涉县网站网络推广培训哪里好
写在前面
本文是基于github开源社区datawhale学习记录原文学习地址,由于原文是基于huggingface的Transformers比较老的版本v4.39.0(原文源码地址:),而本文准备基于当前master分支(20250819-v4.55.2),做下学习记录
前期准备
开发环境准备
开发工具
pycharm、minianconda
创建环境
# 创建项目的虚拟环境,并指定Python版本
conda create -n python3.11 python=3.11
# 没有独显,装的是cup
pip3 install torch torchvision版本说明
python3.11,主要是window老电脑没有独显,用的cup跑Pytorch,支持的最高版本就是3.11了。
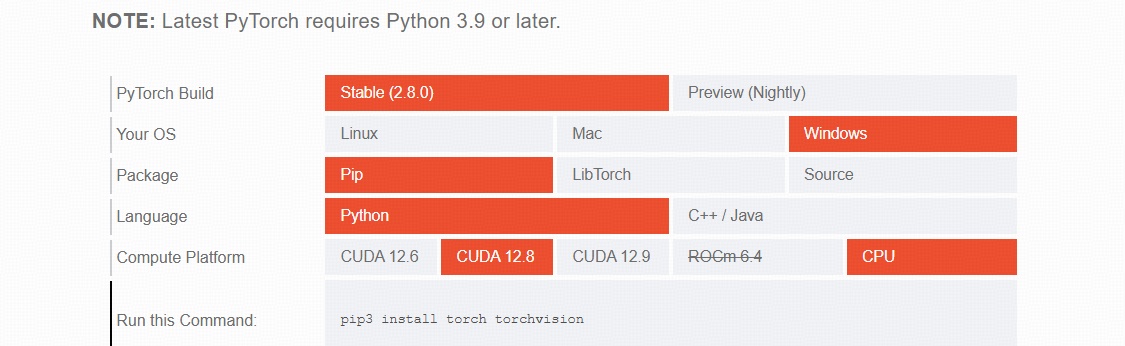
Pytorch 根据自己电脑选择,复制Commend即可
工程目录
直接在src/transformers/models/qwen2目录下新增一个测试文件:
测试代码
# jeremy_test.py
from transformers import Qwen2Model, Qwen2Config,AutoTokenizer
import torchif __name__ == '__main__':# ************ 0-前置配置:******************# 创建Qwen2模型配置对象,设置更小的模型参数用于本地测试myConfig = Qwen2Config(vocab_size=151936, # 保持词汇表大小不变hidden_size=512, # 从2048减小到512intermediate_size=1376, # 从11008减小到1376num_hidden_layers=4, # 从32减小到4层num_attention_heads=8, # 从32减小到8个注意力头num_key_value_heads=4, # 添加这个参数,默认是32,确保能整除num_attention_headsmax_position_embeddings=512 # 从1024减小到512)# ************ 1-使用Qwen2的分词器对文本进行编码******************# 文本输入texts = ["Hello, I'm Jeremy.","I am learning to use transformers models."]# 加载分词器tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B", trust_remote_code=True)# 使用分词器将文本转换为input_idsencoded = tokenizer(texts,padding=True, # 填充到相同长度truncation=True, # 截断超过最大长度的序列max_length=64, # 最大序列长度return_tensors="pt" # 返回PyTorch张量)input_ids = encoded['input_ids']# ********************* 2-主干(重点Debug) *************************# 创建Qwen2模型实例:__init__myModel = Qwen2Model(myConfig)# 进行前向传播:forwardresult = myModel(input_ids)print("Output shape:", result.last_hidden_state.shape)print("Output sample:", result.last_hidden_state[0, 0, :10]) # 打印部分输出结果
执行结果
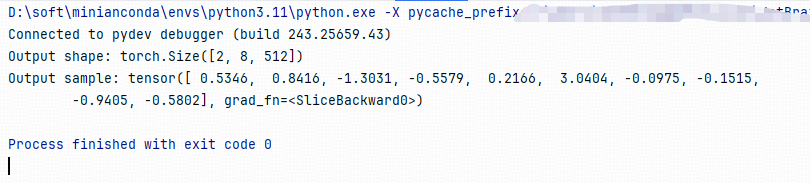
接下里咱们就开始撸袖子慢慢断点啦
代码梳理
文件目录

modular_qwen2


其中Model大部分很多是空实现,直接调用父类。所以这里重点关注下Qwen2MLP

整体架构
核心思想
Qwen2 的核心思想是:基于 Transformer 解码器架构,通过优化归一化、位置编码、注意力机制和工程实现,在保证模型理解与生成能力的同时,提升效率、扩展性和长文本处理能力
模型结构详解
该图摘自原博客,超级清晰了,细心的小伙伴应该可以发现测试入口函数也是据此开始码的呢
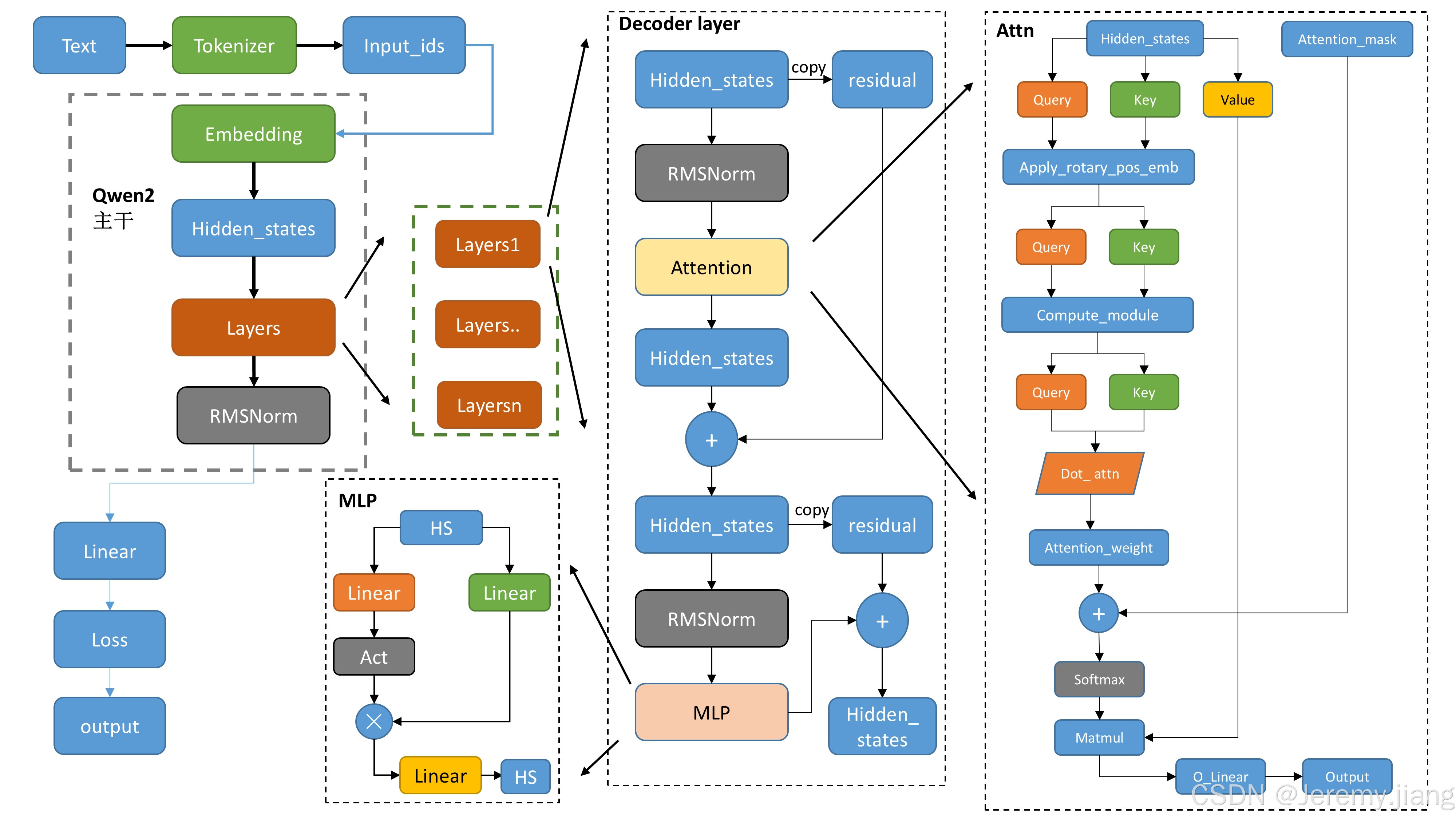
一、整体流程:文本 → Token → 隐藏态 → 输出
输入层(左上方)
Text → Tokenizer → Input_ids:文本经分词器(Qwen2Tokenizer)转换为 token 索引(input_ids),对应代码中 tokenize 逻辑。
Input_ids → Embedding → Hidden_states:索引经词嵌入层(nn.Embedding)映射为向量(hidden_states),代码中 Qwen2Model 的 embed_tokens 实现。
二、主干网络:多层 Decoder Layer
每个Qwen2DecoderLayer,进行如下操作:步骤
- copy hidden_states 作为残差
- 先经 RMSNorm 归一化(Qwen2RMSNorm)
- 进入seff_attn (Qwen2Attention )
- 通过残差连接(residual)叠加原始信息
- copy hidden_states 作为残差
- 再经 RMSNorm 归一化(Qwen2RMSNorm)
- 进入 mlp-前馈神经网络
- 三个线性层+激活函数
- 其中对gate_proj输出经过激活函数处理并与up_proj变换后再乘以up_proj,整体作为down_proj输入进行线性变换
- 再次通过残差连接(residual)叠加原始信息
Qwen2DecoderLayer
class Qwen2DecoderLayer(GradientCheckpointingLayer):def __init__(self, config: Qwen2Config, layer_idx: int):super().__init__()self.hidden_size = config.hidden_size# self_attn:自注意力机制self.self_attn = Qwen2Attention(config=config, layer_idx=layer_idx)# mlp:多头注意力机制self.mlp = Qwen2MLP(config)# norm:层归一化self.input_layernorm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)self.post_attention_layernorm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)self.attention_type = config.layer_types[layer_idx]def forward(self,hidden_states: torch.Tensor,attention_mask: Optional[torch.Tensor] = None,position_ids: Optional[torch.LongTensor] = None,past_key_value: Optional[Cache] = None,use_cache: Optional[bool] = False,cache_position: Optional[torch.LongTensor] = None,position_embeddings: Optional[tuple[torch.Tensor, torch.Tensor]] = None, # necessary, but kept here for BC**kwargs: Unpack[TransformersKwargs],) -> tuple[torch.Tensor]:# 1、copy hidden_states 作为残差residual = hidden_states# 2、先经 RMSNorm 归一化(Qwen2RMSNorm)hidden_states = self.input_layernorm(hidden_states)# 3、进入seff_attn (Qwen2Attention )hidden_states, _ = self.self_attn(hidden_states=hidden_states,attention_mask=attention_mask,position_ids=position_ids,past_key_value=past_key_value,use_cache=use_cache,cache_position=cache_position,position_embeddings=position_embeddings,**kwargs,)# 4、通过残差连接(residual)叠加原始信息hidden_states = residual + hidden_states# Fully Connected# 5、copy hidden_states 作为残差residual = hidden_states# 6、再经 RMSNorm 归一化(Qwen2RMSNorm)hidden_states = self.post_attention_layernorm(hidden_states)# 7、进入 mlp-前馈神经网络hidden_states = self.mlp(hidden_states)# 8、通过残差连接(residual)叠加原始信息hidden_states = residual + hidden_statesreturn hidden_states
Qwen2RMSNorm
class Qwen2RMSNorm(nn.Module):def __init__(self, hidden_size, eps=1e-6):"""初始化Qwen2RMSNorm层,实现均方根归一化操作,等价于T5LayerNormArgs:hidden_size (int): 隐藏层维度大小,用于初始化权重参数的维度eps (float, optional): 用于数值稳定性的小常数,防止除零错误. Defaults to 1e-6."""super().__init__()# 权重参数self.weight = nn.Parameter(torch.ones(hidden_size))self.variance_epsilon = epsdef forward(self, hidden_states):"""前向传播函数,对输入进行均方根归一化处理Args:hidden_states (torch.Tensor): 输入的隐藏状态张量Returns:torch.Tensor: 经过均方根归一化和权重缩放后的张量"""input_dtype = hidden_states.dtypehidden_states = hidden_states.to(torch.float32)# 均方根归一化:使用方差进行归一化variance = hidden_states.pow(2).mean(-1, keepdim=True)hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)return self.weight * hidden_states.to(input_dtype)Qwen2MLP
class Qwen2MLP(nn.Module):def __init__(self, config):super().__init__()self.config = configself.hidden_size = config.hidden_sizeself.intermediate_size = config.intermediate_size# 三个线性层self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)# 激活函数self.act_fn = ACT2FN[config.hidden_act]def forward(self, x):# 其中对gate_proj输出进过激活函数处理并与up_proj变换后再乘以up_proj,整体作为down_proj输入进行线性变换down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))return down_proj
三、注意力机制:核心交互逻辑(右侧区域)
- 隐藏态经线性投影
- 旋转位置嵌入
- 通过attention_interface,计算注意力与权重,默认使用eager模式计算,可切换为flash_attention模式
- 输出线性变换
Qwen2Attention代码解读
class Qwen2Attention(nn.Module):"""Multi-headed attention from 'Attention Is All You Need' paper"""def __init__(self, config: Qwen2Config, layer_idx: int):super().__init__()self.config = configself.layer_idx = layer_idxself.head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)# 计算键值头分组数量,用于多查询注意力机制self.num_key_value_groups = config.num_attention_heads // config.num_key_value_heads# 计算注意力缩放因子,用于防止点积注意力分数过大self.scaling = self.head_dim**-0.5self.attention_dropout = config.attention_dropoutself.is_causal = True# qkv线性层+偏置self.q_proj = nn.Linear(config.hidden_size, config.num_attention_heads * self.head_dim, bias=True)self.k_proj = nn.Linear(config.hidden_size, config.num_key_value_heads * self.head_dim, bias=True)self.v_proj = nn.Linear(config.hidden_size, config.num_key_value_heads * self.head_dim, bias=True)# 输出线性变换,未使用偏置self.o_proj = nn.Linear(config.num_attention_heads * self.head_dim, config.hidden_size, bias=False)self.sliding_window = config.sliding_window if config.layer_types[layer_idx] == "sliding_attention" else Nonedef forward(self,hidden_states: torch.Tensor,position_embeddings: tuple[torch.Tensor, torch.Tensor],attention_mask: Optional[torch.Tensor],past_key_value: Optional[Cache] = None,cache_position: Optional[torch.LongTensor] = None,**kwargs: Unpack[FlashAttentionKwargs],) -> tuple[torch.Tensor, Optional[torch.Tensor], Optional[tuple[torch.Tensor]]]:input_shape = hidden_states.shape[:-1]hidden_shape = (*input_shape, -1, self.head_dim)# 1、隐藏态经线性投影query_states = self.q_proj(hidden_states).view(hidden_shape).transpose(1, 2)key_states = self.k_proj(hidden_states).view(hidden_shape).transpose(1, 2)value_states = self.v_proj(hidden_states).view(hidden_shape).transpose(1, 2)# 2、旋转位置嵌入cos, sin = position_embeddings# Q、K 经 Qwen2RotaryEmbedding 注入位置信息(旋转编码 RoPE),让模型感知 token 相对位置query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)if past_key_value is not None:# sin and cos are specific to RoPE models; cache_position needed for the static cachecache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position}key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)# 3、通过attention_interface,计算注意力与权重,默认使用eager模式计算,可切换为flash_attention模式attention_interface: Callable = eager_attention_forwardif self.config._attn_implementation != "eager":attention_interface = ALL_ATTENTION_FUNCTIONS[self.config._attn_implementation]attn_output, attn_weights = attention_interface(self,query_states,key_states,value_states,attention_mask, # 注意力压掩码dropout=0.0 if not self.training else self.attention_dropout, # 注意力丢弃率,训练时使用,防止过拟合scaling=self.scaling, # 缩放因子,防止点积注意力分数过大sliding_window=self.sliding_window, # main diff with Llama**kwargs,)# 4、输出线性变换attn_output = attn_output.reshape(*input_shape, -1).contiguous()attn_output = self.o_proj(attn_output)return attn_output, attn_weightsQwen2 模型进行的优化点
归一化层优化:RMSNorm
优化点:采用 RMSNorm(Root Mean Square Layer Normalization)替代传统的 LayerNorm,减少计算量,提升训练稳定性。
代码体现:在modeling_qwen2.py中,Qwen2RMSNorm类实现了该归一化方法。
位置编码优化:旋转位置编码(RoPE)
优化点:使用旋转位置编码,能有效编码相对位置信息,并且对长序列有更好的适应性。
代码体现:在modeling_qwen2.py中,Qwen2RotaryEmbedding类负责生成位置编码,apply_rotary_pos_emb函数用于将位置编码应用到 query 和 key 上。
Qwen2RotaryEmbedding类预计算不同位置的余弦和正弦值缓存起来,避免重复计算。apply_rotary_pos_emb函数通过将 query 和 key 与对应的余弦和正弦值进行运算,实现旋转操作,为 query 和 key 注入位置信息。这种方式相比传统的位置编码,能更好地处理长序列,并且不需要重新训练就能适应超出预训练长度的序列。
注意力机制优化:分组查询注意力(GQA)
优化点:采用分组查询注意力,减少 KV 缓存的显存占用,在性能和效率之间取得平衡。
代码体现:在modeling_qwen2.py的Qwen2Attention类中实现。
通过num_key_value_heads参数将注意力头分组,使得多个查询头可以共享一组键值对。在代码中,通过repeat_kv函数将少量的键值对重复,以匹配查询头的数量,从而在不显著降低性能的情况下,大幅减少了 KV 缓存的显存占用,提升了推理效率。
常见问题
1、版本问题如:
conftest.py:26: in <module>from transformers.testing_utils import HfDoctestModule, HfDocTestParser, is_torch_available
src/transformers/__init__.py:27: in <module>from . import dependency_versions_check
src/transformers/dependency_versions_check.py:57: in <module>require_version_core(deps[pkg])
src/transformers/utils/versions.py:117: in require_version_corereturn require_version(requirement, hint)^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
src/transformers/utils/versions.py:111: in require_version_compare_versions(op, got_ver, want_ver, requirement, pkg, hint)
src/transformers/utils/versions.py:44: in _compare_versionsraise ImportError(
E ImportError: huggingface-hub>=0.34.0,<1.0 is required for a normal functioning of this module, but found huggingface-hub==0.33.4.
E Try: `pip install transformers -U` or `pip install -e '.[dev]'` if you're working with git main类似的问题,根据提示升级或者降低相应版本即可,尝试执行Try后面的命令