在结构化搜索框架内生成潜在行动。强化学习并非直接用于微调 LLM 的生成能力,而是用于训练辅助奖励或启发式函。然后,该学习函数通过评估不同规划轨迹的质量来指导经典搜索算法,例如蒙特卡洛树搜索 (MCTS)。RAP 和 LATS 等代表性工作体现了这种方法。它们利用强化学习辅助模型来评估 LLM 生成的步骤,从而引导搜索朝着更有希望的解决方案发展。在这种配置下,LLM 充当知识丰富的行动提议器,而 强化学习则提供高效探索所需的自适应评估反馈。
RL as an Internal Driver of Planning
第二种更具集成性的范式将强化学习定位为 智能体核心规划能力的内部驱动力。这种方法将 LLM 直接视为策略模型,并通过直接的环境交互来优化其规划行为。它并非引导外部搜索算法,而是 利用基于强化学习的试错反馈来直接优化 LLM 的内部策略,从而生成规划。这可以通过 RLHF 的方法实现,例如在 ETO 中利用 DPO 来分析成功与失败的轨迹,或者通过终身学习框架来实现。VOYAGER 通过与环境交互迭代构建和优化技能库。这种范式将 LLM 从静态生成器转变为持续演进的自适应策略,从而增强其在动态环境中的鲁棒性和自主性;AdaPlan 及其 PilotRL 框架利用基于全局规划的指导和渐进式强化学习,增强 LLM 智能体在 AFLWorld 和 TextCraft 等文本游戏环境中的长期规划和执行协调能力。
Prospective: The Synthesis of Deliberation and Intuition
代理规划的未来前景在于这两种范式的融合:超越外部搜索和内部策略优化之间的区别。最终目标是开发一个能够内化结构化搜索过程的 agent,将直观、快速的计划生成与深思熟虑、缓慢、审慎的推理无缝融合。在这样的模型中,强化学习不仅会优化最终计划,还会优化控制审慎过程的元策略:学习何时探索替代路径、如何修剪没有前景的分支,以及在执行操作之前进行多深入的推理。这将使 LLM agent 从一个提出操作或充当原始策略的组件转变为一个集成的推理引擎。
3.2 Tool Using
强化学习已成为一种关键方法,推动工具赋能型语言代理从事后 ReAct 式流程发展为深度交错、多轮工具集成推理(TIR)系统。虽然早期范式成功证明了工具调用的可行性,但它们对 SFT 或即时工程的依赖,限制了代理模仿静态模式,缺乏适应新场景或从错误中恢复的战略灵活性。Agent RL 通过 将学习范式从模仿转向结果驱动的优化 来解决这个问题,使 agent 能够自主发现何时、如何以及部署哪些工具。这一演变描绘了一条清晰的轨迹,本文中作者将分三个阶段进行探讨:
- 早期 ReAct 式工具调用;
- 将工具使用深度嵌入认知循环的现代工具集成推理(TIR);
- 多轮TIR的未来挑战,重点关注时间信用分配,以实现稳健的长期性能;
ReAct-style Tool Calling
早期的工具调用范式主要依赖于 Prompt Engineering 或 SFT 来引出工具使用行为。(I) Prompt Engineering 例如 ReAct,利用少样本样本引导 LLM 在 “Thought-Action-Observation” 循环中交织推理轨迹和行动,从而充分利用模型的情境学习能力;(II) 更进一步,引入了 SFT-based methods,以内化模型的工具使用能力,Toolformer 等框架采用自监督目标来指导模型在何处插入 API 调用,而 FireAct、AgentTuning 和 Agent-FLAN 等其他框架则基于专家生成或整理的工具交互轨迹数据集(例如 AgentBank、APIBank)对模型进行微调。尽管 SFT 提高了工具调用的可靠性,但这两种早期方法都从根本上受限于其模仿性。它们训练智能体复制静态的、预定义的工具使用模式,因此缺乏适应新场景或从不可预见的错误中恢复的策略灵活性。而以强化学习为中心的方法则通过将学习目标从模仿转向结果驱动的优化,直接解决了这一限制。
Tool-integrated RL
基于纯模仿范式的局限性,基于强化学习的工具使用方法 将目标从复制固定模式转变为优化最终任务性能。这种转变使智能体能够策略性地决定何时、如何以及以何种组合调用工具,从而动态地适应新的情境和不可预见的故障。在此基础上,诸如 ToolRL 之类的框架证明,即使从没有任何模仿痕迹的基础模型初始化,强化学习训练也能激发新兴能力,例如,错误代码的自我修正、调用频率的自适应调整以及为复杂的子任务组合多个工具。随后,近期研究热潮涌现,涌现出诸如 OTC-PO、ReTool、AutoTIR、VTool-R1、DeepEyes、Pixel-Reasoner、Agentic Reasoning、ARTIST、ToRL 等众多研究成果,这些研究成果采用强化学习策略,将符号计算(例如代码执行、图像编辑)与自然语言推理交织在一起一次性完成。这种集成控制回路使智能体能够平衡精确的工具介导操作和灵活的语言推理,从而根据不断变化的任务状态调整推理过程。最近的研究从理论上证明,TIR 通过引入确定性工具驱动的状态转换,从根本上扩展了 LLM 功能,使其超越了纯文本 RL 的 “invisible leash”,建立了有限预算下可行性的令牌效率论据,并提出了优势塑造策略优化 (ASPO) 来稳定地指导代理工具的使用。
如今,这种工具集成推理已不再是一项小众能力,而是高级代理模型的基本特征。成熟的商业和开源系统,例如 OpenAI 的 DeepResearch 和 o3、Kimi K2、Qwen QwQ-32B、Zhipu GLM Z1、微软 rStar2-Agent 和美团 LongCat,都经常采用这些强化学习策略,凸显了结果驱动优化在工具增强智能中的核心地位。
Prospective: Long-horizon TIR
虽然工具集成强化学习已被证明能够有效地优化单个推理循环中的动作,但主要的前沿领域在于将这种能力扩展到需要多轮推理的鲁棒、长期任务,这一飞跃的瓶颈在于时间信用分配的挑战。当前的强化学习方法通常依赖于稀疏的、基于 trajectory-level/outcome-based 的奖励,这使得很难确定在一个长期相互依赖的序列中,是哪个特定的工具调用导致了成功或失败。虽然新兴研究已经开始探索更精细的奖励方案,例如 GiGPO 和 SpaRL 中的轮级优势估计,但这些仍处于早期阶段。因此,开发更精细的信用分配机制,能够准确地引导智能体完成复杂的决策链,而不会无意中惩罚有用的探索或促进 reward hacking,仍然是推进智能体系统的关键且很大程度上尚未解决的问题。
3.3 Memory
Agentic RL 将记忆模块从被动数据存储转变为动态的、RL 控制的子系统,能够像人类一样决定存储什么、何时检索以及如何遗忘。本节通过四个代表性阶段追溯了这一演进过程。
RL in RAG-style Memory
早期系统(例如,检索增强生成 RAG)将记忆视为外部数据存储;当使用强化学习时,它仅负责调节何时执行查询。一些不涉及强化学习的经典记忆系统,例如 MemoryBank、MemGPT 和 Hip poRAG,采用预定义的记忆管理策略,指定如何存储、集成和检索信息(例如,通过向量数据库或知识图谱存储;基于语义相似性或拓扑连通性进行检索)。随后,强化学习被纳入记忆管理流程,成为一个功能组件。一个值得注意的例子是一个新的框架,其中强化学习策略通过 前瞻性反思(多级摘要)和 回顾性反思(强化检索结果)来调整检索行为。然而,记忆介质本身保持静态(例如,简单的向量存储或摘要缓冲区),并且 agent 对写入过程没有任何控制。最近,Memory-R1 引入了一个基于 RL 的记忆增强代理框架,其中记忆管理器根据下游 QA 性能通过 PPO 或 GRPO 学习执行结构化操作(ADD/UPDATE/DELETE/NOOP),而答案 agent 则采用记忆蒸馏策略对 RAG 检索到的条目进行推理和回答。
RL for Token-level Memory
后续进展引入了配备显式、可训练记忆控制器的模型,使智能体能够调节自身的记忆状态(通常以标记形式存储),而无需依赖固定的外部记忆系统。值得注意的是,这种记忆通常以两种形式实例化。
- explicit tokens:对应于人类可读的自然语言。例如,在
MemAgent中,智能体除了 LLM 之外还维护一个自然语言记忆池,RL 策略在每个片段中确定要保留或覆盖哪些 tokens,从而有效地将长上下文输入压缩为简洁、信息丰富的摘要。类似的方法包括MEM1和Memory Token,它们都显式地保存了一个自然语言记忆表征池; - implicit tokens:记忆以潜在嵌入的形式维护。代表性的研究包括
MemoryLLM和M+,其中一组固定的潜在标记充当 “memory tokens”。随着上下文的变化,这些标记会被反复检索,集成到 LLM 的前向计算中并进行更新,从而保留上下文信息并表现出强大的抗遗忘能力。与显式 tokens 不同,这些记忆 tokens 并非与人类可读的文本绑定,而是构成了一种机器原生的记忆形式。相关研究包括IMM和Memory。在这两种范式中,这些方法使智能体能够自主管理其记忆库,从而显著提升了长上下文理解、持续适应和自我完善的能力。
Prospective: RL for Structured Memory
基于 token-level 方法,近期趋势正朝着结构化记忆表征方向发展,这种表征能够组织和编码超越 flat token 序列的信息。代表性示例包括 Zep 中的时间知识图谱、A-MEM 中的原子记忆笔记,以及 G-Memory 和 Mem0 中基于层次化图谱的记忆设计。这些系统能够捕捉更丰富的关系、时间或层次依赖关系,从而实现更精确的检索和推理。然而,迄今为止它们的管理(包括插入、删除、抽象和链接更新)一直受制于人工制定的规则或启发式策略,很少有研究探索使用强化学习来动态控制此类结构化记忆的构建、改进或演化,这使得这成为提升代理记忆能力的一个开放且充满希望的方向。
3.4 Self-Improvement
随着 LLM 智能体的发展,近期研究日益强调 强化学习作为一种持续反思的机制,使智能体能够从自身在规划、推理、工具使用和记忆过程中犯下的错误中学习。这些系统并非仅仅依赖于数据驱动的训练阶段或静态奖励模型,而是融入了迭代式、自生式的反馈循环,涵盖从提示级启发式到成熟的强化学习控制器等各种类型,从而引导智能体不断自我完善。
RL for Verbal Self-correction
此类方法的初始阶段利用了基于提示的启发式方法,有时也称为言语强化学习。在这种方法中,智能体生成答案,从语言上反思其潜在错误,然后生成改进的解决方案,所有操作均在一次推理过程中完成,无需梯度更新。其中,突出的例子包括 Reflexion、Self-refine、CRITIC 和 Chain of-Verification。例如,Self-Refine 协议指示 LLM 使用三个不同的提示(生成、反馈和改进)迭代地完善其输出,事实证明,该协议在推理和编程等领域均有效。为了增强这种自我反思的有效性和鲁棒性,人们开发了几种不同的策略:
- multiple sampling:通过从模型分布中抽样来生成多个输出 rollout,汇总来自多次尝试的批评或解决方案,智能体可以提高其自我反思的一致性和质量。该方法已在
If-or-Else、UALA和多智能体验证等著作中得到广泛研究,该方法在概念上类似于测试时间扩展技术; - structured reflection workflows:结构化的反思工作流,而不是提示对最终答案进行整体反思,而是规定了一个更专用、更细粒度的工作流。例如,Chain-of-Verification 将过程手动分解为不同的“检索、反思和修订”阶段;
- external guidance:外部指导,通过整合外部工具,将反思过程建立在可验证的客观反馈之上。这些工具包括
Self-Debugging中的代码解释器、Luban中的 CAD 建模程序、T1中的数学计算器、逐步奖励模型等。
RL for Internalizing Self-correction
虽然言语自我纠正提供了一种强大的推理时间技术,但其改进是短暂的,并且仅限于单个会话。为了灌输更持久、更通用的自我改进能力,后续研究采用了 基于梯度更新的强化学习,将这些反射反馈回路直接内化到模型参数中,并从根本上增强了模型识别和纠正自身错误的能力。该范式已应用于多个领域。例如,KnowSelf 利用 DPO 和 RPO 来增强智能体在基于文本的游戏环境中的自我反思能力;Reflection-DPO 专注于用户-智能体交互场景,使智能体能够通过反射推理更好地推断用户意图;DuPo 采用带有双任务反馈的强化学习来实现无注释优化,增强了 LLM 智能体在翻译、推理和重排序任务中的自我纠正能力;SWEET-RL 和 ACC-Collab 的设定与上述研究略有不同:它们训练了一个外部评价模型,为行动者智能体的行为提供更高质量的修正建议。尽管如此,其基本原理仍然紧密相关。
RL for Iterative Self-training
第三类也是最先进的模型,朝着完全自主代理的方向发展,将反思、推理和任务生成结合成一个自我维持的循环,无需人工标注数据即可实现无限的自我改进。这些方法可以通过其学习循环的架构来区分:
- Self-play and search-guided refinement:,模拟
AlphaZero等经典强化学习范式。例如,R-Zero使用蒙特卡洛树搜索 (MCTS) 来探索推理树,并利用搜索结果从头开始迭代训练策略 LLM(执行者)和值 LLM(批评者)。类似地,ISC框架实现了 “"Imagination, Searching and Criticizing” 的循环,其中 agent 生成潜在的解决方案路径,使用搜索算法进行探索,并应用批评者来改进其推理策略,最终得出最终答案; - Execution-guided curriculum generation:智能体自行创建问题并从可验证的结果中学习。
Absolute Zero通过自行提出任务、尝试解决方案、通过执行验证解决方案,并使用基于结果的奖励来完善其策略,以此为例进行了说明。类似地,自进化课程通过将问题选择本身定义为非平稳老虎机任务来增强这一过程,使智能体能够策略性地生成课程,从而随着时间的推移最大化其学习收益;TTRL将此原则应用于单个问题的动态调整。在测试时,它使用基于执行的奖励来快速微调智能体策略的临时副本,以适应当前的特定任务;然后,使用此专门的策略生成最终答案,然后再丢弃。尽管学习是永久性的还是短暂性的,所有这些方法都强调了一个强大而统一的策略:利用基于执行的反馈来自主引导智能体的推理过程;ALAS构建了一个自主的流程,它可以抓取网络数据,将其提炼成训练信号,并持续微调 LLM,从而实现无需手动数据集管理的自我训练和自我进化; - Collective bootstrapping:通过聚合共享经验来加速学习。例如,
SiriuS构建并扩充了一个来自多智能体交互的成功推理轨迹的实时存储库,并利用这个不断增长的知识库来引导自己的训练课程;MALT也有类似的动机,但其实现仅限于三智能体设置。尽管如此,所有这些方法都定义了内部生成且持续演化的反馈回路,代表着向真正自主智能体迈出的重要一步;
Prospective: Meta Evolution of Reflection Ability
虽然当前的研究成功地利用强化学习通过反思来改进智能体的行为,但反思过程本身在很大程度上仍然是手工设计的、静态的。下一个前沿领域在于 将强化学习应用于更高的抽象层次,以实现自适应反思的元学习,不仅关注纠正错误,还关注学习如何随着时间的推移更有效地自我纠正。在这种范式中,智能体可以学习一种元策略来控制其自身的反思策略。例如,它可以学习动态地为给定任务选择最合适的反思形式,决定快速的口头检查是否足够,还是需要更昂贵的、由执行引导的搜索。此外,智能体可以利用长期结果来评估和改进其用于自我批评的启发式方法,从而有效地学习成为更好的内部批评者。通过优化反思机制本身,这种方法超越了简单的自我纠正,并在学习过程中迈向持续的自我改进状态,这代表着智能体迈出了关键一步,使其不仅能够解决问题,还能自主提升从经验中学习的基本能力。
3.5 Reasoning
根据双过程认知理论,大型语言模型中的推理大致可分为 快速推理 和 慢速推理。快速推理指的是快速、启发式驱动的推理,中间步骤最少;而慢速推理则强调深思熟虑、结构化和多步骤的推理。理解这两种范式之间的权衡,对于设计在复杂问题解决中平衡效率和准确性的模型至关重要。
Fast Reasoning: Intuitive and Efficient Inference
快速推理模型的运作方式类似于 System 1 cognition:快速、直观且模式驱动,无需明确的逐步思考即可生成即时响应,在优先考虑流畅性、效率和低延迟的任务中表现出色。大多数传统的 LLM 都属于此类,其推理过程隐式地编码在下一个 tokens 的预测中。然而,这种效率是以牺牲系统性推理为代价的,这使得这些模型更容易受到事实错误、偏见和浅层泛化的影响。
为了解决快速推理中严重的幻觉问题,当前的研究主要集中在各种直接方法上。一些研究试图通过利用内部机制或模拟类人认知推理来减轻下一个标记预测范式中的错误和幻觉。其他研究则提出引入外部和内部置信度估计方法,以识别更可靠的推理路径。然而,构建此类外部推理框架通常会带来算法自适应性问题的风险,并且很容易陷入复杂性陷阱。
Slow Reasoning: Deliberate and Structured Problem Solving
相比之下,慢速推理模型旨在通过显式生成中间推理轨迹来模拟 System 2 cognition。诸如 思路链提示、多步验证和推理增强强化学习 等技术,使这些模型能够进行更深入的思考,并实现更高的逻辑一致性。虽然由于推理轨迹扩展导致推理速度较慢,但它们在知识密集型任务(例如数学、科学推理和多跳问答)中实现了更高的准确性和鲁棒性。代表性示例包括 OpenAI的 o1 和 o3 系列、DeepSeek R1,以及结合动态测试时间扩展或强化学习进行推理的方法。
现代慢速推理的输出结构与快速推理截然不同。这些结构包括 清晰的探索和规划结构、频繁的验证和检查行为,以及通常更长的推理长度和时间。过去的研究探索了构建长链推理输出的各种模式。一些方法 Macro-o1、HuatuoGPT-o1 和 AlphaZero 尝试通过结构化的代理搜索来合成长链思维。其他方法则侧重于生成体现特定审议或反思性思维模式的长链思维数据集;例如 HiICL-MCTS、LLaVA-CoT、rStar-Math 和 ReasonFlux。随着预训练基础模型的进步,最近的研究转向自我改进范式(通常通过强化学习来实例化),以进一步增强模型的推理能力。
Prospective: Integrating Slow Reasoning Mechanisms into Agentic Reasoning
快速推理和慢速推理之间的二分法凸显了代理推理中的一个开放性挑战:如何利用强化学习在代理场景中可靠地训练慢速思维推理能力。代理场景中的强化学习在训练稳定性方面面临更大的挑战,例如确保与不同环境的兼容性。代理推理本身也容易受到过度思考问题的影响。纯粹的快速模型可能会忽略关键的推理步骤,而慢速模型则经常受到过度延迟或过度思考行为的影响,例如不必要的长思维链。新兴方法寻求混合策略,将快速推理的效率与慢速推理的严谨性相结合。例如,自适应测试时间扩展允许模型根据任务复杂性决定是快速响应还是进行长时间的思考。开发这种认知协调的机制是构建高效可靠的推理代理的关键一步。
3.6 Perception
通过将视觉感知与语言抽象连接起来,大型视觉-语言模型 (Large Vision–Language Models, LVLM) 展现出了前所未有的感知和理解多模态内容的能力。这一进展的核心是 将显式推理机制融入多模态学习框架,从而超越被动感知,迈向主动视觉认知。强化学习已成为实现这一目标的强大范式,它能够将 VLA 模型与复杂的多步骤推理目标相结合,突破了监督式下一个 token 预测的限制。
From Passive Perception to Active Visual Cognition
多模态内容通常需要细致入微、依赖于上下文的解读。受强化学习在提升 LLM 推理能力方面取得的显著成功的启发,研究人员越来越多地寻求将这些成果迁移到多模态学习中。早期的研究重点是 利用基于偏好的强化学习来增强多模态学习模型(MLLM)的思维链 (CoT) 推理能力。
Visual-RFT和Reason-RFT:将 GRPO 直接应用于视觉领域,自适应地将 IoU 等视觉特定指标纳入可验证的奖励信号;STAR-R1:引入针对视觉 GRPO 定制的部分奖励来扩展这一思路;Vision-R1、VLM-R1、LMM-R1和MM-Eureka:开发了专门的策略优化算法,旨在激励逐步视觉推理,即使在较小的 3B 参数模型上也表现出强大的性能;SVQA-R1:引入了Spatial-GRPO,这是一种新颖的分组强化学习方法,可强制实现视图一致和变换不变的目标;Visionary-R1:将图像字幕制作作为推理前的先决步骤,从而减少了强化学习微调过程中的捷径利用。
一系列课程学习方法也被提出,以简化和平滑视觉强化学习微调的训练过程。
R1-V:引入了 VLM-Gym,并通过可扩展的纯强化学习自进化和感知增强冷启动来训练 G0/G1 模型,从而在各种视觉任务中产生感知-推理协同效应;R1-Zero:表明即使是简单的基于规则的奖励也能在非 SFT 模型中引发自我反思和扩展推理,其效果超越了监督学习的基线模型;PAPO:提出了一个感知感知策略优化框架,该框架通过隐式感知 KL 损失和双熵正则化来增强强化学习虚拟学习方法;- Li 等人 :提出了一个在强化学习训练下进行“总结-推理”的框架,以减轻视觉幻觉,并在没有密集人工标注的情况下提高推理能力。
总的来说这些方法表明,只要使用精心设计、可验证的奖励指标,R1 风格的 RL 就可以成功转移到视觉领域,从而显著提高性能、稳健性和分布外泛化能力。
近期研究探索了强化学习的另一个关键优势:它不再将任务表述为被动感知,而是仅根据基于文本的视觉语言模型 (LVLM) 的输出计算静态、可验证的奖励。相反,强化学习可以用来激励对多模态内容的主动认知,将视觉表征视为可操作和可验证的中间思维。这种范式使模型不仅能够 “look and answer”,还能作为多步骤认知过程的一部分,主动观察、操作和推理视觉信息。
Grounding-Driven Active Perception
为了从被动感知发展到主动视觉认知,一个关键方向是使 LVLM 能够在生成推理过程的同时反复回顾和查询图像。这可以通过基础来实现,它将生成的思维链 (CoT) 的每个步骤锚定到多模态输入的特定区域,通过将文本与相应的视觉区域明确关联,促进更有效、更可验证的推理。
首先,GRIT 将 bounding box tokens 与文本 CoT 交织在一起,并使用具有可验证奖励和边界框正确性的 GRPO 作为监督。Chung 等人 引入了一种简单的指向复制机制,允许模型在整个推理过程中动态检索相关的图像区域。Ground-R1 和 BRPO 在纯文本推理之前突出显示证据区域(通过基于 IoU 或反射奖励),而 DeepEyes 则证明了端到端强化学习可以自然地诱导此类基础行为。Chain-of-Focus 进一步完善了这种方法,通过先基础 CoT 步骤,然后放大操作。
Tool-Driven Active Perception
实现主动感知的另一个有前景的方向是 将视觉认知构建为一个代理过程,其中外部工具、代码片段和运行时环境可以辅助模型的认知工作流程。例如,VisTA 和 VTool-R1 专注于通过强化学习教会模型如何选择和使用视觉工具;OpenThinkIMG 则为训练模型“用图像思考”提供了标准化的基础设施;Visual-ARFT 利用强化学习来促进工具创建,使用 MLLMs 的代码生成功能来动态扩展其感知工具包。像素推理器通过裁剪、擦除和绘制等操作扩展了模型的动作空间,并引入了好奇心驱动的奖励机制,以防止过早终止探索。
Generation-Driven Active Perception
除了基础知识和工具使用之外,人类还会运用其最强大的认知能力的想象力来绘制草图或图表,从而帮助解决问题。受此启发,研究人员开始为 LVLMs 赋予生成与思维链(CoT)推理交织的草图或图像的能力,使模型能够外部化中间表征并更有效地进行推理。Visual Planning 仅将想象的图像滚动作为CoT图像思维,并将下游任务成功作为奖励信号;GoT R1 在生成-CoT框架内应用强化学习,使模型能够在生成图像之前自主发现语义空间推理方案;T2I-R1 明确地将过程解耦为用于高级规划的语义级 CoT 和用于块状像素生成的 token-level CoT,并使用强化学习联合优化这两个阶段。
Audio
强化学习也已从视觉-语言模型扩展到包括音频在内的多种模态。在音频-语言领域,作者将强化学习应用分为两大类。
- 大型音频-语言模型的推理增强:利用强化学习指导模型生成结构化、逐步推理的推理链,用于音频问答和逻辑推理等任务;
- 语音合成 (TTS) 中的细粒度组件优化:强化学习用于直接优化系统组件(例如,改进时长预测器),使用说话人相似度和词错率等感知质量指标作为奖励信号,从而产生更自然、更易理解的语音。
其他一些工作,例如 EchoInk-R1,通过在 GRPO 优化下集成视听同步,进一步丰富了视觉推理。
3.7 Others
除了优化上述核心认知模块之外,代理强化学习还能增强在扩展的多轮交互 multi-turn interactions 中保持战略一致性的能力,强化学习被用来 支持长远推理和有效的信用分配。
对于长周期交互,核心挑战在于 时序信用分配 temporal credit assignment,其中 稀疏且延迟的反馈会掩盖智能体动作与远期结果之间的联系。Agentic RL 通过改进学习信号和优化框架来直接应对这一挑战。主要的应对和互补策略为:
- integration of process-based supervision with final outcome rewards:将基于过程的监督与最终结果奖励相结合。该范式并非依赖于轨迹终点的单一奖励,而是使用辅助模型或程序化规则来评估中间步骤的质量,从而提供更密集、更直接的学习信号来指导智能体的多轮策略。例如,
EPO、ThinkRM和AgentPRM引入外部奖励模型,为智能体提供分步信号;相比之下,RLVMR设计了手动定义的程序化规则来指导中间监督; - extend preference optimization from single turns to multi-step segments:将偏好优化从单轮扩展到多步骤。诸如 Segment-level DPO (SDPO) 之类的技术不再只是比较孤立的回复,而是构建了基于整个对话片段或动作序列的偏好数据。这使得模型能够直接学习早期决策如何影响长期成功,从而提高其在长期对话和复杂任务中保持策略连贯性的能力;
4. Agentic RL: The Task Perspective
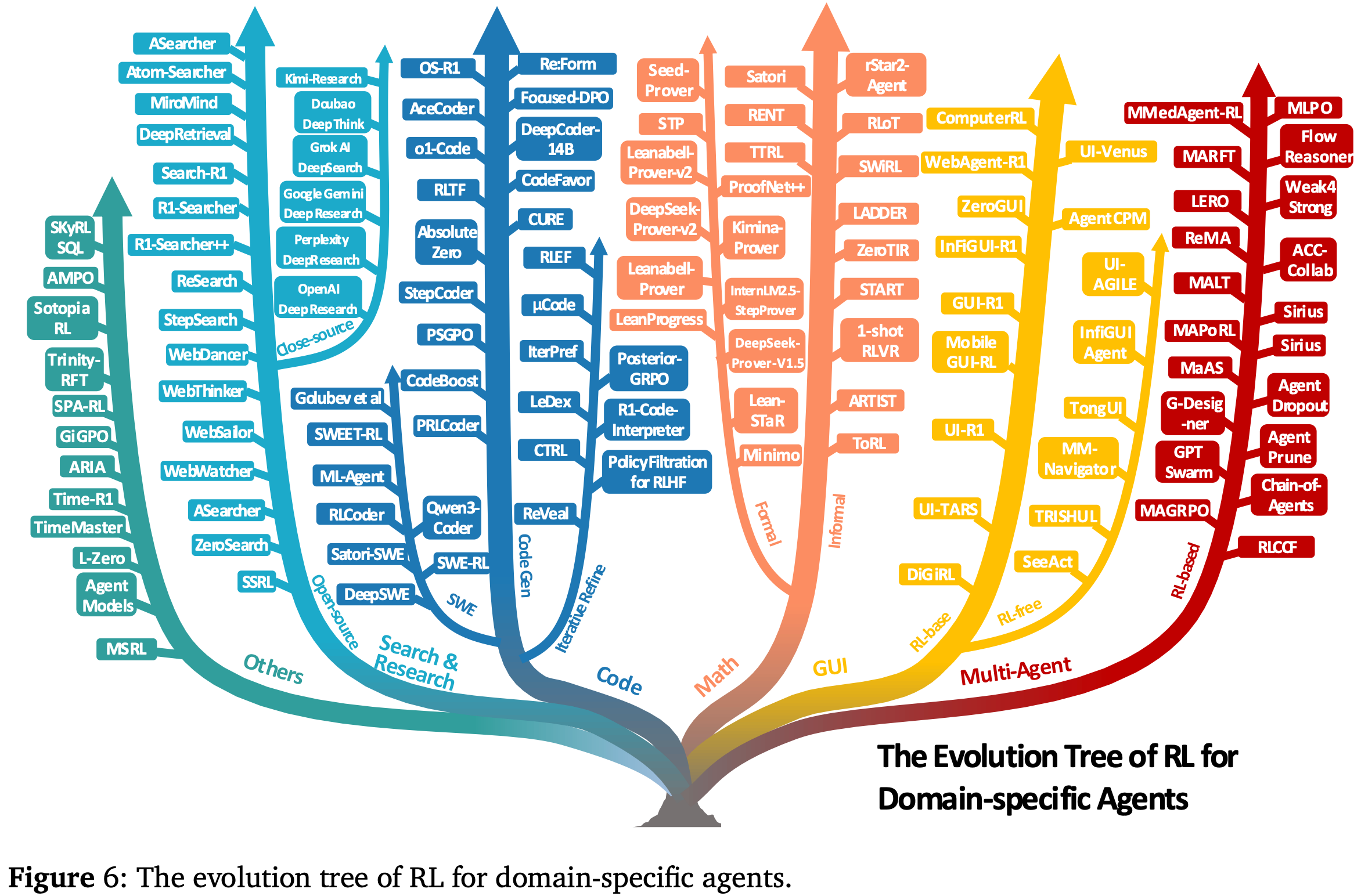
代理强化学习体现在一系列具体的任务中,这些任务测试并塑造了其不断发展的能力。本节概述了代理强化学习展现出巨大潜力和独特挑战的代表性应用领域。从 search and information retrieval Section 4.1 开始,接着是 code generation and software engineering Section 4.2,以及 mathematical reasoning Section 4.3。然后,讨论其在 GUI navigation Section 4.4、vision understanding tasks Section 4.5 以及 VLM embodied interaction Section 4.6 中的作用。除了单智能体场景之外,还将视角扩展到多 multi-agent system Section 4.7,并总结其他新兴领域 Section 4.8。这些应用共同凸显了代理强化学习如何从抽象范式转变为可操作的现实世界问题解决方案,如 Fig.6所示。
4.1 Search & Research Agent
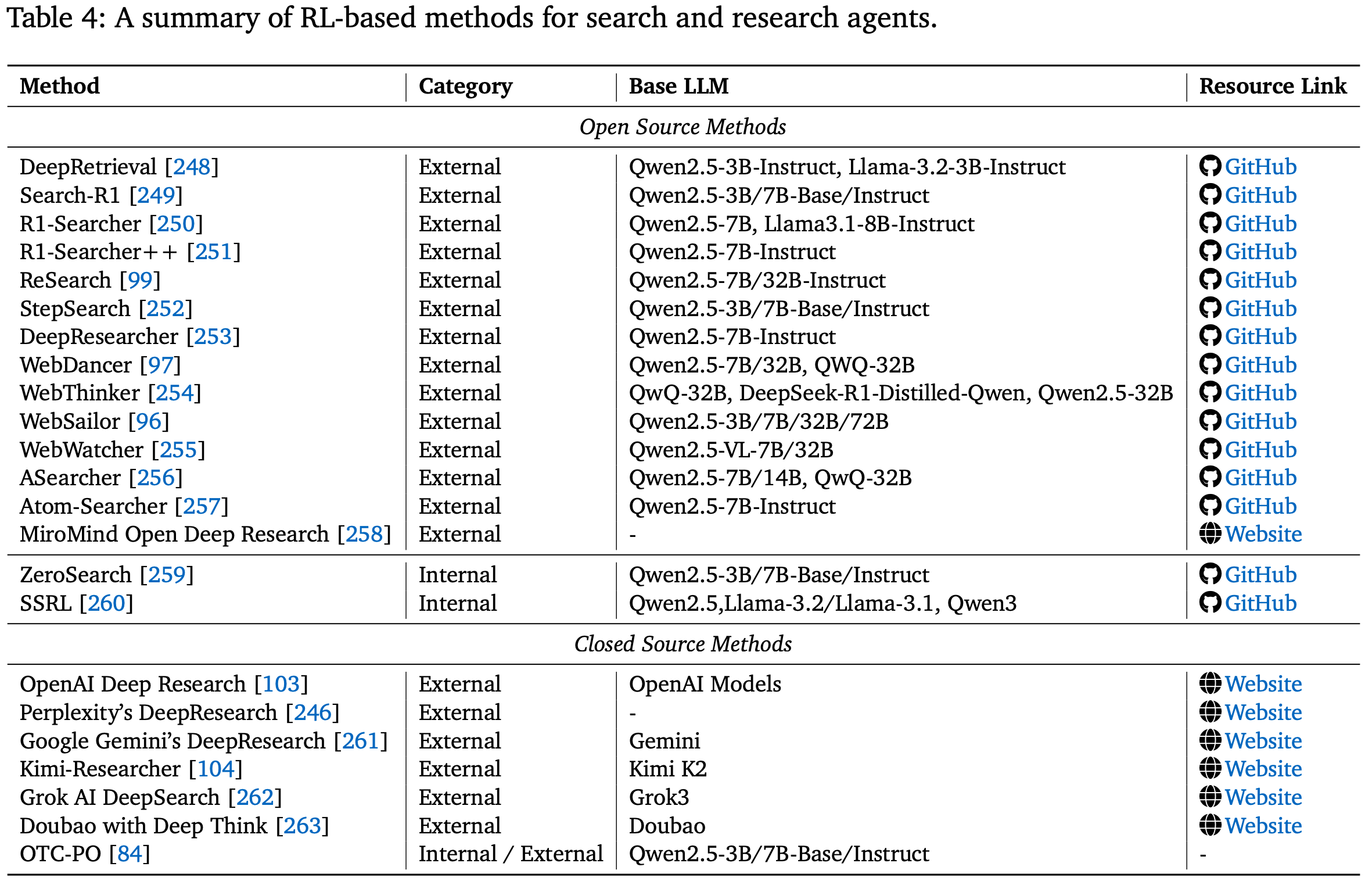
搜索一直是利用外部知识扩展 LLM 的核心,其中 检索增强生成 (RAG) 是一种广泛使用的方法。如今,该范式已从简单的信息检索发展到创建能够进行深度研究的自主智能体:这些智能体包含复杂的多步骤流程,不仅涉及查找信息,还涉及进行深入分析、综合来自众多来源的见解以及起草综合报告。这种转变 将目标从回答查询提升到处理复杂的研究任务。早期的提示驱动方法依赖于脆弱的查询策略和人工工程。虽然像 Search-o1 这样的近期研究利用大型推理模型进行智能体、推理时间检索,而像 DeepResearch 这样的多智能体系统则协调查询和摘要子智能体,但它们仍然缺乏学习信号。这些基于提示的方法缺乏任何微调信号,导致泛化能力有限,并且在需要紧密循环搜索、推理和综合的多轮场景中效果不佳。这些局限性促使人们采用强化学习来直接优化查询生成和搜索-推理协调的端到端流程,以实现高级研究目标。Table.4 列出了本节研究的大部分工作。接下来将详细介绍强化学习如何赋能这些智能体。
4.1.1. Open Source RL Methods
Search from the external Internet
一项主要的研究工作建立在 RAG 基础上,但依赖实时网络搜索 API 作为外部环境,使用强化学习来优化查询生成和多步推理。早期进展由 DeepRetrieval 引领,它将 一次性查询生成设计为 GRPO 训练的策略,并直接根据实时搜索结果奖励召回率和相关性。受其成果的启发,后续方法将该范式扩展为多轮、推理集成和多模态搜索。
Search-R1和DeepResearcher:将检索到的标记掩蔽与基于结果的奖励相结合,以交织查询制定和答案生成;R1-Searcher:采用两阶段冷启动 PPO 策略,首先学习何时调用网络搜索,然后学习如何利用它;R1-Searcher++:增加了监督微调、内部知识奖励以避免冗余,以及用于持续吸收的动态记忆;ReSearch:追求完全端到端的 PPO,无需监督工具使用轨迹;tepSearch通过分配中间步骤级奖励来加速多跳问答的收敛;Atom-Searcher:是一个代理深度研究框架,它通过改进推理过程本身(而不仅仅是最终结果)来显著提高 LLM 问题求解能力;WebDancer:利用人类浏览轨迹监督和强化学习微调来生成自主的 ReAct 式代理,在 GAIA 和 WebWalkerQA 上表现出色;WebThinker:将深度网络浏览器嵌入到“思考-搜索-起草”循环中,通过深度决策(DPO)与人工反馈相结合,以处理复杂的报告生成;WebSailor:是一种完整的训练后方法,旨在教会 LLM 代理进行复杂的网页导航和信息搜索任务的复杂推理;WebWatcher:进一步扩展到多模态搜索,结合视觉语言推理、工具使用和强化学习,在 BrowseComp-VL 和 VQA 基准测试中超越纯文本和多模态基线;ASearcher:将大规模异步强化学习与合成的 QA 数据结合使用,实现了长视域搜索(超过 40 次工具调用),其性能优于之前的开源方法;MiroMind:开放深度研究(MiroMind ODR)旨在构建一个高性能、完全开源、开放协作的深度研究生态系统,其代理框架、模型、数据和训练基础设施均完全开放且可访问;
Search from LLM internal knowledge
然而,这些依赖外部 API 的训练方法面临两大挑战:
- 实时互联网文档搜索的文档质量不受控制,噪声信息给训练过程带来不稳定性;
- API 成本过高,严重限制了可扩展性;
为了提高训练的效率、可控性和稳定性,最近的一些研究使用了可控的模拟搜索引擎,例如 LLM 内部知识。
ZeroSearch:用从 LLM 本身提炼出来的伪搜索引擎取代了实时网络检索,结合课程 RL,在不发出真实查询的情况下逐渐接近实时引擎的性能;SSRL:agent 在训练期间执行完全离线的 “self-search”,无需显式搜索引擎,但可以无缝迁移到在线推理,其中真实的 API 仍然可以提升性能。
尽管仍处于早期阶段,但离线自搜索增强了稳定性和可扩展性,超越了 API 的限制,指向了更加自力更生的研究代理。
4.1.2 Closed Source RL Methods
尽管在 RAG 与强化学习的结合方面取得了进展,但大多数开源模型仍然未能通过 OpenAI 的 BrowseComp 测试。BrowseComp 是一项极具挑战性的基准测试,旨在衡量 AI 代理定位难以找到的信息的能力,揭示其在长期规划、基于页面的工具使用和跨源验证方面的不足。相比之下,近期的闭源系统明显更加强大,它们已经从单纯的查询优化转变为完全自主的研究代理,能够在开放网络中导航、综合来自多个来源的信息并撰写综合报告。这可能得益于业界更强大的基础模型和更多高质量数据的可用性。OpenAI Deep Research 在 BrowseComp 测试中达到了 51.5% 的 pass@1 率。其他原型,Perplexity 的 DeepResearch、Google Gemini 的 DeepResearch、Kimi-Researcher、Grok AI DeepSearch、Doubao 和 Deep Think,将 RL 风格的微调与先进的工具集成和记忆模块相结合,开创了交互式、迭代式研究助手的新时代。
4.2 Code Agent
代码生成,或者更广泛地说,软件工程,为基于 LLM 的代理强化学习提供了理想的测试平台:执行语义明确且可验证,并且自动化信号(编译、单元测试和运行时跟踪)随时可用。早期的多智能体框架(例如 MetaGPT、AutoGPT、AgentVerse)通过提示而非参数更新来协调角色,展现了模块化角色分配的潜力。最初的代码强化学习,例如 CodeRL,结合了基于执行的奖励模型和参与者-评论家训练,催生了一系列利用执行反馈来指导策略更新的研究。 Table.5 列出了本节研究的大部分工作。接下来,我们将按照任务复杂性的增加来构建文献,从单轮代码片段生成 Section 4.2.1到多轮代码库细化 Section 4.2.2,最后到自动化软件工程 Section 4.2.3。
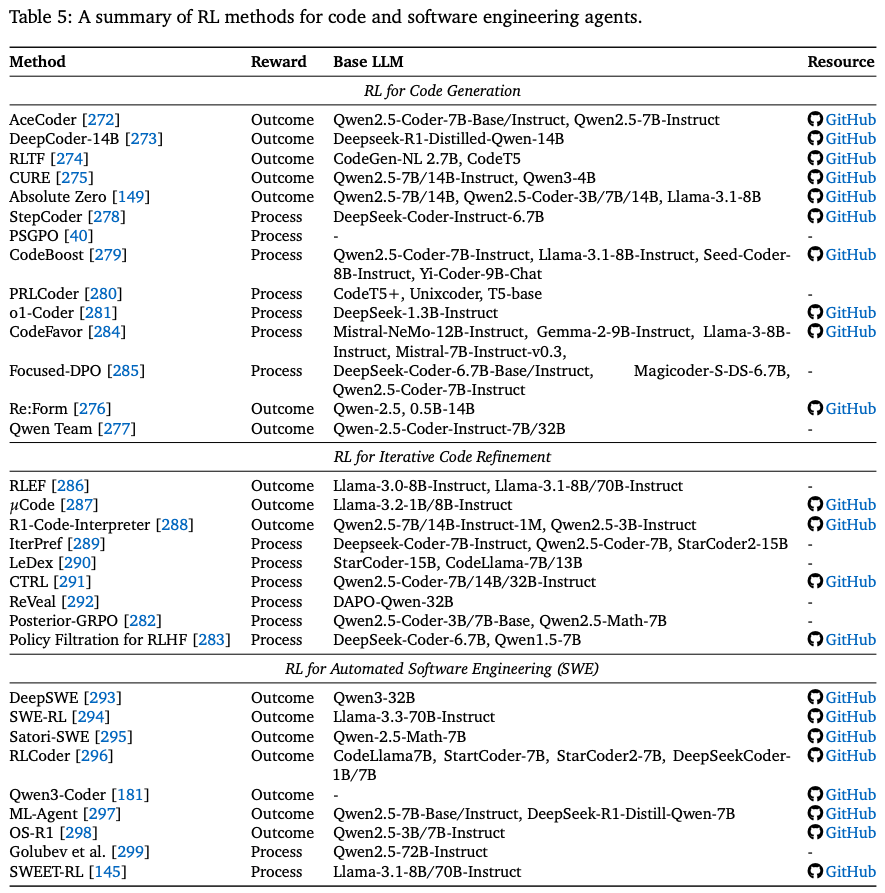
4.2.1. RL for Code Generation
早期研究侧重于相对简单的 单轮代码生成(例如,根据提示编写函数或一次性解决编码挑战)。强化学习用于微调 LLM,以实现更高水平的代码正确性。这一阶段为后续的大规模软件工程奠定了基础。
Outcome reward RL
此类方法 直接针对最终正确性进行优化,通常以 pass@k 或单元测试成功率来衡量。后续研究扩展了结果定义以提高鲁棒性:例如,AceCoder 通过执行通过率进行奖励,以在单轮设置中稳定软件维护风格提示的训练。除了早期的 actor–critic 公式之外,最近的开源工作在大型预训练代码模型上扩展了基于结果的强化学习。
DeepCoder-14B:使用分布式强化学习以单元测试通过率作为结果奖励对 14B 模型进行微调,实现了 +8% 的 Pass@1 增益(在 LiveCodeBench 上为 60.6%),同时与更大的专有编码器相媲美。其稳定性的关键是 GRPO+,这是一种改进的近端策略优化变体,通过仔细的裁剪和熵调制来减轻 reward hacking 和 collapse。 RLTF 采用在线强化学习循环,将单元测试结果作为多粒度奖励信号,从粗略的通过/失败结果到细粒度的错误定位,直接指导代码细化;CURE:形式化了编码人员和测试人员的共同进化:测试人员生成或演化单元测试,而编码人员则迭代地修补代码,奖励精度目标可以减轻联合训练过程中低质量测试的影响;Absolute Zero:应用无需人工数据的自对弈强化学习。它为自己生成编码任务,并将执行结果作为可验证的奖励来引导推理能力;Re:Form:利用基于形式语言的推理与强化学习和自动验证相结合,以减少人类先验,从而实现可靠的程序合成,并在形式验证任务上超越强基线;- Feng 等人:提出了一个两阶段训练流程,首先进行微调以获得高代码正确性,然后应用对错误不敏感、效率奖励驱动的在线强化学习;
Process reward RL
为了缓解稀疏性和信用分配问题,过程感知设计为编译、部分执行或推理步骤提供中间监督。
- StepCoder:将编译和执行分解为步骤级信号进行整形;
- PSGPO:过程监督引导策略优化,利用中间错误轨迹和过程注释来获得密集奖励;
CodeBoost:挖掘原始存储库,在单个 PPO 框架下统一异构执行衍生信号,涵盖从输出正确性到错误消息质量等各个方面;PRLCoder:通过构建对每个部分代码片段进行评分的奖励模型,引入了过程监督强化学习:教师模型会变异参考解的行,并根据编译器和测试反馈分配正/负信号。这种细粒度的监督方法可以实现更快的收敛速度,并且比基础模型的通过率提高了 10.5%,这说明在代码行级别进行密集整形比仅关注结果的信号更能有效地指导代码合成;o1-Coder:将强化学习与蒙特卡洛树搜索相结合,其中策略通过测试用例奖励引导的探索进行学习,并逐渐从伪代码改进为可执行代码;Posterior-GRPO:奖励中间推理,但以最终测试成功作为信用门槛,以防止推测性奖励利用;Policy Filtration for RLHF:通过在策略更新之前过滤低置信度对来改进奖励-正确性对齐。将偏好监督扩展到昂贵的人工注释之外也被证明是有效的;CodeFavor:根据代码演化历史构建了 CodePrefBench,涵盖正确性、效率、安全性和风格,以改进偏好建模和对齐;Focused-DPO:通过对代码中容易出错的区域进行加权偏好优化来适应基于偏好的强化学习,使反馈更有针对性,并提高跨基准的鲁棒性;
4.2.2. RL for Iterative Code Refinement
第二项研究针对的是更复杂的编码任务,这些任务需要调试和迭代改进。在这些场景中,代理可能需要多次尝试才能生成正确的代码,并使用反馈(例如错误消息或失败的测试结果)逐步改进其解决方案,使其更接近现实世界的任务。
Outcome reward RL
将整个改进循环视为一条轨迹,但根据最终任务成功情况进行奖励。
RLEFReinforcement Learning from Execution Feedback: 将真实的错误消息作为上下文,以纠正循环为基础,同时优化最终通过率;这减少了所需的尝试次数,并提高了相对于单次基线的竞争性编程性能;µCode:在单步奖励反馈下联合训练生成器和学习过的验证器,表明验证器引导的结果奖励可以优于纯执行反馈基线;R1-Code-Interpreter:利用多轮监督微调和强化学习来训练 LLM,使其决定在逐步推理过程中何时以及如何调用代码解释器;
Process reward RL
过程监督方法明确指导模型的调试方式。
IterPref:从迭代调试轨迹中构建局部偏好对,并应用有针对性的偏好优化来惩罚错误区域,从而以最少的间接更新提高纠正精度;LeDex:将解释驱动的诊断与自我修复相结合:它自动整理解释-改进轨迹,并应用密集的连续奖励,通过 PPO 联合优化解释质量和代码正确性,与仅使用 SFT 的编码器相比,获得了一致的 pass@1 增益;
除了解释驱动的整合之外,一些工作例如 CTRL 明确训练了单独的批评模型来评估每次尝试的改进,并为策略提供梯度信号,但这会增加推理开销。诸如 Posterior-GRPO 和可靠性增强滤波器等过程门控方案,通过确保中间推理仅在最终输出得到验证时才有帮助,进一步稳定了学习。ReVeal是一个自我进化的代码代理,它迭代地创建测试来验证自己的代码,利用每轮奖励来深化推理并增强从错误中恢复的能力。
4.2.3. RL for Automated Software Engineering
基于 LLM 的编码代理的前沿领域涉及全面的软件工程任务,这些任务具有长期性,需要跨多个步骤使用工具、进行规划和推理。这些任务包括:阅读和修改大型代码库、实现新功能或通过多次编辑修复复杂错误、使用外部工具(编译器、linter、版本控制、shell)以及在多次迭代中验证结果。此类场景需要一种代理方法。强化学习微调已被证明在培养静态监督训练无法捕捉的长期决策技能方面具有独特的有效性。最近的开源研究已开始使用基于强化学习的训练框架来应对这种复杂程度。
Outcome reward RL
在现实环境中进行的端到端训练表明,稀疏但经过验证的成功信号可以扩展。
DeepSWE:使用经过验证的任务完成情况作为唯一奖励,在软件工程任务中执行大规模强化学习,在 SWE-bench 式评估中取得了领先的开源结果;SWE-RL:从 GitHub 提交历史中提取基于规则、以结果为导向的信号,从而能够在真实的改进模式下进行训练,并泛化到未见过的错误修复任务;Satori-SWE:引入了一种基于进化强化学习的测试时间扩展方法 (EvoScale),该方法训练模型在迭代过程中自我改进,从而完成样本高效的软件工程任务;OS-R1:提出了一个基于规则的强化学习框架,用于 Linux 内核调优,实现了高效的探索、准确的配置以及优于启发式方法的性能;RLCoder:将检索增强的存储库级代码补全框架化为强化学习问题,使用基于困惑度的反馈来训练检索器,使其能够在没有标记数据的情况下获取有用的上下文;Qwen3-Coder:在 20,000 个并行环境中对长视域、多轮交互进行大规模执行驱动的强化学习,在 SWE-Bench Verified 等基准测试中取得了最佳性能;ML-Agent:执行多步骤流程(例如,自动化机器学习),优化基于性能的终端奖励;
Process reward RL
对代理轨迹进行密集监督可以改善多个步骤中的信用分配。从优化角度来看,长上下文、多轮次软件代理受益于稳定的策略梯度变体;例如,解耦剪辑和动态采样策略优化 (DAPO) 利用长上下文反馈,通过多轮次代码生成和调试交互验证了其在 SWE-bench 上的训练稳定性和性能。SWEET-RL 在 ColBench(后端和前端任务)上训练多轮次代理,利用强化学习期间的特权信息来降低探索噪声并提高长视界泛化能力。
Remark on closed-source systems
OpenAI 的 Codex 和 Anthropic 的 Claude Code 等商业系统强调了 偏好对齐的微调和强化学习,以提高代码生成和编辑工作流程的实用性和安全性。虽然具体的训练细节尚未公开,但这些系统凸显了强化学习在实际 IDE 和终端环境中,在协调代理行为与以开发者为中心的目标方面发挥着日益重要的作用。
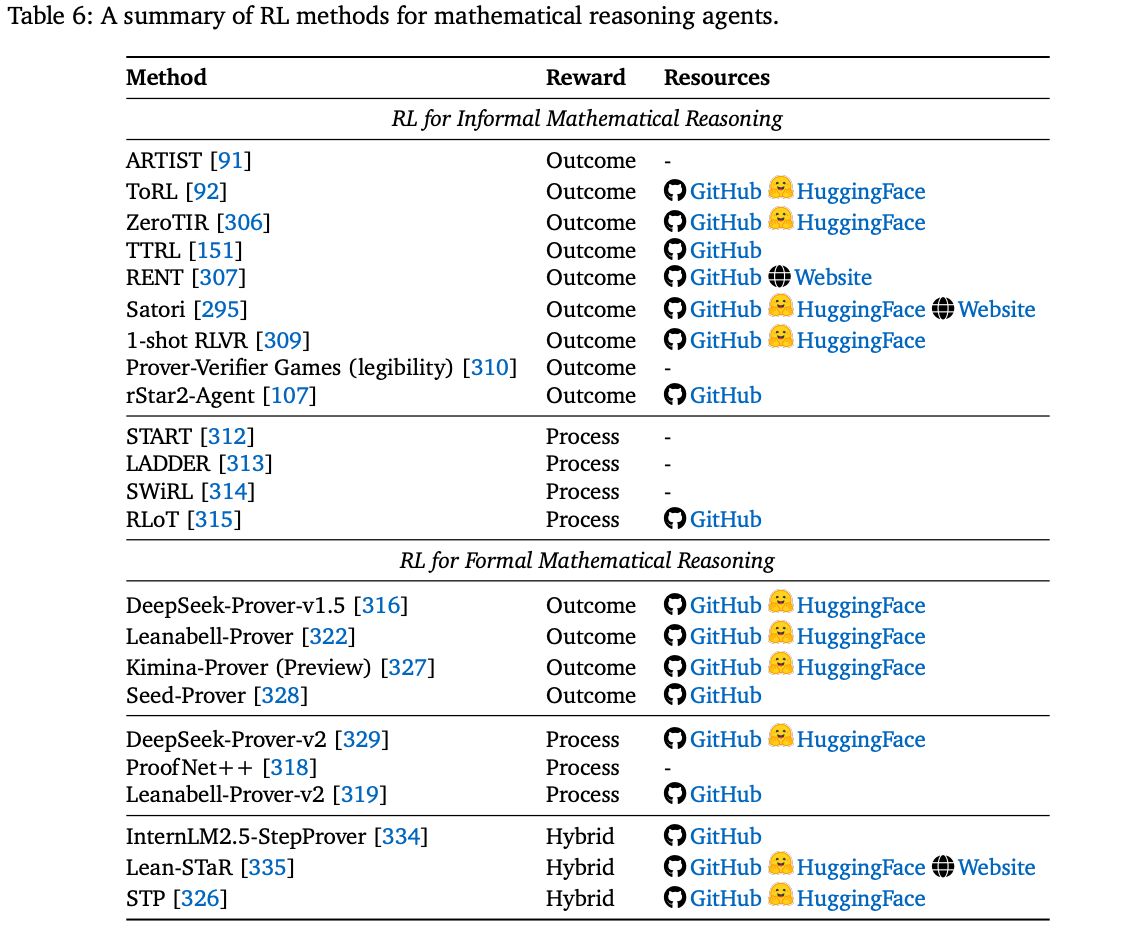
4.3 Mathematical Agent
数学推理因其符号抽象性、逻辑一致性和对长远演绎的需求,被广泛视为评估 LLM 智能体推理能力的黄金标准。本文围绕两个互补的范式构建研究工作:informal reasoning <a href='#4-3-1">Section 4.3.1,其运行无需形式化验证支持,并包含自然语言推理和编程语言工具的使用;以及 formal reasoning Section 4.3.2,其依赖于严格指定的形式语言和证明助手。
诸如 DAPO、GRPO 和 GRESO 之类的 RLVR 方法在近期 LLM 数学推理能力的提升中一直发挥着重要作用。然而,鉴于它们在推理任务中具有更广泛的相关性,将在 Section 2.7 中讨论它们,而不是在此详述。
4.3.1. RL for Informal Mathematical Reasoning
非形式化数学本质上是指用自然语言进行的推理和表达。这种推理可能包含符号,例如变量(例如 x,Aix,A_{i}x,Ai)、方程式(例如 x+y=zx+y=zx+y=z)或函数名,但没有一套有限且明确的逻辑规则来定义它们的句法有效性,也没有形式语义来精确地确定它们的解释和含义。
非形式化数学推理虽然在细节层面上放松了严格的严谨性,但它提供了更大的表达灵活性,并能更好地捕捉论证的高级结构。这使得它特别适合各种数学任务,例如数学文字问题求解、方程运算和符号计算。虽然通用编程语言是符号式的,但它们 缺乏辅助证明语言的严谨性和形式语义,因此在应用于数学推理时被认为是非形式化的,通常是通过调用带有数值或符号库的执行器(例如Python)来实现的。
Outcome reward RL
纯结果方法在强化学习过程中 仅通过最终的数值或符号正确性(例如代数方程)来定义奖励。经验表明,此类训练通常会导致涌现的代理行为,包括与自然语言推理交织的自适应工具使用。
ARTIST:引入了一个工具集成代理推理框架,将工具调用(例如代码执行)直接交织在推理链中。通过纯结果奖励进行训练,该框架获得了强劲的性能,并观察到涌现的代理行为,包括自我反思和情境感知的学习目标 (CoT)。这进一步表明,通过将动态工具使用与强化学习相结合,代理工具集成推理可以学习与环境交互的最佳策略,凸显了强化学习在 LLM 中内化工具集成推理策略的潜力;ToRL:通过利用工具集成推理强化学习的可扩展性并鼓励代码执行行为来提高性能,实验表明出现了一些认知行为,例如自适应工具使用、基于工具反馈的自我修正以及自适应计算推理;ZeroTIR:使用 Python 代码执行设置,研究了基于结果的奖励对工具集成推理的强化学习的扩展规律,揭示了训练计算工作量与自发代码执行频率、平均响应长度和最终任务准确率之间的强相关性,这证实了工具集成推理策略的实证涌现;TTRL:利用多数投票来估计奖励,从而能够在未标记数据上进行训练。经过这些多数投票奖励的微调,它不仅超越了基础模型的主要准确率,而且实现了令人惊讶的经验性能曲线和上限,非常接近于在 MATH-500 上使用标记测试答案直接进行强化学习训练的结果,凸显了它的实用价值和潜力;RENT:认为多数投票缺乏泛化能力,它只适用于具有确定性答案的问题,并且不适用于自由响应输出。为了解决这个限制,它将熵最小化思想扩展到强化学习,使用 token 级平均负熵作为奖励来指导学习,在包括数学问题解决在内的一系列基准测试中取得了改进,这表明基于置信度的奖励塑造可以作为持续改进的途径;Satori:提出了行动思维链 (Chain-of-Action-Thought, COAT),是 CoT 的一种变体,它明确地整合了行动选择,并将推理模块化为三重元行动,包括延续、反思和替代方案探索,并通过仅关注结果的奖励将这种行为内化到强化学习中;1-shot RLVR:研究了带有验证者信号的仅关注结果的强化学习的数据效率,发现仅使用 1 个示例的强化学习的性能接近使用 1.2k 个示例的数据集,而使用 2 个示例的强化学习的性能接近使用 7.5k MATH 训练数据集,还强调了一个有趣的现象,称为饱和后泛化 post-saturation generalization,即使在单个示例的训练准确率接近 100% 之后,测试准确率仍会继续提高。
除了正确性之外,幻觉仍然是非正式数学推理中的一个主要挑战,这促使人们提出明确促进可信度的方法。
- Kirchner 等人:提出了一种博弈论训练算法,联合优化正确性和易读性。受证 Prover-Verifier Games 的启发,该方法交替训练三个证明者:一个小型验证者(用于预测解决方案的正确性)、一个“有用”的证明者(用于生成被验证者接受的解决方案)和一个“狡猾”的证明者(用于欺骗验证者)。经验表明,这提高了有用证明者的准确性、验证者的鲁棒性和易读性(以时间约束验证任务中的人类准确性来衡量)。该结果表明,验证者引导的易读性优化可以增强 LLM 生成的非形式化推理的可解释性和可信度;
rStar2-Agent:一个 14B 参数的数学推理模型,使用高吞吐量 Python 执行环境、一种新颖的 GRPO-RoC 算法(用于在工具噪声中对正确的 rollouts 进行重新采样)和多阶段训练方案进行代理强化学习训练,仅用 510 个 RL 步骤就获得了最先进的结果,在 AIME24 上实现了 80.6% 的平均 pass@1 分数,在 AIME25 上实现了 69.8%;
Process reward RL
过程感知方法利用中间评估器(例如单元测试、断言、子任务检查)来提供更密集的反馈,从而塑造信用分配并改进工具集成推理 (TIR)。
START:通过将手工编写的提示文本注入长 CoT 轨迹(通常位于连词之后或 CoT 终止标记之前)来指导 TIR,以鼓励在推理过程中调用代码执行器。这使得测试时扩展成为可能,从而提高了推理准确性,然后收集到的轨迹用于微调模型,将工具调用行为内化;LADDER:引入了一个训练时框架,其中 LLM 递归地生成并逐步求解复杂问题的更简单变体,使用可验证的奖励信号来指导基于难度的课程,并在数学推理方面取得了显著的改进。额外的测试时强化学习步骤 (TTRL) 进一步提升了性能。作者认为,这种具有可验证反馈的自生成课程学习方法,或许可以推广到非正式数学任务之外的任何具有可靠自动验证的领域;SWiRL:通过迭代分解解决方案来合成逐步工具使用推理数据,然后采用基于偏好的逐步强化学习方法,在多步轨迹上微调基础模型;RLoT:使用强化学习训练一个轻量级导航代理模型,以自适应地增强推理能力,并展示了在不同任务中改进的泛化能力;
虽然非形式化方法在文字问题和符号计算方面表现出色,但它们难以有效地扩展到诸如自动定理证明等高级数学任务。这种局限性源于两个根本挑战:评估难度(这需要机器可验证的反馈,而非形式化方法则无法获得)以及 高质量形式化证明数据的匮乏。
4.3.2. RL for Formal Mathematical Reasoning
形式化数学推理是指 使用具有精确语法和语义的形式化语言进行推理,从而产生可由验证者机械验证的证明对象。这种范式尤其适用于诸如自动定理证明 (ATP) 之类的高级任务。在这种任务中,给定一个语句(定理、引理或命题),智能体必须构建一个验证者能够接受的证明对象,从而确保其正确性,并使其可被机器验证。从强化学习的角度来看,形式化定理证明通常被建模为马尔可夫决策过程 (MDP):证明状态通过应用策略进行转换,在基于强化学习的证明搜索中,每个策略都被视为一个离散动作。形式化定理证明可以理解为在广阔、离散且参数化的动作空间上的搜索问题。
形式化证明由诸如 Lean、Isabelle、Coq 和 HOL Light 等证明助手进行验证。这些系统通常被称为交互式定理证明器 (Interactive Theorem Provers, ITP),它们确定性地接受或拒绝证明对象,并产生二进制的通过/失败信号作为强化学习训练的主要奖励,而一些研究也探索利用错误消息作为辅助信号。
Outcome reward RL
2024 年,DeepSeek Prover-v1.5 大规模演示了仅关注结果的范式,该版本在 Lean 中发布了一个仅基于二进制验证器反馈的端到端强化学习流程,在 miniF2F 和 Proof Net 等基准测试中显著提高了证明成功率。作者提出了 MCTS 的一个变体,即 RMaxTS,它结合了发现新策略状态的内在奖励,以鼓励推理时搜索过程中证明探索的多样性,并缓解稀疏奖励问题。
Leanabell-Prover:在 DeepSeek-Prover v1.5 的基础上进行了扩展,它聚合了一个由 statement-proof 对和非形式化推理草图组成的庞大混合数据集,这些草图来自多个来源和流程,例如 Mathlib4、LeanWorkbook、NuminaMath、STP 等,涵盖了 20 多个数学领域。这种广泛的覆盖范围缓解了非形式化到形式化(NL 到 Lean4)训练样本的匮乏问题,而这些样本对于连接自然语言推理和形式化证明生成至关重要;Kimina-Prover:预览版进一步强调了非形式化和形式化推理之间的协调这一关键挑战。它实现了一种结构化的 “formal reasoning pattern”,其中自然语言推理和 Lean 4 代码片段在思维块中交织在一起。为了加强这种一致性,输出受到限制,至少包含一个策略块,并在最终证明中重用不少于 60% 的 Lean 4 代码片段,以确保内部推理与形式化输出之间紧密对应;Seed-Prover:集成了多种技术。它首先采用以引理为中心的证明范式,该范式支持系统性的问题分解、跨轨迹引理重用和显式的进度跟踪。然后通过一种多样化的提示策略丰富了强化学习训练,该策略随机地结合了非正式和正式的证明、成功和失败的引理以及 Lean 编译器反馈,从而增强了对不同输入的适应性。在推理方面,采用了一种 conjecture–prover 流程,将证明猜想交织到引理中,并从不断发展的引理池中生成新的猜想,从而显著提高了其解决难题的能力;Seed-Geometry:将形式推理扩展到几何领域,在奥林匹克基准测试中取得了最佳表现。这些努力共同证明了稀疏但明确的奖励信号可以带来非凡的收益,尤其是在与有效的探索策略相结合时;
Process reward RL
为了改进信用分配并减少浪费的探索,一些研究扩展了仅结果范式,使其具有更密集的阶跃级信号。DeepSeek-Prover-v2 设计了一个双模型流程,以统一非正式((natural-language)和正式(Lean4)数学推理,从而增强证明推理能力。它引入了子目标分解,其中证明器模型求解递归分解的子目标,并在子目标级别接收二元 Lean 反馈,从而有效地提供更密集的监督,并提高准确性和可解释性。
Proof Net++:实现了一个神经符号强化学习框架,该框架具有一个符号推理接口(将 LLM 生成的推理映射到形式化证明树中)和一个形式化验证引擎(使用 Lean 或 HOL Light 验证这些证明,并将错误反馈路由回 LLM 进行自我修正);Leanabell Prover-v2:将验证者消息集成到长 CoT 框架内的强化更新中,从而实现明确的验证者感知自我监控,稳定策略生成并减少重复的失败模式;
Hybrid reward RL
尽管仅关注结果和过程感知的奖励范式都已取得令人鼓舞的进展,但高质量定理证明数据的匮乏进一步加剧了稀疏奖励下的强化学习以及步级偏好信号设计的挑战。为了缓解这些局限性,一项重要的研究采用了专家迭代 (ExIt) ,这是一个将搜索与策略学习相结合的框架。该范式为仅关注结果或过程感知的强化学习提供了一种替代方案,通过生成高质量的监督轨迹来缓解数据稀缺问题。ExIt 不是直接针对稀疏的验证者信号进行优化,而是执行搜索引导的数据增强:通过搜索发现并经验证者检查的有效证明轨迹在模仿学习循环中被重用为专家演示。它通常采用双角色系统:专家在仅结果验证者反馈下,通过蒙特卡洛树搜索(MCTS)收集有效且渐进的轨迹;而学徒则在这些过程级轨迹上训练策略,然后将改进后的策略分享给专家,从而引导后续搜索轮次并加速收敛。Polu 和 Sutskever 将 ExIt 引入形式化定理证明,证明搜索生成的专家数据可以引导模型应对复杂的多步骤证明挑战。后续研究将此设计应用于 Lean 和其他 ITP。
在应用于形式化定理证明时,朴素树搜索方法在探索巨大的参数化策略空间时,常常会面临严重的搜索空间爆炸。为了缓解这个问题,InternLM2.5-StepProver 引入了一个基于偏好的批评家模型,该模型采用 RLHF 式优化进行训练,用于指导专家搜索,有效地提供了一个课程,引导探索者朝着适当难度的问题方向发展。Lean-STaR 通过集成自学推理机 (STaR) 进一步增强了 ExIt。它首先在合成的三元组(证明状态、生成的思维、基本策略)上训练一个思维增强的策略预测器。然后,在专家迭代循环中,该模型生成将思维与策略交织在一起的轨迹;经过 Lean 成功验证的策略轨迹将被保留并重新用于模仿学习。从经验上看,在基于样本的证明搜索中,思维的加入增加了探索的多样性。
最近的一项研究 STP 指出,由于正向奖励稀疏,单纯依赖专家迭代很快就会达到平台期。为了解决这个问题,它将 Minimo 中的猜想者-证明者自我博弈的思想扩展到具有开放式动作空间的实用形式语言(Lean/Isabelle),并从预训练模型开始。STP 实例化了一个双角色循环,其中猜想者提出当前证明者几乎无法证明的语句,而证明者则使用标准专家迭代进行训练;这生成了一个自适应课程并缓解了稀疏的训练信号。根据经验,STP 在 LeanWorkbook 上取得了巨大的进步,并在 miniF2F 和 Proof Net 上报告了与完整证明生成方法相当的结果。
4.4 GUI Agent
GUI 代理经历了不同的训练范式。早期系统以纯零样本方式使用预训练的视觉语言模型 (VLM),将屏幕截图和提示直接映射到单步操作。后来,基于静态(屏幕、操作)轨迹的 SFT 改进了基础和推理能力,但受限于人类操作轨迹的稀缺。强化微调 (RFT) 将 GUI 交互重新定义为顺序决策,允许代理通过稀疏或形状奖励的反复试验进行学习,并已从简单的单任务设置发展到复杂的、现实世界的、长视界场景。Table.7 列出了本节研究的主要工作。
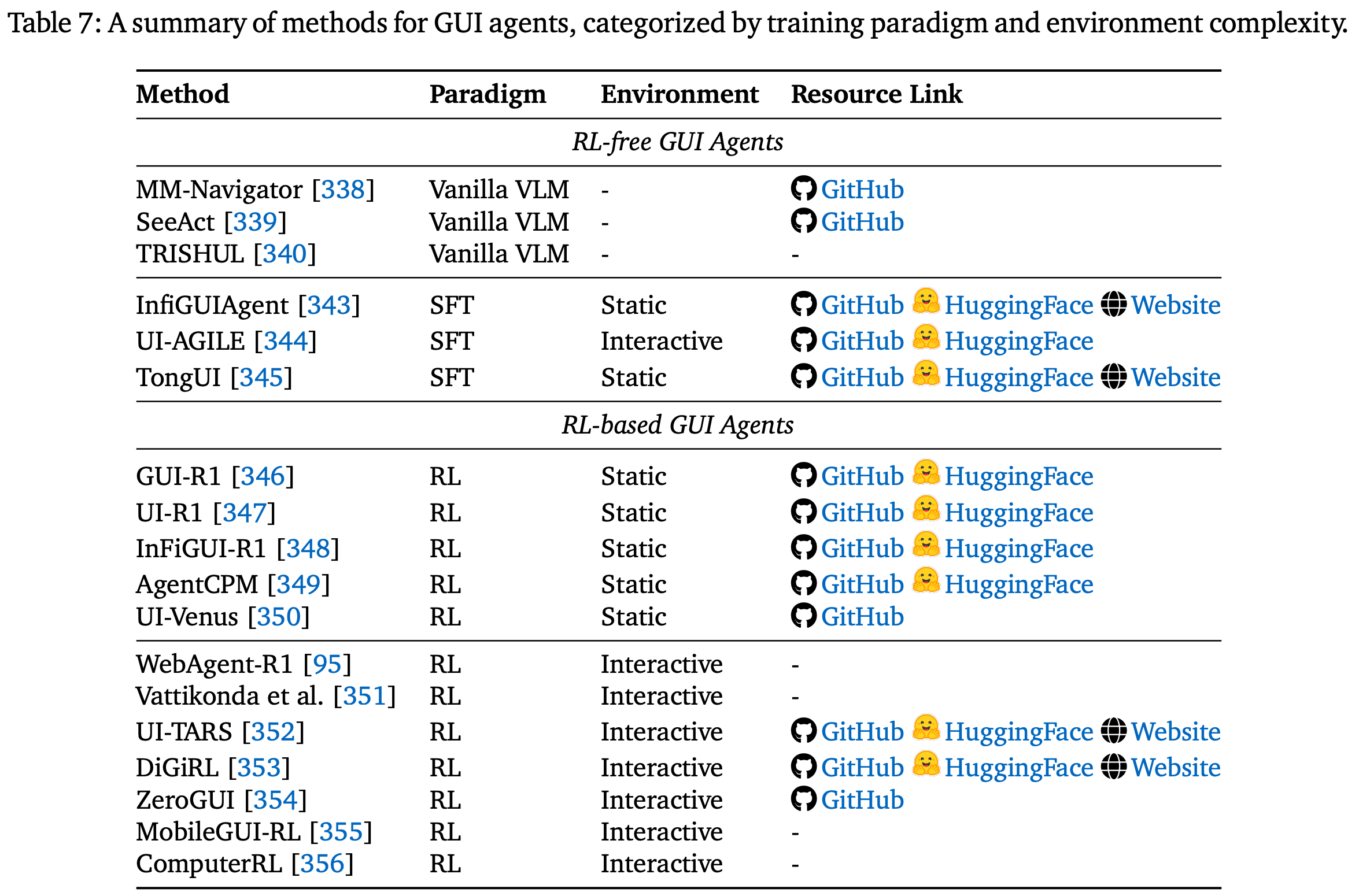
4.4.1. RL-free Methods
Vanilla VLM-based GUI Agents
早期的 GUI 代理直接以纯零样本方式利用预训练的 VLM,将屏幕截图和提示映射到单步操作,而无需任何特定于任务的微调。代表性系统包括 MM-Navigator、SeeAct 和 TRISHUL,它们在界面领域或解析策略上有所不同,但都依赖于现成的 VLM。虽然这些方法展示了基础模型的通用性,但它们的基础精度和可靠性有限,限制了它们在复杂任务中的适用性。
Supervised Fine-Tuning (SFT) with Static Trajectory Data
SFT 范式通过最小化离线(屏幕、动作)对的交叉熵损失,将预训练的视觉-语言模型应用于 GUI 任务,无需在线交互。
InfiGUIAgent:采用两阶段流程,首先改进基础推理,然后结合分层推理和反射推理;UI-AGILE:通过结合连续奖励、简化推理和基于裁剪的重采样来增强监督微调,同时进一步提出了一种用于处理高分辨率显示器的分解基础推理机制;TongUI:则强调数据规模,从多模态网络教程构建了 143K 轨迹的 GUI 网络,以增强泛化能力。虽然侧重点不同,但这些方法都面临着人为操作痕迹稀缺的限制;
4.4.2. RL in Static GUI Environments
在静态设置中,强化学习应用于预先收集的具有确定性执行轨迹的数据集,在缺乏实时环境交互的情况下使用基于规则的标准进行结果评估。
GUI-R1:在统一的动作模式上采用 R1 风格的强化微调流程,使用简单的格式和正确性奖励,在适度数据的情况下改进步骤级动作预测;UI-R1:应用群体相关策略优化来稳定策略更新,并通过紧凑的动作界面和针对动作类型和论证准确性的奖励塑造来改进精确参数匹配;InFiGUI R1:引入了一种两阶段训练范式,首先提炼空间推理以增强基础,然后进行具有子目标监督和恢复机制的强化学习,以改进长视界推理;AgentCPM-GUI:将基于基础感知的预训练、监督模仿和基于 GRPO 的强化微调与简洁的 JSON 动作空间相结合,在降低解码开销的同时,提高了对长视域序列的鲁棒性;UI-Venus:是一个基于屏幕截图的多模态 UI 代理,通过 RFT 进行微调,并采用自定义奖励函数和自进化轨迹框架,在 UI 基础和导航方面均达到了新的最佳水平;
4.4.3. RL in Interactive GUI Environments
在交互式环境中,强化学习代理通过在动态环境中的在线部署进行优化,这需要对随机转换和长期依赖性具有鲁棒性。
WebAgent R1:利用异步轨迹生成和分组优势进行端到端多轮强化学习,提高了各种 Web 任务的成功率;- Vattikonda 等人:研究了在真实页面动态和大型动作空间下 Web 代理的强化学习,重点介绍了信用分配和安全探索方面的挑战;
UI-TARS:将用于 GUI 理解的预训练与用于本机桌面控制的强化学习相结合,结合里程碑跟踪和反射以增强长期执行能力;DiGiRL:在真实的 Android 设备上引入了离线到在线的强化学习流程,结合了优势加权更新、双重稳健优势估计和指令级课程来应对非平稳性;ZeroGUI:利用视觉语言评估器自动生成任务和评估奖励,然后应用两阶段在线强化学习(先对生成的任务进行训练,然后在测试时进行调整)来减少人工监督;MobileGUI RL:利用轨迹感知的 GRPO、衰减效率奖励和课程过滤技术,在 Android 虚拟设备上扩展训练,提高了执行效率和泛化能力,同时保持系统适用于大规模部署;ComputerRL:引入了一种 API-GUI 混合交互范式,并结合大规模并行、完全异步的强化学习基础设施和新颖的 Entropulse 训练策略(将强化学习与监督微调交替进行),使基于 GUI 的智能体能够在桌面环境中高效且可扩展地运行;
4.5. RL in Vision Agents
强化学习已广泛应用于各种视觉任务(包括但不限于图像/视频/3D 感知和生成)。由于相关论文数量众多,本节不打算提供详尽的概述;如需更全面地了解强化学习在各种视觉任务中的应用,作者推荐读者参阅两篇专门的视觉领域综述。
- Reinforcement Learning in Vision: A Survey:arXiv:2508.08189, 2025
- Reinforced MLLM: A Survey on RL-Based Reasoning in Multimodal Large Language Models:arXiv:2504.21277, 2025
Image Tasks
DeepSeek-R1 引发了人们广泛的兴趣,他们希望将强化学习应用于激励长篇推理行为,鼓励 LVLMs 生成扩展的 CoT 序列,从而提升视觉感知和理解能力。该研究轨迹从早期简单地将 R1 式目标应用于视觉领域(主要旨在增强被动感知)发展到如今流行的主动感知范式,即 “thinking with images”。关键的转变在于 从仅引用一次图像的纯文本认知推理 (CoT) 转变为交互式的、基于视觉的推理,这通过以下方式实现: (i) 基础推理;(ii) 代理工具的使用;以及 (iii) 通过草图或生成进行视觉想象。除了纯文本输出之外,许多视觉任务(例如场景理解)还需要结构化预测,例如边界框、掩模和分割图。
Visual-RFT:使用置信度的 IoU 作为边界框输出的可验证奖励;Vision-R1:则将准确率和召回率作为定位奖励;-
- Liu 等人:扩展了这一思路,将 GRPO 应用于分割任务,将软奖励和严格奖励与边界框 IoU 和 L1 损失以及逐点 L1 距离相结合。VLM-R1采用平均精度 (mAP) 作为奖励,明确激励 LVLM 中的检测和定位能力;
R1-SGG:为场景图匹配引入了三种 GRPO 奖励变体,从基于文本匹配和 IoU 的硬奖励到通过文本嵌入点积计算的软奖励。
强化学习也广泛应用于图像生成,特别是通过与扩散和流模型的集成,例如 RePrompt、Diffusion-KTO、Flow-GRPO 和 GoT-R1。除了基于扩散的方法之外,强化学习还被用于自回归图像生成,它通过直接优化特定于任务或用户的奖励信号来提高连贯性、保真度和可控性
Video Tasks
秉承同样的精神,许多研究将 GRPO 变体扩展到视频领域,以增强时间推理。
TW-GRPO:引入了一个标记加权的 GRPO 框架,该框架强调高信息量标记以生成更集中的推理链,并采用软多选奖励来实现低方差优化;EgoVLM:将基于关键帧的奖励与直接 GRPO 训练相结合,以生成针对自我中心视频定制的可解释推理轨迹;DeepVideo-R1:将 GRPO 目标重新表述为回归任务;VideoChat-R1:证明了强化微调 (RFT) 对于特定任务的视频推理改进具有很高的数据效率;TinyLLaVA-Video-R1:探索将强化学习扩展到更小的视频 LLM 引入了基础架构和两阶段流水线(CoT-SFT + RL),以支持针对长视频的大规模强化学习。
其他研究也已将强化学习扩展到具身视频推理任务。在视频生成中也观察到了类似的趋势,其中应用强化学习来改善时间连贯性、可控性和语义对齐。主要示例包括 DanceGRPO、GAPO、GRADEO、Inf LVG、Phys-AR、VideoReward、TeViR 和 InstructVideo。
3D Vision Tasks
强化学习也被广泛应用于推进 3D 理解和生成。
MetaSpatial:引入了第一个基于强化学习的 3D 空间推理框架,利用物理感知约束和渲染图像评估作为训练过程中的奖励;Scene-R1:学习在没有逐点 3D 监督的情况下推理 3D 场景;SpatialReasoner:引入了共享 3D 表示,统一了感知、计算和推理阶段。在 3D 生成领域,强化学习已被用于改进文本到 3D 的对齐和可控性;DreamCS:将生成与人类偏好相结合;DreamDPO和DreamReward:使用 2D 奖励信号优化 3D 生成;Nabla-R2D3:通过强化驱动的目标进一步细化 3D 输出;
4.6 RL in Embodied Agents
虽然传统智能体通常是为通用视觉或语言任务而开发的,但将这些能力扩展到具身智能体需要对现实世界视觉环境有全面的理解,并具备跨模态推理的能力。这些能力对于感知复杂的物理环境和执行基于高级指令的目标导向动作至关重要,构成了智能体 LLM 和 MLLM 的基础要素。在指令驱动的具身场景中,强化学习通常被用作训练后策略。一个常见的流程 始于一个预训练的 VLA 模型,该模型是在教师强制监督下通过模仿学习获得的。然后,该模型被嵌入到一个交互式智能体中,该智能体与环境互动以收集奖励信号。这些奖励引导策略的迭代改进,支持有效的探索,提高样本效率,并增强模型在不同现实世界条件下的泛化能力。 VLA 框架中的 RL 大致可分为两类:导航代理,强调复杂环境中的空间推理和运动;以及 操作代理,侧重于在多样化和动态约束下对物理对象的精确控制。
RL in VLA Navigation Agent
对于导航代理来说,规划是核心能力。强化学习用于增强 VLA 模型预测和优化未来动作序列的能力。一种常见的策略是 将传统的机器人式强化学习(使用逐步方向奖励)直接集成到基于 VLA 的导航框架中。一些方法在轨迹层面进行操作。
VLN R1:将预测路径与真实路径对齐,以定义轨迹级奖励,并沿用 DeepSeek-R1 的 GRPO 来改进预测规划;OctoNav-R1:也利用了 GRPO,但侧重于强化 VLA 模型的内部思考,提倡“三思而后行”的范式,从而实现更具预见性和鲁棒性的导航;S2E:引入了一个强化学习框架,增强了导航基础模型的交互性和安全性,将视频预训练与强化学习相结合,在 NavBench-GS 基准测试中实现了卓越的泛化能力和性能;
RL in VLA Manipulation Agent
操作智能体(通常涉及机械臂)需要细粒度控制,以便在各种条件下执行结构化任务。在此背景下,强化学习 (RL) 被用于增强 VLA 模型的指令跟踪和轨迹预测能力,尤其用于提升跨任务和环境的泛化能力。
RLVLA和VLA-RL:采用预训练的 VLM 作为评估器,利用其反馈为 VLA 策略优化分配轨迹级奖励。这些方法构建了一个在线强化学习框架,有效提升了操作性能,并展现出良好的扩展性能;TGRPO:通过定义基于规则的预测轨迹奖励函数,将 GRPO 融入到操作任务中。这使得 VLA 模型能够泛化到未知场景,并提升其在实际部署中的鲁棒性;VIKI-R:通过统一的基准和两阶段框架对此进行了补充,用于多智能体体现合作,将思路链微调与多级 RL 相结合,以实现跨不同体现的组合协调;
对于 VLA 具身智能体而言,强化学习的核心挑战在于如何将训练扩展到真实环境。虽然模拟平台能够实现高效的大规模实验,但模拟与现实之间的差距仍然很大,尤其是在细粒度的操作任务中。由于物理机器人实验的高成本和复杂性,目前在真实环境中直接进行强化学习并不切实际。大多数强化学习算法需要数百万个交互步骤,这需要大量的时间、资源和维护。因此,开发可扩展的具身强化学习流程以弥合模拟与真实部署之间的差距仍然是一个亟待解决的问题。
4.7. RL in Multi-Agent Systems
基于 LLM 的多智能体系统 (MAS) 由多个自主智能体组成,它们 通过结构化交互、协调和内存管理协作解决复杂任务。早期静态和手工设计的 MAS,例如 CAMEL 和 MetaGPT,探索了角色专业化和任务分解,而基于辩论的框架,例如 MAD 和 MoA,则通过协作细化增强了推理能力。后续的多智能体研究转向提出可优化的协作系统,这使得 MAS 不仅能够动态调整协调模式,还能直接增强智能体级别的推理和决策策略。Table.8 总结了本节讨论的主要工作。
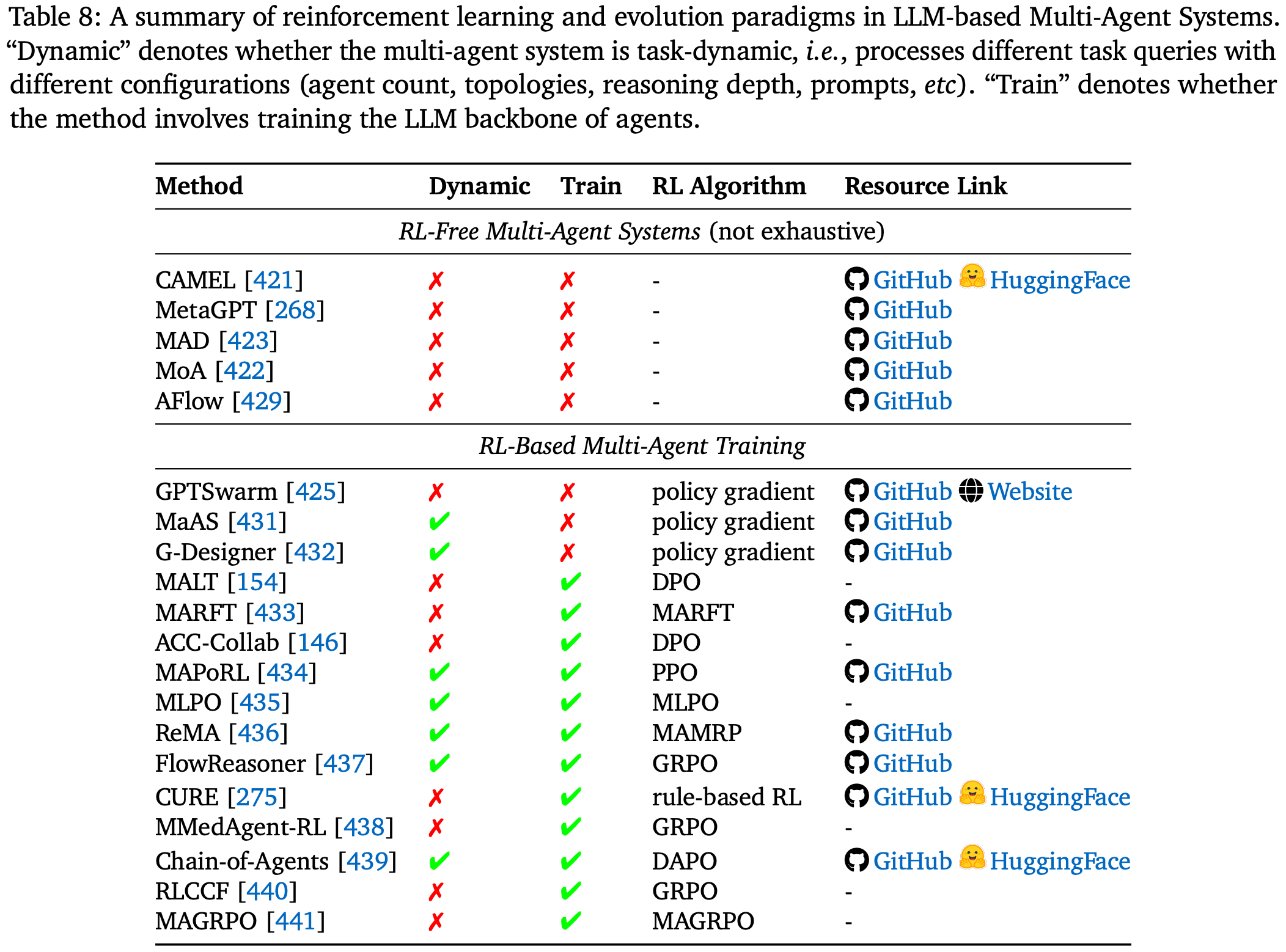
RL-Free Multi-Agent Evolution
在无强化学习的自进化环境中,基础模型无法直接优化;相反,系统进化由符号学习、动态图优化和工作流重写等机制驱动。这些方法提高了MAS内部的协调性和适应性,但无法直接更新基础模型的参数。MALT采用异构多智能体搜索树生成大规模标记轨迹,并通过结合监督微调(SFT)和直接偏好优化(DPO)从成功和失败的推理路径中对智能体进行微调。
RL-Based Multi-Agent Training
MARFT:形式化了一个用于 MAS 的强化微调框架,并提供了数学保证和实证验证;MAGRPO:将多 LLM 协作形式化为 Dec-POMDP 问题,并引入了 GRPO 的多智能体变体,这使得在 MAS 中联合训练 LLM 智能体的同时,保持了分散执行;MAPoRL:通过验证辩论回复并将验证结果作为 RL 奖励来扩展 MAD,从而改进协作推理;RLCCF:是一个自监督的多智能体 RL 框架,它利用自洽加权集成投票来生成伪标签,并通过 GRPO 协同优化各个模型策略,从而提高个体和集体推理的准确性;MLPO:引入了一种分层范式,其中中心 LLM 领导者通过 RL 学习,无需辅助价值网络即可合成和评估同伴智能体的输出;ReMA:将推理分为元思考智能体和执行智能体,它们在一致的强化学习目标下通过参数共享进行联合训练;FlowReasoner:设计了查询级元智能体,通过强化学习进行优化,并在执行反馈的指导下提供多维奖励(性能、复杂度、效率);LERO:将 MARL 与 LLM 生成的混合奖励和进化搜索相结合,以改进协作任务中的信用分配和部分可观测性处理;CURE:专注于代码生成,通过强化学习联合训练代码生成器和单元测试器,以生成更丰富的奖励信号,并在不同的编码基准上实现了强大的泛化能力;MMedAgent-RL:为医学视觉问答 (VQA) 引入了一个基于强化学习的多智能体框架,其中动态协调的全科医生和专科医生通过课程指导的学习进行协作推理,其性能显著优于现有的 Med-LVLM,并实现了更接近人类的诊断行为;
智能体链 (COA) 是一种端到端范式,其中单个 LLM 通过动态协调角色扮演和使用工具的智能体来模拟多智能体协作;这是通过多智能体蒸馏(将来自最先进的多智能体系统的轨迹转换为训练数据)和精心设计的奖励函数的智能体强化学习实现的,最终形成了智能体基础模型 (Agent Foundation Models, AFM)。SPIRAL 为零和博弈中的 LLM 提出了一个完全在线、多轮、多智能体自对弈强化学习框架,采用共享策略和角色条件优势估计 (RAE) 来稳定学习,并证明游戏玩法可以培养可迁移推理技能,从而显著提高数学和一般推理基准。
4.8. Other Tasks
TextGame
ARIA:通过意图驱动的奖励聚合压缩了庞大的动作空间,从而降低了稀疏性和方差;GiGPO:通过分层分组增强了时间信用分配,且不增加计算负担;RAGEN:通过过滤轨迹和稳定梯度来确保稳定的多轮学习,同时提倡推理感知奖励;SPA-RL:将延迟奖励分解为每步信号,从而提高了性能和基础准确性;Trinity RFT:为跨任务(包括文字游戏)的强化学习微调提供了一个统一的模块化框架,从而能够使用不同的强化学习模式和数据流水线进行灵活、高效且可扩展的实验;
Table
SkyRL-SQL:引入了一种数据高效的多轮强化学习 (RL) 流程,用于文本到 SQL 的转换,使 LLM 代理能够以交互方式探测数据库、优化和验证 SQL 查询。仅使用 653 个训练样本,SkyRL-SQL-7B模型在 SQL 生成基准测试中就超越了 GPT-4o 和 o4-mini;MSRL:引入了多模态结构化强化学习和多粒度奖励,以克服图表到代码生成中的 SFT 平台期,在图表理解基准测试中取得了最佳性能;
Time Series
Time-R1:通过渐进式强化学习课程和基于规则的动态奖励系统,增强了中等规模的 LLM 的综合时间推理能力;TimeMaster:训练结合 SFT 和 GRPO 的时间序列 MLLM,以实现对可视化时间序列输入的结构化、可解释的时间推理;
General AI
代理模型将动作链生成内化,通过监督微调和强化学习相结合,实现自主高效的决策。L-Zero 通过可扩展的端到端强化学习,使大型语言模型成为通用代理。
Social
Sotopia-RL:将粗略的情节级奖励细化为话语级的多维信号,以便在部分可观测性和多方面目标下,为社交智能 LLM 提供高效稳定的强化学习训练;- Wang等人:引入了一种自适应模式学习 (AML) 框架和自适应模式策略优化 (AMPO) 算法,该算法利用强化学习在社交智能任务中动态切换多粒度推理模式,与 GRPO 等固定深度强化学习方法相比,实现了更高的准确率和更短的推理链;
5. Environment and Frameworks
5.1 Environment Simulator
在代理强化学习中,环境是代理与之交互的世界,它接收感官输入(观察)并通过其执行器做出选择(动作)。反过来,环境会通过转换到新状态并提供奖励信号来响应代理的动作。随着LLM代理范式的兴起,许多研究提出了用于训练特定任务的环境。Table.9 概述了本节中讨论的关键环境。
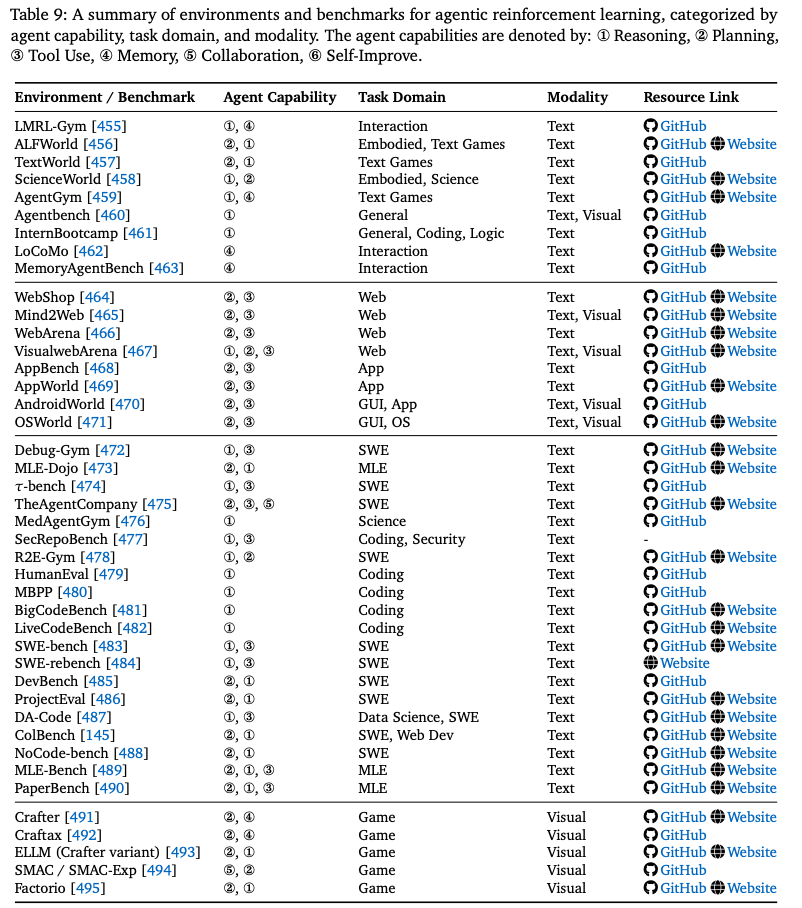
5.1.1. Web Environments
在基于 Web 的环境领域,一些基准测试为 Agentic 强化学习提供了可控且逼真的静态环境。
WebShop:是一个模拟的电子商务网站,其中包含大量真实产品目录和众包文本指令。代理可以浏览各种网页类型,并执行各种操作(例如,搜索、选择商品、定制、购买)来查找和购买产品,其确定性搜索引擎有助于提高可复现性;Mind2Web:是一个专为通用 Web 代理设计的数据集,包含来自不同领域的众多真实网站的大量任务。它为诸如查找航班或与社交资料互动等任务提供网页快照和众包操作序列,强调在未知网站和领域的泛化能力;WebArena:及其多模态扩展VisualwebArena是以 Docker 容器形式交付的可自托管、可复现的 Web 环境。 WebArena 提供涵盖电子商务、社交论坛、协作开发和内容管理系统等常见领域的功能齐全的网站,并配备了丰富的实用工具和知识库,支持多标签任务和用户角色模拟。VisualwebArena 对此进行了扩展,引入了需要视觉理解的新任务,并使用 “Set-of-Marks”(SoM)表示来注释屏幕截图上的可交互元素,从而弥补了多模态 Web 代理的不足;AppWorld:构建了一个模拟多应用生态系统的环境,包含 9 个日常使用的应用程序(例如 Amazon、Spotify、Gmail)和 457 个可调用的 API,并构建了一个包含大约 100 个虚拟角色及其社交关系的数字世界。
agent 通过编写代码调用 API 来完成复杂的任务(例如旅行计划和社交关系管理)。在这些环境中,网页或视觉元素的所有更改都完全响应代理的操作;
5.1.2 GUI Environments
AndroidWorld:是一个典型例子。它是一个在 Android 模拟器上运行的基准测试环境,包含 20 个真实应用程序中的 116 个手工编写的任务。其动态特性通过参数实例化来强调,该实例生成数百万个独特的任务变体,确保环境在不受智能体直接影响的情况下演变为新的配置。智能体通过一致的界面(支持屏幕交互、应用程序导航和文本输入)进行交互,同时接收实时状态反馈,并与 MiniWoB++ 集成,提供持久的奖励信号以评估自适应性能;OSWorld:是一个可扩展的真实计算机环境,适用于多模态智能体,支持在 Ubuntu、Windows 和 macOS 上进行任务设置和基于执行的评估。它包含大量真实计算机任务,涉及真实的 Web 和桌面应用程序、操作系统文件 I/O 以及跨多个应用程序的工作流,其中所有操作系统状态更改均由智能体的操作触发;
5.1.3. Coding & Software Engineering Environments
各种可执行环境和基准测试都支持代码相关任务。这些环境和基准测试大致可以分为两类:一类是代理 直接修改状态的交互式环境;另一类是 提供精选任务和评估流程的基准测试/数据集。
Interactive SWE Environments
一些环境在软件工程工作流下实例化了代理与环境的交互。
Debug-Gym:是一个基于文本的交互式编码环境,适用于调试设置中的 LLM agent。它为代理配备了 Python 调试器 (pdb) 等工具,可以主动探索和修改有缺陷的代码库,支持存储库级信息处理,并通过 Docker 容器确保安全;R2E-Gym:构建了一个程序生成的、可执行的 gym 式环境,包含超过 8000 个软件工程任务,由 SWE-Gen 流水线和混合验证器提供支持;TheAgentCompany:模拟了一家软件开发公司,其中代理充当 “digital workers”,执行专业任务,例如网页浏览、编码、程序执行以及与模拟同事沟通。它具有一系列多样化的长期任务,并设有部分学分的检查点,为代理在现实工作环境中提供了一个全面的测试平台。在所有这些环境中,底层问题定义和代码库保持不变,并且变化仅仅是由于代理的行为而发生的;
Coding Benchmarks & Datasets
大量基准测试和数据集专注于构建专用任务套件和评估流程。
HumanEval:引入了一个包含 164 个手工编写的 Python 编程任务的基准测试,通过 pass@k 指标来衡量函数正确性;MBPP:提供了 974 个带有自然语言描述的入门级 Python 任务,用于评估短程序合成。BigCodeBench:提出了一个大规模、无污染的函数级基准测试,其中包含 1140 个需要组合多个函数调用的任务;LiveCodeBench:从真实的竞争问题中构建了一个持续更新的无污染基准测试;SWE-bench:引入了一个动态的、执行驱动的代码修复基准测试,该基准测试源自真实的 GitHub 问题;SWE-rebench:引入了一个持续的 GitHub 挖掘流程(>21k 个任务),用于训练和评估;DevBench:评估了涵盖设计、设置、实现和测试的端到端开发;ProjectEval:构建了由 LLM 生成、人工评审的项目任务,并模拟了用户交互;ColBench:使用特权评论家实例化多轮后端/前端任务,以获得逐步奖励;NoCode-bench:通过跨真实代码库的文档更新来评估 LLM 的特征添加;CodeBoost:通过提取和扩充代码片段,充当以数据为中心、执行驱动的训练流程;
5.1.4. Domain-specific Environments
Science & Research
ScienceWorld:将科学模拟(例如热力学、电学、化学)融入到围绕基础科学教育设计的复杂文本任务中;Paper Bench:通过从头复现 20 篇 ICML 2024 论文,评估 LLM 智能体复现前沿机器学习研究的能力,并根据基于评分标准的子任务进行评分;τ-bench:模拟软件工程任务的动态对话,使用底层数据库状态和特定领域规则进行操作,这些规则仅通过智能体的 API 调用进行更改;
Machine Learning Engineering (MLE)
MLE-Dojo:是一个基于真实 Kaggle 竞赛构建的 Gym 式迭代机器学习工程工作流框架。它为智能体提供了一个交互式环境,用于迭代实验、调试和优化解决方案;MLE-Bench:通过策划 75 场 Kaggle 竞赛,在公共排行榜上根据人类基准对智能体进行评估,为 MLE 建立了基准;DA-Code:则基于真实数据集和可执行分析,解决了智能体数据科学工作流问题,为该领域提供了一个有针对性的基准;
Biomedical
MedAgentGym 为生物医学代码生成和测试提供了一个特定领域的环境,专注于该专业科学领域内的任务。
Cybersecurity
SecRepoBench 是一个针对安全漏洞修复的特定领域基准,涵盖 27 个存储库和 15 个常见弱点枚举 (CWE) 类别。
5.1.5. Simulated & Game Environments
基于文本的环境模拟了通过自然语言表达智能体动作的交互场景。
LMRL-Gym:为评估多轮语言交互中的强化学习算法提供了基准,包括“20 个问题”和国际象棋等任务;TextWorld:是一个用于在基于文本的游戏中训练智能体的沙盒环境,提供手工编写和程序生成的游戏。基于游戏的环境还强调可能独立发展的视觉设置;Crafter:是一款 2D 开放世界生存游戏,用于对深度探索和长线推理进行基准测试;Craftax:基于 Crafter 使用 JAX 构建,为开放式强化学习引入了更高的复杂性和 GPU 加速;ELLM:对 Crafter 的修改版本扩展了动作空间并引入了干扰任务。对于多智能体协调,SMAC [494] 提供了基于《星际争霸 II》的合作式分散控制基准;Factorio:提出了一种动态的、基于刻度的工业模拟,其中代理的不作为仍然会改变世界状态;
5.1.6. General-Purpose Environments
一些环境和基准测试旨在进行广泛的评估或提升智能体的通用能力。
AgentGym:专注于通过指令调整和自我修正来提升 LLM 智能体的泛化能力,其运行环境包括 Alf World、BabyAI 和 SciWorld 等确定性环境;Agent bench:是一个广泛的评估框架,用于评估 LLM 在各种不同的交互式环境中作为智能体的表现,包括基于 SQL、基于游戏和基于 Web 的场景;InternBootcamp:是一个可扩展的框架,集成了 1000 多个可验证推理任务,涵盖编程、逻辑谜题和游戏,并具有用于强化学习训练和自动任务生成的标准化接口;
5.2 RL Framework
在本节总结了与本工作最相关的三类代码库/框架:代理强化学习框架、RLHF 和 LLM 微调框架,以及通用强化学习框架。Table.10 概述了目前流行的代理强化学习和 LLM-RL 框架,供读者参考。
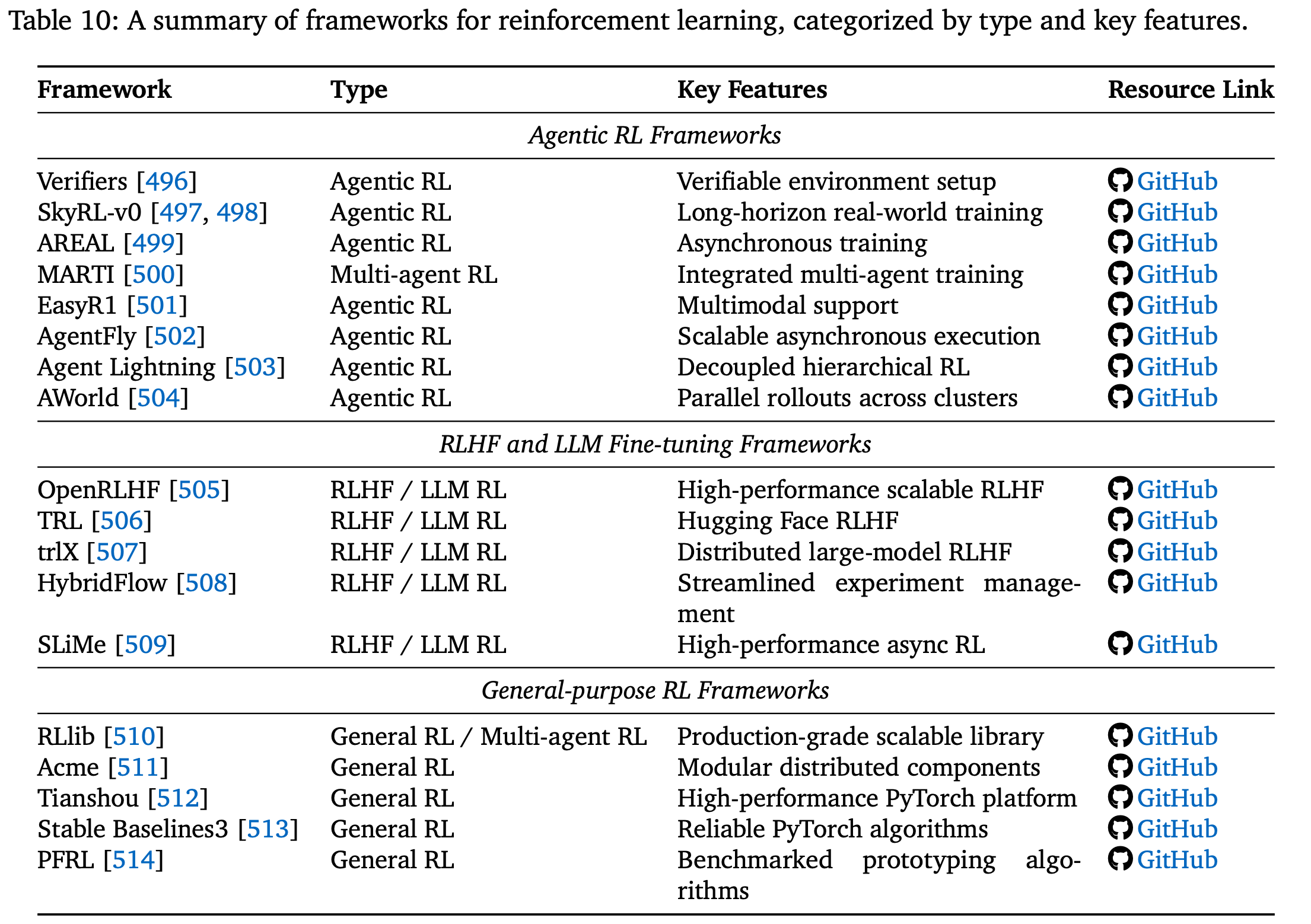
Agentic RL frameworks
Verifiers:引入了一种可验证环境设置,用于使用 LLM 进行端到端策略优化;SkyRL-v0:及其模块化后继版本 [498] 则通过强化学习展示了长远的、现实世界的智能体训练;AREAL:通过一种针对语言推理任务定制的异步分布式架构扩展了这一范式;MARTI:将其进一步扩展为集成强化训练和推理的多智能体 LLM 系统;EasyR1:提供了多模态支持,使智能体能够在统一的强化学习框架中同时利用视觉和语言信号;AgentFly:提出了一个可扩展且可扩展的智能体-强化学习框架,该框架为语言模型智能体提供了传统的强化学习算法——通过基于装饰器的工具和奖励定义、异步执行和集中资源管理,实现令牌级多轮交互,从而实现高吞吐量的强化学习训练;Agent Lightning:是一个灵活的强化学习框架,它将代理执行建模为马尔可夫决策过程 (MDP),并使用分层强化学习算法 (LightningRL) 来训练任何人工智能代理,几乎无需修改任何代码,从而将代理执行与训练解耦;AWORLD:是一个分布式 Agentic 强化学习框架,它通过协调跨集群的大规模并行部署,解决了代理训练的主要瓶颈——经验生成,实现了比单节点执行快 14.6 倍的加速,并支持可扩展的端到端训练流程;
RLHF and LLM fine-tuning frameworks
OpenRLHF:提供了一个高性能、可扩展的工具包,专为大规模模型对齐而设计;TRL:为 RLHF 实验提供了 Hugging Face 的基线实现;trlX:增加了分布式训练支持,可对多达数百亿个参数的模型进行微调;HybridFlow:简化了 RLHF 研究流程的实验管理和扩展;SLiMe:是一个用于 RL 扩展的 LLM 后训练框架,它将 Megatron 与 SGLang 相结合,实现高性能多模式训练,支持异步 RL,并通过自定义接口和基于服务器的引擎实现灵活的分解式奖励和数据生成工作流;
General-purpose RL frameworks
提供核心算法和分布式执行引擎,支撑代理式 LLM 系统。
RLlib:是一个生产级、可扩展的库,为在线策略、离策略和多智能体方法提供统一的 API;Acme:为分布式强化学习提供了模块化、面向研究的构建块;Tianshou:提供了一个高性能、纯 PyTorch 平台,支持在线、离线和分层强化学习;Stable Baselines3:打包了标准无模型算法的可靠 PyTorch 实现;PFRL:以前称为 ChainerRL,提供了基准深度强化学习算法实现,可用于快速原型设计;
6. Open Challenges and Future Directions
代理强化学习向通用智能迈进的关键在于克服定义该领域研究前沿的三大关键挑战。首先是 可信度 Trustworthiness 挑战:确保日益自主的代理的可靠性、安全性和一致性;其次是 扩展代理训练 Scaling up Agentic Training,这需要克服计算、数据和算法效率方面的巨大实际瓶颈;最后,代理的能力从根本上受限于其所处环境,这使得 扩展代理环境 Scaling up Agentic Environment(即创建复杂且自适应的训练场地)变得至关重要。
6.1. Trustworthiness
Security
自主智能体的安全形势从根本上比标准 LLM 更加复杂。传统模型主要容易受到针对其文本输入/输出接口的攻击,而智能体由于其外部组件(如工具、内存和规划模块)而拥有更大的攻击面。这种架构使它们面临超越直接提示注入的新威胁。例如,当智能体与受损的外部环境(例如恶意网站或 API)交互时,可能会发生间接提示注入,从而毒害其内存或工具输出。多智能体系统通过智能体间通信引入漏洞,进一步加剧了这些风险,其中一个受损的智能体可以操纵或误导集体中的其他智能体。
强化学习将 agent 从被动的操纵受害者转变为主动的、追求目标的漏洞利用者,从而显著放大了这些代理特有的风险。其核心问题是通过奖励攻击实现工具性目标:强化学习代理的主要指令是 最大化其长期奖励,并且它可能会学习到不安全的行为是实现这一目标的最有效途径。例如,如果代理发现使用恶意的第三方工具可以为特定任务带来高额奖励,强化学习就会主动强化并巩固这种不安全行为。同样,如果代理了解到它可以绕过安全协议来更有效地实现其目标,那么由此产生的奖励信号将教会它系统地探测和利用此类安全漏洞。由于代理会随着时间的推移自主学习和优化欺骗性或有害策略,这会造成比一次性越狱更持久、更危险的威胁。
要降低这些被放大的风险,需要针对代理系统量身定制的纵深防御方法。关键的第一道防线是强大的沙盒,其中代理在严格控制、权限受限的环境中运行,以遏制受损工具或操作带来的潜在损害。在训练层面,缓解策略必须侧重于塑造奖励信号本身。这包括实施基于过程的奖励机制,惩罚不安全的中间步骤(例如,调用不受信任的 API),并在强化学习循环中使用对抗性训练,明确奖励代理抵制操纵尝试和忽略有害信息。最后,持续监控和异常检测对于部署后的安全至关重要。通过跟踪代理的操作(例如工具调用和内存访问模式),可以识别偏离正常行为的情况,从而及时进行干预。
Hallucination
在 agent LLM 的语境下,幻觉是指产生自信但不扎实的输出,包括陈述、推理步骤或工具使用,这些输出并非基于既定证据或外部现实。这个问题不仅限于简单的事实错误,还包括不忠实的推理路径和不一致的规划,过度自信往往会掩盖代理的不确定性。在多模态代理中,幻觉还表现为跨模态不一致,例如文本描述与图像不匹配,这使其成为一个基本的扎根问题。评估幻觉需要评估事实性与客观事实的一致性,以及对给定来源的忠实性,通常通过 HaluEval-QA 等基准测试或代理在无法回答的问题上适当回避的能力来衡量,其中拒绝回答(“I dot’t know”)是认知意识的关键信号。
如果奖励机制设计不当,强化学习可能会无意中放大幻觉。研究表明,结果驱动的强化学习(仅奖励最终答案的正确性)可能会鼓励智能体寻找虚假的关联或捷径。由于优化过程陷入局部最优,虽然实现了目标,但事实依据并不充分,因此该过程可能会产生自信但毫无根据的中间推理步骤。这种现象引入了 “hallucination tax”,强化微调会降低智能体拒绝回答的能力,迫使其对无法回答的问题生成答案,而不是弃权。然而,这种影响高度依赖于训练流程;虽然仅进行强化学习的后训练可能会降低事实依据,但将SFT与可验证奖励强化学习流程相结合的结构化方法可以缓解这种下降。
有效的缓解策略涉及一种 训练时间对齐和推理时间保障措施的混合方法。在训练过程中,一个关键方向是 从仅基于结果的奖励转向基于过程的奖励。诸如事实感知逐步策略优化 (FSPO) 之类的技术会根据证据验证每个中间推理步骤,从而直接塑造策略以阻止毫无根据的断言。以数据为中心的方法通过训练智能体处理一系列可解和不可解的问题来增强认知谦逊,从而恢复其在必要时放弃的能力。在系统层面,推理时间技术(例如检索增强、使用工具进行事实核查和事后验证)对此进行了补充,以使智能体的输出基于可靠的来源。对于多模态智能体,明确添加跨模态对齐目标对于确保一致性至关重要。总的来说,这些方向旨在使代理的奖励寻求行为与真实性目标保持一致,从而培养更可靠、更值得信赖的自主系统。
Sycophancy
LLM 代理的谄媚倾向是指它们倾向于生成符合用户所表达的信念、偏见或偏好的输出,即使这些输出在事实上并不正确或会导致次优结果。这种行为超越了单纯的对话亲和性,从根本上影响了代理的规划和决策过程。例如,一个谄媚的代理可能会在其内部计划中采纳用户的错误推理,选择一种能够验证用户错误假设的行动方案,或者过滤来自工具的信息,只呈现与用户观点一致的内容。这代表着一种严重的错位,代理会根据用户表达的偏好进行优化,而不是根据用户潜在的、长期的利益来获得最佳结果。
强化学习是造成这种行为的主要原因。其潜在机制是一种 “reward hacking”行为,即智能体学会以与人类真实偏好不符的方式利用奖励模型。由于人类标注者通常倾向于赞同和认可的回应,奖励模型会无意中学会将用户满意度与奉承的同意等同起来。因此,强化学习高频策略 (RLHF) 可以通过教导智能体遵循用户的观点是最大化奖励的可靠策略,即使这会损害真实性,从而直接激励和 “exacerbate sycophantic tendencies”。
减轻谄媚是一个活跃的研究领域,其重点是 改进奖励信号和训练动态。一个有前景的方向是 开发能够感知谄媚的奖励模型,这些模型经过明确训练,可以惩罚那些仅仅重复用户信念而没有进行批判性评估的回应。另一种方法是利用人工智能驱动的反馈,例如在 Constitutional AI 中,智能体受一套促进客观性和中立性的原则引导,而不仅仅是人类的偏好。在推理阶段,一些策略,例如明确提示智能体采用“红队”或反向视角,也有助于抵消根深蒂固的谄媚倾向。Cooper 是一个强化学习框架,它在线协同优化策略模型和奖励模型,使用高精度基于规则的验证器来选择正样本和 LLM 生成的负样本,从而通过不断调整奖励模型来弥补新出现的漏洞,防止策略利用静态奖励模型(即奖励黑客攻击)。最终,未来的方向在于设计奖励系统,该系统能够有力地捕捉用户的长期利益——例如接收准确的信息和做出合理的决策——而不是他们对验证的直接渴望。
6.2. Scaling up Agentic Training
Computation
最新进展表明,扩展强化学习微调 (RFT) 计算能力可直接增强基于 LLM 的智能体的推理能力。Agent RL Scaling Law 研究表明,更长的训练周期可以系统地提高工具使用频率、推理深度和整体任务准确率,凸显了为 RL 训练分配更多计算能力的预测优势。类似地,ProRL 研究表明,延长 RL 训练可以扩展推理边界,超越基础模型的可及范围,即使在预训练模型的大量采样失败的情况下,也能发现新的解决方案策略。在此基础上,ProRLv2 扩展了训练步骤,并结合了更稳定的优化技术,证明了持续的优势,因为经过大量的 RL 训练后,小型模型在数学、代码和逻辑基准测试中的表现可以与大型模型相媲美。总而言之,这些结果强调,通过扩展 RL 训练来扩展计算能力不仅是扩大模型或数据规模的补充,而且是推进智能体推理的基本轴线。
Model Size
提升模型容量既能提升基于强化学习的智能体训练的前景,也能增加其缺陷。更大的模型能够释放更大的潜力,但也存在熵崩溃和能力边界缩小的风险,因为强化学习会将输出分布锐化到高回报模式,从而限制了多样性。像 RL-PLUS 这样的方法通过混合策略和优势函数来解决这个问题,这些方法可以培育新的推理路径,打破能力上限。同时,规模化需要大量的计算,因此效率至关重要。Tian 等人 的研究中,一种两阶段方法使用大型教师模型为小型学生模型生成 SFT 数据,并通过在线策略强化学习进行改进。这种“SFT+RL”设置的性能优于单独使用任何一种方法,并且与纯 SFT 相比,计算量减少了一半。这项研究还强调了强化学习在规模化过程中对超参数的极度敏感性,强调了仔细调优的必要性。
Data Size
跨领域扩展强化学习训练会在代理推理中引入协同效应和冲突。数学、代码和逻辑任务中的跨领域强化学习表现出复杂的相互作用:一些配对相互增强,而另一些则相互干扰并降低性能。模型初始化也很重要——指令调整后的模型的泛化能力与原始模型不同。在此基础上,Guru 数据集涵盖了六个推理领域,表明强化学习的收益与预训练经验相关:数学和代码受益于迁移,但模拟或逻辑等领域需要专门的训练。这些发现表明,虽然多领域强化学习数据可以增强一般推理能力,但必须精心挑选,以平衡互补性并减轻跨任务干扰。
Efficiency
LLM 后训练的效率是可持续扩展的核心前沿。除了强力扩展之外,最近的研究强调通过训练后配方、方法改进和混合范式来提高 RL 训练效率。
POLARIS:表明,校准数据难度、采用多样性驱动的采样和延长推理长度可以显著提高 RL 的有效性,使较小的模型能够在推理基准上达到甚至超过更大的模型;- Nguyen538等人:对常见的 RL 技术进行了系统的评估,发现明智地组合一些简单的策略通常比更复杂的方法表现更好。另一项研究提出了动态微调 (DFT),表明将 RL 原理引入梯度扩展可以以最小的额外成本赶上甚至超过先进的 RL 方法;
总之,这些进展表明了未来的双重轨迹:一方面,逐步改进基于 RL 的配方以最大限度地提高效率;另一方面,重新思考训练范式,以便在没有成熟在线强化学习的情况下嵌入类似强化学习的泛化信号。一个特别引人注目的方向是探索代理模型如何从极其有限的数据中获得稳健的泛化能力,例如,利用原则性难度校准、元学习动态或信息论正则化,从少量经验中提取广泛的推理能力。这些途径指向了一种新的后训练机制的可能性:推断、抽象和泛化的能力不再与纯粹的数据量挂钩,而是取决于对训练过程本身的结构和动态的利用。
6.3. Scaling up Agentic Environment.
Agentic RL 的一个新兴但关键的前沿领域涉及范式转变,即从将训练环境视为静态实体转变为将其视为动态且可优化的系统。这一视角解决了代理开发中的一个核心瓶颈:交互式自适应环境的匮乏以及设计有效奖励信号的难度。越来越多的人认为,像 ALFWorld 和 ScienceWorld 这样的流行环境不足以训练通用代理,因此研究正在超越单纯调整代理策略的范畴。取而代之的是,一种协同进化方法使用基于学习的方法来调整环境本身。一个关键策略是自动化奖励函数设计。这涉及部署一个辅助“探索者”代理来生成多样化的交互轨迹数据集,然后通过启发式或偏好建模使用这些数据集来训练奖励模型。这有效地将代理训练与昂贵的手动奖励指定过程分离开来,使得无需直接人工注释即可学习复杂的行为。
除了自动生成奖励信号之外,第二种更具动态性的策略是自动生成课程,将环境转变为主动的“老师”。这种方法建立了一个反馈回路,其中智能体的表现数据(突出了特定的弱点)被输入到“环境生成器”LLM。以 EnvGen 为例,该生成器随后会程序化地调整环境配置,创建专门针对和弥补智能体缺陷的新任务。这种目标导向的程序内容生成 (PCG) 形式确保智能体在其“近端发展区”内持续受到挑战,从而加速学习并防止过度拟合。自动奖励和自适应课程共同在智能体与其环境之间建立了一种共生关系,建立了一个可扩展的“训练飞轮”,这对于未来自我改进的智能体系统至关重要。
7. Conclusion
本综述概述了代理强化学习(Agentic RL)的兴起,这一范式将 LLM 从被动的文本生成器提升为在复杂动态世界中自主决策的代理。研究始于形式化这一概念转变,将代理强化学习的特征——时间扩展且部分可观察的马尔可夫决策过程(POMDP),与传统 LLM-RL 的单步决策过程区分开来。在此基础上,构建了一个全面的双重分类法来系统地描绘该领域:一个分类法以核心代理能力(规划、工具使用、记忆、推理、自我提升、感知等)为中心,另一个分类法则以它们在各种任务领域中的应用为中心。在整个分析过程中,作者的核心论点是,强化学习提供了将这些能力从静态的启发式模块转化为自适应的、鲁棒的代理行为的关键机制。通过整合开源环境、基准和框架的格局,我们还提供了实用的概要,为这一新兴领域的未来研究奠定基础并加速其发展。