论文解读 -- A FOUNDATION MODEL FOR MUSIC INFORMATICS
一、技术解读
1.1 MusicFM模型的作用
本研究针对音乐信息学领域面临的标注数据稀缺和泛化挑战,系统性地探索了基础模型的优化路径。通过自监督学习范式,论文比较了多种模型变体在音乐信息检索任务上的性能,确立了影响模型效果的六大关键因素。
核心方法
- 掩码标记建模:采用BERT-style的预训练框架,通过预测被掩码的音频片段学习音乐表示
- 随机标记化:使用随机投影量化器(BEST-RQ)替代传统可训练标记化方法,降低计算复杂度
- 多尺度架构:对比了BERT编码器和Conformer架构在音乐序列建模中的表现
关键发现
- 标记化策略:随机标记化在音乐数据上展现出色泛化能力,无需额外表示学习阶段
- 上下文长度:30秒输入序列显著提升长期依赖建模能力,优于传统的5秒片段
- 架构优势:Conformer在所有下游任务中一致优于BERT编码器
- 数据规模:160K小时专业数据训练模型显著优于8K小时众包数据
- 分辨率权衡:25Hz时间分辨率在计算效率和性能间取得最佳平衡
- 微调策略:全模型微调虽提升性能,但需警惕过拟合风险
技术贡献
- 首次系统验证随机标记化在音乐领域的有效性
- 确立Conformer作为音乐序列建模的最优架构选择
- 证明长序列输入对音乐结构理解的重要性
- 提供公开可用的预训练模型促进后续研究
应用价值
该研究为音乐AI领域提供了实证指导,在音乐分类、节拍跟踪、和弦识别、结构分析等任务中实现性能提升,同时为多模态音乐理解和生成任务奠定基础。
1.2 MusicFM使用代码示例
HOME_PATH = "/Users/bytedance/Desktop/codes/ASAE" # path where you cloned musicfmimport os
import sys
import librosa
import torchsys.path.append(HOME_PATH)
from musicfm.model.musicfm_25hz import MusicFM25Hz# 加载音频文件,采样率设置为 24kHz
wav, sr = librosa.load("test.wav", sr=24000)# 将音频数据转换为 PyTorch 张量并添加批处理维度
wav = torch.from_numpy(wav).float().unsqueeze(0) # 添加批处理维度# load MusicFM
musicfm = MusicFM25Hz(is_flash=False,stat_path=os.path.join(HOME_PATH, "musicfm", "data", "msd_stats.json"),model_path=os.path.join(HOME_PATH, "musicfm", "data", "pretrained_msd.pt"),
)# to MPS (for Apple Silicon)
if torch.backends.mps.is_available():wav = wav.to("mps") # 将张量移动到 MPS 设备musicfm = musicfm.to("mps") # 将模型移动到 MPS 设备
else:print("MPS is not available. Please check your PyTorch installation.")# get embeddings
musicfm.eval()
logits, hidden_emb = musicfm.get_predictions(wav)# 打印 hidden_emb 的类型和内容
print(f"Type of hidden_emb: {type(hidden_emb)}") # 打印 hidden_emb 的类型
print(f"Length of hidden_emb: {len(hidden_emb)}") # 打印 hidden_emb 的长度# 打印每一层的形状
for i, emb in enumerate(hidden_emb):print(f"Shape of hidden state for layer {i}: {emb.shape}") # 打印每一层的形状
Type of hidden_emb: <class 'tuple'>
Length of hidden_emb: 13
Shape of hidden state for layer 0: torch.Size([1, 250, 1024])
Shape of hidden state for layer 1: torch.Size([1, 250, 1024])
Shape of hidden state for layer 2: torch.Size([1, 250, 1024])
Shape of hidden state for layer 3: torch.Size([1, 250, 1024])
Shape of hidden state for layer 4: torch.Size([1, 250, 1024])
Shape of hidden state for layer 5: torch.Size([1, 250, 1024])
Shape of hidden state for layer 6: torch.Size([1, 250, 1024])
Shape of hidden state for layer 7: torch.Size([1, 250, 1024])
Shape of hidden state for layer 8: torch.Size([1, 250, 1024])
Shape of hidden state for layer 9: torch.Size([1, 250, 1024])
Shape of hidden state for layer 10: torch.Size([1, 250, 1024])
Shape of hidden state for layer 11: torch.Size([1, 250, 1024])
Shape of hidden state for layer 12: torch.Size([1, 250, 1024])
1.3 代码分析
-
导入库和模块:
- 导入必要的库,如
os、sys、librosa和torch,以及自定义的MusicFM25Hz模型。
- 导入必要的库,如
-
加载音频文件:
- 使用
librosa.load加载音频文件,并将其采样率设置为 24 kHz。音频数据被转换为 NumPy 数组。
- 使用
-
转换为 PyTorch 张量:
- 将加载的音频数据转换为 PyTorch 张量,并添加批处理维度。
-
加载 MusicFM 模型:
- 创建
MusicFM25Hz模型的实例,指定统计数据和预训练模型的路径。
- 创建
-
设备选择:
- 检查 MPS 是否可用,如果可用,则将音频张量和模型移动到 MPS 设备。
-
获取嵌入:
- 调用
get_predictions方法获取logits和hidden_emb,其中hidden_emb包含所有层的输出。
- 调用
-
打印输出:
- 打印
hidden_emb的类型、长度和每一层的形状。
- 打印
1.4 特征分析
- 音频输入:
- 加载的音频数据
wav的形状为(n_samples,),其中n_samples是音频样本的总数。 - 在转换为 PyTorch 张量并添加批处理维度后,形状变为
(1, n_samples)。
- 模型输出:
get_predictions方法返回两个值:logits:通常是模型的预测结果,形状为(batch_size, num_classes, time_frames)。具体维度取决于模型的设计和任务。hidden_emb:包含所有层的隐藏状态,通常是一个元组,长度等于模型的层数(在此情况下为 13 层),每层的形状为(batch_size, time_frames, feature_dim),其中:batch_size是输入的批处理大小(在此为 1)。time_frames是时间帧的数量(在此为 250)。feature_dim是每层的特征维度(在此为 1024)。
二、论文翻译:音乐信息学的基础模型
0 摘要
本文研究了专为音乐信息学量身定制的基础模型,该领域目前面临标注数据稀缺和泛化问题的挑战。为此,我们对各种基础模型变体进行了深入的比较研究,考察了关键决定因素,如模型架构、标记化方法、时间分辨率、数据和模型可扩展性。本研究旨在通过阐明这些个体因素如何促进基础模型在音乐信息学中的成功,来弥合现有的知识空白。采用谨慎的评估框架,我们评估了这些模型在音乐信息检索中各种下游任务上的性能,特别关注标记级和序列级分类。我们的结果表明,我们的模型展现出强大的性能,在特定关键指标上超越了现有模型。这些发现有助于理解音乐信息学中的自监督学习,并为在该领域开发更有效和多功能的基础模型铺平道路。我们模型的预训练版本已公开可用,以促进可重复性和未来研究。
索引术语 - 基础模型,音乐信息检索,自监督学习
1. 引言
基础模型指的是任何经过预训练的机器学习模型,能够适应广泛的下游任务[1]。通过利用其自监督的特性,人工智能研究人员已经能够使用海量数据扩展基础模型,从而产生可以泛化到多个领域(如自然语言处理[2,3]、计算机视觉[4,5]、语音识别[6,7]和多模态研究[8])中各种下游任务的通用表示。
基础模型的潜力不仅限于上述领域。在音乐信息检索(MIR)领域,研究人员一直面临着扩展模型的挑战,主要原因是缺乏标注数据。音乐数据的标注工作劳动密集,通常需要专业的领域知识,这阻碍了大规模数据收集工作。为了规避这些限制,研究人员采用了半监督学习[9,10]或迁移学习[11,12]方案,这些方案利用了来自更大标注数据集的知识。然而,这些方法经常遇到泛化问题,特别是当下游任务涉及监督数据中未表示的信息时[13]。此外,可扩展性仍然受到标注数据可用性的限制。这导致人们对开发专门为音乐信息学研究量身定制的自监督基础模型越来越感兴趣。
尽管音乐信息学中的基础模型研究仍处于起步阶段,但一些开创性工作已经做出了显著贡献。CLMR[14]和MULE[13]采用了简单的对比学习框架[15]来捕获序列级音乐表示,该表示总结了整个序列,而不是在每个时间步保留信息。尽管它们的性能落后于监督方法,但它们已经证明了自监督模型在多个音乐标注任务中泛化的潜力。另一项创新研究[16]揭示,在标记化表示(如Jukebox[17])上预训练的语言模型可以作为各种下游MIR任务的强大基础模型。作者讨论到,生成模型可以学习比传统标注模型更丰富的表示。最近,MERT[18]采用了HuBERT[6](一个成功的语音识别基础模型)来构建一个明确为音乐表示量身定制的框架,证明了其在各种序列级分类任务中的可泛化性。
然而,尽管取得了这些进展,目前仍不清楚各个因素(如模型架构、标记化方法、时间分辨率、数据和模型可扩展性)如何促进基础模型在音乐信息学中的成功。这一知识空白强调了进行全面调查的必要性,这也是我们研究的重点。在这项工作中,我们通过仔细评估标记级和序列级下游分类任务,比较了来自语音识别的一种新的自监督学习方法(即BEST-RQ[7])与MERT[18]。我们发现我们的模型在一系列MIR任务中展现出强大的性能,并在特定情境下优于现有模型。我们模型的预训练版本可在线获取 1{}^{1}1,以促进可重复研究。
1{}^{1}1 https://github.com/minzwon/musicfm
2. 模型
本章概述了本研究中采用的基础模型的关键概念。鉴于我们研究的目标是考察促成基础模型成功开发的各种因素,我们利用了先前工作[7, 18]中的现有模型和训练方法。需要指出的是,本节描述的方法均非我们的原创贡献;它们作为我们研究如何优化音乐信息学基础模型的基础。
2.1 掩码标记建模
与GPT-3[3]等生成模型并列,掩码标记建模技术(如BERT[2])已在各种序列数据类型中展现出作为基础模型的强大性能,特别是在语音音频领域[19,20,6,7]。在掩码标记建模范式中,目标是在序列中预测被故意掩码的标记。如图1所示,输入音频的部分被随机用噪声掩码。然后,基础模型的任务是预测这些被故意掩码或省略的标记(粉色高亮部分)。这种方法使基础模型能够学习上下文语义,这对各种下游任务非常有用。
虽然各种模型架构可以作为基础模型的骨干网络,但由于其卓越的序列建模能力,Transformer变体[19, 20, 6, 7]是最常用的。具体来说,BERT风格的编码器[6]已被整合到MERT[18]中,而Conformer[20]已被用于BEST-RQ[7],这两者都是我们实验的核心骨干网络。掩码标记建模可以使用标记化方法(图1右侧)形式化为自监督分类任务,这将在下一小节介绍。
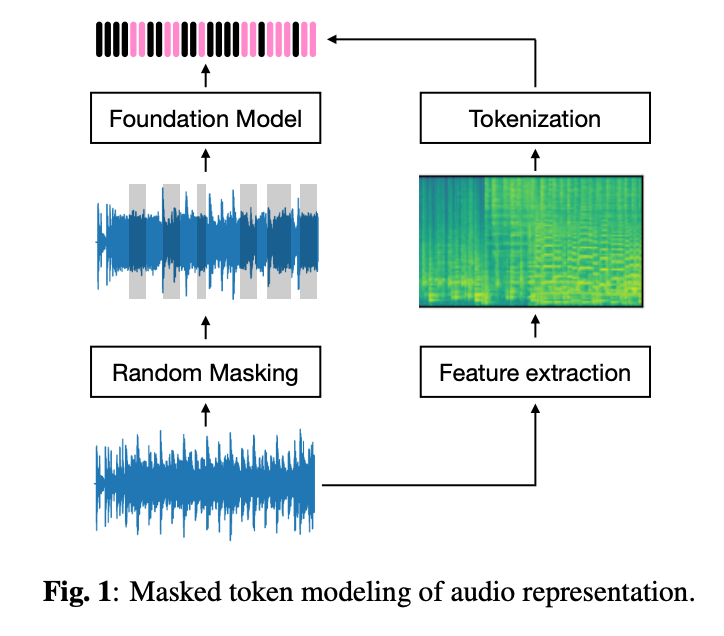
2.2 标记化
为了在掩码标记建模框架内进行音乐序列建模,必须将短音频片段转换为离散标记,这个过程称为标记化。虽然可以使用各种标记化方法,但我们的基线MERT[18]使用了k-means聚类[6]和残差向量量化(RVQ)[21]。作者在log-mel频谱上使用k-means聚类来捕捉音色特征,并使用chroma特征来编码和声属性。然后根据相应的特征聚类将得到的表示进行标记化。
然而,大多数传统的标记化方法,包括k-means聚类和RVQ,都需要一个单独的表示学习训练阶段。这个额外的步骤可能引入复杂性并产生可能影响基础模型整体性能的依赖关系。为了解决这些挑战,最近的工作(BEST-RQ[7])提出了一种使用随机投影量化器的标记化方法,以绕过对可训练的表示学习阶段的需求。这种方法有两个随机组件:随机投影和随机码本查找,两者都不需要训练。在这个方案中,一个d维输入向量x通过随机投影R映射到一个h维潜在空间。然后从随机初始化的n×hn\times hn×h码本C中选择最近邻索引作为特征表示标记。标记化表示τ\tauτ可以形式化为:
τ=argmini∥R⋅x−ci∥2\tau = \arg\min_{i} \| R \cdot x - c_i \|_2τ=argimin∥R⋅x−ci∥2
其中R是用于随机投影的h×dh\times dh×d矩阵,cic_ici表示随机码本C中的第i个向量,∥⋅∥2\|\cdot\|_2∥⋅∥2表示l2l_2l2范数。投影矩阵R使用Xavier初始化初始化,而码本C使用标准正态分布。Log-mel频谱是唯一的特征向量,并被归一化为零均值和单位方差。当使用不可训练的随机投影时,这个归一化步骤尤其重要,因为如果没有它,码本利用率可能非常低。
3. 实验
本章详细介绍了我们为评估音乐基础模型而设计的实验设置。我们首先描述使用的数据集,然后阐述评估协议,最后介绍我们研究的不同基础模型变体。
3.1 数据集
我们使用了两个不同的数据集来训练我们的基础模型。第一个数据集包含160,000小时的内部音乐数据,其规模与训练MERT使用的数据量保持一致。第二个数据集是自由音乐档案(FMA)数据集[22],包含8,000小时的创意共享许可音乐音频。两个数据集的所有音频文件都经过预处理,统一为24kHz单声道音频格式。
3.2 评估
以往的研究[14, 16, 13, 18]主要关注通过序列级分类任务(如流派分类、情感识别、调性检测和音乐标注)来评估音乐基础模型。然而,音乐信息检索中的许多应用需要在个体时间步长上进行预测。基于这一背景,我们提出强大的基础模型应该在标记级分类任务(如节拍跟踪和和弦识别)中展现出强大能力。为验证这一假设,我们的研究在五个不同任务上评估基础模型:节拍跟踪、和弦识别、结构分析(均为标记级分类任务),以及调性检测和音乐标注(均为序列级分类任务)。
遵循先前工作[16],我们在基础模型之上采用探测模型进行评估。该探测模型是一个浅层神经网络,包含单个512维隐藏层和一个输出层。由于我们的目标是检查预训练表示,基础模型在此探测阶段保持冻结状态。对于序列级分类,我们使用平均池化层在时间维度上聚合表示,然后进行线性探测。
评估任务详述
节拍/下拍跟踪旨在预测每个节拍的时间戳以及每小节第一个节拍的位置。根据先前研究[23],我们的模型每50毫秒生成节拍、下拍和非节拍事件的帧级概率。为解码下拍时间戳,我们使用madmom[24]中实现的动态贝叶斯网络(DBN)进行后处理。使用Harmonix Set[25]进行训练,GTZAN[26]作为测试集。使用mir_eval[27]中的F-measure进行评估。
和弦识别是一项具有挑战性的MIR任务,因为音乐作品中存在复杂的和声关系。在本研究中,我们仅关注大调和小调和弦。模型每125毫秒输出25个类别的帧级概率,包括12个音高的大调和小调和弦,以及一个称为"无"的类别。使用HookTheory[28]进行训练,选择2000首歌曲进行测试。评估指标是mir_eval[27]中的大调/小调加权准确率。
结构分析旨在将音乐录音分割成不同的、非重叠的段落,并预测每个段落的功能标签(如’主歌’和’副歌’)。遵循先前设置[29],探测模型有两个分类器,用于预测七个功能类别和边界的帧级概率。每帧分辨率为200毫秒。从Harmonix Set[25]中选择150首曲目进行测试,其余部分用于训练。使用mir_eval[27]包计算命中率在0.5秒处的F-measure(HR.5F)来评估边界,使用帧级准确率来评估功能标签。
调性检测旨在预测整个歌曲的音调音阶和音高关系。模型必须每2秒输出25个类别(12个大调键、12个小调键和一个"无"键)的帧级概率。使用HookTheory[28]进行训练。Giantsteps[30]用作测试集。评估指标是mir_eval[27]中实现的精炼准确率(加权准确率),具有对合理错误给予部分信任的误差容限。
音乐标注包含各种音乐分类任务[31],如流派、情绪、乐器和语言分类。由于任何音乐属性都可以作为音乐标签,音乐标注作为综合的下游任务,用于衡量模型的 versatility。我们使用了广泛使用的MagnaTagATune数据集[32],包含流行的50个标签。我们保持了与先前研究[33]中使用的相同数据划分。评估指标是平均平均精度(mAP)和接收者操作特征曲线下面积(ROC-AUC)。
3.3 基础模型
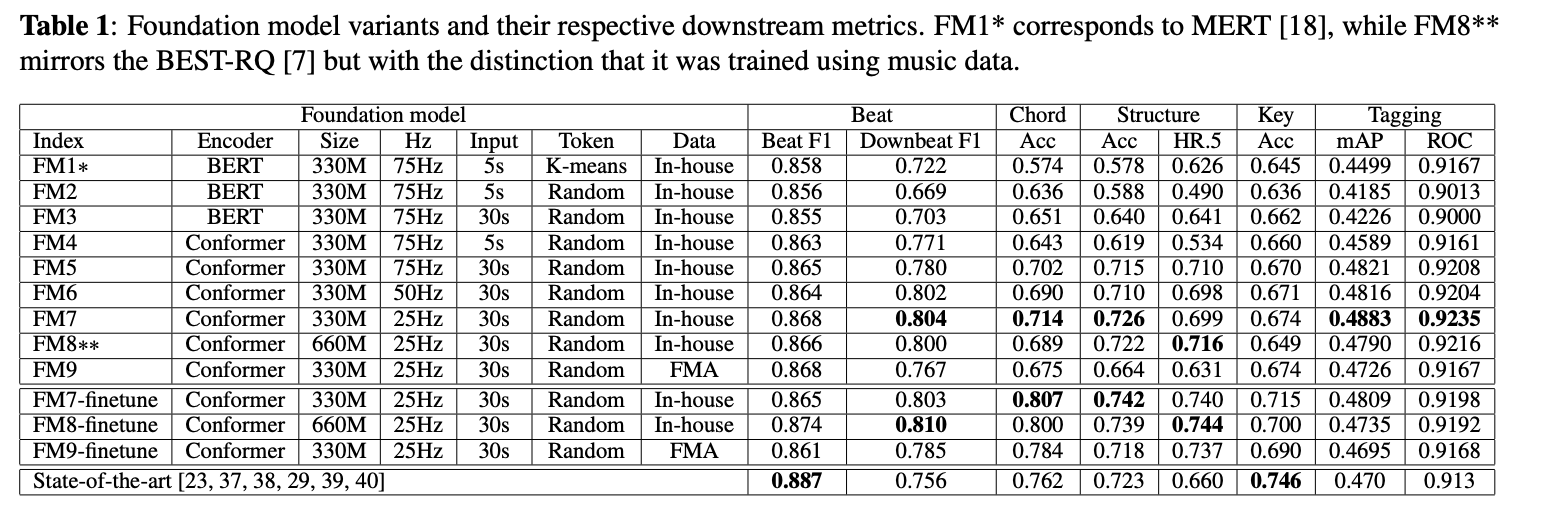
我们实施了一种自监督学习方法,如第2节所述,该方法密切遵循相关工作中概述的方法论[7]。该方法利用随机量化,消除了对单独表示学习的需求。与参考文献一致,我们的码本包含8192个16维向量。我们应用了400毫秒窗口和60%概率掩码,仅使用掩码段进行交叉熵损失优化。表1中的FM8遵循了先前语音领域工作BEST-RQ[7]的完全相同设置,除了数据。
在本研究中,我们旨在解决如何构建高级基础模型的基本问题。为实现这一目标,我们仔细检查每个组件以评估它们的个体影响。我们的研究包括对随机量化的探索、对各种架构(包括来自HuBERT[6]的BERT风格编码器和Conformer[20])的深入检查,同时考虑不同的模型大小配置,以及对变化的时间分辨率(即每秒标记数)、预训练的不同输入长度和两个不同数据集的调查。各种模型配置的总结可在表1中找到。
我们使用了学习率为0.0001的Adam优化器[34]。在30,000步上进行学习率预热在我们的训练过程中发挥了关键作用,特别是在使用float16时。为提高训练效率,我们使用了deepspeed[35]、flash attention[36]和混合精度技术。所有模型都使用八个A100-80GB GPU训练了两周。
4. 结果
本章展示我们的实验结果和发现。我们精心设计的消融研究阐明了开发成功的音乐基础模型的关键因素。
随机标记化[7]能够很好地泛化到音乐数据。尽管没有额外的表示学习阶段,它仍能有效获取适用于各种下游任务的有用表示。值得注意的是,即使随机标记化仅应用于梅尔频谱,它在和弦识别任务中的表现也超过了FM1(MERT)。这一成就尤其值得关注,因为FM1利用了额外的辅助任务,包括用于捕捉和声信息的常数Q变换(CQT)重建。在结构分析任务中,FM1和FM2之间最初存在性能差距,这归因于FM2省略了辅助任务,但通过使用更长的输入序列(FM3),这一差距得到了有效弥补。
标记级分类提供了对基础模型更全面的理解。当我们仅使用序列级分类(如音乐标注)比较各种模型时,很难辨别它们之间的显著差异。然而,标记级分类任务,特别是那些需要较长上下文的任务,如下拍跟踪和结构分析,清楚地暴露了在较短输入序列上训练的模型(FM2和FM4)的局限性。
训练期间使用的输入长度对于捕捉长期上下文至关重要。使用5秒输入进行预训练的基础模型(FM1、FM2和FM4)在音色相关任务(如音乐标注)或仅依赖局部上下文的任务(如节拍跟踪)中表现出色。然而,在下拍跟踪和结构分析等任务中,它们的性能低于使用30秒输入训练的模型。我们相信,先进的基础模型应该能够同时建模长期和短期上下文,因此推荐选择更长的输入。
在我们的实验设置中,时间分辨率的影响较小。具有25Hz时间分辨率的模型(FM7)表现出略优于其50Hz(FM6)和75Hz(FM5)对应模型的性能,同时由于序列长度较短,所需计算量更少。
模型架构带来显著差异。Conformer(FM5)在所有下游任务中 consistently 优于BERT编码器(FM3)。有趣的是,模型大小的影响相对较小(FM7和FM8)。然而,值得注意的是,更大的模型可能需要更长的训练和更精细的优化才能充分发挥其性能潜力。
数据在任何数据驱动方法中无疑至关重要。使用160k小时音乐音频预训练的模型(FM7)表现出比在8k小时FMA数据集上训练的模型(FM9)更好的性能。有两个因素可能导致这种差异:首先是可扩展性,其次是FMA的众包性质,包含大量噪声数据,影响了模型的泛化能力。
对基础模型进行微调进一步提高了下游性能。然而,我们确实在标注任务中观察到性能下降,这主要归因于过拟合。
5. 结论
在本研究中,我们对基础模型设置进行了全面调查,评估了它们在五个音乐信息检索任务中的效果,涵盖了标记级和序列级分类。我们的实验揭示了开发基础模型的六个关键因素。因此,我们的基础模型 consistently 超越了其前身的所有下游任务,在需要长期上下文的标记级分类任务中表现尤为显著。我们预计,这种增强的基础模型将做出有价值的贡献,不仅限于分类任务,还包括多模态检索和生成模型领域,因为它融入了更丰富的音乐上下文。