100美元成本复现ChatGPT:nanochat全栈技术栈深度剖析
在人工智能领域,Andrej Karpathy的名字始终与开创性的工作和深刻的教育贡献紧密相连。作为OpenAI的联合创始人及前特斯拉AI总监,他的每一个新项目都能在开发者社区中激起巨大的波澜。2025年10月13日,Karpathy再次引爆了技术圈,发布了他的最新开源项目nanochat。项目发布至今,其在GitHub上的Star数量就已超过7300。
nanochat的核心标签极具冲击力:一个花费约100美元、仅需4小时即可训练完成的ChatGPT克隆版。这不仅是一个引人注目的噱头,更是一次对构建大型语言模型全流程的极致简化与深刻洞察。
从预训练到推理的全栈实现
许多开发者都熟悉Karpathy之前的nanoGPT项目,它以极简的代码出色地展示了GPT模型的预训练过程。而nanochat则在此基础上迈出了一大步,它不再局限于预训练,而是覆盖了构建一个完整、可对话的LLM所需的全栈流程。
-
数据处理与分词
nanochat的起点是公开的FineWeb数据集。在数据处理的第一步,即分词环节,Karpathy做出了一个有趣的选择:使用Rust语言从零实现了一个全新的分词器。分词是将文本分解为模型能够理解的最小单元(tokens)的过程,而Rust以其内存安全和高性能著称,这一选择不仅展示了在AI工作流中引入高性能语言的潜力,也为学习者提供了一个现代化的分词器实现范例。 -
训练三部曲
nanochat的训练过程被设计成一个清晰的三部曲。首先,它在FineWeb数据集上进行基础的预训练,让模型学习语言的基本规律和知识。接着,进入中期训练阶段,使用包含用户与助手对话、多选问答、工具使用等更多样化的数据,对模型进行初步的能力引导。最后,通过监督微调(Supervised Fine-Tuning, SFT)阶段,使用高质量的指令数据,将模型“塑造”成一个乐于助人且遵循指令的对话助手。 -
强化学习与工具调用
更进一步,nanochat还可选地集成了强化学习环节。它使用了一种名为GRPO的算法,在GSM8K这个数学问题数据集上进行训练。强化学习是一种通过奖励和惩罚来引导模型行为的训练方法,旨在提升模型的推理能力。此外,项目还实现了一个轻量级的Python解释器沙箱,赋予了模型调用外部工具来解决问题的能力。这标志着nanochat已经触及了当前AI Agent研究的核心领域。 -
高效推理与交互
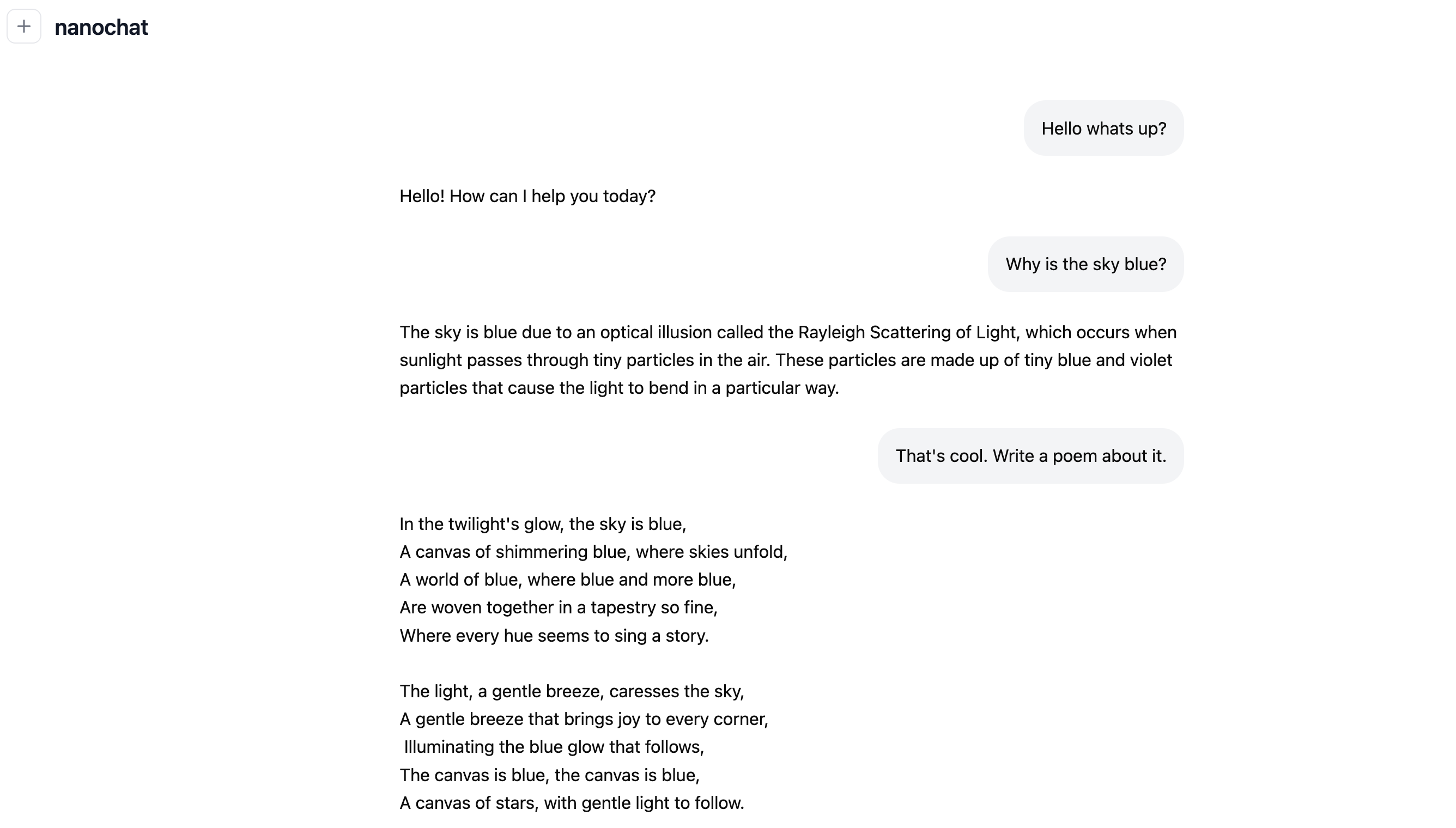
训练完成后,nanochat提供了一个包含KV Cache优化的高效推理引擎。KV Cache是一种广泛用于加速Transformer模型推理的技术,它通过缓存中间计算结果,避免了大量的重复计算。用户可以通过命令行或一个ChatGPT风格的Web界面,与自己亲手训练的模型进行实时交互。
成本、性能与直观预期
nanochat项目最吸引人的地方,在于它将成本和性能进行了明确的量化,为开发者提供了极为直观的实践预期。
-
100美元级别(Speedrun模式)
这是项目的“闪电战”模式。在一台配备8个H100 GPU的云主机上,大约花费4小时和100美元,你就能得到一个可以进行基本对话的迷你ChatGPT。但需要明确的是,其智能水平非常有限。Karpathy形容与它的对话体验“像与一个幼儿园小孩对话”,它能写一些简单的故事和诗歌,但知识和逻辑能力与商用模型相去甚远。 -
300美元级别
将训练时间延长至约12小时,花费约300美元,模型的性能将得到显著提升,其CORE指标(一种衡量模型核心能力的基准)能够略微超过经典的GPT-2模型。 -
1000美元级别
当投入约41.6小时和1000美元时,模型的连贯性会快速提升,开始具备解决基础数学和代码任务的能力,并能在一些多项选择题测试中取得不错的成绩。例如,一个训练24小时的模型,在MMLU这个综合能力测试中就能获得超过40分。
学习价值与应用边界
nanochat的核心价值在于其教育意义。它以约8000行清晰、极少依赖的代码,将一个看似遥不可及的ChatGPT完整地呈现在每个开发者面前。通过学习和实践nanochat,开发者不仅能深刻理解LLM从数据到对话的全过程,更能获得一个可任意修改、可深入研究的“活体”实验平台。
然而,Karpathy本人也明确指出了nanochat的局限性。它是一个“强势基eline”,一个完美的学习起点,但不适合直接用于生产环境或严肃的个性化应用。其模型规模过小,原始智能有限,如果直接在个人数据上进行微调,很可能会丢失其来之不易的通用能力,变成一个只会“鹦鹉学舌”的玩具。
从nanochat的学习到真正的生产级应用,开发者需要跨越一道鸿沟。生产环境中的AI应用,往往需要处理更复杂的业务逻辑,对模型的稳定性、响应速度和安全性有极高的要求。这时,开发者需要的便不再是一个教学级的实现,而是像七牛云这样提供稳定、高性能AI大模型推理服务的平台。通过兼容OpenAI API的统一接口,开发者可以将从nanochat中学到的原理,无缝地应用到数十种主流大模型上,并获得百万级并发处理能力和企业级的安全合规保障,从而将一个实验性的想法,真正转化为能够服务万千用户的可靠产品。
nanochat为我们打开了一扇门,让我们得以一窥LLM内部的完整运作机制。而如何走好门后的道路,将学习到的知识与强大的生产级工具相结合,则是每一位AI开发者需要继续探索的课题。