PC端AI推理存储IO流量剖析
本文基于Micron团队发布的《AI Inferencing Storage IO Traffic Profiling and Analysis》报告,对PC端AI推理过程中的存储IO流量特征展开系统性剖析。报告聚焦AI推理的核心步骤与性能指标,深入分析基准测试及实际应用(多模态、多模型、RAG)中的IO流量模式,并提炼出AI推理流量的独特性,为存储硬件优化与软件栈适配提供关键技术依据。

随着大语言模型(LLM)、多模态AI在PC端的普及,AI推理已从“算力主导”转向“算力-存储协同主导”。传统PC存储设计侧重通用IO场景(如文件读写、系统启动),而AI推理过程中模型加载、KV缓存交换、向量数据库检索等操作,会产生独特的存储IO流量——其带宽需求、读写模式与延迟敏感点均与传统场景存在显著差异。因此,精准刻画AI推理存储IO特征,成为突破PC端AI性能瓶颈的核心前提。

PC端AI推理的本质是“模型驱动的用户请求响应过程”,其链路可拆解为三大核心步骤,对应三项关键性能指标,且存储IO性能在各环节均扮演重要角色。AI推理的完整链路遵循“数据输入-模型计算-结果输出”逻辑,具体可分为:
-
模型加载阶段:将硬盘中存储的AI模型权重(如LLM的Transformer层参数)加载至GPU显存/系统内存,为计算做准备;
-
用户查询处理阶段:接收用户输入(文本、图像等),通过AI框架预处理数据,并初始化KV缓存(Key-Value Cache,用于缓存中间计算结果以加速后续token生成);
-
响应生成阶段:基于预处理数据与KV缓存,通过GPU执行推理计算,生成连续token(如文本回复、图像分析结果)。

为量化AI推理性能,行业普遍采用三项核心指标,且均与存储IO深度绑定:
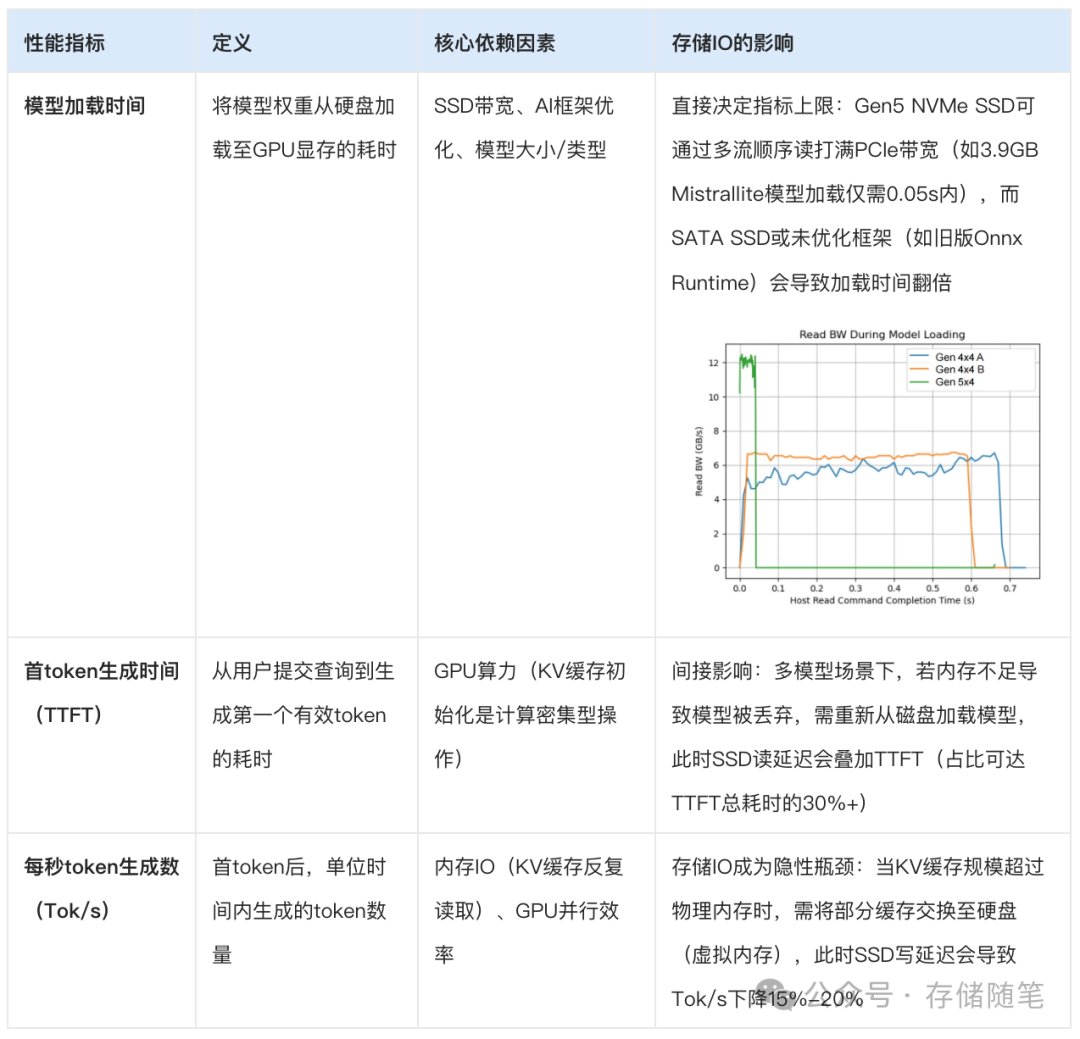
需特别注意:模型加载时间的核心影响因子可进一步拆解为三类:
-
硬件层:SSD的持续读带宽(Gen4→Gen5的带宽提升可使Llama2 13B模型加载时间从2.5s降至1.2s);
-
软件层:AI框架的IO优化(如Ollama支持多流顺序读,而旧版Onnx Runtime为随机读,带宽利用率仅为Ollama的50%);
-
模型层:模型大小与压缩格式(2GB的Phi1 Mini加载时间仅为7GB Llama2 13B的1/4)。
AI推理IO流量并非单一模式,其特征随场景(基准测试/实际应用)、模型类型(单模态/多模态)、部署方式(单模型/多模型)而变化。报告通过实测,分别刻画了基准测试中的模型加载流量与实际场景中的复杂IO流量。
基准测试聚焦“单一模型加载”场景,核心变量为SSD世代(Gen3→Gen5)、AI框架(Ollama vs Onnx Runtime)与模型规格,其IO流量呈现两大关键规律:
Ollama框架:采用多流顺序读策略,可充分打满NVMe SSD带宽。例如:
-
加载Mistrallite模型(3.69GB)时,启用2-5个IO流,每个流对应独立队列ID(QID),实现“并行顺序读”;
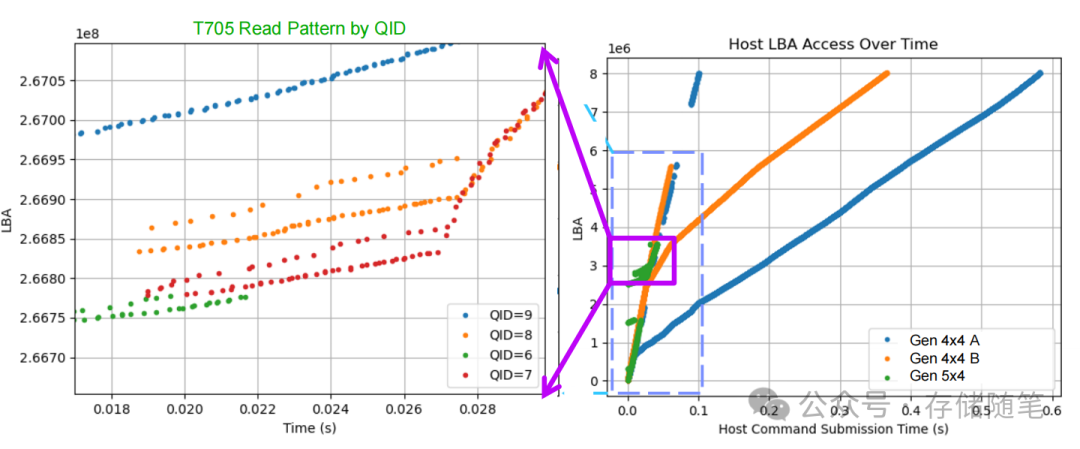
-
Gen5 NVMe SSD加载Llama3 8B模型(4.92GB)时,带宽利用率达95%以上,加载时间仅1.1s;
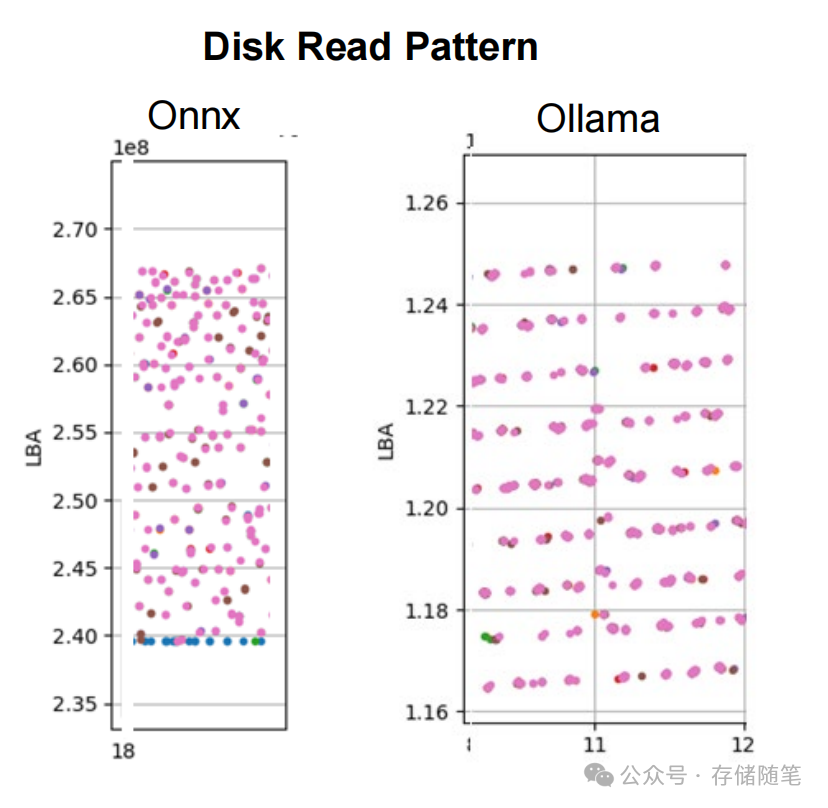
Onnx Runtime(ORT):旧版本存在显著优化缺陷,表现为随机读,带宽利用率不足Ollama的50%;最新版本虽改进为顺序读,但多流调度效率仍落后Ollama约20%。
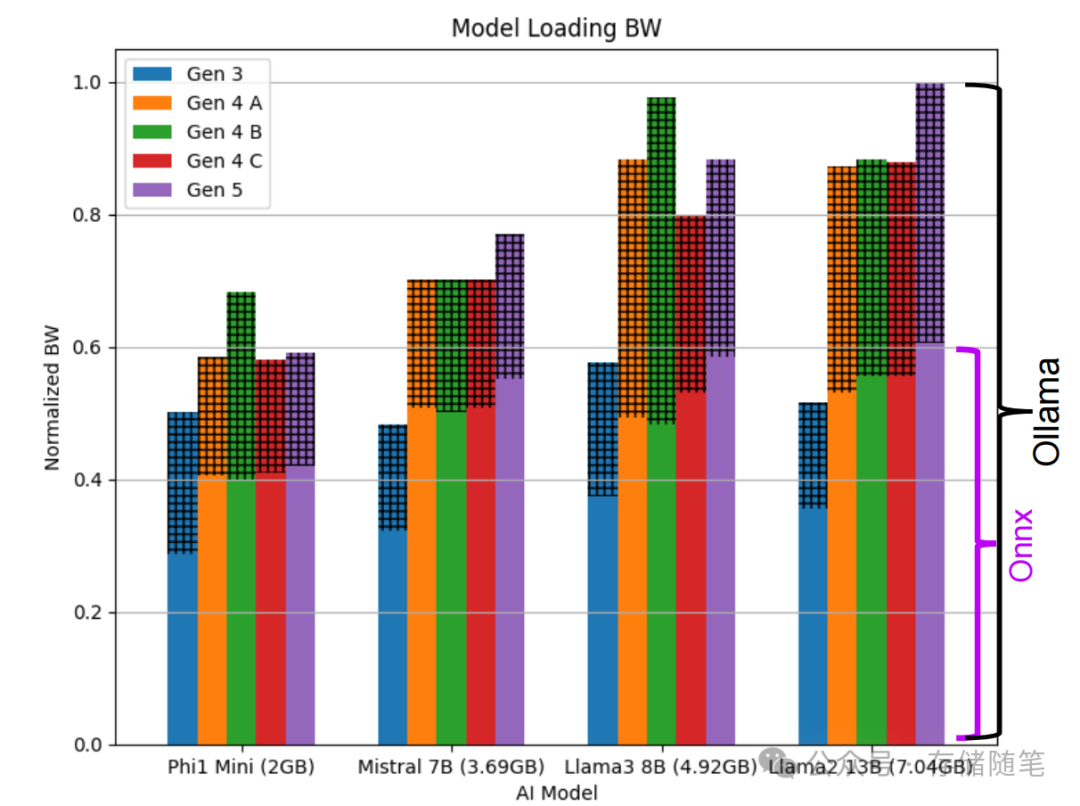
报告通过对比Gen3~Gen5 NVMe SSD加载不同尺寸模型的带宽表现,发现:
-
小模型(如2GB Phi1 Mini):Gen4与Gen5 SSD