SD:在一个 Ubuntu 系统安装 stable diffusion ComfyUI
目录
- 1. 环境准备
- 2. git仓库
- 3. 配置 WebUI 的模型路径
- 4.启动软件
- 5. 插件安装
- 5.1 管理插件的插件 ComfyUI-Manager
- 5.2 安装其他插件
- 5.2.1 安装举例
- 6. 关于位置
- 6.1 模型位置
- 6.2 工作流保存位置
- 6.3 生成结果的位置
- 7. 简单使用
- 7.1 文生图为例
- 7.2 图生视频
- 附录1 - 关于模型下载
1. 环境准备
- 个人系统
查看系统信息(方便向AI提问)
cat /etc/os-release
- 新建 python 环境
- 创建新环境
- 激活环境
python3 -m venv ~/venv_sd_comfy
source ~/venv_sd_comfy/bin/activate
- 注:关于使用 系统自带 python 还是 conda 来安装环境
之前我安装WebUI 已经占了一个 Conda 环境,ComfyUI 强烈建议「另起炉灶」——用系统自带的 Python 3.12 单独建 venv,而不是再开一个 Conda 环境。原因有三:
- 隔离最干净
WebUI 的 Conda 环境里可能装了一堆它自己改动的包(xformers、gradio 老版本等),ComfyUI 并不需要,混用反而容易版本冲突。系统 venv 与 Conda 完全隔离,升级/回滚互不影响。 - 省内存 + 省磁盘
Conda 每新建一个环境都会再复制一份基础库,动辄 2-3 GB;Python 自带 venv 只做符号链接,几十 MB 搞定。推理时两个进程各自驻留显存即可,不会因为「同门」就节省。 - 官方仓库就是按「系统 Python + venv」测试的
ComfyUI 的 requirements.txt 里很多 wheel 只有 cp312 版本,Conda 的 python 3.10/3.11 反而要多编译,速度慢且容易踩坑。
一句话结论
「ComfyUI 用系统 Python 建 venv」→ 最省心、最省资源,后期维护也简单。
- python包
pip install --upgrade pip
pip install torch torchvision torchaudio \--extra-index-url https://download.pytorch.org/whl/cu121
2. git仓库
我将其安装在本地的 ~/programs 下面(这个路径自选)
cd ~/programs
git clone https://github.com/comfyanonymous/ComfyUI.git
- 如果提示找不到这个url
git clone --depth 1 \--config http.postBuffer=524288000 \https://github.com/comfyanonymous/ComfyUI.git
- 安装依赖的python包
cd ComfyUI
pip install -r requirements.txt
3. 配置 WebUI 的模型路径
- 创建文件 extra_model_paths.yaml
cp extra_model_paths.yaml.example extra_model_paths.yaml
- 修改文件内容如下:
a111:base_path: **/home/xxx/programs**/stable-diffusion-webui/checkpoints: models/Stable-diffusionvae: models/VAEloras: |models/Loramodels/LyCORISclip_vision: models/clip_visiongligen: models/GLIGENcontrolnet: models/ControlNetcontrolnet_preprocessors: models/ControlNetipadapter: models/IpAdapterinstantid: models/InstantIDupscale_models: models/ESRGANembeddings: embeddingshypernetworks: models/hypernetworks
注:
base_path 必须是绝对路径,~ 不会展开。
缩进只能空格,YAML 对 Tab 零容忍。
如果想再加自己独立目录,继续往下加同级字段即可,ComfyUI 会合并读取。
4.启动软件
- 新建启动脚本 0_launch.sh(在 ComfyUI 根目录下),内容如下:
source ~/venv_sd_comfy/bin/activate
exec python main.py "$@"
- 添加可执行权限
chmod +x 0_launch.sh
-
启动
- 普通启动
./0_launch.sh - 低显存启动
./0_launch.sh --lowvram --fp8_e4m3fn-unet --fp8_e5m2-text-enc
- 普通启动
-
进入前端
在浏览器打开 http://127.0.0.1:8188 即可
5. 插件安装
先退出后台进程(ctrl+c)
位置:ComfyUI/custom_nodes/ 文件夹下
cd 到该位置下进行操作 !!!
5.1 管理插件的插件 ComfyUI-Manager
git clone https://github.com/ltdrdata/ComfyUI-Manager.git# 先激活你之前建的 venv
source ~/venv_sd_comfy/bin/activate
# 装它自己的依赖
python -m pip install -r ComfyUI-Manager/requirements.txt
重启 ComfyUI 后可以看到:
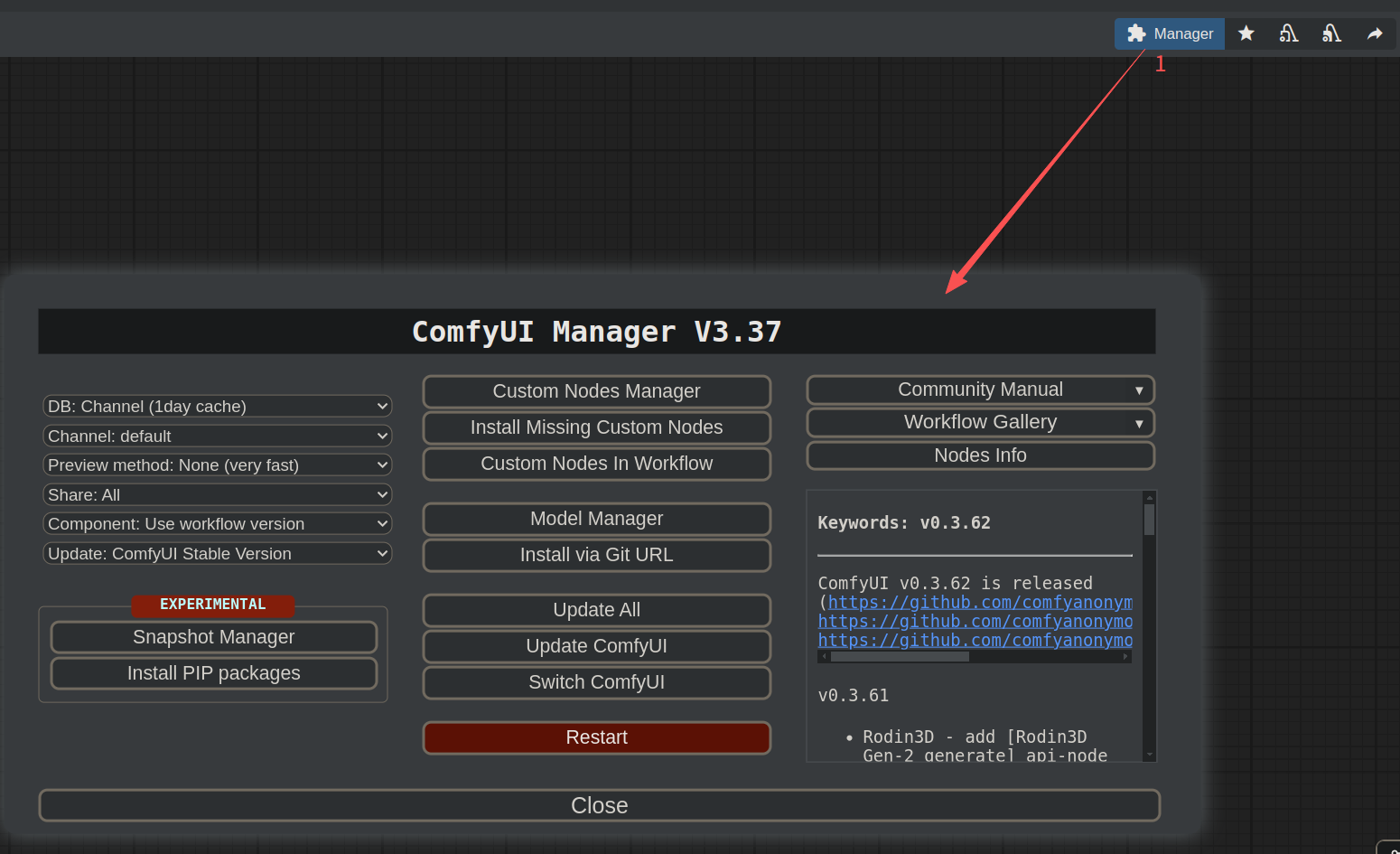
5.2 安装其他插件
5.2.1 安装举例
- 在上一个窗口中,选择 Custom Nodes Manager 即可进入插件列表,通过搜索、install 即可导入。
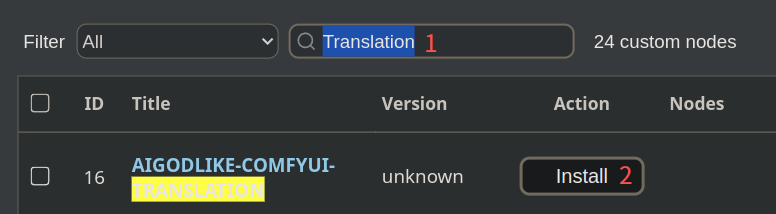
- 下载完需要重启

6. 关于位置
6.1 模型位置
| 模型类型 | 放到(ComfyUI 根目录) | 若共用 WebUI 则放到 |
|---|---|---|
| 主模型 ckpt/safetensors | models/checkpoints/ | models/Stable-diffusion/ |
| LoRA | models/loras/ | models/Lora/ |
| VAE | models/vae/ | models/VAE/ |
| ControlNet | models/controlnet/ | models/ControlNet/ |
| CLIP Vision | models/clip_vision/ | models/clip_vision/ |
| Textual Inversion | models/embeddings/ | embeddings/ |
6.2 工作流保存位置
ComfyUI/user/default/workflows
6.3 生成结果的位置
ComfyUI/output/
7. 简单使用
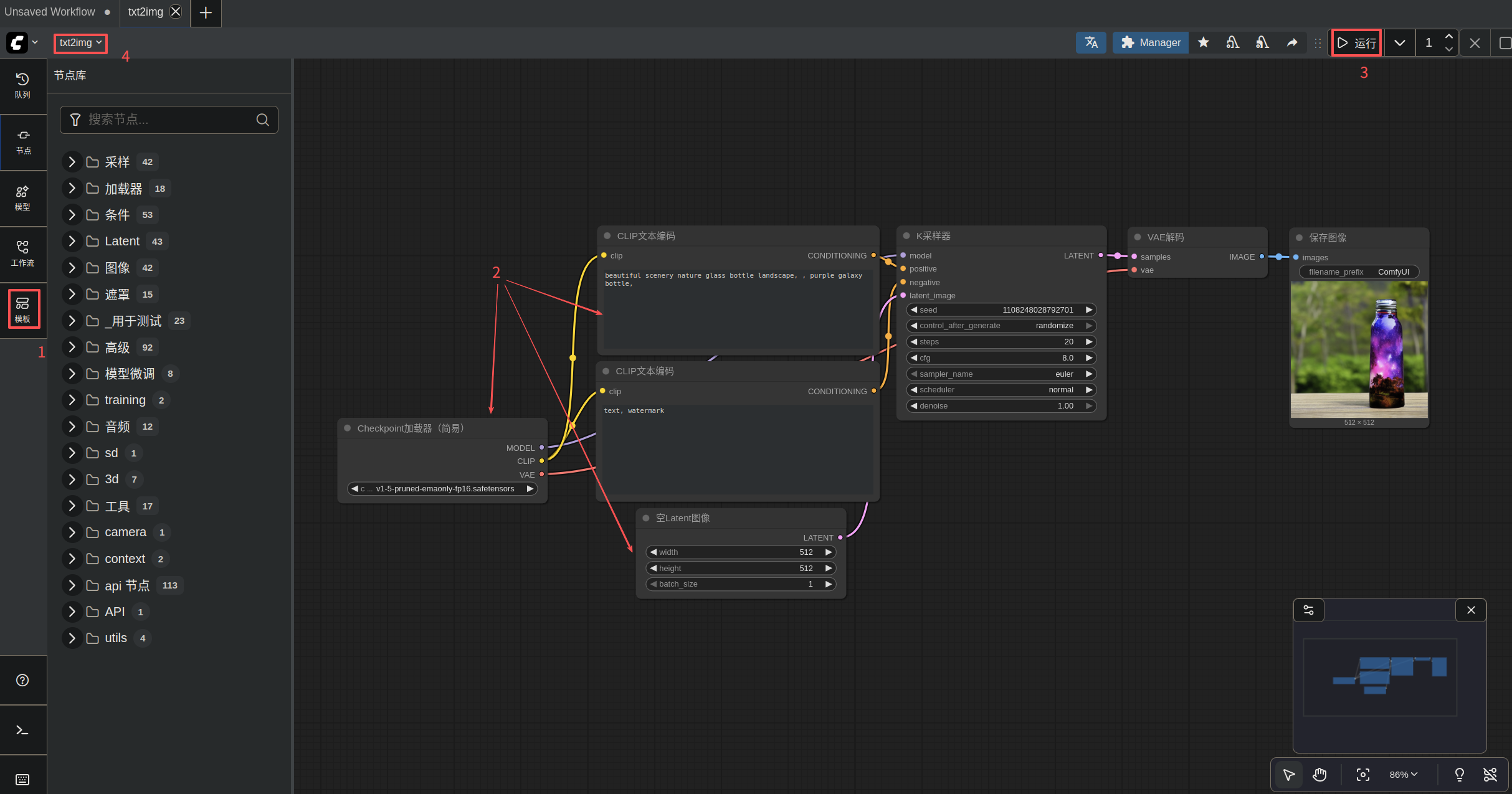
7.1 文生图为例
- step1: 在模版中找到第一个文生图工作流
- step2: 修改相关参数
- step3: 运行
- step4: 可以进行 重命名、保存这个工作流 等操作
7.2 图生视频
再试一下图生视频工作流。这里由于显存限制,将 wan2.2_i2v_low_noise_14B_fp8_scaled.safetensors 换成:
wan2.1_t2v_1.3B_fp16.safetensors
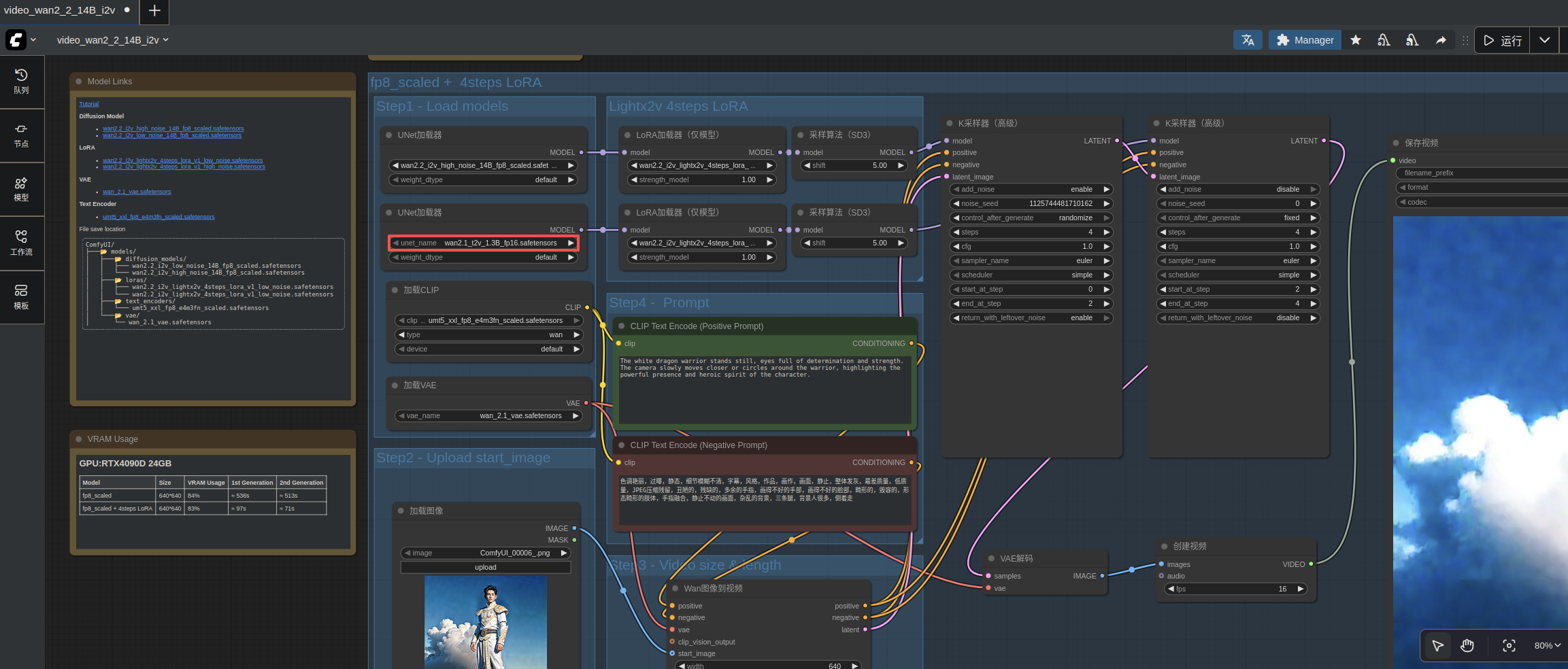
- 结果
这里仅简单尝试,图片较小 640×640

附录1 - 关于模型下载
- 国内下载
- https://hf-mirror.com/
先复制链接
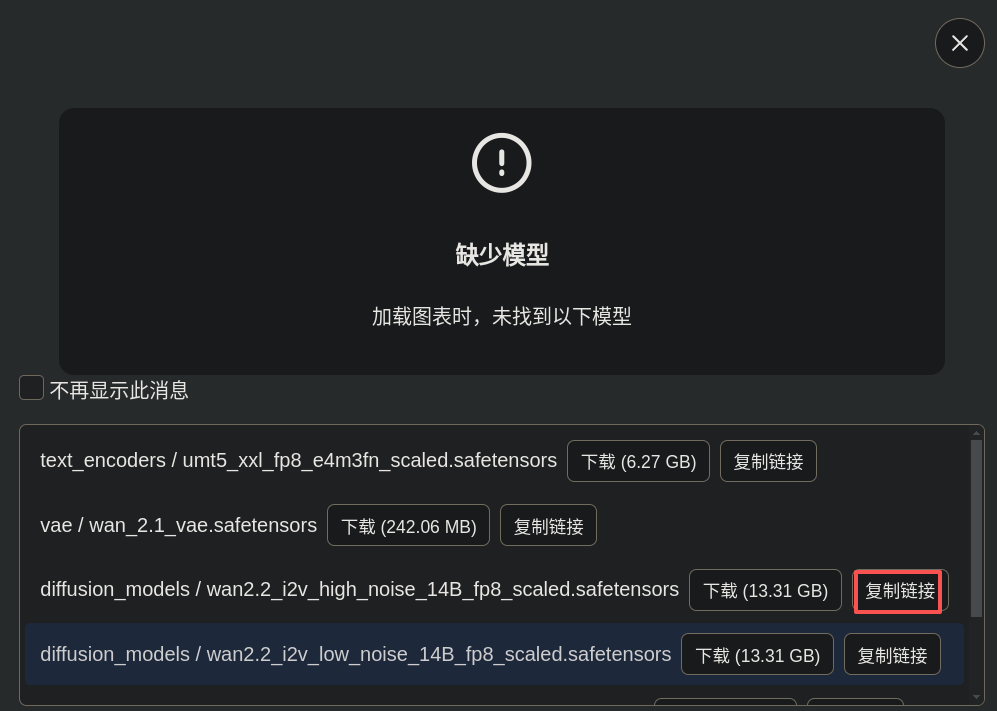
然后,尝试将 huggingface.co 改为 hf-mirror.com,在浏览器里面粘贴
- https://hf-mirror.com/
例如:
https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/diffusion_models/wan2.2_i2v_low_noise_14B_fp8_scaled.safetensors改为:
https://hf-mirror.com/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/diffusion_models/wan2.2_i2v_low_noise_14B_fp8_scaled.safetensors