【组队学习】Post-training-of-LLMs TASK01
文章目录
- 大模型训练
- 后训练方法概述
- 后训练技术介绍
- 后训练
- 预训练
- 后训练方法
- 成功的后训练需要确保三个关键要素
- 大模型后训练场景
大模型训练
预训练阶段:模型学习预测下一个词或标记。从计算和成本角度看,这是训练的主体部分,通常需要在数万亿甚至数十万亿文本标记上进行训练。对于超大规模模型,这一过程可能耗时数月。
后训练阶段:模型通过进一步训练以执行更具体的任务(例如回答问题)。此阶段通常使用规模小得多的数据集,训练速度更快且成本更低。
后训练方法概述
-
监督微调(SFT):通过带标注的提示-响应对训练模型,使其学会遵循指令或使用工具,核心在于让模型模仿输入提示与输出响应之间的映射关系。该技术特别适用于引入新行为或对模型进行重大调整。在课程中,您将动手对一个千问小模型进行指令遵循微调。
-
直接偏好优化(DPO):通过向模型展示同一提示下的优质(y_w)与劣质答案(y_l)。驱动模型学习。DPO通过构造性损失函数,使模型趋近优质响应而远离劣质响应。例如,若模型当前回复“我是你的助手”,而您希望其回答“我是你的AI助手”,则可将前者标记为劣质响应,后者标记为优质响应。您将使用DPO调整一个Qwen指令模型的“身份认知”。
DPO的目标是调整模型参数,使得模型赋予y_w的概率高于y_l- 训练流程:首先通常使用监督微调(SFT)后的模型作为参考模型,然后给定相同的提示,参考模型和目标模型分别生成各自的回答,接着根据人类的反馈或预定义的标准,标注这两个回答的相对优劣,最后使用 DPO 损失函数直接优化目标模型的参数,使其生成更符合人类偏好的输出。
- 优势:DPO 在计算上更轻量、速度更快,且在对齐效果上与 RLHF 相当。它特别适用于没有明确正确答案,而主观因素如语气、风格或特定内容偏好很重要的场景。此外,DPO 也使模型能够从正例和负例中学习,并且客户更容易生成高质量训练数据集,因为他们可以基于用户日志、A/B 测试或较小的手动注释工作收集偏好数据。
- 数据格式:DPO 文件的格式与监督微调不同,客户需要提供包含系统消息和初始用户消息的 “对话”,然后是带有成对偏好数据的 “完成项”。用户只能提供两个完成项,数据集包含三个顶级字段:“input”“preferred_output” 和 “non_preferred_output”,训练数据集必须是 jsonl 格式。
- 与RLHF的区别:RLHF需要训练模型奖励模型和进行强化学习,涉及多个阶段,计算成本高。且训练过程可能不稳定,超参数敏感。而 DPO 通过数学推导,将偏好优化问题转化为一个简单的监督学习任务,绕过了奖励模型和强化学习的复杂性,计算效率更高,稳定性更强。
-
在线强化学习(Online RL):
- 技术核心
让模型接收提示并生成响应,再由奖励函数对回答质量评分,模型依据奖励分数更新自身。 - 获取奖励函数的方式
- 基于人类评判训练评分函数:训练出与人类判断一致的评分函数,最常用算法为近端策略优化。
- 利用可验证奖励:适用于数学、编程等有客观正确性标准的任务,如用数学验证器或单元测试判定生成的解题步骤或代码是否正确,将这种正确性度量作为奖励函数。针对此类奖励函数,DeepSeek 团队提出的 GRPO 算法是高效实现方案。
- 课程应用
在本课程中,将使用 GRPO 训练一个 Qwen 小模型解决数学问题。
- 技术核心
后训练技术介绍
后训练
首先了解什么是后训练。通常训练语言模型时,我们会从随机初始化的模型开始进行预训练。这个阶段的目标是从各类数据源学习知识,包括维基百科、全网爬取的Common Crawl数据,或GitHub的代码数据。完成预训练后,我们将获得一个基础模型,它能够预测下一个词或标记——如图所示,每个标记代表一个子词单元。
以此基础模型为起点,下一步我们将进行后训练,其核心目标是从精心筛选的数据中学习响应模式。这类数据包括对话数据、工具使用数据或智能体数据。通过此过程,模型将升级为指令模型或对话模型,能够对指令作出响应或与用户进行交流。当被问及"巴黎是哪个国家的首都"时,模型将能准确回答"巴黎是法国的首都"。
在此基础之上,我们还可以进一步开展后训练,以调整模型行为或增强特定能力。最终我们将获得一个定制化模型,该模型可专精于特定领域或具备特定行为模式。例如在本案例中,模型将能够针对各类指令生成更优质的SQL查询语句。
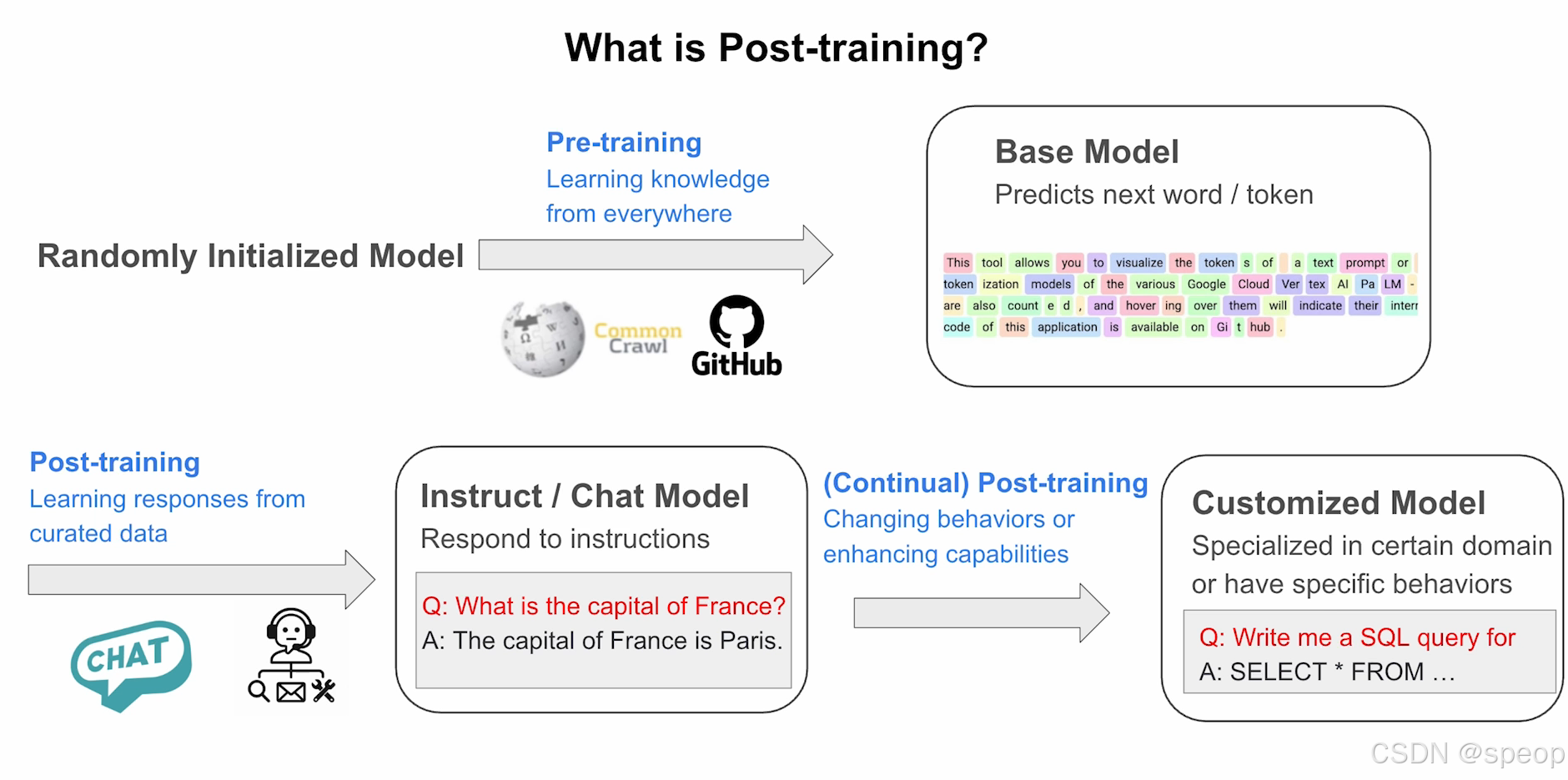
预训练
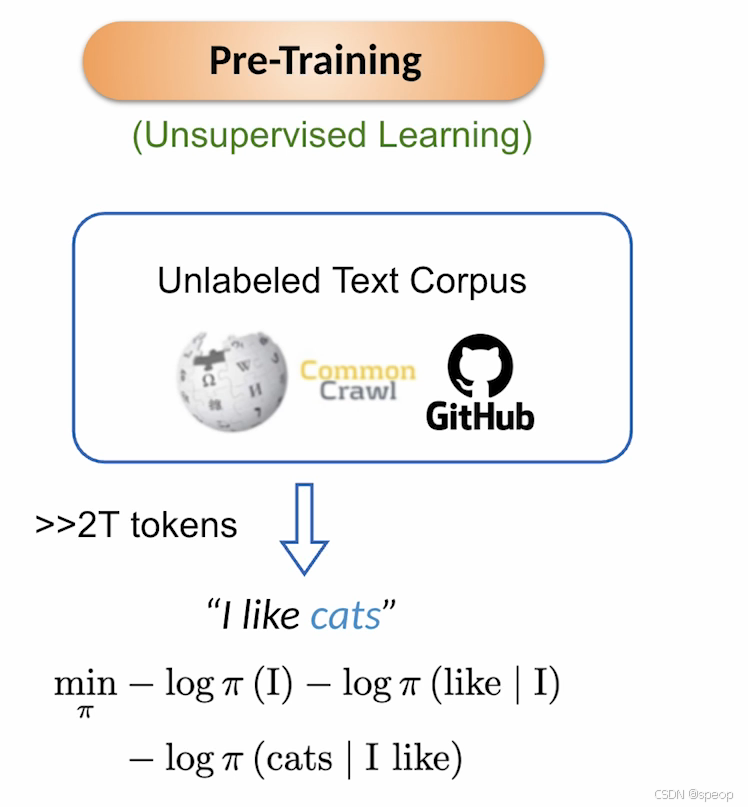
预训练通常被视为无监督学习,其起点是大规模无标注文本语料(如维基百科、Common Crawl或GitHub等)。通常可从这些语料中提取超过2万亿个标记进行训练。
以最小示例说明,当输入"我喜欢猫"这样的句子时,模型会基于前面所有标记来最小化每个标记的负对数概率:首先最小化"我"的负对数概率,然后是给定"我"时"喜欢"的负对数似然,最后是给定"我喜欢"时"猫"的概率。通过这种方式,模型被训练成能根据已见标记预测下一个标记。
后训练方法
完成预训练后,接下来会采用不同的后训练方法:
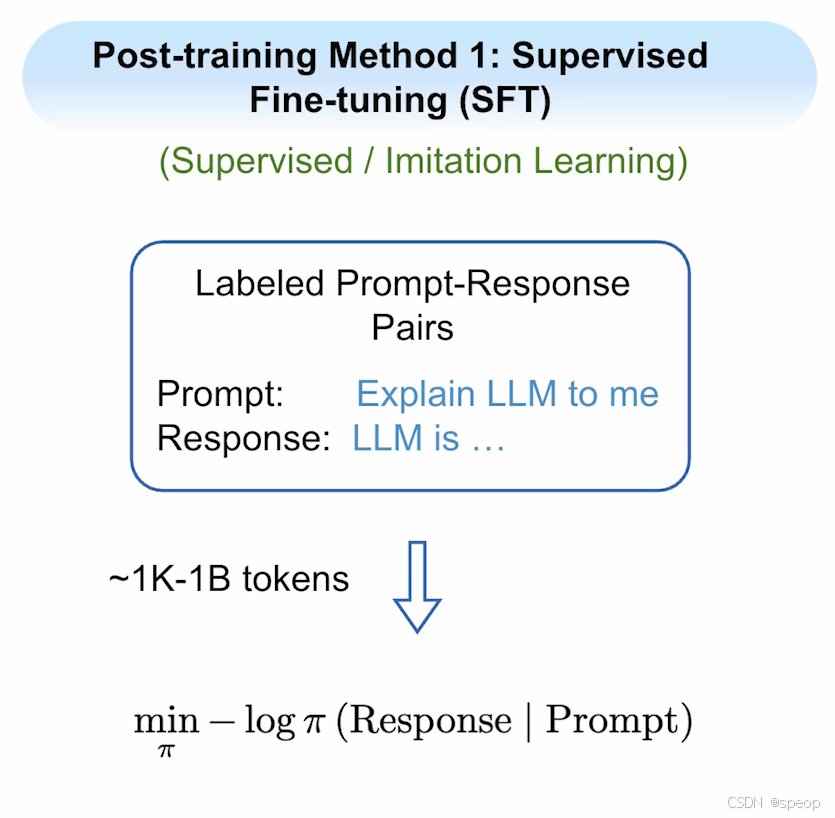
- 监督微调(SFT):作为最简单且最流行的后训练方法,它属于监督学习/模仿学习范畴。需要创建包含标注的提示-响应对数据集,其中提示通常是给模型的指令,响应则是模型应有的理想回答。此过程仅需1,000至10亿个标记,远少于预训练规模。其训练损失的关键区别在于:仅对响应标记进行训练,而不涉及提示标记。
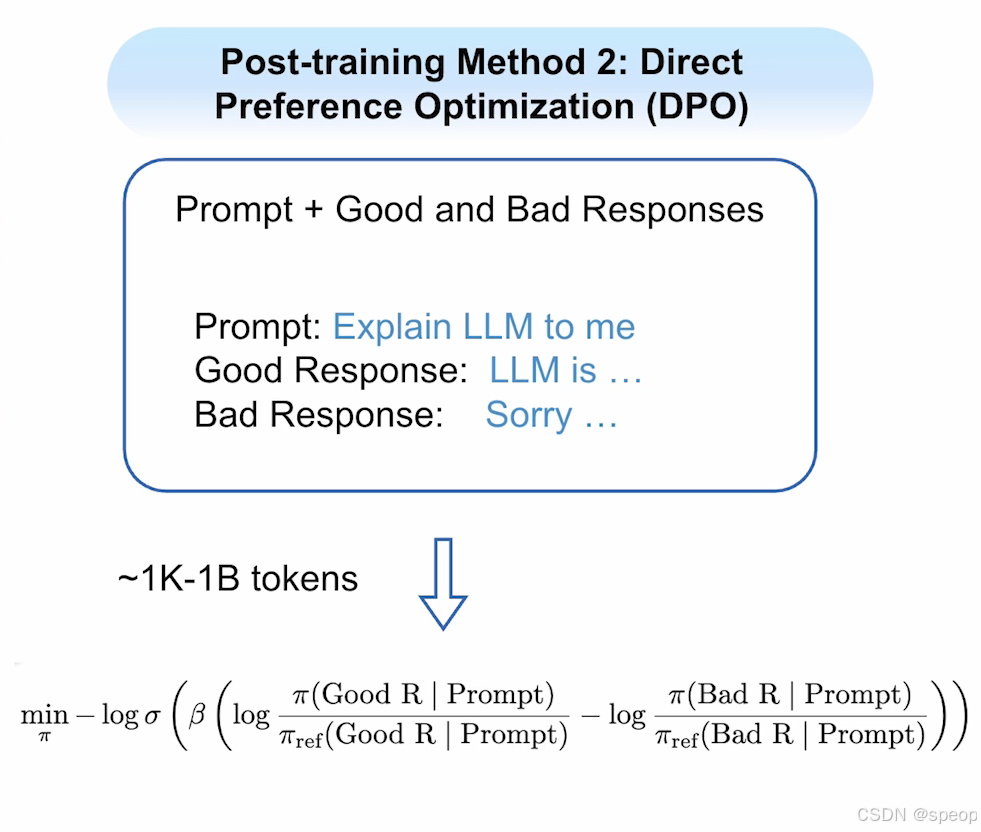
- 直接偏好优化(DPO):该方法需要创建包含提示及其对应优质/劣质响应的数据集。针对任一提示,可生成多个响应并筛选出优质与劣质样本。训练目标是使模型远离劣质响应并学习优质响应。该方法同样仅需1,000至10亿个标记,并采用更复杂的损失函数(后续课程将详细展开)。
- 在线强化学习(Online RL):此方法只需准备提示集和奖励函数。从提示开始,让语言模型生成响应,再通过奖励函数对该响应进行评分,最后利用该信号更新模型。通常需要1,000至1,000万(或更多)个提示,目标是通过模型自身生成的响应来最大化奖励值。

| 后训练方法 | 核心思想 | 数据需求 | 训练目标 | 标记规模范围 | 损失函数特点 | 典型应用场景 |
|---|---|---|---|---|---|---|
| 监督微调(SFT) | 基于标注的“提示-响应”对,让模型模仿人类理想回答(监督学习) | 包含明确指令(提示)和理想回答(响应)的标注数据集 | 最小化响应部分标记的负对数概率,仅优化响应内容 | 1,000–10亿个标记 | 简单,仅对响应标记计算损失(忽略提示标记) | 基础指令跟随(如问答、文本生成)、对齐基础语言风格 |
| 直接偏好优化(DPO) | 通过优质/劣质响应对比,让模型学习偏好排序(偏好学习) | 包含提示及对应优质、劣质响应的对比数据集(无需人工打分,仅需排序) | 最大化优质响应相对于劣质响应的概率,使模型向优质方向优化 | 1,000–10亿个标记 | 复杂,基于优质/劣质响应的概率比设计损失(如交叉熵变体) | 对齐人类偏好(如回答相关性、无害性)、优化生成内容的质量排序 |
| 在线强化学习(Online RL) | 让模型自主生成响应,通过奖励函数评分反馈更新模型(强化学习) | 仅需提示集和可量化的奖励函数(无需预标注响应) | 最大化模型生成响应的奖励值,通过自我迭代提升长期表现 | 1,000–1,000万+个提示 | 基于奖励信号的策略优化(如PPO、GRPO),需平衡探索与利用 | 动态优化任务(如数学解题、代码生成)、需要持续适应环境反馈的场景 |
成功的后训练需要确保三个关键要素
后训练需要做好3个要素
| 数据与算法协同设计 | 可靠且高效的库 |
|---|---|
| - 监督微调(SFT) - 直接偏好优化(DPO) - 强化(Reinforce)/在线强化学习优化(RLOO) - 生成式随机策略优化(GRPO) - 近端策略优化(PPO) - …… | - Huggingface TRL - OpenRLHF - veRL - Nemo RL |
合适的评估体系
- 数据与算法的协同设计:如前所述,后训练有多种方法选择(SFT、DPO及各在线强化学习算法等),每种方法所需的数据结构略有不同。良好的协同设计对后训练成效至关重要。
- 可靠高效的算法库:HuggingFace TRL作为首批易用库之一,实现了大部分前述算法,本课程将主要使用该库进行编程实践。此外还推荐Open RLHF、veRL和Nemo RL等更精密、内存效率更高的库。
- 合适的评估体系:需通过完善的评估方案追踪模型在后训练前后的表现,确保模型性能持续优良。现有流行语言模型评估标准包括:
- 对话机器人竞技场:基于人类偏好的聊天评估
- 替代人类评判的LLM评估:AlpacaEval、MT Bench、Arena Hard
- 指令模型静态基准:LiveCodeBench(热门代码基准)、AIME 2024/2025(高难度数学评估)
- 知识与推理数据集:GPQA、MMLU Pro
- 指令遵循评估:IFEval
- 函数调用与智能体评估:BFCL、NexusBench、TauBench、ToolSandbox(后两者专注多工具使用场景)

大模型后训练场景

你真的需要训练后处理吗?
使用场景
- 遵循几条指令(不讨论XXX)
- 查询实时数据库或知识库
- 创建医疗大语言模型(LLM)/网络安全大语言模型
- 严格遵循20条以上指令;提升特定能力(“创建强大的SQL/函数调用/推理模型”)
方法
- 提示工程
- 检索增强生成(RAG)或搜索
- 持续预训练 + 训练后处理
- 训练后处理
特点
- 简单但脆弱:模型可能并非总能遵循所有指令
- 适应快速变化的知识库
- 注入大规模领域知识(超过10亿个标记),这些知识在预训练期间未被模型接触过
- 可靠地改变模型行为并提升特定能力;如果操作不当,可能会降低其他能力
最后,并非所有用例都需要进行模型后训练:
- 若仅需模型遵循少量指令(如回避敏感话题或禁止公司间比较),通过提示工程即可实现,但该方法虽简单却不够稳定
- 如需查询实时数据库,检索增强生成或基于搜索的方法可能更适用
- 创建领域专用模型(如医疗或网络安全语言模型)时,通常需要持续预训练结合标准后训练,先让模型学习领域知识(至少需10亿标记),再学习用户交互
负对数概率(Negative Log Probability, NLL) 作为损失函数
- 概率意义:衡量预测的“可信度”
模型预测下一个标记时,会输出一个概率分布(如对词汇表中所有词的概率分配)。对于正确的标记(如“猫”),我们希望模型赋予它的概率尽可能高。
- 若正确标记的概率为ppp(0 < p≤ 1),则其“可信度”与ppp正相关(p越大,预测越可信)
- 但直接用ppp作为优化目标存在问题:概率值范围是(0,1],且多个标记的概率相乘会导致数值下溢(如多个小概率相乘趋近于 0)。
- 数学便利性:将“最大化概率”转化为“最小化损失”
预训练的目标是最大化正确标记的概率(即让模型更可能预测出正确答案)。但机器学习中习惯用 “损失函数最小化” 来定义优化目标,而对数函数的单调性可实现这种转化:
- 对概率p取对数(log§):由于log是单调递增函数,“最大化p"等价于“最大化log§”。
- 加负号(- log§):将“最大化log§”转化为"最小化-log§”,符合损失函数“越小越好”的定义。
例如: - 若正确标记的概率p= 0.8,则-log(0.8)≈ 0.22(损失小,预测好);
- 若p = 0.1,则-log(0.1)≈ 2.3(损失大,预测差)。
- 信息论解释:与“自信息”的一致性
在信息论中,一个事件的自信息(Self-Information)定义为- log§,表示“该事件发生所包含的信息量”:
- 概率越小的事件(如罕见词),自信息越大(发生时携带的信息量越多):
- 概率越大的事件(如常见词),自信息越小。
预训练中,模型需要“学习语言的规律”,本质是理解不同标记出现的“信息量”。用负对数概率作为损失,等价于让模型最小化“正确标记的自信息”——即让模型学会“常见的标记,应该被更轻松地预测(损失小),罕见的标记允许更高的损失,但仍需尽可能准确”。
总结
-负对数概率(NLL)作为预训练损失函数,核心是:
- 利用对数单调性将 “最大化正确概率” 转化为 “最小化损失”,适配机器学习优化框架;
- 避免概率相乘的数值下溢问题,计算更稳定;
- 与信息论中的自信息概念一致,符合语言建模的本质(学习标记出现的规律)。