HICom论文阅读

2025
1.摘要
background
视频多模态大语言模型(MLLMs)在处理视频时面临巨大的计算开销,因为视频包含大量帧,从而产生海量的视觉token。现有的主流解决方法是无条件压缩(unconditional compression),例如对每帧进行空间池化(spatial pooling)或使用Q-Former/Resampler将所有帧压缩成固定数量的token。然而,这种“一刀切”的压缩方式没有考虑用户的具体指令(问题),可能会丢失与问题相关的关键视觉信息,导致性能下降。
innovation
本文的核心思想是引入指令作为条件来指导视频token的压缩过程,即条件化压缩(Conditional Compression),确保压缩过程能最大程度地保留与用户意图相关的信息。为此,论文提出了一个名为HICom (Hybrid-level Instruction Injection Strategy for Conditional Token Compression) 的新框架。
1.混合层级指令注入 (Hybrid-Level Instruction Injection): 这是HICom的核心。它模仿人类“先粗后精”的观察模式,在两个层级上注入指令信息来指导压缩:
局部层面 (Local Level): 将视频token(时空维度)分成多个组(group),在每个组内部,利用指令信息进行注意力计算,将该组压缩成一个token。这有助于保留视频的时空结构,并关注每个局部区域内的相关细节。
全局层面 (Global Level): 将指令信息注入到一组可学习的token中,让这些token与整个视频的所有token进行注意力计算,从而从全局视角捕捉与指令最相关的信息。
2.新的条件化预训练阶段: 为了充分发挥HICom的潜力,作者提出了一个新的三阶段训练范式(对齐->条件化预训练->指令微调),并为此构建了一个新的数据集HICom-248K。这个新的预训练阶段使用“指令-描述”对来专门训练条件化压缩模块,使其更好地学会如何根据指令来筛选信息。
好处与对比: 与SOTA方法(如LLaVA-Video-7B)相比,HICom在多个视频问答基准上取得了更高的性能(平均提升2.43%),同时节省了78.8%的视觉token。这证明了条件化压缩能在大幅降低计算成本的同时,更有效地保留关键信息,从而提升了模型的理解能力。
2. 方法 Method
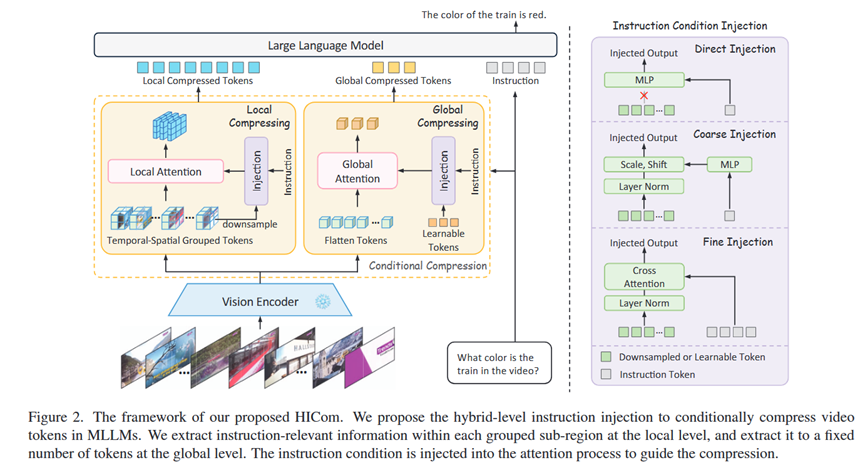
总体 Pipeline:
HICom是一个位于视觉编码器和LLM之间的条件化压缩模块。它的pipeline如下:
输入: 视觉编码器输出的视频帧特征 V (尺寸为 T x H x W x D) 和 文本编码器输出的指令特征 C。
输出: 经过压缩后的、数量大大减少的视觉token序列,然后送入LLM。
各部分详解 (HICom):
1.局部层面压缩 (Local-Level Compression):
分组: 将输入的视频特征 V 沿着时空维度(T, H, W)划分成 NT x NH x NW 个小的数据块(group)。
压缩: 对每个数据块,先将其内部的token池化成一个token V_p。然后,使用指令注入模块将指令特征 C 注入到 V_p 中,得到查询向量 Q。最后,在这个数据块内部进行自注意力计算 Attention(Q, K, V),将整个块压缩成一个输出token Z_l。
作用: 保持视频原有的时空网格结构,关注局部细节。
2.全局层面压缩 (Global-Level Compression):
可学习Token: 初始化一组数量较少的可学习token L。
压缩: 使用指令注入模块将指令特征 C 注入到 L 中,得到查询向量 Q。然后,用这个Q与整个视频的所有token(经过3D位置编码)进行交叉注意力计算 Attention(Q, K_V, V),得到压缩后的全局token Z_g。
作用: 从全局视角捕捉与指令最相关的信息,作为局部压缩的补充。
3.指令注入模块 (Instruction Condition Injection):
论文探索了三种注入方式:直接注入(用MLP直接转换指令token)、粗粒度注入(类似AdaLN,用指令token生成缩放和平移参数)、细粒度注入(用指令token和视觉token做交叉注意力)。实验表明,局部压缩用“直接注入”效果好,全局压缩用“粗粒度注入”效果好。
4.三阶段训练范式:
阶段一:对齐 (Alignment Stage): 类似于LLaVA,使用图文对数据训练视觉编码器和LLM的连接。此时压缩模块不工作。
阶段二:条件化预训练 (Conditional Pre-training Stage): (核心贡献) 在此阶段,使用专门构建的HICom-248K数据集(包含“指令-描述”对),来预训练整个压缩模块(包括指令注入部分)。这使得模块学会如何根据指令来提取相关的视觉信息并生成描述。
阶段三:指令微调 (Instruction Tuning Stage): 使用通用的视频问答数据集对整个模型(主要是LLM和压缩模块)进行微调。
3. 实验 Experimental Results
实验数据集:
条件化预训练: 自建的 HICom-248K 数据集,包含24.8万个视频片段和73.9万个“指令-描述”对。
评测: 在多个主流视频问答基准上进行评估,包括 VideoMME, MV-Bench, EgoSchema (多选QA) 和 ActivityNet-QA, VideoChatGPT Bench (开放式QA)。
每个实验的结论:
1.SOTA性能 (Table 2): 在三个多选QA基准上,HICom-7B模型以远少于其他模型的token数量(例如,相比LLaVA-Video的6272个token,HICom只需1328个),取得了更高的平均分,证明了其压缩效率和性能优势。
2.组件分析 (Table 4): 消融实验证明,条件化压缩显著优于无条件压缩;而局部+全局的混合层级压缩效果最好,优于只使用其中任何一个。
3.条件化预训练阶段的有效性 (Table 5): 实验证明,增加了新的条件化预训练阶段后,模型在所有基准上的性能都有一致的提升(平均1.17%),验证了该阶段的必要性。
4.长视频泛化能力: HICom由于其高效的压缩机制,在推理时可以轻松扩展到更多的帧数(如从32帧扩展到128帧),从而在处理中长视频时性能提升明显,展现了良好的泛化能力。
5.定性分析 (Figure 6): 可视化注意力图显示,在加入指令条件后,压缩模块确实能更准确地关注到与问题相关的物体(如蜡烛台、圣诞树),而无条件压缩的注意力则比较分散。
4. 总结 Conclusion
本文的核心信息是,在压缩视频token时,不应“盲目”压缩,而应利用用户的指令作为“向导”。通过在局部和全局混合层级上进行条件化压缩,可以在大幅减少计算成本的同时,更智能地保留对回答问题至关重要的视觉信息,从而实现效率和性能的双赢。