rrk3588 与 NPU 主机下的异构通信:基于 PCIe 的设计与实现
一、背景介绍
在项目中,我们遇到了一种非常经典的在异构体系下基于PCIE通信的设计,这种设计模式下rk3588负责作为主机,提供系统环境支持、运行支持,其上运行了我们的操作系统,内核为5.10; NPU由地平线提供,内置了其定制的linux操作系统,两者通过PCIE3.0x2连接,进行通信。 3588将模型任务通过PCIE下发到NPU后由NPU进行计算, NPU将运算后的成果返回给3588。
二、通信方式介绍
这是一种非常通用且常见的的异构通信方式,实际上我们在配置电脑的独立显卡时就采用的是这种通信方式,为了方便理解,我们这里以GPU为例,介绍一下这种架构的通信方式。
其基本架构为:
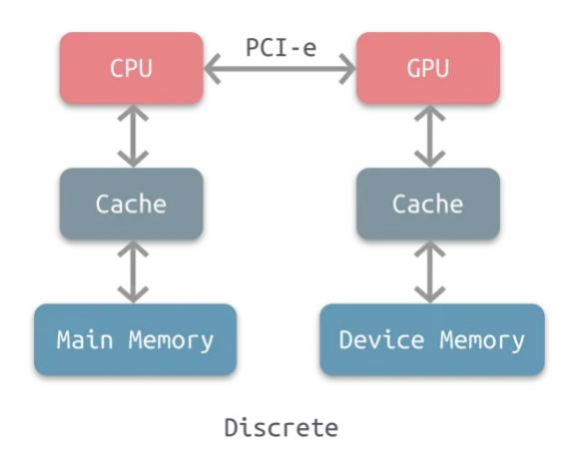
其中CPU 和 GPU 拥有各自独立的缓存和内存,两者之间通过 PCIe 总线通信。那么,两者是如何通过PCIE进行数据交换与通信的呢?接下来我们要介绍异构设备通过PCIE的通信流程。
2.1 PCIE通信原理
PCIE本质上是一种全双工的的连接总线,传输数据量的大小由通道数lane决定的。 一般, 1个连接通道
lane称为X1,每个通道lane由两对数据线组成, 一对发送, 一对接收。现在比较新的版本是PCIe是5.0的版本,速度可以做到32GB/s。在项目中,我们使用的是PCIE3.0的协议,速度大概为2.5GB/s。
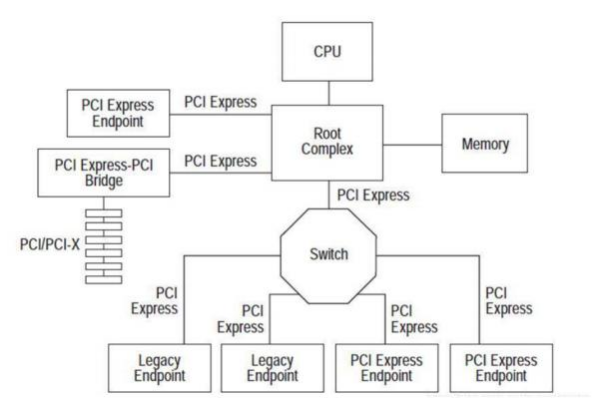
PCIE体系架构一般包含根组件RC( rootcomplex),交换器switch,终端设备EP( endpoint)等类型的PCIE设备组成。 RC在总线架构中只有一个,用于处理器和内存子系统与I/O设备之间的连接,而switch的功能通常是以软件形式提供的,它包括两个或更多的逻辑PCI到PCI的连接桥(PCI-PCI Bridge),以保持与现有PCI兼容,具体功能类似现在的网络交换机。
当总线上存在多种PCIE设备时,主机host会依照深度优先的算法对全部的设备树上的PCIE设备进行枚举查询,统称PCIE设备枚举。
一般来说,当系统上电后, host会自动查询PCIE设备枚举以获取总线拓扑结构。除一些特殊系统外,普通的系统只会在开机阶段进行设备的扫描,启动成功后,即枚举过程结束后,即使插入一个PCIE设备,系统也不会再去识别它。
2.2 PCIE的RC模式和EP模式配置
一般情况下,系统默认自己为RC模式,配置为EP模式的操作因设备而异,以地平线NPU为例,需要进行如下操作:
1. 连接NPU调试串口进入u boot
2. 执行如下命令:
| setenv fdt-blacklist "hobot,pcie-rc" setenv fdt-whitelist "hobot,pcie-ep" |
就本质而言,设置设备为ep模式,设备是进行了如下操作:
• 在 PCIE 设备的配置空间中,将类型值设置为 0,表示 EP 类型。 PCIE RC 设备的类型值为 1,表示 RC 类型
• 在 PCIE 设备的配置空间中,设置 BAR( Base Address Register)的大小和属性,用于分配 PCIE 设备的内存空间或 I/O 空间。 PCIE RC 设备可以通过 BAR(Base Address Register) 访问 PCIE EP 设备的内存或 I/O 资源
• 在 PCIE 设备的配置空间中,设置中断类型和中断号,用于向 PCIE RC 设备发送中断信号
• 在 PCIE 设备的控制器中,配置 Outbound 和 Inbound 的映射关系,用于实现 PCIE 设备和 PCIE RC 设备之间的数据传输。 Outbound 映射是指 PCIE 设备访问 PCIE RC 设备的内存空间, Inbound 映射是指 PCIE RC 设备访问 PCIE 设备的内存空间
总结为:修改配置空间描述、设置bar空间、设置映射空间、设置中断。
2.3 数据传输
在配置完成设备之后,下一步的工作就是检验RC端和EP端是否可以通信与数据传输,这里采用了一种非常传统的数据传输方式,即DMA数据传输。接下来一章节将重点介绍DMA数据传输的原理、优劣势、技术路线。
三、 DMA
DMA,全称Direct Memory Access,即直接存储器访问。 DMA传输将数据从一个地址空间复制到另一个地址空间,提供在外设和存储器之间或者存储器和存储器之间的高速数据传输。当CPU初始化这个传输动作,传输动作本身是由DMA控制器来实现和完成的。 DMA传输方式无需CPU直接控制传输,也没有中断处理方式那样保留现场和恢复现场过程,通过硬件为RAM和IO设备开辟一条直接传输数据的通道,使得CPU的效率大大提高。
以下介绍了DMA传输和传统内存数据拷贝的流程,比如我们需要将磁盘中的数据发送到网络,在没有任何优化技术使用的背景下,操作系统为此会进行 4 次数据拷贝,以及 4 次上下文切换,如下图所示:
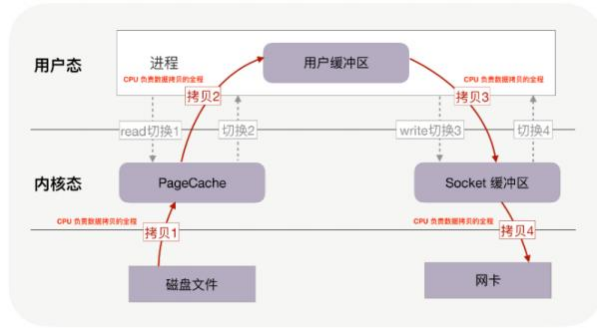 4 次 copy:
4 次 copy:
. 物理设备 <-> 内存:
CPU 负责将数据从内核空间的 Socket 缓冲区搬运到的网络中;
内存内部拷贝:
CPU 负责将数据从内核空间的 Page Cache 搬运到用户空间的缓冲区;
CPU 负责将数据从用户空间的缓冲区搬运到内核空间的 Socket 缓冲区中;
4 次上下文切换:
1. read 系统调用时:用户态切换到内核态;
2. read 系统调用完毕:内核态切换回用户态;
3. write 系统调用时:用户态切换到内核态;
4. write 系统调用完毕:内核态切换回用户态;
CPU 全程负责内存内部的数据拷贝还可以接受,因为内存的数据拷贝效率还行(不过还是比 CPU 慢很
多),但是如果要 CPU 全程负责内存与磁盘、 内存与网卡的数据拷贝,这将难以接受,因为磁盘、网卡的 I/O 速度远小于内存; 4 次copy 太多了, 4 次上下文切换也太频繁了;
这种方式不但耗时,而且极大地占用了CPU时间,影响系统性能,而且这种情景在操作系统中会频繁出
现,所以一种非常直观的想法就是将内存数据搬运的任务通过某种操作卸载到芯片上,将CPU解放出来。实际上, CPU作为系统的绝对运算单位,可以胜任绝大部分的运算操作,在不考虑性能的情况下,可以直接不外接任何硬件进行操作,所谓的软硬件优化的核心思想就是释放更多的CPU给用户。 DMA就完成了这部分的工作:
整个数据传输操作在一个 DMA 控制器的控制下进行的。 CPU 除了在数据传输开始和结束时做一点处理外(开始和结束时候要做中断处理),在传输过程中 CPU 可以继续进行其他的工作。这样在大部分时间
里,CPU 计算和 I/O 操作都处于并行操作,使整个计算机系统的效率大大提高。
引入DMA后,我们的数据拷贝流程就从图1变成了图2:
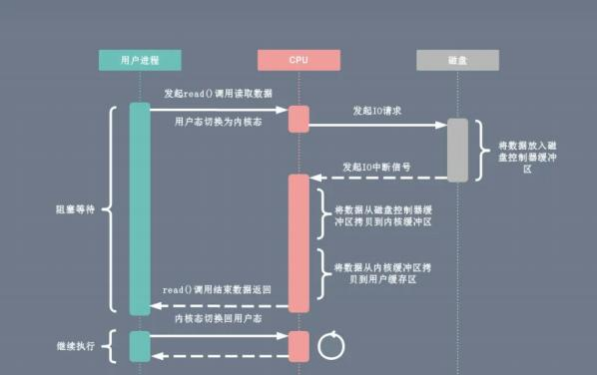
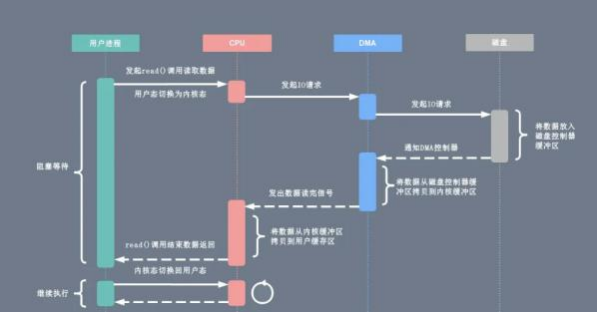
1. 用户进程向 CPU 发起 read 系统调用读取数据,由用户态切换为内核态,然后一直阻塞等待数据的返回。
2. CPU 在接收到指令以后对 DMA 磁盘控制器发起调度指令。
3. DMA 磁盘控制器对磁盘发起 I/O 请求,将磁盘数据先放入磁盘控制器缓冲区, CPU 全程不参与此过程。
4. 数据读取完成后, DMA 磁盘控制器会接受到磁盘的通知,将数据从磁盘控制器缓冲区拷贝到内核缓冲区。
5. DMA 磁盘控制器向 CPU 发出数据读完的信号, 由 CPU 负责将数据从内核缓冲区拷贝到用户缓冲区。
6. 用户进程由内核态切换回用户态,解除阻塞状态,然后等待 CPU 的下一个执行时间钟。
3.1 PCI Express DMA
PCI设备与存储器直接进行数据交换的过程也被称为DMA。与其他总线的DMA过程类似, PCI设备进行DMA操作时,需要获得数据传送的目的地址和传送大小。支持DMA传递的PCI设备可以在其BAR空间中设置两个寄存器,分别保存这个目标地址和传送大小。这两个寄存器也是PCI设备DMA控制器的组成部件。
值得注意的是, PCI设备进行DMA操作时,使用的目的地址是PCI总线域的物理地址,而不是存储器域的物理地址,因为PCI设备并不能识别存储器域的物理地址,而仅能识别PCI总线域的物理地址。简单来说cpu通过操控pci的bar空间,通过映射来实现对RAM等的读写操作。
DMA分为读和写种操作,两种操作在细节上不同。
这里先简单介绍一下DMA读过程:
1、驱动程序向操作系统申请一片物理连续的内存;
2、主机向该地址写入数据;
3、主机将这个内存的物理地址告诉NPU;
4、 NPU向主机发起读TLP请求—连续发出多个读请求;
5、主机向NPU返回CPLD包—连续返回多个CPLD;
6、 NPU取出CPLD包中的有效数据;
7、 NPU发送完数据后通过中断等形式通知主机DMA完成;
DMA写过程如下:
1、驱动程序向操作系统申请一片物理连续的内存;
2、主机将这个内存的物理地址告诉NPU;
3、 NPU向主机发起写TLP请求,并将数据放入TLP包中—连续发出多个写请求;
4、 NPU发送完数据后通过中断等形式通知主机DMA完成;
5、主机从内存中获取数据;
四、零拷贝技术、统一内存架构、 MMIO、字符设备
4.1 零拷贝
所谓零拷贝技术,是指计算机执行IO操作时, CPU不需要将数据从一个存储区域复制到另一个存储区域,从而可以减少上下文切换以及CPU的拷贝时间。它是一种 I/O 操作优化技术。
零拷贝并不是没有拷贝数据,而是减少用户态/内核态的切换次数以及CPU拷贝的次数。零拷贝实现有多种方式,分别是:
1. mmap+write
2. sendfile
3. 带有DMA收集拷贝功能的sendfile
4.1.1 mmap+write
mmap 的函数原型如下:
| void *mmap (void *addr, size_t length, int prot, int flags, int fd, off_t offset) ; |
. addr :指定映射的虚拟内存地址
. length:映射的长度
. prot:映射内存的保护模式
. flags:指定映射的类型
. fd:进行映射的文件句柄
. offset:文件偏移量
内核空间和用户空间的虚拟地址映射到同一个物理地址,从而减少数据拷贝次数。 mmap就是用了虚拟内存这个特点,它将内核中的读缓冲区与用户空间的缓冲区进行映射,所有的IO都在内核中完成。
mmap+write 实现的零拷贝流程如下:
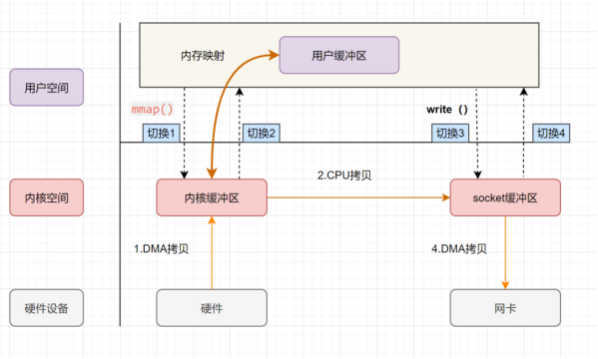
. 用户进程通过 mmap方法 向操作系统内核发起IO调用, 上下文从用户态切换为内核态。
下文从内核态切换回用户态, mmap方法返回。
· 用户进程通过 write 方法向操作系统内核发起IO调用, 上下文从用户态切换为内核态。
. CPU将内核缓冲区的数据拷贝到的socket缓冲区。
. CPU利用DMA控制器,把数据从socket缓冲区拷贝到网卡, 上下文从内核态切换回用户态, write调用返回。
可以发现, mmap+write 实现的零拷贝, I/O发生了4次用户空间与内核空间的上下文切换,以及3次数据拷贝。其中3次数据拷贝中,包括了2次DMA拷贝和1次CPU拷贝。
mmap 是将读缓冲区的地址和用户缓冲区的地址进行映射,内核缓冲区和应用缓冲区共享,所以节省了一次CPU拷贝,并且用户进程内存是虚拟的,只是映射到内核的读缓冲区,可以节省一半的内存空间。
4.1.2 sendfile
sendfile 是Linux2.1内核版本后引入的一个系统调用函数 ,API如下:
| ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count) ; |
. out_fd:为待写入内容的文件描述符, 一个socket描述符。,
. in_fd:为待读出内容的文件描述符,必须是真实的文件,不能是socket和管道。
. offset:指定从读入文件的哪个位置开始读,如果为NULL,表示文件的默认起始位置。
. count:指定在fdout和fdin之间传输的字节数。
sendfile表示在两个文件描述符之间传输数据, 它是在操作系统内核中操作的,避免了数据从内核缓冲区和用户缓冲区之间的拷贝操作,因此可以使用它来实现零拷贝。
sendfile实现的零拷贝流程如下:
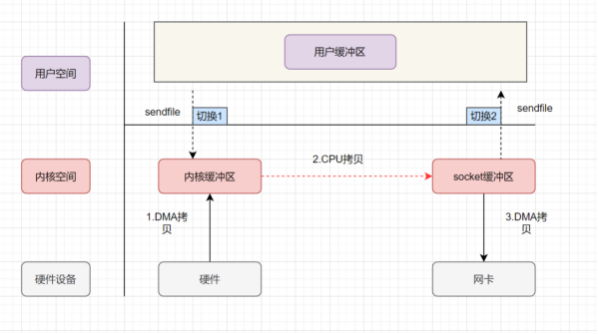
1. 用户进程发起sendfile系统调用, 上下文(切换1)从用户态转向内核态
2. DMA控制器,把数据从硬盘中拷贝到内核缓冲区。
3. CPU将读缓冲区中数据拷贝到socket缓冲区
4. DMA控制器,异步把数据从socket缓冲区拷贝到网卡,
5. 上下文(切换2)从内核态切换回用户态, sendfile调用返回。
可以发现, sendfile 实现的零拷贝, I/O发生了2次用户空间与内核空间的上下文切换,以及3次数据拷贝。其中3次数据拷贝中,包括了2次DMA拷贝和1次CPU拷贝。那能不能把CPU拷贝的次数减少到0次呢?有的,即带有DMA收集拷贝功能的sendfile。
4.1.3 sendfile+DMA scatter/gather实现的零拷贝
linux 2.4版本之后,对 sendfile 做了优化升级,引入SG-DMA技术,其实就是对DMA拷贝加入了
scatter/gather 操作,它可以直接从内核空间缓冲区中将数据读取到网卡。使用这个特点搞零拷贝,即还可以多省去一次CPU拷贝。
sendfile+DMA scatter/gather实现的零拷贝流程如下:
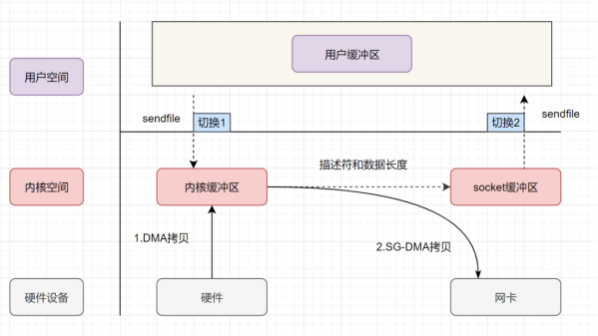
1. 用户进程发起sendfile系统调用, 上下文(切换1)从用户态转向内核态
2. DMA控制器,把数据从硬盘中拷贝到内核缓冲区。
3. CPU把内核缓冲区中的 文件描述符信息(包括内核缓冲区的内存地址和偏移量)发送到socket缓冲区
4. DMA控制器根据文件描述符信息,直接把数据从内核缓冲区拷贝到网卡
5. 上下文(切换2)从内核态切换回用户态, sendfile调用返回。
可以发现, sendfile+DMA scatter/gather 实现的零拷贝, I/O发生了2次用户空间与内核空间的上下文切换,以及2次数据拷贝。其中2次数据拷贝都是DMA拷贝。全程都没有通过CPU来搬运数据,所有的数据都是通过DMA来进行传输的。
4.2 统一内存架构( Unified Memory Architecture)
以上的数据传输都是基于对于不同外设、不同形式的数据进行数据拷贝和传输,进而做到所谓的零拷
贝,实际上,无论是基于外接硬件,还是基于零拷贝,其本质还是需要对数据进行处理或者映射,那有没有一种可能,我们无需进行任何的映射、搬运或者处理,就可以实现数据的直接访问呢?
答案是有可能的,前提是需要对内存中的数据进行规范化的排布,使其既可以被cpu访问,有可能被GPU或者其他外设进行良好地使用,根据Apple最新的分享,我们确实实现了这样的设计,即内存作为所有内置外设均可以直接访问的资源,这样,对于大部分外设来说,内存是一种可以直接访问或者经过一次映射既可访问的资源。因此尽快Macbook的显卡性能相对于A卡与N卡来说,没有与之对应的计算能力,但是其在人工智能领域、图形渲染的专业领域表现十分优秀,未来可期。
4.3 MMIO
MMIO(Memory mapping I/O)即内存映射I/O,它是PCI规范的一部分, I/O设备被放置在内存空间而不是I/O空间。从处理器的角度看,内存映射I/O后系统设备访问起来和内存一样。这样访问PCI设备就可以使用读写内存一样的汇编指令完成,简化了程序设计的难度和接口的复杂性。
IO地址空间:访问外部设备寄存器的地址区域
内存地址空间:访问memory的地址空间,包括了其他各种各样的ROM
PCIe总线中有两种MMIO: P-MMIO和NP-MMIO。 P-MMIO,即可预取的MMIO( Prefetchable MMIO); NP- MMIO,即不可预取的MMIO( Non-Prefetchable MMIO)。其中P-MMIO读取数据并不会改变数据的值。
0-1M:被分配成DOS Legacy Address Range ,其中还被细分为三个部分 可以从Datasheet查看
1M-TOLUD :被分配成Low Main Memory Address Range,这一部分主要是Main Memory,i也就是对应DRAM,但是在这段memory中间还有一些小小的地址被占用作他用,比如ISA Hole TSEG等,这些被占用的地址是极少部分,绝大部分都是被分配用在了memory上,所以这些地址大部分是可以直接被DRAM Controller访问找到对应的DRAM的
TOLUD-4G:被分配成为PCI Memory Address Range (MMIO Low),其中主要分了三个部分 Flash APCI等,
DMI Interface 和 PCIe Configuration Space 。这部分地址就是被MMIO所占用的,所以这部分地址就不能让DRAM Controller在DRAM上找到对应的位置了,因为这地址表示的就不是DRAM。
可以看到,在DRAM Controller的角度上,在4G以下,最重要的分割点就是TOLUD ,TOLUD以上都被用作了MMIO,那么这部分地址对应的memory就不能被访问,这样就造成了memory资源的浪费。其实在TOLUD以下,也是有部分被占用的地址,但是这部分都是很少的,不像MMIO部分,大块的内存被浪费掉。
TOLUD决定了4G以下能够使用的MMIO地址空间的大小,目前很多机器上,这个值都是能通过BIOS进行设置的。
在早期,计算机能够支持的内存很小,这时TOLUD的大小就是实际上DRAM的大小,这样4G-DRAM的部分就都能够用来进行MMIO,就算有大量的IO设备需要remapping,也不会浪费大量的memory,所以这种在4G下进行MMIO映射的规范就被保留了下来,但是随着内存的不断扩大, 4G以上内存早就屡见不鲜,
memory占用问题也就急需解决了。
4G以上的情况就比较容易了,主要分成了三个部分:
4G -TOUUD : Upper Main Memory Address Range, 这部分就比较容易理解,就是DRAM中超过4G的部分,所对应的地址。
TOUUD-TOUUD+X : Reclaim Address 对4G以下MMIO占用部分内存的重新映射,利用这部分地址就能够重新利用之前浪费掉的地址空间。
TOUUD+X- MAX range : MMIO High 这部分都可以用来作为PCI E MMIO 的地址了 并且利用这部分地址也不会再占用内存地址造成内存空间的浪费了。
4.4 字符设备
字符设备是一种在Unix/Linux系统中用于与设备进行通信的设备类型之一。字符设备以字符为单位进行输入和输出操作,而不是以块为单位。在字符设备中,数据是按字符流的形式进行传输的,没有固定的大小限制。
字符设备通常用于表示串口、终端、键盘、鼠标等设备,这些设备以字符流的形式进行通信。用户可以通过读取和写入字符设备文件来与这些设备进行交互。
在Linux系统中,字符设备通过字符设备文件来表示,通常位于 /dev 目录下。用户可以通过打开、读取、写入和关闭字符设备文件来与字符设备进行通信。
总的来说,字符设备是一种用于按字符流进行输入和输出操作的设备类型,常用于表示串口、终端等设备,在Linux系统中通过字符设备文件进行访问和控制。
五 、 MSI/MSI-X中断
MSI( Message Signaled Interrupts)是一种中断机制,它允许设备通过写入特定的内存地址来触发中断,而不是使用传统的线路中断,这样可以提高效率并减少资源占用。 MSI-X( Message Signaled Interrupts
eXtended)是MSI的扩展,它支持更多的中断向量和更高的可编程性,允许每个PCI Function支持多个中断向量,这对于需要处理多个不同中断请求的设备来说非常有用。
为了方便之后的驱动介绍,我们需要补充一部分PCIe中断的知识,这里只是浅显地介绍一下MSI与MSIX中断。
5.1MSI/MSI-X概述
MSI , message signal interrupt, 是PCI设备通过写一个特定消息到特定地址,从而触发一个CPU中断。特定消息指的是PCIe总线中的Memory Write TLP, 特定地址一般存放在MSI capability中。
MSI中断有以下几个优点:
1. 基于引脚的传统中断会被多个设备所共享,中断共享时,如果触发了中断, linux需要一一调用对应的中断处理函数,这样会有性能上的损失,而MSI不存在共享的问题。
2. 设备向内存写入数据,然后发起引脚中断, 有可能会出现CPU收到中断时,数据还没有达到内存。而使用MSI中断时,产生中断的写不能越过数据的写,驱动可以确信所有的数据已经达到内存。
3. 多功能的PCI设备,每一个功能最多只有一个中断引脚,当具体的事件产生时,驱动需要查询设备才能知道是哪一个事件产生,这样会降低中断的处理速度。而一个设备可以支持32个MSI中断,每个中断可以对应特定的功能。
MSI-x是MSI的扩展和增强。 MSI有它自身的局限性, MSI最多支持32个中断,且要求中断向量连续, 而MSI- x没有这个限制,且支持的中断数量更多。此外, MSI-X的中断向量信息并不直接存储在capability中,而是在一块特殊Memory中.
MSI和MSI-X的规格对比:
| MSI | MSI-X | |
| 中断向量数 | 32 | 2048 |
| 中断号约束 | 必须连续 | 可以随意分配 |
| MSI信息存放 | capability寄存器 | MSI-X Table(BAR空间) |
总之, PCIe设备在提交MSI中断请求时,都是向MSI/MSI-X Capability结构中的Message Address的地址写Message Data数据,从而组成一个存储器写TLP,向处理器提交中断请求。
5.2 MSI/MSI-X中断报文
根据PCIe规范的定义, MSI/MSI-X中断请求发生时, PCIe设备会实际产生1个Memory Write Transaction。它对应的数据封包为Memory Write类型的Trasaction Layer Packet(TLP),其格式如下图所示(对MSI-X也同样适用)。其中目标Memory Address称为“Message Address” ,要写入该内存地址的数据称为 “Message Data”。这两个字段都来自MSI/MSI-X Capability Structure中的设定,系统软件在Enable并初始化MSI/MSI-X的过程中必须要预先设置好它们。
5.3 MSI/ MSI-X Capability Structure
PCI/PCIe设备通过在其PCI Configuration Space中实现MSI/MSI-X Capability Registers来向系统软件表明是否支持MSI/MSI-X。 MSI/MSI-X Capability Registers属于传统的Basic PCI Capability Structure,其组成包括:
. 标准的Basic PCI Capability Header (1-byte Capability ID + 1-byte Next Cpability Pointer)
. Capability-specific Registers (根据Capability ID不同而变化,但从功能角度来看都包含如下要素:
Vector Masking & Pending Status: 用来屏蔽MSI/MSI-X中断请求并反映中断Pending状态)
六、 NPU ep驱动代码分析
完以上基础知识以后,现在可以分析NPU的ep驱动代码了。根据驱动与之前介绍的知识,我们大致推测整个设备的工作流程如下:
1. 初始化阶段:
驱动加载时,进行初始化操作,包括初始化设备结构体、注册字符设备、初始化PCI设备等。
初始化MSI地址和数据,根据PCI配置空间中的信息更新MSI地址和数据。
2. 中断处理与DMA传输阶段:
在中断处理函数中,根据中断来源执行相应的操作,可能包括读取或写入寄存器、处理DMA传输等。
3. ioctl通信阶段:
处理用户空间和内核空间之间的通信,通过ioctl命令执行相应的操作,如初始化设备、进行DMA读写操作等。
4. 设备移除阶段:
当需要移除设备时,执行设备移除函数,释放资源、注销字符设备等操作。
根据流程我们开始分析函数的实现与功能:
6.1初始化阶段
初始化阶段由 hobot_ep_drv_probe 进行探测,如果探测到设备,则由该探测函数负责初始化HOBOT EP设备结构体、 PCI设备、 EP设备以及字符设备,并根据需要启用或禁用STL功能。如果初始化过程中出现错误,则会逐级释放资源并返回-1表示探测失败。
ho bot_ep_drv_probe
hdev_init:初始化HOBOT EP结构体
pdev_init:初始化PCI设备
pci_set_drvdata:将HOBOT EP设备结构体指针 hdev 保存到PCI设备的私有数据中
pcim_enable_device:启用PCI设备
pci_request_regions :请求PCI设备的资源区域
pci_set_master :启用PCI设备的总线主控制器功能
pci_set_consistent_dma_mask:设置PCI设备的DMA掩码为64位
pci_save_state:保存PCI设备的状态信息ep_dev_init:初始化EP设备
bar_map:映射EP设备的BAR资源
msi_alloc :分配MSI中断资源
irq_vectors_alloc:为HOBOT EP设备分配中断向量,并设置设备的中断处理机制ep_dmac_init:初始化EP设备的DMAC
reserved_bar_init:初始化EP设备的保留BAR
chrdev_alloc:为HOBOT EP设备分配和初始化字符设备
6.1.1主要逻辑代码分析
bar_map
函数 bar_map 用于映射EP设备的BAR( Base Address Register)资源,主要进行了如下操作:
1. 遍历EP设备的所有BAR:通过循环遍历6个BAR,获取每个BAR的起始地址、结束地址、标志和大小,并打印相关信息。
2. 检查BAR的起始地址和结束地址是否正常:如果BAR的起始地址或结束地址为0,则记录异常信息并跳过该BAR的映射。
3. 映射BAR资源:对于不是第1和第3个BAR(i=1和i=3),调用 pcim_iomap 函数将BAR映射到内存空间。如果映射失败,则记录错误信息并返回-1表示映射失败。
4. 保存BAR的大小和物理地址:保存成功映射的BAR的大小、物理地址和虚拟地址。
5. 检查必要的BAR是否成功映射:检查BAR0和BAR2是否成功映射,如果有任何一个映射失败,则记录错误信息并返回-1表示映射失败。
6. 设置DMA寄存器基地址和保留BAR EP物理地址:根据映射成功的BAR设置DMA寄存器基地址和保留BAR EP物理地址。
irq_vectors_alloc
irq_vectors_alloc 函数用于为HOBOT EP设备分配中断向量,并设置设备的中断处理机制。以下是 irq_vectors_alloc 函数的主要功能和步骤:
1. 变量初始化:初始化变量 i
2. MSI中断向量分配:
1. 尝试首先分配MSI中断向量,如果成功则打印分配的向量数量
2. 如果MSI分配失败,则尝试分配MSI-X中断向量。
3. 如果MSI-X分配成功,则打印分配的向量数量; 如果失败,则记录错误信息并返回-1表示分配失败。
4. 获取中断向量:对于每个分配的中断向量,通过 pci_irq_vector 函数获取中断向量号。
5. 错误处理:如果获取中断向量失败,则记录错误信息并释放已分配的中断向量,然后返回-1表示分配失败。
ep_dmac_init
ep_dmac_init 函数是HOBOT EP设备中用于初始化DMA控制器的函数,用于初始化DMA控制器,包括设置DMA引擎、清除中断掩码等操作,函数通过循环遍历DMA通道,为每个通道设置中断处理,以确保DMA控制器正常工作:
1. 变量初始化:初始化变量 i 和 dev
2. 重置DMA寄存器:通过 dma_reg_writel 函数分别将DMA写引擎和读引擎的使能位清零,实现DMA寄存器的重置
3. 延时处理:通过 udelay 函数进行延时处理,等待DMA控制器重置完成
4. 清除中断掩码:将DMA写引擎和读引擎的中断掩码清零,以确保中断能够被触发
5. 设置中断处理:通过循环遍历DMA通道,调用 ep_dma_set_irq 函数为每个通道设置中断处理
6. 错误处理:如果设置DMA中断处理失败,则记录错误信息并返回-1表示初始化失败
reserved_bar_init
reserved_bar_init 函数用于初始化HOBOT EP设备的保留BAR,包括写入总线ID和设备ID、 BAR PCI地址,设置设备状态、清除通道分配信息以及设置DMA缓冲区信息等操作。函数确保设备的保留BAR正确初始化,
以支持设备的正常运行
1. 变量初始化:初始化变量 ret 、 bar_id 、 reg 、 val ,声明指向PCI设备和设备结构的指针 pdev和 dev 。
2. 写入总线ID和设备ID到bar2 :将PCI设备的总线ID和设备ID分别写入保留BAR的 ep_bus_id 和 ep_dev_id 字段,设备功能ID设置为0。
3. 写入BAR PCI地址:循环遍历6个BAR,将每个BAR的PCI地址( bar_phys )写入保留BAR的 bar_pci_addrs 数组中,并通过 dev_dbg 函数打印BAR的PCI地址。
4. 备份MSI信息:遍历MSI寄存器,通过 pci_read_config_dword 函数读取MSI信息并备份到保留BAR的 msi_backup 数组中。
5. 设置设备状态:将设备状态设置为ENUMED,表示设备已枚举。
6. 清除通道分配信息:将保留BAR中的通道分配信息 rc_chan_alloc 和 rc_recv_installed 清零,表示未分配通道和未安装接收。
7. 写入DMA缓冲区信息:将DMA缓冲区的大小和物理地址写入保留BAR的 rc_dma_buf_size 和 rc_dma_buf_phys 字段。
6.2 中断处理与DMA传输阶段
驱动通过 devm_request_irq 将 hobot_ep_msi_handler 函数注册为中断处理函数,实现了对HOBOT EP设备的MSI中断的处理逻辑,通过注册为中断处理函数并在中断发生时被调用,完成相应的中断处理操作,然后返回给系统继续执行:
1. 识别中断来源:通过参数 irq 确定中断的来源,即特定的中断号。
2. 查找对应的MSI(-X) ID :根据中断号查找对应的MSI(-X) ID,以确定具体的中断来源。
3. DMA处理:可能会涉及DMA相关的操作,如读取或写入DMA通道的数据。
4. UIRQ发送:可能会将UIRQ发送给用户空间,通知用户空间发生了特定的事件。
5. 设备操作:可能会执行与HOBOT EP设备相关的操作,如读取寄存器状态、写入控制命令等。
6. 返回适当的中断处理结果:处理完中断后,通常会返回 IRQ_HANDLED 表示中断已经被处理。 hobot_ep_msi_handler
dma_handler :处理DMA相关的中断事件
wait_ep_clear_int :等待DMA中断状态被清除
bar2_readl :从指定的BAR地址中读取数据
check_write_chan :检查写通道的状态,处理写通道的中断或数据传输完成等情况| uirq_handler :处理用户中断请求
notify_handler :实现通知机制,将数据传递给相应的处理程序
6.2.1主要逻辑代码分析
wait_ep_clear_int
wait_ep_clear_int 函数用于等待DMA中断状态被清除,以确保在进行下一步DMA操作之前, DMA写入和读取的中断状态已经被处理完毕。
1. 等待DMA中断状态清除:使用循环结构不断检查DMA写入和读取的中断状态,直到两者的中断状态都被清除为止。
2. 读取DMA中断状态:通过读取DMA写入和读取的中断状态寄存器,获取当前的中断状态。
3. 超时处理 :设置超时时间,如果在超时时间内中断状态未被清除,则进行超时处理。
4. 日志记录:使用 dev_err 函数记录日志信息,以便在出现超时或其他异常情况时进行错误处理。
5. 返回适当的处理结果:根据中断状态是否清除,返回相应的处理结果,通常是返回0表示中断状态已清除。
6. 使用jiffies进行时间比较:使用 jiffies 和 time_after 函数进行时间比较,以判断是否超过了设定的超时时间。
7. DMA寄存器读取:通过 dma_reg_readl 函数读取DMA写入和读取的中断状态寄存器的值。
bar2_readl
bar2_readl 函数用于从指定的BAR地址中读取数据,根据内核的config,可能会通过DMA进行数据读取操作,也可能直接读取数据:
1. 确定读取的地址:根据传入的参数确定要读取的地址,通过计算偏移量来确定在特定的BAR中的地址
2. 使用DMA进行读取:会根据系统配置情况,选择使用DMA进行数据的读取操作,以提高读取效率
3. 调用DMA读取函数:调用DMA读取函数从指定地址读取数据
4. 处理读取结果:获取从指定地址读取的数据,并返回给调用者
5. 返回读取结果:将读取的数据返回给调用者
check_write_chan
check_write_chan 函数用于检查写通道的状态,处理写通道的中断或数据传输完成等情况,并根据情况进行相应的处理:
1. 读取写通道状态:使用 bar2_readl 函数从寄存器中读取写通道的状态。
2. 检查写通道状态:
1. 根据读取到的状态值进行不同的处理:
1. 如果状态为DMA_EP_TRIGGERD,则执行以下操作:
1. 如果启动了DMA传输,则记录时间戳(如果启用了时间戳统计)。
2. 调用 notify_receiver 函数通知接收器处理数据,如果通知成功则将写通道状态设置为 DMA_HANDSHAKE_OK ,否则设置为 DMA_RECV_FIFO_FULL 。
2. 如果状态为 DMA_EP_TEST_TRIGGERD ,则将写通道状态设置为 DMA_HANDSHAKE_OK 。
3. 否则,使用 complete 函数完成写通道的传输。
3. 增加写通道计数:如果启用了DMA计数功能,则增加写通道的计数值。
u irq_handler
uirq_handler 函数用于处理用户中断请求,通过读取用户中断请求ID并调用 notify_handler 函数进行处理,最终更新用户中断请求ID的状态:
1. 读取用户中断请求ID:使用 bar2_readl 函数从寄存器中读取用户中断请求ID。
2. 调用 notify_handler 函数:将读取到的用户中断请求ID传递给 notify_handler 函数进行处理。
3. 处理通知结果:如果 notify_handler 函数返回0 (表示通知成功),则将用户中断请求ID设置为 UIRQ_HANDSHAKE_OK ;否则将用户中断请求ID设置为 UIRQ_RECV_FIFO_FULL 。
4. 更新用户中断请求ID :根据通知结果更新用户中断请求ID的状态。
notify_handler
notify_handler 函数用于向指定ID的处理程序发送通知数据, 确保通知数据被正确处理;
1. 准备通知数据:在结构体 hobot_pcie_cmd_uirq_data 中设置通知的ID。
2. 加锁:使用 spin_lock_irqsave 函数获取锁,以确保在处理通知数据时不会被其他操作干扰。
3. 检查处理程序是否已安装:检查指定ID的处理程序是否已经安装,如果未安装则记录警告信息并返回。
4. 将通知数据写入FIFO:使用 kfifo_in 函数将通知数据写入到相应的FI FO队列中,以便处理程序读取。
5. 唤醒等待队列 :如果有进程或线程在等待通知数据,唤醒相应的等待队列。
6. 解锁资源:在处理完通知数据后,使用 spin_unlock_irqrestore 函数释放锁,允许其他操作对资源进行访问。
notify_receiver
notify_receiver 函数用于向指定通道的接收器发送DMA数据,确保数据被正确写入到FI FO队列中,并进行相应的处理:
1. 加锁:使用 spin_lock_irqsave 函数获取锁,以确保在处理通知数据时不会被其他操作干扰。
2. 检查接收器是否安装:检查指定通道的接收器是否已经安装,如果未安装则记录警告信息并返回成功。
3. 获取DMA元素:调用 get_dma_elements 函数获取指定通道的DMA元素数据。
4. 将数据写入FIFO:使用 kfifo_in 函数将获取到的DMA数据写入到相应的FI FO队列中。
5. 处理写入结果:
1. 如果成功写入数据,则增加DMA计数(如果启用)、记录时间戳(如果启用)、标记通道等待数据并唤醒等待队列。
2. 如果写入失败(FI FO已满),记录警告信息并返回错误。
6. 解锁资源:在处理完通知数据后,使用 spin_unlock_irqrestore 函数释放锁,允许其他操作对资源进行访问。
6.3ioctl通信阶段
hobot_ep_drv_ioctl 函数是一个关键的IO控制函数,根据不同的命令来执行不同的设备操作,包括初始化、 DMA传输、通道管理、接收器安装、中断处理等功能:
hobot_ep_drc_ioctl :执行传入命令
HOBOT_PCIE_IOC_INIT :io control初始化命令
HOBOT_PCIE_IOC_DEINIT :取消初始功能(直接break ,内部没有逻辑)
HOBOT_PCIE_IOC_CHAN_REQUEST :请求通道
HOBOT_PCIE_IOC_CHAN_RELEASE :释放通道
down_interruptible :阻塞当前进程并等待信号
cmd_release_chan_process :释放通道逻辑实现
HOBOT_PCIE_IOC_DMA_WRITE : DMA写
ep_status_check :检查设备状态
copy_from_user :从useraspace拷贝数据
ep_dma_ll_xfer :DMA传输实现
HOBOT_PCIE_IOC_DMA_READ : DMA读
ep_status_check :检查ep设备状态
copy_from_user :从useraspace拷贝数据 HOBOT_PCIE_IOC_PRE_CHECK :
ep_status_check :检查ep设备状态
HOBOT_PCIE_IOC_INSTALL_RECEIVER :加载接收器
cmd_install_receiver_process :处理安装接收器的逻辑
HOBOT_PCIE_IOC_UNINSTALL_RECEIVER :
down_interruptible :阻塞当前进程并等待信号
copy_from_user :从useraspace拷贝数据
cmd_uninstall_receiver_process :处理卸载接收器
HOBOT_PCIE_IOC_INSTALL_IRQ :安装中断请求处理程序
cmd_install_handler_process : IRQ 处理程序逻辑实现 HOBOT_PCIE_IOC_UNINSTALL_IRQ :卸载中断处理程序
cmd_uninstall_handler_process :卸载IRQ处理程序逻辑实现
HOBOT_PCIE_IOC_GET_BAR_INFO :获取Hobot PCIe驱动程序中BAR的相关信息
HOBOT_PCIE_IOC_REMOTE_RECV_EXIST :远程接收器存在性检查
down_interruptible :阻塞当前进程并等待信号
copy_from_use :从useraspace拷贝数据
cmd_check_receiver_process :检查远程接收的存在性
HOBOT_PCIE_IOC_BAR_READ_VIA_DMA :通过DMA进行BAR读取
ep_dma_ll_set_regs :设置DMA的寄存器
ep_dma_ll_set_elements :设置DMA的元素
ep_dma_ll_set_abort_reg :设置DMA的控制寄存器
ep_dma_ll_set_addr_reg :设置DMA的地址寄存器 HOBOT_PCIE_IOC_GET_RBAR_ID :获取RBAR的ID
copy_from_user :从useraspace拷贝数据
bar2_readq :读取RBAR的物理地址
copy_to_user :将 cmd_data 复制回用户空间
6.3.1主要逻辑代码分析
HOBOT_PCIE_IOC_INIT:
1. 调用 down_interruptible(&hdev->opsem) 来获取 opsem 信号量的所有权,如果获取失败(返回值不为0),则记录错误并返回 -HOBOT_PCIE_ERR_INTERRUPTTED 。
2. 使用 copy_from_user 从用户空间复制数据到 cmd_data 结构体中,如果复制失败( copy_ret 不为
0),则记录错误,释放信号量并返回 -HOBOT_PCIE_ERR_MEM_COPY 。
3. 调用 cmd_init_process(uinfo, &cmd_data.init) 来初始化一个进程,如果初始化过程中出现错误( ret 不为0),则释放信号量并返回错误码。
4. 将更新后的 cmd_data 结构体通过 copy_to_user 复制回用户空间,如果复制失败,则记录错误,释放信号量并返回 -HOBOT_PCIE_ERR_MEM_COPY 。
5. 释放 opsem 信号量并结束该操作。
HOBOT_PCIE_IOC_CHAN_REQUEST:
1. 获取信号量 opsem 的所有权,以确保在请求通道过程中不会被其他进程中断。
2. 从用户空间复制数据到 cmd_data 结构体中,这些数据将用于请求通道的操作。
3. 调用 cmd_request_chan_process 函数来处理请求通道的逻辑,传递用户信息和通道请求数据。
4. 释放信号量 opsem ,表示请求通道操作已完成。
cmd_release_chan_process
将 uinfo->chan_alloc 从 chan_alloc 中清除,并将更新后的 chan_alloc 写回硬件寄存器,释放通道:
1. 阻止并发访问:使用自旋锁保护 hdev->chan_alloc_lock ,
2. 读取 hdev->rbar->rc_chan_alloc 寄存器的值
3. 将 uinfo->chan_alloc 按位与取反操作符与 chan_alloc 按位与操作符进行运算,将 uinfo- >chan_alloc 从 chan_alloc 中清除
4. 将更新后的 chan_alloc 值写回 hdev->rbar->rc_chan_alloc 寄存器
5. 将 uinfo->chan_alloc 置为0
6. 释放自旋锁
ep_status_check
ep_status_check函数对PCIe设备进行一系列状态检查,并根据检查结果返回相应的状态码:
1. 从 hdev 结构体中获取设备信息
2. 调用 link_up_check 函数检查PCIe连接状态。如果连接未就绪(返回值非0),则使用 dev_err_ratelimited 宏记录错误信息
link_up_check
用于检查PCIe设备的链接状态,如果链接未就绪或者在检查过程中遇到错误,函数会返回错误码-1。如果链接已经就绪,函数返回0,函数的主要步骤如下:
1. 使用 pci_find_capability 查找 Express Capability
2. 如果找不到,记录错误信息,并返回-1
3. 如果找到了 Express Capability 结构,函数会尝试读取位于偏移量offset加上PCI_EXP_LNKSTA的寄存器值到变量 val 中
4. 如果读取寄存器失败,记录错误信息并返回-1
5. 如果读取成功,检查PCI_EXP_LNKSTA_LT。如果该位为0,表示链接已经就绪,函数返回0
6. 如果PCI_EXP_LNKSTA_LT不为0,表示链接未就绪,函数返回-1
cmd_ install_receiver_process
cmd_install_receiver_process 在PCIe设备驱动中为特定通道安装接收器,确保每个通道只能安装一个接收器,并维护用户进程与硬件状态之间的同步,使用自旋锁确保这些操作是原子的,避免了并发访问问题:
1. 初始化变量:定义了指向 hobot_ep_dev 结构体的指针 hdev ,用于记录接收器安装状态的recv_installed ,以及用于保护临界区的自旋锁变量 flags
2. 加锁:使用 spin_lock_irqsave 宏来锁定 chan_alloc_lock 自旋锁,并保存当前的中断状态到flags变量中,保证修改共享资源时防止中断和其他核心的干扰
3. 检查接收器是否已安装:检查 hdev->receiver_installed[channel_id] 的值来确定指定通道的接收器是否已经安装。为0,表示还没有安装接收器。
4. 安装接收器:如果接收器未安装,函数会记录安装接收器的进程ID,设置等待队列和条件变量,然后更新硬件寄存器来标记接收器已安装,并重置对应通道的FI FO缓冲区。
5. 更新硬件寄存器:通过 bar2_readl 函数读取硬件寄存器的当前值,然后将对应通道的位设置为1,最后将更新后的值写回寄存器。
6. 清理FI FO:使用 kfifo_reset 函数重置对应通道的FI FO缓冲区,清除里面的所有数据。
7. 接收器已安装的错误处理:如果检查发现接收器已经安装,函数会记录错误信息,并释放之前获得的自旋锁,然后返回错误码-HOBOT_PCIE_ERR_RECEIVER_EXIST。
8. 解锁:无论接收器是否安装成功,最后都会执行 spin_unlock_irqrestore 宏来释放自旋锁,并恢复之前保存的中断状态。
9. 返回结果:如果接收器成功安装,函数返回0;如果接收器已存在,返回错误码。
cmd_uninstall_receiver_process
cmd_uninstall_receiver_process 用于卸载PCIe设备驱动中特定通道的接收器, 只有安装接收器的进程才能卸载,其具体流程为:
1. 获取设备和锁定资源:通过用户信息结构体 uinfo 获取到PCIe设备结构体 hdev 和设备dev。然后使用 spin_lock_irqsave 宏锁定 chan_alloc_lock 自旋锁,并保存当前的中断状态到flags变量中,以保护通道分配数据结构。
2. 检查接收器所有权:函数检查指定通道的接收器是否由当前进程安装,通过比较 hdev-
>receiver_installed[channel_id] 和 uinfo->pid ,如果不匹配,表示当前进程不拥有该通道的接收器。
3. 错误处理:如果当前进程不拥有接收器,函数会记录错误信息,解锁之前获得的自旋锁,并恢复中断状态,然后返回错误码-HOBOT_PCIE_ERR_HANDLER_NOT_OWN。
4. 卸载接收器:如果当前进程拥有接收器,函数会将 hdev->receiver_installed[channel_id] 设置为
0,清除等待队列和条件变量的指针,并将用户信息中的 receiver_installed 标记为0。
5. 更新硬件寄存器:函数读取硬件寄存器 rc_recv_installed 的当前值,清除对应通道ID的位,然后将更新后的值写回寄存器。
6. 解锁:最后,函数使用 spin_unlock_irqrestore 宏释放之前获得的自旋锁,并恢复中断状态
cmd_ instal l_handler_process
cmd_install_handler_process 的函数为PCIe设备驱动中为特定的MSI安装处理程序,其具体流程如下:
1. 初始化变量:函数开始时,通过 uinfo 获取到PCIe设备结构体 hdev 和设备 dev 。然后定义了一个flags变量用于保存中断状态。
2. 加锁:使用 spin_lock_irqsave 宏锁定 handler_alloc_lock 自旋锁,并保存当前的中断状态到flags变量中。这是为了在修改共享资源时防止中断和其他核心的干扰。
3. 检查处理程序是否已安装:通过检查 hdev->handler_installed[msi_id] 的值来确定指定MSI的处理程序是否已经安装。如果这个值为0,表示还没有安装处理程序。
4. 安装处理程序:如果处理程序未安装,函数会记录安装处理程序的进程ID,设置等待队列和条件变量,然后将用户信息中的 handler_installed[msi_id] 标记为1。
5. 错误处理:如果检查发现处理程序已经安装,函数会记录错误信息,解锁之前获得的自旋锁,并恢复中断状态,然后返回错误码-HOBOT_PCIE_ERR_HANDLER_EXIST。
6. 解锁:无论处理程序是否安装成功,最后都会执行 spin_unlock_irqrestore 宏来释放之前获得的自旋锁,并恢复中断状态。
7. 返回结果:如果处理程序成功安装,函数返回0;如果处理程序已存在,返回错误码。
cmd_uninstal l_handler_process
用于卸载PCIe设备驱动中特定MSI,只有安装处理程序的进程才能卸载它,函数流程如下:
1. 初始化变量:函数开始时,通过用户信息结构体 uinfo 获取到PCIe设备结构体 hdev 和设备dev。 ret变量被初始化为0,用于存储函数的返回值。
2. 加锁:使用 spin_lock_irqsave 宏锁定 handler_alloc_lock 自旋锁,并保存当前的中断状态到flags变量中。这是为了在修改共享资源时防止中断和其他核心的干扰。
3. 检查处理程序所有权:函数检查指定MSI的处理程序是否由当前进程安装。这是通过比较 hdev-
>handler_installed[msi_id] 和 uinfo->pid 来实现的。如果不匹配,表示当前进程不拥有该MSI的处理程序。
4. 错误处理:如果当前进程不拥有处理程序,函数会记录错误信息,解锁之前获得的自旋锁,并恢复中断状态,然后将ret设置为错误码-HOBOT_PCIE_ERR_HANDLER_NOT_OWN。
5. 卸载处理程序:如果当前进程拥有处理程序,函数会将 hdev->handler_installed[msi_id] 设置为
0,清除等待队列和条件变量的指针,并将用户信息中的handler_installed[msi_id]标记为0。
6. 解锁:最后,函数使用 spin_unlock_irqrestore 宏释放之前获得的自旋锁,并恢复中断状态。
7. 返回结果:函数返回ret变量的值,如果处理程序成功卸载, ret为0;如果当前进程不拥有处理程序, ret为错误码。
cmd_check_receiver_process
cmd_check_receiver_process 用于检查远程接收器在PCIe设备驱动中的安装状态,其具体流程如下:
1. 获取设备信息:函数通过 uinfo 参数获取到PCIe设备结构体 hdev 和设备 dev 。
2. 读取接收器状态:使用 bar2_readl 函数从硬件寄存器 ep_recv_installed 读取远程接收器的安装状态。
3. 记录状态:使用 dev_dbg 宏记录远程接收器的状态。这条信息仅在内核调试时输出,帮助开发者了解当前的接收器状态。
4. 检查指定通道的接收器:函数检查特定通道的接收器是否已安装。这是通过将receiver_status与通道ID对应的位进行与操作来实现的。如果结果为0,表示该通道的远程接收器未安装。
5. 返回结果:如果指定通道的远程接收器未安装,函数返回错误码-
HOBOT_PCIE_ERR_REMOTE_RECV_NOT_EXIST。如果已安装,函数返回0。
ep_dma_ ll_x fer
用于执行PCIe设备的DMA,其具体流程如下:
1. 初始化变量:函数开始时,定义了返回值ret ,互斥锁指针mutex,完成量comp,以及从设备结构体hdev中获取的设备dev。还有一个chan变量,表示数据传输的通道。
2. 选择互斥锁和完成量:根据传输方向dirc(读或写),选择相应通道的读或写互斥锁和完成量。
3. 锁定互斥锁:尝试锁定互斥锁。如果锁定被中断,记录警告信息并返回错误码- HOBOT_PCIE_ERR_INTERRUPTTED。
4. 检查DMA状态:调用ep_dma_get_status函数检查指定通道的DMA状态。如果DMA正在运行,则记录警告信息,解锁互斥锁,并返回错误码-HOBOT_PCIE_ERR_DMA_XFER_ABORTED。
5. 重新初始化完成量:使用reinit_completion函数重新初始化完成量,为新的DMA传输做准备。
6. 设置DMA触发状态:根据传输方向,设置读或写通道的状态为触发状态。
7. 设置DMA寄存器:调用ep_dma_ll_set_regs函数设置DMA传输的相关寄存器,包括权重、传输方向、元素大小和元素数量。
8. 增加DMA传输计数(如果启用):如果启用了DMA传输计数,增加对应通道的计数。
9. 记录DMA时间戳(如果启用):如果启用了DMA时间戳统计,并且传输方向为读,记录时间戳。
10. 触发DMA传输:调用ep_dma_set_doorbell函数触发DMA传输。
11. 等待DMA完成:调用ep_dma_wait_done函数等待DMA传输完成,并获取结果。
12. 解锁互斥锁:完成DMA传输后,解锁之前获得的互斥锁。
13. 返回结果:函数返回DMA传输的结果,如果成功,返回0;如果有错误,返回相应的错误码。
ep_dma_ ll_ set_re gs
设置PCIe设备的DMA传输所需的一系列寄存器,其具体流程如下:
1. 设置DMA元素:调用 ep_dma_ll_set_elements 函数,为指定通道配置DMA传输的元素列表 ele_list 和元素数量 ele_nr 。配置DMA传输的源地址和目标地址,以及传输的数据大小。
2. 设置DMA中止寄存器:调用 ep_dma_ll_set_abort_reg 函数,设置DMA中止寄存器.
3. 设置DMA控制寄存器:调用 ep_dma_ll_set_ctrl_reg 函数,设置DMA控制寄存器
4. 设置DMA地址寄存器:调用 ep_dma_ll_set_addr_reg 函数,设置DMA地址寄存器,用于指定DMA传输的源地址和目标地址。
5. 设置DMA权重:调用 ep_dma_set_wei 函数,为指定通道和传输方向设置权重wei,用于调整不同DMA通道之间的传输优先级
ep_dma_ l l_ set_elements
配置PCIe设备的DMA描述符,以准备进行数据传输,函数具体流程如下:
1. 选择描述符数组:根据传输方向dirc(读或写) ,选择对应通道的读或写DMA描述符数组。
2. 配置描述符:遍历每个DMA元素,为每个描述符设置控制字段、大小、源地址和目标地址。
3. 中断使能:对于最后一个DMA元素,启用完成中断和链路中断,以便在传输完成时通知CPU。
4. 调试信息:输出每个描述符的配置信息
5. 清零控制字段:在配置完所有描述符后,将最后一个描述符的控制字段清零
ep_dma_ ll_ set_abort_reg
设置PCIe设备的DMA传输的中止寄存器,根据需要启用或禁用特定通道的本地和远程DMA中止功能,其具体流程如下:
1. 确定中止寄存器:根据传输方向dirc(读或写) ,选择相应的中止寄存器偏移量
2. 读取寄存器值:读取当前的中止寄存器值
3. 设置本地中止位:如果local参数非零,设置对应通道的本地中止位;如果为零,清除该位
4. 设置远程中止位:如果remote参数非零,设置对应通道的远程中止位;如果为零,清除该位
5. 写入寄存器:将更新后的中止寄存器值写回
ep_dma_ ll_ set_addr_reg
设置PCIe设备的DMA传输链表地址寄存器,确保DMA引擎能够访问正确的描述符链表进行数据传输:
1. 获取BAR物理地址:从hdev结构体中获取保留的BAR( Base Address Register)物理地址
2. 计算链表地址:根据传输方向dirc,计算出DMA描述符链表的物理地址,并确定相应的寄存器偏移量
3. 写入链表地址:将链表的物理地址分为高32位和低32位,分别写入对应的高地址和低地址寄存器
HOBOT_PCIE_IOC_BAR_READ_VIA_DMA
具体流程如下:
1. 获取操作信号量(down_interruptible):如果被中断或超时,记录错误并返回- HOBOT_PCIE_ERR_INTERRUPTTED。
2. 从用户空间复制数据(copy_from_user):如果复制失败,记录错误,释放信号量,并返回- HOBOT_PCIE_ERR_MEM_COPY。
3. 分配DMA缓冲区(dma_alloc_coherent):如果分配失败,记录错误,释放信号量,并返回- HOBOT_PCIE_ERR_NOMEM。
4. 初始化偏移量和读取大小• 根据需要读取的数据量和缓冲区大小确定每次DMA传输的数据量。
5. 执行DMA传输(ho bot_rc_dma_xfer):如果DMA传输失败,记录错误,释放DMA缓冲区和信号量,并返回-HOBOT_PCIE_ERR_DMA_XFER_TIMEOUT。
6. 将数据复制回用户空间(copy_to_user):如果复制失败,记录错误,释放DMA缓冲区和信号量,并返回-HOBOT_PCIE_ERR_MEM_COPY。
7. 更新剩余大小和偏移量• 继续读取直到所有数据被传输完毕。
8. 释放DMA缓冲区和信号量(dma_free_coherent, up):完成所有传输后,清理分配的资源并释放信号量。
6.3.2 ioctl通信阶段内核相关函数简介
IRQ是中断请求( Interrupt Request )的缩写。它是计算机硬件中用于处理外部事件的一种机制。当外部设备需要引起处理器的注意时,会发送一个中断请求信号,以通知处理器有待处理的事件。处理器在接收到中断请求后,会暂停当前正在执行的任务,转而执行与中断相关的处理程序,处理完后再返回原来的任务。中断请求可以是来自各种设备的信号,如键盘、鼠标、磁盘等。
up 函数是一个信号量操作函数,用于增加信号量的计数值。在 Linux 内核编程中,信号量是一种用于同步和互斥访问共享资源的机制。 up 函数通常用于释放(增加)信号量的计数值,以允许其他进程或线程访问受保护的资源。
在代码中, up 函数通常与 down 函数配对使用, down 用于获取信号量的所有权,而 up 用于释放信号量的所有权。通过适当地使用 down 和 up 函数,可以确保对共享资源的访问是安全和有序的。
copy_from_user是一个在Linux内核编程中使用的函数,它的作用是将数据从用户空间安全地复制到内核空间。这个函数在内核与用户空间交互数据时非常重要,因为直接访问用户空间的数据可能会导致安全问题或者内核崩溃。
6.4 设备移除阶段
设备移除阶段的逻辑相对简单,由 hobot_ep_drv_remove 实现,主要负责所有与设备相关的资源被正确地释放和清理,流程如下:
hobot_ep_drv_remove :释放设备相关资源
chrdev_free :移除字符设备,释放相关资源
device_destroy :删除设备节点
cdev_del :删除字符设备
unregister_chrdev_region :注销设备号
ep_dev_deinit :去初始化PCIe设备
msi_free :释放MSI中断
hdev_deinit :去初始化PCIe设备的 hdev 结构体,并释放相关资源
6.4.1 主要逻辑代码分析
ms i_free
函数的主要作用是将所有分配给PCIe设备的MSI中断都被正确地释放,其具体流程如下:
1. 检查中断数量:函数首先检查传入的中断数量 nirqs 是否小于等于设备当前拥有的中断数量 hdev- >irqs 。
2. 循环释放MSI中断:遍历从0到 nirqs 的每个中断。调用 devm_free_irq 函数释放每个中断
3. 释放所有MSI向量:循环结束后,调用 pci_free_irq_vectors 函数释放设备 pdev 的所有MSI向量。
mem_free
释放与设备的每个 DMA 通道相关联的 FI FO 队列内存,其具体流程如下:
1. 初始化循环变量:定义一个循环计数器。
2. 循环遍历,释放 FI FO 队列:从 0 到 DMA_MAX_CHANNEL,调用 kfifo_free 函数释放 hdev 结构体中 chan_recv_fifo 数组的每个元素,这个数组为每个 DMA 通道的接收 FI FO 队列
h dev_de init
函数的主要作用是去初始化PCIe设备的 hdev 结构体,并释放相关资源,其具体流程如下:
1. 获取设备指针:首先,函数通过 hdev 结构体指针获取关联的 device 结构体指针。
2. 条件编译释放DMA资源:如果编译时定义了 CONFIG_PCIE_BAR_CFG_DMA,则调用 rc_dma_deinit 函数来释放与PCIe BAR配置相关的DMA资源。
3. 释放结构体内存:使用 mem_free 函数释放 hdev 结构体指针所指向的内存。
4. 设备管理内存释放:最后,调用 devm_kfree 函数释放 hdev 结构体占用的内存,这是设备管理器提供的内存释放方法。
6.4.2 相关内核函数简介
device_destroy 函数是 Linux 内核中用于删除一个设备的函数。它的主要作用是从系统中移除一个设备,并删除 /sys/devices/virtual 目录下对应的设备目录以及 /dev 目录下对应的设备文件。
cdev_del 函数是 Linux 内核中用于删除字符设备的函数。它的作用是从系统中移除 struct cdev 结构体变量所描述的字符设备。 一旦执行了 cdev_del ,相关的字符设备就不再可用。函数的原型是: void
cdev_del(struct cdev *p) ; 其中, p 是指向要删除的 cdev 结构体的指针。在使用 cdev_del 之前,通常会先通过 cdev_add 函数将 cdev 结构体添加到内核中, 这样设备才能被系统识别和使用。当设备不再需要时,就会调用 cdev_del 来删除它,这样做可以防止内存泄漏和资源占用。
unregister_chrdev_region 函数是 Linux 内核中用于注销一系列字符设备号的函数。当一个模块不再需要它所占用的设备号时,应该调用这个函数来释放这些号码,以便系统可以将它们重新分配给其他模块。
devm_kfree 是 Linux 内核中用于释放由 devm_kmalloc 或其他设备管理内存分配函数分配的内存的函数。
这个函数与常规的 kfree 函数不同,是设备资源管理器的一部分,用于自动管理和释放与设备关联的内存资源,使用 devm_kmalloc 分配内存时,这块内存会与一个设备关联起来,并且在驱动卸载或设备移除时自动释放。
kfifo_free 是 Linux 内核中用于释放 kfifo 缓冲区的函数。 kfifo 是一个无锁环形队列, 主要用于在内核中存储字节流数据。这个队列的设计允许在不需要加锁的情况下进行快速的数据入队和出队操作。
kfifo_free 函数的作用是释放由 kfifo_alloc 分配的 kfifo 缓冲区。
7.总结
本文以NPU驱动浅显地介绍了异构体系通过PCIe进行数据传输与通信的工作流程与相关知识,包括PCIE通信设计、 DMA传输方式以及异构体系间的通信方式和技术细节。通过对PCIE通信原理的解析,我们了解了PCIE作为一种全双工连接总线的特点和架构组成,以及在异构体系中的应用以及DMA传输方式、 MSI中断等相关知识。
异构体系通信的设计和应用展示了在不同设备之间通过PCIE连接进行数据交换和通信的实际场景。作为智能系统设计的架构与体系的实现策略之一,可以进一步探索更高效的通信协议和技术,提升系统性能和数据传输速度,结合相关AI技术,将异构体系通信应用于更广泛的领域。