CV论文速递:覆盖视频生成与控制、图像视频修复、AIGC检测与隐私保护等方向!(10.06-10.10)
本周精选12篇CV领域前沿论文,覆盖视频生成与控制、图像/视频修复与生成(含3D)、AI生成内容检测与隐私保护、视频检索与机器人视觉等核心方向。全部200多篇论文,感兴趣的自取。
原文、姿料 这里!

一、视频生成与控制
1、FlexTraj: Image-to-Video Generation with Flexible Point Trajectory Control
作者:Zhiyuan Zhang, Can Wang, Dongdong Chen, Jing Liao
亮点:针对图像转视频生成中“轨迹控制灵活性不足”的痛点,提出统一的基于点的运动表示方案——为每个点编码分割ID、时间一致轨迹ID及可选颜色通道,支持密集与稀疏轨迹控制。区别于传统的token拼接或ControlNet注入方式,采用高效序列拼接策略,实现更快收敛、更强可控性与更高效推理,同时在非对齐条件下保持鲁棒性。通过退火训练策略逐步降低对完整监督与对齐条件的依赖,最终支持多粒度、与对齐无关的轨迹控制,可应用于运动克隆、拖拽式图像转视频、运动插值、相机重定向等多种场景。
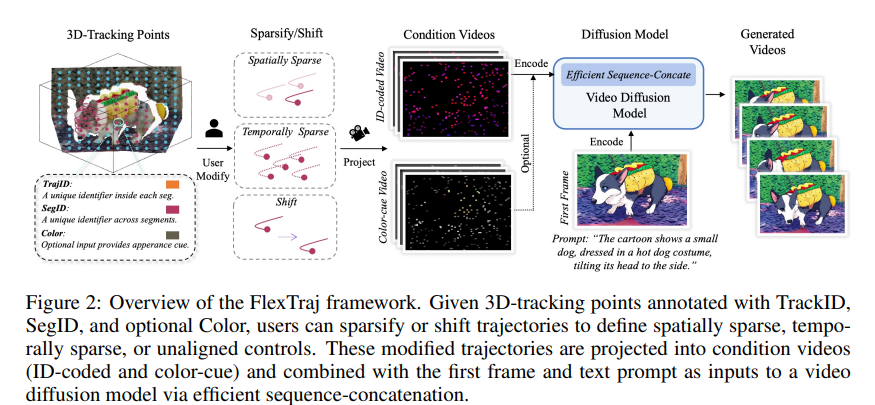
论文:(arxiv论文网址:https://arxiv.org/abs/2510.08527)
开源代码:https://bestzzhang.github.io/FlexTraj
Comments:聚焦图像转视频的精细化控制,为动态视觉生成提供更灵活的交互方式。
2、MATRIX: Mask Track Alignment for Interaction-aware Video Generation
作者:Siyoon Jin, Seongchan Kim, Dahyun Chung, Jaeho Lee, Hyunwook Choi, Jisu Nam, Jiyoung Kim, Seungryong Kim
亮点:解决视频DiT模型在多实例或主体-客体交互建模上的短板,首先构建MATRIX-11K数据集(含交互感知字幕与多实例掩码轨迹),并从“语义接地”(视频-文本注意力评估名词/动词token对实例及关系的捕捉)与“语义传播”(视频-视频注意力评估实例绑定的跨帧持续性)两个维度分析模型内部交互表示机制,发现交互相关效应集中在少量交互主导层。基于此提出MATRIX正则化方法,将视频DiT特定层注意力与掩码轨迹对齐,强化语义接地与传播能力;同时设计InterGenEval评估协议量化交互感知生成效果。实验表明,该方法提升交互保真度与语义对齐度,减少漂移与幻觉问题。
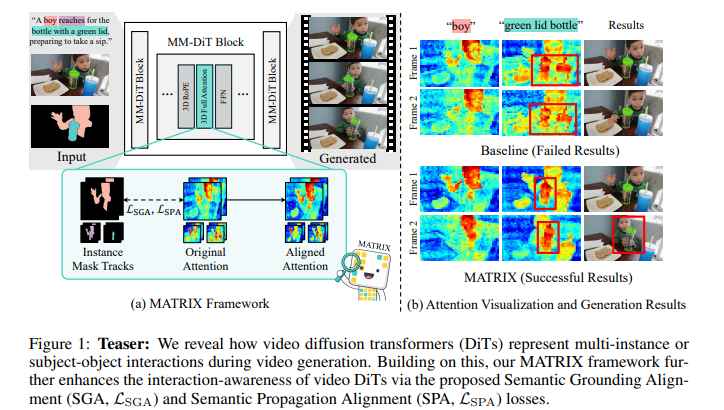
论文:(arxiv论文网址:https://arxiv.org/abs/2510.07310)
开源代码:https://cvlab-kaist.github.io/MATRIX/
Comments:从数据与模型双维度突破交互建模难题,为复杂动态场景生成提供新范式。
3、TTOM: Test-Time Optimization and Memorization for Compositional Video Generation
作者:Leigang Qu, Ziyang Wang, Na Zheng, Wenjie Wang, Liqiang Nie, Tat-Seng Chua
亮点:针对视频基础模型(VFM)在组合场景(运动、数量、空间关系)中的生成短板,提出无训练框架TTOM。区别于现有逐样本干预 latent 或注意力的方案,通过通用布局-注意力目标优化新增参数,实现推理时VFM输出与时空布局的对齐;将视频生成建模为流式场景,设计参数记忆机制维护历史优化上下文,支持插入、读取、更新、删除等灵活操作。实验证实TTOM可解耦组合世界知识,具备强迁移性与泛化性,在T2V-CompBench与Vbench基准上验证了其在跨模态对齐、组合视频生成上的有效性,兼顾实用性与高效性。
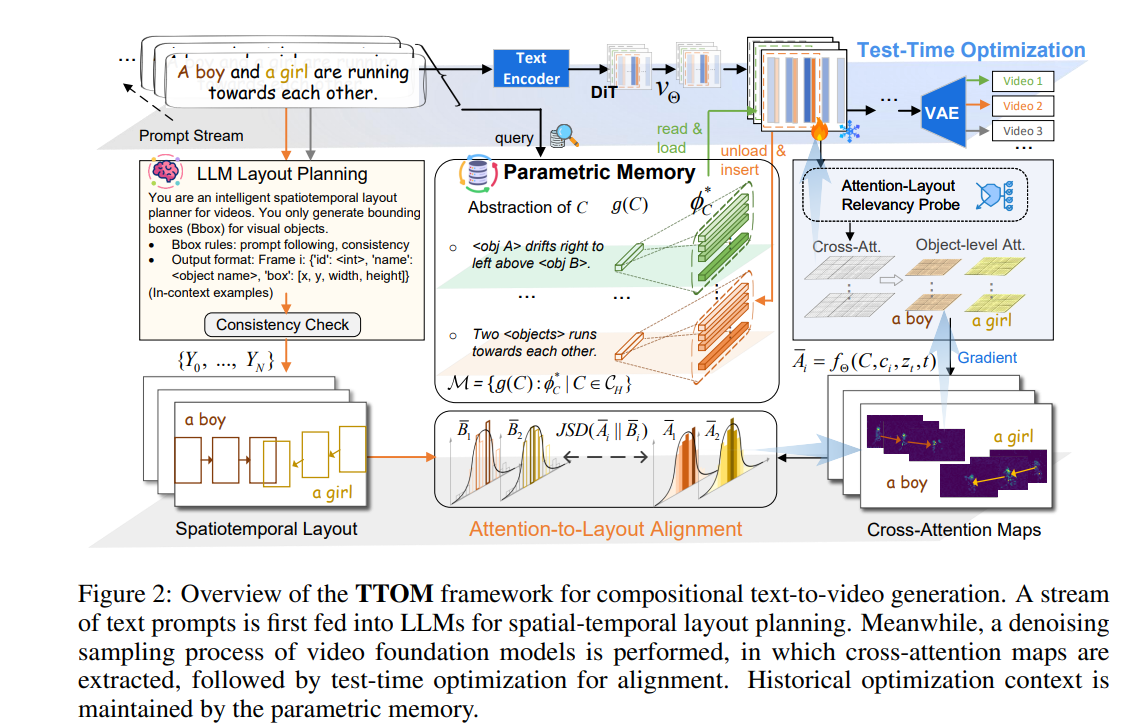
论文:(arxiv论文网址:https://arxiv.org/abs/2510.07940)
开源代码: https://ttom-t2v.github.io/
Comments:聚焦推理阶段优化,为组合性视频生成提供轻量高效的解决方案。
4、UniVideo: Unified Understanding, Generation, and Editing for Videos
作者:Cong Wei, Quande Liu, Zixuan Ye, Qiulin Wang, Xintao Wang, Pengfei Wan, Kun Gai, Wenhu Chen
亮点:突破现有多模态模型局限于图像领域的问题,提出视频领域统一建模框架UniVideo。采用双流设计:多模态大语言模型(MLLM)负责指令理解,多模态DiT(MMDiT)负责视频生成,兼顾复杂指令解析与视觉一致性保持。通过跨任务联合训练,将文本/图像转视频、上下文感知视频生成与编辑等多样化任务统一到多模态指令范式下。实验表明,其性能匹配或超越任务专用SOTA基线;更具备两种泛化能力:一是支持任务组合(如编辑+风格迁移),二是可从图像编辑数据迁移到未训练的自由形式视频编辑场景(如绿幕抠图、材质修改),同时支持视觉提示驱动的视频生成。
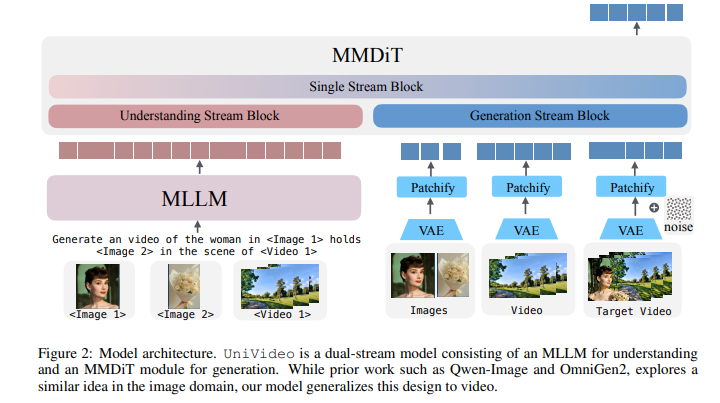
论文:(arxiv论文网址:https://arxiv.org/abs/2510.08377)
开源代码:https://congwei1230.github.io/UniVideo/
Comments:推动视频领域“理解-生成-编辑”全流程统一,为通用视频智能奠定基础。
二、图像/视频修复与生成(含3D)
1、One Stone with Two Birds: A Null-Text-Null Frequency-Aware Diffusion Models for Text-Guided Image Inpainting
作者:Haipeng Liu, Yang Wang, Meng Wang
亮点:针对文本引导图像修复中“未掩码区域保留”与“掩码-未掩码区域语义一致”难以兼顾的核心问题,提出NTN-Diff模型。通过分析发现,问题根源在于编码不同图像属性的混合频段(如中低频)在去噪过程中对文本提示的鲁棒性差异。将跨区域语义一致性分解为各频段一致性,同时保护未掩码区域;将去噪过程分为早期(高频噪声)与晚期(低频噪声)阶段,实现中低频段解耦:早期通过文本引导去噪逐步优化稳定的中频段以实现语义对齐,同时引导空文本去噪优化掩码区域低频段;晚期再通过文本引导去噪实现中低频段跨区域语义一致。实验证实其性能超越现有文本引导扩散模型SOTA。
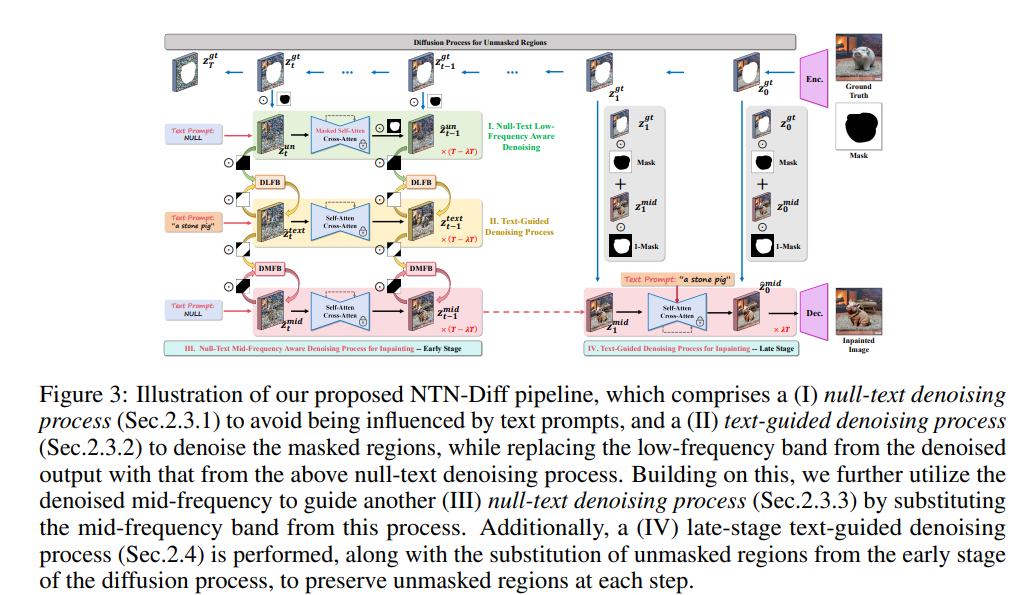
论文:(arxiv论文网址:https://arxiv.org/abs/2510.08273)
开源代码:https://github.com/htyjers/NTN-Diff
Comments: To appear NeurIPS 2025,从频段分解角度突破修复难题,实现“保区域+保语义”双重目标。
2、SViM3D: Stable Video Material Diffusion for Single Image 3D Generation
作者:Andreas Engelhardt, Mark Boss, Vikram Voletti, Chun-Han Yao, Hendrik P. A. Lensch, Varun Jampani
亮点:解决单图像3D生成中“反射率建模简单”或“需额外步骤估计反射率”的问题,提出SViM3D框架。扩展 latent 视频扩散模型,基于显式相机控制,在生成每个视图的同时输出空间变化的物理基渲染(PBR)参数与表面法向量,无需额外步骤即可支持重光照与外观编辑。引入多种机制优化这一病态问题,在多个物体中心数据集上实现SOTA的重光照与新视图合成性能,可泛化到多样化输入,生成可用于AR/VR、电影、游戏等领域的可重光照3D资产。
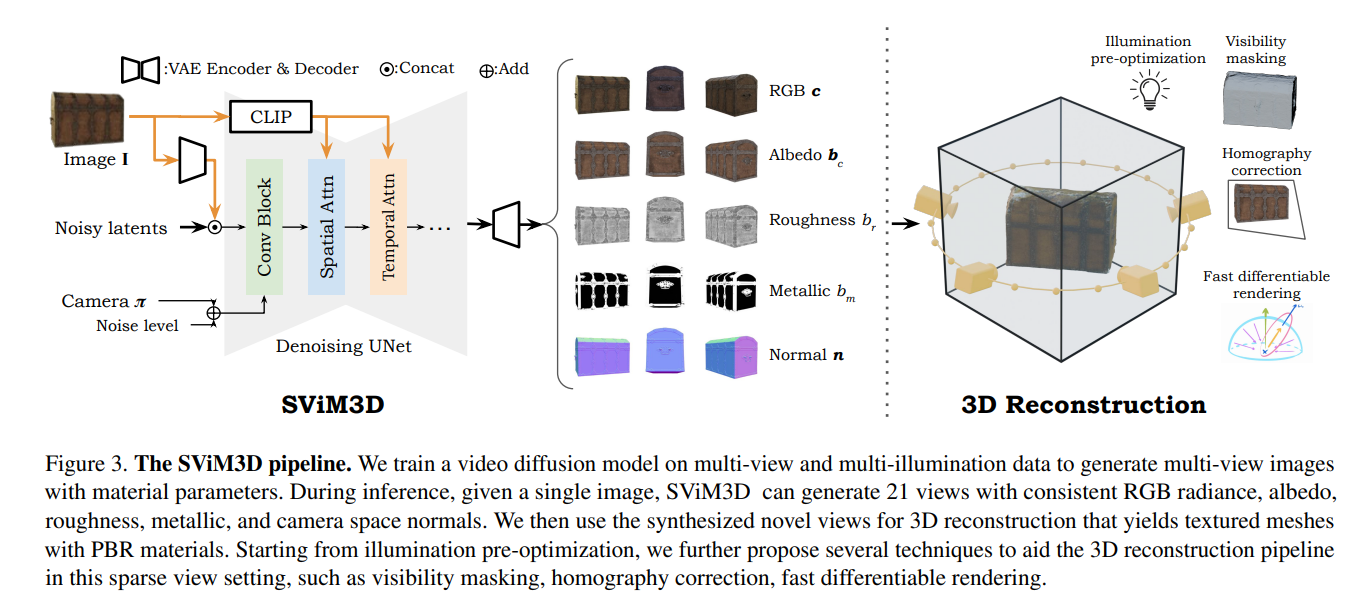
论文:(arxiv论文网址:https://arxiv.org/abs/2510.08271)
开源代码:http://svim3d.aengelhardt.com
Comments:Accepted by International Conference on Computer Vision (ICCV 2025),打通单图像到高质量3D资产的生成链路,兼顾效率与实用性。
3、Latent Harmony: Synergistic Unified UHD Image Restoration via Latent Space Regularization and Controllable Refinement
作者:Yidi Liu, Xueyang Fu, Jie Huang, Jie Xiao, Dong Li, Wenlong Zhang, Lei Bai, Zheng-Jun Zha
亮点:针对超高清(UHD)图像修复中“计算效率”与“高频细节保留”的权衡问题,提出两阶段框架Latent Harmony。第一阶段设计LH-VAE:通过视觉语义约束增强语义鲁棒性,通过渐进式退化扰动与 latent 等变性强化高频重建,解决传统VAE高斯约束丢弃退化相关高频信息的问题。第二阶段将优化后的VAE与修复模型联合训练,引入高频低秩适应(HF-LoRA):编码器LoRA由保真度导向的高频对齐损失驱动以恢复真实细节,解码器LoRA由感知导向损失驱动以合成真实纹理;通过交替优化与选择性梯度传播训练LoRA,保留预训练 latent 结构。推理时可通过可调参数α灵活权衡保真度与感知质量,在UHD及标准分辨率修复任务上实现SOTA。
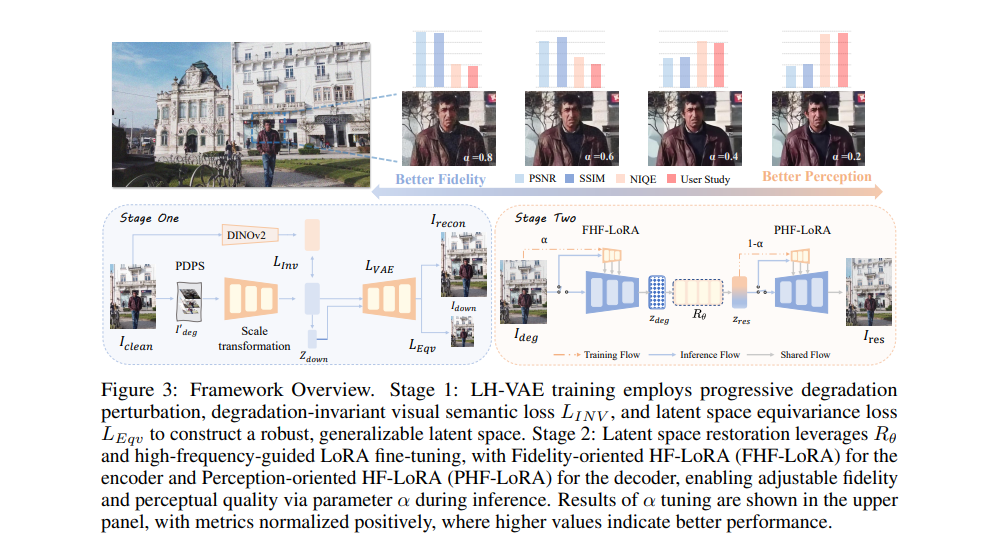
论文:(arxiv论文网址:https://arxiv.org/abs/2510.07961)
开源代码:https://github.com/lyd-2022/Latent-Harmony
Comments:Accepted by NeurIPS 2025,为UHD图像修复提供“高效+高质量”的统一解决方案,兼顾工程实用性与视觉效果。
三、AI生成内容检测与隐私保护
1、Physics-Driven Spatiotemporal Modeling for AI-Generated Video Detection
作者:Shuhai Zhang, ZiHao Lian, Jiahao Yang, Daiyuan Li, Guoxuan Pang, Feng Liu, Bo Han, Shutao Li, Mingkui Tan
亮点:针对AI生成视频(如Sora)视觉真实性高、检测难度大的问题,提出基于概率流守恒原理的物理驱动检测范式。设计归一化时空梯度(NSG)统计量,量化空间概率梯度与时间密度变化的比值,直接捕捉违背自然视频动力学的细微异常。基于预训练扩散模型,无需复杂运动分解,通过空间梯度近似与运动感知时间建模开发NSG估计器,同时保留物理约束。进一步提出NSG-VD检测方法,计算测试视频与真实视频NSG特征的最大均值差异(MMD)作为检测指标,并从理论上推导真实与生成视频NSG特征距离的上界,证实生成视频因分布偏移会表现出更大差异。实验表明,NSG-VD在召回率(+16.00%)与F1分数(+10.75%)上超越SOTA基线。
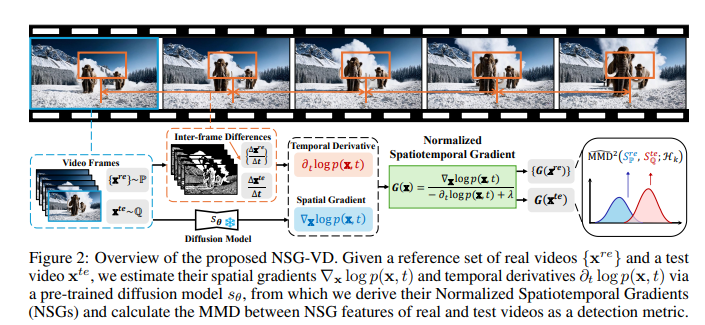
论文:(arxiv论文网址:https://arxiv.org/abs/2510.08073)
开源代码:https://github.com/ZSHsh98/NSG-VD
Comments:Accepted at NeurIPS 2025 spotlight,从物理规律角度突破AI生成视频检测瓶颈,兼具理论严谨性与实践有效性。
2、The impact of abstract and object tags on image privacy classification
作者:Darya Baranouskaya, Andrea Cavallaro
亮点:聚焦图像隐私分类中“标签类型选择”的问题,区分“对象标签”(描述具体实体,常用于计算机视觉任务)与“抽象标签”(捕捉高层信息,适用于上下文相关、主观场景理解)。通过实验分析两类标签在隐私分类中的作用:当标签预算有限时,抽象标签效果更优;当可使用更多标签时,对象标签信息价值与抽象标签相当。研究结果为设计更精准的图像隐私分类器提供指导,明确了不同标签类型与数量对隐私分类性能的影响,填补了“标签类型与隐私分类关联”的研究空白。
论文:(arxiv论文网址:https://arxiv.org/abs/2510.07976)
Comments:This work has been submitted to the ICASSP 2026,从标签语义粒度角度优化隐私分类,为视觉隐私保护提供新的设计思路。
四、视频检索与机器人视觉
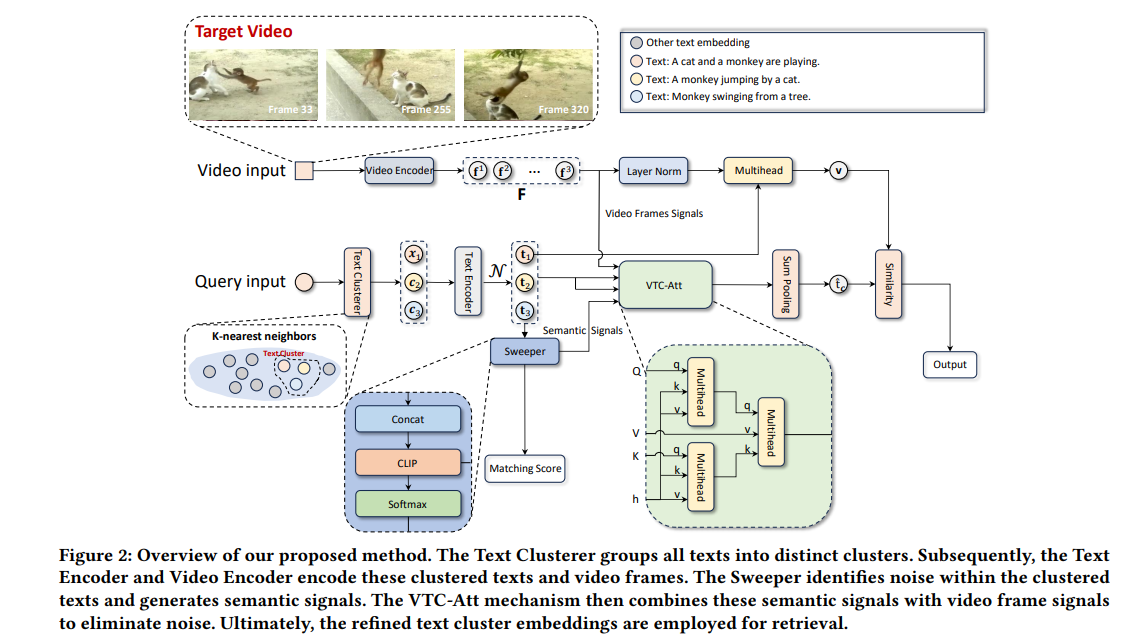
1、Queries Are Not Alone: Clustering Text Embeddings for Video Search
作者:Peyang Liu, Xi Wang, Ziqiang Cui, Wei Ye
亮点:解决传统视频检索“依赖文本查询与视频元数据直接匹配,难以弥合文本描述与视频多维度内容语义鸿沟”的问题,提出Video-Text Cluster(VTC)框架。核心创新在于:通过独特聚类机制对相关文本查询分组,捕捉查询的多解释与细微差异,扩大语义覆盖范围;设计Sweeper模块识别并消除聚类中的噪声,提升聚类质量;引入Video-Text Cluster-Attention(VTC-Att)机制,基于视频内容动态调整聚类内注意力权重,聚焦最相关文本特征。在五个公共数据集上的实验证实,VTC框架性能超越现有SOTA视频检索模型,显著提升检索语义对齐度。
论文:(arxiv论文网址:https://arxiv.org/abs/2510.07720)
Comments:Accepted by International ACM SIGIR Conference on Research and Development in Information Retrieval 2025,从查询聚类角度优化视频检索,为大规模视频内容检索提供高效方案。
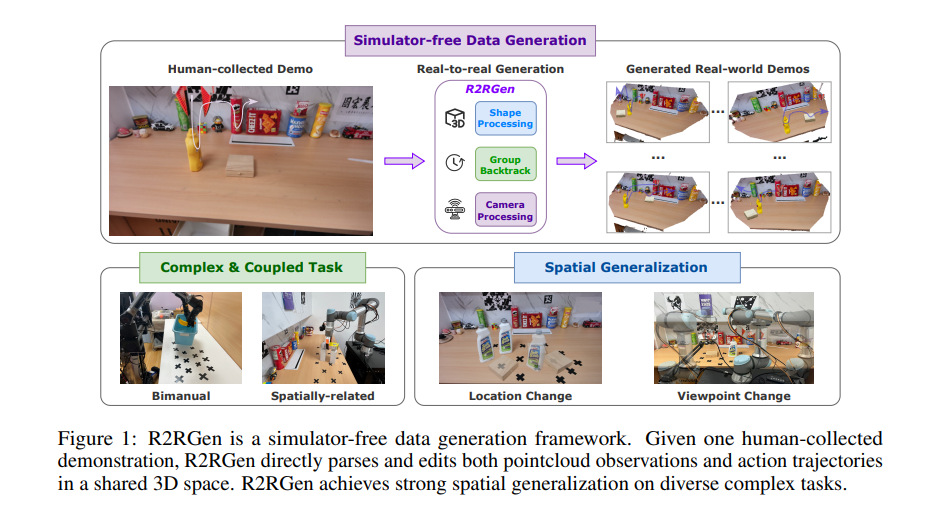
2、R2RGEN: Real-to-Real 3D Data Generation for Spatially Generalized Manipulation
作者:Xiuwei Xu, Angyuan Ma, Hankun Li, Bingyao Yu, Zheng Zhu, Jie Zhou, Jiwen Lu
亮点:针对机器人操作空间泛化能力不足、需大量人类演示覆盖不同空间配置的问题,提出无模拟器、无渲染的Real-to-Real 3D数据生成框架R2RGen。给定单源演示,首先通过标注机制实现场景与轨迹的细粒度解析;设计组级增强策略,处理复杂多物体组合与多样化任务约束;引入相机感知处理,使生成数据分布与真实世界3D传感器数据对齐。该框架可直接增强点云观测-动作对以生成真实世界数据,具备即插即用特性。实验证实R2RGen大幅提升数据效率,在移动操作场景中展现出强扩展性与应用潜力,为机器人视觉的空间泛化提供数据驱动解决方案。
论文:(arxiv论文网址:https://arxiv.org/abs/2510.08547)
开源代码: https://r2rgen.github.io/
Comments:突破“ sim-to-real 鸿沟”,为机器人操作的真实世界数据增强提供新路径。