YOLO v3:目标检测领域的经典革新与实战指南
目录
一、YOLO v3 概述:承前启后的定位
二、YOLO v3 核心技术改进
2.1 网络架构:Darknet-53 与残差连接
Darknet-53 的结构细节:
2.2 多尺度特征融合与先验框设计
(1)多尺度特征融合机制
(2)9 种先验框(Anchor Box)设计
2.3 Logistic 分类器:替代 Softmax 支持多标签检测
Logistic 分类器的优势:
三、YOLO v3 实战流程
3.1 数据集标注:使用 Labelme 工具
3.2 标签格式转换:JSON→YOLO 格式
3.3 模型配置文件设置
(1)自定义配置文件(yolov3-custom.cfg)
(2)数据配置文件(custom.data)
(3)类别名称文件(classes.names)
3.4 训练与测试参数配置
(1)训练参数(train.py)
(2)测试参数(detect.py)
四、YOLO v3 的应用与价值
五、总结
在人工智能深度学习的目标检测领域,YOLO(You Only Look Once)系列算法以其 “单阶段检测” 的高效性,彻底改变了传统目标检测依赖多阶段处理的模式。自 2016 年 Joseph Redmon 等人提出 YOLO v1 以来,该系列不断迭代优化,而YOLO v3作为其中的里程碑版本,在保持实时检测速度的同时,大幅提升了小目标检测精度,融合了当时主流的深度学习技术,成为工程落地与学术研究的重要桥梁。本文将从 YOLO v3 的核心技术改进、实战流程及应用价值三方面,全面解析这一经典算法。
一、YOLO v3 概述:承前启后的定位
YOLO 系列的核心思想是将目标检测问题转化为 “回归问题”—— 通过一个神经网络直接预测目标的类别概率与位置坐标,无需先生成候选框(如两阶段算法 Faster R-CNN 的 RPN 网络)。YOLO v1 以 “快” 著称,但存在小目标检测效果差、每个网格仅预测 1 个类别等问题;YOLO v2 通过锚框(Anchor Box)、多尺度训练等改进提升了精度,但小目标检测仍有瓶颈。
YOLO v3 的核心突破在于 **“更细致的特征提取” 与 “更灵活的多尺度检测”**:它引入残差网络(ResNet)思想构建 Darknet-53 骨干网络,通过多尺度特征融合覆盖不同大小目标,并优化分类器以支持多标签检测,最终在 “速度 - 精度” 平衡上实现了显著提升,成为实时目标检测场景(如自动驾驶、安防监控)的优选方案。
二、YOLO v3 核心技术改进
YOLO v3 的性能提升源于三大核心技术革新,每一项改进都针对性解决了前序版本的痛点,同时吸收了当时深度学习领域的前沿思路。
2.1 网络架构:Darknet-53 与残差连接
YOLO v3 摒弃了 v1 的 GoogLeNet 风格架构与 v2 的简化 Darknet,采用Darknet-53作为骨干网络,其核心特点是 “全卷积 + 残差连接”,彻底移除了全连接层与池化层,通过卷积层的步长(stride=2)实现下采样,既减少参数冗余,又增强特征复用能力。
Darknet-53 的结构细节:
- 残差块(Residual Block)设计:网络由 5 组残差块组成,每组残差块数量分别为 1、2、8、8、4,总卷积层数量达 53 层(得名 “Darknet-53”)。每个残差块通过 “1×1 卷积降维 + 3×3 卷积提特征” 的组合,在减少计算量的同时保留关键信息,并用 “残差连接(H (x)=F (x)+x)” 缓解深层网络的梯度消失问题。
- 下采样方式:通过设置卷积层的步长为 2,实现特征图尺寸的减半(如 416×416→208×208→104×104→52×52→26×26→13×13),每下采样一次,特征图的通道数翻倍,逐步提升语义信息的抽象程度。
- 无全连接层优势:由于移除全连接层,网络对输入图像尺寸的适应性更强,只需保证输入尺寸为 32 的倍数(如 320×320、416×416、608×608),即可灵活调整检测精度与速度。
2.2 多尺度特征融合与先验框设计
小目标检测差是 YOLO v1/v2 的核心痛点,根源在于 “单一尺度特征图难以覆盖不同大小目标”。YOLO v3 通过 **“多尺度特征融合 + 9 种先验框”** 彻底解决这一问题,实现 “大特征图检测小目标、小特征图检测大目标” 的精准匹配。
(1)多尺度特征融合机制
YOLO v3 从 Darknet-53 的不同阶段提取 3 个尺度的特征图,通过 “上采样(UpSampling)+ 特征拼接(Concat)” 实现跨尺度信息融合:
3 个特征图尺度:13×13、26×26、52×52,分别对应 “大感受野”“中感受野”“小感受野”:
- 13×13 特征图:源于网络最深层,语义信息最丰富,适合检测大目标(如汽车、行人);
- 26×26 特征图:由 13×13 上采样后与中层特征拼接,适合检测中等目标(如猫狗);
- 52×52 特征图:由 26×26 上采样后与浅层特征拼接,细节信息最丰富,适合检测小目标(如交通标志、手机)。
融合逻辑:上采样后的特征图与浅层特征图 “通道维度拼接”(而非相加),确保浅层的细节信息(如边缘、纹理)能传递到深层,帮助小目标定位。
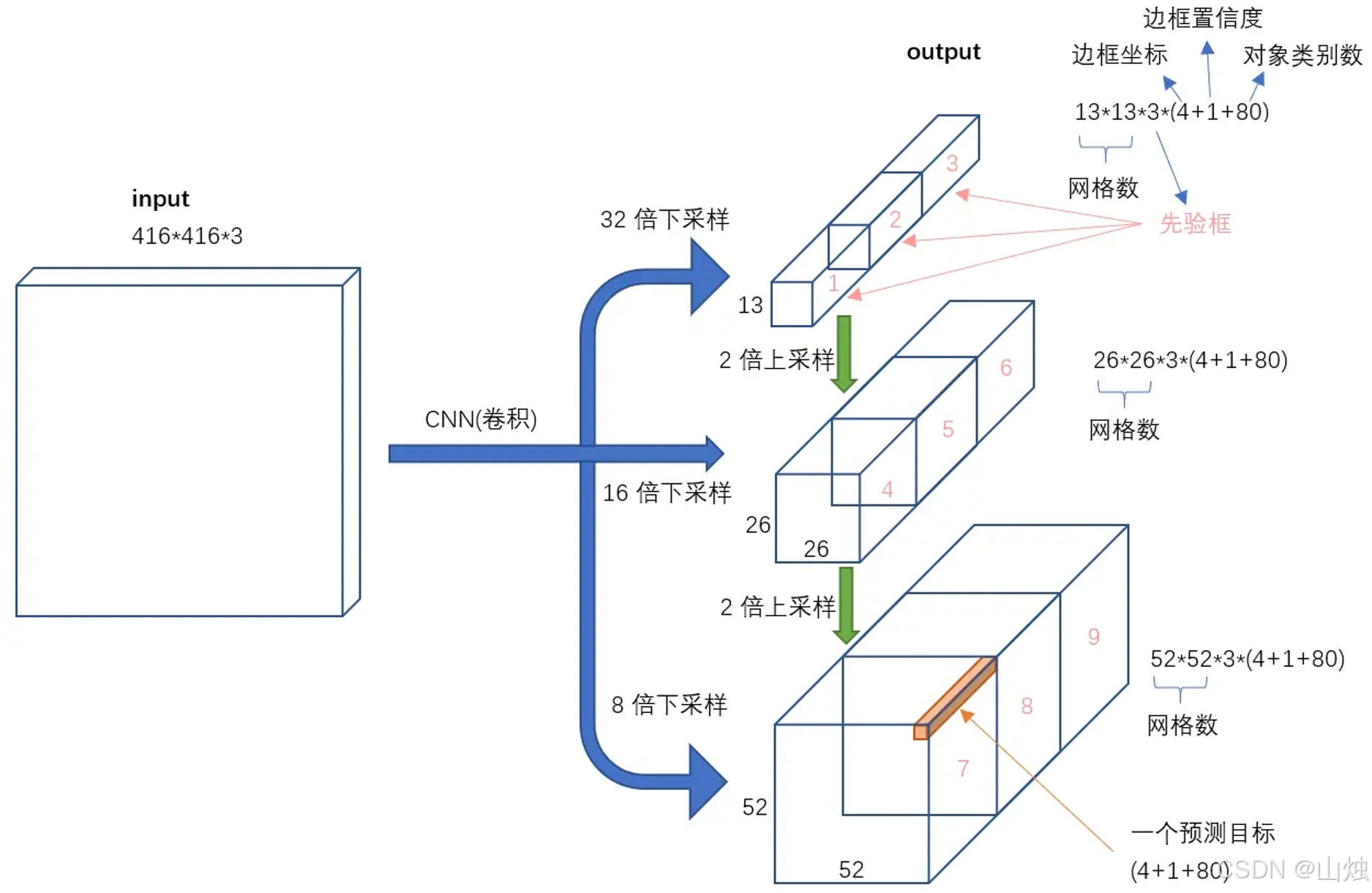
(2)9 种先验框(Anchor Box)设计
YOLO v3 延续 v2 的 “K-means 聚类生成先验框” 思路,但将先验框数量从 5 种提升至 9 种,覆盖更广泛的目标长宽比。通过对 COCO 数据集的目标框聚类,得到 9 种先验框尺寸,并按 “特征图尺度 - 目标大小” 匹配分配:
| 特征图尺度 | 先验框尺寸(宽 × 高) | 适用目标类型 |
|---|---|---|
| 13×13 | (116×90)、(156×198)、(373×326) | 大目标(如人、汽车) |
| 26×26 | (30×61)、(62×45)、(59×119) | 中等目标(如猫狗、自行车) |
| 52×52 | (10×13)、(16×30)、(33×23) | 小目标(如交通灯、瓶盖) |
这种分配方式确保每个尺度的特征图都有适配的先验框,减少模型对 “目标形状” 的学习难度,提升定位精度。
2.3 Logistic 分类器:替代 Softmax 支持多标签检测
传统目标检测模型(如 YOLO v1/v2、Faster R-CNN)采用 Softmax 分类器,其核心局限是 “强制每个目标仅属于一个类别”(概率和为 1),但实际场景中目标可能存在 “多标签属性”(如 “人 + 行人”“猫 + 宠物”)。YOLO v3 通过Logistic 分类器(逻辑回归) 解决这一问题,实现更灵活的类别预测。
Logistic 分类器的优势:
- 独立类别预测:对每个类别单独训练一个 Logistic 分类器,使用 Sigmoid 激活函数将输出映射到 (0,1) 区间,每个类别概率独立计算,无需满足 “概率和为 1”,支持多标签标注(如一张图中 “狗” 和 “宠物” 可同时为正类)。
- 简化计算与稳定训练:相比 Softmax,Logistic 分类器无需计算类别间的归一化,减少计算量,同时避免因类别不平衡导致的训练偏移。
例如,在 “动物检测” 任务中,若图像包含一只 “既是狗又是宠物” 的目标,Softmax 会强制选择 “狗” 或 “宠物” 中的一个标签,而 Logistic 分类器可输出 “狗:0.92,宠物:0.88”,更符合实际场景需求。
三、YOLO v3 实战流程
YOLO v3 的工程落地需经过 “数据准备 - 模型配置 - 训练 - 测试” 四大步骤,以下为关键流程解析。
3.1 数据集标注:使用 Labelme 工具
目标检测模型训练的前提是 “带标注的数据集”,YOLO v3 要求标注格式为 “类别 ID + 目标中心坐标(cx, cy)+ 目标宽高(w, h)”(均为相对图像尺寸的归一化值,0-1 之间)。推荐使用Labelme工具进行标注,步骤如下:
- Labelme 安装:通过 Python 包管理工具安装依赖:
pip install labelme # 核心标注工具
pip install pyqt5 # 图形界面依赖
pip install pillow # 图像处理依赖
- 启动与标注:在命令行输入
labelme启动工具,打开待标注图像,选择 “矩形框(rectangle)” 标注目标,输入类别名称(如 “person”“animal”),标注完成后保存为 JSON 格式文件(包含目标的绝对坐标 x1,y1,x2,y2)。
3.2 标签格式转换:JSON→YOLO 格式
Labelme 生成的 JSON 文件包含 “绝对坐标”,需转换为 YOLO v3 要求的 “相对归一化坐标”,转换逻辑如下:
假设图像宽为 W、高为 H,标注的目标框左上角为 (x1,y1)、右下角为 (x2,y2),则:
- 中心坐标:cx = (x1 + x2)/(2W),cy = (y1 + y2)/(2H)
- 目标宽高:w = (x2 - x1)/W,h = (y2 - y1)/H
转换后生成 TXT 文件,每行格式为 “class_id cx cy w h”(如 “0 0.368 0.550 0.148 0.637”,其中 “0” 代表 “person” 类别)。
转换脚本(如json2yolo.py)通常放在项目的utils文件夹中,转换后的 TXT 文件需统一输出到data/custom/labels目录,与图像文件(存于data/custom/images)一一对应。
3.3 模型配置文件设置
YOLO v3 的训练需配置 3 类核心文件,确保模型参数与数据集匹配:
(1)自定义配置文件(yolov3-custom.cfg)
通过项目中的create_custom_model.sh脚本自动生成,需指定 “类别数量”(如检测 “person” 和 “animal” 两类,则输入bash create_custom_model.sh 2)。脚本会自动调整网络输出层的通道数(通道数 = 3×(类别数 + 5),其中 “3” 为每个网格的先验框数量,“5” 为 x,y,w,h,confidence)。
(2)数据配置文件(custom.data)
存放数据集相关路径与参数,格式如下:
classes=2 # 类别数量
train=data/custom/train.txt # 训练集图像路径列表
valid=data/custom/valid.txt # 验证集图像路径列表
names=data/custom/classes.names # 类别名称映射文件
(3)类别名称文件(classes.names)
按 “类别 ID 顺序” 记录类别名称,每行一个类别,例如:
person # 类别0
animal # 类别1
3.4 训练与测试参数配置
(1)训练参数(train.py)
通过命令行指定核心参数,启动训练:
python train.py \
--model_def config/yolov3-custom.cfg \ # 模型配置文件路径
--data_config config/custom.data \ # 数据配置文件路径
--pretrained_weights weights/darknet53.conv.74 # 预训练权重(加速收敛)
其中,darknet53.conv.74是 Darknet-53 骨干网络在 ImageNet 上预训练的权重,仅包含前 74 层卷积参数,避免从头训练导致的收敛缓慢。
(2)测试参数(detect.py)
训练完成后,使用训练好的权重(如checkpoints/yolov3_ckpt_100.pth)进行目标检测:
python detect.py \
--image_folder data/samples/ \ # 待检测图像文件夹
--model_def config/yolov3-custom.cfg \ # 模型配置文件
--checkpoint_model checkpoints/yolov3_ckpt_100.pth \ # 训练好的权重
--class_path data/custom/classes.names # 类别名称文件(用于显示类别)
检测结果会自动保存到output目录,标注出目标的边界框、类别与置信度。
四、YOLO v3 的应用与价值
YOLO v3 的 “速度 - 精度” 平衡使其在多个领域具备不可替代的价值:
- 实时检测场景:在 CPU 上可实现约 15 FPS、GPU 上达 60 FPS 的检测速度,满足自动驾驶(实时识别行人、车辆)、安防监控(实时追踪目标)、工业质检(实时检测产品缺陷)等场景的低延迟需求。
- 小目标检测优化:通过多尺度特征融合,YOLO v3 对小目标(如交通标志、无人机航拍中的行人)的检测精度较 v2 提升约 10%-15%,拓展了算法的适用范围。
- 工程落地友好性:PyTorch、TensorFlow 等主流框架均有成熟的 YOLO v3 实现,且支持模型压缩(如 Tiny YOLO v3)与跨平台部署(如嵌入式设备、边缘计算节点),降低了工业应用的门槛。
五、总结
YOLO v3 作为 YOLO 系列的经典版本,既继承了 “单阶段检测” 的速度优势,又通过 Darknet-53、多尺度融合、Logistic 分类器等改进,弥补了前序版本在小目标检测与多标签支持上的短板,成为 “实时目标检测” 领域的标杆算法。其核心价值不仅在于技术层面的创新,更在于为后续版本(如 YOLO v4、v5)奠定了 “结构优化 + 工程落地” 的双重导向 ——YOLO v4 的 CSPNet、YOLO v5 的工程化封装,均在 YOLO v3 的基础上进一步迭代,足见其深远影响。
对于开发者而言,YOLO v3 仍是学习目标检测的优选案例:它涵盖了残差网络、特征融合、锚框设计等核心技术,且实战流程清晰,既能帮助理解目标检测的底层逻辑,又能快速上手工程开发,堪称 “理论与实践结合的典范”。